Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Analyses IRMf Oury Monchi, Ph.D.
Centre de Recherche, Institut Universitaire de Gériatrie de Montréal & Université de Montréal 1

2
But de ce cours Donner une introduction à l’analyse IRMf la plus classique, c’est à dire celle qui utilise le modèle général linéaire Cette introduction devrait être indépendante du software (à peu de choses prêt!) utilisé pour l’analyse, mais les exemples viendront des minc tools/fmristat (aussi implémenté dans Neurolens) et de SPM
 utilisé pour l’analyse, mais les exemples viendront des minc tools/fmristat (aussi implémenté dans Neurolens) et de SPM.")
3
Plan pour une éxpérience IRMf et son analyse
Dessin Expérimental Prétraitement Modèle statistique Significativité et comparaison multiple Moyennage des séries, des sujets, comparaison de groupes Visualisation A quelle étape devrait-on normaliser les données?

4
Types de dessins expérimentaux
Dessin en block Dessin évènementiel espacé Dessin évènementiel mixte

5
Dessins expérimentaux
Block design (dessin en blocks) Comparaison de longues périodes (ex 16s) d’une condition avec une longue période d’une autre condition Approche traditionnelle Le plus puissant en termes statistiques Dépend moins du modèle hémodynamique créé Event-related design (dessin évènementiel): Comparaison de conditions à périodes courtes (ex 1s) Assez nouveau (date d’à peu près 1997) Moins puissant statistiquement, mais a beaucoup d’avantages
 Comparaison de longues périodes (ex 16s) d’une condition avec une longue période d’une autre condition. Approche traditionnelle. Le plus puissant en termes statistiques. Dépend moins du modèle hémodynamique créé. Event-related design (dessin évènementiel): Comparaison de conditions à périodes courtes (ex 1s) Assez nouveau (date d’à peu près 1997) Moins puissant statistiquement, mais a beaucoup d’avantages.")
6
Plan pour une éxpérience IRMf et son analyse
Dessin Expérimental Prétraitement Modèle statistique Significativité et comparaison multiple Moyennage des séries, des sujets, comparaison de groupes Visualisation A quelle étape devrait-on normaliser les données?

7
Prétraitement – analyses SPM

8
Prétraitement – Correction du Mouvement
1 2 3 4 N-1 N-2 N-3 . N Série 1 Réaligner au 2ème volume de la même série pour toutes les séries p.ex

9
Convolué avec le fintre Gaussien
Lissage Spatial Application d’un filtre Gaussien Généralement exprimé en #mm FWHM “Full Width – Half Maximum” Typiquement ~2 fois la taille d’un voxel Convolué avec le fintre Gaussien Avant la convolution

10
Prétraitement du MNI Fmr_preprocess fait à la fois la correction du mouvement: spécifier l’acquisition cible (-target #) et le lissage, spécifier la taille (-fwhm #en mm) En général choisir la taille du lissage (fwhm), 2 fois plus grand que la taille du voxel acquis
 et le lissage, spécifier la taille (-fwhm #en mm) En général choisir la taille du lissage (fwhm), 2 fois plus grand que la taille du voxel acquis.")
11
Plan pour une éxpérience IRMf et son analyse
Dessin Expérimental Prétraitement Modèle statistique Significativité et comparaison multiple Moyennage des séries, des sujets, comparaison de groupes Visualisation A quelle étape devrait-on normaliser les données?

12
Une Expérience simple TEMPS Blank Screen Intact Objects Scrambled
Lateral Occipital Complex: responds when subject views objects Blank Screen TEMPS Intact Objects Scrambled Objects Un volume (12 tranches) chaque 2 secondes pour 272 secondes (4 minutes, 32 secondes) Conditions changent chaque 16 secondes (8 volumes)
 chaque 2 secondes pour 272 secondes (4 minutes, 32 secondes) Conditions changent chaque 16 secondes (8 volumes)")
13
Quelles sont les données avec lesquels nous devons travailler?
Expérience typique: 64 voxels x 64 voxels x 12 slices x 136 points temporels Cela fait 136 volumes Ou vu autrement 64x64x12 = 49,152 voxels, chacun avec son décours temporel!!

