Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Symbolisation et Sémiologie graphique

2
Principes La réalisation d’une carte suppose connu trois règles fondamentales : 1 – A chaque type de variable correspond un type de carte. 2 – A chaque combinaison ou traitement de variables correspondent des interprétations spécifiques. 3 – Pour chaque représentation cartographique, des règles de sémiologie graphique permettent de donner une meilleure visibilité aux structures spatiales.

3
Première règle Quand la variable a des valeurs discrètes, il est nécessaire d’attribuer un symbole à chaque objet de la carte : symbole pour les points, couleur pour les lignes ou les polygones, etc. Par exemple : cartes de végétation, géologie, implantation de monuments ou d’édifices. Quand la variable est constituée de valeurs continues, il y a deux cas : Valeurs brutes : par exemple quantité de population, on utilise un symbole dont la superficie est proportionnelle à la valeur. Valeurs relatives : par exemple un pourcentage de croissance, on utilise une gamme de couleurs et un modèle de discrétisation pour le découpage en classes.

4
La discrétisation est un processus complexe et délicat
Complexe: Si on dispose de 5 méthodes de discrétisation et de 4 à 9 classes, nous pouvons réaliser 30 cartes différentes. Si on utilise deux gammes (continue et en opposition), nous arrivons à 60 cartes différentes. Délicat parce qu’il pose deux problèmes: Quelle est la carte, parmi les 60, qui correspond à la meilleure visualisation de la structure spatiale ? L’interprétation visuelle et la subjectivité finissent par l’emporter sur la statistique ! On suppose qu’il existe une certaine homogénéité spatiale (à l’intérieur des polygones) et statistique (les éléments graphique d’un même classe sont-ils équivalents ?) Il est donc important de bien maîtriser ces méthodes et d’effectuer les interprétations en conséquence.
, nous arrivons à 60 cartes différentes. Délicat parce qu’il pose deux problèmes: Quelle est la carte, parmi les 60, qui correspond à la meilleure visualisation de la structure spatiale L’interprétation visuelle et la subjectivité finissent par l’emporter sur la statistique ! On suppose qu’il existe une certaine homogénéité spatiale (à l’intérieur des polygones) et statistique (les éléments graphique d’un même classe sont-ils équivalents ) Il est donc important de bien maîtriser ces méthodes et d’effectuer les interprétations en conséquence.")
5
Analyser une carte 1 – analyse à partir d’une interprétation statistique
1.a - Y a-t-il eu une transformation de variable ? De quelle nature ? % du total de la variable (colonne) -> La carte se réfère à la comparaison entre les unités spatiales, d’une seule caractéristique. Permet une lecture des relations entre les unités. Calcul sur l’espace total / discrétisation sur l’espace total % du total de l’unité (ligne) -> La carte se réfère à une proportion, pour chaque unité, d’un caractère. Les unités ne sont pas comparables directement entre elles. Calcul pour une seule unité / discrétisation pour l’espace total Il est nécessaire de connaître le poids de chaque unité: on associe en général une carte en symbole proportionnel du caractère en valeur absolue. Le calcul du Khi2 est souvent meilleur. Rapport entre deux variables: -> La distribution se lit par rapport à la valeur 1. Il peut y avoir une confusion entre cette valeur 1 (les deux variables ont les mêmes valeurs dans l’unité) et la moyenne (les deux variables sont équivalentes dans la distribution totale). Utiliser de préférence la discrétisation standard ou moyennes emboîtées pour distinguer les deux valeurs. Rapport sur la moyenne ou une valeur particulière. -> La valeur de la moyenne n’a plus de sens, c’est une carte de référence par rapport à une unité spatiale spécifique.
 -> La carte se réfère à la comparaison entre les unités spatiales, d’une seule caractéristique. Permet une lecture des relations entre les unités. Calcul sur l’espace total / discrétisation sur l’espace total. % du total de l’unité (ligne) -> La carte se réfère à une proportion, pour chaque unité, d’un caractère. Les unités ne sont pas comparables directement entre elles. Calcul pour une seule unité / discrétisation pour l’espace total. Il est nécessaire de connaître le poids de chaque unité: on associe en général une carte en symbole proportionnel du caractère en valeur absolue. Le calcul du Khi2 est souvent meilleur. Rapport entre deux variables: -> La distribution se lit par rapport à la valeur 1. Il peut y avoir une confusion entre cette valeur 1 (les deux variables ont les mêmes valeurs dans l’unité) et la moyenne (les deux variables sont équivalentes dans la distribution totale). Utiliser de préférence la discrétisation standard ou moyennes emboîtées pour distinguer les deux valeurs. Rapport sur la moyenne ou une valeur particulière. -> La valeur de la moyenne n’a plus de sens, c’est une carte de référence par rapport à une unité spatiale spécifique.")
6
Réaliser 3 cartes à l’aide des fichiers agriindus-ct et agriindus-lr:
Exercice Réaliser 3 cartes à l’aide des fichiers agriindus-ct et agriindus-lr: % Agriculture / total agriculture % Agriculture / total PEA Ratio Agriculture / Services Conclusion ?

