Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
INTRODUCTION A LA METHODOLOGIE OBJET
Chapitre 1 : LA QUALITE DU LOGICIEL Chapitre 2 : MODULARITE Chapitre 3 : REUTILISABILITE Chapitre 4 : VERS LA TECHNOLOGIE OBJET Chapitre 5 : TYPES ABSTRAITS DE DONNEES Chapitre 6 : LA STRUCTURE STATIQUE: LES CLASSES Chapitre 7 : LA STRUCTURE A L'EXECUTION: LES OBJETS Chapitre 8 : GENERICITE Chapitre 9 : CONSTRUIRE DU LOGICIEL FIABLE Chapitre 10 : INTRODUCTION A L'HERITAGE

2
Chapitre 1 : LA QUALITE DU LOGICIEL
1.1 INTRODUCTION 1.2 FACTEURS EXTERNES 1.3 DE LA MAINTENANCE LOGICIELLE

3
1.1 INTRODUCTION Facteurs internes: perceptibles par les informaticiens modularité lisibilité complexité Facteurs externes: appréciés par les utilisateurs

4
Validation de la correction par couches
1.2 FACTEURS EXTERNES Correction: capacité que possède un produit logiciel de mener à bien sa tâche, telle qu'elle a été définie par sa spécification Validation de la correction par couches 4) Système applicatif 4.4) Bibliothèque d'applications 4.3) Autres bibliothèques 4.2) Bibliothèque de base 4.1) Bibliothèque noyau 3) Compilateur 2) Système d'exploitation 1) Matériel
 Système applicatif. 4.4) Bibliothèque d applications. 4.3) Autres bibliothèques. 4.2) Bibliothèque de base. 4.1) Bibliothèque noyau. 3) Compilateur. 2) Système d exploitation. 1) Matériel.")
5
Robustesse: capacité qu'offrent des systèmes logiciels à réagir de manière appropriée à la présence de conditions anormales Un cas anormal correspond simplement à un cas qui n'est pas couvert par la spécification Le système ne peut causer de catastrophes; il doit fournir des messages d'erreur appropriés ou entrer dans un mode appelé "dégradation harmonieuse"

6
Extensibilité: facilité d'adaptation des produits logiciels aux changements de spécifications
La base de tout logiciel repose sur une intervention humaine et son cortège de caprices. Il faut donc: simplicité de conception: une architecture simple sera toujours plus facile à adapter aux changements décentralisation: une modification d'un module aura d'autant moins d'incidence sur les autres modules que celui-ci sera autonome, évitant ainsi le déclenchement d'une réaction en chaîne de changements dans l'ensemble du système.

7
Réutilisabilité: capacité des éléments logiciels à servir à la construction de plusieurs applications différentes Les systèmes logiciels suivent souvent les mêmes modèles. Il devrait être possible d'exploiter ces ressemblances et d'éviter de réinventer des solutions à des problèmes qui se sont déjà posés

8
Compatibilité: facilité avec laquelle des éléments logiciels peuvent être combinés à d'autres
Parmi les approches possibles, on trouve: Les formats de fichiers standardisés Les structures de données standardisées Les interfaces utilisateur standardisées

9
Efficacité: capacité d'un système logiciel à utiliser le minimum de ressources matérielles, que ce soit le temps machine, l'espace occupé en mémoire externe et interne, ou la bande passante des moyens de communication Certains développeurs sont obsédés par les questions de performance, ce qui les pousse à dépenser beaucoup d'efforts dans de soi-disant optimisations. Mais une autre faction tend à minimiser l'importance de la performance. "Faites bien les choses avant de les faire vite"

10
Portabilité: facilité avec laquelle des produits logiciels peuvent être transférés d'un environnement logiciel ou matériel à un autre Une grande partie des incompatibilités entre plate-formes n'est pas justifiée mais elle existe ! Quelle qu'en soit la cause, cette diversité fait que la portabilité reste une préoccupation majeure des développeurs et des utilisateurs de logiciel.

11
Facilité d'utilisation: facilité avec laquelle des personnes présentant des formations et des compétences différentes peuvent apprendre à utiliser les produits logiciels et à s'en servir pour résoudre des problèmes. C'est aussi la facilité d'installation, d'opération et de contrôle. D'où, "Ne prétendez pas connaître l'utilisateur; vous ne le connaissez pas"

12
Fonctionnalité: étendue des possibilités offertes par un système
Le problème le plus difficile est d'éviter d'être tellement obnubilé par les détails que l'on en oublie les autres qualités

13
Ponctualité: capacité d'un système logiciel à être livré au moment désiré ou avant
Vérifiabilité: facilité à préparer les procédures de recette, en particulier les jeux de tests, ainsi que les procédures permettant de détecter les erreurs Intégrité: capacité que présentent certains systèmes logiciels à protéger leurs divers composants contre les accès et modifications non autorisés Réparabilité: capacité à faciliter la réparation des défauts Economie, cousine de la ponctualité: capacité d'un système à être terminé dans les limites de son budget, ou en deçà

14
Documentation externe, qui permet aux utilisateurs de maîtriser la puissance du système et de l'utiliser correctement; c'est une conséquence de la définition de la facilité d'utilisation. interne, qui permet aux développeurs logiciels de comprendre la structure et l'implémentation du système; c'est une conséquence de l'exigence d'extensibilité. d'interface de modules, qui permet aux développeurs de comprendre les fonctionnalités offertes par un module sans avoir à en comprendre l'implémentation; c'est une conséquence de l'exigence de réutilisabilité. Plutôt que de traiter la documentation comme un produit séparé du logiciel, il est préférable de rendre le logiciel aussi auto-documenté que possible

15
Préoccupations essentielles
Toutes les qualités évoquées ci-dessus sont importantes. Mais, dans l'état actuel de l'industrie du logiciel, quatre d'entre elles sont primordiales: correction et robustesse extensibilité et réutilisabilité

16
1.3 DE LA MAINTENANCE LOGICIELLE

17
Chapitre 2 : MODULARITE 2.1 CINQ CRITERES 2.2 CINQ REGLES 2.3 CINQ PRINCIPES

18
2.1 CINQ CRITERES Une méthode de conception digne d'être appelée "modulaire" devrait répondre à cinq exigences fondamentales: décomposabilité, composabilité, compréhensibilité, continuité, protection.

19
Décomposabilité modulaire: capacité à décomposer facilement un problème logiciel en un petit nombre de sous-problèmes moins complexes, reliés entre eux par une structure simple et suffisamment indépendants pour permettre de travailler séparément sur chacun d'eux. Pour les traitements Pour les données, donc pas de variables globales

20
Composabilité modulaire: capacité à produire des éléments logiciels qui peuvent ensuite être combinés librement avec d'autres pour produire de nouveaux systèmes, éventuellement dans un environnement très différent de celui pour lequel ils ont été initialement développés. La composabilité est directement liée à l'objectif de réutilisabilité: le but est de pouvoir transformer le processus de conception du logiciel en un jeu de construction, de telle manière que nous puissions construire des programmes en combinant des éléments préfabriqués standard.

21
La composabilité est indépendante de la décomposabilité
La composabilité est indépendante de la décomposabilité. En fait, ces critères sont souvent contradictoires. La conception descendante, qui est une technique favorisant la décomposabilité, tend à produire des modules qu'il n'est pas facile de combiner avec des modules provenant d'autres sources. La méthode suggère, en effet, de développer chaque module pour répondre à un besoin spécifique, correspondant à un sous-problème découvert à un moment précis du processus de raffinement. De tels modules sont souvent étroitement liés au contexte immédiat de leur développement, et donc peu adaptés à d'autres contextes.

22
Compréhensibilité modulaire: capacité à produire des logiciels dans lesquels un lecteur humain peut comprendre chaque module sans avoir à connaître les autres ou, au pire, après l'examen de quelques uns. L'importance de ce critère découle de son influence sur le processus de maintenance.

23
Continuité modulaire: si, dans les architectures logicielles, un changement mineur dans la spécification du problème ne déclenche un changement que dans un seul module ou un petit nombre de modules. Ce critère est directement lié à l'objectif général d'extensibilité. Le terme de "continuité" est tiré d'une analogie avec la notion de fonction continue en analyse mathématique. Une fonction mathématique est continue si (informellement) un petit changement de l'argument entraîne un changement proportionnel dans le résultat.
 un petit changement de l argument entraîne un changement proportionnel dans le résultat.")
24
Protection modulaire: capacité à produire des architectures dans lesquelles l'effet d'une condition anormale se produisant, à l'exécution, dans un module donné sera confiné à ce module ou, au pire, ne se propagera qu'à quelques modules voisins. La question implicite, celle des échecs et des erreurs, est centrale dans le génie logiciel. Exemple: validation des données à la source. Imposer que chaque module qui utilise des données en entrée soit également responsable de leur validité favorise la protection modulaire.

25
2.2 CINQ REGLES Des critères précédents, on déduit cinq règles que nous devons observer pour assurer la modularité: correspondance directe, peu d'interfaces, petites interfaces (couplage faible), interfaces explicites, rétention d'information.
, interfaces explicites, rétention d information.")
26
Correspondance directe
Tout système logiciel cherche à prendre en compte les besoins d'un certain domaine de problèmes. Si vous avez un bon modèle pour décrire ce domaine, c'est une bonne idée de maintenir une correspondance claire entre la structure de la solution, fournie par le logiciel, et la structure du problème, décrite par le modèle. D'où la première règle: La structure modulaire envisagée lors du processus de construction d'un système logiciel devrait rester compatible avec toute structure modulaire envisagée lors du processus de modélisation du domaine du problème.

27
Peu d'interfaces La règle de peu d'interfaces restreint le nombre total de canaux de communication entre les modules d'une architecture logicielle: Chaque module devrait communiquer avec le minimum d'autres modules. Si un système est composé de n modules, le nombre de connexions intermodules devrait rester plus près du minimum, n - l, que du maximum, n (n - 1) /2.
 /2.")
28
Petites interfaces La règle des petites interfaces, ou "couplage faible", concerne la taille des connexions intermodules plutôt que leur nombre: Si deux modules communiquent, ils doivent échanger aussi peu d'informations que possible.

29
Interfaces explicites
Avec la quatrième règle, nous allons un cran plus loin vers la création d'un régime totalitaire dans la société des modules: nous imposons non seulement que toute conversation soit limitée - à quelques participants et à quelques mots, mais nous exigeons aussi que ces conversations soient tenues en public et à haute voix! Quand deux modules A et B communiquent, cela doit apparaître de manière évidente dans le texte de A, de B ou des deux.

30
Rétention d'information
La règle de rétention d'information peut être explicitée comme suit: Le concepteur de tout module doit choisir un sous-ensemble des propriétés du module pour représenter l'information officielle de ce module, information qui sera rendue publique aux auteurs des modules clients. L'application de cette règle suppose que chaque module est connu du reste du monde (c'est-à- dire, des concepteurs des autres modules) via une description officielle, correspondant aux propriétés publiques.
 via une description officielle, correspondant aux propriétés publiques.")
31
Quelles propriétés d'un module devraient être publiques, ou secrètes?
De manière générale, la partie publique devrait inclure la spécification de la fonctionnalité du module; tout ce qui se rapporte à l'implémentation d'une telle fonctionnalité devrait rester secret, pour préserver les autres modules des changements ultérieurs des choix d'implémentation.

32
2.3 CINQ PRINCIPES Des règles précédentes, on déduit cinq principes de construction de logiciel: le principe des unités linguistiques modulaires, le principe d'autodocumentation, le principe d'accès uniforme, le principe ouvert-fermé, le principe du choix unique.

