Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
La Régression Multiple
Ursula Hess UQAM

2
Définitions Corrélation bivariée: Relation entre deux variables continues sans distinction entre VI et VD Régression bivariée: Prédiction d ’une variable dépendante à partir d ’une variable indépendante Corrélation multiple: Relation entre une variable dépendante et une série des variables indépendantes qui sont combinées afin de créer une variable composite Régression multiple: Prédiction d’une variable dépendante à partir d ’une série des variables indépendantes Régression hiérarchique: Le chercheur assigne des priorités aux variables indépendantes Corrélation canonique: La relation entre une série des variables dépendantes et une série de variables indépendantes

3
Questions de recherche
Prédiction Modèle théorique L’importance relative des différentes VIs Ajout d’une variable -> amélioration du modèle? Comparaison de différents modèles théoriques Analyse de chemins causaux

4
Introduction Régression multiple: une extension de la régression simple; la prédiction d’une variable dépendante à partir de plusieurs variables indépendantes continues Modèle de régression multiple: Y = 0 + 1X1 + 2X2 + e

5
Plan La relation entre deux variables Les moindres carrés
La régression Les commandes SPSS “Goodness of fit”

6
La relation entre deux variables

7
Les moindres carrés Nous visons à ajuster une droite: Y’ = a + bX
avec une pente b de façon à minimiser d = Y - Y’ ou bien d2 = (Y-Y’)2
2.")
8
Les moindres carrés La pente qui correspond à ces exigences:
Déf.: La pente b = la variation de Y qui accompagne la variation d’une unité de X

