Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
L’économie de l’assurance est issue de deux domaines qui étaient restés séparés jusqu’au début des années 1960, les statistiques et l’économie de l’incertain. L’économie de l’incertain ou de la prise de décision en univers incertain tente de comprendre comment les agents prennent leurs décisions lorsqu’ils se trouvent dans une configuration où ils ne possèdent pas toute l’information nécessaire à une prise de décision. Soit qu’ils ne connaissent pas à l’avance les conséquences de leurs décisions car ils se trouvent en interaction avec d’autres agents soit en raison d’un environnement économique changeant (phénomène de contingence). Dans ce type d’environnement de nombreuses questions se posent sans qu’il soit malheureusement possible d’y répondre de manière complète. C’est pour cette raison que va être développée une axiomatique, c'est-à-dire un ensemble d’hypothèses raisonnables mais restrictives visant à limiter le champ des possibles pour pouvoir modéliser les comportements raisonnables des agents économiques.
. Dans ce type d’environnement de nombreuses questions se posent sans qu’il soit malheureusement possible d’y répondre de manière complète. C’est pour cette raison que va être développée une axiomatique, c est-à-dire un ensemble d’hypothèses raisonnables mais restrictives visant à limiter le champ des possibles pour pouvoir modéliser les comportements raisonnables des agents économiques.")
2
On peut parler de noyau dur au sens de Lakatos
On peut parler de noyau dur au sens de Lakatos. Si on n’accepte pas cet ensemble d’hypothèses, on ne peut pas traiter de l’économie de l’assurance, ou bien il faut développer un autre noyau dur, une nouvelle approche. Le premier élément qui vient délimiter l’axiomatique de Von Neumann Morgenstern est qu’il existe deux notions différentes : la notion de risque et la notion d’incertitude. Cette distinction est réalisée par F. Knight dans son ouvrage de 1921 Risk, Uncertainty and Profit et Keynes A Treatise on Probability 1921

3
Le risque correspond au contraire à des systèmes fermés où il est possible de déterminés précisément les probabilités d’occurrences des événements ainsi que de quantifier leurs conséquences. Les loteries sont des systèmes fermés. On verra qu’elles sont utilisées fréquemment afin de représenter les comportements des agents en univers incertain, probabilisable. L’incertitude correspond à des systèmes ouverts au sens de Faber et Proops. C'est-à-dire que l’ensemble des événements possibles n’est pas défini ex ante. Autrement dit, on ne peut uniquement connaître tous les Etats de la nature possibles avec leurs conséquences qu’après qu’ils se soient réalisés. Limite de l’inférence statistique, le signe noir, le soleil.

4
On parle également d’incertitude radicale et d’incertitude probabilisable. Pour résumer en simplifiant, il y a les risques quantifiables et non quantifiables. L’assurance s’intéresse aux premiers, les seconds ne pouvant être tarifés dans le cadre d’un contrat d’assurance. L’économie de l’incertain va donc abandonner une partie des événements possibles car on pourra les traiter dans ce cadre. Un autre élément de complexité entre dans les questions touchant aux décisions prises en univers incertain. Chaque agent économique en fonction de son éducation, de son milieu sociale, de son niveau de patrimoine et de richesse va aborder la notion de risque avec des aprioris différents.

5
Certains, très riches pourront prendre des risques importants du fait qu’ils détiennent un coussin de sécurité important. D’autres aussi riches mais plus prudents auront peur de s’engager dans telles aventures. Réciproquement, des gens pauvres n’ayant rien à perdre pourraient être tentés de se lancer dans des activités fortement risquées. Au contraire, sans le sou, et ne souhaitant pas perdre le peu qu’ils possèdent, ils adopteront une attitude prudente. Le propos ici est de souligner la divergence de l’appréciation du risque en fonction des individus. Ainsi trois types de comportement vont être identifiés, les individus adverses au risque, les prudents, les individus indifférents au risque, et enfin les individus qui apprécient le sel du risque. Ces notions seront définies formellement dans le cadre de l’utilité espérée.

6
On peut également ajouter qu’un individu peut voir ses probabilités subjectives évoluer au cours du temps. Les personnes âgées sont plus attachées à leur sécurité, les adolescents au contraire sont disposés à prendre des risques. Par ailleurs en fonction de la structure des risques, des gains et des pertes des positions différentes pourraient être adoptées qui ne seraient pas congruentes vis-à-vis de l’axiomatique VNM. On verra ainsi le paradoxe de Allais. L’axiomatique VNM sans pouvoir répondre à l’ensemble de ces limites va néanmoins constituer le bloc à partir duquel l’économie de l’assurance est construite. Il faut avoir conscience de ces limites, mais par définition le risque et la subjectivité des agents ne peuvent entièrement entrer dans un cadre formel quantifiable. Néanmoins cette approche permet d’aborder de manière cohérente et systématique les problématiques assurantielles, c’est le cadre à travers lequel on peut essayer de modéliser le comportement des agents face au risque. Dans cette partie on va tenter d’appréhender les notions théoriques de base qui régissent le fonctionnement des assurances. Ces notions sont l’aversion au risque, la prime de risque, l’équivalent certain, l’espérance d’utilité et surtout les hypothèses qui composent l’axiomatique Von Neumann Morgenstern.

7
La théorie de la décision en univers incertain :
Habituellement, la microéconomie décrit le comportement des agents en fonction d’alternatives qui sont certaines. Un consommateur va chercher à maximiser son utilité en fonction de ses préférences qui sont connues, de sa contrainte budgétaire ainsi que des prix des biens et des services auxquels il peut accéder eux-mêmes connus. Dans la réalité les choses sont un peu plus complexes. Un agent s’il décide de produire un certain type de produit ne connait pas à l’avance le montant de la demande pour ce type de bien, il doit donc choisir. Ce choix constitue une prise de risque.

8
Cette prise de risque peut être présentée en fonction de 3 critères : le critère d’action qui relève du choix de l’acteur, le critère lié à l’état de la nature, dans cet exemple le niveau de la demande, et enfin la probabilité de réalisation des différents états de la nature. L’idée principale est que les gains réalisés sont conditionnés par des événements qui ne sont pas sous le contrôle de l’agent individuel. Ces situations peuvent être représentées sous la forme de distribution de probabilité ou de loterie. Mais au final, ces représentations vont servir à établir les niveaux de primes qui pourront être exigées par les assureurs pour se couvrir de divers risques. Ce qui va guider l’agent c’est l’espérance d’utilité de sa richesse. Son critère de décision consiste à choisir la distribution de la richesse finale qui lui permettra de maximiser son espérance d’utilité.

9
L’axiomatique Von Neumann Morgerstern, le critère d’utilité espérée pour dépasser les limites de l’approche statistique Dans ces situations, les statistiques seules ne peuvent répondre de manière satisfaite à l’établissement de critères de décision. Si on considère les deux loteries suivante on verra que les statisques ne permettent pas de rendre compte des comportement dans l’incertain.

10
Soit un agent joue à la loterie suivante, il peut gagner le montant Z ou – Z avec les probabilité ½, ½. L’espérance de gain de la loterie s’ecrit donc : E(l0) = ½*Z+1/2*(-Z) = 0 La seconde loterie le gain vs. la perte est nulle E(l1) =0 A partir de la seule espérance de gain, il n’est pas possible de faire un choix entre ces deux loteries car leur espérance est la même. Pourtant dans la réalité, les agents vont effectuer des choix que le seul critère d’espérance mathématique ne peut résoudre. Il faut donc trouver autrechose. Avant d’aller plus loin nous revenons sur les notions de base permettant de caractériser les prises de décision dans l’incertain.
 = ½*Z+1/2*(-Z) = 0. La seconde loterie le gain vs. la perte est nulle. E(l1) =0. A partir de la seule espérance de gain, il n’est pas possible de faire un choix entre ces deux loteries car leur espérance est la même. Pourtant dans la réalité, les agents vont effectuer des choix que le seul critère d’espérance mathématique ne peut résoudre. Il faut donc trouver autrechose. Avant d’aller plus loin nous revenons sur les notions de base permettant de caractériser les prises de décision dans l’incertain.")
11
États de la nature e1 ei en a1 R1,1 R1,i R1,n aj Rj,1 Rj,i Rj,n am
Rm,1 Rm,i Rm,n Prob{e} Prob{e1} Prob{ei} Prob{en} Actions

12
États du temps Temps humide (e1) Temps moyen (e2) Temps sec (e3) Blé
Rb,h Rb,m Rb,s Maïs (a2) Rm,h Rm,m Rm,s Prob{e} Prob{h} Prob{m} Prob{s} Choix de la culture
 Rm,h. Rm,m. Rm,s. Prob{e} Prob{h} Prob{m} Prob{s} Choix de la culture.")
13
États du temps Temps humide Temps moyen Temps sec Blé Rb,h 4 t/h Rb,m
Rb,s Maïs Rm,h 5 t/h Rm,m Rm,s 3 t/h Prob{e} Prob{h} 0.35 Prob{m} 0.5 Prob{s} 0.15 Choix de la culture Les probabilities de survenu des different états de nature peuvent être établis en fonction de relevés passés de la météo dans la région.

14
A partir de l’ensemble de ces combinaisons
Rb,h; Rb,m; Rb,s; Rm,h; Rm,m; Rm,s un ordre de préférence va pouvoir être établi Cet ensemble de résultats forme un cardinal C’est à dire un nombre fini de résultats que l’on peut ordonné

15
P(a1)={ 0.00;0.15; 0.35;0.40;0.50}=1 P(a2)={ 0.00;0.15; 0.35;0.40;0.50}=1 Le choix entre produire du blé ou du maïs peut être assimilé au choix entre 2 loteries. Ces loteries ne diffèrent pas par leurs résultats (les éléments de C) mais diffèrent par les distributions de probabilité p(aj).
 mais diffèrent par les distributions de probabilité p(aj).")
16
Quelle que soit l’action ménée appartenant à l’ensemble des actions possibles, il existe une probabilité associée à cette action telle que, cette probabilité soit supérieure ou égale à zéro et que la somme de probabilité formée par cette loterie soit égale à 1.

17
Probabilité que l’action aj conduise au l ième résultat de C*
Une action aj peut être caractérisée de la façon suivante : Ou encore :

18
Chaque décision (loterie) peut alors être comparée
par sa distribution de probabilité sur l’ensemble des conséquences C • Par conséquent, si on prend le cardinal des conséquences des toutes les loteries, chaque loterie ne diffère que par sa distribution de probabilités, • Si on suppose que l’agent dispose d’un pré-ordre complet sur les conséquences (relation de préférence et d’indifférence sur les conséquences), alors la définition d’une relation de préférence sur les loteries suffit à caractériser le comportement vis-à-vis du risque d’un agent, Cette relation de préférence doit respecter les axiomes suivants pour que la fonction d’utilité VNM existe :
, alors la définition d’une relation de préférence sur les loteries suffit à caractériser le comportement vis-à-vis du risque d’un agent, Cette relation de préférence doit respecter les axiomes suivants pour que la fonction d’utilité VNM existe :")
19
Soit l’utilité espérée définit en 1947 par VNM
Nous allons définir une relation de préférence dans l’ensemble P et demander à cette relation de vérifier l’axiomatique de Von Neumann et Morgenstern Soit l’utilité espérée définit en 1947 par VNM Von Neumann Oskar Morgenstern (Görlitz Princeton 1977) ( )
 ( )")
20
Intérêt de l’approche VNM en terme d’utilité espérée (1947)
Séparation entre les croyances sur les sources de l’incertitudes représentées par des probabilités sur des évenements incertains, de l’utilité pour les gains certains La séparation entre des situations de risque où les probabilités sont données (jeu de roullette) et des situations où ces probabilités ne sont pas connue (course de cheveaux) est levée. C’est le modèle d’espérance subjective d’utilité de Savage (1954) qui permet le passage de situation d’incertitude à des situation de risque probabilisable. Mais les probabilités ne sont plus objectives, mais subjective.
 et des situations où ces probabilités ne sont pas connue (course de cheveaux) est levée. C’est le modèle d’espérance subjective d’utilité de Savage (1954) qui permet le passage de situation d’incertitude à des situation de risque probabilisable. Mais les probabilités ne sont plus objectives, mais subjective.")
21
L’axiomatique de VNM A-1- L’axiome de comparabilité, réflexivité
Il faut supposer que deux distributions de probabilités pourront toujours être comparées. A-2- L’axiome de transitivité Cet axiome traduit une rationalité pure qui induit la cohérence entre les classements Les axiomes A1 et A2 forment un préordre, ie une relation une relation binaire réflexive et transitive. Elle est dite totale si elle est complete. Paradoxe de Condorcet, Paradoxe de Allais

22
A-3- L’axiome d’indépendance forte ou de substitution
Cet axiome peut s’interpréter de la façon suivante : L’attitude d’un individu face aux deux loteries ne devra dépendre que de son attitude face à p et q et non pas de la façon d’obtenir p et q.

23
A-4- L’axiome de continuité ou d’Archimède
L’analogie avec le principe d’Archimède vient du fait que : quelque soit un couple (z , z’) de deux entiers naturels, il existe toujours un entier naturel k tel que : kz > z’
 de deux entiers naturels, il existe toujours un entier naturel k tel que : kz > z’")
24
Utilité ordinale Vs. Utilité cardinale
Comment mesurer l’utilité, voire même l’utilité était-elle mesurable ? Utilité ordinale Vs. Utilité cardinale Les fonctions d’utilité définies par vNM sont qualifiées de cardinales. Elles permettent d’attribuer une valeur caractérisant le niveau de satisfaction associe a la consommation d’un ≪ bien ≫. Elles se différencient des fonctions d’utilité ordinales qui permettent seulement de classer les ≪ biens ≫ les uns par rapport aux autres. Avec la cardinalité il est possible de dire cette loterie est préférée 4 fois plus que celle autre loterie. C’est la cardinalité qui permet la maximisation. Une hypothèse importante sous jacente à la théorie de l’utilité espérée est l’indépendance : la valeur donnée à un résultat est indépendante de la manière dont il est arrivé ou de son contexte (axiome 3).
.")
25
L’utilité ici est mesurable.
Ordinale vs. cardinale La fonction d’utilité cardinale joue un rôle centrale dans l’étude des préférences des individus car elle permet de quantifier l’utilité associée à chaque bien et ainsi de réaliser des arbitrages visant à maximiser l’utilité individuelle. On peut dire qu’un bien apporte 4 fois plus d’utilité qu’un autre bien. L’utilité ici est mesurable. Pourtant Paréto et d’autres économistes rejettent la fonction d’utilité pour représenter les comportements individuelles, car ils ne croient pas que l’on puisse établir une fonction d’utilité objective. Dans ce cas, il se contente de la définition d’un préordre complet. La connaissance sur l’ordre des préférence suffit. Toutefois, ordonner les préférences ne permet pas de mesurer l’utilité.

