Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Informatique parallèle IP 07 : La charge de travail et l’évaluation de performance

2
Le problème

3
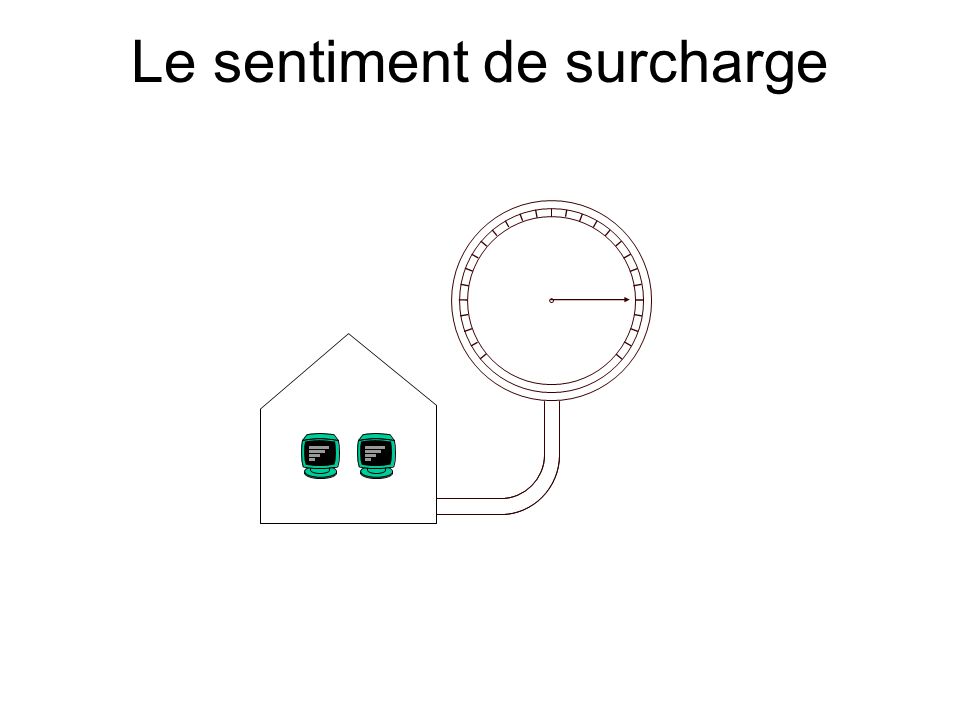
La charge de travail La charge de travail, nous en avons de façon naturelle une sensation. Nous constatons de façon intuitive qu’un système surchargé n’a pas un fonctionnement optimal pas plus qu’un système sous-chargé. Il