Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Décodage des informations

2
Trois approches pour le décodage des informations
Approche analytique Approche globale Approche statistique Approche connexionniste (réseau de neurones)
")
3
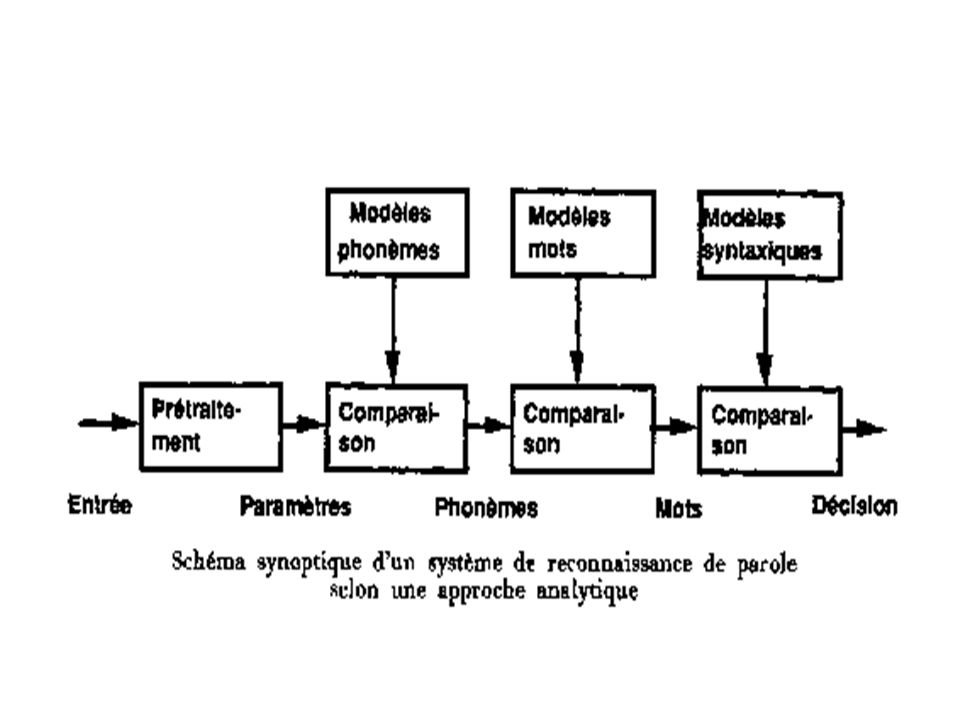
Approche analytique le signal obtenu après l'analyse acoustique est segmenté à partir de différents critères (énergie, stabilité spectrale,...) en unités de taille phonétique comme les phonèmes, ou les syllabes. une identification phonétique des segments est réalisée en comparant les mesures acoustiques à des formes de références, on obtient donc un treillis phonétique. ce décodage obtenu est exploité par un analyseur lexical, qui utilise des connaissances lexicales, émet des hypothèses de mots, suivi d'un analyseur syntaxique qui en utilisant les connaissances syntaxiques détermine la phrase prononcée en cherchant parmi toutes les phrases syntaxiquement correctes, construites à partir des mots détectés, celle qui est la plus vraisemblable. ces systèmes dits à base de connaissances ou d'IA(Intelligence artificielle) tentent de reproduire le raisonnement d'un expert phonéticien. ces systèmes sont restés au stade expérimental et ne sont plus d'actualité.
 en unités de taille phonétique comme les phonèmes, ou les syllabes. une identification phonétique des segments est réalisée en comparant les mesures acoustiques à des formes de références, on obtient donc un treillis phonétique. ce décodage obtenu est exploité par un analyseur lexical, qui utilise des connaissances lexicales, émet des hypothèses de mots, suivi d un analyseur syntaxique qui en utilisant les connaissances syntaxiques détermine la phrase prononcée en cherchant parmi toutes les phrases syntaxiquement correctes, construites à partir des mots détectés, celle qui est la plus vraisemblable. ces systèmes dits à base de connaissances ou d IA(Intelligence artificielle) tentent de reproduire le raisonnement d un expert phonéticien. ces systèmes sont restés au stade expérimental et ne sont plus d actualité.")
5
La comparaison dynamique
Lorsqu’un locuteur, même entraîné, répète plusieurs fois une phrase ou un mot, il ne peut éviter les variations du rythme de prononciation ou de la vitesse d’élocution. Ces variations entraînent des transformations non linéaires dans le temps du signal acoustique. La non-linéarité vient du fait que les transformations affectent plus les parties stables du signal que les phases de transitions. Une méthode pour s’affranchir de ces transformations est de réaliser une normalisation temporelle en même temps que la comparaison des deux mots. On peut utiliser pour cela une technique de comparaison dynamique, ou alignement temporel dynamique (DTW: Dynamic Time Warping) introduit en reconnaissance de la parole par Vintsujk
 introduit en reconnaissance de la parole par Vintsujk.")
6
La comparaison dynamique
Soit les formes A et B, deux images acoustiques (des spectrogrammes dans le cas de la figure suivante, de longueur I et J, à comparer. L’alignement dynamique entre ces deux formes est représenté par le chemin {C(k)=(n(k), m(k)); k=1 à K}, avec C(1)=(1, 1) et C(K)=(I, J).
=(n(k), m(k)); k=1 à K}, avec C(1)=(1, 1) et C(K)=(I, J).")
7
Alignement temporel dynamique
Mot test Mot ref