7
Analyser une carte 2 – analyse a partir de la discrétisation
Chaque type de discrétisation se base sur une comparaison: De rang avec la progression arithmétique, géométrique et les quantiles; En relation avec la moyenne pour la standard et les moyennes emboîtées; En relation avec la variance pour Jenks et Equiprobabilités. Il est important de considérer cette relation dans l’interprétation des cartes.

8
Fichier agriindus-lr.txt Faire deux cartes (homme et femme)
Exercice Fichier agriindus-lr.txt Faire deux cartes (homme et femme) Modifier les discrétisation Chaque fois, regarder l’histogramme Conclusion ?
 Modifier les discrétisation. Chaque fois, regarder l’histogramme. Conclusion")
9
Analyser une carte 3 – Analyse à partir de la distribution spatiale
Quand on construit une carte statistique, on peut chercher deux types de distributions: - Oppositions: on utilise alors des discrétisation qui renforcent cette opposition: standard, moyennes emboîtées, valeurs exceptionnelles. - Homogénéité: on utilise les méthodes qui diminuent les effets des valeurs exceptionnelles: quantiles, equiprobabilités, Jenks. Dans tous les cas, il est nécessaire de “tatonner” pour trouver des structures spatiales particulières. Mais quand on a rencontrer “quelque chose”, il est nécessaire d’analyser la méthode qui a servir à le construire, et de déterminer la significastion des classes.

10
L’utilisation des couleurs
Utiliser des gammes continues pour des valeurs continues Couleurs claires pour des petites valeurs, foncées pour des valeurs fortes (toujours du plus clair au plus foncé) Respecter la tonalité de la gamme, dans l’ordre de l’arc en ciel: une gamme verte commence par du jaune; une gamme bleue ne commencera jamais par du jaune. Pour les gammes en opposition: il faut respecter l’harmonie des couleurs. Vert / orange, Bleu / Magenta, etc… jamais vert / bleu. Les couleurs chaudes sont pour les phénomènes “positifs”, les froides pour les “négatifs”, mais il y a des exceptions.
 Respecter la tonalité de la gamme, dans l’ordre de l’arc en ciel: une gamme verte commence par du jaune; une gamme bleue ne commencera jamais par du jaune. Pour les gammes en opposition: il faut respecter l’harmonie des couleurs. Vert / orange, Bleu / Magenta, etc… jamais vert / bleu. Les couleurs chaudes sont pour les phénomènes positifs , les froides pour les négatifs , mais il y a des exceptions.")
11
Comment cartographier l’indice de masculinité ? Fichier pop-age-lr.txt
Utiliser une gamme en opposition seulement s’il y a opposition: standard, moyennes emboîtées, référence à une valeur particulière, ... Utiliser des couleurs qui sont en relation avec le thème, quand cela est possible : vert pour l’agricole ou la végétation, rouge pour l’industrie, bleu / orange / rouge pour les températures, … Eviter d’utiliser trop de classes: l’oeil peut distinguer 5 ou 6 tonalités différentes. Une carte avec 4 classes est souvent plus éfficace qu’avec 10 classes oú rien ne peut se différencier. Exercice Comment cartographier l’indice de masculinité ? Fichier pop-age-lr.txt