26
Supposons que les préférences d’un individu soient telles que
On représente ces préférences par une fonction d’utilité U(.) qui vérifie U(a) = 20; U(b) = 10; U(c) = 5 De ces trois chiffres, on peut également tirer les renseignements suivants : l’utilité de a, b et c vaut exactement 20, 10 et 5 ; a est deux fois plus utile que b et quatre fois plus que c ; On obtient 15 degrés d’utilité en plus en ayant a plutôt que c ; et 5 degrés en plus en ayant b plutôt que c ; La différence d’utilité entre a et c est trois fois plus grande que la différence d’utilité entre b et c. Supposons que nous prenions la racine carrée de la fonction U. On appelle V cette nouvelle fonction d’utilité V =pU
 qui vérifie U(a) = 20; U(b) = 10; U(c) = 5. De ces trois chiffres, on peut également tirer les renseignements suivants : l’utilité de a, b et c vaut exactement 20, 10 et 5 ; a est deux fois plus utile que b et quatre fois plus que c ; On obtient 15 degrés d’utilité en plus en ayant a plutôt que c ; et 5 degrés en plus en ayant b plutôt que c ; La différence d’utilité entre a et c est trois fois plus grande que la différence d’utilité entre b et c. Supposons que nous prenions la racine carrée de la fonction U. On appelle V cette nouvelle fonction d’utilité. V =pU.")
27
Il vient évidemment, V (a) = p20 = 4, V (b) = p10 = 3, V (c) =p5 = 2, On constate que des 4 renseignements précédents, seul le fait que continue à être vérifié. En effet, les « valeurs d’utilité » ont changé et il est désormais faux que a soit deux fois plus utile que b. De plus, les variations d’utilité et les rapports de différences ont également changé. Si on admet qu’une fonction d’utilité n’est définie qu’à une fonction croissante près, alors on reconnaît ipso facto que le seul renseignement qu’on veut préserver en passant d’une fonction d’utilité à une autre est l’ordre. Par exemple, toute transformation croissante de la fonction U donnera toujours. Abordons maintenant le problème de l’utilité cardinale. Reprenons l’exemple précédent, où on avait U(a) = 20 U(b) = 10 U(c) = 5
 = 20 U(b) = 10 U(c) = 5.")
28
Qu’elles sont les transformations qui permettent de préserver
les renseignements 1 à 4 ? Le premier renseignement n’est préservé que par la transformation « identité ». En effet, si V = Id *U alors, on a : V (a) = 20 V (b) = 10 V (c) = 5 Le deuxième renseignement nous dit que U(a)/U(b) = 2 et U(a)/U(c)=4 On constate donc que les transformations linéaires de U ne modifient pas ce renseignement. Si V = α U on a V (a)/ V(b) = α U(a)/ αU(b) = 2 et V (a)/V(c) = αU(a)/ αU(c) =4.
 = 20 V (b) = 10 V (c) = 5. Le deuxième renseignement nous dit que. U(a)/U(b) = 2 et U(a)/U(c)=4. On constate donc que les transformations linéaires de U ne modifient pas ce renseignement. Si V = α U on a V (a)/ V(b) = α U(a)/ αU(b) = 2. et V (a)/V(c) = αU(a)/ αU(c) =4.")
29
V (a)−V (c) = (U(a)+ β )−(U(c)+ β ) = 15
Le troisième renseignement nous dit que U(a)−U(c) = 15 et U(b)−U(c) = 5. Il est évident qu’en ajoutant une constante à la fonction U on ne change pas ce renseignement. Si V =U + β on aura bien V (a)−V (c) = (U(a)+ β )−(U(c)+ β ) = 15 V (b)−V (c) = (U(b)+ β )−(U(c)+ β ) = 5 Le dernier renseignement nous dit que Il est clair qu’une transformation affine (positive) de U ne le modifie pas. Si V = αU +β On aura bien
−U(c) = 15 et U(b)−U(c) = 5. Il est évident qu’en ajoutant une constante à la fonction U on ne change pas ce renseignement. Si V =U + β on aura bien. V (a)−V (c) = (U(a)+ β )−(U(c)+ β ) = 15. V (b)−V (c) = (U(b)+ β )−(U(c)+ β ) = 5. Le dernier renseignement nous dit que. Il est clair qu’une transformation affine (positive) de U ne le modifie pas. Si V = αU +β On aura bien.")
30
On appelle « affines » les transformations de type V = αU +β
On appelle « affines » les transformations de type V = αU +β. Et comme on peut le remarquer, toutes les transformations que nous avons évoquées sont « affines ». Outre le fait qu’elles conservent l’ordre, on remarque que : – si α = 1 et β = 0 on obtient la transformation identité. Elle laisse invariante l’échelle sur laquelle on mesure la grandeur (ici, l’utilité) ; – si α > 0 et β = 0 on obtient une transformation linéaire croissante. Cette transformation dilate l’échelle de mesure en conservant le même « zéro » ; – si α = 0 et β > 0 on obtient un décalage de l’origine. On déplace le « zéro » de l’échelle de mesure sans changer la taille des « graduations » ; – si α > 0 et β > 0 on obtient une transformation affine dans le sens le plus large du terme. Elle change le zéro de l’échelle de mesure tout en dilatant les espaces entre les graduations.
 ; – si α > 0 et β = 0 on obtient une transformation linéaire croissante. Cette transformation dilate l’échelle de mesure en conservant le même « zéro » ; – si α = 0 et β > 0 on obtient un décalage de l’origine. On déplace le « zéro » de l’échelle de mesure sans changer la taille des « graduations » ; – si α > 0 et β > 0 on obtient une transformation affine dans le sens le plus large du terme. Elle change le zéro de l’échelle de mesure tout en dilatant les espaces entre les graduations.")
31
On voit que les transformations affines contiennent comme cas particuliers les simples décalages d’origine et les simples dilatations des espaces entre les graduations qui contiennent elles-mêmes comme cas particulier la transformation identité. On parlera d’utilité cardinale lorsque la classe des transformations d’une fonction d’utilité est restreinte aux transformations affines croissantes (ou positives). Cela veut donc dire que l’utilité est dite «mesurable » lorsque toutes les fonctions d’utilité représentant les préférences d’un consommateur préservent les rapports de différences d’utilité, c’est à dire lorsque les instruments de mesure ne diffèrent que par le degré de dilatation (proportionnel) des graduations et la place du « zéro ».
. Cela veut donc dire que l’utilité est dite «mesurable » lorsque toutes les fonctions d’utilité représentant les préférences d’un consommateur préservent les rapports de différences d’utilité, c’est à dire lorsque les instruments. de mesure ne diffèrent que par le degré de dilatation (proportionnel) des graduations et la place du « zéro ».")
32
Les fonctions d’utilité espérées de VNM permettent de mesurer l’utilité en univers incertain
Supposons qu’un individu soit confronté à différentes possibilités (tenues pour certaines). Partant de ces possibilités, on définit ce qu’on appelles des « loteries », c.-à-d. des distributions de probabilités sur les différentes possibilités. Selon von Neumann et Morgenstern, on peut établir des préférences sur les loteries. Ces préférences possèdent selon eux des propriétés tout à fait particulières.
. Partant de ces possibilités, on définit ce qu’on appelles des « loteries », c.-à-d. des distributions de probabilités sur les différentes possibilités. Selon von Neumann et Morgenstern, on peut établir des préférences sur les loteries. Ces préférences possèdent selon eux des propriétés tout à fait particulières.")
33
Axiome 1 et 2 Les préférences existent et sont transitives.
Axiomes de la théorie de l’utilité espérée de Von Neumann – Morgenstern Au fil du temps, les axiomes originaux de von Neumann et Morgenstern ont été reformules par différents auteurs. Bell et Farquhar (Bell and Farquhar 1986) les présentent de la façon suivante. Axiome 1 et 2 Les préférences existent et sont transitives. Pour toute paire de loteries y et y' , ou bien y est préféré a y', ou bien y' est préféré à y, ou bien l’individu est indifférent entre y et y'. De plus pour tout triplet de loteries y, y' et y' ', si y est préféré à y' et si y' est préféré à y' ', alors y est préféré à y' '. De meme si y est indifférent a y‘ et si y' est indifférent a y' ', alors y est indifférent a y' '. Source : (Drummond 1998) tirée de la thèse de Julie Chevalier.
 les présentent de la façon suivante. Axiome 1 et 2 Les préférences existent et sont transitives. Pour toute paire de loteries y et y , ou bien y est préféré a y , ou bien y est préféré à y, ou bien l’individu est indifférent entre y et y . De plus pour tout triplet de loteries y, y et y , si y est préféré à y et si y est préféré à y , alors y est préféré à y . De meme si y est indifférent a y‘ et si y est indifférent a y , alors y est indifférent a y . Source : (Drummond 1998) tirée de la thèse de Julie Chevalier. sequence=1.")
34
Axiome 3 Indépendance. Un individu devrait être indifférent entre une loterie à deux niveaux et une loterie simple équivalente en probabilité, qui s’en déduit selon les lois de probabilité usuelles. Par exemple, considérons deux loteries y et y' . y correspond au résultat x1 avec la probabilité p1 et au résultat x2 avec la probabilité 1 - p1 , ce qu’on note formellement par y = (p1, x1, x2 ) . De même, y'= (p2, x1,x2 ) .Selon l’axiome l’indépendance, un individu est indifférent entre la loterie à deux niveaux (p,y,y' ) et la loterie équivalente en probabilité (pp1 +(1 - p)p2 , x1, x2 ). Source : (Drummond 1998) tirée de la thèse de Julie Chevalier.
 . De même, y = (p2, x1,x2 ) .Selon l’axiome l’indépendance, un individu est indifférent entre la loterie à deux niveaux (p,y,y ) et la loterie équivalente en probabilité (pp1 +(1 - p)p2 , x1, x2 ). Source : (Drummond 1998) tirée de la thèse de Julie Chevalier. sequence=1.")
35
Axiome 4 Continuité des préférences.
Si on a trois résultats x1 , x2 et x3, tels que x1 est préféré à x2 qui est préféré à x3 , il existe une probabilité p pour laquelle l’individu est indifférent entre le résultat x2 obtenu avec certitude et la loterie qui correspond au résultat x1 avec la probabilité p et au résultat x3 avec la probabilité (1 – p) Source : (Drummond 1998) tirée de la thèse de Julie Chevalier. Supposons qu’on appelle a et z la meilleure et la pire des possibilités aux yeux de l’individu i. On choisit deux nombres Ui (a) et Ui (z) qui fixent la plus élevée et la plus faible des utilités. On considère maintenant la possibilité b vérifiant Cela veut dire - dans le langage des loteries - que i préfère la loterie L(a, z;1,0) à b et préfère b à la loterie L(a, z;0,1). L’hypothèse fondamentale de von Neumann et Morgenstern est qu’il existe une probabilité 0 < p < 1 telle que l’individu i est indifférent entre b et la loterie L(a, z;p,1−p). L’indice d’utilité de b est alors Ui (b) = pUi (a)+(1−p)Ui (z).
 Source : (Drummond 1998) tirée de la thèse de Julie Chevalier. sequence=1. Supposons qu’on appelle a et z la meilleure et la pire des possibilités aux yeux de l’individu i. On choisit deux nombres Ui (a) et Ui (z) qui fixent la plus élevée et la plus faible des utilités. On considère maintenant la possibilité b vérifiant . Cela veut dire - dans le langage des loteries - que i préfère la loterie L(a, z;1,0) à b et préfère b à la loterie L(a, z;0,1). L’hypothèse fondamentale de von Neumann et Morgenstern est qu’il existe une probabilité 0 < p < 1 telle que l’individu i est indifférent entre b et la loterie. L(a, z;p,1−p). L’indice d’utilité de b est alors Ui (b) = pUi (a)+(1−p)Ui (z).")
36
Mélanges et lois de probabilité

37
q(1-z)+(1-q)*z+(1-q)*(1-z)=(1-p)
Axiome 5 de réduction des loteries composées. • Un agent doit être indifférent entre une loterie A qui lui donne une probabilité p de gagner x$ et (1-p) de gagner 0$ et une loterie qui lui donne une probabilité q de gagner une loterie B (x$,0$); (z, (1-z)) et une probabilité (1-q) de gagner 0$ ssi : q*z=p Implique que : q(1-z)+(1-q)*z+(1-q)*(1-z)=(1-p) • Exemple : un agent doit être indifférent entre une loterie A qui lui donne 25% de chances de gagner 100$ et une loterie qui lui donne 50% de chances de gagner une loterie B qui lui donne 50% de chances de gagner 100$ ½*Lb(1/2,1/2;0;50) ~ La(0,1/4,0;100)
 de gagner 0$ et une loterie qui lui donne une probabilité q de gagner une loterie B (x$,0$); (z, (1-z)) et une probabilité (1-q) de gagner 0$ ssi : q*z=p. Implique que : q(1-z)+(1-q)*z+(1-q)*(1-z)=(1-p) • Exemple : un agent doit être indifférent entre une loterie A qui lui donne 25% de chances de gagner 100$ et une loterie qui lui donne 50% de chances de. gagner une loterie B qui lui donne 50% de chances de gagner 100$ ½*Lb(1/2,1/2;0;50) ~ La(0,1/4,0;100)")
38
Sous les axiomes A-1, A-2, A-3, A-4,
il existe une fonction u telle que : Dans le cadre de l’axiomatique établie précédement, la fonction d’utilité espérée de VNM permet de comparer de manière satisfaisante les critères qui vont conduire aux choix de différentes loteries des agents et de pouvoir les comparer.