33
Unités linguistiques modulaires
Le principe d'unités linguistiques modulaires exprime que le formalisme utilisé pour décrire le logiciel aux différents niveaux (spécification, conception, implémentation) doit permettre l'expression de la modularité au niveau envisagé: Principe: Les modules doivent correspondre aux unités syntaxiques du langage utilisé. Le langage mentionné peut être un langage de programmation, un langage de conception, un langage de spécification, etc. Dans le cas des langages de programmation, les modules devraient être compilables séparément.
 doit permettre l expression de la modularité au niveau envisagé: Principe: Les modules doivent correspondre aux unités syntaxiques du langage utilisé. Le langage mentionné peut être un langage de programmation, un langage de conception, un langage de spécification, etc. Dans le cas des langages de programmation, les modules devraient être compilables séparément.")
34
Autodocumentation Comme la règle de la rétention d'information, le principe d'autodocumentation gouverne la manière dont nous devrions documenter les modules: Principe: Le concepteur d'un module devrait s'arranger pour que toute l'information concernant un module soit une partie intégrante du module lui-même. Cela élimine la situation fréquente dans laquelle l'information d'un module est maintenue, séparée, dans d'autres documents du projet. La documentation en question ici est la documentation interne concernant les composants du logiciel, pas la documentation utilisateur à propos du produit final.

35
Accès uniforme Soit x le nom utilisé pour accéder à une certaine donnée (ce que nous appellerons plus tard un objet) et f le nom d'une caractéristique applicable à x. Par exemple, x peut être une variable représentant un compte en banque, et f la caractéristique qui donne le solde courant du compte. L'accès uniforme concerne la question de savoir comment exprimer le résultat de l'application de f à x, en utilisant une notation qui ne fait pas d'hypothèse prématurée sur la manière dont f est implémentée.
 et f le nom d une caractéristique applicable à x. Par exemple, x peut être une variable représentant un compte en banque, et f la caractéristique qui donne le solde courant du compte. L accès uniforme concerne la question de savoir comment exprimer le résultat de l application de f à x, en utilisant une notation qui ne fait pas d hypothèse prématurée sur la manière dont f est implémentée.")
36
Al) Vous pouvez représenter le solde comme l'un des champs de l'enregistrement décrivant chaque compte. Avec cette technique, chaque opération qui modifie le solde doit prendre soin de mettre à jour le champ balance. A2) Ou vous pouvez définir une fonction qui calcule le solde en utilisant d'autres champs de l'enregistrement, par exemple les champs représentant les listes de débit et crédit. Avec cette technique, le solde d'un compte n'est pas stocké, mais est calculé à la demande. Une notation courante, dans des langages comme Pascal, C, C++ et Java, utilise x.f dans le cas Al f (x) dans le cas A2
 Ou vous pouvez définir une fonction qui calcule le solde en utilisant d autres champs de l enregistrement, par exemple les champs représentant les listes de débit et crédit. Avec cette technique, le solde d un compte n est pas stocké, mais est calculé à la demande. Une notation courante, dans des langages comme Pascal, C, C++ et Java, utilise. x.f dans le cas Al. f (x) dans le cas A2.")
37
Dans sa forme générale, le principe peut être exprimé de la façon suivante:
Tous les services offerts par un module devraient être accessibles via une notation uniforme, ne révélant pas s'ils sont implémentés par des moyens de calcul ou de stockage mémoire.

38
Le principe ouvert-fermé
Principe: Les modules devraient être à la fois ouverts et fermés. Un module est dit ouvert s'il est encore extensible. Par exemple, il devrait être possible d'étendre son ensemble d'opérations ou d'ajouter des champs à ses structures de données. Un module est dit fermé s'il est accessible à d'autres modules. Cela suppose que le module a reçu une description bien définie et stable. Au niveau de l'implémentation, la fermeture d'un module implique également que vous pouvez le compiler, peut-être le stocker dans une bibliothèque, et le rendre accessible aux autres (ses clients).
.")
39
L'héritage fournira la solution à cette contradiction.
class A' inherit A redefine f, g, ... end feature f is ... g is .. ... u is ... end où la clause feature contient à la fois la définition de nouvelles caractéristiques spécifiques à A', comme u, et la redéfinition de caractéristiques (comme f, g, ...) dont la forme dans A' diffère de celle qu'elles avaient dans A. Le module A reste fermé et, grâce à l'héritage, il peut être ouvert pour donner naissance à un nouveau module étendu A'.
 dont la forme dans A diffère de celle qu elles avaient dans A. Le module A reste fermé et, grâce à l héritage, il peut être ouvert pour donner naissance à un nouveau module étendu A .")
40
Choix unique type PUBLICATION = record auteur, titre: STRING; année_publication: INTEGER; case type_publication: (livre, revue, compte-rendu) of livre: (éditeur: STRING); revue: (volume, numéro: STRING); compte-rendu: (éditeur, lieu: STRING); end
 of. livre: (éditeur: STRING); revue: (volume, numéro: STRING); compte-rendu: (éditeur, lieu: STRING); end.")
41
La principale observation est que, pour réaliser une telle discrimination, chaque client doit connaître la liste exacte des variantes de la notion de publication représentée par A. La conséquence est facile à prévoir, Tôt ou tard, vous réaliserez que vous avez besoin d'une nouvelle variante, comme des rapports techniques d'entreprise ou d'université. Il vous faudra alors étendre la définition du type PUBLICATION dans le module A pour prendre en compte ce nouveau cas. Dans de tels cas, nous devons accepter la possibilité que la liste des variantes, quoique fixée et connue à un moment donné de l'évolution du logiciel, change ensuite par addition ou élimination de variantes.

42
Principe: Chaque fois qu'un système logiciel doit gérer un ensemble d'alternatives, un module du système, et un seul, devrait en connaître la liste exhaustive. En imposant que la connaissance de la liste des choix soit limitée à un module unique, nous préparons l'environnement des futurs changements: si des variantes sont ajoutées, nous n'aurons qu'à mettre à jour le module qui possède l'information - le point de choix unique. Tous les autres, en particulier ses clients, pourront continuer leurs affaires comme si de rien n'était.

43
Chapitre 3 : REUTILISABILITE
Suivez le chemin tracé par la conception du matériel! On ne peut plus accepter que chaque nouveau développement parte chaque fois de zéro. Il devrait exister des catalogues de modules logiciels, comme il existe des catalogues de circuits VLSI: pour construire un nouveau système, nous devrions commander des composants sur ces catalogues et les combiner entre eux, plutôt que de réinventer la roue à chaque fois. Nous écririons moins de logiciel, et celui qu'il nous resterait à écrire serait peut-être meilleur.

44
3.1 LES OBJECTIFS DE LA REUTILISABILITE
3.2 CE QUE VOUS DEVRIEZ REUTILISER 3.3 REPETITION DURANT LE DEVELOPPEMENT LOGICIEL 3.4 OBSTACLES NON TECHNIQUES 3.5 LE PROBLEME TECHNIQUE 3.6 CINQ EXIGENCES SUR LES STRUCTURES DE MODULE

45
3.1 LES OBJECTIFS DE LA REUTILISABILITE
Bénéfices attendus Ponctualité Effort de maintenance diminué Fiabilité Efficacité Cohérence Investissement

46
Réutiliser les consommateurs, réutiliser les producteurs
Deux aspects de la réutilisabilité: la vision du consommateur, adoptée par les développeurs d'application qui peuvent s'appuyer sur les composants; la vision du producteur, celle des groupes qui intègrent la réutilisabilité dans leurs propres développements.

47
3.2 CE QUE VOUS DEVRIEZ REUTILISER
Réutilisation de personnel Réutilisation des conceptions et des spécifications Les modèles de conception Réutilisabilité par le code source Réutilisation de modules abstraits

48
3.3 REPETITION DURANT LE DEVELOPPEMENT LOGICIEL
Combien de fois, avez-vous, vous-même ou ceux qui travaillent pour vous, écrit un bout de programme qui effectue une recherche dans une table? La recherche dans une table est définie ici comme le problème consistant à trouver si un élément donné x apparaît dans une table t d'éléments similaires. Le problème admet de nombreuses variantes en fonction des types des éléments, de la représentation de la structure de données t, du choix de l'algorithme de recherche.

49
3.4 OBSTACLES NON TECHNIQUES
Le syndrome NIH (Not Invented Here) L'économie des achats Les entreprises du logiciel et leurs stratégies Accéder aux composants
 L économie des achats Les entreprises du logiciel et leurs stratégies. Accéder aux composants")
50
3.5 LE PROBLEME TECHNIQUE Changement et stabilité recherche (t: TABLE, x: ELEMENT): BOOLEAN is -- Y a-t-il une occurrence de x dans t? local pos: POSITION do from pos := INITIAL_POSITION (x, t) until EXHAUSTED (pos, t) or else FOUND (pos, x, t) loop pos := NEXT (pos, x, t) end Result := not EXHAUSTED (pos, t)
 until. EXHAUSTED (pos, t) or else FOUND (pos, x, t) loop. pos := NEXT (pos, x, t) end. Result := not EXHAUSTED (pos, t)")
51
3.6 CINQ EXIGENCES SUR LES STRUCTURES DE MODULE
variation de type, regroupement de routines, variation d'implémentations, indépendance de représentation, factorisation des comportements communs.

52
Variation de type Le modèle de routine recherche suppose la présence d'une table contenant des objets de type ELEMENT. Une définition particulière utilisera un type spécifique, comme INTEGER ou BANK_ACCOUNT, pour appliquer ce modèle à une table d'entiers ou de comptes en banque. Mais ce n'est pas satisfaisant. Un module de recherche réutilisable devrait être applicable à de nombreux types différents d'éléments, sans exiger que les réutilisateurs aient à effectuer des modifications manuelles du texte du logiciel.

53
Regroupement de routines
Même s'il avait été complètement défini et paramétré par des types, le modèle de routine recherche ne serait pas un composant réutilisable tout à fait satisfaisant. La manière dont vous parcourez une table dépend de la façon dont elle a été créée, dont les éléments sont insérés ou éliminés. Ainsi, la routine de recherche n'est pas suffisante en elle-même, en tant qu'unité de réutilisation. Un module réutilisable autosuffisant devrait contenir un ensemble de routines, une pour chacune des opérations citées - création, insertion, élimination, recherche.

54
Variation d'implémentation
Le modèle recherche est très général: il y a en pratique, comme nous l'avons vu, une grande variété de structures de données et d'algorithmes applicables. Nous ne pouvons donc pas espérer qu'un seul module puisse prendre en compte toutes les possibilités: il serait énorme. Nous aurons besoin d'une famille de modules pour couvrir toutes les implémentations différentes. Une technique générale pour produire et utiliser des modules réutilisables devra admettre cette notion de famille de modules.

55
Indépendance de représentation
Supposez qu'un module client C d'un certain système applicatif ait besoin de déterminer si un certain élément x apparaît dans une certaine table t (d'investissements, de mots-clés d'un langage, de villes). L'indépendance de représentation indique ici que C a la capacité d'obtenir cette information par un appel comme present := recherche (t, x) sans savoir le genre de table qu'est t au moment de l'appel. L'auteur de C devrait seulement savoir que t est une table d'éléments d'un certain type et que x désigne un objet de ce type. Que t soit un arbre binaire, une table de hachage ou une liste chaînée lui importe peu.
. L indépendance de représentation indique ici que C a la capacité d obtenir cette information par un appel comme present := recherche (t, x) sans savoir le genre de table qu est t au moment de l appel. L auteur de C devrait seulement savoir que t est une table d éléments d un certain type et que x désigne un objet de ce type. Que t soit un arbre binaire, une table de hachage ou une liste chaînée lui importe peu.")
56
Factorisation des comportements communs
La diversité des implémentations disponibles dans certains domaines de problèmes conduira typiquement à une solution basée sur une famille de modules. Cette famille est souvent tellement grande qu'il est naturel d'envisager des sous-familles. Dans le cas de la recherche dans une table, un premier essai de classification pourrait amener à considérer trois grandes sous-familles: les tables gérées avec une certaine forme de hachage, les tables organisées comme des arbres d'un type ou d'un autre, les tables gérées séquentiellement.