13
Distribution spatiale, hétérogénéité et comparaison de données
Comparaison avec un modèle statistique - Regression – Analyse Structure-résidus Diversité / Specificité – La mesure de la diversité – Mesure de la spçecificité en relation à un modèle Classification - Classification manuelle (triangulaire, combinatoire) – Analyse en composante principale et analyse de correspondance - Classification statistique
 – Analyse en composante principale et analyse de correspondance. - Classification statistique.")
14
Comparaison avec un modèle statistique
Comment comparer deux distributions de données ? Par exemple, l’évolution dans le temps d’une variable relative: 1 – rapport 2 – taux de croissance 3 – différence de pourcentage 4 – relation entre les distributions

15
Ficher demog-monde.txt et fond Shape File des country:
Exercice Ficher demog-monde.txt et fond Shape File des country: Différence, rapport et % de variation de la fertilité Regression : menu « Statistiques / Regression » Fertility Y Fertility80 X Regression POP_TOT et POP_TOT80, comparer avec le growth rate. Faire le grahique en Excel Interpretation ?

16
Régression

17
La régression C’est l’expression de la relation statistique entre deux variables quantitatives, par exemple:

18
Propriété des résidus (1)
Les résidus correspondent à la partie de la variance qui ne peut pas s’expliquer dans le modèle. Ils peuvent avoir plusieurs significations: Un “bruit” complètement aléatoire, apellé erreur ou perturbation. Les phénomènes biologiques ou sociaux ne sont pas déterministes. Erreurs de mesure. Une composante qui peut s’expliquer à partir d’autres variables. On utilisera alors des méthodes multivariables (régression multiple, analyse en composante principale, etc.). Un composant relatif à l’hétérogénéité du milieu, on utilisera alors des méthodes de la statistique spatiale (krigeage par exemple). L’utilisation d’un modèle de comparaison non adapté (linéaire, bilogarithmique, etc…).
. Un composant relatif à l’hétérogénéité du milieu, on utilisera alors des méthodes de la statistique spatiale (krigeage par exemple). L’utilisation d’un modèle de comparaison non adapté (linéaire, bilogarithmique, etc…).")
19
Propriété des résidus (2)
Dans tous les cas, il faut manipuler ces résidus avec beaucoup de précautions : La relation corrélative est une relation de coïncidence statistique, non une relation de causalité ou fonctionnelle. Par exemple, s’il existe une relation forte entre le taux de chômage et la proportion de femme, cela ne veut pas dire que le fait d’être femme génère une probabilité plus forte d’être au chômage; cela est vrai au niveau de la population mais pas au niveau des unités spatiales car les populations au sein de l’unité peu`vent être très diverses. Il faut donc chercher à expliquer le phénomène. Toujours prendre beaucoup de précautions pour l’interprétation des résidus: Tester son seuil de signification statistique (intervalle de confiance, normalité des résidus et coefficient de corrélation). Chercher des variables qui diminuent la variance et les résidus: la carte n’est pas meilleure quand il y a beaucoup de résidus, au contraire. Chercher d’autre méthodes.
. Chercher des variables qui diminuent la variance et les résidus: la carte n’est pas meilleure quand il y a beaucoup de résidus, au contraire. Chercher d’autre méthodes.")
20
Régression Pour utiliser le modèle de la régression, il est nécessaire de connaitre au préalable deux caractères de la relation: La relation est-elle linéaire ? Existe-t-il une relation fonctionnelle entre les deux variables ? Si la relation n‘est pas linéaire, il est nécessaire d’appliquer au préalable une transformation de données de manière à s’approcher d’un modèle linéaire. Les transformations les plus utilisées sont: logarithme, puissance et racine. S’il existe une relation de dépendance entre les variables (par exemple entre deux populations) il est nécessaire d’utiliser la méthode des minimum carrés. S’il n’existe pas de relation de dépendance (par exemple entre la production agricole et le niveau d’éducation des producteurs), il faut utiliser la méthode des minimum rectangulaires, sauf s’il s’agit de vérifier une hypothèse particulière.
 il est nécessaire d’utiliser la méthode des minimum carrés. S’il n’existe pas de relation de dépendance (par exemple entre la production agricole et le niveau d’éducation des producteurs), il faut utiliser la méthode des minimum rectangulaires, sauf s’il s’agit de vérifier une hypothèse particulière.")
21
–a – Minimum carré On utilise la covariance: Moment centré d’ordre 1.
On cherche à minimiser la somme des différences entre la valeur observée et la valeur calculée de la variable dépendante référence, c’est à dire la quantité: : Variance résiduelle Le modéle s’exprime sous la forme d’une équation: Et a comme paramétre: passant par la valeur moyenne Et covariance comparée à la variance de la valeur de référence les résidus sont indépendant de x. Il y a une variable de référence et une variable dépendante Variance non expliquée = disperssion de y – variance expliquée