39
On considère maintenant la possibilité b vérifiant
Supposons qu’on appelle a et z la meilleure et la pire des possibilités aux yeux de l’individu i. On choisit deux nombres Ui (a) et Ui (z) qui fixent la plus élevée et la plus faible des utilités. On considère maintenant la possibilité b vérifiant Cela veut dire que dans le langage des loteries que i préfère la loterie L(a, z;1,0) à b et préfère b à la loterie L(a, z;0,1). L’hypothèse fondamentale de von Neumann et Morgenstern est qu’il existe une probabilité 0 < p < 1 telle que l’individu i est indifférent entre b et la loterie L(a, z;p,1−p). L’indice d’utilité de b est alors Ui (b) = pUi (a)+(1−p)Ui (z). C’est l’application de l’axiome de continuité
 et Ui (z) qui fixent la plus élevée et la plus faible des utilités. On considère maintenant la possibilité b vérifiant. Cela veut dire que dans le langage des loteries que i préfère la loterie L(a, z;1,0) à b et préfère b à la loterie L(a, z;0,1). L’hypothèse fondamentale de von Neumann et Morgenstern est qu’il existe une probabilité 0 < p < 1 telle que l’individu i est indifférent entre b et la loterie. L(a, z;p,1−p). L’indice d’utilité de b est alors Ui (b) = pUi (a)+(1−p)Ui (z). C’est l’application de l’axiome de continuité.")
40
En reprenant la démarche précédente, on
Cette procédure peut être répétée pour chaque possibilité b, c, d, ..., y et donne une fonction d’utilité von Neumann-Morgenstern. La fonction que nous avons construite n’est bien sûr pas unique. Prenons par exemple deux nouveaux nombres Vi (a) et Vi (z) pour fixer la plus élevée et la plus faible des utilités. En reprenant la démarche précédente, on aboutit une fois encore à l’idée que l’utilité de la possibilité b est Vi (b) = p Vi (a)+(1−p)Vi (z). En répétant cette procédure pour chaque possibilité b, c, d, ..., y on obtient une nouvelle fonction d’utilité VNM. Maintenant, intéressons-nous au rapport qui existe entre Ui et Vi . On a Ui (b) = pUi (a)+(1−p)Ui (z)
 et Vi (z) pour fixer la plus élevée et la plus faible des utilités. En reprenant la démarche précédente, on. aboutit une fois encore à l’idée que l’utilité de la possibilité b est. Vi (b) = p Vi (a)+(1−p)Vi (z). En répétant cette procédure pour chaque possibilité b, c, d, ..., y on obtient une nouvelle fonction d’utilité VNM. Maintenant, intéressons-nous au rapport qui existe entre Ui et Vi . On a. Ui (b) = pUi (a)+(1−p)Ui (z)")
41
En soustrayant la seconde à la première, il vient :
Ui (b) = pUi (a)+(1−p)Ui (z), Ui (b)−Vi (b) = p (Ui (a)−Vi (a))+(1−p) (Ui (z)−Vi (z)). De la première on tire l’expression de p On remplace dans la seconde ce qui donne En tenant compte du fait que Ui (a),Ui (z), Vi (a) et Vi (z) sont des données, on obtient facilement (après simplification) que : Vi (z) = αUi (z)+β. La fonction VNM Vi est une transformation affine de la fonction Ui. Le même résultat pour tous les indices d’utilités haut et bas qu’on veut bien se donner comme point de départ.
 = pUi (a)+(1−p)Ui (z), Ui (b)−Vi (b) = p (Ui (a)−Vi (a))+(1−p) (Ui (z)−Vi (z)). De la première on tire l’expression de p. On remplace dans la seconde ce qui donne. En tenant compte du fait que Ui (a),Ui (z), Vi (a) et Vi (z) sont des données, on obtient facilement (après simplification) que : Vi (z) = αUi (z)+β. La fonction VNM Vi est une transformation affine de la fonction Ui. Le même résultat pour tous les indices d’utilités haut et bas qu’on veut bien se donner comme point de départ.")
42
L’aversion vis à vis du risque
Rappel: si une variable aléatoire suit une loi normale, alors son espérance correspond à sa moyenne L’attitude face au risque : On suppose qu’un individu a une richesse initiale w0 et détient une loterie Sa richesse finale est notée : L’agent a le choix entre garder ou obtenir de façon certaine

43
Si l’agent préfère obtenir de façon certaine l’espérance de sa richesse finale que la richesse finale, on dit que l’agent est risquophobe. Si l’agent préfère garder sa richesse finale alétoire plutôt que d’obtenir de façon certaine l’espérance de sa richesse finale, on dit que l’agent est risquophile. Si l’agent est indifférent entre avoir de façon certaine l’espérance de sa richesse finale et aa richesse finale, on dit que l’agent est neutre par rapport au risque.

44
Soit la loterie : La richesse finale est donc : Nous devons comparer : Avec :

45
1er cas : agent risquophobe :

46
2ème cas : agent risquophile :

47
3ème cas : agent neutre vis à vis du risque :

48
Exercice d’application

50
Cet exemple illustre l’idée qu’il est nécessaire de réaliser des transformations affines pour pouvoir comparer les niveaux d’utilité espérée et ainsi de construire la fonction d’utilité espérée. On va normaliser les niveaux d’utilité dans un cadrant. De cette manière on transforme un ordre de préférences, un ordre complet: un ordinal, en un cardinal.

53
Si l’agent est risquophobe, il va être prêt à payer une prime pour se prémunir du risque.
Cette prime de risque va correspond à ce que l’agent est prêt à payer pour éviter le risque. Notation correspond à la richesse certaine, correspond à la richesse aléatoire, sans assurance. L’agent sera au maximum prêt à payer la prime P qui égalise son niveau d’utilité de la richesse certaine, avec le niveau de l’espérance d’utilité de la richesse incertaine. La prime correspond à réduction de la richesse certaine qui est juste équivalent à l’utilité générée par la richesse incertain, c’est le seuil d’indifférence. Les deux loteries sont équivalentes.

54
Par hypothèse on sait que l’espérance d’utilité de la richesse aléatoire est inférieure à l’utilité de l’espérance de la richesse aléatoire Qui correspond à l’équivalent certain de la richesse finale aléatoire

55
Le concept d’équivalent certain :
L’équivalent certain est le montant w* sûr et certain qui procure la même utilité que la richesse finale risquée (c-à-d la richesse initiale w0 et la loterie )
")
60
Si la richesse initiale est nulle, l’équivalent de la richesse certaine vaut : 0+100-20=80

61
EXERCICE : 1- Tracez la fonction d’utilité. Qu’en déduisez vous ? w u(w) -2000 -1000 1000 2000 3000 4000 5000 10 000 -600 -150 80 150 210 250 280 340 2- Quel montant maximal est-on prêt à investir dans un projet qui rapportera 1000€ ou € avec la même probabilité ?

62
Solution : La somme maximale est donc telle que :

63
Jusqu’à présent la prime de risque a été définie de manière globale
Or pouvoir établir cette prime de risque il va falloir être en mesure de la déterminer pour chaque agent en fonction de ses caractéristiques (subjectives) face au risque et aux caractéristiques objectives de la distribution du risque. C’est l’approximation de Pratt par développement limité qui permet d’approcher la prime de risque de manière spécifique.
 face au risque et aux caractéristiques objectives de la distribution du risque. C’est l’approximation de Pratt par développement limité qui permet d’approcher la prime de risque de manière spécifique.")
64
Rappel: La prime de risque correspond à l’écart entre l’équivalent certain et la richesse aléatoire
L’agent sera au maximum prêt à payer la prime P qui égalise son niveau d’utilité de la richesse certaine, avec le niveau de l’espérance d’utilité de la richesse incertaine.

66
L’approximation de Pratt (1964)
A partir de développements limités de Taylor, Pratt propose une approximation de l’expression de la prime de risque. Cette approximation est : Est une composante subjective propre à l’agent Relative Risk Aversion (RRA) Est une composante objective propre à la loterie Absolute Risk Aversion (ARA)
 Est une composante objective propre à la loterie. Absolute Risk Aversion (ARA)")
67
Exemple : Calculez la prime de risque par l’approximation de Pratt. Réponse :

68
Quelques précisions : La composante subjective de la prime de risque par l’approximation de Pratt est appelée coefficient d’aversion absolue pour le risque. Propriété #1 : L’individu est risquophobe Increasing Absolute Risk (IARA) L’individu est neutre vis à vis du risque Constant Absolute Risk Aversion (CARA) L’individu est risquophile Decreasing Absolute Risk Aversion (DARA)
 L’individu est neutre vis à vis du risque. Constant Absolute Risk Aversion (CARA) L’individu est risquophile. Decreasing Absolute Risk Aversion (DARA)")
69
Propriété #2 : Plus Ru est élevé en étant positif, plus l’individu est risquophobe. Propriété #3 : Le coefficient Ru est invariant lors de toute transformation affine croissante de la fonction d’utilité. Propriété #4 : Le coefficient Ru mesure en fait la courbure de la fonction d’utilité. Propriété #5 : De façon réciproque, on peut mesurer la tolérance pour le risque, notée T u(w) par :
 par :")
70
Les fonctions d’utilité usuelles :
Nous allons présenter quelques fonctions d’utilité qui sont couramment utilisées en économie. La fonction d’utilité linéaire : L’aversion vis à vis du risque est nulle donc un agent qui aurait une fonction d’utilité linéaire est agent neutre vis à vis du risque.

71
La fonction d’utilité logarithmique :
L’aversion vis à vis du risque est positive donc un agent qui aurait une fonction d’utilité logarithmique est agent risquophobe. On remarque que l’aversion vis à vis du risque décroît avec la richesse.

72
La fonction d’utilité exponentielle négative :
L’aversion vis à vis du risque est positive donc un agent qui aurait une fonction d’utilité exponentielle négative est agent risquophobe. On peut remarquer que l’aversion vis à vis du risque est constante quelque soit la richesse.

73
La fonction puissance :
L’aversion vis à vis du risque est positive donc un agent qui aurait une fonction d’utilité de ce type est agent risquophobe. On peut remarquer que l’aversion vis à vis du risque est décroissante par rapport à la richesse.

74
Exercice 2 : Soit un agent dont la psychologie est donnée par :
Sa richesse initiale est : w0= € Il peut acheter un billet de type loto qui lui permet de gagner 3 millions d'€ avec une chance sur 13 millions. Quel est le prix maximum est-il prêt à payer pour acheter un tel billet ?

75
Solution : L'agent achètera le billet si et seulement si l'équivalent certain est supérieur ou égal à sa richesse initiale.

82
Le contrat d’assurance
Les agents cherchent à se protéger contre les risques pesant sur leur patrimoine, leur niveau de richesse. L’assurance vise à couvrir un sinistre contre le paiement d’une prime. La couverture peut-être complète, on parle alors d’assurance complète, sinon on se trouve dans le cas de la co-assurance, seule une partie du sinistre est indemnisé par l’assurance.

83
Dans le cadre le plus simple, l’agent possède un richesse initiale W0.
et il se trouve deux états de nature e1 avec sinistre, e2 sans sinistre Y sont associés deux probabilités complémentaires π et (1-π) La probabilité d’absence de sinistre est (1-π) dans ce cas la richesse finale W1 = W0 Dans le cas contraire la richesse de l’agent perd de sa valeur à hauteur du sinistre S. W2 = W0 -S
 La probabilité d’absence de sinistre est (1-π) dans ce cas la richesse finale W1 = W0. Dans le cas contraire la richesse de l’agent perd de sa valeur à hauteur du sinistre S. W2 = W0 -S.")
84
Les situations respectives W1 et W2 peuvent être représentées
Utilité sans sinistre W2 - Sinistre Utilité avec sinistre

85
L’agent ne s’assure que si l’utilité que lui procure l’assurance lui permet d’accéder à un niveau d’utilité supérieur à celui sans assurance.

86
Ceci va en partie dépendre du niveau de la prime d’assurance qui va affecter le niveau de la richesse finale en cas de souscription d’une assurance, ainsi que du niveau d’indemnité. Vc > Vo Dans le cas de l’assurance complète, on suppose que l’indemnité correspond au niveau du sinistre. Il vient donc : W1 = W – P = W – P – S + I = W2 W1 = W2 La richesse finale est indépendante de l’état du monde

87
Pour se couvrir Il faut que l’utilité obtenue au point C soit supérieure à celle obtenue au point O

88
Dans le cas du contrat A, l’agent accepte de s’assurer car son utilité en ce point est supérieure à celle au point o. En C, on trouve la prime maximale pour laquelle on accepte de s’assurer O et C sont sur la même courbe d’indifférence C Par contre en B, il n’acceptera pas de s’assurer car la prime d’assurance est trop élevée

89
Sur le point C, l’agent est indifférent entre la situation d’assurance ou de non assurance, la prime maximale est définie par l’indifférence entre le point C et O. En C, on se trouve sur la bissectrice, là où les niveaux de richesse dans les deux états du monde sont équivalents. Ici le TMS entre les deux richesse vaut : TMS = Un contrat d’assurance peut être caractérisé par son niveau de prime et son d’indemnité, de le cadre suivant cela donne un point Contrat.

90
Si l’agent ne s’assure pas il se trouve sur le point O.
Si il s’assure, il se trouve sur le point A.

91
L’espérance d’utlité de l’agent assuré est :
L’espérance de profit pour l’assurance est : Pour un profit nul la compagnie va fixer sa prime L’utilité de l’agent devient après substitution de P L’agent devra également décider du niveau de sinistre qu’il souhaite assurer, soit I = α S

92
α, le degré de protection face au sinistre va être déterminer de manière à maximiser l’utilité espérée de l’assuré.