57
recherche (t: SEQ_TABLE; x: ELEMENT): BOOLEAN is
-- Y a-t-il une occurrence de x dans t? do from start until after or else found (x) loop forth end Result := not after End start: pour placer le curseur sur le premier élément forth: pour avancer le curseur d'une position after: pour savoir si le curseur s'est déplacé au-delà de la table found (x): pour savoir si l'élément sous le curseur a la valeur x.
 loop. forth. end. Result := not after. End. start: pour placer le curseur sur le premier élément. forth: pour avancer le curseur d une position. after: pour savoir si le curseur s est déplacé au-delà de la table. found (x): pour savoir si l élément sous le curseur a la valeur x.")
58
Toutes ces variantes de tables séquentielles partagent la fonction recherche et ne diffèrent que par l'implémentation des quatre opérations de bas niveau. Une solution satisfaisante au problème de la réutilisabilité doit inclure le texte de recherche en un seul endroit, associé d'une façon ou d'une autre à la notion générale de table séquentielle, indépendamment de tout choix de représentation. Pour décrire une nouvelle variante, tout ce que vous aurez à faire sera de fournir les versions appropriées de start, forth, after et found.

59
Chapitre 4 : VERS LA TECHNOLOGIE OBJET
4.1 LES INGREDIENTS DU CALCUL 4.2 DECOMPOSITION FONCTIONNELLE 4.3 DECOMPOSITION ORIENTEE OBJET 4.4 CONSTRUCTION DE LOGICIEL ORIENTE OBJET 4.5 PROBLEMATIQUE

60
4.1 LES INGREDIENTS DU CALCUL
Trois forces interviennent quand un logiciel effectue un calcul quelconque: exécuter un système logiciel revient à utiliser certains processeurs pour appliquer certaines actions à certains objets. Les processeurs sont des dispositifs de calcul, physiques ou virtuels, qui exécutent des instructions. Les actions sont les opérations qui constituent le calcul. Les objets sont les structures de données sur lesquelles s'appliquent les actions.

61
4.2 DECOMPOSITION FONCTIONNELLE
Mérites et limitations de l'approche traditionnelle: utiliser les fonctions comme base d'architecture des systèmes logiciels. Continuité Développement descendant Pas une fonction unique Trouver le sommet Interfaces et conception logicielle Ordonnancement prématuré Réutilisabilité

62
Evaluation de la conception descendante
La méthode est peu adaptée au développement de systèmes importants. Elle reste un paradigme utile pour de petits programmes et des algorithmes individuels, en particulier dans les cours de programmation. Mais elle ne se généralise pas aux logiciels pratiques de taille importante. En développant un système de manière descendante, vous gagnez en facilité à court terme ce que vous payerez par une inflexibilité à long terme; vous privilégiez une fonction par rapport aux autres; vous pouvez être conduit à concentrer votre attention sur les caractéristiques de l'interface au lieu de propriétés plus fondamentales; vous perdez de vue l'aspect donnée; et vous risquez de sacrifier la réutilisabilité.

63
4.3 DECOMPOSITION ORIENTEE OBJET
La justification de l'utilisation des objets comme clé de voûte de la modularisation des systèmes est fondée sur les objectifs de qualité, en particulier l'extensibilité, la réutilisabilité et la compatibilité. Ceci ne devrait pourtant pas nous conduire à éliminer entièrement la notion de fonction. Aucune approche de la construction de logiciel ne peut être complète si elle ne prend en compte à la fois les aspects fonction et objet.

64
Extensibilité Si les fonctions d'un système ont tendance à changer lors de la vie d'un système, nous est-il possible de trouver une caractérisation plus stable de ses propriétés essentielles, de façon à guider notre choix des modules et atteindre l'objectif de continuité? Les types des objets manipulés par le système sont des candidats particulièrement prometteurs. Quoiqu'il arrive au système de traitement de la paye du personnel, il continuera probablement toujours à manipuler des objets représentant des employés, des grilles de salaire, des règlements internes, des heures de travail, des chèques.

65
Réutilisabilité Recherche dans une table: en débutant avec ce qui paraissait être un candidat naturel pour la réutilisation, une routine de recherche, on a noté que nous ne pouvions pas facilement réutiliser une telle routine séparément des autres opérations s'appliquant à une table, comme sa création, l'insertion ou l'élimination. Mais, si nous essayons de comprendre le cheminement conceptuel qui unit toutes ces opérations, nous trouvons le type des objets auxquels elles s'appliquent - les tables. De tels exemples suggèrent que les types d'objets, associés aux opérations correspondantes, fourniront les unités stables de réutilisation.

66
Compatibilité Un autre facteur de qualité du logiciel, la compatibilité, a été défini comme étant la facilité avec laquelle les produits logiciels (ici, les modules) peuvent être combinés entre eux. Il est difficile de combiner des actions si les structures de données sur lesquelles elles opèrent ne sont pas conçues dans cette perspective. Pourquoi, alors, ne pas essayer de combiner des structures de données entières?
 peuvent être combinés entre eux. Il est difficile de combiner des actions si les structures de données sur lesquelles elles opèrent ne sont pas conçues dans cette perspective. Pourquoi, alors, ne pas essayer de combiner des structures de données entières")
67
4.4 CONSTRUCTION DE LOGICIEL ORIENTE OBJET
Construction de logiciel orienté objet (définition I) La construction de logiciel orienté objet est la méthode de développement logiciel qui fonde l'architecture de tout système logiciel sur des modules déduits des types des objets qu'il manipule (plutôt que sur la ou les fonctions que le système est supposé remplir). La devise objet: Ne demandez pas en premier ce que fait le système, demandez à qui il le fait!
 La construction de logiciel orienté objet est la méthode de développement logiciel qui fonde l architecture de tout système logiciel sur des modules déduits des types des objets qu il manipule (plutôt que sur la ou les fonctions que le système est supposé remplir). La devise objet: Ne demandez pas en premier ce que fait le système, demandez à qui il le fait!")
68
4.5 PROBLEMATIQUE Comment trouver les types d'objets pertinents? Comment décrire les types d'objets? Comment décrire les relations et les similitudes entre les types d'objets? Comment utiliser les types d'objets pour structurer le logiciel?

69
Trouver les types d'objets
De nombreux objets ne demandent justement qu'à être cueillis. Ils modélisent directement la réalité physique à laquelle s'applique le logiciel. Les classes développées précédemment par d'autres. L'expérience et l'imitation

70
Décrire types et objets
Deux critères doivent nous guider: La nécessité de fournir des descriptions indépendantes de toute représentation, de peur de perdre le bénéfice principal de la conception fonctionnelle descendante: l'abstraction. La nécessité de réintroduire les fonctions, en leur donnant une place appropriée dans les architectures logicielles dont la décomposition est essentiellement fondée sur l'analyse des types d'objets puisque nous devrons prendre en compte les deux aspects de la dualité objet-fonction.

71
Décrire les relations et structurer le logiciel
Dans la forme la plus pure de la technologie objet, seules deux relations existent: le client et l'héritage. Elles correspondent à des familles différentes de dépendance possible entre deux types d'objets A et B: B est un client de A si chaque objet de type B peut contenir des informations concernant un ou plusieurs objets de type A. B est un héritier de A si B représente une version spécialisée de A.

72
Chapitre 5 : TYPES ABSTRAITS DE DONNEES
5.1 CRITERES 5.2 VARIATIONS D'IMPLEMENTATION 5.3 VERS UNE VUE ABSTRAITE DES OBJETS 5.4 FORMALISER LA SPECIFICATION 5.5 DES TYPES ABSTRAITS DE DONNEES AUX CLASSES

73
5.1 CRITERES Les descriptions devraient être précises et sans ambiguïté. Elles devraient être complètes - ou au moins aussi complètes que nous le souhaitons dans chaque cas (nous pouvons décider de ne pas préciser certains détails). Elles ne devraient pas surspécifier.
. Elles ne devraient pas surspécifier.")
74
5.2 VARIATIONS D'IMPLEMENTATION
Représentations des piles ARRAY_UP : représente une pile par un tableau representation et un entier count dont la valeur varie entre 0 (pour une pile vide) et capacity, la taille du tableau representation; les éléments de la pile sont stockés dans le tableau entre les indices 1 et count. ARRAY_DOWN : comme ARRAY_UP, mais avec des éléments stockés à partir de la fin du tableau plutôt que depuis le début. Ici, l'entier est appelé free (c'est l'indice de la position libre la plus élevée du tableau, ou 0 si toutes les positions sont occupées) et il varie entre capacity pour une pile vide et 0. Les éléments de la pile sont stockés dans le tableau entre les indices capacity et free + 1.
 et capacity, la taille du tableau representation; les éléments de la pile sont stockés dans le tableau entre les indices 1 et count. ARRAY_DOWN : comme ARRAY_UP, mais avec des éléments stockés à partir de la fin du tableau plutôt que depuis le début. Ici, l entier est appelé free (c est l indice de la position libre la plus élevée du tableau, ou 0 si toutes les positions sont occupées) et il varie entre capacity pour une pile vide et 0. Les éléments de la pile sont stockés dans le tableau entre les indices capacity et free + 1.")
75
LINKED : une représentation en chaîne qui stocke chaque élément dans une cellule possédant deux champs: item représente l'élément, et previous contient un pointeur vers la cellule contenant l'élément empilé précédemment. La représentation utilise également last, un pointeur vers la cellule représentant le sommet. Pour ARRAY_UP et ARRAY_DOWN, les instructions incrémentent ou décrémentent l'indicateur de sommet (count ou free) et affectent x à l'élément correspondant du tableau. Les gardiens suivants sont nécessaires: if count < capaci ty then ... if free > 0 then ...
 et affectent x à l élément correspondant du tableau. Les gardiens suivants sont nécessaires: if count < capaci ty then ... if free > 0 then ...")
76
Pour LINKED, empiler un élément nécessite quatre opérations: créer une nouvelle cellule n; affecter x au champ item de la nouvelle cellule; enchaîner la nouvelle cellule au sommet précédent de pile en affectant à son champ previous la valeur courante de last; et mettre à jour last de façon qu'il soit dorénavant attaché à la nouvelle cellule créée. Bien que ce soient les représentations de pile le plus souvent utilisées, il en existe beaucoup d'autres. Choisir l'une d'elles comme "la" définition des piles serait un cas type de surspécification.

77
5.3 VERS UNE VUE ABSTRAITE DES OBJETS
Utiliser les opérations Empiler un élément sur le sommet d'une pile: put. Ôter l'élément en sommet de pile: remove. Obtenir l'élément au sommet, si la pile n'est pas vide: item. Déterminer si la pile est vide ou non. Création d'une pile initialement vide: make. Une pile est n'importe quelle structure sur laquelle des clients peuvent appliquer les opérations répertoriées ci-dessus.