existe donc une (zone de) charge de travail où le rendement du système est maximum et cette zone est lié à la capacité de travail du système.
 charge de travail où le rendement du système est maximum et cette zone est lié à la capacité de travail du système..")
4
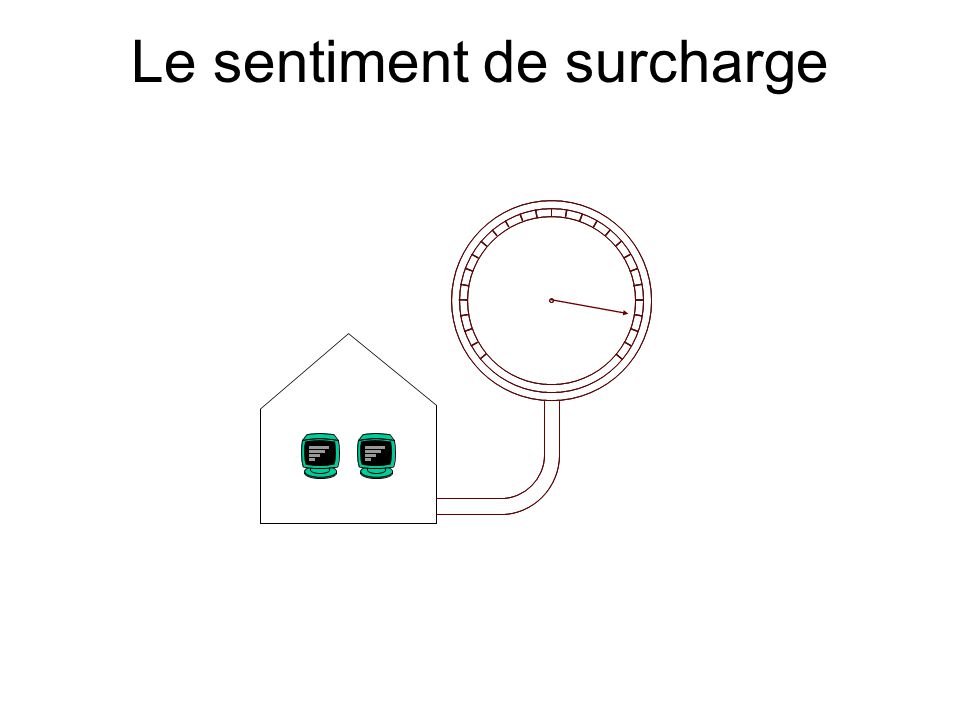
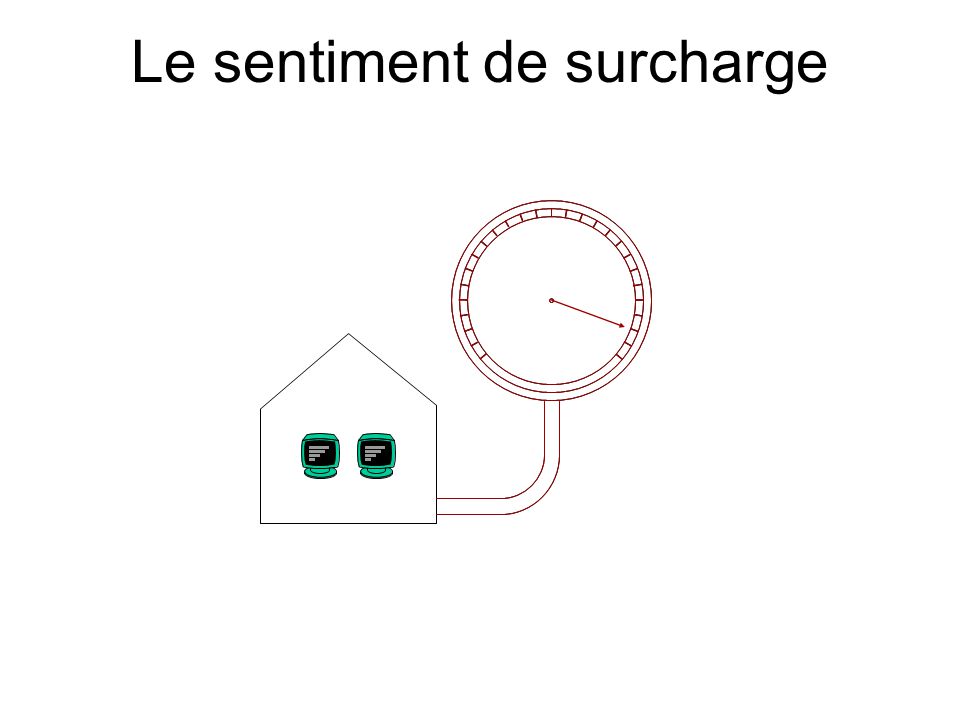
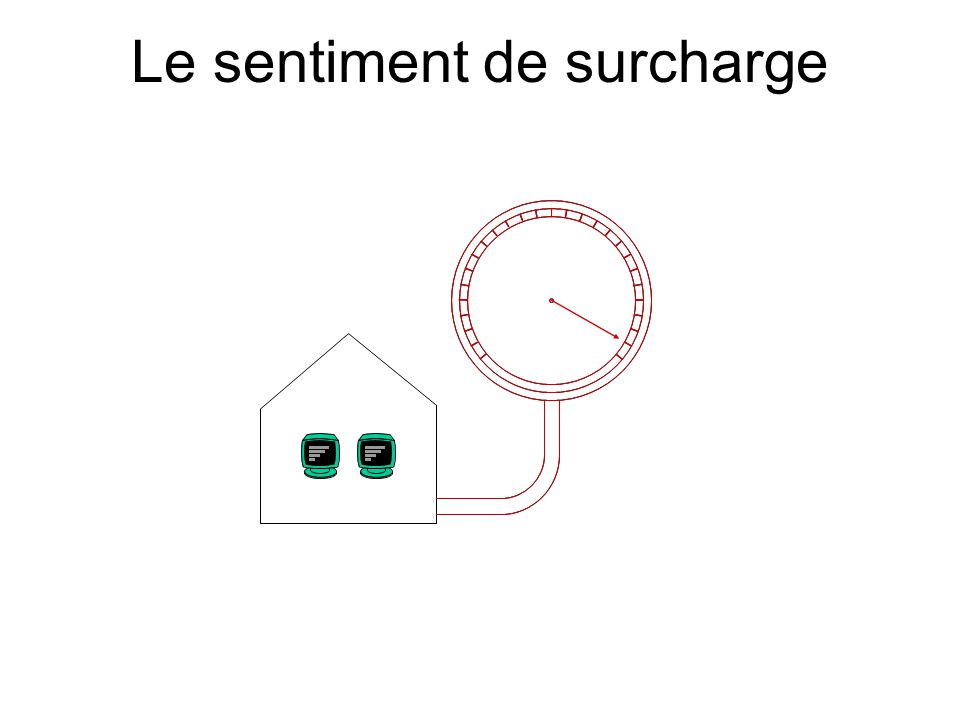
Le sentiment de surcharge