8
Pour respecter la réalité, il est appliqué des contraintes suivante sur les fonctions n(k) et m(k) afin qu’elles soient croissantes et respectent des conditions de continuité (exprimées par les contraintes). Exemples de contraintes locales.

9
si on retient les contraintes (a) (c'est à dire on peut joindre le point (i, j) soit
à partir du point (i-1, j) à partir de (i-1, j-1) à partir de (i, j-1) ) indiquées précédente nous obtenons la formule récursive suivante : d(i,j) représente la distance entre le spectre de la référence et le spectre du test aux instants i et j D(i,j) représente la distance cumulée et est calculée en respectant les propriétés de monotonie et d'évolution lente du signal étudié. Le coût du chemin optimal est
 à partir de (i-1, j-1) à partir de (i, j-1) ) indiquées précédente. nous obtenons la formule récursive suivante : d(i,j) représente la distance entre le spectre de la référence et le spectre du test aux instants i et j. D(i,j) représente la distance cumulée et est calculée en respectant les propriétés de monotonie et d évolution lente du signal étudié. Le coût du chemin optimal est.")
10
La méthode de la comparaison dynamique consiste à choisir, parmi tous les chemins physiquement possibles, la référence pour laquelle la distance totale D(I,J)/(I+J) est la plus faible et qui représente le chemin le plus court. L'étiquette du mot reconnu peut alors être fournie comme un résultat. Si la distance est trop élevée, en fonction d'un seuil pré-défini, la décision de non reconnaissance du mot est alors prise ; cela permet de rejeter les mots qui n'appartiennent pas au dictionnaire de référence. La ressemblance idéale se traduit donc par une diagonale comme dans la figure de l’alignement temporel.

11
Approche statistique L'approche statistique propose une modélisation plus générale et permet la reconnaissance de plus grands vocabulaires en parole continue de manière efficace en intégrant les niveaux acoustiques et linguistiques dans un seul processus de décision, Ces niveaux sont représentés par des modèles probabilistes à savoir les Modèles de Markov Cachés, Les unités acoustiques modélisées peuvent être des mots, des unités courtes telles que la syllabe, le phonème, le pseudo-diphone

12
Approche statistique Étant données une suite d'observations Y et une suite de mots prononcés M, l'approche statistique consiste à chercher parmi toutes les suites possibles , la suite la plus probable connaissant la suite d'observations Y, soit :

