Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Eléments de statistique et de visualisations pour l’analyse textuelle
Jean-Marie Viprey Maison des Sciences de l’Homme de Franche-Comté UMR Bases Corpus Langages CNRS-Nice

2
Généralités

3
La statistique a pour objet de caractériser des ensembles (« populations ») en regroupant les individus qui les constituent selon les attributs ou propriétés qu’ils ont ou non en commun. Posséder un même attribut, pour N individus, c’est relever d’une même classe. Pour le démographe statisticien, le genre sexuel est une classe (de même la CSP, la tranche d’âge…). Pour l’économiste statisticien, le chiffre d’affaire des entreprises, le PNB des états, le revenu d’un ménage détermine (par seuils) des classes statistiques.
. Pour l’économiste statisticien, le chiffre d’affaire des entreprises, le PNB des états, le revenu d’un ménage détermine (par seuils) des classes statistiques.")
4
La taille est arrondie au centimètre, ou de 5 en 5 cm…
Que la propriété soit qualitative (sexe, CSP, lieu d’implantation) ou quantitative (taille, âge, PNB), elle doit le plus souvent être discrétisée pour donner prise à la statistique. Ainsi : Le lieu n’est pas un point GPS, mais une commune, un département, un état… La taille est arrondie au centimètre, ou de 5 en 5 cm… L’âge est arrondi au mois, à l’an, de 5 en 5, de 10 en 10, ou par tranches inégales… *** Le genre sexuel est une donnée binaire, non discrétisable. ***
 ou quantitative (taille, âge, PNB), elle doit le plus souvent être discrétisée pour donner prise à la statistique. Ainsi : Le lieu n’est pas un point GPS, mais une commune, un département, un état… La taille est arrondie au centimètre, ou de 5 en 5 cm… L’âge est arrondi au mois, à l’an, de 5 en 5, de 10 en 10, ou par tranches inégales… *** Le genre sexuel est une donnée binaire, non discrétisable. ***")
5
Exemple d’un « mot » dans un « texte » :
« chanté » propriétés qualitatives : séquence des lettres c-h-a-n-t-é entièrement en bas de casse forme verbale forme fléchie du verbe chanter participe passé sa fonte et son corps 4ème mot du premier vers…

6
Exemple d’un « mot » dans un « texte » :
« chanté » propriétés quantitatives : comporte 6 lettres Comporte 4 phonèmes, 2 syllabes Comporte 4 consonnes graphiques Comporte 2 consonnes phonétiques Comporte 2 voyelles graphiques…

7
Exemple d’un « mot » dans un « texte » :
« chanté » « autres » propriétés qualitatives : « champ sémantique » de la musique « domaine » du show-business ? métaphore !

8
Un « texte », au sens restreint d’énoncé écrit, est formé d’unités successives délimitées conventionnellement (lettres, mots, phrases, paragraphes, chapitres…) Si l’on considère ces unités, ou segments, comme les individus d’une population, comportant des attributs susceptibles de les associer à des classes, dès lors le texte est un objet statistique.

9
La statistique a pour intérêt de permettre la connaissance synthétique d’objets complexes, très complexes, voire infiniment complexes. Un ensemble discursif et ses matérialités textuelles (corpus) deviennent rapidement aussi complexes que la population ou l’économie d’un état ou du monde. Quelques applications statistiques relativement simples permettent de prendre connaissance de structures et de contrastes grossiers et simplifiés, mais surplombants, étayés et reproductibles, afin de les confronter à une expérience empirique subtile et diverse, mais « au ras du sol », labile et contradictoire.
 deviennent rapidement aussi complexes que la population ou l’économie d’un état ou du monde. Quelques applications statistiques relativement simples permettent de prendre connaissance de structures et de contrastes grossiers et simplifiés, mais surplombants, étayés et reproductibles, afin de les confronter à une expérience empirique subtile et diverse, mais « au ras du sol », labile et contradictoire.")
10
APPLICATION : Un corpus de 692 articles de presse « vernaculaire » constitué dans le cadre d’une enquête commanditée par la Préfecture de Région Franche-Comté Après une segmentation conventionnelle, on dénombre « individus », « segments » ou « mots » (à l’exception des ponctuations). On désigne cette « population » par la lettre N. Si l’on prend en compte le caractère qualitatif : Chaîne de caractères indépendamment de la casse, et de toute mise en forme de caractères, on détermine « classes », dont les plus fréquentes sont : (On désigne ce nombre de classes par la lettre V.)
. On désigne cette « population » par la lettre N. Si l’on prend en compte le caractère qualitatif : Chaîne de caractères indépendamment de la casse, et de toute mise en forme de caractères, on détermine « classes », dont les plus fréquentes sont : (On désigne ce nombre de classes par la lettre V.)")
11
de 18231 a 1972 la 11204 sur 1906 l' 8511 il 1886 et 8336 nous 1860 le 7488 pas 1765 les 7329 ce 1623 à 6757 plus 1605 des 6719 ne 1339 d' 5515 avec 1276 en 5017 aux 1252 du 4066 europe 1200 pour 3577 se 1166 une 3480 s' 1159 un 3419 qu' 1151 que 2752 sont 1124 est 2728 n' 1080 dans 2665 cette 967 qui 2550 ont 929 au 2164 européenne 890 par 2083 c'est 886 Et parmi lesquelles une majorité (13 919) n’ont qu’une occurrence (« hapax »).
 n’ont qu’une occurrence (« hapax »).")
12
Si l’on rapporte le nombre d’occurrences (effectif) de chaque classe à N ( ), on établit sa fréquence. de 18231 5,4219% a 1972 0,5865% la 11204 3,3321% sur 1906 0,5668% l' 8511 2,5312% il 1886 0,5609% et 8336 2,4791% nous 1860 0,5532% le 7488 2,2269% pas 1765 0,5249% les 7329 2,1797% ce 1623 0,4827% à 6757 2,0095% plus 1605 0,4773% des 6719 1,9982% ne 1339 0,3982% d' 5515 1,6402% avec 1276 0,3795% en 5017 1,4921% aux 1252 0,3723% du 4066 1,2092% europe 1200 0,3569% pour 3577 1,0638% se 1166 0,3468% une 3480 1,0350% s' 1159 0,3447% un 3419 1,0168% qu' 1151 0,3423% que 2752 0,8184% sont 1124 0,3343% est 2728 0,8113% n' 1080 0,3212% dans 2665 0,7926% cette 967 0,2876% qui 2550 0,7584% ont 929 0,2763% au 2164 0,6436% européenne 890 0,2647% par 2083 0,6195% c'est 886 0,2635%

13
Il est plus aisé de comparer des fréquences que des effectifs.
2ème APPLICATION : Un corpus de 252 numéros du mensuel Le Monde diplomatique de 1980 à 2000. Après une segmentation suivant les mêmes normes que pour le corpus « SGAR », et sur la base du même caractère qualitatif : N = V =

14
NB : on peut déjà comparer les « rangs »…
Monde diplomatique SGAR de 955371 18231 la 579160 11204 l' 466407 8511 les 408350 et 8336 392779 le 7488 385327 7329 des 357728 à 6757 343633 6719 d' 297294 5515 en 267353 5017 du 220847 4066 un 190264 pour 3577 une 186261 3480 dans 155703 3419 que 153648 2752 qui 141006 est 2728 130662 2665 par 122728 2550 119622 au 2164 a 114916 2083 NB : on peut déjà comparer les « rangs »…

15
La comparaison la plus immédiatement « parlante » est celle des fréquences.
Monde diplomatique SGAR de 955371 5,41% 18231 5,42% la 579160 3,28% 11204 3,33% l' 466407 2,64% 8511 2,53% les 408350 2,31% et 8336 2,48% 392779 2,22% le 7488 2,23% 385327 2,18% 7329 des 357728 2,03% à 6757 2,01% 343633 1,95% 6719 2,00% d' 297294 1,68% 5515 1,64% en 267353 1,51% 5017 1,49% du 220847 1,25% 4066 1,21% un 190264 1,08% pour 3577 1,06% une 186261 1,05% 3480 1,03% dans 155703 0,88% 3419 1,02% que 153648 0,87% 2752 0,82% qui 141006 0,80% est 2728 0,81% 130662 0,74% 2665 0,79% par 122728 0,69% 2550 0,76% 119622 0,68% au 2164 0,64% a 114916 0,65% 2083 0,62%

16
La comparaison la plus immédiatement « parlante » est celle des fréquences.
Monde diplomatique SGAR de 955371 5,41% 18231 5,42% la 579160 3,28% 11204 3,33% l' 466407 2,64% 8511 2,53% les 408350 2,31% et 8336 2,48% 392779 2,22% le 7488 2,23% 385327 2,18% 7329 des 357728 2,03% à 6757 2,01% 343633 1,95% 6719 2,00% d' 297294 1,68% 5515 1,64% en 267353 1,51% 5017 1,49% du 220847 1,25% 4066 1,21% un 190264 1,08% pour 3577 1,06% une 186261 1,05% 3480 1,03% dans 155703 0,88% 3419 1,02% que 153648 0,87% 2752 0,82% qui 141006 0,80% est 2728 0,81% 130662 0,74% 2665 0,79% par 122728 0,69% 2550 0,76% 119622 0,68% au 2164 0,64% a 114916 0,65% 2083 0,62%

17
RAPPORT DE V ET DE N. Souvent défini comme indice de « richesse » lexicale (parfois mieux dit : « variété » Comparaison difficile. L’accroissement de V (l’emploi de formes non encore utilisées) diminue au fur et à mesure du développement du texte (et donc, de l’accroissement de N). Le rapport n’est en aucun cas proportionnel. De nombreuses formules d’indices ont été proposée, sans qu’aucune parvienne à maîtriser les grandes variations de V. On en est réduit à recenser des échantillons du corpus le plus étendu.
 diminue au fur et à mesure du développement du texte (et donc, de l’accroissement de N). Le rapport n’est en aucun cas proportionnel. De nombreuses formules d’indices ont été proposée, sans qu’aucune parvienne à maîtriser les grandes variations de V. On en est réduit à recenser des échantillons du corpus le plus étendu.")
18
RAPPORT DE V ET DE N. En l’occurrence, si l’on prend plusieurs tranches de mots extraites du Monde diplomatique, on obtient un résultat « V » toujours supérieur au V de SGAR. Exemples : SGAR N = V = Mondiplo1 N = V = (1980) Mondiplo2 N = V = (1986) Mondiplo3 N = V = (1998) Mais Le Vicomte de Bragelonne, de Dumas père : N = V = !
 Mondiplo2 N = V = (1986) Mondiplo3 N = V = (1998) Mais Le Vicomte de Bragelonne, de Dumas père : N = V = !")
19
RAPPORT DE V ET DE N. Quelles conclusions (ne pas) en tirer ? Certains linguistes ont considéré qu’il s’agissait d’un indice d’étendue du lexique sous-jacent. Le terme de « richesse » va dans le sens d’un jugement de valeur et a minima d’un jugement stylistique. En réalité, le rapport de V à N renvoie à plusieurs facteurs que seules des analyses plus poussées peuvent espérer discriminer.