78
5.4 FORMALISER LA SPECIFICATION
Une spécification de type abstrait de données (ADT pour "Abstract Data Type") contient quatre paragraphes: TYPES, FONCTIONS, AXIOMES, PRÉCONDITIONS.
 contient quatre paragraphes: TYPES, FONCTIONS, AXIOMES, PRÉCONDITIONS.")
79
Spécifier les types Un type est une collection d'objets caractérisés par des fonctions, des axiomes et des préconditions. Un type abstrait de données comme STACK (pour les piles) n'est pas un objet (une pile particulière), mais une collection d'objets (l'ensemble de toutes les piles). Un objet appartenant à l'ensemble des objets décrits par une spécification d'ADT est appelé une instance de l'ADT. Par exemple, une pile spécifique qui vérifie les propriétés du type abstrait de données STACK sera une instance de STACK.
 n est pas un objet (une pile particulière), mais une collection d objets (l ensemble de toutes les piles). Un objet appartenant à l ensemble des objets décrits par une spécification d ADT est appelé une instance de l ADT. Par exemple, une pile spécifique qui vérifie les propriétés du type abstrait de données STACK sera une instance de STACK.")
80
Le paragraphe TYPES répertorie les types introduits dans la spécification. Ici:
STACK [G] La spécification concerne un unique type abstrait de données STACK, décrivant des piles d'objets de type arbitraire G.

81
Généricité Dans STACK [G], G désigne un type arbitraire, non spécifié. G est appelé un paramètre générique formel du type abstrait de données STACK, et STACK lui-même est appelé un ADT générique. En conséquence, un ADT comme STACK n'est pas exactement un type, mais plutôt un schéma de type; pour obtenir un type pile directement exécutable, vous devez obtenir un type d'élément et le fournir comme paramètre générique réel correspondant au paramètre formel G: STACK [ACCOUNT] est un type complètement défini.

82
Répertorier les fonctions
FONCTIONS put: STACK [G] x G → STACK [G] remove: STACK [G] |→ STACK [G] item: STACK [G] |→ G empty: STACK [G] → BOOLEAN new: STACK [G]

83
Le paragraphe FONCTIONS ne définit pas complètement les fonctions; il n'introduit que leurs signatures - la liste des types des arguments et du résultat. La signature de put est put: STACK [G] x G → STACK [G] ce qui indique que put accepte une paire d'arguments de la forme <s, x> où s est une instance de STACK[G] et x est une instance de G, et renvoie comme résultat une instance de STACK [G]. La signature des fonctions remove et item utilise |→ plutôt que la flèche standard utilisée par put et empty. Cette notation exprime le fait que ces fonctions ne sont pas applicables à tous les membres de l'ensemble source.

84
Catégories de fonctions
Une fonction comme new, dans laquelle un nouveau type T n'apparaît qu'à droite de la flèche, est une fonction de création. Une fonction comme item et empty, dans laquelle T n'apparaît qu'à gauche de la flèche, est une fonction de requête. Une fonction comme put ou remove, dans laquelle T apparaît des deux côtés de la flèche, est une fonction de commande. Une autre proposition terminologique appelle ces trois catégories "constructeur", "accédeur" et "modificateur".

85
Le paragraphe AXIOMES Pour indiquer que nous avons une pile, et non une autre structure de données, la spécification de l'ADT donnée jusqu'à présent n'est pas suffisante. Toute structure "distributeur", comme une file premier entré-premier sorti, y correspond. AXIOMES (d'une pile) Pour tout x: G, s: STACK [G], A1 : item (put (s, x)) = x A2 : remove ((put (s, x)) = s A3 : empty (new) A4 : not empty (put (s, x))
 Pour tout x: G, s: STACK [G], A1 : item (put (s, x)) = x. A2 : remove ((put (s, x)) = s. A3 : empty (new) A4 : not empty (put (s, x))")
86
Les fonctions partielles
La spécification de tout exemple réaliste, même aussi simple que les piles, rencontre le problème qu'introduisent les opérations non définies: certaines opérations ne sont pas applicables à tout élément possible de leur ensemble source. Ici, c'est le cas de remove et item: vous ne pouvez pas dépiler un élément d'une pile vide; et une pile vide n'a pas de sommet. Le domaine d'une fonction partielle de X |→ Y est le sous-ensemble de X qui contient les éléments pour lesquels la fonction renvoie une valeur. Cela soulève un nouveau problème: comment spécifier les domaines de ces fonctions?

87
Préconditions Toute spécification d'ADT qui contient des fonctions partielles doit spécifier le domaine de chacune d'entre elles. C'est le rôle du paragraphe PRECONDITIONS. PRECONDITIONS remove (s: STACK [G]) require not empty (s) item (s: STACK [G]) require not empty (s) où, pour chaque fonction, la clause require indique les conditions que les arguments de la fonction doivent vérifier pour appartenir au domaine de la fonction.
 require not empty (s) item (s: STACK [G]) require not empty (s) où, pour chaque fonction, la clause require indique les conditions que les arguments de la fonction doivent vérifier pour appartenir au domaine de la fonction.")
88
Spécification de l'ADT des piles
TYPES STACK [G] FONCTIONS put: STACK [G] x G → STACK [G] remove: STACK [G] |→ STACK [G] item: STACK [G] |→ G empty: STACK [G] → BOOLEAN new: STACK [G] AXIOMES Pour tout x: G, s: STACK [G], A1 : item (put (s, x)) = x A2 : remove ((put (s, x)) = s A3 : empty (new) A4 : not empty (put (s, x)) PRECONDITIONS remove (s: STACK [G]) require not empty (s) item (s: STACK [G]) require not empty (s)
) = x. A2 : remove ((put (s, x)) = s. A3 : empty (new) A4 : not empty (put (s, x)) PRECONDITIONS. remove (s: STACK [G]) require not empty (s) item (s: STACK [G]) require not empty (s)")
89
5.5 DES TYPES ABSTRAITS DE DONNEES AUX CLASSES
Classes Définition: une classe est un type abstrait de données muni d'une implémentation éventuellement partielle. Ainsi, pour obtenir une classe, nous devons fournir un ADT et décider d'une implémentation. L'ADT est un concept mathématique; l'implémentation est sa version adaptée à l'ordinateur. Définition: une classe qui est complètement implémentée est dite effective. Une classe qui n'est implémentée que partiellement, ou pas du tout, est dite retardée.

90
Comment produire une classe effective
Trois genres d'éléments rendront effective une classe: El: une spécification d'ADT E2: un choix de représentation E3: une correspondance entre les fonctions (El) et la représentation (E2) sous la forme d'un ensemble de mécanismes, ou caractéristiques ("features"), où chacun implémente une des fonctions grâce à la représentation choisie, de manière à vérifier les axiomes et les préconditions. Nombre de ces caractéristiques seront des routines (sous-programmes) au sens usuel du terme, bien que certaines puissent apparaître sous forme de champs de données, ou "attributs".
 et la représentation (E2) sous la forme d un ensemble de mécanismes, ou caractéristiques ( features ), où chacun implémente une des fonctions grâce à la représentation choisie, de manière à vérifier les axiomes et les préconditions. Nombre de ces caractéristiques seront des routines (sous-programmes) au sens usuel du terme, bien que certaines puissent apparaître sous forme de champs de données, ou attributs .")
91
Exemple: si l'ADT est STACK (E1) et la représentation ARRAY_UP qui implémente toute pile par une paire <representation, count> où representation est un tableau et count un entier (E2), pour les implémentations des fonctions (E3), nous aurons des "features" correspondant à put, remove, item, empty et new, qui réalisent les effets souhaités; par exemple, nous pouvons implémenter put par une routine de la forme put (x: G) is -- Empiler x sur la pile. -- (Pas de vérification de débordement possible de pile.) do count := count + 1 representation [count] := x end
, pour les implémentations des fonctions (E3), nous aurons des features correspondant à put, remove, item, empty et new, qui réalisent les effets souhaités; par exemple, nous pouvons implémenter put par une routine de la forme put (x: G) is. -- Empiler x sur la pile. -- (Pas de vérification de débordement possible de pile.) do. count := count + 1. representation [count] := x. end.")
92
Le rôle des classes retardées
Si des informations d'implémentation (E2, E3) sont manquantes, la classe est retardée. Les classes retardées sont particulièrement utiles: en analyse OO, aucun détail d'implémentation n'est nécessaire, ni souhaitable en conception OO, de nombreux aspects de l'implémentation sont négligés car la conception doit se concentrer sur les fonctionnalités à fournir par chaque module et non comment les fournir plus la conception se rapproche d'une implémentation complète, plus on ajoute des propriétés d'implémentation jusqu'à l'obtention de classes effectives.
 sont manquantes, la classe est retardée. Les classes retardées sont particulièrement utiles: en analyse OO, aucun détail d implémentation n est nécessaire, ni souhaitable. en conception OO, de nombreux aspects de l implémentation sont négligés car la conception doit se concentrer sur les fonctionnalités à fournir par chaque module et non comment les fournir. plus la conception se rapproche d une implémentation complète, plus on ajoute des propriétés d implémentation jusqu à l obtention de classes effectives.")
93
Types abstraits de données et rétention d'information
Si le module est une classe provenant d'un ADT, sur les trois parties présentes dans la transition, El, la spécification de l'ADT, est publique; E2 et E3, le choix de représentation et l'implémentation de l'ADT, devraient être secrètes.

94
Introduire une vision plus impérative
put (x: G) is -- Empiler x sur le sommet de pile require ... La précondition, si nécessaire... do ... L'implémentation appropriée, si connue... ensure item = x not empty end D'autres axiomes de la spécification de l'ADT donneront une clause appelée invariant de classe.
 is. -- Empiler x sur le sommet de pile. require. ... La précondition, si nécessaire... do. ... L implémentation appropriée, si connue... ensure. item = x. not empty. end. D autres axiomes de la spécification de l ADT donneront une clause appelée invariant de classe.")
95
Construction de logiciel orienté objet
Définition II La construction de logiciel orienté objet est l'élaboration de systèmes logiciels vus comme des collections structurées d'implémentations, éventuellement partielles, de types abstraits de données.

96
La base est la notion de type abstrait de données.
Pour un logiciel, nous n'avons pas besoin d'ADT en soi, faisant référence à une notion mathématique, mais d'une implémentation d'ADT, une notion logicielle. Ces implémentations, cependant, n'ont pas à être complètes; la qualification "éventuellement partielle" recouvre les classes retardées - ce qui comprend le cas extrême d'une classe complètement différée, dans laquelle aucune caractéristique n'a été implémentée. Un système est une collection de classes, sans que l'une d'elles occupe une position principale - pas de programme principal ou de sommet. La collection est structurée, grâce aux deux relations inter-classes: client et héritage.

97
Chapitre 6 : LA STRUCTURE STATIQUE: LES CLASSES
6.1 LE SUJET N'EST PAS LES OBJETS 6.2 LE ROLE DES CLASSES 6.3 UN SYSTEME DE TYPES UNIFORME 6.4 UNE CLASSE SIMPLE 6.5 LE STYLE ORIENTE OBJET DE CALCUL 6.6 EXPORTATIONS SELECTIVES ET RETENTION D'INFORMATION 6.7 REGROUPER LE TOUT

98
6.1 LE SUJET N'EST PAS LES OBJETS
Quel est le concept central de la technologie objet? Les objets sont certes importants pour décrire l'exécution d'un système orienté objet. Mais la base sur laquelle repose l'ensemble de la technologie orientée objet est la classe. Les types abstraits de données sont une notion mathématique, adaptée à l'étape de spécification (appelée aussi analyse). Parce qu'elle conduit à des implémentations, partielles ou totales, la notion de classe établit le lien nécessaire avec la construction logicielle – conception et implémentation. Rappelez-vous qu'une classe est dite effective si son implémentation est totale, et retardée sinon.
. Parce qu elle conduit à des implémentations, partielles ou totales, la notion de classe établit le lien nécessaire avec la construction logicielle – conception et implémentation. Rappelez-vous qu une classe est dite effective si son implémentation est totale, et retardée sinon.")
99
Comme un ADT, une classe est un type: elle décrit un ensemble de structures de données possibles, appelées les instances de la classe. La définition d'une "classe" conduit à la définition d'un "objet". Un objet est simplement une instance d'une classe. Les textes logiciels qui servent à produire des systèmes sont les classes. Les objets sont une notion n'ayant un sens qu'à l'exécution: ils sont créés et manipulés par le logiciel durant son exécution.