13
Approche statistique D'après la formule de Bayes on a :
P(Y/M) représente la probabilité d'observer la suite Y étant donnée la suite M de mots prononcés, elle est estimée par une modélisation acoustique. P(M) représente la probabilité a priori, liée au langage de l'application, que la suite de mots M soit prononcée. On peut estimer la probabilité de la séquence M, si on a un modèle de langage On peut supposer aussi que les mots ont la même probabilité d'être prononcés.
 représente la probabilité d observer la suite Y étant donnée la suite M de mots prononcés, elle est estimée par une modélisation acoustique. P(M) représente la probabilité a priori, liée au langage de l application, que la suite de mots M soit prononcée. On peut estimer la probabilité de la séquence M, si on a un modèle de langage. On peut supposer aussi que les mots ont la même probabilité d être prononcés.")
14
Puisque P(Y) ne dépend pas de M, l'équation précédente devient :
Au cours des dernières années, les plus grands systèmes de RAP ont été conçus avec une approche statistique markovienne.

16
Modèles de Markov Cachés (MMC) ou (HMM en anglais)
 ou (HMM en anglais)")
17
Modèles de Markov Cachés
Depuis l'introduction en traitement automatique de la parole des Modèles de Markov cachés (Hidden Markov Models ou HMM en anglais), la majorité des systèmes de reconnaissance utilisent ces outils comme base de leurs modélisations.
, la majorité des systèmes de reconnaissance utilisent ces outils comme base de leurs modélisations.")
18
Définition des MMCs Un modèle de Markov caché est un double processus où est une chaîne de Markov d'ordre 1 à valeurs dans un ensemble d'états Q fini de cardinal N, Elle vérifie pour tout instant t>1 et pour toute suite d'états

19
Définition des MMCs pour t=1, on a : pour i =1, ..., N.
Distribution initiale

20
Définition des MMCs L'état du processus n'est pas directement observable - on dit qu'il est "caché" -, mais lors du passage par une observation est émise, une réalisation du processus est un processus observable à valeurs dans un ensemble mesurable Y. Le processus vérifie : . est la probabilité d'émission de l'observation par l'état

21
Les observations sont supposées indépendantes les unes des autres conditionnellement à la suite d'états et chaque observation ne dépend que de l'état courant. Ces observations peuvent être : - discrètes, dans ce cas est une distribution de probabilité discrète définie un ensemble appelé "dictionnaire", - continues, dans ce cas sera une fonction de densité de probabilité continue de

22
Il s'en suit qu'un modèle de Markov caché est caractérisé par :
- l'ensemble fini des états - la matrice des probabilités de transitions de la chaîne -la distribution de probabilité initiale de -la distribution de probabilité associée à chaque état , pour i = 1,......, N. Par convention un MMC sera noté

23
Remarques Les probabilités d'émissions sont parfois notées dans le cas où l'on associe les lois d'observations aux transitions plutôt qu'aux états. Dans ce cas on a : . Les deux approches sont équivalentes, et le choix est guidé par des critères de simplicité de l'écriture des algorithmes.

24
Modèle de Markov à 5 états

25
Vraisemblance d'une suite d'observations
Soient une suite d'observations émises par le modèle précédemment défini et une suite d'états de longueur T définissant un chemin, la vraisemblance de ces observations est calculée comme suit :

26
Vraisemblance d'une suite d'observations
est l'ensemble de tous les chemins de longueur T. En utilisant la règle de Bayes et les équations définies précédemment on obtient après réarrangement :