93
Pour avoir le niveau d’utilité espéré le plus élevé l’agent va se placé sur le contrat C
Ce point doit qui représente le contrat optimal doit correspondre à un TMS égal à la pente de la tangente de la courbe d’indifférence. On doit avoir l’égalité suivante avec la pente de la droite OC P=πs

94
On retrouve l’idée qu’un agent adverse au risque se trouvera dans une situation optimale si il peut s’assurer complètement contre le risque I = S et que la prime corresponde à la probabilité d’occurrence de sinistre P=πs Du point de vue de l’assureur on trouve que

96
le fonctionnement de l’assurance
Rappel de base sur le fonctionnement de l’assurance le contrat d’ assurance est défini par 3 éléments : l’Aléa, la prime et l’indemnité en fonction de la nature de l’aléa on se trouve dans le cadre de l’assurance dommage ou de l’assurance vie

97
Principe indemnitaire : l’assurance ne permet pas l’enrichissement de l’assuré mais uniquement la compensation d’une perte. Ce principe s’applique particulièrement à l’assurance dommage. Principe forfaitaire: l’indemnité est fixée de manière forfaitaire. Ce principe s’applique particulièrement à l’assurance de personne.

98
Responsabilité civile vs. pénale
Elle est engagée lorsqu’une règle de droit est enfreinte. Cette situation n’est pas assurable puisqu’elle relève d’un acte volontaire. Civile: Elle est engagée lorsque des préjudices sont causés à un tiers. Causé par sa faute mais de manière in-intentionnelle, par imprudence ou négligence. Par les personnes dont on est en responsabilité, descendants et ascendants, nos proposés, les objets possédés ou loués.

99
La responsabilité pénale n’est pas couverte par une assurance, mais peut entrer dans le cadre d’analyse de l’économie de l’assurance Lorsqu’un agent économique se livre à une activité délictueuse. Il effectue un calcul en terme de gains et de pertes. La perte correspond au risque d’être pris. Celui-ci n’est pas certain. L’agent cherche à maximiser son gain net. D’un point de vue économique, l’acte délictuel peut être rationnel.

100
Un préjudice, un dommage Une faute
L’assurance dans le cadre de la responsabilité civile implique la présence de trois éléments: Un préjudice, un dommage Une faute Un lien de causalité entre la faute et le préjudice. Le dommage peut être corporel, matériel et/ou moral. L’analyse économique par l’intermédiaire de la fonction d’utilité peut englober ces trois aspects du dommage et transformer la perte d’utilité en une compensation financière. Ceci conduit à des calculs parfois sordides mais nécessaires du type combien vaut une vie, un bras… Pour effectuer cette quantification des simplifications sont nécessaires sur l’appréciation de l’utilité des agents. Celle-ci est supposée indépendante du temps et de l’ensemble des choix de l’agent.

101
En fonction de la position sociale de l’agent la fonction d’utilité pourra varier. Les préférences sont différentes suivant que l’on se trouve sans emploi, que l’on se trouve plus ou moins avancé dans le cycle de la vie. C’est la problème de la contingence que l’on ne fait qu’évoquer. Cette prise en compte de complexité de la réalité ne trouve pas actuellement de solution générale et constitue l’objet de recherches non stabilisées. La responsabilité civile délictuelle ou quasi délictuelle, et la responsabilité civile contractuelle. La responsabilité civile contractuelle est engagée lors de la non ou la mauvaise exécution d’un contrat. Pour les autres cas, c’est du ressort de la responsabilité civile. Elle recouvre la responsabilité personnelle du fait d’autrui, du fait des choses, du fait des animaux, des propriétaires de bâtiments.

102
Responsabilité civile, contractuelle:
responsabilité de moyens ou de résultats? Dans le cadre de service de maintenance ou de livraison. La garantie de résultat est engagée. La responsabilité de la poste se trouve engagée si un colis n’arrive pas à son destinataire en bon état. Idem pour un contrat de maintenance, les équipements pris en charge doivent être réparer dans les délais prévus par le contrat. Dans le cadre de services juridique, de médecine, seule la responsabilité de moyen est engagée. Pour pouvoir recevoir un dédommageant en cas de problème de santé suite à une intervention chirurgicale, il faudra être en mesure d’établir une faute avérée du médecin ou de l’équipe soignante.

103
On a établi précédemment que l’agent risquophobe va choisir une assurance complète dès lors que la prime correspond à la prime pure, c’est-à-dire celle permettant juste de faire face à la survenue de sinistre. Ce cadre théorique satisfaisant pour une première approche ne permet pas de comprendre le fonctionnement réel de l’assurance En effet, en tant qu’entreprise celle-ci doit faire face à ses coûts de fonctionnement et dégager un bénéfice. Aussi, la prime effectivement payée devra tenir compte des frais de fonctionnement de l’assurance, ainsi que d’une marge bénéficiaire. Dans ce cas nous verrons que l’assurance complète n’est plus la situation optimale pour l’agent. Pour retrouver une situation optimale l’agent pourra arbitrer entre un contrat qui prévoit une indemnisation partielle ou la prise en charge d’une franchise. On passe dans le monde « réel » de la coassurance.

104
De l’assurance complète, à la co-assurance et la franchise
Dans le cadre de l’assurance complète, le seul paramètre inconnu est le montant de la prime. Le montant de l’indemnité est équivalent au montant du sinistre et la richesse initiale est connue. Cette prime ne peut excéder la valeur initiale de la richesse de l’agent, même elle devra en être assez éloigné pour que l’agent accepte de s’assurer. Pour que l’assureur accepte d’assurer, la prime ne pourra pas être nulle. On peut déterminer le niveau maximal de la prime pour laquelle l’agent serait indifférent entre l’assurance et la non assurance. ) )
 )")
105
Le partage du risque peut être réalise par la co-assurance ou la franchise
La co-assurance implique que l’assuré ne s’assure que sur une partie du sinistre. La franchise implique que l’assuré paie un forfait, la franchise lorsque celui-ci décide d’activer l’assurance. C’est donc sur l’un des deux variables d’assurance indemnité (I) ou prime (P) que va porter l’arbitrage.
 ou prime (P) que va porter l’arbitrage.")
106
Les contrats d’assurance :
Le contrat de pleine assurance est un contrat où l’intégralité du sinistre est remboursée par l’assurance Le contrat de co-assurance est un contrat ou seulement une part du sinistre est remboursée par l’assurance Le contrat d’assurance avec franchise est un contrat où l’assuré prend à sa charge le sinistre jusqu’à un certain montant fixé. Au delà de ce montant, la différence entre la perte et la franchise est à la charge de l’assurance.

107
0 > α > 1 assurance partielle
Si α représente le niveau de richesse sinistrable que l’agent souhaite assurer, il peut exister trois cas : α = 0 pas d’assurance α =1 assurance complète 0 > α > 1 assurance partielle Afin de représenter les frais de gestion et la marge que doit réaliser l’assurance, la prime va être réécrite de manière à tenir compte du risque et d’un facteur de chargement (g). P = P(α) = gαS αS correspond au montant sinistrable assuré, et g représente le taux de prime par montant d’euros assurés, le taux de chargement
. P = P(α) = gαS. αS correspond au montant sinistrable assuré, et g représente le taux de prime par montant d’euros assurés, le taux de chargement.")
108
La richesse aléatoire finale peut s’écrire ainsi :
L’agent va chercher à maximiser l’utilité l’espérance de l’utilité de la richesse finale aléatoire en fonction de α :

109
Premier ordre Second ordre
Afin de maximiser l’espérance d’utilité de l’agent il faut établir les conditions de premier et de second ordre: Premier ordre Second ordre

110
Si π > g alors α*<1 car W1 doit être inférieur à W2
Dès lors que l’agent est adverse au risque (u’’<0), la condition de second ordre est respectée. A partir de la condition de premier ordre il possible d’établir que la co-assurance est optimale dès lors que la prime exigée est supérieure à la prime pure du fait du chargement Si π > g alors α*<1 car W1 doit être inférieur à W2 En effet si W1=W2 α = 1 On retrouve le cas de l’assurance complète uniquement si g ≤ π ce qui implique gS ≤ πS
, la condition de second ordre est respectée. A partir de la condition de premier ordre il possible d’établir que la co-assurance est optimale dès lors que la prime exigée est supérieure à la prime pure du fait du chargement. Si π > g alors α*<1 car W1 doit être inférieur à W2. En effet si W1=W2 α = 1. On retrouve le cas de l’assurance complète uniquement si g ≤ π ce qui implique gS ≤ πS.")
111
Dans le même esprit nous allons étudier la situation
d’une assurance avec franchise, Ici ce n’est plus le montant assurable qui va faire l’objet de l’ajustement mais le niveau de la franchise. L’indemnité qui n’est pas certaine d’être versée va prendre la forme suivante : La prime peut-être écrite ainsi : λ représente le facteur de chargement, F la franchise

112
La richesse finale de l’agent
L’agent va maximiser son utilité en fonction du niveau de la Franchise

113
Condition de première ordre :
Condition de second ordre : Cette dernière est vérifiée si u’’<0 Si λ > 0 le montant de la franchise optimale F* > 0 également.

122
La théorie de la prévention P = πS
Jusqu’à présent le risque est présenté comme une fatalité pour l’agent économique. Il ne pouvait s’en prémunir, mais uniquement en limiter les conséquences en souscrivant un contrat d’assurance. Désormais, l’agent ne sera plus sans influence sur le risque. L’agent va pouvoir : soit tenter d’en limiter la probabilité (auto-protection), soit tenter de limiter le niveau de sinistralité (auto-assurance). Une nouvelle question va apparaître dans quelle mesure cette attitude de protection va -t-elle être substituable à un contrat d’assurance. On doit préciser avant d’aller plus loin que la séparation entre autoprotection et auto-assurance revêt une caractère assez théorique et que l’une peut-être remaner à l’autre d’une point de vue formelle.
, soit tenter de limiter le niveau de sinistralité (auto-assurance). Une nouvelle question va apparaître dans quelle mesure cette attitude de protection va -t-elle être substituable à un contrat d’assurance. On doit préciser avant d’aller plus loin que la séparation entre autoprotection et auto-assurance revêt une caractère assez théorique et que l’une peut-être remaner à l’autre d’une point de vue formelle.")
123
c’> 0, c’’ < 0 et S’<0 , S’’ > 0
L’auto-assurance L’auto-assurance représente un effort consenti par l’agent économique (e) qui doit permettre de limiter le niveau du sinistre (S). Le coût par l’agent est fonction croissante de l’effort c= c(e) Les fonctions de coût et de sinistre prennent les forment suivantes : c’> 0, c’’ < 0 et S’<0 , S’’ > 0 Dans le cas de l’auto-assurance la richesse finale de l’agent peut être écrite ainsi : L’agent va chercher à maximiser l’utilité espérée de la richesse finale aléatoire en fonction de l’effort consenti La richesse avec et sans incident :
 qui doit permettre de limiter le niveau du sinistre (S). Le coût par l’agent est fonction croissante de l’effort c= c(e) Les fonctions de coût et de sinistre prennent les forment suivantes : c’> 0, c’’ < 0 et S’<0 , S’’ > 0. Dans le cas de l’auto-assurance la richesse finale de l’agent peut être écrite ainsi : L’agent va chercher à maximiser. l’utilité espérée de la richesse. finale aléatoire en fonction de l’effort consenti. La richesse avec et sans incident :")
124
c’(e*)+S’(e*) < 0 , c’(e*) < -S’(e*)
Condition de premier ordre : Condition de second ordre : Compte tenu de la forme des fonctions u, S, c la condition de second ordre est toujours respectée. La condition de première ordre est plus problématique : On doit avoir : c’(e*)+S’(e*) < 0 , c’(e*) < -S’(e*) Ce qui signifie que l’efficacité marginale de l’effort doit être supérieur à son coût marginale. Il y bien une volonté d’accroitre l’autoprotection avec l’aversion au risque
+S’(e*) < 0 , c’(e*) < -S’(e*) Ce qui signifie que l’efficacité marginale de l’effort doit être supérieur à son coût marginale. Il y bien une volonté d’accroitre l’autoprotection avec l’aversion au risque.")
125
La théorie du portefeuille de Markowitz (1952)
L’autoprotection Il n’y a pas nécessairement d’augmentation de l’autoprotection avec l’aversion au risque. De ce point de vue l’auto-assurance peut-être vue comme un substitut à l’assurance, ce qui n’est pas le cas de l’autoprotection perçue plutôt comme un complément à l’assurance. Exemple de Eeckhoudt (1991) avec recours à la théorie du portefeuille de Markowitz (1952) La théorie du portefeuille de Markowitz (1952) Le rapport rendement/risque, espérance/variance Pour décider d’investir dans un projet risqué, un agent va tenter d’établir une mesure du risque et une mesure du rendement associée à ce projet. L’espérance de gain est associée au rendement et la variance au risque. La rapport espérance sur variance donne donc le critère de décision.
 avec recours à la théorie du portefeuille de Markowitz (1952) La théorie du portefeuille de Markowitz (1952) Le rapport rendement/risque, espérance/variance. Pour décider d’investir dans un projet risqué, un agent va tenter d’établir une mesure du risque et une mesure du rendement associée à ce projet. L’espérance de gain est associée au rendement et la variance au risque. La rapport espérance sur variance donne donc le critère de décision.")
126
Ces principes ont été forgés par Markowitz en observant le comportement des investisseurs sur les marchés financiers. L’objectif de Markowitz est de définir une politique de placement idéale, autrement dit une composition optimale. Il s’agit donc de définir des choix financiers en univers incertain. Markowitz observe que les agents ne cherchent pas à obtenir la valeur maximale espérée du portefeuille, ni la valeur moyenne mais cherchent avant tout à réduire la dispersion des rendement de ce portefeuille. Markowitz décide de retenir comme critère de dispersion la variance. Les investisseurs vont donc tenter d’établir pour un rendement donné, la variance minimale en réalisant une composition optimale de leur portefeuille. Un portefeuille optimal va pouvoir être construit dès lors que l’on connait la moyenne et la variance de rendement de chaque actif composant le portefeuille.