100
6.2 LE ROLE DES CLASSES Pour comprendre l'approche orientée objet, il est essentiel de bien comprendre que les classes jouent deux rôles que les approches pré-OO avaient toujours traités comme distincts: le module et le type. Les modules et les types Un module est une unité de décomposition logicielle. Un type est une description statique de certains objets dynamiques: les divers éléments de données qui seront traités durant l'exécution d'un système logiciel.

101
La classe comme module et type
Dans les approches non OO, les concepts de module et de type restent distincts. La propriété la plus remarquable de la notion de classe est qu'elle généralise ces deux concepts, les fusionnant en une seule construction linguistique. Une classe est un module, ou une unité de décomposition logicielle; mais c'est aussi un type. L'essentiel de la puissance de la méthode orientée objet vient de cette identification. L'héritage, en particulier, ne peut être complètement appréhendé que si nous le considérons comme fournissant à la fois des extensions de module et des spécialisations de type.

102
6.3 UN SYSTEME DE TYPES UNIFORME
Règle de l'objet: Tout objet est instance d'une certaine classe. La règle de l'objet s'appliquera non seulement aux objets composés définis par le développeur (comme les structures de données ayant plusieurs champs), mais aussi aux objets de base comme les entiers, les nombres réels, les valeurs booléennes et les caractères, qui seront tous considérés comme des instances de classes prédéfinies de bibliothèque (INTEGER, REAL, BOOLEAN, CHARACTER).
, mais aussi aux objets de base comme les entiers, les nombres réels, les valeurs booléennes et les caractères, qui seront tous considérés comme des instances de classes prédéfinies de bibliothèque (INTEGER, REAL, BOOLEAN, CHARACTER).")
103
6.4 UNE CLASSE SIMPLE (POINT)
Les caractéristiques Pour caractériser le type POINT comme un type abstrait de données, nous aurons besoin de quatre fonctions de requête x, y, ρ, θ. La fonction x donne l'abscisse d'un point, y son ordonnée, ρ sa distance à l'origine, θ l'angle avec l'axe horizontal. Une autre fonction utile de requête est distance, qui renvoie la distance entre deux points. La spécification d'ADT préciserait ensuite les commandes comme translate (pour déplacer un point d'une certaine distance horizontale et verticale), rotate (pour tourner le point d'un certain angle autour de l'origine) et scale (pour approcher ou éloigner le point de l'origine selon un certain facteur).
, rotate (pour tourner le point d un certain angle autour de l origine) et scale (pour approcher ou éloigner le point de l origine selon un certain facteur).")
104
Il n'est pas difficile d'écrire la spécification complète d'ADT qui contient ces fonctions et certains des axiomes associés. Par exemple, deux des signatures de fonctions seront: x: POINT → REAL translate: POINT x REAL x REAL → POINT et l'un des axiomes sera (pour tout point p et tous réels a, b): x (translate (p, a, b)) = x (p) + a indiquant que translater un point de <a, b> incrémente son abscisse de a.
: x (translate (p, a, b)) = x (p) + a. indiquant que translater un point de <a, b> incrémente son abscisse de a.")
105
Attributs et routines Un type abstrait de données comme POINT est caractérisé par un ensemble de fonctions, qui décrivent les opérations applicables aux instances de l'ADT. Dans les classes (les implémentations des ADT), les fonctions deviendront des caractéristiques - les opérations applicables aux instances de la classe. Nous avons vu que les fonctions d'ADT sont de trois sortes: les requêtes, les commandes et les créateurs. Pour les caractéristiques, nous avons besoin d'une classification complémentaire, fondée sur la manière dont chacune d'elles est implémentée: par de l'espace mémoire ou du temps de calcul.
, les fonctions deviendront des caractéristiques - les opérations applicables aux instances de la classe. Nous avons vu que les fonctions d ADT sont de trois sortes: les requêtes, les commandes et les créateurs. Pour les caractéristiques, nous avons besoin d une classification complémentaire, fondée sur la manière dont chacune d elles est implémentée: par de l espace mémoire ou du temps de calcul.")
106
L'exemple des coordonnées des points illustre clairement la différence
L'exemple des coordonnées des points illustre clairement la différence. Deux représentations courantes sont disponibles pour les points: cartésienne et polaire. Si nous choisissons la représentation cartésienne, chaque instance de la classe contiendra deux champs représentant le x et le y du point correspondant. Si p est le point indiqué, obtenir son x ou son y ne nécessite qu'un accès au champ correspondant dans sa structure. Obtenir ρ ou θ, cependant, demande un calcul: pour ρ, nous devons calculer (x² + y²) ½ et, pour θ, nous devons calculer arctg (y/x) si x est non nul. Si nous utilisons la représentation polaire, la situation est renversée: ρ et θ sont maintenant accessibles par simple accès à un champ, x et y demandant de petits calculs (de ρ cos θ et ρ sin θ).
 ½ et, pour θ, nous devons calculer arctg (y/x) si x est non nul. Si nous utilisons la représentation polaire, la situation est renversée: ρ et θ sont maintenant accessibles par simple accès à un champ, x et y demandant de petits calculs (de ρ cos θ et ρ sin θ).")
107
Accès uniforme Est-il donc approprié de faire une distinction explicite entre attribut et fonction? Le principe d'accès uniforme, introduit lors de l'étude de la modularité, répond à cette inquiétude. Ce principe indique qu'un client devrait être capable d'accéder à une propriété d'un objet en utilisant une notation unique, que la propriété soit implémentée par de la mémoire ou par du calcul. L'expression qui désigne la valeur de la caractéristique x pour p sera toujours p.x que ce soit pour accéder à un champ d'un objet ou pour exécuter une routine.

108
La classe POINT indexing description: "Points à deux dimensions" class POINT feature x, y: REAL -- Abscisse et ordonnée rho: REAL is -- Distance à l'origine (0,0) do Result := sqrt (x ** 2 + y ** 2) end theta: REAL is -- Angle avec l'axe horizontal do ... end distance (p: POINT): REAL is -- Distance à p Result := sqrt ((x - p.x) ** 2 + (y - p.y) ** 2)
 do. Result := sqrt (x ** 2 + y ** 2) end. theta: REAL is -- Angle avec l axe horizontal. do ... end. distance (p: POINT): REAL is -- Distance à p. Result := sqrt ((x - p.x) ** 2 + (y - p.y) ** 2)")
109
translate (a, b: REAL) is -- Déplacer de a horiz.., b vertic.
do x := x + a y := y + b end scale (factor: REAL) is -- Augmenter d'un facteur factor. x := factor * x y := factor * y rotate (p: POINT; angle: REAL) is -- Rotation autour de p de angle. do ... end
 is -- Augmenter d un facteur factor. x := factor * x. y := factor * y. rotate (p: POINT; angle: REAL) is. -- Rotation autour de p de angle. do ... end.")
110
D'où vient la fonction sqrt (dans rho et distance)?
Afin de ne polluer pas le langage général avec des opérations arithmétiques spécialisées, la meilleure technique consiste à définir de telles opérations comme des caractéristiques d'une classe spécialisée - disons ARITHMETIC- et de demander simplement que toute classe qui a besoin de ces services hérite de cette classe spécialisée. D'où: class POINT inherit ARITHMETIC feature ... Le reste comme auparavant ... end

111
6.5 LE STYLE ORIENTE OBJET DE CALCUL
L'instance courante translate (a, b: REAL) is -- Déplacer de a horiz.., b vertic. do x := x + a y := y + b end À première vue, ce texte apparaît suffisamment clair. Mais, nulle part dans le texte nous n'avons précisé de quel point il s'agissait. À qui appartiennent ces x et ces y auxquels nous ajoutons a et b? C'est dans la réponse à cette question que réside l'un des aspects les plus caractéristiques du style de développement orienté objet.
 is -- Déplacer de a horiz.., b vertic. do. x := x + a. y := y + b. end. À première vue, ce texte apparaît suffisamment clair. Mais, nulle part dans le texte nous n avons précisé de quel point il s agissait. À qui appartiennent ces x et ces y auxquels nous ajoutons a et b C est dans la réponse à cette question que réside l un des aspects les plus caractéristiques du style de développement orienté objet.")
112
Le texte d'une classe décrit les propriétés et le comportement des objets d'un certain type, des points dans cet exemple. Il le fait en décrivant les propriétés et le comportement d'une instance typique de ce type appelée l'instance courante de la classe (Current). Mais qui est Current? La réponse viendra lors de l'étude des appels de routines. Tant que nous ne regardons que le texte de la routine, il suffit de savoir que toutes les opérations sont relatives, par défaut, à un objet défini implicitement, l'instance courante.

113
Clients et fournisseurs
Comment utiliser une classe comme POINT? Soit on hérite d'elle, soit on devient client. Définition: Soit S une classe. Une classe C qui contient une déclaration de la forme a: S est un client de S. S est alors un fournisseur de C.

114
class GRAPHICS feature
pl: POINT ... some_routine is -- Effectuer des actions sur p1 do ... Créer une instance de POINT, attachée à p1... pl.translate (4.0, -1.5) end
 end.")
115
Appel de caractéristique
pl.translate (4.0, -1.5) Durant l'exécution d'un système logiciel orienté objet, tout calcul est effectué en appelant certaines caractéristiques sur certains objets. Cet appel de caractéristique particulier veut dire: appliquer à pl la caractéristique translate de la classe POINT, avec les arguments 4.0 et -1.5, correspondant à a et b dans la déclaration de translate donnée dans la classe.
 Durant l exécution d un système logiciel orienté objet, tout calcul est effectué en appelant certaines caractéristiques sur certains objets. Cet appel de caractéristique particulier veut dire: appliquer à pl la caractéristique translate de la classe POINT, avec les arguments 4.0 et -1.5, correspondant à a et b dans la déclaration de translate donnée dans la classe.")
116
L'identification module-type
Une classe est à la fois un module et un type; mais comment pouvons-nous réconcilier la notion syntaxique de module (un regroupement de services voisins, formant une partie d'un système logiciel) avec la notion sémantique de type (la description statique de certains objets possibles à l'exécution)? L'exemple de POINT rend la réponse limpide: les services fournis par la classe POINT, considérée comme un module, sont précisément les opérations applicables aux instances de la classe POINT, considérée comme un type.
 avec la notion sémantique de type (la description statique de certains objets possibles à l exécution) L exemple de POINT rend la réponse limpide: les services fournis par la classe POINT, considérée comme un module, sont précisément les opérations applicables aux instances de la classe POINT, considérée comme un type.")
117
Le rôle de Current Current veut dire: "la cible de l'appel courant". Par exemple, pendant la durée de l'appel ci-dessus, Current désignera l'objet attaché à p1. Dans un appel suivant, Current désignera la cible de ce nouvel appel. Tout ceci a un sens grâce à l'extrême simplicité du modèle de calcul orienté objet, fondé sur des appels de caractéristiques et sur le principe de cible unique: Principe de l'appel de caractéristique Aucun élément logiciel n'est jamais exécuté s'il ne fait pas partie d'un appel de routine. Tout appel a une cible.

118
6.6 EXPORTATIONS SELECTIVES ET RETENTION D'INFORMATION
Exposition complète class S1 feature f ... g ... end les caractéristiques f, g, ... sont accessibles à tous les clients de S1, ce qui veut dire que, dans une classe C, pour une entité x déclarée de type S1, un appel: x.f ... est valide, sous réserve que l'appel vérifie les autres conditions de validité de f concernant le nombre et les types des arguments, s'il y en a.

