Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
MBA Statistique

2
La Statistique, c ’est ? « C’est la science d’apprendre à partir de données. Cette définition doit être interprétée dans un sens très large. Elle doit tout inclure, de la planification pour la cueillette des données en passant par la gestion subséquente de celles-ci jusqu’aux dernières activités comme l’inférence statistique pour la prise de décision et la présentation des résultats. » Jon Kettenring, ASA Past President

3
Plan du cours Variation. Échantillonnage et estimation.
Inférence statistique et prise de décision. Analyse de données qualitatives. Régression linéaire simple et multiple. Prévisions. Contrôle statistique des procédés. Révision.

4
ÉVALUATION Travail en équipe: 40% Examen final: 60%

5
Variation, échantillonnage et estimation.
COURS # 1 Variation, échantillonnage et estimation.

6
Variation “Le principal problème en gestion est l’incapacité à comprendre et interpréter le concept de variation" W. Edwards Deming

7
Variation "Management takes a major step forward when they stop asking you to explain random variation" F. Timothy Fuller

8
Variation "Failure to understand variation is a central problem of management" Lloyd S Nelson

9
Airport Immigration

10
Airport Immigration La direction s’attendait à ce que les employés s’occupent de 10 passagers durant cette période. Le directeur des services d’immigration, en prenant connaissance de ces données, était insatisfait de la performance de Colin songeait à récompenser Frank

11
Expérience des billes (Deming)
Programme EXCEL: beads.xls Les billes rouges sont associées à des produits défectueux. Cinq fois par jour, des techniciens choisissent au hasard un échantillon de 50 billes et comptent le nombre de billes rouges (produits défectueux).
.")
12
Beads History – 17 July 2000

13
Beads History - 9 March 2000

14
Beads History - 8 March 2001 This and the following 7 slides gives results from some previous experiments. You should aim to replace these by your own experimental results.

15
Beads History - 5 March 1999

16
Beads History - 19 July 1996

17
Beads History - 8 March 1996

18
Beads History - 10 March 1995

19
Beads History - 6 March 1998

20
Beads History: 27 Experiments
10 more sets of results added to those given in the book.

21
Beads Averages

22
Approche de pompier Problème Solution

23
Approche scientifique
Baser ses décisions sur des données et non des intuitions. Tenter de trouver les causes du problème au lieu de simplement réagir aux symptômes. Chercher des solutions permanentes au lieu de solutions rapides.

24
Approche scientifique
Solution Problème Cause

25
On a besoin de données pour
Comprendre le processus Déterminer les priorités Éliminer les causes de variation Observer le processus Établir des liens

26
Étapes d’une analyse statistique:
Planifier la collecte de données; Récolter les données; Les évaluer; Tirer des conclusions.

27
L ’échantillonnage Notre connaissance, nos attitudes et nos actions sont basés, en grande partie, sur des échantillons. Par exemple, l’opinion d’une personne sur une institution ou une entreprise qui fait des milliers de transactions dans une journée est souvent déterminé par seulement une ou deux rencontres avec cette institution.

28
Opérations gouvernementales:
Faire des études pour aider au développement des affaires publiques et des programmes sociaux. Exemples: prix des biens et services; fluctuations de l’économie; taux de chômage; évolution de la population.

29
Recherche scientifique:
La statistique permet de valider des inférences dans divers domaines: Datation au carbone 14; Estimation de risque d’éruptions ou de tremblements de terre; Essais cliniques (performance d’un nouveau traitement); Études de populations en biologie(cerfs, poissons); Qualité de l’eau; Tests psychologiques.
; Études de populations en biologie(cerfs, poissons); Qualité de l’eau; Tests psychologiques.")
30
Affaires et industries:
Prévision de la demande de biens et services; Contrôles de la qualité; Gestion de portefeuilles; Prévision des risques.

31
Recensement vs Échantillon
Recensement = vérité l’information que l’on désire est disponible pour tous les individus de la population étudiée. Échantillon = estimation de la vérité l’information n’est disponible que pour un sous-ensemble des individus de la population étudiée.

32
Schéma de l’échantillonnage
Population Paramètre Choix estimation Échantillon Statistique calcul

33
Avantages d’un échantillon
Coût réduit Rapidité accrue Offre plus de possibilités dans certains cas il peut être impossible de faire un recensement (ex: contrôle de qualité) Peut-être plus précis! cas où une main-d’œuvre hautement qualifiée est requise pour la collecte des données
 Peut-être plus précis! cas où une main-d’œuvre hautement qualifiée est requise pour la collecte des données.")
34
Échantillons probabilistes et non probabilistes

35
Les erreurs d’échantillonnages
Erreur aléatoire différents échantillons vont produire différentes estimations de la caractéristique de la population à l’étude Erreurs systématiques - biais échantillon non probabiliste échantillon probabiliste mais avec un taux élevé de non-répondants instrument de mesure biaisé

36
TV Show Poll - March 1998 Should Hamilton be renamed Waikato City?
4400 ont appelé participé 73% étaient contre le changement Quel type d’échantillonnage a été utilisé? Quelles sont les conclusions à tirer?