127
Ce principe est généralisé avec l’idée que l’investisseur opère un arbitrage entre espérance (μ) et variance (σ) Pour une fonction Ф = Ф(μ, σ) avec et La fonction Ф peut être considérée comme un index de satisfaction que la combinaison (μ, σ) procure à l’agent. L’investisseur retiendra la combinaison qui maximise la valeur de Ф. En établissant les conditions de premier ordre d Ф=0 on observe que : dμ/dσ >0 Et de second ordre : d²μ/d²σ > 0 Ces éléments nous permettent de définir un choix d’investissement optimal en univers incertain. On obtient un nombre, donc un critère cardinal aisément utilisable.
 avec et. La fonction Ф peut être considérée comme un index de satisfaction que la combinaison (μ, σ) procure à l’agent. L’investisseur retiendra la combinaison qui maximise la valeur de Ф. En établissant les conditions de premier ordre. d Ф=0 on observe que : dμ/dσ >0. Et de second ordre : d²μ/d²σ > 0. Ces éléments nous permettent de définir un choix d’investissement optimal en univers incertain. On obtient un nombre, donc un critère cardinal aisément utilisable.")
128
Ce critère cardinal, permet de comparer le rendement/risque des projets mais sans faire référence à la nature des préférences de l’investisseur. Or il est évident que chaque individu à des préférences spécifiques. En effet, l’investisseur plus ou moins adverse au risque ne classera pas nécessairement les projets d’investissement en fonction du ratio espérance/variance de manière identique. Autrement dit l’équivalent certain, c’est à dire la perte qu’est prêt à enregistrer un agent pour obtenir la sécurisation de ses gains peut être très différente en fonction des individus. La faiblesse de la théorie du portefeuille est qu’elle ne repose pas sur une axiomatique clairement définie. Ainsi, les orientations qu’elle impose aux agents pourront être perçues comme arbitraire. Il faudrait pouvoir établir une équivalence entre la méthode de Markowitz et l’axiomatique VNM.

129
L’établissement d’une équivalence entre Markowitz et VNM implique que non seulement on va pouvoir établir la même loterie préférée par les deux méthodes mais que de surcroît les classements des loteries seront identiques, indifférent à la méthode utilisées. Pour y parvenir, il faut opérer des limitations soit du côté de la fonction d’utilité, soit du côté des loteries. Il y aura équivalence si les fonctions d’utilité dans VNM sont quadratique : U(x) = ax²+bx+c Ou bien que les loteries suivent une lois normale Si ces 2 critères alternatifs ne sont pas remplis, les classements suivants les deux méthodes donneront des résultats différents. Retour au cas de l’autoprotection comme illustration de l’approche en terme de portefeuille.
 = ax²+bx+c. Ou bien que les loteries suivent une lois normale. Si ces 2 critères alternatifs ne sont pas remplis, les classements suivants les deux méthodes donneront des résultats différents. Retour au cas de l’autoprotection comme illustration de l’approche en terme de portefeuille.")
130
Soit une entreprises dont le bilan est composé de 3000 d’actifs sans risque, d’un immeuble L d’une valeur de 2000, d’une passif sous forme de dette envers les tiers T de 400. Comme l’actif doit être égal au passif, les fonds propres valent 4600 W = A + L – T = – 400 = 5000 – 400 = 4600 Le risque porte sur l’immeuble qui peut disparaitre dans un incendie avec une probabilité 0.1 En cas de réalisation du sinistre, la richesse de l’entreprises ne vaut plus que : W =A0 + L – T = = 2600 La valeur de l’entreprise suit donc une variable aléatoire (binomiale) susceptible de prendre la valeur 4600 ou 2600 avec les probabilités respective de 0,9 et 0,1.
 susceptible de prendre la valeur 4600 ou 2600 avec les probabilités respective de 0,9 et 0,1.")
131
L’espérance et la variance de cette variable aléatoire va donc être :
E(W) = 4400 Var(W) = Si l’entreprise s’assure avec un contrat qui stipule une prime P = 200 et une indemnité I = 1600. Dans ce cas la richesse de l’entreprise avec et sans sinistre vaut : W = 3000 – – 400 = 4800 – 400 = 4400 W= 3000 – – 400 = 4400 – 400 =4000 E(W)= 4360 Var(W) = L’assurance permet à la fois une diminution de l’espérance et de la variance. Si on considère que la variance permet une bonne représentation du risque et qu’elle constitue un critère de décision, on peut transcrire ce situation par la théorie du portefeuille (Markowitz). Désormais, la prime sera perçue comme un investissement en autoprotection.
 = 4400 Var(W) = Si l’entreprise s’assure avec un contrat qui stipule une prime P = 200 et une indemnité I = Dans ce cas la richesse de l’entreprise avec et sans sinistre vaut : W = 3000 – – 400 = 4800 – 400 = W= 3000 – – 400 = 4400 – 400 =4000. E(W)= 4360 Var(W) = L’assurance permet à la fois une diminution de l’espérance et de la variance. Si on considère que la variance permet une bonne représentation du risque et qu’elle constitue un critère de décision, on peut transcrire ce situation par la théorie du portefeuille (Markowitz). Désormais, la prime sera perçue comme un investissement en autoprotection.")
132
Le taux de rendement de ce portefeuille suit une loi aléatoire qui peut prendre deux valeurs en %
1 avec une probabilité 0.9 et 7 avec une probabilité 0.1 E(R) =0.9(-1)+0.1*(+7) = -2 Bien que le rendement soit négatif, l’agent va investir dans ce portefeuille, l’assurance, car elle réduit le risque ( la variance) Si on compare avec les situations d’autoprotection et d’auto-assurance. On se rend compte que l’auto-assurance produit les mêmes effets que l’assurance, ce qui n’est pas le cas de l’autoprotection. Par exemple, si on investit 80 pour permettre de réduire de moitié la probabilité de risque supporté par la richesse W ou W suit une loi binomiale on a :
 =0.9(-1)+0.1*(+7) = -2. Bien que le rendement soit négatif, l’agent va investir dans ce portefeuille, l’assurance, car elle réduit le risque ( la variance) Si on compare avec les situations d’autoprotection et d’auto-assurance. On se rend compte que l’auto-assurance produit les mêmes effets que l’assurance, ce qui n’est pas le cas de l’autoprotection. Par exemple, si on investit 80 pour permettre de réduire de moitié la probabilité de risque supporté par la richesse W ou W suit une loi binomiale on a :")
133
E(W) = 4400 et Var(W) = La variance diminue en contrepartie d’une baisse de l’espérance. Mais si la variance baisse moins rapidement que l’espérance, il se peut que la mise en œuvre d’une politique de protection ne soit pas optimale. En effet, si le coût de la protection augmente plus rapidement que l’aversion au risque, le coût de l’autoprotection est supérieur au gain qu’il génère. Ainsi l’auto-assurance et l’assurance peuvent être vu comme des substituts tandis que l’autoprotection peut être assimilée à un complément de l’assurance.

139
L’assurance dommage du point de vue de l’offre :
L’assurance est entreprises privée, elle cherche donc le profit maximal (sauf mutuelle) Elle assure la contrepartie pour des risques que les particuliers ne peuvent assurer seuls. Pour ce faire, elle mobilise le principe de mutualisation des risques qui permet de répartir le risque sur une large population. Le risque pour l’assurance est toutefois de mal anticiper ces risques. Mais des risques à l’actifs peuvent également apparaître. L’assurance est donc menacée par un risque de ruine. C’est pour cette raison qu’elle est contrôlée et qu’elle doit disposer d’importantes réserves afin de faire face à des situations extrêmes.
 Elle assure la contrepartie pour des risques que les particuliers ne peuvent assurer seuls. Pour ce faire, elle mobilise le principe de mutualisation des risques qui permet de répartir le risque sur une large population. Le risque pour l’assurance est toutefois de mal anticiper ces risques. Mais des risques à l’actifs peuvent également apparaître. L’assurance est donc menacée par un risque de ruine. C’est pour cette raison qu’elle est contrôlée et qu’elle doit disposer d’importantes réserves afin de faire face à des situations extrêmes.")
140
La comptabilité des assurances ressemble dans ces grands principes à la comptabilité des autres entreprises. Mais à la place d’avoir un compte achat et vente de marchandises. Elle a un compte sinistres et primes, auquel vient s’ajouter les revenus tirés des placements financiers. Les engagements vis-à-vis des assurés sont appelés provisions techniques des assurances. Elles sont inscrites au passifs des assurances et représentent les montants que l’assurance prévoit de distribuer aux assurés dans l’éventualité de réalisation des sinistres couverts par le contrat d’assurance. Elles sont composées de 2 parties, celles pour primes non-acquises et celle pour paiement de sinistre. Les primes non acquises sont liées au décalage temporel avec l’exercice comptable. Le calcul des provisions techniques, éléments aléatoires, fait l’objet de développements statistiques importants qui permettent aux assurances de mobiliser les niveaux avec une marge d’erreur suffisantes pour éviter les risques de liquidité et de solvabilité. Plus les immobilisations sont importantes et plus cela coûte à l’assurance.

141
Avec facteur de chargement, S est une variable aléatoires, R aussi.
Les assurances ne conservent pas toutes les primes d’assurances sous formes de liquidité mais en place une grande partie sur les marchés financiers afin de produire des revenus additionnels. Le compte de résultat est établi en comptabilité analytique, ce qui pose un problème pour les frais généraux. L’estimation de la probabilité de ruine et l’établissement du niveau optimal de réserves. Résultats net de la compagnie d’assurance : R = (1+)*P-S Avec facteur de chargement, S est une variable aléatoires, R aussi. Si le déficit de l’assurance dépasse K, elle est ruinée. On cherche donc à minorer que R devienne inférieur à (– K) Prob (R < - K) < , avec seuil de sécurité établi à l’avance
*P-S. Avec facteur de chargement, S est une variable aléatoires, R aussi. Si le déficit de l’assurance dépasse K, elle est ruinée. On cherche donc à minorer que R devienne inférieur à (– K) Prob (R < - K) < , avec seuil de sécurité établi à l’avance.")
142
Définition de l’espérance mathématique de gain de l’assurance
E(R) = (1 + )*P – E(S) = (1+)*P – P = P Sa variance est : Var(R) = var (S) = ² Grâce à l’inégalité de Bienaymé-Tchebytchev on peut écrire : Prob (P - t R +t) >1 – 1/t² Si on choisit t tel que K= t - P Puis On a alors :
 = (1 + )*P – E(S) = (1+)*P – P = P. Sa variance est : Var(R) = var (S) = ². Grâce à l’inégalité de Bienaymé-Tchebytchev on peut écrire : Prob (P - t R +t) >1 – 1/t². Si on choisit t tel que. K= t - P. Puis. On a alors :")
143
Soit Prob [(- K > R) ou (R > 2 P – K)]
La ruine ou la non ruine sont exclusif l’un de l’autre Le coefficient de sécurité permet de majorer le risque de ruine. Le coefficient de sécurité varie avec de K, et P, et inversement avec . Plus K est élevé et plus la probabilité de ruine est faible. K constitue donc un instrument de gestion du risque de ruine. Il représente le niveau des réserves techniques . Il en va de même pour et P. Le niveau des recettes contribuant à réduire le risque de faillite. A l’inverse si la variance des risque s’accroit cela a pour conséquence de réduire
![Soit Prob [(- K > R) ou (R > 2 P – K)]](http://slideplayer.fr/slide/1158726/3/images/143/Soit+Prob+%5B%28-+K+%3E+R%29+ou+%28R+%3E+2+%EF%81%ACP+%E2%80%93+K%29%5D.jpg "La ruine ou la non ruine sont exclusif l’un de l’autre. Le coefficient de sécurité permet de majorer le risque de ruine. Le coefficient de sécurité varie avec de K, et P, et inversement avec . Plus K est élevé et plus la probabilité de ruine est faible. K constitue donc un instrument de gestion du risque de ruine. Il représente le niveau des réserves techniques . Il en va de même pour et P. Le niveau des recettes contribuant à réduire le risque de faillite. A l’inverse si la variance des risque s’accroit cela a pour conséquence de réduire ")
144
Soit un ensemble de n variables aléatoires X1, X2, …, Xn, de même loi, indépendantes 2 à 2, d’espérance mathématique m et de variance ². Z est une variable aléatoire dont l’espérance mathématique est donnée par: Et la variance par : Avec l’application de l’inégalité de Bienaymé-Tchebytchev :

145
Plus n est grand est plus Z se rapproche de l’espérance mathématique m, c’est l’illustration de la loi faible des grands nombres De plus à partir de la variable centrée réduite : Dont la moyenne vaut 0 et de variance =1. Lorsque n tend vers l’infini, la distribution limite quelle que soit la loi des Xi est celle d’une loi centrée réduite. C’est le théorème de la limite centrale. On peut s’en servir en théorie de l’assurance lorsqu’on est face à un portefeuille de n polices identiques et pour des sinistres indépendants deux à deux. Si S est le montant total des sinistres assurés et P la prime versée (supposée égale à la valeur actuarielle, c’est-à-dire égale à l’espérance du sinistre) On peut écrire :
 On peut écrire :")
146
La suite des variables Yn converge en loi vers la variable Z qui suit une loi normale
La probabilité que le gain net R dépasse le montant – K est donné par la relation suivante : Avec Y qui représente la limite de Yn Par rapport au coefficient de sécurité β on a : Le passage à une variable centrée réduite permet de mieux comprendre le sens du coefficient de sécurité. La probabilité de ruine pour un niveau de réserve donné K est donnée par la valeur de la fonction de répartition de la loi normale centrée réduite pour le coefficient de sécurité β=β(K)
")
147
β correspond donc à la valeur seuil à ne pas dépasser si on souhaite éviter la ruine.
Ainsi, on se donne au départ une probabilité de ruine a priori à partir de laquelle on en déduit le coefficient de sécurité. Ce dernier permet d’établir le montant de réserves K pour éviter la ruine dans le contexte précédemment défini.