27
Mise en oeuvre des MMCs L'utilisation des MMCs en reconnaissance des formes s'effectue en trois étapes : définition de la topologie de la chaîne de Markov, ce qui équivaut à construire un graphe dépendant de l'application visée (vocabulaire, syntaxe pour la RAP), apprentissage du modèle : un des grands avantages de l'approche markovienne réside dans l'utilisation d'un apprentissage automatique des paramètres d'un modèle donné quelle que soit la nature des observations (continues ou discrètes) -, ses paramètres sont optimisés de manière à maximiser la probabilité d'émission des observations données, une fois définie la topologie du modèle,
, apprentissage du modèle : un des grands avantages de l approche markovienne réside dans l utilisation d un apprentissage automatique des paramètres d un modèle donné - quelle que soit la nature des observations (continues ou discrètes) -, ses paramètres sont optimisés de manière à maximiser la probabilité d émission des observations données, une fois définie la topologie du modèle,")
28
3. reconnaissance : il s'agit, pour une suite
Mise en oeuvre des MMCs 3. reconnaissance : il s'agit, pour une suite Y= d'observations et un modèle donné de définir : soit la vraisemblance d'une suite d'observations par rapport à un modèle , soit de retrouver le chemin optimal , au sens probabiliste, c'est à dire la suite d'états cachés qui a vraisemblablement généré ces observations, parmi toutes les séquences s d'états possibles, soit :

29
D'après la formule de Bayes on a :
Remarquons que Pr(Y) ne dépend pas de la suite d'états s ; par conséquent la séquence qui donne la meilleure probabilité est celle qui maximise la probabilité conjointe Pr(Y,s) : Pour résoudre les problèmes posés dans ces deux dernières étapes, deux algorithmes ont été développés, - l'algorithme de Baum-Welch pour calculer la vraisemblance d'une suite d'observations, - l'algorithme de Viterbi pour le calcul du chemin optimal.
 ne dépend pas de la suite d états s ; par conséquent la séquence qui donne la meilleure probabilité est celle qui maximise la probabilité conjointe Pr(Y,s) : Pour résoudre les problèmes posés dans ces deux dernières étapes, deux algorithmes ont été développés, - l algorithme de Baum-Welch pour calculer la vraisemblance d une suite d observations, - l algorithme de Viterbi pour le calcul du chemin optimal.")
30
Algorithme de Baum-Welch "avant-arrière"
Soient une suite d'observations et soit un modèle donné, on définit deux variables et - La variable avant (forward en anglais) représente la probabilité d'observer les t premières observations et d'aboutir dans l'état au temps t. - La variable arrière (backward en anglais) représente la probabilité d'observer les t+1 dernières observations sachant que l'on part de l'état au temps t
 représente la probabilité d observer les t premières observations et d aboutir dans l état au temps t. - La variable arrière (backward en anglais) représente la probabilité d observer les t+1 dernières observations sachant que l on part de l état au temps t.")
31
Les variables forward et backward sont initialisées, pour tous les états par :
La règle de Bayes permet un calcul récursif de ces deux variables : pour t=2,...,T et pour t=T-1,T-2,..,1et

32
la vraisemblance de la suite d'observations par rapport au modèle

33
Algorithme de Viterbi l'algorithme de Viterbi est utilisé pour la recherche du meilleur chemin, dans un graphe, ayant généré une suite d'observations selon un modèle Il permet une réduction importante des calculs Le chemin optimal recherché est défini par :

34
Détermination du chemin optimal
Soit la variable le maximum, sur tous les chemins partiels possibles de longueur t et aboutissant à l'état des probabilités d'émission des t premières observations la probabilité d'émission le long du chemin optimal recherché La règle de Bayes nous donne la formule récurrente suivante pour t =1,...,T et pour j=1,...,N .

35
Détermination du chemin optimal
Pour déterminer le chemin optimal, on utilise une variable supplémentaire pour mémoriser, à chaque itération l'état correspondant au maximum : l'état final du chemin optimal la variable permet de retrouver les états précédents par une récurrence arrière : ….. …

36
Sélection d'un chemin dans le treillis entre les instants t - 1 et t
t t

37
Procédure d'apprentissage

Présentations similaires


>")

