20
LOI DE ZIPF Liée aux théories de l’information (Shannon, Mandelbrot), c’est une loi statistique applicable aux dépouillements lexique-fréquence dans les langues naturelles. Rang décroissant et effectif sont liés : grosso modo, le produit d’un rang par l’effectif correspondant à ce rang est constant. (plus exactement : où f est l’effectif et K une constante) La relation des logarithmes du rang et de l’effectif correspondant donne lieu à un nuage de points typiquements alignés.
, c’est une loi statistique applicable aux dépouillements lexique-fréquence dans les langues naturelles. Rang décroissant et effectif sont liés : grosso modo, le produit d’un rang par l’effectif correspondant à ce rang est constant. (plus exactement : où f est l’effectif et K une constante) La relation des logarithmes du rang et de l’effectif correspondant donne lieu à un nuage de points typiquements alignés.")
21
LOI DE ZIPF Vocabulaire de SGAR en formes graphiques ramenées au bas de casse - abscisse log(rang), ordonnée log(effectif) -
, ordonnée log(effectif) -")
22
LOI DE ZIPF Vocabulaire de Mondiplo en formes graphiques ramenées au bas de casse - abscisse log(rang), ordonnée log(effectif) -
, ordonnée log(effectif) -")
23
LOI DE ZIPF Vocabulaire de La Comédie humaine en formes graphiques ramenées au bas de casse - abscisse log(rang), ordonnée log(effectif) -
, ordonnée log(effectif) -")
24
LOI DE ZIPF Vocabulaire d’ Illusions perdues en formes graphiques ramenées au bas de casse - abscisse log(rang), ordonnée log(effectif) -
, ordonnée log(effectif) -")
25
LOI DE ZIPF Vocabulaire du Vicomte de Bragelonne en formes graphiques ramenées au bas de casse - abscisse log(rang), ordonnée log(effectif) -
, ordonnée log(effectif) -")
26
MD GAMMES DE FREQUENCES SGAR TOTAL (N= 17 662 550 V=182 190)
10 ANS (N= V= ) MD 6 MOIS (N= V=28 085) 2 ANS (N= V=55 663) SGAR
 MD. 6 MOIS (N= V=28 085) 2 ANS (N= V=55 663) SGAR.")
27
BALZAC GAMMES DE FREQUENCES DUMAS
COMEDIE HUMAINE (N= V=66 108) ILLUSIONS (N= V=18 287) BALZAC DUMAS BRAGELONNE (N= V=25 417)
 ILLUSIONS (N= V=18 287) BALZAC. DUMAS. BRAGELONNE (N= V=25 417)")
28
2. Probabilités

29
La majorité des tests statistiques employés dans l’étude des textes sont de nature probabiliste.
La probabilité affectée à un événement dans un cadre spatio-temporel défini est un quotient : Le dénominateur est le nombre total de configurations envisageables de tous les facteurs efficaces contenus dans le cadre défini Le numérateur est le nombre de configurations produisant cet événement.

30
Ainsi, la probabilité de tirer un Roi dans un jeu de 32 cartes classique neuf et normal, non marqué, en prenant une seule carte est de 4/32 (il existe 4 configurations favorables pour un total de 32). On comprend que p a pour bornes 0 et 1. Une probabilité peut être inférée des paramètres du cadre (exemples : un dé à six faces) ou (cas le plus fréquent) de l’observation prolongée du cadre (sexe de l’enfant à naître, météorologie, voire astrologie…).
 ou (cas le plus fréquent) de l’observation prolongée du cadre (sexe de l’enfant à naître, météorologie, voire astrologie…).")
31
La distinction est importante.
Le modèle théorique d’un dé à six faces, conduit à prêter à chacun des six résultats possibles d’un lancer simple une probabilité égale (équiprobabilité). Mais on peut tester un dé « réel », qui peut ne pas être équilibré. Il faut alors le lancer un « certain » nombre de fois afin de vérifier si les résultats sont conformes aux prédictions du modèle. Si le dé est mal équilibré, l’expérience permet à un tricheur de détenir un modèle non équiprobable susceptible de lui permettre un système de paris gagnants.
. Mais on peut tester un dé « réel », qui peut ne pas être équilibré. Il faut alors le lancer un « certain » nombre de fois afin de vérifier si les résultats sont conformes aux prédictions du modèle. Si le dé est mal équilibré, l’expérience permet à un tricheur de détenir un modèle non équiprobable susceptible de lui permettre un système de paris gagnants.")
32
Modèle du lancer de dés :
un seul lancer Chaque résultat est « équiprobable » Le total des probabilités est 1. Chaque probabilité est comprise entre 0 et 1

33
Un dé « pipé », lancé 1000 fois. Résultats de 1000 lancers : Modèle probabiliste de ce dé :

34
Contraste des deux modèles :
Permet de spéculer sur le(s) facteur(s) d’une telle déviation. Ici, une masse plus dense entre le centre du dé et la face « 6 » ?
 facteur(s) d’une telle déviation. Ici, une masse plus dense entre le centre du dé et la face « 6 »")
35
Modèle du lancer de dés : un seul lancer Additivité
Le total des probabilités reste 1. Chaque probabilité est comprise entre 0 et 1, ces bornes comprises

36
Modèle du lancer de dés : deux lancers Composition exemple A
Le total des probabilités reste 1. Attention à l’opérateur « ET »

37
Modèle du lancer de dés : deux lancers Composition exemple B
Le total des probabilités reste 1. Attention à l’opérateur « PUIS »

38
Modèle du lancer de dés : deux lancers Composition exemple C
Le total des probabilités reste 1.

39
Les tirages ne sont plus indépendants les uns des autres
Modèle du jeu de cartes Les tirages ne sont plus indépendants les uns des autres Exemple 1 : on tire une seule carte. Le total des probabilités reste 1.

40
Les tirages ne sont plus indépendants les uns des autres
Modèle du jeu de cartes Les tirages ne sont plus indépendants les uns des autres Exemple 1 : on tire deux cartes SANS REMETTRE LA 1ère. Les probabilités concernant la 2ème carte sont modifiées par le tirage de la 1ère carte. Si je tire un Roi, il reste alors 3 rois sur 31 cartes. La probabilité combinée de tirer SIMULTANEMENT 2 rois se calcule ainsi : 4/32 * 3/31 = (si l’on remettait la carte et rebattait le jeu, la probabilité de tirer SUCCESSIVEMENT 2 rois serait : 4/32 * 4/32 =

41
Les tirages ne sont plus indépendants les uns des autres
Modèle du jeu de cartes Les tirages ne sont plus indépendants les uns des autres La différence de à peut paraître minime… Mais si je tire 4 cartes dans l’espoir d’obtenir 4 Rois : La probabilité combinée de tirer SIMULTANEMENT 4 rois (un « carré de rois » ) se calcule ainsi : 4/32 * 3/31 * 2/30 * 1/29 = 28 pour UN MILLION (noté 2.78 E-05) (si l’on remettait la carte et rebattait le jeu, la probabilité de tirer SUCCESSIVEMENT 2 rois serait : 4/32 * 4/32 * 4/32 * 4/32 = 244 pour un million (noté 2.44 E-04) SOIT 9 FOIS PLUS.
 se calcule ainsi : 4/32 * 3/31 * 2/30 * 1/29 = 28 pour UN MILLION (noté 2.78 E-05) (si l’on remettait la carte et rebattait le jeu, la probabilité de tirer SUCCESSIVEMENT 2 rois serait : 4/32 * 4/32 * 4/32 * 4/32 = 244 pour un million (noté 2.44 E-04) SOIT 9 FOIS PLUS.")
42
Modèle du jeu de cartes En pratique, on se souviendra que la plupart des calculs en statistique lexicale se font sur ce modèle (« sans remise ») Exemple : si je compare le vocabulaire d’un article de journal à celui de la collection complète de ce journal, c’est « comme si » je tirais SIMULTANEMENT d’un immense jeu de (mettons) 40 millions de cartes une « poignée » de (mettons) 5000 cartes Si je veux calculer la probabilité que cette « poignée » comporte (mettons) 50 « cartes » marquées « je », je devrai tenir compte du fait que le « stock » total de cartes « je » est limité et épuisable.
 Exemple : si je compare le vocabulaire d’un article de journal à celui de la collection complète de ce journal, c’est « comme si » je tirais SIMULTANEMENT. d’un immense jeu de (mettons) 40 millions de cartes. une « poignée » de (mettons) 5000 cartes. Si je veux calculer la probabilité que cette « poignée » comporte (mettons) 50 « cartes » marquées « je », je devrai tenir compte du fait que le « stock » total de cartes « je » est limité et épuisable.")
43
Modèle du jeu de cartes En pratique, on se souviendra que la plupart des calculs en statistique lexicale se font sur ce modèle (« sans remise ») REMARQUE ECLAIRANTE : Quelle est la probabilité de tirer SIMULTANEMENT 5 rois en 5 cartes dans un jeu de 32 cartes ordinaire ?
 REMARQUE ECLAIRANTE : Quelle est la probabilité de tirer SIMULTANEMENT 5 rois en 5 cartes dans un jeu de 32 cartes ordinaire")
44
Modèle du jeu de cartes En pratique, on se souviendra que la plupart des calculs en statistique lexicale se font sur ce modèle (« sans remise ») REMARQUE ECLAIRANTE : Quelle est la probabilité de tirer SIMULTANEMENT 5 rois en 5 cartes dans un jeu de 32 cartes ordinaire ? Cette probabilité est NULLE. On le montre aisément par le calcul : p = 4/32 * 3/31 * 2/30 * 1/29 * 0/28 = 0 Il en va de même pour l’hypothèse de rencontrer 51 occurrences de « je » dans un article si la collection complète n’en comporte que 50.
 REMARQUE ECLAIRANTE : Quelle est la probabilité de tirer SIMULTANEMENT 5 rois en 5 cartes dans un jeu de 32 cartes ordinaire Cette probabilité est NULLE. On le montre aisément par le calcul : p = 4/32 * 3/31 * 2/30 * 1/29 * 0/28 = 0. Il en va de même pour l’hypothèse de rencontrer 51 occurrences de « je » dans un article si la collection complète n’en comporte que 50.")
45
Fréquence et probabilité
Si l’on « prend » (« tire ») un mot au hasard dans la suite des mots du corpus, la probabilité que ce mot soit une occurrence de telle ou telle forme graphique est égale à la fréquence de cette forme dans le corpus (Fréquence et probabilité sont également bornées par 0 et 1) [ DANS LE MODELE LEXICAL D’EQUIPROBABILITE ] qui permettra, par contraste avec les observations réelles, de connaître certaines contraintes (STOCHASTIQUES)
 un mot au hasard dans la suite des mots du corpus, la probabilité que ce mot soit une occurrence de telle ou telle forme graphique. est égale à la fréquence de cette forme dans le corpus. (Fréquence et probabilité sont également bornées par 0 et 1) [ DANS LE MODELE LEXICAL D’EQUIPROBABILITE ] qui permettra, par contraste avec les observations réelles, de connaître certaines contraintes. (STOCHASTIQUES)")
46
Fréquence et probabilité
Si l’on « prend » (« tire ») un mot au hasard dans la suite des mots du corpus, la probabilité que ce mot soit une occurrence de telle ou telle forme graphique est égale à la fréquence de cette forme dans le corpus (Fréquence et probabilité sont également bornées par 0 et 1) [ DANS LE MODELE LEXICAL D’EQUIPROBABILITE ] qui permettra, par contraste avec les observations réelles, de connaître certaines contraintes (STOCHASTIQUES)
 un mot au hasard dans la suite des mots du corpus, la probabilité que ce mot soit une occurrence de telle ou telle forme graphique. est égale à la fréquence de cette forme dans le corpus. (Fréquence et probabilité sont également bornées par 0 et 1) [ DANS LE MODELE LEXICAL D’EQUIPROBABILITE ] qui permettra, par contraste avec les observations réelles, de connaître certaines contraintes. (STOCHASTIQUES)")
47
Stochastique On laissera ici de côté la combinatoire syntaxique proprement dite (impossibilité linguistique de la suite « de je », fréquence de la suite « de la » bien supérieure à sa probabilité calculée mot par mot). Combinatoire « lexicale ». Exemple de la séquence « conseil général ». Dans SGAR, la fréquence de « conseil » est 9.57 E-04, celle de « général » de 6.22 E-04. La probabilité de les trouver dans cet ordre est 5.05 E-07 (0.6 pour 1 million). Or, la fréquence de « conseil général » parmi les « bi-formes » du corpus est 2.17 E-04, soit à peine plus faible que celle de ses constituants !
. Combinatoire « lexicale ». Exemple de la séquence « conseil général ». Dans SGAR, la fréquence de « conseil » est 9.57 E-04, celle de « général » de 6.22 E-04. La probabilité de les trouver dans cet ordre est 5.05 E-07 (0.6 pour 1 million). Or, la fréquence de « conseil général » parmi les « bi-formes » du corpus est 2.17 E-04, soit à peine plus faible que celle de ses constituants !")
48
Conclusion partielle Face à un événement, produit « naturellement » ou provoqué « artificiellement » (on le nomme un résultat), du type : « je dénombre 8 occurrences de démocratie dans une page de ce livre, qui en compte 355 pour 220 pages » on calcule quelle était la probabilité de ce résultat « avant qu’il ait eu lieu », c’est-à-dire la probabilité a posteriori de se tromper en affirmant qu’il est dû au hasard (ou l’inverse, de parier qu’il va se reproduire, p.ex.) Les « lois » de distribution (binomiale, normale, de Poisson) expriment directement la probabilité de ce qui est observé, comme si elles avaient à le prévoir, et c’est ce qui valorise – ou non – l’événement.
 Les « lois » de distribution (binomiale, normale, de Poisson) expriment directement la probabilité de ce qui est observé, comme si elles avaient à le prévoir, et c’est ce qui valorise – ou non – l’événement.")
49
Conclusion partielle Face à un événement, produit « naturellement » ou provoqué « artificiellement » (on le nomme un résultat), du type : « je dénombre 8 occurrences de démocratie dans une page de ce livre, qui en compte 355 pour 220 pages » on calcule quelle était la probabilité de ce résultat « avant qu’il ait eu lieu », c’est-à-dire la probabilité a posteriori de se tromper en affirmant qu’il est dû au hasard (ou l’inverse, de parier qu’il va se reproduire, p.ex.) Les « lois » de distribution (binomiale, normale, de Poisson) expriment directement la probabilité de ce qui est observé, comme si elles avaient à le prévoir, et c’est ce qui valorise – ou non – l’événement.
 Les « lois » de distribution (binomiale, normale, de Poisson) expriment directement la probabilité de ce qui est observé, comme si elles avaient à le prévoir, et c’est ce qui valorise – ou non – l’événement.")
50
Conclusion partielle Le calcul de l’écart-réduit d’une observation à sa valeur calculée dans le modèle de l’équidistribution substitue un indice « désincarné », épuré d’attributs accidentels, à l’effectif dénombré. Et c’est lui, l’écart-réduit, qui répond de sa probabilité « d’être dû au hasard ». Pour ceux qui le pratiquent, il a incorporé l’échelle statistique (on dit « un écart-réduit de 3, un écart-réduit « du feu de Dieu »).
.")
51
3. Distributions Evaluation en probabilité