119
Restreindre l'accès aux clients
class S2 feature f ... g ... feature {A, B} h ... end La caractéristique h n'est accessible qu'à A et B et à tous leurs descendants (les classes qui héritent directement ou indirectement de A ou B). Cela veut dire que, si x est déclaré avec un type S2, un appel de la forme: x.h ... est invalide, sauf s'il apparaît dans le texte de A, de B ou d'un de leurs descendants.
. Cela veut dire que, si x est déclaré avec un type S2, un appel de la forme: x.h ... est invalide, sauf s il apparaît dans le texte de A, de B ou d un de leurs descendants.")
120
6.7 REGROUPER LE TOUT Relativité générale Ce qui est un peu déroutant, c'est que chaque description de ce qui arrive à l'exécution a été, jusqu'à présent, relative. L'effet d'une routine comme translate est relatif à l'instance courante; à l'intérieur du texte de la classe, l'instance courante n'est pas connue. Donc, nous ne pouvons essayer de comprendre l'effet d'un appel que par rapport à une cible spécifique, comme p1 dans: pl.translate (u, v) Mais cela soulève la question suivante: que désigne exactement p1? Ici, à nouveau, la réponse est relative. L'appel ci-dessus doit apparaître dans le texte d'une certaine classe, comme GRAPHICS. Mais qui est l'instance courante dans GRAPHICS?
 Mais cela soulève la question suivante: que désigne exactement p1 Ici, à nouveau, la réponse est relative. L appel ci-dessus doit apparaître dans le texte d une certaine classe, comme GRAPHICS. Mais qui est l instance courante dans GRAPHICS")
121
Le big-bang Définition: l'exécution d'un système logiciel orienté objet comprend les deux étapes suivantes: créer un objet, appelé objet racine de l'exécution, appliquer une certaine procédure, appelée procédure de création, à cet objet. Au moment du big-bang, un objet est créé et la procédure de création est démarrée. La procédure de création crée de nouveaux objets et appelle des routines sur ceux-ci, déclenchant d'autres créations d'objets et appels de routines, etc.

122
Systèmes Pour obtenir un code exécutable, nous devons rassembler les classes en systèmes. Pour fabriquer un système, nous avons besoin de trois choses: un ensemble CS de classes, appelé l'ensemble des classes du système, indiquer quelle classe de CS est la classe racine, indiquer quelle procédure de la classe racine est la procédure racine de création. Pour obtenir un système correct, ces éléments doivent vérifier une condition de cohérence, la fermeture du système: toute classe dont a besoin directement ou indirectement la classe racine doit faire partie de CS.

123
Chapitre 7 : LA STRUCTURE A L'EXECUTION: LES OBJETS
7.2 LES OBJETS: OUTILS DE MODELISATION 7.3 MANIPULER LES OBJETS ET LES REFERENCES

124
7.1 LES OBJETS À tout moment de son exécution, un système OO aura créé un certain nombre d'objets. La structure à l'exécution est l'organisation de ces objets et de leurs relations. Qu'est-ce qu'un objet? Un système logiciel qui contient une classe C peut, en différents points de son exécution, créer des instances de C; une telle instance est une structure de données construite selon le modèle défini par C; par exemple, une instance de la classe POINT introduite dans le chapitre précédent est une structure de données formée de champs associés aux deux attributs x et y déclarés dans la classe. Les instances de toutes les classes possibles constituent l'ensemble des objets.

125
Forme de base Soit O un objet. Sa définition indique qu'il est instance d'une certaine classe. Plus précisément, c'est une instance directe d'une seule classe, disons C. C est appelée la classe génératrice, ou simplement générateur, de O. C est un texte logiciel; O est une structure de données à l'exécution, produite par l'un des mécanismes de création d'objets. Parmi ses caractéristiques, C a un certain nombre d'attributs. Ces attributs déterminent entièrement la forme de l'objet: O est simplement une collection de composants, ou champs, un par attribut.

126
Champs simples Les deux attributs de la classe POINT sont de type REAL. En conséquence, chaque champ correspondant d'une instance directe de POINT contient une valeur réelle. C'est un exemple d'un champ correspondant à un attribut ayant un "type de base". Bien que ces types soient formellement définis comme des classes, leurs instances prennent leur valeur dans des ensembles prédéfinis, implémentés efficacement sur les ordinateurs. Parmi ceux-ci, on trouve BOOLEAN, CHARACTER, INTEGER, REAL et DOUBLE.

127
Une notion simple de livre
class BOOK1 feature title: STRIl\lG date, page_count: INTEGER end bl: BOOK1 bl.page_count := 355

128
Ecrivains class WRITER feature name, real_name: STRING birth_year, death_year: INTEGER end

129
Références Les objets dont les champs ont tous des types de base ne vont pas nous mener très loin. Nous avons besoin d'objets ayant des champs qui représentent d'autres objets. Par exemple, nous voudrons représenter la propriété selon laquelle un livre a un auteur - indiqué par une instance de la classe WRITER. class BOOK3 feature title: STRING date, page_count: INTEGER author: WRITER -- C'est le nouvel attribut. end

131
Définition: une référence est une valeur à l'exécution qui est vide ou attachée. Si elle est attachée, une référence identifie un objet unique. Dans la figure, les champs de référence author dans les instances de BOOK3 sont tous les deux attachés à l'instance de WRITER, comme le montrent les flèches qui sont conventionnellement utilisées dans de tels diagrammes pour représenter une référence attachée à un objet.

132
Le type utilisé pour déclarer author est simplement le nom de la classe correspondante: WRITER. Il s'agit d'une règle générale: chaque fois qu'une classe est déclarée sous la forme standard: class C feature ... end toute entité déclarée de type C grâce à une déclaration de la forme: x: C désigne des valeurs qui sont des références aux objets potentiels de type C. Cette convention se justifie par la souplesse d'utilisation des références, qui sont donc plus appropriées dans la grande majorité des cas.

133
Un aperçu de la structure à l'exécution d'un objet

134
Une telle complexité à l'exécution n'a pas à affecter la vision statique.
Nous devrions essayer de conserver au logiciel lui-même - l'ensemble des classes et de leurs relations - la plus grande simplicité. Le fait que des modèles simples puissent avoir des instances complexes est, en partie, une conséquence de la puissance des ordinateurs. Un petit texte logiciel peut décrire un calcul gigantesque; un simple système OO peut, au moment de l'exécution, fournir des millions d'objets connectés par de nombreuses références. Un objectif primordial du génie logiciel est de maintenir la simplicité du logiciel, même quand ses instances ne le sont pas.

135
7.2 LES OBJETS: OUTILS DE MODELISATION
Les quatre mondes du développement logiciel le système modélisé, aussi appelé système externe (en opposition au système logiciel) et décrit par les types d'objets et les relations abstraites; une instance particulière du système externe, faite d'objets entre lesquels des relations peuvent exister; le système logiciel, fait de classes connectées par les relations de la méthode orientée objet (client et héritage); une structure d'objets, comme celle qui peut exister durant l'exécution du système logiciel, faite d'objets logiciels connectés par des références.
 et décrit par les types d objets et les relations abstraites; une instance particulière du système externe, faite d objets entre lesquels des relations peuvent exister; le système logiciel, fait de classes connectées par les relations de la méthode orientée objet (client et héritage); une structure d objets, comme celle qui peut exister durant l exécution du système logiciel, faite d objets logiciels connectés par des références.")
137
7.3 MANIPULER LES OBJETS ET LES REFERENCES
Création dynamique et rattachement À partir d'un état initial dans lequel un seul objet a été créé - l'objet racine -, un système exécutera de manière répétitive sur la structure des objets des opérations telles que créer un nouvel objet, attacher une référence précédemment vide à un objet, créer une référence vide ou rattacher à un objet différent une référence précédemment attachée. La nature dynamique et imprévisible de ces opérations explique, en partie, la flexibilité de l'approche et sa capacité à prendre en compte les structures de données dynamiques qui sont nécessaires si nous voulons utiliser des algorithmes sophistiqués et modéliser les propriétés volatiles des systèmes externes.

138
L'instruction de création
Cela n'est possible que dans une routine d'une classe qui est client de BOOK3, comme: class QUOTATION feature source: BOOK3 page: INTEGER make_book is -- Créer un objet BOOK3 et lui attacher source. do !! source end

139
L'effet d'une instruction de création de la forme
L'effet d'une instruction de création de la forme !! x, où le type de la cible x est un type référence fondé sur une classe C, est d'exécuter les trois étapes suivantes: C1 : Créer une nouvelle instance de C (faite d'une collection de champs, un pour chaque attribut de C). Soit OC cette nouvelle instance. C2 : Initialiser chaque champ de OC selon les valeurs standards par défaut. C3 : Attacher la valeur de x (une référence) à OC.
. Soit OC cette nouvelle instance. C2 : Initialiser chaque champ de OC selon les valeurs standards par défaut. C3 : Attacher la valeur de x (une référence) à OC.")
140
L'étape C1 créera une instance de C
L'étape C1 créera une instance de C. L'étape C2 positionnera les valeurs de chaque champ à une valeur prédéterminée, qui dépend du type de l'attribut correspondant. Ainsi, pour une cible source de type BOOK3, l'instruction de création !! source, exécutée comme partie d'un appel à la procédure make_book de la classe QUOTATION, donnera un objet dont les champs entiers seront initialisés à zéro, le champ référence pour author sera initialisé à une référence vide et le champ pour title, une chaîne STRING, sera aussi initialisé à une référence vide. Cela découle du fait que le type STRING est, en fait, également un type référence.

141
La vue globale Il est important de ne pas perdre le fil de l'ordre dans lequel les événements se produisent. Pour que l'instance ci-dessus de BOOK3 soit créée, les deux événements suivants ont dû avoir lieu: B1 : Une instance de QUOTATION est créée. Soit Q_OBJ cette instance et soit a une entité dont la valeur est une référence attachée à Q_OBJ. B2 : Quelque temps après l'étape B1, un appel de la forme a.make_book exécute la procédure make_book en ayant Q_OBJ comme cible.

142
CHAPITRE 8 : GENERICITE 8.1 GENERALISATIONS HORIZONTALE ET VERTICALE DE TYPE 8.2 LA NECESSITE DE PARAMETRISATION DE TYPE 8.3 CLASSES GENERIQUES 8.4 TABLEAUX

143
Pour atteindre nos objectifs d'extensibilité, de réutilisabilité et de fiabilité, il nous faut rendre la construction de classes encore plus flexible, un effort que nous poursuivrons dans deux directions. L'une, verticale, représente l'abstraction et la spécialisation; elle donnera lieu à l'étude de l'héritage; l'autre, horizontale: représente la paramétrisation de type, connue sous le nom de généricité.

144
8.1 GENERALISATIONS HORIZ. ET VERTIC. DE TYPE
Les listes représentent un cas spécial de structures "conteneurs", dont les arbres, les piles et les tableaux sont des exemples parmi d'autres. Une variante plus abstraite pourrait être décrite par une classe SET_OF_BOOKS d'ensembles de livres. Une variante plus spécialisée, correspondant à un choix particulier de représentation de liste, pourrait être décrite par une classe LINKED_LIST_OF_BOOKS de listes chaînées de livres. C'est la dimension verticale de notre figure - la dimension d'héritage. Les listes de livres sont un cas particulier de listes d'objets de toutes sortes. C'est la dimension horizontale de notre figure - la dimension de généricité. Utiliser des paramètres de classe qui représentent des types arbitraires nous dispensera d'écrire de nombreuses classes quasi identiques - comme LIST_OF_BOOKS pour des livres et LIST_OF_PEOPLE pour des personnes - sans sacrifier la sûreté qu'offre le typage statique.