12
La charge de travail La charge de travail, nous en avons de façon naturelle une sensation. Nous constatons de façon intuitive qu’un système surchargé n’a pas un fonctionnement optimal pas plus qu’un système sous-chargé. Il existe donc une (zone de) charge de travail où le rendement du système est maximum et cette zone est lié à la capacité de travail du système. Pour trouver cette relation, nous devons : 1. Caractériser la charge de travail (analyser le workload) 2. Modéliser la charge de travail 2. Etudier la réponse du système en fonction de différents modèle de workload pour (peut être) en déduire une relation avec la capacité
 charge de travail où le rendement du système est maximum et cette zone est lié à la capacité de travail du système. Pour trouver cette relation, nous devons : 1. Caractériser la charge de travail (analyser le workload) 2. Modéliser la charge de travail 2. Etudier la réponse du système en fonction de différents modèle de workload pour (peut être) en déduire une relation avec la capacité.")
13
Caractériser le workload

14
Etat de l’art 1978 : Ferrari propose une technique d’analyse de workload en vue de construire puis de valider un modèle de comportement des utilisateurs La plupart des travaux d’analyse de workload concerne les machines à mémoire partagée (voir page « workload » de D. Feitelson). L’une des études les plus complètes concerne la machines iPSC/860 de la NASA effectuée par Feitelson en 1995. D. Ferrari – Workload Characterization and Selection in Computer Performance Measurement – IEEE Computer – Volume 5, n°4 – p. 18-24 – 1972 D. Feitelson et B. Nitzberg – Job characteristics of a production parallel scientific workload on the NASA Ames iPSC/ 860 – In Proceedings of IPPS '95 Workshop on Job Scheduling Strategies for Parallel Processing – p. 215-227 – Avril 1995 – http://citeseer.nj.nec.com/ feitelson95job.html D. Feitelson – Parallel Workloads Archive – http://www.cs.huji.ac.il/labs/parallel/workload/
. L’une des études les plus complètes concerne la machines iPSC/860 de la NASA effectuée par Feitelson en D. Ferrari – Workload Characterization and Selection in Computer Performance Measurement – IEEE Computer – Volume 5, n°4 – p – 1972 D. Feitelson et B. Nitzberg – Job characteristics of a production parallel scientific workload on the NASA Ames iPSC/ 860 – In Proceedings of IPPS 95 Workshop on Job Scheduling Strategies for Parallel Processing – p – Avril 1995 – feitelson95job.html D. Feitelson – Parallel Workloads Archive –")
15
Etude de cas : le workload d’I-cluster Analyse de logs du serveur PBS situé dans le frontal d’I-cluster 3 files d’attentes en fonction du nombre de machines demandées : les travaux sur au plus 6 processeurs (durée par défaut 6h) ; les travaux utilisant entre 7 et 10 processeurs (durée par défaut 12h) ; les travaux nécessitant plus de 10 processeurs (durée par défaut 24h).