52
Espérance mathématique.
Si un mot quelconque a une probabilité connue d’être l’occurrence d’une forme donnée, on peut calculer un nombre « théorique » d’occurrences de cette forme dans un ensemble de n mots. C’est ce que la théorie des jeux appelle l’espérance mathématique. La formule en est En d’autres termes, si l’on prend pour norme la fréquence d’une forme dans un (vaste) corpus de référence (p) , on « s’attend » à en trouver, dans un corpus de travail comprenant n mots, p*n occurrences .
 corpus de référence (p) , on « s’attend » à en trouver, dans un corpus de travail comprenant n mots, p*n occurrences .")
53
Effectif « théorique » ou calculé.
En d’autres termes encore, si l’on prend pour norme l’effectif (X) d’une forme dans un (vaste) corpus de référence comprenant N mots, on « s’attend » à en trouver, dans un corpus de travail comprenant n mots, X*n/N occurrences . L’ « espérance mathématique » est un effectif (un nombre d’occurrences). On parle plutôt d’effectif théorique, et mieux encore d’effectif calculé (vs effectif mesuré), que d’ « espérance mathématique » Sa formule nous laisse entrevoir qu’il n’a pas de borne supérieure* et prendra le plus souvent l’aspect d’un nombre « avec décimales ». * Si ce n’est n, au cas où p=1…
 d’une forme dans un (vaste) corpus de référence comprenant N mots, on « s’attend » à en trouver, dans un corpus de travail comprenant n mots, X*n/N occurrences . L’ « espérance mathématique » est un effectif (un nombre d’occurrences). On parle plutôt d’effectif théorique, et mieux encore d’effectif calculé (vs effectif mesuré), que d’ « espérance mathématique » Sa formule nous laisse entrevoir qu’il n’a pas de borne supérieure* et prendra le plus souvent l’aspect d’un nombre « avec décimales ». * Si ce n’est n, au cas où p=1…")
54
Le corpus de travail ne fait pas partie du corpus de référence.
Cas n°1 : norme exogène Le corpus de travail ne fait pas partie du corpus de référence. Exemple : corpus de travail Monde Diplo , corpus de référence Frantext 19ème-20ème siècles. Dans Frantext, la forme « production » a une fréquence de E-04 (195 pour un million). Le n de Mondiplo étant , l’effectif calculé de « production » y est de * E-04 =
. Le n de Mondiplo étant , l’effectif calculé de « production » y est de * E-04 =")
55
Cas n°1 : norme exogène Le corpus de travail ne fait pas partie du corpus de référence. Exemple : corpus de travail Monde Diplo , corpus de référence Frantext 19ème-20ème siècles. Dans Frantext, la forme « production » a une fréquence de E-04 (195 pour un million). Le N de Mondiplo étant , l’effectif calculé de « production » y est de * E-04 = L’effectif mesuré (« réel ») est 8199. On note donc un excédent, un suremploi. On verra plus loin comment évaluer cet excédent.
. Le N de Mondiplo étant , l’effectif calculé de « production » y est de * E-04 = L’effectif mesuré (« réel ») est On note donc un excédent, un suremploi. On verra plus loin comment évaluer cet excédent.")
56
Exemple : corpus de travail Monde Diplo , sous-ensemble année 2000.
Cas n°2 : norme endogène Le corpus de travail sert de norme aux sous-ensembles qu’on veut y étudier (on cherche à étudier les structures lexicales du corpus) Exemple : corpus de travail Monde Diplo , sous-ensemble année 2000. Dans Monde Diplo , la forme « production » a une fréquence de E-04 (464 pour un million). Le n de 2000 étant , l’effectif calculé de « production » y est de * E-04 =
 Exemple : corpus de travail Monde Diplo , sous-ensemble année Dans Monde Diplo , la forme « production » a une fréquence de E-04 (464 pour un million). Le n de 2000 étant , l’effectif calculé de « production » y est de * E-04 =")
57
Cas n°2 : norme endogène L’effectif mesuré (« réel ») est 181.
Le corpus de travail sert de norme aux sous-ensembles qu’on veut y étudier (on cherche à étudier les structures lexicales du corpus) Exemple : corpus de travail Monde Diplo , sous-ensemble année 2000. Dans Monde Diplo , la forme « production » a une fréquence de E-04 (464 pour un million). Le n de 2000 étant , l’effectif calculé de « production » y est de * E-04 = L’effectif mesuré (« réel ») est 181. On note donc un déficit, un sous-emploi. On verra plus loin comment évaluer ce déficit.
 Exemple : corpus de travail Monde Diplo , sous-ensemble année Dans Monde Diplo , la forme « production » a une fréquence de E-04 (464 pour un million). Le n de 2000 étant , l’effectif calculé de « production » y est de * E-04 = L’effectif mesuré (« réel ») est 181. On note donc un déficit, un sous-emploi. On verra plus loin comment évaluer ce déficit.")
58
Récapitulons : Le Monde Diplomatique emploie PLUS que la norme de Frantext la forme « production ». En 2000, le Monde Diplomatique emploie MOINS que la norme de sa collection la forme « production ». Excédents et déficits entrent dans une même catégorie : les écarts à l’équirépartition. On parle tout d’abord d’écart absolu; c’est une soustraction simple. Dans le premier cas, l’écart est de = +4790 Dans le second cas, il est de =

59
Vue d’ensemble sur les effectifs mesurés (en bleu) et calculés (en rouge) de « production » dans les 21 années du corpus.
 et calculés (en rouge) de « production » dans les 21 années du corpus.")
60
Evaluation des écarts à la norme endogène.
L’existence d’écarts entre effectifs mesurés et calculés est normale. L’absence d’écarts, ou de très faibles écarts, signaleraient des objets fabriqués artificiellement (règle de parité H/F par exemple). On doit évaluer les écarts afin de décider s’ils sont ou non significatifs (par exemple, si l’histogramme vu précédemment représente une baisse tendancielle significative).
. On doit évaluer les écarts afin de décider s’ils sont ou non significatifs (par exemple, si l’histogramme vu précédemment représente une baisse tendancielle significative).")
61
Une unité de mesure pertinente
Excédents et déficits sont exprimés en effectifs, en nombre d’individus. Ils ne sont comme tels pas comparables entre eux, car plus le corpus est grand, plus des écarts absolus « normaux », non significatifs, vont pouvoir être importants. Ils ne peuvent pas non plus être évalués en pourcentage (excédent de 10%, etc), car ce sont alors les petits corpus qui exprimeront artificieusement des écarts importants. On va chercher une unité de mesure pertinente pour exprimer les écarts indépendamment de la taille du corpus. Une mesure d’écart pouvant être rapportée à une échelle universelle, et être ainsi évaluée.
, car ce sont alors les petits corpus qui exprimeront artificieusement des écarts importants. On va chercher une unité de mesure pertinente pour exprimer les écarts indépendamment de la taille du corpus. Une mesure d’écart pouvant être rapportée à une échelle universelle, et être ainsi évaluée.")
62
L’écart-type. Dans l’observation de variables, on nomme écart-type une déviation « moyenne » (en réalité, la racine carrée de la moyenne des carrés des déviations). Cette déviation est la plus probable dans le cadre d’expériences multiples. Par exemple, voici une suite de 200 lancers simultanés de 5 dés, exprimée en total de points.
. Cette déviation est la plus probable dans le cadre d’expériences multiples. Par exemple, voici une suite de 200 lancers simultanés de 5 dés, exprimée en total de points.")
63
L’écart-type.