14
Pourquoi a-t-on besoin de statistique?
Tranche 9, Voxel 0, 0 Même là où il n’y a pas de cerveau, il y a du bruit Tranche 9, Voxel 1, 0 Tranche 9, Voxel 22, 7 Signal beaucoup plus grand où le cerveau est, mais il y a encore du bruit Tranche 9, Voxel 14, 42 Ici quelques uns qui montrent à peu près le bon patron... mais est-ce réel? Tranche 9, Voxel 18, 36 Tranche 9, Voxel 9, 27 Ici un voxel qui réponb bien lorsqu’il y a un stimulus visuel Tranche 9, Voxel 13, 41 Ici un qui répond bien lorsqu’il y a des objets intacts On pourrait en principe analyser les données en naviguant à travers les voxels: déplacer le curseur sur différentes régions et regarder si on trouve temporelle qui nous intéresse

15
Pourquoi a-t-on besoin de statistique?
Il est clair que naviguer à travers les voxels n’est pas plausible. Il nous faudrait le faire 49,152 fois cela demanderait beaucoup de décisions subjectives pour savoir si une activation est réelle. C’est pour cela qu’on a besoin de statistiques Statistiques: Nous indiques ou regarder pour les activations qui SONT reliés à notre paradigme Nous aide à décider à quel point les activations sont ‘réelles’ The lies and damned lies come in when you write the manuscript

16
Statistiques: le test t
Le test t sert à comparer la grosseur des effets (i.e. la différence entre blocks) à la variance des données (i.e. déviation standard). En (A), l’effet est de 2 unités, variance est haute, donc t = 2,3. En (B), l’effet est de seulement 1 unité, mais la variance est beaucoup plus petite, donc t = 6,7, une valeur beaucoup plus grande
 à la variance des données (i.e. déviation standard). En (A), l’effet est de 2 unités, variance est haute, donc t = 2,3. En (B), l’effet est de seulement 1 unité, mais la variance est beaucoup plus petite, donc t = 6,7, une valeur beaucoup plus grande.")
17
PCA_IMAGE: PCA du temps x espace
20 40 60 80 100 120 140 4 3 2 1 Composante Cadre Composantes temporelles (d.s., % variance expliquée) 0.68, 46.9% 0.29, 8.6% 0.17, 2.9% 0.15, 2.4% -1 -0.5 0.5 Tranche (0 based) Composantes Spatiales 6 8 10 12 1: exclure les premières images 2: drift (dérive) 3: long-range correlation or anatomical effect: remove by converting to % of brain 4: signal? PCA = Principal Component Analysis
 0.68, 46.9% 0.29, 8.6% 0.17, 2.9% 0.15, 2.4% Tranche (0 based) Composantes Spatiales : exclure les premières images. 2: drift. (dérive) 3: long-range. correlation. or anatomical. effect: remove. by converting. to % of brain. 4: signal PCA = Principal Component Analysis.")
18
Le Modèle Linéaire Général (GLM)
Le test t, corrélations et analyse Fourier fonctionnent pour des dessins simples, et étaient très communs au début d’imagerie Le modèle linéaire général (GLM) est maintenant disponible dans beaucoup de paquets software, et a tendance à être l’analyse préférée Pourquoi le GLM est si populaire? Le GLM est un outil qui peut faire tout ce que les tests plus simples peuvent faire Vous pouvez imaginer n’importe quelle combinaison de contrastes (e.g. intact – scrambled, scrambled – repos) avec un GLM, plutôt que des corrélations multiples Le GLM nous donne une plus grande flexibilité pour combiner les données intra- et inter-sujet Il est aussi plus facile de contrebalancer les ordres et jeter les mauvaises sections des données Le GLM nous permet de modéliser des choses qui pourraient faire partie de la variance des données, même si elles ne sont pas intéressantes par soi-même (e.g. mouvements de la tête On verra plus tard dans le cours, le GLM permet aussi d’utiliser des dessins plus complexes (e.g. dessins factoriels)
 est maintenant disponible dans beaucoup de paquets software, et a tendance à être l’analyse préférée. Pourquoi le GLM est si populaire Le GLM est un outil qui peut faire tout ce que les tests plus simples peuvent faire. Vous pouvez imaginer n’importe quelle combinaison de contrastes (e.g. intact – scrambled, scrambled – repos) avec un GLM, plutôt que des corrélations multiples. Le GLM nous donne une plus grande flexibilité pour combiner les données intra- et inter-sujet. Il est aussi plus facile de contrebalancer les ordres et jeter les mauvaises sections des données. Le GLM nous permet de modéliser des choses qui pourraient faire partie de la variance des données, même si elles ne sont pas intéressantes par soi-même (e.g. mouvements de la tête. On verra plus tard dans le cours, le GLM permet aussi d’utiliser des dessins plus complexes (e.g. dessins factoriels)")
19
Modéliser la réponse attendue (assomptions)
La réponse est presque entièrement déterminée par le dessin expérimental La réponse BOLD a la même forme et le même délai à travers toutes les régions du cerveau The signal BOLD est décomposable de manière linéaire à travers les événements La réponse devrait être la même pour tous les essais d’une même condition