 ; les travaux utilisant entre 7 et 10 processeurs (durée par défaut 12h) ; les travaux nécessitant plus de 10 processeurs (durée par défaut 24h).")
16
Exemple de log de PBS 03/13/2002 10:09:04;E;570.nis-grappes;user=ecaron group=vthd jobname=STDIN queue=Workq1 ctime=1016008284 qtime=1016008284 etime=1016008284 start=1016008287 exec_host=icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=1 Resource_List.nodect=1 Resource_List.nodes=1 Resource_List.walltime=06:00:00 session=28065 end=1016010544 Exit_status=0 resources_used.cput=00:00:00 resources_used.mem=3644kb resources_used.vmem=7300kb resources_used.walltime=00:37:38 03/13/2002 10:16:03;Q;572.nis-grappes;queue=Rting 03/13/2002 10:16:03;Q;572.nis-grappes;queue=Workq1 03/13/2002 10:42:21;Q;573.nis-grappes;queue=Rting 03/13/2002 10:42:21;Q;573.nis-grappes;queue=Workq1 03/13/2002 10:42:24;S;573.nis-grappes;user=ecaron group=vthd jobname=STDIN queue=Workq1 ctime=1016012541 qtime=1016012541 etime=1016012541 start=1016012544 exec_host=icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=1 Resource_List.nodect=1 Resource_List.nodes=1 Resource_List.walltime=06:00:00 03/13/2002 10:44:09;E;573.nis-grappes;user=ecaron group=vthd jobname=STDIN queue=Workq1 ctime=1016012541 qtime=1016012541 etime=1016012541 start=1016012544 exec_host=icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=1 Resource_List.nodect=1 Resource_List.nodes=1 Resource_List.walltime=06:00:00 session=28244 end=1016012649 Exit_status=0 resources_used.cput=00:00:00 resources_used.mem=3668kb resources_used.vmem=7336kb resources_used.walltime=00:01:48 03/13/2002 10:44:48;D;517.nis-grappes;requestor=mgeups@icluster2 03/13/2002 10:44:53;D;518.nis-grappes;requestor=mgeups@icluster2 03/13/2002 10:44:53;E;517.nis-grappes;user=mgeups group=equipar jobname=runXMLClient.pb queue=Workq2 ctime=1015862679 qtime=1015862679 etime=1015862679 start=1015862681 exec_host=icluster152/0+icluster151/0+icluster149/0+icluster147/0+icluster146/0+icluster144/0+icluster143/0+icluster1 42/0+icluster141/0+icluster140/0+icluster139/0+icluster138/0+icluster136/0+icluster135/0+icluster134/0+icluster133/0+ icluster132/0+icluster131/0+icluster130/0+icluster129/0 Resource_List.ncpus=1 Resource_List.neednodes=20 Resource_List.nodect=20 Resource_List.nodes=20 Resource_List.walltime=72:00:00 session=30306 end=1016012693 Exit_status=143 resources_used.cput=00:00:00 resources_used.mem=13096kb resources_used.vmem=29464kb resources_used.walltime=41:40:12 03/13/2002 10:44:58;S;567.nis-grappes;user=etchever group=vthd jobname=script.pbs queue=Workq1 ctime=1015950309 qtime=1015950309 etime=1015950309 start=1016012698 exec_host=icluster130/0+icluster129/0+icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=3 Resource_List.nodect=3 Resource_List.nodes=3 Resource_List.walltime=100:00:00

