Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Relations Supercalculateurs et Réseaux Dominique Boutigny Prospective Nationale sur les Grilles de Production

2
Remerciements Groupe de travail « Infrastructure du calcul intensif » du colloque «Penser Pétaflops » Michel Kern (DGRI) Dany Vandromme (Renater)
 Dany Vandromme (Renater)")
3
Constatation: Grille et HPC - 2 mondes différents Communautés à priori différentes Supercalculateurs: Météo – Climat – Mécanique des fluides – Grandes simulations d’astrophysique… Grilles Physique corpusculaire – Biomédical… …mais quelques passerelles: Sciences de la terre Chimie Fusion

5
2 mondes différents Architecture de calcul très différentes Grilles Clusters de PC Parallélisme non couplé Supercalculateurs Machines massivement parallèles Couplage massif entre les processeurs Par contre une problématique autour des données présente dans les 2 communautés Les masses de données ont probablement été l’élément déclenchant pour la mise en place d’une architecture de grille pour le LHC

6
Grilles de supercalculateurs Teragrid aux USA 11 sites – 750 Tflops – 30 Po DEISA en Europe 10 sites Infrastructure de calcul distribué dotée d’un système de stockage global Nature des calculs effectués Architecture différente de celle des grilles de production

7
(Maximilien Brice, © CERN) Masse de données
 Masse de données")
8
Un exemple: Simulation météo haute résolution 13 mai 20088 Mécanique des fluides + physique en chaque point de calcul: Thermodynamique, rayonnement, turbulence… Code développé par un consortium de labos: ~20 chercheurs sur 10 ans Situation actuelle: ~100 Matrices 500 x 500 x 100 x 64 bits ~ 150 sorties x 20 Go chacune évolution temporelle Stockage Visualisation 1 projet 10 à 20 To disponibles pendant 4 à 5 ans Crédit: Patrick Mascart

9
Simulation météo haute résolution 13 mai 20089 Sur une machine Pétaflopique doublement de la taille de la grille et division du pas temporel par 2 Mémoire x8 - CPU et stockage x16 En 2009 sur les nouvelles machines nationales Triplement de la taille de la grille… Les estimations de ressources nécessaires sont complexes à extrapoler mais on voit qu’il faudra de toutes façons faire face à une augmentation exponentielle du stockage À terme: quelques pétaoctets pour chaque simulation

10
Un autre exemple: La QCD sur réseau (LQCD) Crédit: Jaume Carbonell Première étape: réalisée sur des supercalculateurs Espace-temps discrétisé sur un réseau 128 3 ×256 ~Pétaflop nécessaire Stockage des configurations sur une grille de données (SRB) – Mise à la disposition de la communauté mondiale Deuxième étape: Calcul des propagateurs sur des clusters classiques – Éventuellement sur une grille de calcul Stockage des propagateurs sur une grille de données (SRB) Troisième étape: Calcul des observables – Moyenne sur les propagateurs Architecture classique avec de relativement grandes mémoires
 Crédit: Jaume Carbonell Première étape: réalisée sur des supercalculateurs Espace-temps discrétisé sur un réseau ×256 ~Pétaflop nécessaire Stockage des configurations sur une grille de données (SRB) – Mise à la disposition de la communauté mondiale Deuxième étape: Calcul des propagateurs sur des clusters classiques – Éventuellement sur une grille de calcul Stockage des propagateurs sur une grille de données (SRB) Troisième étape: Calcul des observables – Moyenne sur les propagateurs Architecture classique avec de relativement grandes mémoires")
11
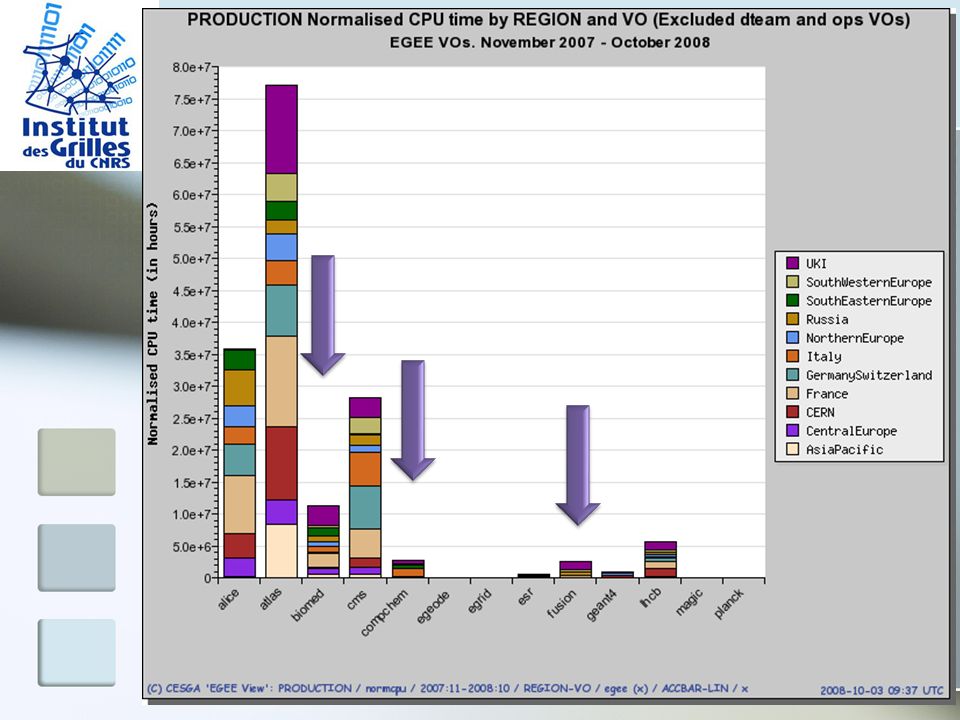
Physique des hautes énergies Les expériences LHC vont produire jusqu’à 15 Pétaoctets de données chaque années Grille LCG L’enjeu du calcul LHC réside essentiellement dans la distribution et le stockage des données 11 Tier-1 60 Tier-2 Tier-3 LHC