150
Asymétrie informationnelle en situation de monopole :
Introduction des notions d’aléas moral et de sélection adverse Il a était supposé jusqu’ici que les assureurs possédé une information exhaustive sur les assurés. En réalité cette information est imparfaite, ce qui entraîne des coûts informationnels, soit en terme de pertes liée à la mauvaise connaissance des assurés, soit en raison des coûts de production de cette connaissance.

151
Généralement toute l’information susceptible d’altérer les termes du contrat d’assurance ne sont pas à la disposition de l’assurance. L’assureur peut à travers un questionnaire tenter d’établir le profile de risque a priori d’un assurer en raison de son âge, son sexe mais sans pouvoir extraire complètement de ces informations la connaissance du comportement de l’agent en termes de précaution ou même de compétence. Le risque lié à la sélection adverse et un risque ex ante pour l’assureur le risque est de recruter beaucoup de mauvais risques. C’est-à-dire des assurés dont le risque de sinistralité est plus élevé que la moyenne. L’aléa moral est un risque ex post, L’assuré se sachant protégé adoptera un comportement plus risqué ou simplement fera moins attention. Dans le pire des cas, des phénomènes de fraude à l’assurance peuvent apparaître. Cette asymétrie d’information va porter préjudice aux profits de l’assurance, mais elle peut tenter de réduire les coûts liés au manque d’information en définissant un menu de contrat dans lequel les risques élevés seront incités à prendre le contrat qui est définit pour eux et idem pour les risques faibles.

152
La sélection adverse L’assurance fait face à une population hétérogène de souscripteurs. Pour faciliter la présentation on ne retient que 2 cas types, les bons et les mauvais risques. Avec π1 probabilité de sinistré des bas risques et π2 probabilité de sinistrés des hauts risques, donc π1< π2. On suppose que les 2 types d’agents possède la même fonction d’utilité : Par la suite les indices 1 et 2 seront omis. Rappel de la définition de la prime et du niveau d’indemnité : P=gαS g la prime par euro assuré et I =α S, α le taux de couverture de l’assurance Le taux de couverture alpha va permettre à l’assureur de décliner un menu de contrat visant les différentes catégories d’assurer. De manière générale on doit vérifier les conditions de 1er et de 2nd ordre

153
La condition de premier ordre est indépendante du niveau de Sinistre quelque soit le profile de risque on obtient : La condition de second ordre est toujours satisfaite pour un agent risquophobe u’’<0. Comme π1<π2, il vient : Le taux de couverture optimal du risque sera plus élevé pour les risques faibles que pour les risques élevés .

154
Plus qu’ailleurs, en asymétrie d’information face à une population hétérogène, l’assurance complète où g =π et impossible. En effet si l’assurance propose un seul contrat g= π1 soit le contrat optimal pour les risques faibles où l’assurance est complète et où l’on se trouve au niveau de la prime actuarielle π1*S= P1 Tous les assurés vont vouloir s’assurer y compris et surtout les risques élevés. Par conséquent l’équilibre financier de l’assurance va être mis en défaut puisque la prime est établie pour le niveau des risques faibles.

155
Selon le principe indemnitaire, on ne peut se trouver dans cette zone.
L’assurance ne peut conduire à un enrichissement du fait de la survenu d’un sinistre Sur la bissectrice on se trouve en assurance complète, avec la prime actuarielle Le point B correspond au contrat optimal pour les bas risques, le point H pour les hauts risques

156
Si l’assurance propose comme seul contrat le point H, les bons risques ne vont pas s’assurer car la prime sera trop élevée on passe en dessus de leur utilité de réservation. Ici l’assurance est optimale, mais l’assurance n’attire qu’une partie du marchés les clients risqués. Une solution moyenne peut-être proposée. Établir un contrat à partir du niveau de risque moyen.

157
Le point A correspond au contrat avec la prime moyenne
Le point A correspond au contrat avec la prime moyenne. Ce contrat n’intéressera pas les risques faibles et seuls les risques élevés vont être recrutés. Ceci illustre le phénomène de sélection adverse, le contrant n’est souscrit que par les mauvais risques. L’équilibre financier n’est donc pas assurer puisque les risques vont apparaître avec une probabilité supérieur à la moyenne. Le menu C et D pourra être proposé. Les risques élevés vont se positionner sur C et les risques faibles sur D.

158
L’assurance doit établir le menu optimal dont les caractéristiques sont les suivantes:
Les agents doivent choisir le contrat qui leur est destiné. Pour cela il faut que le contrat soit doté de contraintes incitatives adéquates. Il faut que chaque souhaite souscrire un contrat d’assurance. L’utilité produit par l’assurance doit placé l’agent au dessus de son utilité de réservation. Il faut définir des contrainte de participation. Lorsque le menu de contrat respects les deux critères précédant il reste à l’assurance à établir le menu qui lui permet de maximiser son profit.

159
Les bas risques vont accepter de s’assurer sur la courbe d’indifférence OB. Au dessus, les hauts risques viendraient également rompant la discrimination du contrat.

160
Annexe statistiques : Pour déterminer concrètement le niveau K nous allons avoir besoins de nous référer à des lois statistiques. L’inégalité de Bienaymé-Tschebicheff, la loi des grands nombres et le théorème de la limite centrale L’inégalité de Bienaymé-Tschebicheff: A partir de l’écart type d’un distribution on peut établir que quelque soit la distribution étudiée, on pourra démontrer qu’on a au minimum 1-1/k² des observations comprises entre la moyenne et plus ou moins k fois l’écart type. Si on prend k =2, la probabilité minimale de trouver 1 – ½²=75 %valeur comprises entre

161
=LOI.NORMALE.INVERSE(0,05;12000;10000)
Pour une loi normale, c’est 95 % de la distribution qui est comprise autour de la moyenne avec plus ou moins 2 écart–type. Issu de l’ouvrage de Vincent Girard, Statistique appliquée à la gestion Pour établir le niveau K de ruine il faut établir la borne inférieure de la distribution. Avec Excel =LOI.NORMALE.INVERSE(0,05;12000;10000)
")
171
Assurance gérée en répartition ou en capitalisation
La répartition : les assurés forment une mutualité. C’est-à-dire que l’ensemble des assurés financent à travers leurs primes les indemnités qui permettront de faire à face à la réalisation des risques individuels. Les cotisations prélevées servent directement au financement des indemnités sans passage par les marchés financiers. Dans le cadre de la retraite, les indemnités (la retraite) mais également les primes (cotisations) sont décidées politiquement par la gestion paritaire : représentants du patronat, des salariés et de l’Etat.
 mais également les primes (cotisations) sont décidées politiquement par la gestion paritaire : représentants du patronat, des salariés et de l’Etat.")
172
La capitalisation: peut-être gérée de manière individuelle ou collective.
Les primes servent à alimenter un fond qui sera placé sur les marchés financiers afin de réaliser des gains en proportion des risques pris. La politique de placement est le plus souvent déléguées mais peut disposer d’un panachage de gestion plus ou moins agressives en fonction du profil de risque des assurés. Historiquement, ce sont les fonds en prestation définies qui étaient dominants aux États-Unis, mais l’arrivée à échéance des retraites qui n’avait pas nécessairement étaient préfinancé par les employeur a conduit nombres de ces dispositifs à la quasi faillite. De plus, les entreprises se sont lestées d’une dette sociale considérable. Pour éviter ces situations, le risque a été reporté sur les salariés à travers les fonds à cotisation définies. Les fonds à cotisations définies établissement le montant des cotisations, le montant des prestations étant largement déterminé par les prix de liquidation des fonds en gestion.

173
La retraite par capitalisation concerne surtout les pays anglo-saxons pour lesquels ces dispositifs représentent une part importante des retraites versées aux salariés. En France, le livre Blanc de Michel Rocard (1991) soulignait les difficultés financières dans lesquelles risquaient d’entrer la retraite française gérées en répartition. Les conclusions tendaient donc à favoriser le développement d’un troisième étage de retraite en capitalisation. A un dispositif général provoquant trop de résistance contre lui a été préférés l’introduction de dispositifs spécifiques et non obligatoires. C’est les lois Fillon de 2003 Qui mettent en place les dispositifs du PERCO, PERCO-I et du PERP.
 soulignait les difficultés financières dans lesquelles risquaient d’entrer la retraite française gérées en répartition. Les conclusions tendaient donc à favoriser le développement d’un troisième étage de retraite en capitalisation. A un dispositif général provoquant trop de résistance contre lui a été préférés l’introduction de dispositifs spécifiques et non obligatoires. C’est les lois Fillon de Qui mettent en place les dispositifs du PERCO, PERCO-I et du PERP.")
174
Les dispositifs en capitalisation sont très intéressants pour les assureurs puisqu’ils devraient conduire à un développement probable de leur chiffre d’affaire. Cependant, ces dispositifs peuvent être rapprochés à de l’assurance vie qui constituait déjà une forme de retraite en capitalisation à la française

175
Le PERCO-I : ordonnance du 23 mars 2006
Plan d’épargne pour la retraite collective – Interentreprises, le plan est financé par de l’intéressement, de la participation aux bénéfices et des versements volontaires. Ces derniers ne doivent pas excéder 25 % du salaire annuel brut, en tenant compte de l’intéressement. Le contrat peut prévoir une sortie en rente viagère ou en capital. Le versement par les salariés de leur participation permet de conserver les avantages fiscaux associés à la participation et l’intéressement qui est imposé est défiscalisé s’il est placé sur le PERCO. Le Perco permet de se constituer un portefeuille de valeurs mobilières constitué par des titres émis par les SICAV et des parts de fonds communs de placement d'entreprise (FCPE). L'entreprise propose un choix entre 3 organismes de placements collectifs au minimum, qui doivent présenter des profils d'investissement différents.
. L entreprise propose un choix entre 3 organismes de placements collectifs au minimum, qui doivent présenter des profils d investissement différents.")
176
Le PERP : décret du 21 avril 2004, arrêté du 22 avril 2004
Plan d’épargne retraite populaire. Il s’agit d’un plan individuel, les sommes ne peuvent être sorties avant la retraite et sont uniquement versées sous forme de rente. Les revenus placés sont défiscalisés. Par contre la rente viagère est soumise à l’impôt. Ce plan est moins souple que le PERCO, car les conditions de sorties sot plus limitées. Le capital constitué est reversé sous forme d'une rente viagère. Il peut également être reversé sous forme de capital, à hauteur de 20 %. Le Perp permet aussi d'utiliser l'épargne accumulée pour financer l'acquisition d'une 1ère résidence principale.

177
Compléments et actualités du secteur de l’assurance

178
Cet article est extrait de Pour le découvrir, cliquez ICI
Les assureurs digéreront plus ou moins bien la nouvelle décote grecque Le montant de leurs provisions dépendra des méthodes appliquées après l'accord du 21 juillet et de la répartition des maturités des titres Cet article est extrait de Pour le découvrir, cliquez ICI Les assureurs européens n’absorberont pas tous avec la même facilité la nouvelle décote sur la dette grecque, mais devraient dans l’ensemble supporter le choc. Leur situation va surtout dépendre de la manière dont ils ont intégré dans leurs comptes l’accord du 21 juillet qui prévoyait une dépréciation de 21% sur les titres arrivant à échéance avant 2020, contre 50% désormais sur l’ensemble des maturités. «Le secteur de l’assurance est globalement moins exposé que le secteur bancaire. L’impact sera différent selon les méthodes adoptées dans les comptes du deuxième trimestre mais après, il faut relativiser par les montants qui sont en jeu», nuance un analyste. Les groupes allemands sont à l’abri puisqu’ Allianz et Munich Re ont provisionné l’intégralité de la moins-value latente enregistrée au bilan, et ce, même pour les titres à échéance postérieure à Et comme à fin juin, la décote sur la Grèce s’élevait à 45%, il ne leur reste que 5% à passer. Axa et Generali ont également déprécié les titres grecs en valeur de marché mais seulement avant Axa paiera un plus lourd tribut que son concurrent italien, les deux tiers de ses titres grecs allant au-delà de 2020, soit 962 millions d’euros à fin juin, selon les données de Raymond James. Mieux loti, Generali n’aura plus qu’à déprécier quelque 800 millions d’euros sur les 3 milliards qu’il détient. Les moins bien positionnés sont les mutualistes qui ont appliqué à la lettre l’accord du 21 juillet comme la Macif et Groupama. La Macif, exposée à hauteur de 55 millions d’euros à la Grèce, a déprécié de 21% les maturités avant Toutefois, outre les 29% supplémentaires à passer, les titres courant après 2020 ne représentent que 2,7 millions d’euros. La situation est plus difficile pour Groupama. Ses titres arrivant à échéance après 2020 représentent 74% des obligations grecques qu’il détient, soit 2,3 milliards d’euros. Il s'agit de montants bruts. Le gros de la charge sera assumé par les assurés, avec des ponctions sur la provision pour participation aux excédents, comme l'avait fait la CNP au deuxième trimestre. Globalement, ces montants seront beaucoup moins élevés que les moins-values latentes enregistrées sur les actions et qui pourront faire l’objet de provisions en fin d’année. A ce titre Axa a indiqué hier qu’il n’envisageait pas de déprécier ses titres BNP Paribas, qui ont perdu plus d’un quart de leur valeur depuis le début de l’année. Par Florent Le Quintrec le 28/10/2011

179
Récapitulatif des sources internet et ouvrages
J-M. Rousseau, T. Blayac et N. Oulmane Introduction à la théorie de l’assurance Edition Dunod Paris 2001 D. Henriet et J-C Rochet Microéconomie de l’assurance Edition Econoica Paris 1991 Pour aller plus loin : M. Cohen et J-M tallon Décision dans le risque et l’incertain: L’apport des modèles non additifs 2000 Arnaud MALAPERT, Gildas JEANTET Coherence dynamique des decisions dans l'incertain 30 janvier