37
Illustration : biais vs variabilité
Le biais est la divergence répétée, dans la même direction, des estimations d'un paramètre. Une grande variabilité signifie que les valeurs répétées des estimations sont très éparpillées; les résultats de l'échantillonnage ne sont pas reproductibles.

38
a) Grand biais, faible variabilité
b) faible biais, grande variabilité c) Grand biais, grande variabilité d) faible biais, faible variabilité
 faible biais, grande variabilité. c) Grand biais, grande variabilité. d) faible biais, faible variabilité.")
39
Biais dû à la non-réponse
Le biais est souvent le résultat de la non-réponse lors de sondages. En effet supposons que la population est divisée en deux groupes : les répondants (60%) et les non répondants (40%). Parmi les répondants 65% des personnes sont en faveur d’un projet et parmi les non répondants 20% sont en faveur du projet. La vraie proportion de la population en faveur du projet est donc p = 47%. Un sondage nous donnera une estimation de p autour de 65 (n’égale pas 47%). Le biais est donc de 18%.
 et les non répondants (40%). Parmi les répondants 65% des personnes sont en faveur d’un projet et parmi les non répondants 20% sont en faveur du projet. La vraie proportion de la population en faveur du projet est donc p = 47%. Un sondage nous donnera une estimation de p autour de 65 (n’égale pas 47%). Le biais est donc de 18%.")
40
Comment faire un tirage aléatoire simple?
Mettre les noms de tous les N individus de la population dans un chapeau et en tirer un échantillon de n au hasard. Numéroter les individus de la population de 1 à N et utiliser une table de nombres aléatoires. Utiliser un logiciel qui génère des nombres aléatoires (ex: Excel, MINITAB, SAS).
.")
42
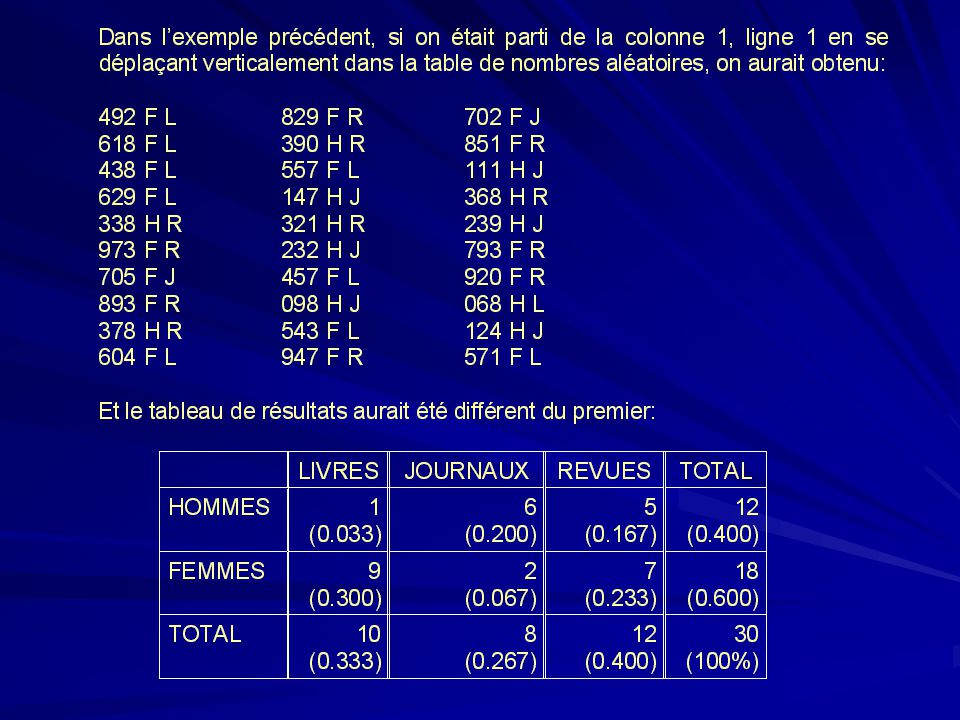
On supposera que les individus de la population sont ordonnés de la manière suivante, afin d ’obtenir les résultats pour divers échantillons que nous choisirons au hasard ultérieurement: 1 à Homme Livre 81 à Homme Journal 281 à Homme Revue 401 à Femme Livre 641 à Femme Journal 761 à Femme Revue. On choisit un échantillon de 30 personnes: (en partant de la colonne 6, ligne 6 en se déplaçant horizontalement dans la table de nombres aléatoires) individu résultat individu résultat individu résultat 033 H L 924 F R 646 F J 648 F J 707 F J 886 F R 847 F R 054 H L 823 F R 204 H J 329 H R 920 F R 334 H R 776 F R 461 F L 639 F L 100 H J 893 F R 193 H J 871 F R 829 F R 639 F L 007 H L 380 H R 411 F L 255 H J 900 F R 095 H J 980 F R 796 F R
 individu résultat individu résultat individu résultat. 033 H L 924 F R 646 F J. 648 F J 707 F J 886 F R. 847 F R 054 H L 823 F R. 204 H J 329 H R 920 F R. 334 H R 776 F R 461 F L. 639 F L 100 H J 893 F R. 193 H J 871 F R 829 F R. 639 F L 007 H L 380 H R. 411 F L 255 H J 900 F R. 095 H J 980 F R 796 F R.")
43
Exemple:

45
Remarques : Les résultats obtenus dépendent de l ’échantillon prélevé.
Si les échantillons sont prélevés selon les règles de l ’art, les résultats devraient se ressembler. Pour un tirage aléatoire simple, chaque individu de la population a la même chance d ’être sélectionné à chaque tirage. Pour un tirage aléatoire simple, tous les échantillons possibles de même taille ont la même chance d ’être sélectionnés.

46
Les sondages d’opinion
Les résultats obtenus dans un échantillon probabiliste serviront à généraliser à l’ensemble de la population. Mais le fait d’utiliser un échantillon induit nécessairement une marge d’erreur que nous essayerons de contrôler. Nous distinguerons deux types de données: qualitatives et quantitatives.

47
Types de données Qualitatives (échelle de mesure: nominale ou ordinale) (paramètre: %) exemples: sexe (F, M) parti politique (PLQ, PQ, ADQ) marque préférée (Coke, Pepsi, Marque maison, …) niveau de satisfaction (échelle de Likert de 1 à 5) Quantitatives (échelle de mesure: intervalle ou rapport) (paramètre: moyenne) Âge, revenu, rendement
 marque préférée (Coke, Pepsi, Marque maison, …) niveau de satisfaction (échelle de Likert de 1 à 5) Quantitatives (échelle de mesure: intervalle ou rapport) (paramètre: moyenne) Âge, revenu, rendement.")
48
Estimation par intervalle de confiance
Pour estimer la proportion p d ’individus possédant la caractéristique à l ’étude dans la population, ou la moyenne , on utilise un intervalle de confiance au niveau (1- ).
.")
49
Estimation par intervalle de confiance (suite)
L ’estimation par intervalle de confiance consiste à établir un intervalle de valeurs qui nous permet d ’affirmer, avec un certain niveau de confiance ou de certitude prédéterminé (en général: 90%, 95% ou 99%), que la vraie valeur du paramètre dans la population se trouve dans cet intervalle.
, que la vraie valeur du paramètre dans la population se trouve dans cet intervalle.")
50
Intervalle de confiance pour estimer une proportion p
Exemple: Sur un échantillon de 125 étudiants d ’un collège interrogés pour savoir s ’ils ont l ’intention de voter aux prochaines élections de leur association, 45 ont répondu positivement. Estimer, de façon ponctuelle, la proportion de l ’ensemble des étudiants de cette institution qui ont l ’intention de voter aux prochaines élections.

51
Solution: On estime la proportion p inconnue (de la population) par celle obtenue dans l’échantillon.
 par celle obtenue dans l’échantillon.")
52
I.C. pour estimer une proportion p
Programme EXCEL: ICproportion.xls Si la taille de l’échantillon n est assez grande, l ’intervalle de confiance au niveau (1 - ) pour estimer la vraie proportion p du caractère à l ’étude dans la population, est donnée par: où est la proportion de succès dans l’échantillon,
 pour estimer la vraie proportion p du caractère à l ’étude dans la population, est donnée par: où est la proportion de succès dans l’échantillon,")
53
Exemple (suite) : Par conséquent, un intervalle de confiance de 95% de certitude pour la proportion de l ’ensemble des étudiants de cette institution qui ont l ’intention de voter aux prochaines élections nous est donné par:

54
Exemple (suite) : Comment rapporterait-on les résultats de ce sondage dans le journal étudiant de ce collège? 36% des étudiants du collège ont l ’intention d ’exercer leur droit de vote aux prochaines élections de l ’association étudiante. La marge d ’erreur est de 8,4% avec un niveau de confiance de 95% (ou avec un degré de certitude de 95% ou 19 fois sur 20).
.")
55
Remarques: Cette formule est approximative et s ’applique uniquement pour les grands échantillons. Si je prends tous les échantillons aléatoires possibles de taille n et que je calcule pour chacun un intervalle de confiance au niveau de 95%, 95% d’entre eux incluront la vraie proportion p de la population, et donc 5% ne l ’incluront pas. La quantité est appelé marge d ’erreur ou précision, au niveau de confiance 95% (19 fois sur 20).
.")
56
Marge d ’erreur au niveau 95%

57
Marge d ’erreur au niveau 90%

58
Calcul de la taille n pour assurer une marge d ’erreur maximale
Si nous voulons estimer la proportion p au niveau de confiance (1-) avec une marge d ’erreur maximale notée e, alors nous avons la relation suivante pour le calcul de la taille n de l ’échantillon:
 avec une marge d ’erreur maximale notée e, alors nous avons la relation suivante pour le calcul de la taille n de l ’échantillon:")
59
I.C. pour estimer la moyenne
Programme EXCEL: ICmoyenne.xls De façon générale, si la taille de l’échantillon n est assez grande, l ’intervalle de confiance au niveau (1 - ) pour estimer la vraie moyenne de la population, est donnée par:
 pour estimer la vraie moyenne de la population, est donnée par:")
60
Remarques: Cette formule est approximative et s’applique uniquement pour les grands échantillons (sauf si la caractéristique a une distribution normale et que l ’écart type est connu la formule est exacte). Lorsque l ’écart type est inconnu, on utilise une estimation de et on remplace la valeur de Z0,025=1,96 pour une valeur légèrement supérieure lu dans une table de la loi de Student qui dépend de la taille de l ’échantillon.
. Lorsque l ’écart type est inconnu, on utilise une estimation de et on remplace la valeur de Z0,025=1,96 pour une valeur légèrement supérieure lu dans une table de la loi de Student qui dépend de la taille de l ’échantillon.")
61
Remarques: (suite) Interprétation d’un intervalle de confiance au niveau 95% pour la moyenne d ’une caractéristique dans la population: Si je prends tous les échantillons aléatoires de taille n et que je calcule pour chacun un intervalle de confiance de 95%, 95% d’entre eux incluront la vraie moyenne de la population, et donc 5% ne l ’incluront pas.

62
Exemple Afin de connaître le coût hebdomadaire moyen du panier d ’épicerie pour une famille de 4 personnes résidant à Sherbrooke, on prélève un échantillon de 50 de ces familles et on note le montant de leur épicerie de cette semaine. On obtient un montant moyen de 155$. L’écart type de l’échantillon est de 15$.

63
Exemple (suite) : Estimer le coût actuel moyen du panier d ’épicerie d ’une famille de 4 personnes résidant à Sherbrooke à l ’aide d ’un intervalle de confiance de 95% de certitude (on suppose l ’écart type connu à 15$): m = 155 ± 4.16 En affirmant que le coût actuel moyen du panier d ’épicerie d ’une famille de 4 personnes résidant à Sherbrooke est dans l ’intervalle [150.84$, $], je suis 95% certain d’avoir raison.
: m = 155 ± En affirmant que le coût actuel moyen du panier d ’épicerie d ’une famille de 4 personnes résidant à Sherbrooke est dans l ’intervalle [150.84$, $], je suis 95% certain d’avoir raison.")
64
Étude de cas Les données du fichier credit.xls représentent le montant dû sur des cartes de crédit ainsi que le revenu total de 100 familles québécoises choisies au hasard. Quel est le montant dû moyen d’une famille québécoise? Quelle est la précision de votre estimation? Que peut-on dire pour une famille canadienne? En faisant l’hypothèse que familles utilisent au moins une carte de crédit régulièrement, quelle est la dette totale de ces familles québécoises? Quelle est la précision de votre estimation?

65
Exemple Une compagnie désire mettre sur le marché un nouveau logiciel permettant de ne plus recevoir de pourriels. Elle vise un marché de consommateurs potentiels. Avant de lancer le produit elle fait une enquête auprès de 40 ménages et 6 se déclarent intéressés par le nouveau produit. Le profit par logiciel vendu est de 3$ et la compagnie doit absorber des coûts fixes de $. Quelle est la décision? Discussion: Est-ce la meilleure façon de répondre à la question?

Présentations similaires