64
L’écart-type. Moyenne des carrés des déviations (variance) : 10.01
Racine carrée de la variance (écart-type) : 3.16 Fréquence cumulée des tirages présentant un écart absolu inférieur à 3.16 : = 0.64 Fréquence cumulée des tirages présentant un écart absolu inférieur à 6.32 : = 0.94
 : Fréquence cumulée des tirages présentant un écart absolu inférieur à 3.16 : = Fréquence cumulée des tirages présentant un écart absolu inférieur à 6.32 : =")
65
L’écart-type. La fréquence (probabilité, pour un tirage ultérieur dans les mêmes conditions), d’un résultat supérieur à moyenne + 2 écarts-types ( , soit ) ou inférieur à moyenne + 2 écarts-types ( , soit ) est de l’ordre de 6 %.
 ou inférieur à. moyenne + 2 écarts-types ( , soit ) est de l’ordre de 6 %.")
66
Calcul de l’écart-type.
Dans le cas où on n’observe pas des variables aléatoires, mais des distributions réelles (notre cas), on est amené à calculer un écart-type dit « théorique », à partir des paramètres précis du problème étudié. Entrent en jeu : ● le nombre total de mots du corpus de référence (N) ● le nombre total de mots du sous-ensemble considéré (n) ● le nombre total d’occurrences de la forme dont on observe la distribution(X) On calcule d’abord la variance théorique, selon la formule NB : est une variante du produit pq où q = 1-p
, on est amené à calculer un écart-type dit « théorique », à partir des paramètres précis du problème étudié. Entrent en jeu : ● le nombre total de mots du corpus de référence (N) ● le nombre total de mots du sous-ensemble considéré (n) ● le nombre total d’occurrences de la forme dont on observe la distribution(X) On calcule d’abord la variance théorique, selon la formule. NB : est une variante du produit pq où q = 1-p.")
67
Calcul de l’écart-type.
L’écart-type théorique est la racine carrée de la variance théorique, sa formule est donc : NB : est une variante du produit pq où q = 1-p. Le produit pq est d’autant plus élevé que p s’approche de la valeur « centrale » 0.5

68
Calcul de l’écart-type.
Si l’on observe les effectifs d’un collège français de 1000 élèves, si le caractère étudié divise la population par moitié (le sexe), l’écart-type est de Si le caractère étudié divise la population selon une proportion 5%/95% (enfants d’immigrés non naturalisés), l’écart-type est de 6.9. Une répartition réelle de 530 filles et 470 garçons sera peu significative d’un facteur discriminant, avec un écart de 30 à la norme donc. En revanche, un même écart absolu, la norme « prévoyant » 50/950, donnera un effectif réel d’enfants d’immigrés non naturalisés de 20 ou de 80, ce qui dans les 2 cas signale un ou plusieurs facteurs sociaux manifestes (la déviation contient plus de 4 écarts-types, voir interprétation plus bas).
, l’écart-type est de Si le caractère étudié divise la population selon une proportion 5%/95% (enfants d’immigrés non naturalisés), l’écart-type est de 6.9. Une répartition réelle de 530 filles et 470 garçons sera peu significative d’un facteur discriminant, avec un écart de 30 à la norme donc. En revanche, un même écart absolu, la norme « prévoyant » 50/950, donnera un effectif réel d’enfants d’immigrés non naturalisés de 20 ou de 80, ce qui dans les 2 cas signale un ou plusieurs facteurs sociaux manifestes (la déviation contient plus de 4 écarts-types, voir interprétation plus bas).")
69
Calcul de l’écart-type.
Dans le cas envisagé plus haut (estimation du déficit de « production » dans l’année 2000 de Mondiplo sur norme endogène – corpus Mondiplo ), les valeurs sont les suivantes : ce qui donne = 17.04
, les valeurs sont les suivantes : ce qui donne =")
70
Emploi de l’écart-type ; l’écart-réduit.
On se souvient que le déficit était de 115.6 Il contient donc / 17.04, soit environ 7.1 fois l’écart-type. L’écart-réduit est le nombre d’écarts-types contenus dans l’écart absolu, affecté du signe + ou du signe -. Ici, l’écart-réduit est -7.08 La probabilité d’un tel écart-réduit dans une distribution aléatoire est infinitésimale. Tableau d’interprétation : z p 0.5 0.617 1 0.317 1.5 0.134 2 0.046 2.5 0.012 3 3.5 4 4.5 z = écart réduit p = probabilité d’atteindre ou dépasser un tel écart-réduit

71
Vue d’ensemble sur les déficits et excédents de « production » dans les 21 années du corpus, vus en écarts-réduits.

72
Evaluation d’une distribution en probabilité
S’il est intéressant d’étudier une déviation individuelle, il l’est plus encore d’étudier l’ensemble des déviations d’une distribution donnée. L’histogramme précédent est significatif au premier regard, mais comment lui attribuer directement et assurément un indice précis ? Comment discriminer les distributions, dans le même cadre, de dizaines de formes ?

73
Evaluation d’une distribution en probabilité
Comment, par exemple, évaluer la distribution figurée ci-dessous (forme « choix », 3769 occurrences)
")
74
Test de Pearson, ou Χ² Soit le tableau de valeurs : Lui correspondent des valeurs calculées selon le modèle d’équirépartition : choix AUTRES TOTAL 192,348224 900970,767 901414 176,661012 827490,916 827898 186,230476 872314,865 872744 182,474046 854719,521 855140 183,916316 861475,197 861899 182,790923 856203,79 856625 174,469122 817223,966 817626 174,121731 815596,767 815998 182,661612 855598,088 856019 182,850671 856483,653 856905 176,839189 828325,505 828733 181,818528 851649,031 852068 187,525083 878378,881 878811 185,713657 869894,055 870322 182,624696 855425,173 855846 181,327315 849348,163 849766 181,062718 848108,773 848526 180,517946 845557,028 845973 175,157715 820449,38 820853 179,239343 839567,974 839981 138,649676 649443,506 649763 choix AUTRES TOTAL 214 900941 901414 183 827482 827898 192 872337 872744 172 854688 855140 199 861408 861899 856161 856625 165 817190 817626 815599 815998 198 855621 856019 856526 856905 160 828356 828733 186 851668 852068 167 878405 878811 169 869885 870322 182 855482 855846 173 849403 849766 176 848174 848526 845546 845973 820421 820853 181 839510 839981 137 649422 649763

75
Test de Pearson, ou Χ² Soit le tableau de valeurs : Lui correspondent des valeurs calculées selon le modèle d’équirépartition : o c choix AUTRES TOTAL 192,348224 900970,767 901414 176,661012 827490,916 827898 186,230476 872314,865 872744 182,474046 854719,521 855140 183,916316 861475,197 861899 182,790923 856203,79 856625 174,469122 817223,966 817626 174,121731 815596,767 815998 182,661612 855598,088 856019 182,850671 856483,653 856905 176,839189 828325,505 828733 181,818528 851649,031 852068 187,525083 878378,881 878811 185,713657 869894,055 870322 182,624696 855425,173 855846 181,327315 849348,163 849766 181,062718 848108,773 848526 180,517946 845557,028 845973 175,157715 820449,38 820853 179,239343 839567,974 839981 138,649676 649443,506 649763 choix AUTRES TOTAL 214 900941 901414 183 827482 827898 192 872337 872744 172 854688 855140 199 861408 861899 856161 856625 165 817190 817626 815599 815998 198 855621 856019 856526 856905 160 828356 828733 186 851668 852068 167 878405 878811 169 869885 870322 182 855482 855846 173 849403 849766 176 848174 848526 845546 845973 820421 820853 181 839510 839981 137 649422 649763

76
Test de Pearson, ou Χ² Pour chaque cellule du tableau (sauf la marge « TOTAL »), on calcule : (o – c)² / c (= variance théorique cf supra) Le X² est la somme de ces calculs. Exemple cellule « A1 » : (214 – )² / = 2.437
² / =")
77
Test de Pearson, ou Χ² Tableau de valeurs : modèle d’équirépartition : Résultats en X² : (somme : 18.32) choix AUTRES TOTAL 214 900941 901414 183 827482 827898 192 872337 872744 172 854688 855140 199 861408 861899 856161 856625 165 817190 817626 815599 815998 198 855621 856019 856526 856905 160 828356 828733 186 851668 852068 167 878405 878811 169 869885 870322 182 855482 855846 173 849403 849766 176 848174 848526 845546 845973 820421 820853 181 839510 839981 137 649422 649763 choix AUTRES TOTAL 192,348224 900970,767 901414 176,661012 827490,916 827898 186,230476 872314,865 872744 182,474046 854719,521 855140 183,916316 861475,197 861899 182,790923 856203,79 856625 174,469122 817223,966 817626 174,121731 815596,767 815998 182,661612 855598,088 856019 182,850671 856483,653 856905 176,839189 828325,505 828733 181,818528 851649,031 852068 187,525083 878378,881 878811 185,713657 869894,055 870322 182,624696 855425,173 855846 181,327315 849348,163 849766 181,062718 848108,773 848526 180,517946 845557,028 845973 175,157715 820449,38 820853 179,239343 839567,974 839981 138,649676 649443,506 649763 2,4372 0,0010 0,2275 0,0001 0,1787 0,0006 0,6012 0,0012 1,2371 0,0052 0,6370 0,0021 0,5139 0,0014 3,5546 0,0000 1,2880 1,2551 1,6035 0,0011 0,0962 0,0004 2,2465 0,0008 1,5042 0,0038 0,3824 0,0035 0,1416 0,0050 0,3131 0,0266 0,0173 0,0040 0,0196 0,0007

78
Test de Pearson, ou Χ² 20 « degrés de liberté »
Résultats en X² (somme : 18.32) pour « choix » choix AUTRES TOTAL 214 900941 901414 183 827482 827898 192 872337 872744 172 854688 855140 199 861408 861899 856161 856625 165 817190 817626 815599 815998 198 855621 856019 856526 856905 160 828356 828733 186 851668 852068 167 878405 878811 169 869885 870322 182 855482 855846 173 849403 849766 176 848174 848526 845546 845973 820421 820853 181 839510 839981 137 649422 649763 20 « degrés de liberté »
 pour « choix » choix. AUTRES. TOTAL « degrés de liberté »")
79
Test de Pearson, ou Χ²