22
B – Minimum rectangulaire ou composante principale
Ce modèle s’utilise quand on ne peut pas dire quelle est la variable dépendante et la variable explicative. Par exemple, on cherche la relation entre la taille et le poids, il est impossible de dire si la taille dépend du poids ou viceversa. La quantité que l’on cherche à minimiser est: Le modéle s’exprime selon l’équation: Et a comme paramétre: passant par l’observation moyenne rapport de la dispersion des deux variables Ce type de régression s’appelle aussi axe principal réduit, axe de régression ortogonal, axe en composante principale. Il est souvent meilleur de travailler avec des variables centrées réduites.

23
C – Expression graphique
Les résidus se calculent de manière très différentes selon la méthode utilisée. En géographie, on peut utiliser: Les valeurs théoriques calculées à partir du modèle de l’équation, comme variable de simulation d’une relation. Les résidus comme variation spatiale de la relation. Dans ce cas il est important de souligner qu’il n’est pas possible d’identifier la partie aléqtoire de la partie explicative d’un phénomène ayant une dimension spatiale.

24
Fichier celiba-can1.txt carte % Célibataire 15-29
Exercice Fichier celiba-can1.txt carte % Célibataire 15-29 carte % Célibataire 30-49 Comparaison ? Faire les régression celib en fonction (celib 30-49) avec les deux méthodes et comparer paramètres et cartes Interprétation ?
 avec les deux méthodes et comparer paramètres et cartes. Interprétation")
25
Résultats Carré Moyen Minimum rectangulaire a 5.890483 -18.965697 b
Valider du coef b Nombre de cantons en dehors de l’IC 31

26
La relation rang-taille ou modèle de Zipf
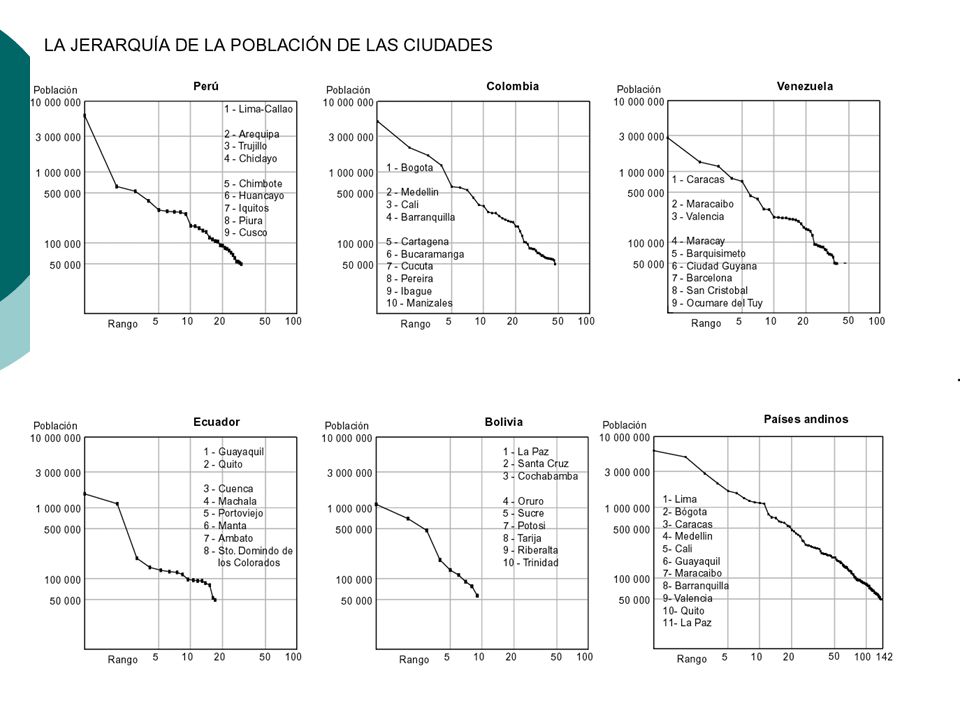
Le modèle rang-taille est très utilisé pour étudier la relation entre le rang et la taille des villes, représentant la hiérarchie urbaine dans un territoire. C’est un modèle dérivé de la théorie des systèmes utilisé aussi en biologie ou en physique. Il se construit à partir de la régression bilogarithmique entre la taille de la population et son rang. On peut cependant remarquer que la relation n’est pas tout à fait linéaire, mais montre des structures qui sont caractéristique du système des villes. Ce modèle existe dans tous les pays du Monde et à toutes les échelles (Voir Moriconi 1994). La théorie générale des systèmes (Bertalanffy – 1968 y 1973) montre que ce tye d’équation: Représente une relatin d’allométrie, c’est à dire un taux de croissance égal au cours du temps et dépendant de la taille. (Taux de croissance relatif).
. La théorie générale des systèmes (Bertalanffy – 1968 y 1973) montre que ce tye d’équation: Représente une relatin d’allométrie, c’est à dire un taux de croissance égal au cours du temps et dépendant de la taille. (Taux de croissance relatif).")
27
Croissance des villes boliviennes