12
Parallélisme couplé/ Grille Le calcul parallèle nécessite des réseaux à très faible latence Applications MPI distribuées géographiquement anecdotique Par contre on peut envisager de soumettre des calculs parallèles sur des centres HPC à partir de l’infrastructure de grille Le calcul est effectué sur le calculateur parallèle, seule la soumission est faite en utilisant l’intergiciel de grille Définir correctement le « Computing Element » Lien avec DEISA / Teragrid

13
Exemple: Projet WISDOM (cf: Vincent Breton) Docking moléculaire sur la grille Calcul de Dynamique Moléculaire sur une architecture HPC Projet en cours dans le cadre du LIA France – Corée: FKPPL
 Docking moléculaire sur la grille Calcul de Dynamique Moléculaire sur une architecture HPC Projet en cours dans le cadre du LIA France – Corée: FKPPL")
14
Conclusion sur les relations Grilles – Supercalculateurs La communauté des grilles de calcul a développé un système sophistiqué de distribution des données La communauté des utilisateurs de supercalculateurs pointe la nécessité de développer considérablement les moyens de stockage en parallèle avec l’augmentation de la puissance de calcul La distribution des données produites par les grandes machines parallèles sur une grille, renforcera l’interaction entre Supercalculateurs – Mésocentres et Grilles de calcul Un rapprochement des communautés est nécessaire Voir présentation de Françoise Genova

15
Relation avec les réseaux Architecture réseaux RENATER 5

16
Exemple d’architecture mise en œuvre par RENATER pour LCG 23 septempbre 200816 Tier2 GRIF backup à travers le Tier1 KIT Karlsruhe Strasbourg Paris 10Gb/s autres Tier2s Tier2s français 2x 2,5Gb/s 10Gb/s Lyon

17
La technologie optique DWDM (multiplexage en longueur d’onde) permet de déployer des liaisons à n × 10 Gb/s entre les grands sites Déplacer de grande quantité de données n’est plus un problème Même à une échelle internationale Ceci favorise grandement l’utilisation de grilles de calcul Production des données auprès des grands instruments (y compris supercalculateurs) Post-traitement sur la grille ou dans les mésocentres
 permet de déployer des liaisons à n × 10 Gb/s entre les grands sites Déplacer de grande quantité de données n’est plus un problème Même à une échelle internationale Ceci favorise grandement l’utilisation de grilles de calcul Production des données auprès des grands instruments (y compris supercalculateurs) Post-traitement sur la grille ou dans les mésocentres")
18
Recommandation sur les réseaux Maintenir une collaboration étroite entre les projets de calcul et RENATER Garantir les financements nécessaires pour RENATER sur le long terme Quantifier les besoins en terme de bande passante des utilisateurs finaux, à priori beaucoup plus dispersés que dans le cas du LHC.

19
Remarque sur les architectures des calculateurs Crédit: Sverre Jarp (CERN) Évolution vers les architecture multi / many cores Demain: 1000 cœurs dans un PC standard – pièce de base des grilles actuelles Le modèle: 1 job sur 1 cœur est voué à l’échec car beaucoup trop inefficace et inapplicable en raison de la quantité de mémoire nécessaire (2 – 4 Go / cœur) Une convergence entre les grilles et le HPC est inévitable Ce problème est un vrai défi pour certaines communautés
 Évolution vers les architecture multi / many cores Demain: 1000 cœurs dans un PC standard – pièce de base des grilles actuelles Le modèle: 1 job sur 1 cœur est voué à l’échec car beaucoup trop inefficace et inapplicable en raison de la quantité de mémoire nécessaire (2 – 4 Go / cœur) Une convergence entre les grilles et le HPC est inévitable Ce problème est un vrai défi pour certaines communautés")
Présentations similaires












 Eugen Dedu IUT Belfort-Montbéliard, R&T1, France avril 2009.>")

>")