9
Corrélation et régression

10
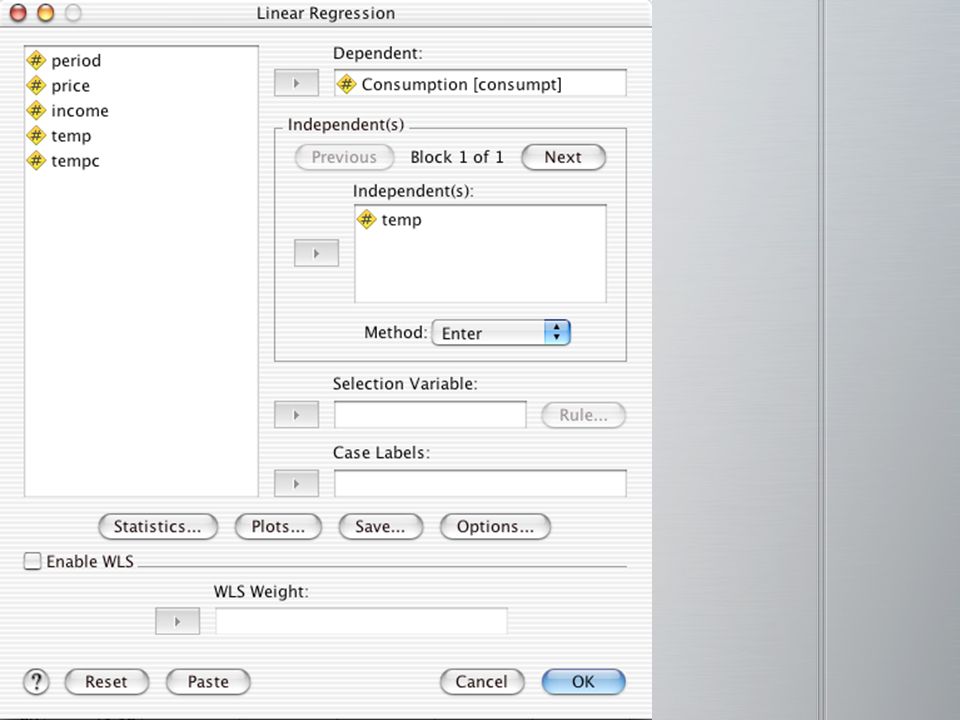
SPSS: Régression simple

12
Output

13
Interpretation des résultats
Prédiction Consommation crème glacée (pinte/personne) = * Température (F) Explication: pour chaque degré F de chaleur la personne mangera .003 pintes de crème glacée de plus pour chaque augmentation d’une unité d’écart-type de température la personne augmente sa consommation de crème glacée de .776 unités d’écart-type
 = * Température (F) Explication: pour chaque degré F de chaleur la personne mangera .003 pintes de crème glacée de plus. pour chaque augmentation d’une unité d’écart-type de température la personne augmente sa consommation de crème glacée de .776 unités d’écart-type.")
14
Consommation et temperature F
Y = * Temperature (F)
")
15
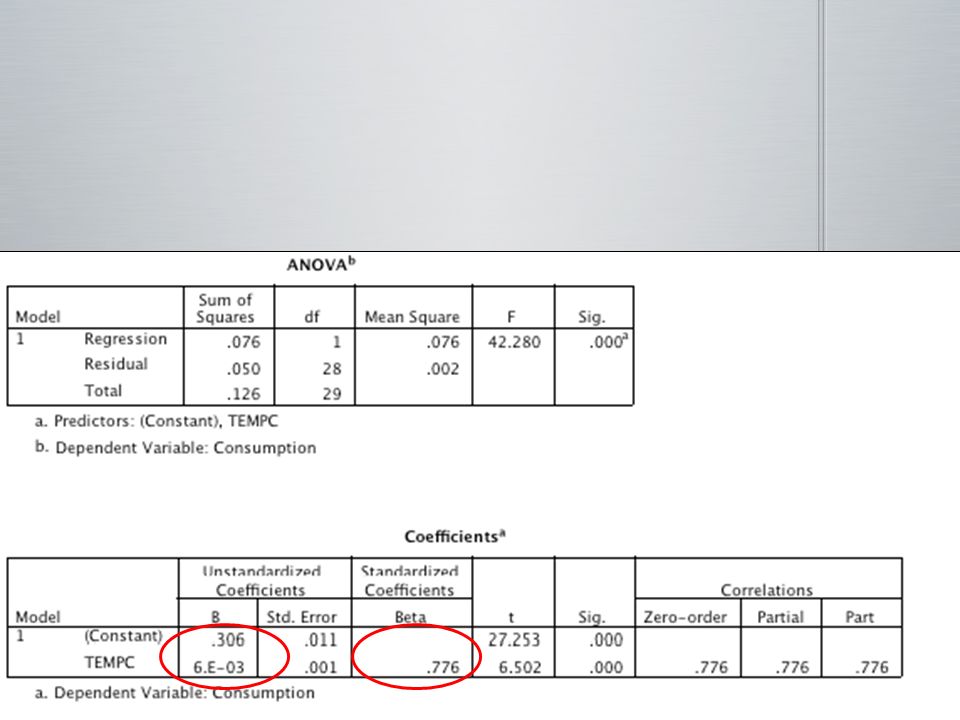
Consommation et temperature C
Y = * Temperature (C) Explication: pour chaque dégré C de chaleur la personne mangera .006 pints de crème glacée de plus pour chaque augmentation d’une unité d’écart-type de temperature la personne augmente sa comsommation de crème glacée .776 unités d’écart-type
 Explication: pour chaque dégré C de chaleur la personne mangera .006 pints de crème glacée de plus. pour chaque augmentation d’une unité d’écart-type de temperature la personne augmente sa comsommation de crème glacée .776 unités d’écart-type.")
17
Régression simple: Tests des hypothèses
L’intervalle de confiance à 95% de la pente = b ± t.025 SE Test - t avec l’hypothèse nulle: b = 0 t = b/SE Intervalle de prédiction à 95% pour une seule valeur Y0 correspondant au niveau X0

18
La Régression simple Modèle: Y = + X + e Postulats de base
e: erreurs indépendantes avec une moyenne de 0 et une variance de 2 Postulats de base Homogénéité de la variance Linéarité Indépendance des observations