180
http://stockage. univ-brest
francois.pigalle théorie de l’assurance chapitre 5

181
Limite de VNM Le paradoxe de Allais Soient les loteries :
B=L(3 000 €, 0 € ; 1, 0) Soient les loteries : C=L(4 000 €, 0 € ; 0.2, 0.8) D=L(3 000 €, 0 € ; , 0.75)
 Soient les loteries : C=L(4 000 €, 0 € ; 0.2, 0.8) D=L(3 000 €, 0 € ; 0.25, 0.75)")
182
u(3000 €) > 0.8 u(4000 €) 0.2 u(4000 €) > 0.25 u(3000 €) 0.8 u(4000 €) > u(3000 €)
 > 0.8 u(4000 €) 0.2 u(4000 €) > 0.25 u(3000 €) 0.8 u(4000 €) > u(3000 €)")
Présentations similaires


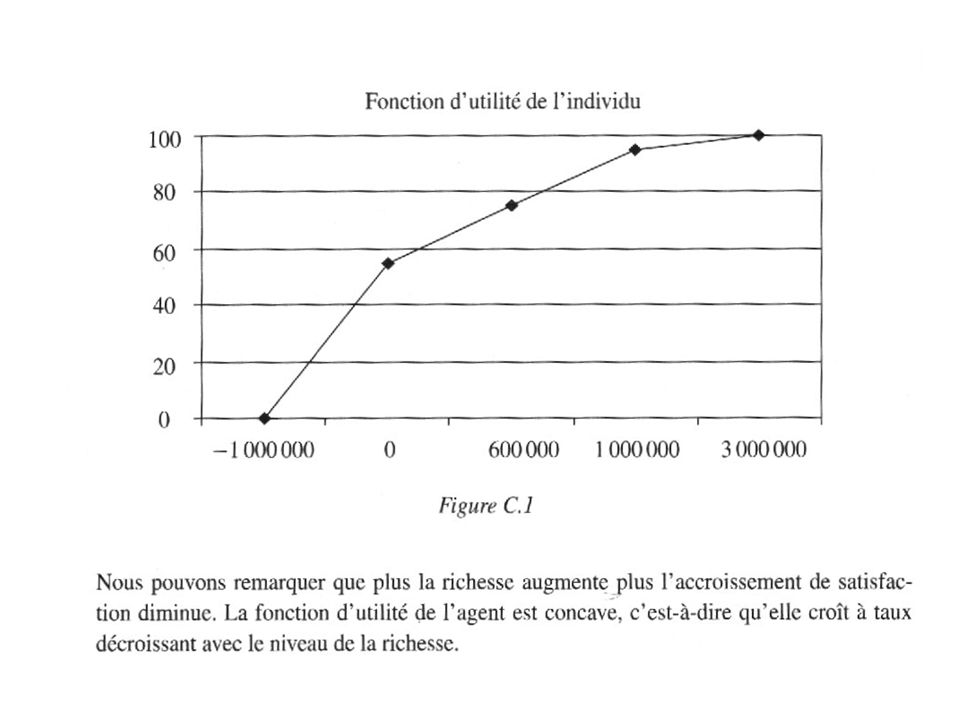

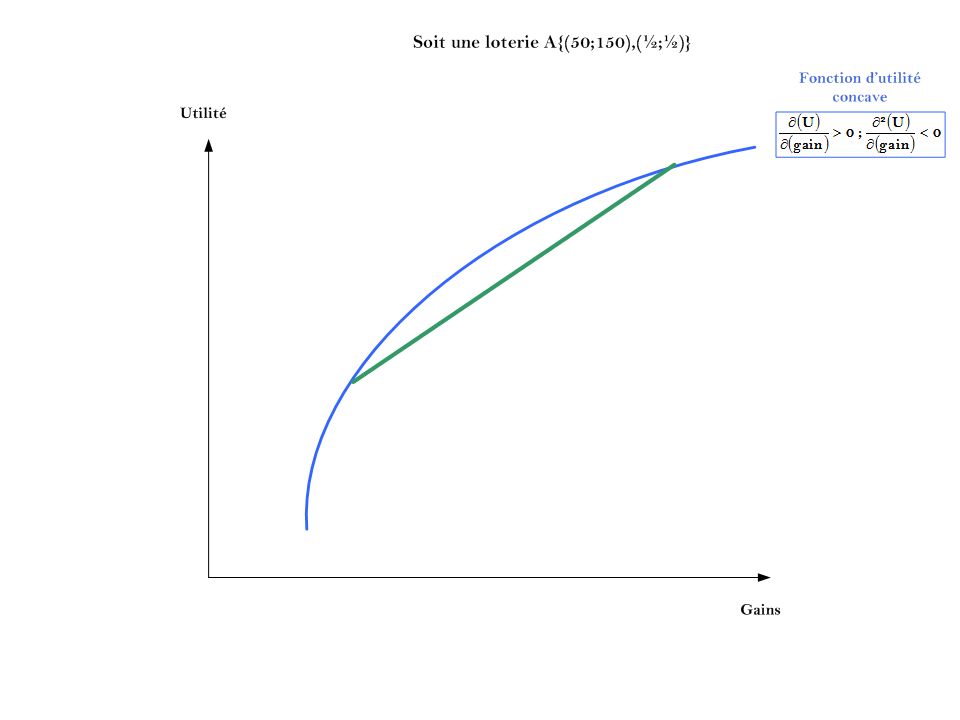
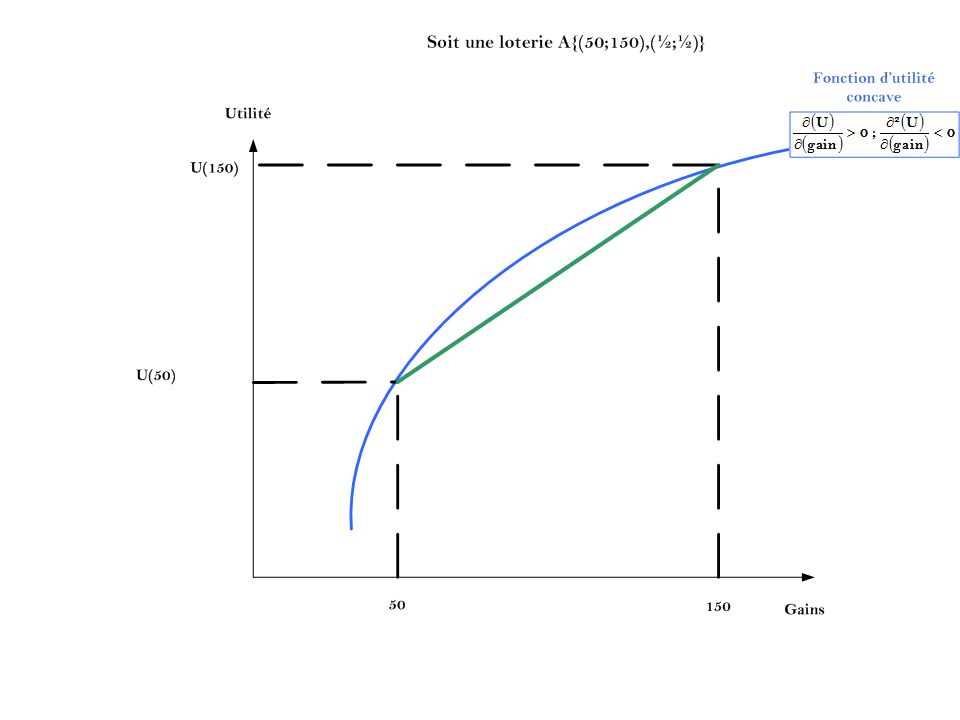
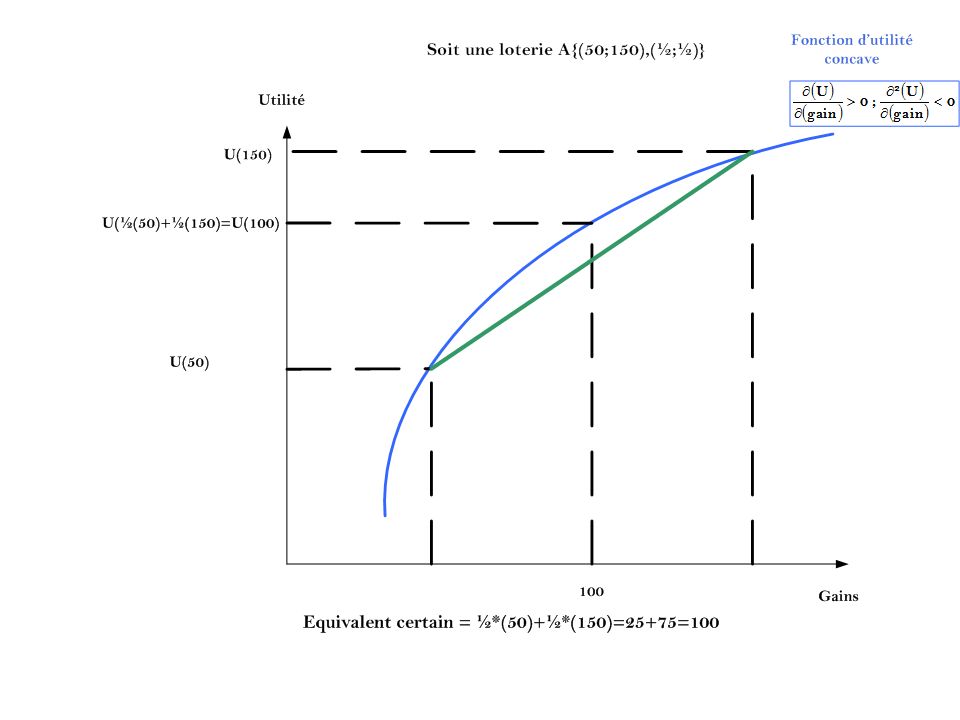