80
Test de Pearson, ou Χ² pour « production »
Tableau de valeurs : modèle d’équirépartition : Résultats en X² : (somme : ) production AUTRES TOTAL 662 900941 901414 717 827482 827898 626 872337 872744 488 854688 855140 414 861408 861899 526 856161 856625 574 817190 817626 299 815599 815998 427 855621 856019 406 856526 856905 318 828356 828733 330 851668 852068 333 878405 878811 315 869885 870322 320 855482 855846 287 849403 849766 250 848174 848526 261 845546 845973 259 820421 820853 201 839510 839981 186 649422 649763 production AUTRES TOTAL 418,430111 900970,767 901414 384,304495 827490,916 827898 405,121696 872314,865 872744 396,950042 854719,521 855140 400,087522 861475,197 861899 397,639368 856203,79 856625 379,536304 817223,966 817626 378,780597 815596,767 815998 397,358067 855598,088 856019 397,769342 856483,653 856905 384,692096 828325,505 828733 395,524041 851649,031 852068 407,937955 878378,881 878811 403,99742 869894,055 870322 397,277762 855425,173 855846 394,455468 849348,163 849766 393,879869 848108,773 848526 392,694784 845557,028 845973 381,034255 820449,38 820853 389,913339 839567,974 839981 301,615466 649443,506 649763 141,7830 0,0010 288,0172 0,0001 120,4261 0,0006 20,8845 0,0012 0,4838 0,0052 41,4357 0,0021 99,6377 0,0014 16,8038 0,0000 2,2112 0,1703 11,5621 0,0011 10,8550 0,0004 13,7661 0,0008 19,6054 15,0319 0,0038 29,2724 0,0035 52,5577 0,0050 44,1654 39,0840 91,5287 0,0040 44,3178 0,0007
 production. AUTRES. TOTAL production. AUTRES. TOTAL. 418, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ,0007.")
81
Test de Pearson, ou Χ² 20 « degrés de liberté »
Résultats en X² (somme : ) pour « production » production AUTRES TOTAL 662 900941 901414 717 827482 827898 626 872337 872744 488 854688 855140 414 861408 861899 526 856161 856625 574 817190 817626 299 815599 815998 427 855621 856019 406 856526 856905 318 828356 828733 330 851668 852068 333 878405 878811 315 869885 870322 320 855482 855846 287 849403 849766 250 848174 848526 261 845546 845973 259 820421 820853 201 839510 839981 186 649422 649763 20 « degrés de liberté »
 pour « production » production. AUTRES. TOTAL « degrés de liberté »")
82
Le résultat est « juste », mais non interprétable.
Limites du X² Le X² ne peut s’employer que pour comparer des distributions en effectifs, et (comme l’écart-réduit, dont il est parent), lorsque les effectifs « calculés » ne sont pas inférieurs à un seuil de pertinence (5, 10…) Surtout, le X² a les propriétés de son modèle (la distribution aléatoire). Son interprétation dans l’étude des distributions lexicales est fiable pour un « nombre de tirages » ‘raisonnable’. Au-delà (par exemple, de occurrences), même des items comme « de » ou « le » prennent des valeurs dont la « probabilité » selon le modèle aléatoire est infinitésimale (ainsi en va-t-il de l’organisation textuelle…) Le résultat est « juste », mais non interprétable.
, lorsque les effectifs « calculés » ne sont pas inférieurs à un seuil de pertinence (5, 10…) Surtout, le X² a les propriétés de son modèle (la distribution aléatoire). Son interprétation dans l’étude des distributions lexicales est fiable pour un « nombre de tirages » ‘raisonnable’. Au-delà (par exemple, de occurrences), même des items comme « de » ou « le » prennent des valeurs dont la « probabilité » selon le modèle aléatoire est infinitésimale (ainsi en va-t-il de l’organisation textuelle…) Le résultat est « juste », mais non interprétable.")
83
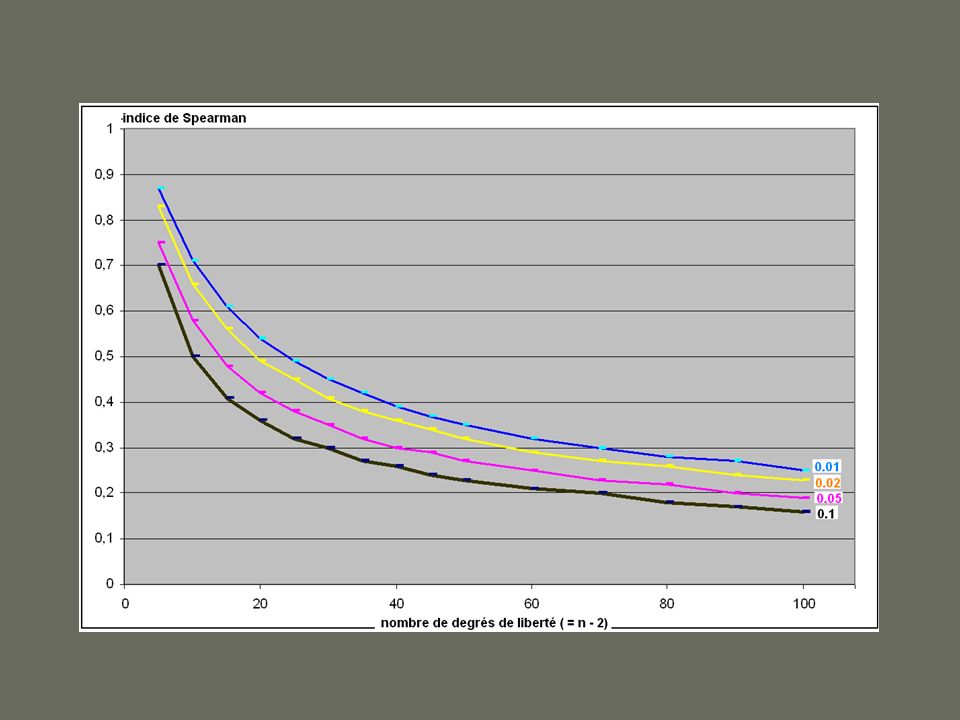
La corrélation des rangs
Revenons au cas de « production » dans Mondiplo. Cette forme a un profil qui semble fort caractéristique : emploi décroissant en diachronie. Nous voyons que le X² de cette distribution est très élevé (le 4ème au total de tout le vocabulaire du corpus). En complément, un test simple et rapide permet de valider l’impression visuelle (qui peut être trompeuse).
. En complément, un test simple et rapide permet de valider l’impression visuelle (qui peut être trompeuse).")
84
La corrélation des rangs
On range les années du corpus par écart-réduit croissant à l’équidistribution (on leur attribue un rang) ANNEE DEVIATION RANG _1999 -11,5154 1 _1996 -9,5477 2 _1997 -8,8278 3 _1998 -8,3434 4 _1995 -7,7129 5 _2000 -7,0764 6 _1993 -6,5311 7 _1987 -6,0913 8 _1990 -6,0420 9 _1994 -5,7233 10 _1992 -5,5330 11 _1991 -5,4903 12 _1984 -2,8751 13 _1989 -2,3527 14 _1988 -1,9727 15 _1983 0,8258 16 _1985 4,4912 17 _1982 6,4654 18 _1986 6,8573 19 _1980 7,7067 20 _1981 12,9421 21
 ANNEE. DEVIATION. RANG. _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ ,")
85
La corrélation des rangs
On range les années du corpus par écart-réduit croissant à l’équidistribution (on leur attribue un rang) ANNEE DEVIATION RANG _1999 -11,5154 1 _1996 -9,5477 2 _1997 -8,8278 3 _1998 -8,3434 4 _1995 -7,7129 5 _2000 -7,0764 6 _1993 -6,5311 7 _1987 -6,0913 8 _1990 -6,0420 9 _1994 -5,7233 10 _1992 -5,5330 11 _1991 -5,4903 12 _1984 -2,8751 13 _1989 -2,3527 14 _1988 -1,9727 15 _1983 0,8258 16 _1985 4,4912 17 _1982 6,4654 18 _1986 6,8573 19 _1980 7,7067 20 _1981 12,9421 21 On calcule les écarts entre les rangs selon les 2 ordres (on les porte au carré et on les totalise – Σ d² -) ANNEE DEVIATION RANG DIACHRONIE (R-D)² _1980 7,7067 20 1 361 _1981 12,9421 21 2 _1982 6,4654 18 3 225 _1983 0,8258 16 4 144 _1984 -2,8751 13 5 64 _1985 4,4912 17 6 121 _1986 6,8573 19 7 _1987 -6,0913 8 _1988 -1,9727 15 9 36 _1989 -2,3527 14 10 _1990 -6,0420 11 _1991 -5,4903 12 _1992 -5,5330 _1993 -6,5311 49 _1994 -5,7233 25 _1995 -7,7129 _1996 -9,5477 _1997 -8,8278 _1998 -8,3434 _1999 -11,5154 _2000 -7,0764 Σ d² 2936
 ANNEE. DEVIATION. RANG. _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , On calcule les écarts entre les rangs selon les 2 ordres (on les porte au carré et on les totalise. – Σ d² -) ANNEE. DEVIATION. RANG. DIACHRONIE. (R-D)². _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ ,5330. _ , _ , _ ,7129. _ ,5477. _ ,8278. _ ,3434. _ ,5154. _ ,0764. Σ d²")
86
La corrélation des rangs
On range les années du corpus par écart-réduit croissant à l’équidistribution (on leur attribue un rang) ANNEE DEVIATION RANG DIACHRONIE (R-D)² _1980 7,7067 20 1 361 _1981 12,9421 21 2 _1982 6,4654 18 3 225 _1983 0,8258 16 4 144 _1984 -2,8751 13 5 64 _1985 4,4912 17 6 121 _1986 6,8573 19 7 _1987 -6,0913 8 _1988 -1,9727 15 9 36 _1989 -2,3527 14 10 _1990 -6,0420 11 _1991 -5,4903 12 _1992 -5,5330 _1993 -6,5311 49 _1994 -5,7233 25 _1995 -7,7129 _1996 -9,5477 _1997 -8,8278 _1998 -8,3434 _1999 -11,5154 _2000 -7,0764 TOTAL 2936 ANNEE DEVIATION RANG _1999 -11,5154 1 _1996 -9,5477 2 _1997 -8,8278 3 _1998 -8,3434 4 _1995 -7,7129 5 _2000 -7,0764 6 _1993 -6,5311 7 _1987 -6,0913 8 _1990 -6,0420 9 _1994 -5,7233 10 _1992 -5,5330 11 _1991 -5,4903 12 _1984 -2,8751 13 _1989 -2,3527 14 _1988 -1,9727 15 _1983 0,8258 16 _1985 4,4912 17 _1982 6,4654 18 _1986 6,8573 19 _1980 7,7067 20 _1981 12,9421 21 On calcule les écarts entre les rangs selon les 2 ordres (on les porte au carré et on les totalise – Σ d² -) n est le nombre de lignes comparées. ρ (rho) est un indice dont les bornes sont -1 et +1.
 ANNEE. DEVIATION. RANG. DIACHRONIE. (R-D)². _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ ,5330. _ , _ , _ ,7129. _ ,5477. _ ,8278. _ ,3434. _ ,5154. _ ,0764. TOTAL ANNEE. DEVIATION. RANG. _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , On calcule les écarts entre les rangs selon les 2 ordres (on les porte au carré et on les totalise. – Σ d² -) n est le nombre de lignes comparées. ρ (rho) est un indice dont les bornes sont -1 et +1.")
87
La corrélation des rangs
On range les années du corpus par écart-réduit croissant à l’équidistribution (on leur attribue un rang) ANNEE DEVIATION RANG DIACHRONIE (R-D)² _1980 7,7067 20 1 361 _1981 12,9421 21 2 _1982 6,4654 18 3 225 _1983 0,8258 16 4 144 _1984 -2,8751 13 5 64 _1985 4,4912 17 6 121 _1986 6,8573 19 7 _1987 -6,0913 8 _1988 -1,9727 15 9 36 _1989 -2,3527 14 10 _1990 -6,0420 11 _1991 -5,4903 12 _1992 -5,5330 _1993 -6,5311 49 _1994 -5,7233 25 _1995 -7,7129 _1996 -9,5477 _1997 -8,8278 _1998 -8,3434 _1999 -11,5154 _2000 -7,0764 TOTAL 2936 ANNEE DEVIATION RANG _1999 -11,5154 1 _1996 -9,5477 2 _1997 -8,8278 3 _1998 -8,3434 4 _1995 -7,7129 5 _2000 -7,0764 6 _1993 -6,5311 7 _1987 -6,0913 8 _1990 -6,0420 9 _1994 -5,7233 10 _1992 -5,5330 11 _1991 -5,4903 12 _1984 -2,8751 13 _1989 -2,3527 14 _1988 -1,9727 15 _1983 0,8258 16 _1985 4,4912 17 _1982 6,4654 18 _1986 6,8573 19 _1980 7,7067 20 _1981 12,9421 21 On calcule les écarts entre les rangs selon les 2 ordres (on les porte au carré et on les totalise – Σ d² -) n est le nombre de lignes comparées. ρ (rho) est un indice dont les bornes sont -1 et +1. Ici, le résultat est
 ANNEE. DEVIATION. RANG. DIACHRONIE. (R-D)². _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ ,5330. _ , _ , _ ,7129. _ ,5477. _ ,8278. _ ,3434. _ ,5154. _ ,0764. TOTAL ANNEE. DEVIATION. RANG. _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , On calcule les écarts entre les rangs selon les 2 ordres (on les porte au carré et on les totalise. – Σ d² -) n est le nombre de lignes comparées. ρ (rho) est un indice dont les bornes sont -1 et +1. Ici, le résultat est")
89
Corrélation négative de probabilité infinitésimale.