17
Exemple de log de PBS 03/13/2002 10:09:04;E;570.nis-grappes;user=ecaron group=vthd jobname=STDIN queue=Workq1 ctime=1016008284 qtime=1016008284 etime=1016008284 start=1016008287 exec_host=icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=1 Resource_List.nodect=1 Resource_List.nodes=1 Resource_List.walltime=06:00:00 session=28065 end=1016010544 Exit_status=0 resources_used.cput=00:00:00 resources_used.mem=3644kb resources_used.vmem=7300kb resources_used.walltime=00:37:38 03/13/2002 10:16:03;Q;572.nis-grappes;queue=Rting 03/13/2002 10:16:03;Q;572.nis-grappes;queue=Workq1 03/13/2002 10:42:21;Q;573.nis-grappes;queue=Rting 03/13/2002 10:42:21;Q;573.nis-grappes;queue=Workq1 03/13/2002 10:42:24;S;573.nis-grappes;user=ecaron group=vthd jobname=STDIN queue=Workq1 ctime=1016012541 qtime=1016012541 etime=1016012541 start=1016012544 exec_host=icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=1 Resource_List.nodect=1 Resource_List.nodes=1 Resource_List.walltime=06:00:00 03/13/2002 10:44:09;E;573.nis-grappes;user=ecaron group=vthd jobname=STDIN queue=Workq1 ctime=1016012541 qtime=1016012541 etime=1016012541 start=1016012544 exec_host=icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=1 Resource_List.nodect=1 Resource_List.nodes=1 Resource_List.walltime=06:00:00 session=28244 end=1016012649 Exit_status=0 resources_used.cput=00:00:00 resources_used.mem=3668kb resources_used.vmem=7336kb resources_used.walltime=00:01:48 03/13/2002 10:44:48;D;517.nis-grappes;requestor=mgeups@icluster2 03/13/2002 10:44:53;D;518.nis-grappes;requestor=mgeups@icluster2 03/13/2002 10:44:53;E;517.nis-grappes;user=mgeups group=equipar jobname=runXMLClient.pb queue=Workq2 ctime=1015862679 qtime=1015862679 etime=1015862679 start=1015862681 exec_host=icluster152/0+icluster151/0+icluster149/0+icluster147/0+icluster146/0+icluster144/0+icluster143/0+icluster1 42/0+icluster141/0+icluster140/0+icluster139/0+icluster138/0+icluster136/0+icluster135/0+icluster134/0+icluster133/0+ icluster132/0+icluster131/0+icluster130/0+icluster129/0 Resource_List.ncpus=1 Resource_List.neednodes=20 Resource_List.nodect=20 Resource_List.nodes=20 Resource_List.walltime=72:00:00 session=30306 end=1016012693 Exit_status=143 resources_used.cput=00:00:00 resources_used.mem=13096kb resources_used.vmem=29464kb resources_used.walltime=41:40:12 03/13/2002 10:44:58;S;567.nis-grappes;user=etchever group=vthd jobname=script.pbs queue=Workq1 ctime=1015950309 qtime=1015950309 etime=1015950309 start=1016012698 exec_host=icluster130/0+icluster129/0+icluster19/0 Resource_List.ncpus=1 Resource_List.neednodes=3 Resource_List.nodect=3 Resource_List.nodes=3 Resource_List.walltime=100:00:00 Construire une moulinette qui construit une liste d’objets logPBS en se basant d’abord sur leur identifiant puis sur l’événement (D,Q,S,E) daté pour traiter le reste des informations
 daté pour traiter le reste des informations")
18
Exemple de log de PBS 03/13/2002 10:44:53;E;517.nis-grappes;user=mgeups group=equipar jobname=runXMLClient.pb queue=Workq2 ctime=1015862679 qtime=1015862679 etime=1015862679 start=1015862681 exec_host=icluster152/0+icluster151/0+icluster149/0+icluster147/0+icluster146/0+iclu ster144/0+icluster143/0+icluster142/0+icluster141/0+icluster140/0+icluster139/0+iclu ster138/0+icluster136/0+icluster135/0+icluster134/0+icluster133/0+icluster132/0+iclu ster131/0+icluster130/0+icluster129/0 Resource_List.ncpus=1 Resource_List.neednodes=20 Resource_List.nodect=20 Resource_List.nodes=20 Resource_List.walltime=72:00:00 session=30306 end=1016012693 Exit_status=143 resources_used.cput=00:00:00 resources_used.mem=13096kb resources_used.vmem=29464kb resources_used.walltime=41:40:12 On extrait d’autres informations comme - le nom du job, - le nom de l’utilisateur, - la durée du travail … pour les placer dans la structure de données