145
8.2 LA NECESSITE DE PARAMETRISATION DE TYPE
Types abstraits génériques de données Notre exemple de travail d'ADT, STACK, a été déclaré comme STACK [G], ce qui indique que toute utilisation réelle vous impose de spécifier un "paramètre générique réel" représentant le type des objets stockés dans une pile donnée. Le nom G utilisé dans la spécification d'ADT représente n'importe quel type possible que peuvent avoir ces éléments de pile; il est appelé paramètre générique formel de la classe. Dans cette approche, vous pouvez utiliser une spécification unique pour toutes les piles possibles.

146
La solution de rechange, difficile à accepter, serait d'avoir une classe INTEGER_STACK pour les entiers, une classe REAL_STACK pour les réels et ainsi de suite. On devrait alors définir: put (element: INTEGER) is -- Empiler element sur le sommet. do ... end item: INTEGER is -- Article au sommet
 is. -- Empiler element sur le sommet. do ... end. item: INTEGER is. -- Article au sommet.")
147
8.3 CLASSES GENERIQUES Réconcilier le typage statique avec l'exigence de réutilisabilité pour les classes qui décrivent des structures conteneurs impose, comme l'illustre l'exemple de la pile, que nous puissions à la fois: déclarer un type pour chaque entité qui apparaît dans le texte d'une classe de pile, y compris les entités représentant des éléments de pile; écrire la classe de façon qu'elle ne donne aucune information à propos du type des éléments, et qu'elle puisse donc être utilisée pour construire des piles d'éléments arbitraires.

148
Déclarer une classe générique
indexing description: "Piles d'éléments d'un type arbitraire G" class STACK [G] feature count: INTEGER -- Nombre d'éléments dans la pile empty: BOOLEAN is -- N'y a-t-il pas d'éléments? do ... end full: BOOLEAN is -- La représentation est pleine? item: G is -- Elément au sommet put (x: G) is -- Ajouter x au sommet remove is -- Ôter l'élément au sommet. end -- class STACK
 is -- Ajouter x au sommet. remove is -- Ôter l élément au sommet. end -- class STACK.")
149
Utiliser une classe générique
La déclaration doit fournir des types, appelés paramètres génériques réels - autant de types que la classe utilise de paramètres génériques formels, ici un seul: sp: STACK [POINT] Fournir un paramètre générique réel à une classe générique de façon à produire un type est appelé une dérivation générique, et le type résultant est dit être dérivé génériquement. Une dérivation générique à la fois produit et exige un type: Le résultat de la dérivation, STACK [POINT] dans cet exemple, est un type. Pour produire ce résultat, il vous faut un type existant pour servir de paramètre générique réel, POINT dans l'exemple.

150
class ARRAY [G] creation make feature
8.4 TABLEAUX indexing description: "Séquence de valeurs, toutes de même type ou de type conforme, accessible par des indices entiers dans un intervalle contigu" class ARRAY [G] creation make feature make (minindex, maxindex: INTEGER) is -- Allouer un tableau de bornes minindex et maxindex -- (vide si minindex > maxindex) do ... end lower, upper, count: INTEGER -- Minimum et maximum d'index légal; taille de tableau. put (v: G; i: INTEGER) is -- Affecter v à la case d'indice i item (i: INTEGER): G is -- Case d'indice i end -- class ARRAY
![class ARRAY [G] creation make feature](http://slideplayer.fr/slide/516727/2/images/150/class+ARRAY+%5BG%5D+creation+make+feature.jpg "8.4 TABLEAUX. indexing. description: Séquence de valeurs, toutes de même type ou de type conforme, accessible par des indices entiers dans un intervalle contigu class ARRAY [G] creation. make. feature. make (minindex, maxindex: INTEGER) is. -- Allouer un tableau de bornes minindex et maxindex. -- (vide si minindex > maxindex) do ... end. lower, upper, count: INTEGER. -- Minimum et maximum d index légal; taille de tableau. put (v: G; i: INTEGER) is -- Affecter v à la case d indice i. item (i: INTEGER): G is -- Case d indice i. end -- class ARRAY.")
151
Pour créer un tableau de bornes m et n, où a est déclaré de type ARRAY [T] pour un type T donné:
!! a.make (m, n) Pour positionner la valeur d'un élément de tableau: a.put (x, i) positionne la valeur du i-ème élément à x. Pour accéder à la valeur d'un élément: x := a.item (i)
![Pour créer un tableau de bornes m et n, où a est déclaré de type ARRAY [T] pour un type T donné:](http://slideplayer.fr/slide/516727/2/images/151/Pour+cr%C3%A9er+un+tableau+de+bornes+m+et+n%2C+o%C3%B9+a+est+d%C3%A9clar%C3%A9+de+type+ARRAY+%5BT%5D+pour+un+type+T+donn%C3%A9%3A.jpg "!! a.make (m, n) Pour positionner la valeur d un élément de tableau: a.put (x, i) positionne la valeur du i-ème élément à x. Pour accéder à la valeur d un élément: x := a.item (i)")
152
Voici une esquisse de la manière d'utiliser la classe depuis un client:
pa: ARRAY [POINT]; p1: POINT; i, j: INTEGER ... !! pa.make (-32, 101) -- Allouer un tableau dont les bornes sont –32 et 101 pa.put (p1, i) -- Affecter p1 à la case d'indice i. p1 := pa.item (j) -- Affecter à p1 la valeur de la case d'indice j.
 -- Allouer un tableau dont les bornes sont –32 et 101. pa.put (p1, i) -- Affecter p1 à la case d indice i. p1 := pa.item (j) -- Affecter à p1 la valeur de la case d indice j.")
153
CHAPITRE 9 : CONSTRUIRE DU LOGICIEL FIABLE
9.1 LES MECANISMES DE BASE DE LA FIABILITE 9.2 A PROPOS DE LA CORRECTION LOGICIELLE 9.3 EXPRIMER UNE SPECIFICATION 9.4 INTRODUIRE DES ASSERTIONS DANS LES TEXTES LOGICIELS 9.5 PRECONDITIONS ET POSTCONDITIONS 9.6 INVARIANTS DE CLASSE

154
9.1 LES MECANISMES DE BASE DE LA FIABILITE
La structure des systèmes logiciels (architectures simples, modulaires et extensibles). L'incitation constante à rendre le logiciel élégant et lisible. La présence de règles de typage vérifiées statiquement évitant les erreurs de typage à l'exécution.
. L incitation constante à rendre le logiciel élégant et lisible. La présence de règles de typage vérifiées statiquement évitant les erreurs de typage à l exécution.")
155
9.2 A PROPOS DE LA CORRECTION LOGICIELLE
Un système ou un élément logiciel n'est ni correct ni incorrect en soi; il est correct ou incorrect par rapport à une certaine spécification. Il convient donc de pouvoir exprimer de telles spécifications par des assertions.

156
9.3 EXPRIMER UNE SPECIFICATION
Formules de correction Soit A une opération (par exemple une instruction ou un corps de routine). Une formule de correction est une expression de la forme: {P} A {Q} toute exécution de A, débutant dans un état où P est vérifié, terminera dans un état où Q est vérifié. P est appelée la précondition et Q la postcondition. Exemple: si x est une entité entière, {x >= 9} x := x + 5 {x > 13}
. Une formule de correction est une expression de la forme: {P} A {Q} toute exécution de A, débutant dans un état où P est vérifié, terminera dans un état où Q est vérifié. P est appelée la précondition et Q la postcondition. Exemple: si x est une entité entière, {x >= 9} x := x + 5 {x > 13}")
157
9.4 INTRODUIRE DES ASSERTIONS DANS LES TEXTES LOGICIELS
Puisque la correction d'un élément logiciel a été définie comme étant la cohérence de son implémentation avec sa spécification, nous devrions prendre des mesures pour inclure la spécification, avec son implémentation, dans le logiciel même. Pour exprimer la spécification, nous utiliserons des assertions. Une assertion est une expression qui fait intervenir certaines entités du logiciel et qui exprime une propriété à laquelle ces entités doivent satisfaire à certaines étapes de l'exécution du logiciel. Une assertion typique peut exprimer qu'un certain entier a une valeur positive ou qu'une certaine référence n'est pas vide.

158
9.5 PRECONDITIONS ET POSTCONDITIONS
indexing description: "Piles: Structures distributrices à politique d'accès dernier entré, premier sorti" class STACK1 [G] feature count: INTEGER -- Nombre d'éléments de pile item: G is -- Elément au sommet require not empty do ... end feature empty: BOOLEAN is -- Pile vide? full: BOOLEAN is -- Représentation de pile pleine?

159
feature -- Elément change
put (x: G) is -- Ajouter x au sommet require not full do ... ensure not empty item = x count = old count + 1 end
 is -- Ajouter x au sommet. require. not full. do ... ensure. not empty. item = x. count = old count + 1. end.")
160
remove is -- Éliminer l'élément au sommet
require not empty do ... ensure not full count = old count – 1 end La notation old e, où e est une expression (dans la plupart des cas pratiques, un attribut), désigne la valeur qu'avait e à l'entrée de la routine. Toute occurrence de e qui n'est pas précédée de old dans la postcondition désigne la valeur de l'expression en sortie.
, désigne la valeur qu avait e à l entrée de la routine. Toute occurrence de e qui n est pas précédée de old dans la postcondition désigne la valeur de l expression en sortie.")
161
9.6 INVARIANTS DE CLASSE class STACK2 [G] creation make feature ... make, empty, full, item, put, remove ... capacity: INTEGER count: INTEGER feature {NONE} -- Implementation representation: ARRAY [G] end Il faut: 0 <= count; count <= capacity …
![9.6 INVARIANTS DE CLASSE class STACK2 [G] creation. make. feature. ... make, empty, full, item, put, remove ...](http://slideplayer.fr/slide/516727/2/images/161/9.6+INVARIANTS+DE+CLASSE+class+STACK2+%5BG%5D+creation.+make.+feature.+...+make%2C+empty%2C+full%2C+item%2C+put%2C+remove+....jpg "capacity: INTEGER. count: INTEGER. feature {NONE} -- Implementation. representation: ARRAY [G] end Il faut: 0 <= count; count <= capacity. …")
162
class STACK4 [G] creation
... Comme dans STACK2 ... feature invariant count_non_negative: 0 <= count count_bounded: count <= capacity consistent_with_array_size: capacity = representation.capacity empty_if_no_elements: empty = (count = 0) item_at_top: (count > 0) implies (representation.item (count) = item) end
![class STACK4 [G] creation](http://slideplayer.fr/slide/516727/2/images/162/class+STACK4+%5BG%5D+creation.jpg "... Comme dans STACK2 ... feature. invariant. count_non_negative: 0 <= count. count_bounded: count <= capacity. consistent_with_array_size: capacity = representation.capacity. empty_if_no_elements: empty = (count = 0) item_at_top: (count > 0) implies (representation.item (count) = item) end.")
163
Un invariant d'une classe C est un ensemble d'assertions que toute instance de C vérifiera aux moments "stables". Les moments stables sont ceux durant lesquels l'instance est dans un état observable: durant la création de l'instance, c'est-à-dire après exécution de !! a ou !! a.make (...), où a est de type C; avant et après tout appel distant a.r (...) à une routine r de la classe.
, où a est de type C; avant et après tout appel distant a.r (...) à une routine r de la classe.")
164
CHAPITRE 10 : INTRODUCTION A L'HERITAGE
10.1 POLYGONES ET RECTANGLES 10.2 POLYMORPHISME 10.3 TYPAGE DE L'HERITAGE 10.4 LIAISON DYNAMIQUE