90
La corrélation des rangs Mêmes données et calculs pour « femmes »
ANNEE DEVIATION RANG DIACHRONIE (R-D)² _1980 -3,7600 11 1 100 _1981 -8,6900 2 _1982 -6,9800 3 _1983 -4,5700 7 4 9 _1984 -1,8500 13 5 64 _1985 -5,5600 6 _1986 -8,1500 25 _1987 -5,4500 8 _1988 -1,1200 14 _1989 -4,0800 10 _1990 -4,4600 _1991 -4,2300 12 _1992 -5,2900 49 _1993 -2,2000 _1994 0,3800 15 _1995 3,0700 16 _1996 6,2100 17 _1997 17,7600 20 18 _1998 19,7400 21 19 _1999 11,9900 _2000 10,9200 X² TOTAL 326 ρ = Corrélation positive de probabilité infinitésimale.
². _ , _ , _ , _ , _ , _ , _ , _ , _ , _ , _ ,4600. _ , _ , _ ,2000. _ , _ , _ , _ , _ , _ ,9900. _ ,9200. X² TOTAL ρ = Corrélation positive de probabilité infinitésimale.")
91
La corrélation des rangs
On peut aussi comparer 2 profils distributionnels particuliers Exemple : république et démocratie

92
La corrélation des rangs république et démocratie
ANNEE DEMOCRATIE REPUBLIQUE (R-D)² _1980 8 10 4 _1981 7 9 _1982 5 6 1 _1983 _1984 2 _1985 _1986 3 _1987 15 81 _1988 11 _1989 16 13 _1990 20 18 _1991 21 100 _1992 17 _1993 19 14 25 _1994 12 _1995 _1996 _1997 _1998 _1999 121 _2000 X² TOTAL 550 ρ = Corrélation positive de très basse probabilité.
². _ _ _ _1983. _ _1985. _ _ _ _ _ _ _ _ _ _1995. _1996. _1997. _1998. _ _2000. X² TOTAL ρ = Corrélation positive de très basse probabilité.")
93
La corrélation des rangs
On peut aussi comparer 2 profils distributionnels particuliers Exemple : internationale et mort

94
La corrélation des rangs Internationale et mort
ANNEE internationale mort (R-D)² _1980 21 1 400 _1981 20 2 324 _1982 7 13 36 _1983 11 4 49 _1984 5 _1985 15 64 _1986 19 _1987 14 8 _1988 _1989 6 225 _1990 18 196 _1991 3 10 _1992 12 _1993 16 100 _1994 _1995 _1996 9 _1997 169 _1998 81 _1999 17 _2000 256 X² TOTAL 2376 ρ = Corrélation négative de basse probabilité.
². _ _ _ _ _ _ _ _ _1988. _ _ _ _ _ _1994. _1995. _ _ _ _ _ X² TOTAL ρ = Corrélation négative de basse probabilité.")
95
La corrélation des rangs
On peut aussi comparer 2 profils distributionnels particuliers Contre-exemple : chef et manière

96
La corrélation des rangs
chef et manière ANNEE chef manière (R-D)² _1980 8 1 49 _1981 12 4 64 _1982 14 3 121 _1983 21 2 361 _1984 9 13 16 _1985 5 _1986 6 _1987 _1988 7 25 _1989 15 196 _1990 10 _1991 11 _1992 _1993 _1994 17 _1995 20 _1996 _1997 18 _1998 19 _1999 _2000 X² TOTAL 1162 ρ = Corrélation positive banale, sans signification.
². _ _ _ _ _ _ _ _1987. _ _ _ _ _1992. _1993. _ _ _1996. _ _ _1999. _2000. X² TOTAL ρ = Corrélation positive banale, sans signification.")
97
4. Distributions Généralisations et synthèses Classifications

98
Profil distributionnel.
Dans les études précédentes, nous avons vu de nombreux histogrammes d’écarts-réduits à l’équi-distribution. Ce sont des images, calculées, de la propriété statistique majeure des unités textuelles, corrélat de leurs fonctions linguistiques, fondement de leur sémantisme : l’irrégularité de leur distribution. Cet autre histogramme, celui de tiers-monde, en dit plus long que bien des phrases sur le discours de la presse anti-mondialiste, sur celui du monde dominant, sur leurs idéologies respectives, sur leurs rapports mutuels.

99
Profil distributionnel.
On nommera ces histogrammes et ce qu’ils figurent des profils distributionnels.

100
Profil distributionnel.
Nous les avons comparés à une norme idéale (tirages aléatoires), à un ordre de référence (diachronie), et entre eux deux à deux. Mais nous n’avons pas la vision synthétique promise en échange de l’emploi fastidieux des méthodes statistiques. Même si notre intuition nous mène à de brillantes ouvertures, et si la validation individuelle nous y conforte, il nous manque les calculs d’ensemble qui seuls nous permettraient de nous orienter en nous élevant au-dessus du substrat.
, à un ordre de référence (diachronie), et entre eux deux à deux. Mais nous n’avons pas la vision synthétique promise en échange de l’emploi fastidieux des méthodes statistiques. Même si notre intuition nous mène à de brillantes ouvertures, et si la validation individuelle nous y conforte, il nous manque les calculs d’ensemble qui seuls nous permettraient de nous orienter en nous élevant au-dessus du substrat.")
101
Profil distributionnel.
Cette « hauteur de vue », nous allons la chercher dans les méthodes de comparaison générale des profils, que nous appellerons méthodes classificatoires. Elles sont de 3 ordres (imbriqués et cousins) : Classifications hiérarchiques (ascendante – CHA – ou descendante – CHD) Calcul de distances + visualisations arborées Analyse Factorielle des Correspondances (AFC)
 : Classifications hiérarchiques (ascendante – CHA – ou descendante – CHD) Calcul de distances + visualisations arborées. Analyse Factorielle des Correspondances (AFC)")
102
Profil distributionnel.
Classifications hiérarchiques (ascendante – CHA – ou descendante – CHD) Il s’agit de former des « clusters » (grappes) dans un ensemble de variables, formalisées en un nuage de points, qui représentent des classes et des sous-classes. La CHA (CAH) est la plus connue, et procède par fusions successives de clusters déjà existants. La CHD (CDH) procède à l’inverse par segmentation progessive. Toutes deux supposent une définition et une méthode de calcul des « distances » entre points déterminés par l’algèbre d’une matrice de données. Il s’agit de méthodes et de visualisations dichotomiques. Même si des méthodes en aval rétablissent des ponts, les classes formées sont exclusives et étanches. Elles mettent en valeur des points de rupture et peuvent être « piégées » par des structures de données où plusieurs « chemins » (bifurcations) sont proches en termes de pertinence (c’est souvent le cas des données textuelles).
 Il s’agit de former des « clusters » (grappes) dans un ensemble de variables, formalisées en un nuage de points, qui représentent des classes et des sous-classes. La CHA (CAH) est la plus connue, et procède par fusions successives de clusters déjà existants. La CHD (CDH) procède à l’inverse par segmentation progessive. Toutes deux supposent une définition et une méthode de calcul des « distances » entre points déterminés par l’algèbre d’une matrice de données. Il s’agit de méthodes et de visualisations dichotomiques. Même si des méthodes en aval rétablissent des ponts, les classes formées sont exclusives et étanches. Elles mettent en valeur des points de rupture et peuvent être « piégées » par des structures de données où plusieurs « chemins » (bifurcations) sont proches en termes de pertinence (c’est souvent le cas des données textuelles).")
103
Profil distributionnel.
Distances et représentations arborées Hyperbase contient ces fonctions. On calcule, par exemple, la distance de Jaccard pour chaque paire de variables selon un critère déterminé (par exemple, distribution des formes graphiques, de traits grammaticaux…), et on dispose les résultats dans une matrice « carrée » (réduite ou non, avec ou sans diagonale). Puis, l’analyse arborée consiste à construire un graphe « arbre », où chaque variable est une feuille, où les feuilles se regroupent en rameaux, branches et troncs, de manière à figurer des clusters, mais surtout à ce que la longueur totale de tous les chemins entre feuilles (paire à paire), soit proportionnelle à la distance indiquée dans la matrice. Cette méthodologie est particulièrement indiquée pour visualiser les similarités et dissimilarités; elle représente un compromis entre une approche dichotomique/hiérarchique et une approche visant au continuum, ce qu’est l’AFC.
, et on dispose les résultats dans une matrice « carrée » (réduite ou non, avec ou sans diagonale). Puis, l’analyse arborée consiste à construire un graphe « arbre », où chaque variable est une feuille, où les feuilles se regroupent en rameaux, branches et troncs, de manière à figurer des clusters, mais surtout à ce que la longueur totale de tous les chemins entre feuilles (paire à paire), soit proportionnelle à la distance indiquée dans la matrice. Cette méthodologie est particulièrement indiquée pour visualiser les similarités et dissimilarités; elle représente un compromis entre une approche dichotomique/hiérarchique et une approche visant au continuum, ce qu’est l’AFC.")
104
L’analyse factorielle des correspondances.
Soit le tableau de distribution suivant (avec ses « marges ») : 80-83 84-87 88-91 92-95 TOTAL développement 3254 2785 2457 2116 1986 12598 gouvernement 4041 3038 2445 2779 3136 15439 guerre 2968 2993 3372 3241 3723 16297 marché 1770 1804 2338 2305 2410 10627 société 2025 1698 2150 2065 2899 10837 tiers-monde 1599 1385 1006 488 203 4681 travail 2056 1836 1768 2077 2911 10648 production 2493 1813 1481 1255 1157 8199 20206 17352 17017 16326 18425 89326
 : TOTAL. développement gouvernement guerre marché société tiers-monde travail production")
105
L’analyse factorielle des correspondances.
On peut lui confronter un tableau « d’indépendance », où les valeurs sont calculées dans l’hypothèse d’équirépartition 80-83 84-87 88-91 92-95 TOTAL développement 3254 2785 2457 2116 1986 12598 gouvernement 4041 3038 2445 2779 3136 15439 guerre 2968 2993 3372 3241 3723 16297 marché 1770 1804 2338 2305 2410 10627 société 2025 1698 2150 2065 2899 10837 tiers-monde 1599 1385 1006 488 203 4681 travail 2056 1836 1768 2077 2911 10648 production 2493 1813 1481 1255 1157 8199 20206 17352 17017 16326 18425 89326 contingence « correspondance » indépendance 80-83 84-87 88-91 92-95 TOTAL développement 2849,73 2447,22 2399,97 2302,52 2598,55 12598 gouvernement 3492,38 2999,1 2941,2 2821,77 3184,56 15439 guerre 3686,47 3165,77 3104,65 2978,58 3361,53 16297 marché 2403,88 2064,35 2024,49 1942,28 2192 10627 société 2451,39 2105,14 2064,5 1980,66 2235,31 10837 tiers-monde 1058,87 909,306 891,751 855,54 965,536 4681 travail 2408,63 2068,42 2028,49 1946,12 2196,33 10648 production 1854,66 1592,69 1561,95 1498,52 1691,18 8199 20206 17352 17017 16326 18425 89326