20
Modéliser la réponse attendue (fmridesign)
Convoluer avec un modèle hrf

21
Modéliser les données (GLM)
= β + y x ε

22
Modéliser les données (GLM)
yi = xiβ + εi PENDANT Pas justifié par le modèle Du scanneur erreur JAMAIS paramètre données modèle Poids du modèle Vous créez APRÈS AVANT

23
En recherche d’un critère
On essaie de minimiser: Σ(yi – Xiβ)2 données modèle paramètre
2. données. modèle. paramètre.")
24
Estimation des Moindres Carrés
Nous devons faire ceci pour chaque voxel séparément (i.e. on a le même nombre de β que de voxels Référence : J. Armony

25
Déduction statistique
Où, dans le cerveau, avons nous un paramètre expérimental (β) significativement plus grand que zéro? Référence : J. Armony
 significativement plus grand que zéro Référence : J. Armony.")
26
Déduction statistique
Hypothèse: Contraste: combinaison linéaire de paramètres c = [1 -1] Référence : J. Armony

27
FMRILM Paramètres inconnus
Ajuste un modèle linéaire pour une série de temps IRMf avec AR(p) erreurs Modèle linéaire: Yt = (stimulust * HRF) b + driftt c + erreurt AR(p) erreurs: erreurt = a1 errort-1 + … + ap erreurt-p + s WNt Paramètres inconnus Référence : Dr. K. Worsley
 erreurs. Modèle linéaire: Yt = (stimulust * HRF) b + driftt c + erreurt. AR(p) erreurs: erreurt = a1 errort-1 + … + ap erreurt-p + s WNt. Paramètres inconnus. Référence : Dr. K. Worsley.")
28
Implémentation FMRISTAT
Pour 120 scans, séparés par 3 secondes, et 13 tranches entrelacées chaque 0.12 secondes, utilisez: frametimes=(0:119)*3; slicetimes=[ ];
*3; slicetimes=[ ];")
29
Implémentation FMRISTAT
events=[ ]; Un dessin en block de « 3 scans de repos; 3 scans de stimulus chaud; 3 scans de repos; 3 scans de stimulus tiède », répété 10 fois (120 scans au total) Contraste: contrast = [1 0; 0 1; 1 -1];
 Contraste: contrast = [1 0; 0 1; 1 -1];")
30
FMRISTAT, étude paramétrique
Chaud = 49oC, Tiède = 35oC Disons que la température du stimulus changeait d’une façon aléatoire sur 20 blocks, prenant 5 valeurs réparties également entre 35 et 49: temperature=[ ]'; events=[zeros(20,1)+1 eventimes duration ones(20,1); zeros(20,1)+2 eventimes duration temperature] contrast=[0 1];
+1 eventimes duration ones(20,1); zeros(20,1)+2 eventimes duration temperature] contrast=[0 1];")
31
FMRISTAT, étude paramétrique

32
Plan pour une éxpérience IRMf et son analyse
Dessin Expérimental Prétraitement Modèle statistique Significativité et comparaison multiple Moyennage des séries, des sujets, comparaison de groupes Visualisation A quelle étape devrait-on normaliser les données?