19
Quelques résultats d’analyse Environ 9332 travaux soumis sur 1 an … ce qui représente 1828 jours de temps CPU

20
Quelques résultats d’analyse

22
Prédominance de certains nombres caractéristiques, on affine l’étude

23
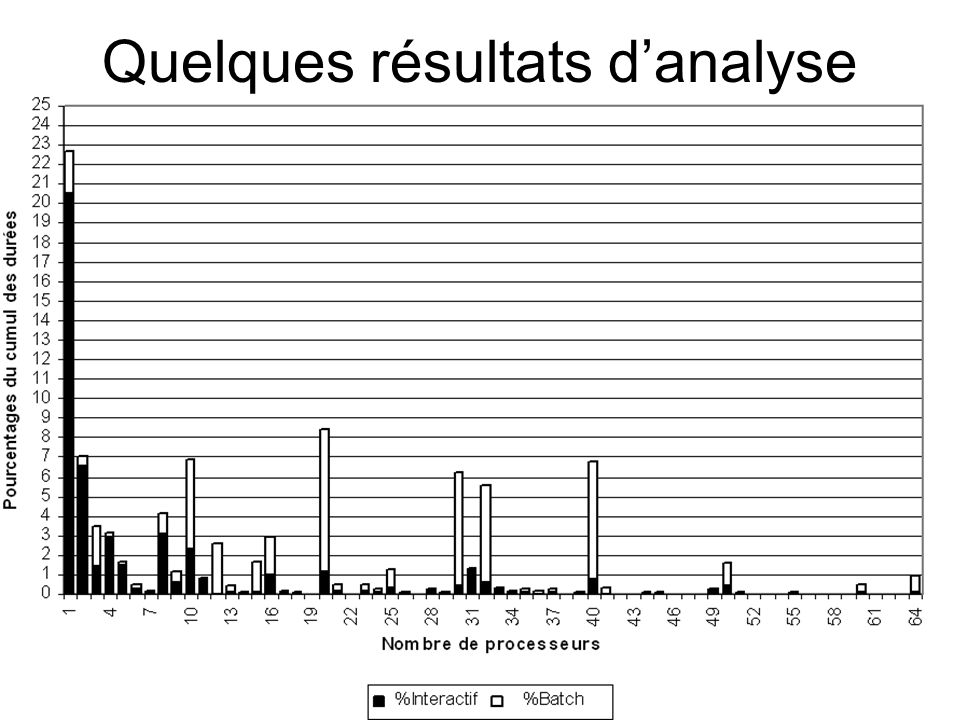
Quelques résultats d’analyse Après avoir regardé le nombre de processeurs utilisés, on caractérise le type d’utilisateur : On en déduit 3 classes d’utilisateurs (batch, interactif et équilibré) à qui on fait correspondre 3 pourcentages de travaux interactifs
 à qui on fait correspondre 3 pourcentages de travaux interactifs")
24
Quelques résultats d’analyse Puis on regarde l’influence du mois, du jour et de l’heure : Influence des stagiaires ?

25
Quelques résultats d’analyse Puis on regarde l’influence du mois, du jour et de l’heure : Influence des stagiaires ? Proximité des conférences ?

26
Quelques résultats d’analyse Puis on regarde l’influence du mois, du jour et de l’heure :

27
Quelques résultats d’analyse Puis on regarde l’influence du mois, du jour et de l’heure : On lance des gros travaux en fin de semaine pour récupérer les résultats le lundi matin

28
Quelques résultats d’analyse Puis on regarde l’influence du mois, du jour et de l’heure :

29
Quelques résultats d’analyse Puis on regarde l’influence du mois, du jour et de l’heure : On lance des gros travaux pour récupérer les résultats l’après-midi ou le lendemain

30
Quelques résultats d’analyse On regarde d’autres critère comme la durée entre deux soumission de travaux, …

31
Quelques résultats d’analyse Faire attention aux biais introduits par le système … la répartition des durée des travaux