106
L’analyse factorielle des correspondances.
On peut lui confronter un tableau « d’indépendance », où les valeurs sont calculées dans l’hypothèse d’équirépartition 80-83 84-87 88-91 92-95 TOTAL développement 3254 2785 2457 2116 1986 12598 gouvernement 4041 3038 2445 2779 3136 15439 guerre 2968 2993 3372 3241 3723 16297 marché 1770 1804 2338 2305 2410 10627 société 2025 1698 2150 2065 2899 10837 tiers-monde 1599 1385 1006 488 203 4681 travail 2056 1836 1768 2077 2911 10648 production 2493 1813 1481 1255 1157 8199 20206 17352 17017 16326 18425 89326 On en déduit un tableau des écarts : 80-83 84-87 88-91 92-95 développement 404,27 337,78 57,03 -186,52 -612,55 gouvernement 548,62 38,90 -496,20 -42,77 -48,56 guerre -718,47 -172,77 267,35 262,42 361,47 marché -633,88 -260,35 313,51 362,72 218,00 société -426,39 -407,14 85,50 84,34 663,69 tiers-monde 540,13 475,69 114,25 -367,54 -762,54 travail -352,63 -232,42 -260,49 130,88 714,67 production 638,34 220,31 -80,95 -243,52 -534,18 contingence indépendance 80-83 84-87 88-91 92-95 TOTAL développement 2849,73 2447,22 2399,97 2302,52 2598,55 12598 gouvernement 3492,38 2999,10 2941,20 2821,77 3184,56 15439 guerre 3686,47 3165,77 3104,65 2978,58 3361,53 16297 marché 2403,88 2064,35 2024,49 1942,28 2192,00 10627 société 2451,39 2105,14 2064,50 1980,66 2235,31 10837 tiers-monde 1058,87 909,31 891,75 855,54 965,54 4681 travail 2408,63 2068,42 2028,49 1946,12 2196,33 10648 production 1854,66 1592,69 1561,95 1498,52 1691,18 8199 20206 17352 17017 16326 18425 89326

107
L’analyse factorielle des correspondances.
On va travailler sur le tableau des écarts, dit « T1 » 80-83 84-87 88-91 92-95 développement 404,27 337,78 57,03 -186,52 -612,55 gouvernement 548,62 38,90 -496,20 -42,77 -48,56 guerre -718,47 -172,77 267,35 262,42 361,47 marché -633,88 -260,35 313,51 362,72 218,00 société -426,39 -407,14 85,50 84,34 663,69 tiers-monde 540,13 475,69 114,25 -367,54 -762,54 travail -352,63 -232,42 -260,49 130,88 714,67 production 638,34 220,31 -80,95 -243,52 -534,18 On cherche quelles marges pourraient, par multiplication, donner un tablea aussi approchant que possible

108
L’analyse factorielle des correspondances.
Une sorte de tableau d’indépendance « dérivé » … 80-83 84-87 88-91 92-95 VECTEUR C développement 297,56693 217,98981 -10,57413 -177,32007 -364,67200 -13,91846 gouvernement 109,11482 79,93468 -3,87743 -65,02149 -133,72157 -5,10376 guerre -221,14491 -162,00502 7,85845 131,78020 271,01586 10,34388 marché -307,77042 -225,46461 10,93672 183,40032 377,17650 14,39572 société -363,99370 -266,65233 12,93463 216,90376 446,07884 17,02552 tiers-monde 1079,48704 790,80417 -38,35990 -643,26608 -1322,92489 -50,49216 travail -341,71262 -250,32979 12,14286 203,62647 418,77310 15,98334 production 484,56141 354,97710 -17,21904 -288,75003 -593,83607 -22,66498 VECTEUR L -21,37930 -15,66192 0,75972 12,73992 26,20060 On considère chaque valeur du vecteur C comme coordonnée du point ligne correspondant sur un axe bi-orienté, et chaque valeur du vecteur L comme coordonnée du point colonne correspondant :

109
L’analyse factorielle des correspondances.
L’AFC est algorithme itératif. La passe n°2 consiste à confronter T1 au tableau « calculé » 80-83 84-87 88-91 92-95 développement 404,27 337,78 57,03 -186,52 -612,55 gouvernement 548,62 38,90 -496,20 -42,77 -48,56 guerre -718,47 -172,77 267,35 262,42 361,47 marché -633,88 -260,35 313,51 362,72 218,00 société -426,39 -407,14 85,50 84,34 663,69 tiers-monde 540,13 475,69 114,25 -367,54 -762,54 travail -352,63 -232,42 -260,49 130,88 714,67 production 638,34 220,31 -80,95 -243,52 -534,18 On en déduit un tableau des écarts …. : …. T1 Calculé d’après T1 80-83 84-87 88-91 92-95 développement 106,70076 119,78882 67,59914 -9,20045 -247,87881 gouvernement 439,50409 -41,03380 -492,32069 22,25500 85,16641 guerre -497,32019 -10,76468 259,49062 130,63773 90,45194 marché -326,11157 -34,88064 302,57255 179,31633 -159,17519 société -62,39136 -140,48642 72,56871 -132,56854 217,60641 tiers-monde -539,35328 -315,11067 152,60860 275,72563 560,38938 travail -10,91967 17,90519 -272,63419 -72,74796 295,89661 production 153,78268 -134,67182 -63,72690 45,22918 59,65350 80-83 84-87 88-91 92-95 développement 297,56693 217,98981 -10,57413 -177,32007 -364,67200 gouvernement 109,11482 79,93468 -3,87743 -65,02149 -133,72157 guerre -221,14491 -162,00502 7,85845 131,78020 271,01586 marché -307,77042 -225,46461 10,93672 183,40032 377,17650 société -363,99370 -266,65233 12,93463 216,90376 446,07884 tiers-monde 1079,48704 790,80417 -38,35990 -643,26608 -1322,92489 travail -341,71262 -250,32979 12,14286 203,62647 418,77310 production 484,56141 354,97710 -17,21904 -288,75003 -593,83607

110
L’analyse factorielle des correspondances.
… sur lequel on va appliquer la même recherche des marges permettant la meilleure approximation 80-83 84-87 88-91 92-95 développement 106,70076 119,78882 67,59914 -9,20045 -247,87881 gouvernement 439,50409 -41,03380 -492,32069 22,25500 85,16641 guerre -497,32019 -10,76468 259,49062 130,63773 90,45194 marché -326,11157 -34,88064 302,57255 179,31633 -159,17519 société -62,39136 -140,48642 72,56871 -132,56854 217,60641 tiers-monde -539,35328 -315,11067 152,60860 275,72563 560,38938 travail -10,91967 17,90519 -272,63419 -72,74796 295,89661 production 153,78268 -134,67182 -63,72690 45,22918 59,65350 80-83 84-87 88-91 92-95 VECTEUR C développement -89,09875 26,01999 143,50418 21,15767 -78,05996 5,5216 gouvernement 341,03313 -99,59375 -549,27460 -80,98279 298,78124 -21,1344 guerre -208,92120 61,01239 336,49255 49,61108 -183,03716 12,9472 marché -363,69187 106,21090 585,76920 86,36341 -318,63270 22,5386 société 43,39723 -12,67353 -69,89643 -10,30524 38,02059 -2,6894 tiers-monde -313,38180 91,51858 504,73882 74,41662 -274,55573 19,4208 travail 276,51335 -80,75169 -445,35779 -65,66172 242,25506 -17,136 production 144,78546 -42,28248 -233,19428 -34,38121 126,84744 -8,9726 VECTEUR L -16,13640 4,71240 25,98960 3,83180 -14,13720

111
L’analyse factorielle des correspondances.
Une sorte de 2ème tableau d’indépendance « dérivé » … 80-83 84-87 88-91 92-95 VECTEUR C développement -89,09875 26,01999 143,50418 21,15767 -78,05996 5,5216 gouvernement 341,03313 -99,59375 -549,27460 -80,98279 298,78124 -21,1344 guerre -208,92120 61,01239 336,49255 49,61108 -183,03716 12,9472 marché -363,69187 106,21090 585,76920 86,36341 -318,63270 22,5386 société 43,39723 -12,67353 -69,89643 -10,30524 38,02059 -2,6894 tiers-monde -313,38180 91,51858 504,73882 74,41662 -274,55573 19,4208 travail 276,51335 -80,75169 -445,35779 -65,66172 242,25506 -17,136 production 144,78546 -42,28248 -233,19428 -34,38121 126,84744 -8,9726 VECTEUR L -16,13640 4,71240 25,98960 3,83180 -14,13720 On effectue la même projection qu’en 1, sur un 2ème axe, orthogonal au 1er :

112
L’analyse factorielle des correspondances.
Un système de coordonnées sur un plan de 2 « facteurs »

113
L’analyse factorielle des correspondances.
Un système de coordonnées sur un plan de 2 « facteurs »

114
L’analyse factorielle des correspondances.
Autant d’itérations (de « facteurs ») que le tableau comporte de colonnes (ou de lignes, s’il y a moins de lignes que de colonnes) – en comptant le Facteur 0, qui correspond au tableau T0 de départ. Chaque itération extrait une part décroissante de l’information totale du tableau d’origine (le total des « pourcentages d’inertie » est 100%.
 que le tableau comporte de colonnes (ou de lignes, s’il y a moins de lignes que de colonnes) – en comptant le Facteur 0, qui correspond au tableau T0 de départ. Chaque itération extrait une part décroissante de l’information totale du tableau d’origine (le total des « pourcentages d’inertie » est 100%.")
115
L’analyse factorielle des correspondances.
Un système de coordonnées sur un plan de 2 « facteurs »

116
L’analyse factorielle des correspondances.
Un système de coordonnées sur un plan de 2 « facteurs » Mais ici, avec 244 lignes et 21 colonnes, il y a 2O facteurs, dont l’histogramme indique la « décroissance » en % d’information. Le 3ème facteur mériterait d’être visualisé. Nous en reparlerons plus loin.