20
Goodness of fit

21
Goodness of fit (suite)
")
22
(a) (b) e e Y’ (c) Y’ e (a) patron de distribution “normale” (b) problème d’hétèrogénéitée de la variance (c) nonlinéarité Y’
 nonlinéarité. Y’")
23
La régression multiple
Sources de variation (Yi-Y.)2 (Somme des carrés totaux; df = n-1) (Yi- Y’i)2 (Somme des carrés résiduels; df = n-k-1) (Y’i-Y.)2 (Somme des carrés régression; df = k) R 2 = somme des carrés régression/somme des carrés totaux. F = (R2/k) / ((1-R2)/(n-k-1)) avec k et n-k-1 df
2 (Somme des carrés totaux; df = n-1) (Yi- Y’i)2 (Somme des carrés résiduels; df = n-k-1) (Y’i-Y.)2 (Somme des carrés régression; df = k) R 2 = somme des carrés régression/somme des carrés totaux. F = (R2/k) / ((1-R2)/(n-k-1)) avec k et n-k-1 df.")
24
Considérations pratiques
Nombre de cas en relation avec le nombre de VIs Quand le nombre de VIs est égal ou supérieur au nombre de cas, la solution explique toujours toute la variance. Afin que la solution des équations soit théoriquement significative, un rapport de 20 pour 1 est généralement recommandé. Pour une régression hiérarchique, le minimum acceptable est un rapport de 5 pour 1. Pour une régression « stepwise » permettant une généralisation de la solution, un ratio de 40 pour 1 est recommandé.

25
Considérations pratiques
Cas extrêmes (outliers): Les corrélations sont très susceptibles à l’influence des cas extrêmes, il faut donc vérifier les données attentivement
: Les corrélations sont très susceptibles à l’influence des cas extrêmes, il faut donc vérifier les données attentivement.")
26
Types de régressions multiples
Régression ordinaire Chacune des variables fait partie de l ’équation. Chaque variable est évaluée comme si elle s ’ajoutait à toutes les autres. C’est-à-dire pour chaque variable, seulement sa contribution unique est évaluée. Il est donc possible qu’une variable soit hautement corrélée avec la VD mais que sa contribution semble négligeable car elle est partagée avec d’autres variables.

27
Régression hiérarchique
Les variables sont inclus dans l ’équation dans un ordre prédéterminé par le chercheur. Dans ce cas, les variables qui entrent en premier «prennent» toute la variance disponible pour elles et celles qui entrent plus tard ne disposent que de la variance non-expliquée au moment de leur entrée.

28
Régression «stepwise»
L’ordre d’entrée des variables n’est pas décidé par des raisons théoriques, mais uniquement par des raisons statistiques. A chaque point, la variable qui a la meilleure corrélation avec la VD est ajoutée. Chaque variable prend toute la variance disponible pour elle au moment de son entrée. Cette procédure fournit des résultats potentiellement peu généralisable (capitalise sur la chance).
.")
29
SPSS

30
SPSS analyses séquentielles

31
SPSS (resultats) B1 = variation de Y consécutive à une variation d’une unité de X1, les autres facteurs de régression restent constants. Ex: Toutes les autres choses étant égales, la consommation augmente de .003 pintes par $ de salaire familiale hebdomadaire

32
Présentation des données (Tabachnick et Fiedel)
")
33
Présentation des données: APA

34
APA suite

35
Analyses séquentielles

36
Hypothèses de base Toutes les variables étaient mesurées au niveau intervalle et sans erreur -> Problème d'erreur de mesure La moyenne du terme d'erreur est zéro pour chaque ensemble de valeurs pour les k variables indépendantes La variance est constante pour chaque ensemble de valeurs pour les k variables indépendantes -> Problème de hétérocédasticité Pour chaque paire d'ensembles de valeurs pour les k variables indépendantes les termes d'erreur ne sont pas corrélés, COV(ei, ei)= 0. => il n'y a pas d'auto-corrélation Pour chaque variables indépendantse la COV(Xi, e) = 0. C-à-d, les variables indépendantes ne sont pas corrélées avec le terme d'erreur -> Problème de spécification du modèle Il n'y a pas colinéarité parfaite. C-à-d, il n'y a pas une variable indépendante qui soit parfaitement linéairement liée à une ou plusieurs autres variables indépendantes -> Problème de multicolinéarité Pour chaque ensemble de valeurs pour les k variables indépendantes, ei est distribuée normalement
= 0. => il n y a pas d auto-corrélation. Pour chaque variables indépendantse la COV(Xi, e) = 0. C-à-d, les variables indépendantes ne sont pas corrélées avec le terme d erreur. -> Problème de spécification du modèle. Il n y a pas colinéarité parfaite. C-à-d, il n y a pas une variable indépendante qui soit parfaitement linéairement liée à une ou plusieurs autres variables indépendantes. -> Problème de multicolinéarité. Pour chaque ensemble de valeurs pour les k variables indépendantes, ei est distribuée normalement.")
Présentations similaires

 r =>")


