33
Types d’erreurs statistique
Erreur Type I Rejet correct Succès Erreur Type II Hypothèse Vraie? H1 (active) H0 (inactive) Réponse du test statistique Accepter H Rejeter H0 (inactive) (active)
 H0 (inactive) Réponse du test statistique. Accepter H0 Rejeter H0. (inactive) (active)")
34
Significcativité et comparisons multiples
Comparaisons multiples à travers le cerveau: il y a ~200,000 voxels dans le cerveau!! Options: Pas de correction (p < 0.05 non corrigé) Avantage: facile, minimise les erreurs de type II Désavantage: Beaucoup trop de faux positifs (Erreurs de Type I), 5% 200,000 = 10,000 voxels! Correction de Bonferroni (p < 0.05/200,000 = ) Avantage: Facile, minimise les erreurs de type I Désavantage: Trop strict. Trop d’erreurs de Type II
 Avantage: facile, minimise les erreurs de type II. Désavantage: Beaucoup trop de faux positifs. (Erreurs de Type I), 5% 200,000 = 10,000 voxels! Correction de Bonferroni (p < 0.05/200,000 = ) Avantage: Facile, minimise les erreurs de type I. Désavantage: Trop strict. Trop d’erreurs de Type II.")
35
Correction de Bonferroni
Données pour un seul sujet à trois niveaux de signifiance Probabilité ajustée à 0.05 Probabilité ajustée à Correction de Bonferroni, ajustée à une valeur P de 0.05 fmri-fig jpg

36
Significativité et comparaisons multiples
Les champs gaussiens aléatoires (sorte de lissage spatial) Avantage: Marche bien pour les données spatialement corrélés. Résultats raisonnable. Désavantage: Encore assez strict. Enlève un peu de spécificité spatiale (à cause du lissage) “Pseudo-Bonferroni” correction (p < 0.001), il faut savoir le motiver Analyses par régions d’intérêts
 Avantage: Marche bien pour les données spatialement corrélés. Résultats raisonnable. Désavantage: Encore assez strict. Enlève un peu de spécificité spatiale (à cause du lissage) Pseudo-Bonferroni correction (p < 0.001), il faut savoir le motiver. Analyses par régions d’intérêts.")
37
Déductions au niveau du voxel
Retenir les voxels au-dessus du seuil du niveau de , u Meilleure spécificité spatiale L’hypothèse nulle à un seul voxel peut être rejetée u space Voxels significatives Voxels non-significatives

38
Déductions au niveau du cluster
Procédé à deux étapes Définir les clusters par seuil arbitraire uclus Retenir les clusters plus grands que le seuil du niveau de , k uclus space Cluster non-significatif k k Cluster significatif

39
Plan pour une éxpérience IRMf et son analyse
Dessin Expérimental Prétraitement Modèle statistique Significativité et comparaison multiple Moyennage des séries, des sujets, comparaison de groupes Visualisation A quelle étape devrait-on normaliser les données?

40
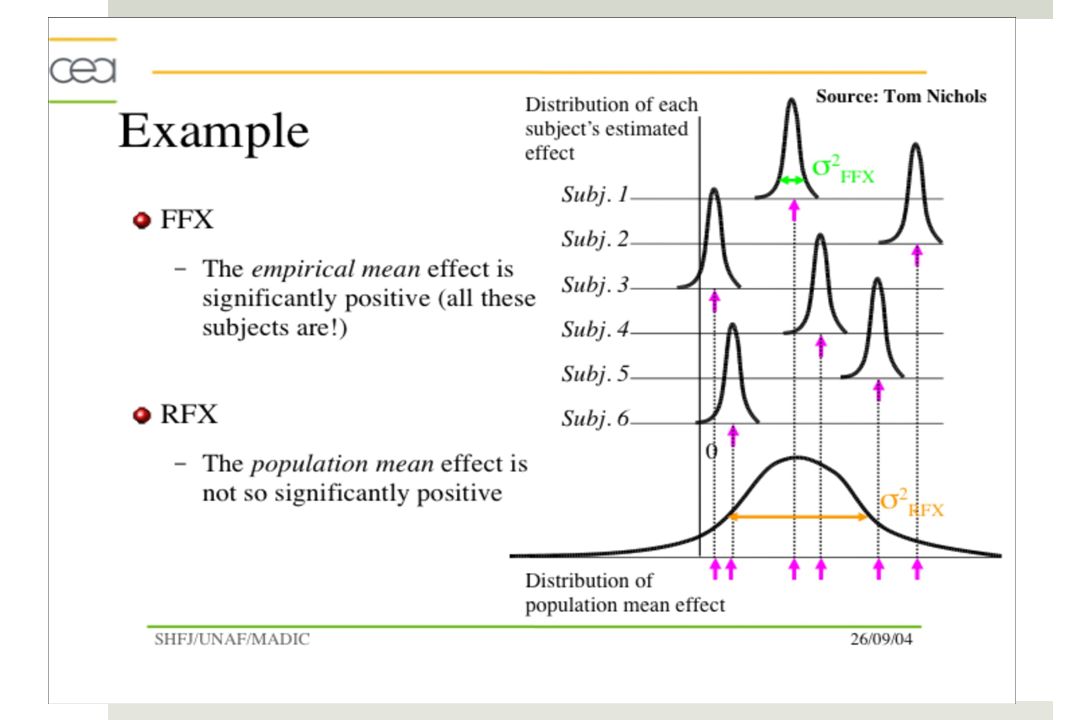
Analyses de Groupe Motivation & Définitions: Le problème d’inférence de groupe Analyse à effets mixtes (FFX) implémentation SPM FMRISTAT (possible, mais pas recommandé!) Analyse à effets aléatoire (RFX) implémentation SPM du RFX ‘classique’ FMRISTAT solution alternative: analyse à effets mélangés: Lissage du rapport des variances
 Analyse à effets aléatoire (RFX) implémentation SPM du RFX ‘classique’ FMRISTAT solution alternative: analyse à effets mélangés: Lissage du rapport des variances.")
41
Motivation effets fixes vs. aléatoires
Quelle est la question qui nous intéresse! Qu’est-ce que nous voulons inférer: Une conclusion sur l’échantillon ou groupe spécifique que nous avons examiné Une conclusion sur toute la population d’ou provient cet échantillon Pour le 1er problème, une analyse à effet fixe est suffisante Conclusion: Ce groupe spécifique de patients de ‘type A’ révèle ce patron d’activation Pour le 2nd problème une analyse à effet aléatoire est nécessaire Conclusion: Ce patron d’activation devrait être observé chez tous les patients de ‘Type A’