32
Modéliser le workload

33
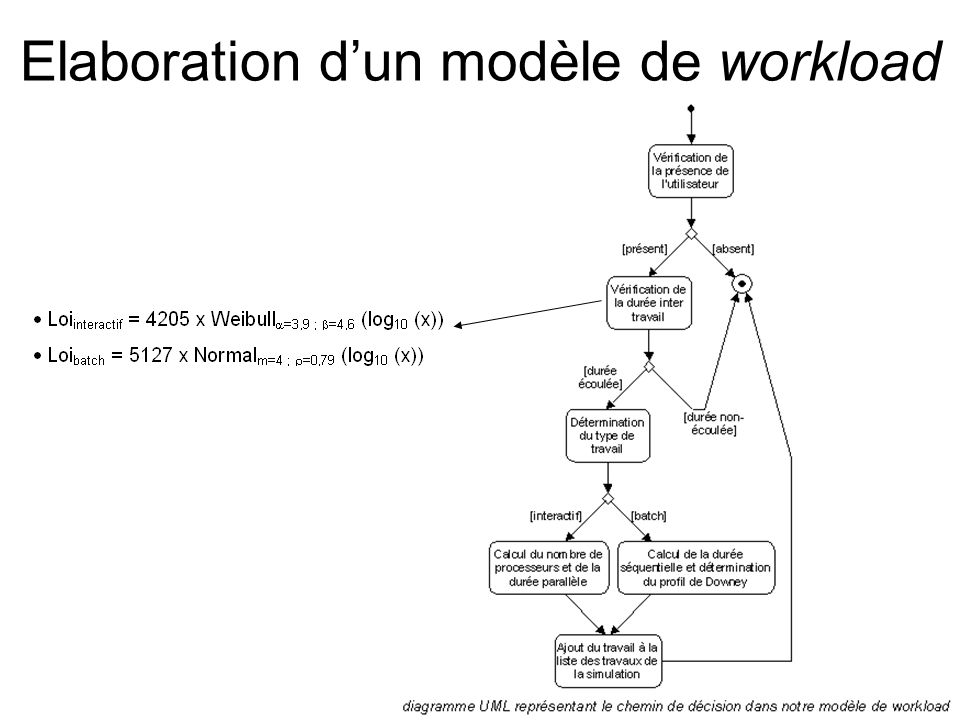
Elaboration d’un modèle de workload On implante un générateur de travaux qui simule le comportement de n utilisateurs (un utilisateur par thread) dont le comportement est modélisé par le diagramme état-transition ci-contre.
 dont le comportement est modélisé par le diagramme état-transition ci-contre.")
34
Elaboration d’un modèle de workload

37
Les 29% restants sont répartis en respectant les proportions ci-dessous :

38
Elaboration d’un modèle de workload Les travaux moldulables ne sont pas utilisés et/ou n’apparaissent pas dans les logs (on ne voit que l’exécution réelles sur un nombre de processeurs donnés) On recherche des travaux qui ont été soumis plusieurs fois sur différents nombres de processeurs afin de construire des pseudo travaux Modulables en utilisant un modèle d’accélération de Downey « modifié »
 On recherche des travaux qui ont été soumis plusieurs fois sur différents nombres de processeurs afin de construire des pseudo travaux Modulables en utilisant un modèle d’accélération de Downey « modifié »")
39
Le modèle d’accélération de Downey On considère: A, le parallélisme moyen ; V, la variance du parallélisme avec Un modèle à forte variance Un modèle à faible variance ( ) Downey proposes deux modèles:
 Downey proposes deux modèles:")
40
Le modèle d’accélération de Downey

41
Et les tailles particulières des travaux ? Jobs monoprocesseurs ; Jobs utilisant 2 n processeurs (2,4, … 128); Jobs utilisant 2 n +1 processeurs (3,5 … 129); Jobs utilisant n 2 processeurs (4,9 … 225); Jobs utilisant n 2 +1 processeurs (5,10 … 197); Jobs utilisant 10n processeurs (10,20 … 220); Jobs utilisant 10n+1 processeurs (11,21 … 221); Les autres jobs. On peut regrouper les travaux selon le nombre de processeurs utilisés :
; Jobs utilisant 2 n +1 processeurs (3,5 … 129); Jobs utilisant n 2 processeurs (4,9 … 225); Jobs utilisant n 2 +1 processeurs (5,10 … 197); Jobs utilisant 10n processeurs (10,20 … 220); Jobs utilisant 10n+1 processeurs (11,21 … 221); Les autres jobs. On peut regrouper les travaux selon le nombre de processeurs utilisés :.")
42
Et les tailles particulières des travaux ? On a constaté les répartitions suivantes : Les puissances de 2 representent 33,92% des soumissions; Les jobs monoprocessors regroupent 17,28% des soumissions; Les multiples de 10 concernent 16,41% des soumissions. Les multiples de 10 occupent 29,54% du temps de traitement; Les jobs monoprocessors utilisent 22,73% du temps de traitement; Les puissances de 2 occupent 21,73% du temps de traitement.