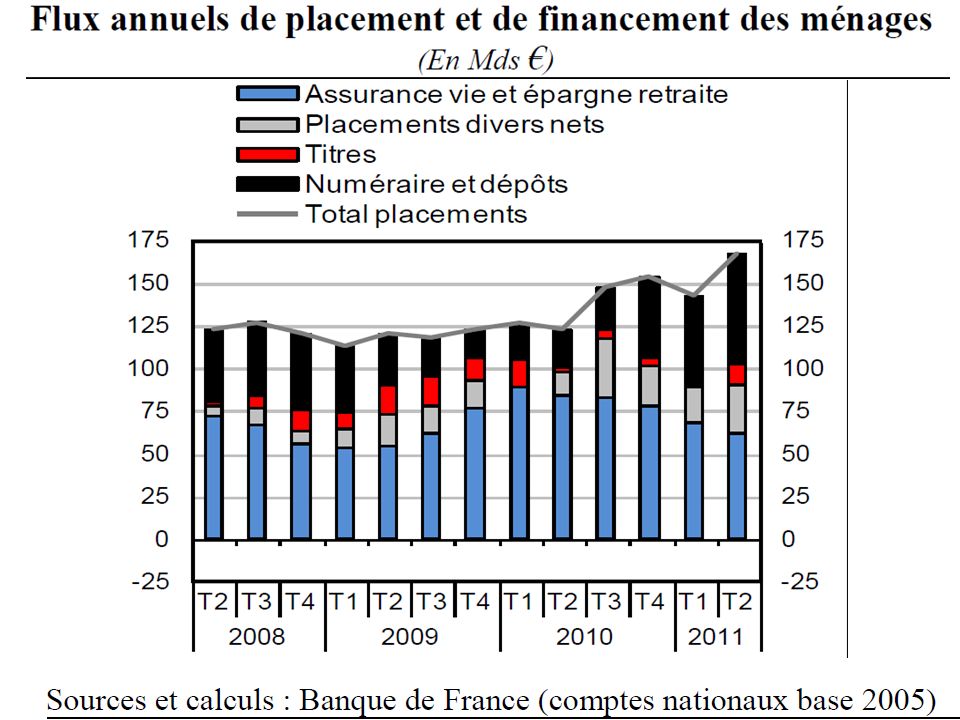
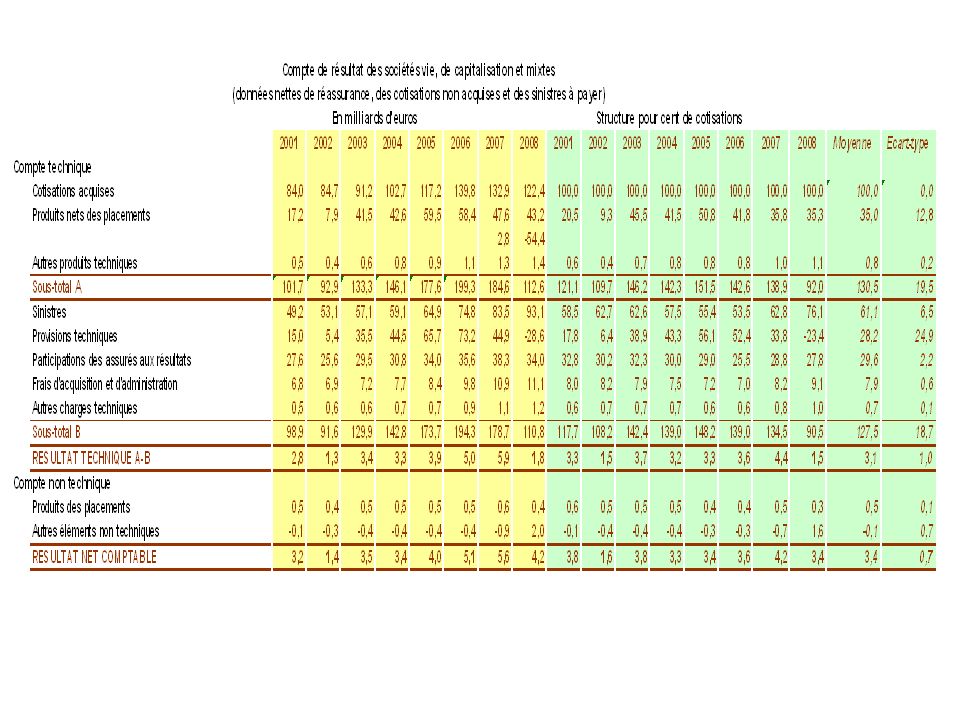
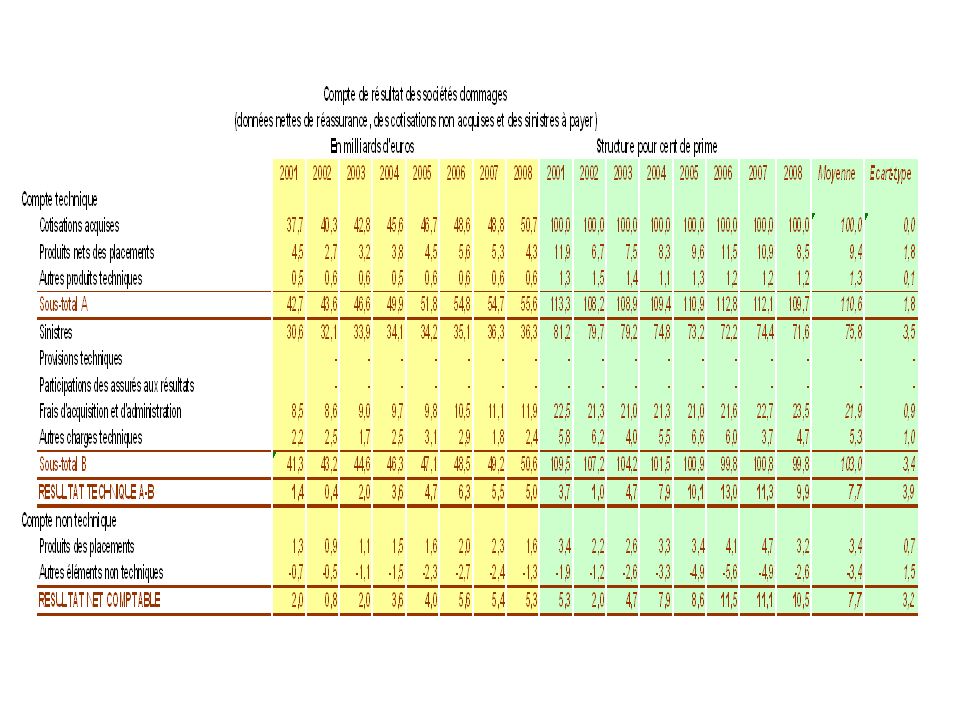
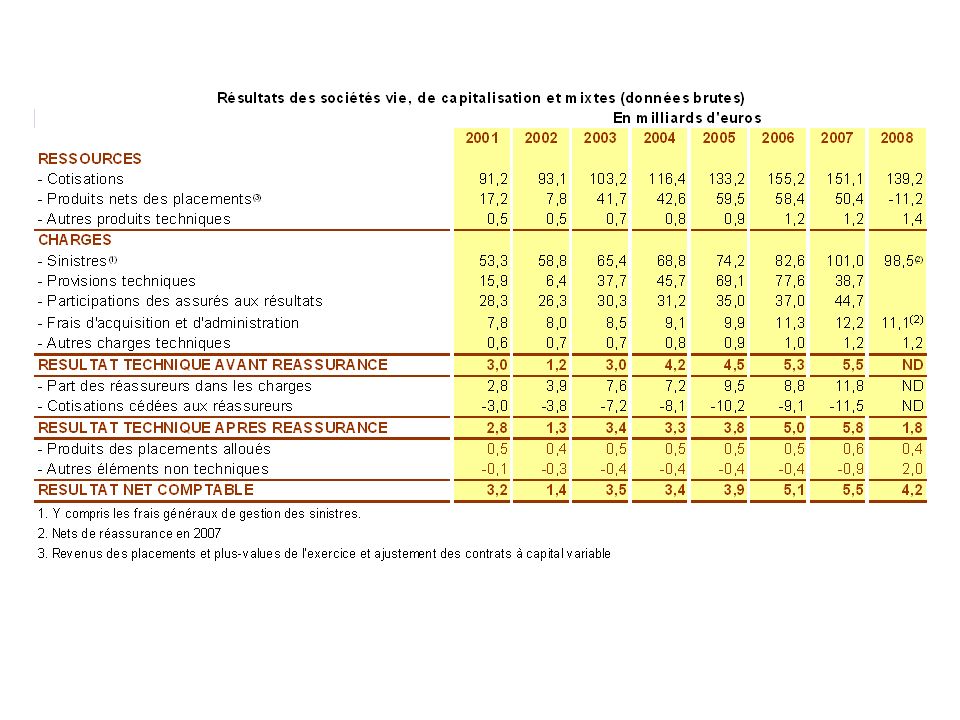
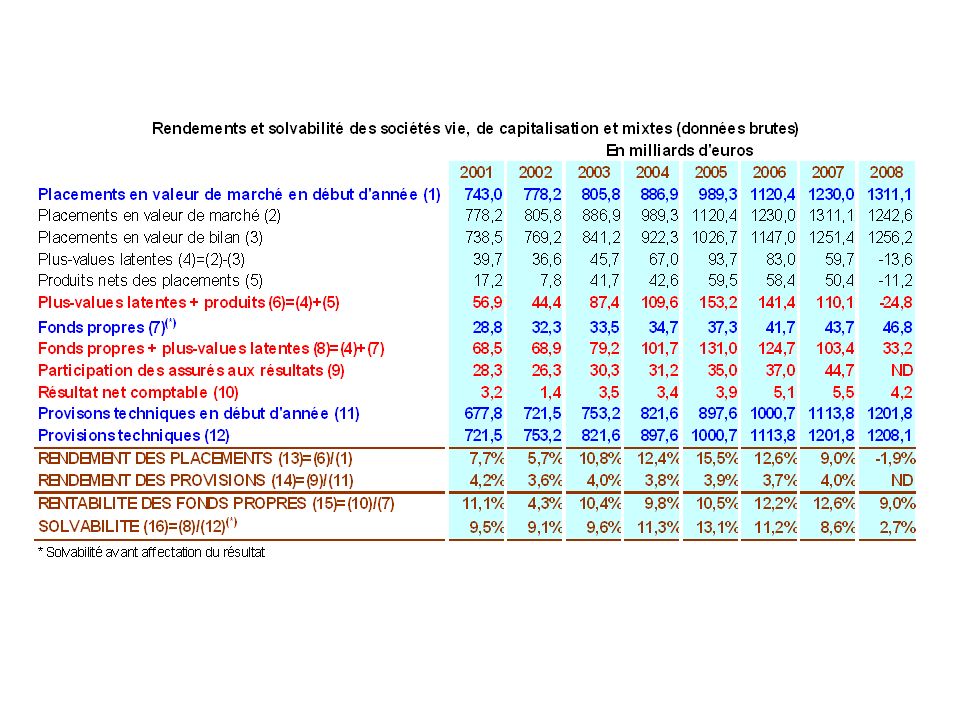
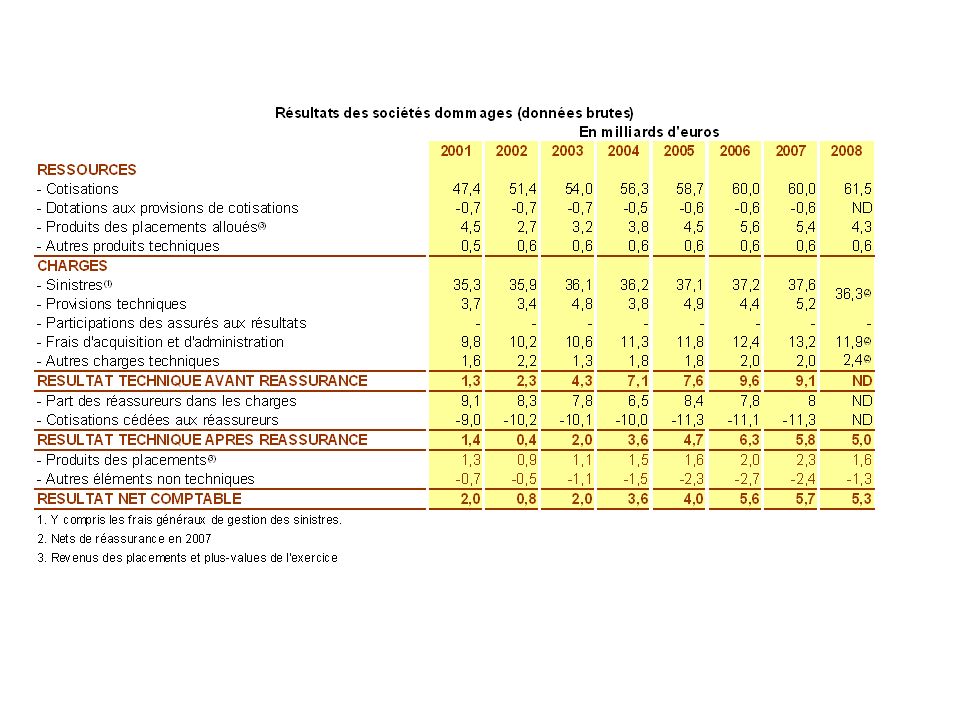
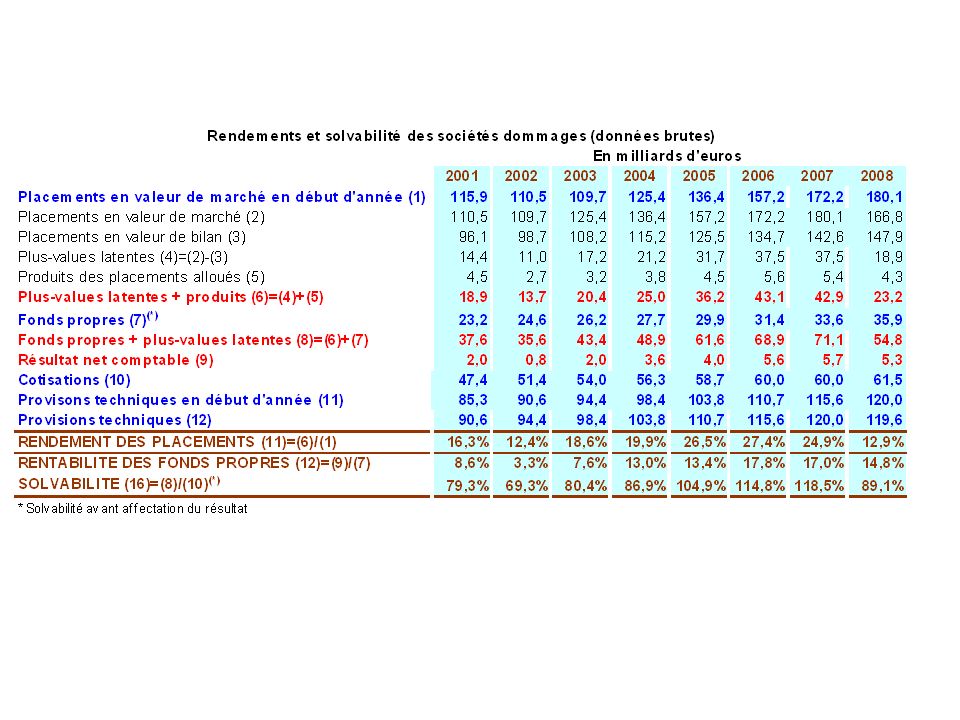
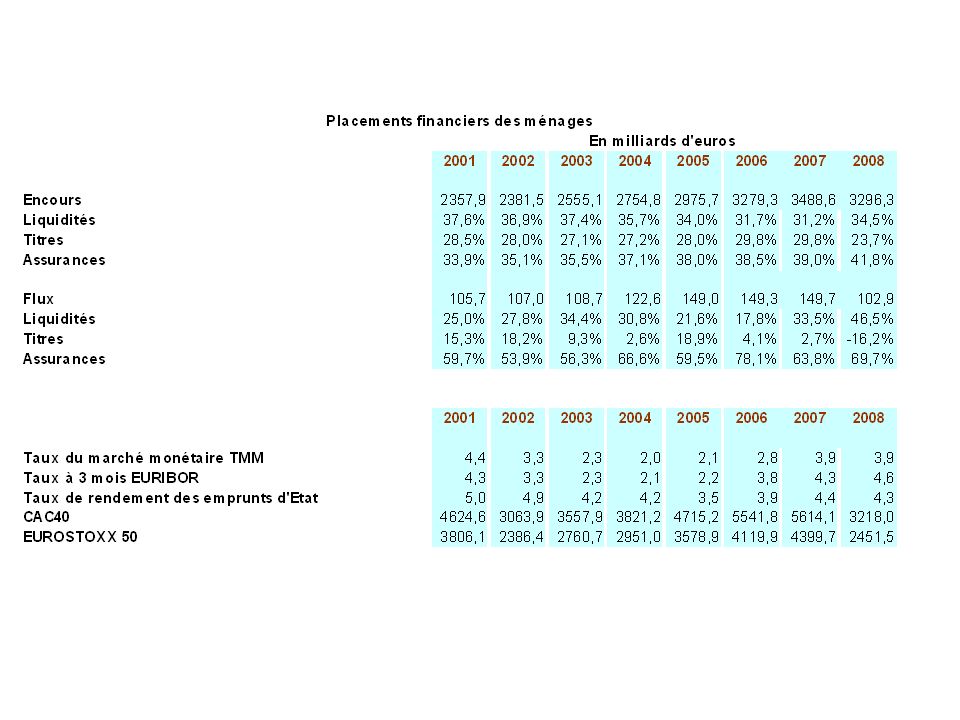

















, de constantes (0, 1), d’opérations (+, ), de relations (=, ) Axiomes : ce sont.>")