43
Effets Fixes Avantages: Beaucoup de degrés de liberté ( ~1000)
Prend en compte la concordance global du modèle Faux négatifs peu probable Désavantages: La variance entre les sujets et les séries n’est pas prise en compte Les résultats peuvent provenir majoritairement d’un ou de quelques sujets Erreurs de Type I, c’est à dire des faux positifs

44
Effets Aléatoires Avantages:
Prend en compte la variabilité inter séries et inter sujets Moins sensible à certains paramètres spécifique du modèle Désavantages: Très peu de degrés de liberté erreur de type II, faux négatifs Très sensible à la variation fonctionnelle et anatomique inter-sujets

45
Effets fixes: implémentation SPM
Autre terme: analyse de premier niveau Identique à l’analyse 1run/sujet, sauf que le nombre de scans doit être spécifié pour chaque run ou sujet Par exemple: « (100, 100, 100, 100, 100) » pour 100 acquisitions, 5 runs ou sujets
 » pour 100 acquisitions, 5 runs ou sujets.")
46
Effets fixes: implémentation fmristat
1 Sujet, 1 contraste, 5 runs df = multistat (input_files_effect, input_files_sdeffect, input_files_df, input_files_fwhm, X, contrast, output_file_base, which_stats, Inf) input_files_effect = [’run1_cont1_mag_ef_tal.mnc'; ’run2_cont1_mag_ef_tal.mnc'; ’run3_cont1_mag_ef_tal.mnc'; ’run4_cont1_mag_ef_tal.mnc'; ’run5_cont1_mag_ef_tal.mnc]; input_files_sdeffect = [’run1_cont1_mag_sd_tal.mnc'; ’run2_cont1_mag_sd_tal.mnc'; ’run3_cont1_mag_sd_tal.mnc'; ’run4_cont1_mag_sd_tal.mnc'; ’run5_cont1_mag_sd_tal.mnc’]; X = [1 1 1] fwhm_varatio
 input_files_effect = [’run1_cont1_mag_ef_tal.mnc ; ’run2_cont1_mag_ef_tal.mnc ; ’run3_cont1_mag_ef_tal.mnc ; ’run4_cont1_mag_ef_tal.mnc ; ’run5_cont1_mag_ef_tal.mnc]; input_files_sdeffect = [’run1_cont1_mag_sd_tal.mnc ; ’run2_cont1_mag_sd_tal.mnc ; ’run3_cont1_mag_sd_tal.mnc ; ’run4_cont1_mag_sd_tal.mnc ; ’run5_cont1_mag_sd_tal.mnc’]; X = [ ] fwhm_varatio.")
47
Effets fixes: implémentation fmristat
Par contre, les analyses à effets fixes ne sont pas recommandées, parce qu’elles ne tiennent pas en compte la variance inter-run et inter-sujet Solution fmristat: Variance ratio smoothing (voir ci-bas)
")
48
Effets aléatoires: implémentation SPM
Importez les fichiers .con de l’analyse à 1er niveau (un seul contraste de différents sujets) dans une analyse a 2ème niveau Degrés de liberté (DF) très bas, donné par le "nombre de sujets" - "rank of 2nd level design matrix" Donc si nous avons 12 sujets dans un groupe, DF = 11 Ce type d’analyse peut être trop conservateur, et requiert beaucoup de sujets, et beaucoup de données pour atteindre signifiance
 dans une analyse a 2ème niveau. Degrés de liberté (DF) très bas, donné par le nombre de sujets - rank of 2nd level design matrix Donc si nous avons 12 sujets dans un groupe, DF = 11. Ce type d’analyse peut être trop conservateur, et requiert beaucoup de sujets, et beaucoup de données pour atteindre signifiance.")
49
Effets aléatoires: implémentation fmristat
Il est possible de faire le même type d’analyse à effets aléatoires dans fmristat en ajustant le paramètre fwhm_variatio à 0. df = multistat (input_files_effect, input_files_sdeffect, input_files_df, input_files_fwhm, X, contrast, output_file_base, which_stats, 0) Par contre, fmristat nous permet d’implémenter une analyse à effets aléatoires avec un nombre de degrés de liberté plus haut, et devient donc moins conservateur