117
L’analyse factorielle des correspondances.
Tout tableau de données comportant des lignes décrivant des classes d’occurrences du corpus des colonnes décrivant des variables recouvrant une partie du corpus des cellules « intersections » rendant compte d’effectifs peut être soumis à l’AFC. Celle-ci classe les profils de lignes par parentés, chaque facteur extrayant successivement l’information résiduelle ; et les profils de colonnes de même, en assurant la correspondane entre les lignes et les colonnes. Moyennant certaines précautions, il s’agit de la visualisation synthétique la plus fidèle des informations dominantes d’une matrice de données de cet ordre. Le résultat de l’AFC est un (double) nuage de points, chaque point ayant ses coordonnées sur N axes orthogonaux (dans un espace à N dimensions), autant qu’il y a de facteurs.
 nuage de points, chaque point ayant ses coordonnées sur N axes orthogonaux (dans un espace à N dimensions), autant qu’il y a de facteurs.")
118
L’analyse factorielle des correspondances.
Les applications sont nombreuses et variées. En statistique lexicale et plus largement : textuelle, les lignes sont généralement des types, formes graphiques, lemmes, indices grammaticaux, codes sémantiques attribués… les colonnes peuvent renvoyer à des partitions linéaires (chapitres d’ouvrages, tranches diachroniques, des auteurs/locuteurs, des classes d’auteurs, des rubriques de presse, des CSP… classiquement des critères considérés comme non textuels, « exogènes ». Mais Max Reinert, avec Alceste, avait déjà institué en colonnes des unités vraiment textuelles (UT), constituées de phrases ou de membres de phrases (le tableau avait alors un très grand nombre de colonnes, et Alceste procédait à un classification hiérarchique avant de se risquer à une AFC sur des données simplifiées). Viprey (1996) a proposé de constituer des tableaux « carrés », constitués de colonnes identiques aux lignes. A l’intersection, le nombre de co-occurrences entre deux formes, deux lemmes… dans un empan cotextuel paramétrable.
, constituées de phrases ou de membres de phrases (le tableau avait alors un très grand nombre de colonnes, et Alceste procédait à un classification hiérarchique avant de se risquer à une AFC sur des données simplifiées). Viprey (1996) a proposé de constituer des tableaux « carrés », constitués de colonnes identiques aux lignes. A l’intersection, le nombre de co-occurrences entre deux formes, deux lemmes… dans un empan cotextuel paramétrable.")
119
Exemple : 12 formes fréquentes dans Mondiplo
AFC des cooccurrences Exemple : 12 formes fréquentes dans Mondiplo culture 5194 dollars 9691 élections 4402 fonds 3991 liberté 4385 libertés 1176 parti 12814 production 8199 ressources 3557 social 5197 société 10837 sociétés 4714 Balayage de l’ensemble du corpus à la recherche des cooccurrences entre ces 12 formes, dans les limites de 15 mots à gauche et à droite, et dans les limites de la phrase (ponctuation forte) culture dollars élections fonds liberté libertés parti partis production ressources social société sociétés 358 7 1 15 32 11 18 42 13 39 129 1598 4 181 91 46 12 57 84 6 357 132 5 154 21 10 26 63 45 24 376 38 55 44 2 1566 242 17 114 141 146 54 306 62 49 87 77 60 19 37 82 90 40 426 56 158
 culture. dollars. élections. fonds. liberté. libertés. parti. partis. production. ressources. social. société. sociétés")
120
Ecarts à l’indépendance (tableau T1) La diagonale est neutralisée
AFC des cooccurrences Ecarts à l’indépendance (tableau T1) La diagonale est neutralisée culture dollars élections fonds liberté libertés parti partis production ressources social société sociétés 0,0000 -4,1619 -5,7677 -2,0373 4,0435 1,8438 -5,8313 -2,9481 3,0365 -1,1214 2,2954 13,6626 2,6713 -4,1138 -6,3436 26,1306 -3,9473 -2,6466 -8,0158 -5,0032 9,2681 4,5638 -4,3563 -0,4877 5,6788 -5,6659 -6,3045 -5,4651 -1,4844 0,6354 30,1856 12,6993 -6,5914 -4,4091 -5,8780 -7,3452 -5,6298 -2,0243 26,2676 -5,5278 -3,5873 -2,8003 -6,4969 -4,6319 -1,1713 9,3082 2,1514 -4,2788 1,5607 4,0702 -4,0198 -1,5210 -3,6341 14,8675 1,4158 -1,2846 -3,8726 -0,7754 -0,1248 3,6982 0,5285 1,8826 -2,7338 0,6604 -2,8774 15,0805 -1,8658 -1,5283 -3,0058 -2,3978 1,2372 1,2400 -1,7676 -5,4862 -7,6296 28,9093 -6,1516 1,3233 -1,7193 17,2584 -6,9917 -4,8229 4,1535 1,3945 -7,1811 -2,9033 -4,9849 12,7313 -4,5909 -1,2568 -1,4742 18,0658 -5,5923 -4,4464 -2,4210 -1,5378 -4,9145 3,0076 9,2870 -6,6459 -1,1676 -3,8106 -2,9159 -7,3607 -5,6243 8,3426 2,2761 4,1252 10,0786 -1,1263 4,6376 -4,5082 9,4094 -0,7737 -2,3589 -5,1490 -4,5349 8,4602 -0,9655 -0,1306 2,1281 2,2715 -4,3614 -5,9213 2,1427 -0,1227 1,1992 4,3689 -2,4327 2,2741 -0,9513 4,3256 2,5427 13,1711 -0,4757 -7,2081 -4,1513 3,5418 1,1708 1,4289 -1,5053 4,0151 -0,1254 4,2139 1,9331 2,6722 5,7472 -5,7329 1,5712 0,5252 -1,7319 -7,6355 -4,9920 10,1791 2,1194 2,5703 2,0059
 La diagonale est neutralisée. culture. dollars. élections. fonds. liberté. libertés. parti. partis. production. ressources. social. société. sociétés. 0, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ,0059.")
121
AFC des cooccurrences Comparaison des profils cooccurrentiels de élections et parti

122
AFC des cooccurrences Comparaison des profils cooccurrentiels de liberté et culture

123
AFC des cooccurrences Comparaison des profils cooccurrentiels de dollars et parti

124
AFC des cooccurrences Plan des 2 premiers facteurs

125
AFC des cooccurrences 244 formes lexicales les plus fréquentes, empan 15g/15d limite de phrase. Plan des 2 premiers facteurs (23 % de l’inertie).
.")
126
AFC des cooccurrences 244 formes lexicales les plus fréquentes, empan 15g/15d limite de phrase Inerties cumulées des facteurs 1 et 2 : 23 % Visualiser l’ensemble des 3 premiers facteurs donnerait une meilleure approximation (Cibois 1994:85) Nuage très enchevêtré Centre du nuage encombré de points
 Nuage très enchevêtré. Centre du nuage encombré de points.")
127
Visualisation des 3 premiers facteurs
On visualise classiquement le plan de 2 facteurs (1/2, 1/3, 2/3..) Les tentatives « 3D », « MacSpin »… aboutissent à des visualisations erronées (et non plus « approximatives » ! nuage vu de l’extérieur avec des superpositions trompeuses) Rappel : en AFC, tous les axes représentant les facteurs sont orthogonaux (dans certaines autres méthodes, ils peuvent présenter des angles différents). Donc, si l’on prend pour point de départ le plan des 2 premiers facteurs, on conçoit aisément que l’axe du 3ème facteur coupe celui-ci à angle droit, « verticalement », de part en part. Ensemble, les 3 axes orthogonaux constituent un repère « sphérique » Le nuage s’inscrit dans une boule. Une boule ne peut être représentée sur le plan d’une feuille de papier ou d’un écran que par un planisphère.
 Les tentatives « 3D », « MacSpin »… aboutissent à des visualisations erronées (et non plus « approximatives » ! nuage vu de l’extérieur avec des superpositions trompeuses) Rappel : en AFC, tous les axes représentant les facteurs sont orthogonaux (dans certaines autres méthodes, ils peuvent présenter des angles différents). Donc, si l’on prend pour point de départ le plan des 2 premiers facteurs, on conçoit aisément que l’axe du 3ème facteur coupe celui-ci à angle droit, « verticalement », de part en part. Ensemble, les 3 axes orthogonaux constituent un repère « sphérique » Le nuage s’inscrit dans une boule. Une boule ne peut être représentée sur le plan d’une feuille de papier ou d’un écran que par un planisphère.")
128
Visualisation des 3 premiers facteurs
Une boule ne peut être représentée sur le plan d’une feuille de papier ou d’un écran que par un planisphère. Inertie cumulée visualisée : 31%

129
Visualisation des 3 premiers facteurs
Une boule ne peut être représentée sur le plan d’une feuille de papier ou d’un écran que par un planisphère. Inertie cumulée visualisée : 31%

130
Visualisation des 3 premiers facteurs
Zoom « régional »

131
Visualisation des 3 premiers facteurs
Les fortes contributions au facteur 1 :

132
Visualisation des 3 premiers facteurs
Les fortes contributions au facteur 2 :

133
Visualisation des 3 premiers facteurs
Les fortes contributions au facteur 3 :

134
Visualisation des 3 premiers facteurs
Marquage des formes excédentaires en 1980 :

135
Visualisation des 3 premiers facteurs
Marquage des formes excédentaires (bleu) et déficitaires (rouge) en 1980 :
 et déficitaires (rouge) en 1980 :")
136
Visualisation des 3 premiers facteurs
Marquage des formes excédentaires (bleu) et déficitaires (rouge) en 2000 :
 et déficitaires (rouge) en 2000 :")
137
Visualisation des 3 premiers facteurs
Marquage des formes excédentaires sur (rouge), (magenta), (bleu), (vert) :
, (magenta), (bleu), (vert) :")
138
Retour à la 1ère application
Marquage des formes excédentaires sur CBLP (rouge), CPTP (magenta), CGSR (bleu), PPOCO (vert) :
, CPTP (magenta), CGSR (bleu), PPOCO (vert) :")
139
Conclusions Les statistiques lexicales offrent deux voies qui peuvent diverger fortement ou au contraire être maintenues parallèles par l’effort de l’analyste. Démarche hypothético-déductive, où l’on cherche à valider et raffiner une hypothèse par test(s) probatoire(s), oui/non Démarche exploratoire, où la seule « hypothèse » est au fond qu’un discours dans son organisation textuelle s’écarte en tous points des modalités de l’aléatoire et de l’équidistribution.
 probatoire(s), oui/non. Démarche exploratoire, où la seule « hypothèse » est au fond qu’un discours dans son organisation textuelle s’écarte en tous points des modalités de l’aléatoire et de l’équidistribution.")
140
Conclusions L’essentiel de cette démarche consiste à mesurer des écarts, locaux, régionaux, globaux, individuels et/ou corrélés, à deux modèles : aléatoire, equidistributif. Une fois mesurés, ils sont pondérés et rapportés pour l’essentiel à des probabilités (donc, à des issues diverses pour l’interprétation et à des poursuites bifurcantes). C’est pourquoi, même si en droit certaines techniques et formules ne peuvent être dites probabilistes, l’ensemble qu’elles forment autour des objets textuels pour éclairer le discours est une démarche probabiliste.
. C’est pourquoi, même si en droit certaines techniques et formules ne peuvent être dites probabilistes, l’ensemble qu’elles forment autour des objets textuels pour éclairer le discours est une démarche probabiliste.")
Présentations similaires