43
Modeling the speedup Nombre of processeurs Speedup

44
Probable scenario of moldable jobs submission Transformation procedure : 1. Separation of interactive sessions and batches Considered as rigid job Considered as an instance of a moldable job

45
Probable scenario of moldable jobs submission Transformation procedure : 1. Separation of interactive sessions and batches 2. Gathering of batches of each user, determination of decreasing section in the curve corresponding to the mean execution time

46
Évaluer la performance

47
Mettre en place un banc de test User Scheduling Service Information in XML format providing by Ganglia sensors Cluster IXI server Cluster Managing Service Mailing Service Monitoring Service Storing Service Connecting Service Internet Incoming mails server (POP3…) IXI client Internet Incoming mails server (POP3…) IXI client
 IXI client Internet Incoming mails server (POP3…) IXI client")
48
Mettre en place un banc de test User Scheduling Service IXI server Cluster Managing Service Monitoring Service Mailing Service Storing Service Connecting Service Information in XML format providing by Ganglia sensors Cluster Information in XML format providing by Ganglia sensors Cluster

49
User Information in XML format providing by Ganglia sensors Cluster Scheduling Service IXI server Cluster Managing Service Monitoring Service Mailing Service Storing Service Connecting Service Information in XML format providing by Ganglia sensors Cluster Mettre en place un banc de test Scientist Gantt’s diagram analyzer Parallel machine simulator Information in XML format providing by the simulator of ganglia sensors Scheduling service tester Workload generator

50
Méthodologie 1. Formalisation du problème définir l’objectif (sous forme de question) définition précise du système étudié 2. Formalisation de l’ensemble des réponse du système (que peut-on observer ?) 3. Choisir les critères d’analyse 4. Description des paramètres 5. Sélection des facteurs à étudier (les paramètres qu’on fait varier) 6. Choix d’une méthode d’évaluation mesure sur un prototype ou sur système en production : développement d’un banc de test benchmarking : mesure sur une application synthétique : par ex. ping-pong pour le réseau simulation : par ex. QNAP pour simuler un système qui fonctionne comme des files d’attente méthode formelle : certifier, dimensionner, étudier l’impact de facteur, …
 définition précise du système étudié 2. Formalisation de l’ensemble des réponse du système (que peut-on observer ) 3. Choisir les critères d’analyse 4. Description des paramètres 5. Sélection des facteurs à étudier (les paramètres qu’on fait varier) 6. Choix d’une méthode d’évaluation mesure sur un prototype ou sur système en production : développement d’un banc de test benchmarking : mesure sur une application synthétique : par ex. ping-pong pour le réseau simulation : par ex. QNAP pour simuler un système qui fonctionne comme des files d’attente méthode formelle : certifier, dimensionner, étudier l’impact de facteur, ….")
51
Méthodologie 7. Construire le plan d’expérience définir les différents scénarii d’expérience (un par ensemble de paramètres) pour chaque scénario, calculer le nombre d’essais à réaliser On veut donner un résultat avec une marge d’erreur (à r%) ce qui correspond à un intervalle de confiance de 100 (1 - )%. Pour atteindre cet objectif, nous devons réaliser n expériences: avec est une fonction tabulée : ( =90) = 1,64 ;( =95) = 1,96 ;( =99) = 2,58 Pour calculer et, nous devons faire quelques essais puis calculer la moyenne et l’écart-type des mesures obtenues (on suppose que les essais « erronés » se distribue selon une loi normale autour de la « vraie » valeur).
 pour chaque scénario, calculer le nombre d’essais à réaliser On veut donner un résultat avec une marge d’erreur (à r%) ce qui correspond à un intervalle de confiance de 100 (1 - )%. Pour atteindre cet objectif, nous devons réaliser n expériences: avec est une fonction tabulée : ( =90) = 1,64 ;( =95) = 1,96 ;( =99) = 2,58 Pour calculer et, nous devons faire quelques essais puis calculer la moyenne et l’écart-type des mesures obtenues (on suppose que les essais « erronés » se distribue selon une loi normale autour de la « vraie » valeur)..")
52
Méthodologie 8. Faire l’expérience (maîtriser les conditions expérimentales spécifiées précédemment) 9. Analyser les résultats et les présenter 10. Présenter les résultats (voir checklist pour faire de bon graphiques)
 9. Analyser les résultats et les présenter 10. Présenter les résultats (voir checklist pour faire de bon graphiques).")
53
Interpréter les résultats

54
L’influence de la taille des batchs

55
Comparaison modulable-rigide

56
L’importance des paramètres

57
Vers un nouveau modèle d’accélération de Downey Number of processors Speedup

Présentations similaires











 Biomarqueurs IHC (n = 412) Séquençage (n = 418) 200 patients évaluables pour les facteurs pronostiques cliniques et biologiques Comparaison.>")