 Par contre, fmristat nous permet d’implémenter une analyse à effets aléatoires avec un nombre de degrés de liberté plus haut, et devient donc moins conservateur.")
50
MULTISTAT: modèle linéaire à effets mixtes
Sert à combiner les effets de différentes runs/sessions/sujets Ei = effect for run/session/subject i Si = standard error of effect Modèle à effets mixtes: Ei = covariatesi c + Si WNiF + WNiR }de FMRILM ? ? D’habitude 1, mais pourrait ajouter groupe, traitement, âge, sexe, ... Effet aléatoire, dû à la variabilité de run en run Erreur des ‘Effets fixes’, dû à la variabilité au sein du même run

51
Alternative fmristat: Variance Ratio Smoothing
La variance à effets aléatoires est très variable, à cause des degrés de liberté (dfs) très bas. L’idée de Variance Ratio Smoothing est d’utiliser la variance à effets fixes comme template pour estimer la variance à effets aléatoires Ceci est fait par régularisant le rapport de variance à effets aléatoires (estimée) divisée par la variance à effets fixes (obtenus de l’analyse précédente) Fwhm_varatio est un filtre qui permet de régulariser ce rapport Comment choisit-on Fwhm_variatio? Sa valeur est motivée par les dfs conséquents. Une bonne valeur à viser est 100df. Les nouvelles versions d’fmristat vous permettent d’entrer le nombre de dfs désiré en insérant une valeur négative au paramètre fwhm_varatio: df = multistat (input_files_effect, input_files_sdeffect, input_files_df, input_files_fwhm, X, contrast, output_file_base, which_stats, -100)
 très bas. L’idée de Variance Ratio Smoothing est d’utiliser la variance à effets fixes comme template pour estimer la variance à effets aléatoires. Ceci est fait par régularisant le rapport de variance à effets aléatoires (estimée) divisée par la variance à effets fixes (obtenus de l’analyse précédente) Fwhm_varatio est un filtre qui permet de régulariser ce rapport. Comment choisit-on Fwhm_variatio Sa valeur est motivée par les dfs conséquents. Une bonne valeur à viser est 100df. Les nouvelles versions d’fmristat vous permettent d’entrer le nombre de dfs désiré en insérant une valeur négative au paramètre fwhm_varatio: df = multistat (input_files_effect, input_files_sdeffect, input_files_df, input_files_fwhm, X, contrast, output_file_base, which_stats, -100)")
52
Exemple: contraste entre populations
n sujets, groupes patients vs contrôles Contraste = [1 -1 Patient > contrôles -1 1] Contrôles > patients input_files_effect = [’subj1_patient_mag_ef_tal.mnc’; ’subj2_patient_mag_ef_tal.mnc’; ’subjn_patient_mag_ef_tal.mnc’; ’subj1_control_mag_ef_tal.mnc'; ’subj2_control_mag_ef_tal.mnc; ‘sunjn_control_mag_ef_tal.mnc]; input_files_sdeffect =[’subj1_patient_mag_sd_tal.mnc'; ’subj2_patient_mag_sd_tal.mnc'; ’subjn_patient_mag_sd_tal.mnc'; ’subj1_control_mag_sd_tal.mnc'; ’subj2_control_mag_sd_tal.mnc; ‘sunjn_control_mag_sd_tal.mnc]; X = [1 0 sujet 1 groupe patient 1 0 sujet 2 groupe patient 1 0 sujet n groupe patient 0 1 sujet 1 groupe contrôle 0 1 sujet 2 groupe contrôle 0 1] sujet n groupe contrôle