29
Exercice Fichier : bolivie-ville
Dans Excel, calculer le rang our chaque date Dans Cabral faire les cartes de la relation rang-taille Comparer les paramètres des années 1992 et 2001

30
Comparaison 1992 - 2001 1992 Parametros de la ecuación y=a+bx
Coeficiente de correlación: Variance résiduelle: ESTIMACION del t Student Coef b - Hipótesis de diferencia a 0: * Significado del coeficiente de correlación: * 2001 Parametros de la ecuación y=a+bx : a= b= Coeficiente de correlación: Variance résiduelle: ESTIMACION del t Student Coef b - Hipótesis de diferencia a 0: * Significado del coeficiente de correlación: *

31
Exercice - Dans Excel, pour le fichier pop-age-lr.txt, calculer le rang (pour la population totale), faire le graphique bi-logarithmique, et la carte Conclusion

32
Analyse Structure - Résidus

33
Shift and Share Structure - Résidus
Il s’agit de faire une comparaison entre une population ayant une caractéristique spécifique et une population de référence. On suppose que le caractère de la population se distribue selon la taille de la population de référence (par exemple il y a plus de celibataire en valeur absolue dans une commune qu’une autre, parce qu’il y a plus de opulation dans cette commune). L’objectif de cette analyse est de différencier les résidus qui proviennent de la structure de la population de ceux qui sont dus à un “effet régional”.
. L’objectif de cette analyse est de différencier les résidus qui proviennent de la structure de la population de ceux qui sont dus à un effet régional .")
34
Principe Exemple: Statut matrimonial et groupe d’âge des femmes

35
Calcul Célibataires moyen = Célibataires moyens Pour chaque région =
Célibataires moyen par groupe d’âge = Célibataires moyens par région en prenant en compte la structure des groupes d’âge (chaque région est conforme à la moyenne nationale)
")
37
Données: celiba-can3.txt Menu: Statistique / Structure - Résidu
EXERCICE Données: celiba-can3.txt Menu: Statistique / Structure - Résidu Valeur de référence: Toutes les variables T Variables spécifiques: Toutes le variables C Interprétation ?

38
Résultats Faire les cartes des résidus de structure et de région

39
Table de contingence Cette méthode ressemble à celle des structure – résidus mais la caomparaison s’effectue au moyen des fréquences marginales. Contingence signifie dépendance, montrant comment une ou deux caractéristiques dépendent l’une de l’autre.

40
Principe Fréquence théorique = Les résidus se calculent comme :
Le Khi2 Mesure la indépendance, C’est à dire la hypothèse nulle quil y ait une différence entre valeurs réelles et valeurs calculées:

41
En cartographie, on utilise deux paramètres:
la contribution de chaque cellule à la valeur du Khi2 total: cette valeur donne la spécificité d’un caractère dans la distribution géographique. La somme de cette indice pour chaque unité géographique: donne la vleur de la spécialisation dans chaque unité spatiale. Cependant, il existe des indices de spécialisaton plus efficaces (voir suivant).
.")
42
Indice de localisation
Quand l’indice est supérieur á 1, la fréquence du caractére dans l’unité spatiale i est supérieure à la fréquence dans la totalité du territoire. L’unité i eut être considérée comme spécialisée dans ce caractère. S l’indice est inférieur à 1, le caractère présente un déficit dans cette unité. Cette indice est le meilleur pour comparer deux ou plusieurs caractères ou modalités de caractères; parce qu’il mesure le niveau de concentration de l’information dans une unité spatiale par comparaison avec la distribution du même caractère dans tout le territoire. Il permet également de mesurer le poids respectif des unités entre elles, parce qu’il utilise les fréquences marginales.