165
10.1 POLYGONES ET RECTANGLES
indexing description: "Polygones ayant un nombre arbitraire de noeuds" class POLYGON creation feature Access count: INTEGER -- Nombre de nœuds perimeter: REAL is -- Longueur du périmètre do ... end feature Transformation display is -- Afficher le polygone à l'écran. rotate (center: POINT; angle: REAL) is -- Tourner de angle autour du center do ... Voir ci-dessous ... end
 is. -- Tourner de angle autour du center. do ... Voir ci-dessous ... end.")
166
translate (a, b: REAL) is
-- Déplacer de a horizontalement, b verticalement. do ... end ... Déclarations d'autres caractéristiques ... feature {NONE} -- Implémentation vertices: LINKED_LIST [POINT] -- Points successifs représentant le polygone invariant same_count_as_implementation: count = vertices.count at_least_three: count >= 3 -- Un polygone possède au moins trois nœuds end

167
rotate (center: POINT; angle: REAL) is
-- Tourner autour de center de angle. do from vertices.start until vertices.after loop vertices.item.rotate (center, angle) vertices.forth end
 vertices.forth. end.")
168
perimeter: REAL is -- Somme des longueurs des arcs
local this, previous: POINT do from vertices.start; this := vertices.item check not vertices.after end -- Conséquence de at_least_three until vertices.is_last loop previous := this; vertices.forth this := vertices.item. Result := Result + this.distance (previous) end Result := Result + this.distance (vertices.first)
 end. Result := Result + this.distance (vertices.first)")
169
Rectangles class RECTANGLE inherit POLYGON feature ... Caractéristiques spécifiques aux rectangles ... end redefine perimeter end

170
class RECTANGLE inherit POLYGON redefine perimeter end creation make
indexing description: "Rectangles comme cas spécial de polygones généraux" class RECTANGLE inherit POLYGON redefine perimeter end creation make feature Initialization make (center: POINT; s1, s2, angle: REAL) is -- Créer un rectangle centré en center, de longueurs de côté s1 et s2 et d'orientation angle. do ... end
 is. -- Créer un rectangle centré en center, de longueurs de côté s1 et s2 et d orientation angle. do ... end.")
171
side1, side2: REAL -- Les longueurs des deux côtés
feature Access side1, side2: REAL -- Les longueurs des deux côtés diagonal: REAL -- Longueur de la diagonale perimeter: REAL is -- Somme des longueurs des côtés -- (Redéfinition de la version POLYGON) do Result := 2 * (side1 + side2) end invariant four_sides: count = 4 first_side: (vertices.i_th (l)).distance (vertices.i_th (2)) = side1 second_side: (vertices.i_th (2)).distance (vertices.i_th (3)) = side2 third_side: (vertices.i_th (3)).distance (vertices.i_th (4)) = side1 fourth side: (vertices.i_th (4)).distance (vertices.i_th (1)) = side2
 do. Result := 2 * (side1 + side2) end. invariant. four_sides: count = 4. first_side: (vertices.i_th (l)).distance (vertices.i_th (2)) = side1. second_side: (vertices.i_th (2)).distance (vertices.i_th (3)) = side2. third_side: (vertices.i_th (3)).distance (vertices.i_th (4)) = side1. fourth side: (vertices.i_th (4)).distance (vertices.i_th (1)) = side2.")
172
Héritage d'invariant L'invariant de la classe RECTANGLE exprime que le nombre de côtés = 4 et que les longueurs des arcs sont side1 et side2. La classe POLYGON possède aussi un invariant qui s'applique à son héritier. Puisque les parents ont eux-mêmes des parents, cette règle est récursive: l'invariant complet d'une classe est finalement obtenu en effectuant un and des clauses d'invariant de tous ses ancêtres.

173
Héritage et création Une procédure de création pour POLYGON pourrait avoir la forme suivante: make_polygon (vl: LINKED_LIST [POINT]) is -- Définir un polygone dont les nœuds sont dans vl. require vl.count >= 3 do ... Initialiser la représentation du polygone à partir des éléments de vl ... ensure -- vertices et vl ont les mêmes éléments (cela peut s'exprimer formellement). end Pas pratique pour rectangle vu son invariant!
![Héritage et création Une procédure de création pour POLYGON pourrait avoir la forme suivante: make_polygon (vl: LINKED_LIST [POINT]) is.](http://slideplayer.fr/slide/516727/2/images/173/H%C3%A9ritage+et+cr%C3%A9ation+Une+proc%C3%A9dure+de+cr%C3%A9ation+pour+POLYGON+pourrait+avoir+la+forme+suivante%3A+make_polygon+%28vl%3A+LINKED_LIST+%5BPOINT%5D%29+is..jpg "-- Définir un polygone dont les nœuds sont dans vl. require. vl.count >= 3. do. ... Initialiser la représentation du polygone à partir des éléments de vl ... ensure. -- vertices et vl ont les mêmes éléments (cela peut s exprimer formellement). end. Pas pratique pour rectangle vu son invariant!")
175
10.2 POLYMORPHISME Attachement polymorphe Soient: p: POLYGON; r: RECTANGLE; t: TRIANGLE Les affectations suivantes sont, alors, valides: p := r p := t Par contre, r := p n'est pas valide car vous ne pouvez attacher quelque chose de général à quelque chose de plus spécifique.

176
Structures polymorphes de données
Considérons un tableau de polygones: poly_arr: ARRAY [POLYGON] Quand vous affectez une valeur x à un élément du tableau, comme dans poly_arr.put (x, some_index) la spécification de la classe ARRAY indique que le type de la valeur affectée doit être conforme au paramètre générique réel: class ARRAY [G] creation ... feature -- Elément change put (v: G; i: INTEGER) is -- Affecter v à l'entrée d'indice i. end -- class ARRAY
 la spécification de la classe ARRAY indique que le type de la valeur affectée doit être conforme au paramètre générique réel: class ARRAY [G] creation. ... feature -- Elément change. put (v: G; i: INTEGER) is. -- Affecter v à l entrée d indice i. end -- class ARRAY.")
177
Puisque v, argument formel correspondant à x, est déclaré dans la classe avec le type G et que le paramètre générique réel correspondant à G est, dans le cas de poly_arr, POLYGON, le type de x doit être conforme à POLYGON. Comme nous l'avons vu, cela ne veut pas nécessairement dire que x doit être de type POLYGON: tout descendant de POLYGON est acceptable. Ainsi, en supposant que le tableau ait pour bornes 1 et 4, que nous ayons déclaré certaines entités comme: p: POLYGON; r: RECTANGLE; s: SQUARE; t: TRIANGLE et que nous ayons créé les objets correspondants, nous pouvons exécuter: poly_arr.put (p, 1) poly_arr.put (r, 2) poly_arr.put (s, 3) poly_arr.put (t, 4) pour obtenir un tableau de références à des objets de types différents.
 poly_arr.put (r, 2) poly_arr.put (s, 3) poly_arr.put (t, 4) pour obtenir un tableau de références à des objets de types différents.")
178
10.3 TYPAGE DE L'HERITAGE Soient: p: POLYGON r: RECTANGLE Ce qui suit est valide: p.perimeter p.vertices, p.translate (...), p.rotate (...) avec des arguments valides; r.diagonal, r.side1, r.side2 r.vertices, r.translate (...), r.rotate (...): r.perimeter Ce qui suit n'est pas valide: p.sidel p.side2 p.diagonal
, p.rotate (...) avec des arguments valides; r.diagonal, r.side1, r.side2. r.vertices, r.translate (...), r.rotate (...): r.perimeter Ce qui suit n est pas valide: p.sidel. p.side2. p.diagonal.")
179
10.4 LIAISON DYNAMIQUE La liaison dynamique, alliée à la redéfinition, au polymorphisme et au typage statique, complétera la tétralogie de base de l'héritage. Utiliser la bonne variante !! p.make (...); x := p.perimeter perimeterPOL sera appliqué !! r.make (...); x := r.perimeter perimeterRECT sera appliqué Qu'en est-il si l'entité polymorphe p déclarée statiquement comme un polygone fait dynamiquement référence à un rectangle? !! r.make (...) p := r x := p.perimeter La liaison dynamique impose que la forme dynamique de l'objet détermine la version de l'opération à appliquer. Ici, il s'agira de perimeterRECT
; x := p.perimeter perimeterPOL sera appliqué. !! r.make (...); x := r.perimeter perimeterRECT sera appliqué. Qu en est-il si l entité polymorphe p déclarée statiquement comme un polygone fait dynamiquement référence à un rectangle !! r.make (...) p := r. x := p.perimeter. La liaison dynamique impose que la forme dynamique de l objet détermine la version de l opération à appliquer. Ici, il s agira de perimeterRECT.")
180
Comme on l'a vu, un cas plus intéressant se produit, bien sûr, quand nous ne pouvons pas déduire le type dynamique qu'aura exactement p lors de l'exécution à partir de la simple lecture du texte logiciel, comme dans: p: POLYGON -- Calculer le périmètre de la figure choisie par l'utilisateur ... if chosen_icon = rectangle_icon then ! RECTANGLE ! p.make (...) elseif chosen_icon = triangle_icon then ! TRIANGLE ! p.make (...) elseif end x := p.perimeter
 elseif chosen_icon = triangle_icon then. ! TRIANGLE ! p.make (...) elseif. end. x := p.perimeter.")
Présentations similaires


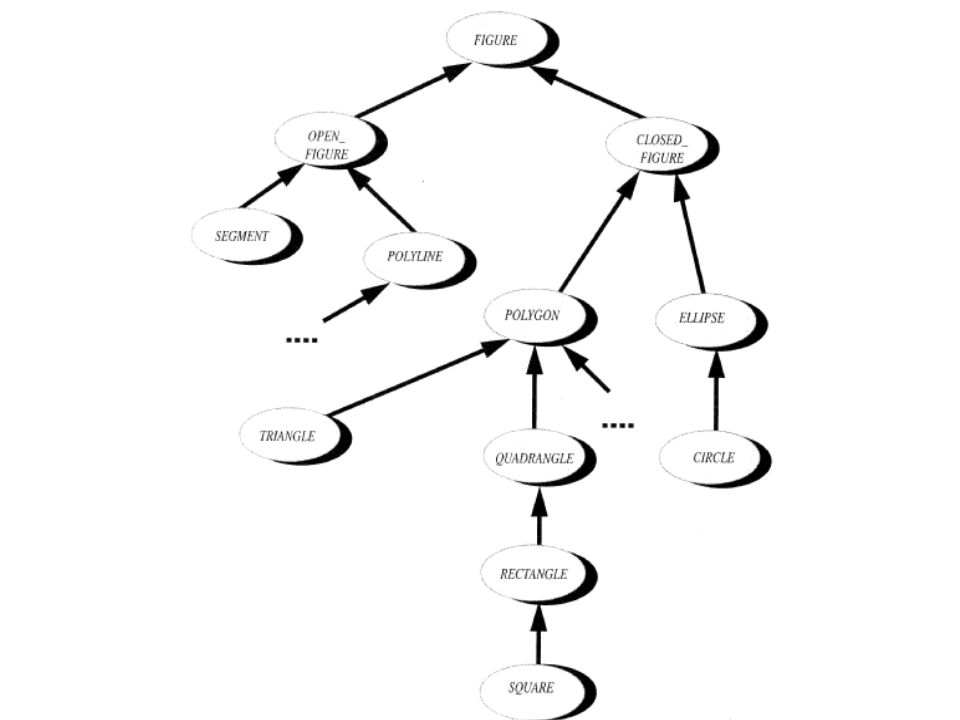













>")