53
Combien de sujets? La plus grande portion de variance vient de la dernière étape, i.e. la combinaison des sujets: sdrun sdsess sdsuj2 nrun nsess nsuj nsess nsuj nsuj Si vous voulez optimiser le temps d’utilisation du scanneur, prenez plus de sujets Ce que vous faites aux premiers stades importe peu! +

54
Comparaison SPM’99 fmristat Différents temps d’acquisition des tranches Ajoute une dérive temporale Décale le modèle Enlèvement du drift Low-frequency cosines (flat at the ends) Splines (free at the ends) Corrélation temporale AR(1), paramètre global, biais réduction pas nécessaire AR(p), paramètres voxel, biais réduction Estimation des effets Band pass filter, ensuite moindres carrés, ensuite correction pour corrélation temporale Pre-whiten, ensuite moindres carrés (pas d’autres corrections nécessaires) Rationale Plus robuste, mais degrés de liberté plus bas Plus précis, degrés de liberté plus haut Effets aléatoires Pas de régularisation, degrés de liberté bas, bas de conjuncs Régularisation, degrés de liberté hauts, conjuncs Carte du délai Non Oui
 Splines (free at the ends) Corrélation temporale. AR(1), paramètre global, biais réduction pas nécessaire. AR(p), paramètres voxel, biais réduction. Estimation des effets. Band pass filter, ensuite moindres carrés, ensuite correction pour corrélation temporale. Pre-whiten, ensuite moindres carrés (pas d’autres corrections nécessaires) Rationale. Plus robuste, mais degrés de liberté plus bas. Plus précis, degrés de liberté plus haut. Effets aléatoires. Pas de régularisation, degrés de liberté bas, bas de conjuncs. Régularisation, degrés de liberté hauts, conjuncs. Carte du délai. Non. Oui.")
55
Plan pour une éxpérience IRMf et son analyse
Dessin Expérimental Prétraitement Modèle statistique Significativité et comparaison multiple Moyennage des séries, des sujets, comparaison de groupes Visualisation A quelle étape devrait-on normaliser les données?

56
Visualisations 2D et 3D fmri-fig jpg

57
Vues « glass-brain » fmri-fig jpg

58
Vue aplatie du cerveau fmri-fig jpg

59
Plan pour une éxpérience IRMf et son analyse
Dessin Expérimental Prétraitement Modèle statistique Significativité et comparaison multiple Moyennage des séries, des sujets, comparaison de groupes. Visualisation A quelle étape devrait-on normaliser les données?

60
À quelle étape devrait-on normaliser les données?

61
À quelle étape devrait-on normaliser les données?
Dans SPM, en défaut, la normalisation se fait du tout début, avant de moyenner les runs. Ceci est un choix sûr, puisque tous les fichiers seront normalisés dans le même espace En fmristat, le choix est à vous! Mais la normalisation déforme les données, et certaines informations sont perdues. Théoriquement, il est meilleur de normaliser vos données à la plus grande étape, i.e. au niveau inter-sujet Par contre, ceci dépend du software de correction de mouvement que vous utilisez. Est-ce que la correction du mouvement est faite intra ou inter-runs?

62
À quelle étape devrait-on normaliser les données?
Resample to Talairach space after linear or non-linear transformations Référence : Worsley et al., 2002

63
À quelle étape devrait-on normaliser les données?
Resample to Talairach space after linear or non-linear transformations Référence : Worsley et al., 2002

64
Software et diapos Jorge Armony BIG seminars: Keith Worsley fmristat: SPM courses: Jody Culham “fMRI for dummies” es.htm Neurolens: FSL: FIN Prochain cours: normalisation Remerciements: Cécile Madjar, Kristina Martinu

Présentations similaires

>")





>")