43
Calculer dans Excel Les indices pour l‘agriculture, le commerce, etc…
EXERCICE Fichier PEA2-LR.TXT Calculer dans Excel Les indices pour l‘agriculture, le commerce, etc… Faire les cartes correspondantes

44
La mesure de la diversité
On considère n unités spatiales qui ont une série de caractères v1,v2,…,vn. On cherche à caractériser la distribution spatiale de cette série, en particulier son niveau de concentration. Deux questions: Y a t il une concentration dans une unité en ce qui concerne ses caractéristiques ? Y a t il une répartition spatiale de la concentration ou de la diversité ?

45
Indice statistique : la dispersion
Ecart-type () ou coefficient de variation100* /m come mesure de la dispersion autour de la moyenne; la kurtosis mesure l’aplatissement de la distributin par les mments d’ordre 2 et 4, mesurant aussi la dispersion autour de la moyenne. Avantage : usage facile, par son mode de calcul et son interprétation. Inconvénient : dépendance à la moyenne et aux fréquences maximales; nécessite une distribution normale, ou au moins qui ne soit pas plurimodale.
 ou coefficient de variation100* /m come mesure de la dispersion autour de la moyenne; la kurtosis mesure l’aplatissement de la distributin par les mments d’ordre 2 et 4, mesurant aussi la dispersion autour de la moyenne. Avantage : usage facile, par son mode de calcul et son interprétation. Inconvénient : dépendance à la moyenne et aux fréquences maximales; nécessite une distribution normale, ou au moins qui ne soit pas plurimodale.")
46
Indice de Shannon : l’entropie
Avec une variable ayant n modalités, la probabilité pour une unité d’avoir ou non cette modalité i est représentée par pi. L’indice de Shannon représente, pour l’observation j, la quantité d’information necessaire pour définir complètement cette observation :

47
L’indice de Gini : la spécialisation
En économie, les études sur l’inégalité et la pauvreté (Atkinson 1970, Sen 1973, Kolm 1976) ou sur la concentration industrielle (Hannah y Kay 1977) utilisent plusieurs indicateurs de concentration / spécialisation basés sur le même concept de l’indice de Shannon mais introduisant une notion de fréquence comparative et de pondération nécessaire pour distinguer la taille inégale des unités. Le plus utilisé est l’indice de Gini, basé sur la construction de la courbe de Lorenz.
 ou sur la concentration industrielle (Hannah y Kay 1977) utilisent plusieurs indicateurs de concentration / spécialisation basés sur le même concept de l’indice de Shannon mais introduisant une notion de fréquence comparative et de pondération nécessaire pour distinguer la taille inégale des unités. Le plus utilisé est l’indice de Gini, basé sur la construction de la courbe de Lorenz.")
48
Indice de Gini L’indice de concentration se calcule comme la superficie définie entre la diagonale du carré et la courbe délimitée par les point (en gris sur la figure) et se calcule selon la formule : L’indice varie de 0 (minima concentration) à 0,5 (maxima concentration) et permet une comparaison facile entre les courbes. L’indice de Gini présente une forte corrélation négative avec l’indice de Shannon.
 et se calcule selon la formule : L’indice varie de 0 (minima concentration) à 0,5 (maxima concentration) et permet une comparaison facile entre les courbes. L’indice de Gini présente une forte corrélation négative avec l’indice de Shannon.")
49
Indice de Gini Cas particulier de la distance

50
Menu: Statistique / Concentration
EXERCICE Fichier PEA-LR.TXT Menu: Statistique / Concentration Prendre toutes les variables sauf total Faire les cartes de l’entropie et de Gini Conclusion ?

Présentations similaires



 r =>")

















