Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Introduction à la Bioinformatique (2)
SIB Institut Suisse de Bioinformatique Groupe Swiss-Prot Novembre 2013

3
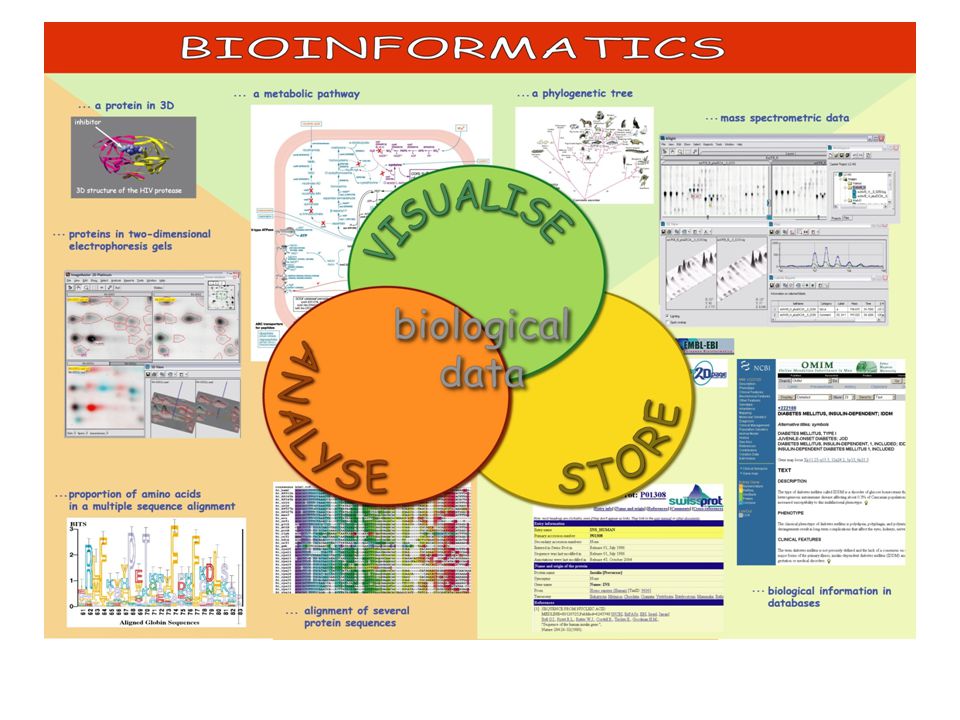
Indispensible for bioinformatic studies
Databases (free access on the web) Software tools Servers
 Software tools. Servers.")
4
Selected categories of life sciences databases
Nucleotide sequences Genomics Mutation/polymorphism Protein sequences Protein domain/family Proteomics (2D gel, Mass Spectrometry) 3D structure Metabolism/Pathways Bibliography Others
 3D structure. Metabolism/Pathways. Bibliography. Others.")
5
Coding Sequence (CDS) Du génome (inclus les variants SNPs), à la protéine, 3D, fonction , …médicament
 Du génome (inclus les variants SNPs), à la protéine, 3D, fonction , …médicament.")
6
Indispensible for bioinformatic studies
Databases (free access on the web) Software tools Servers
 Software tools. Servers.")
7
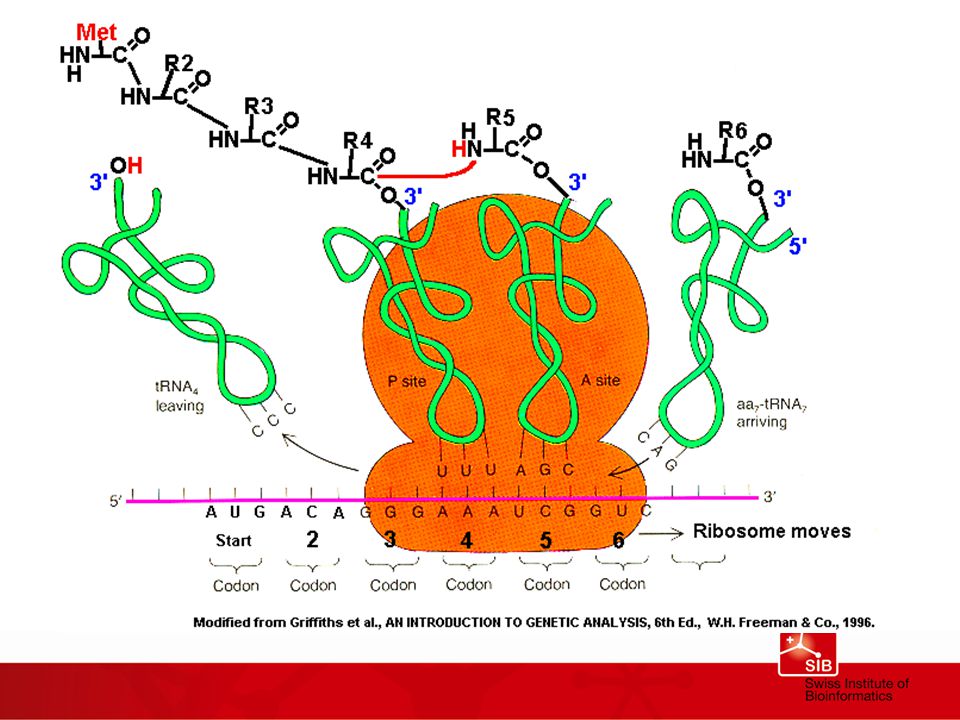
Analyse des séquences ADN et ARN

8
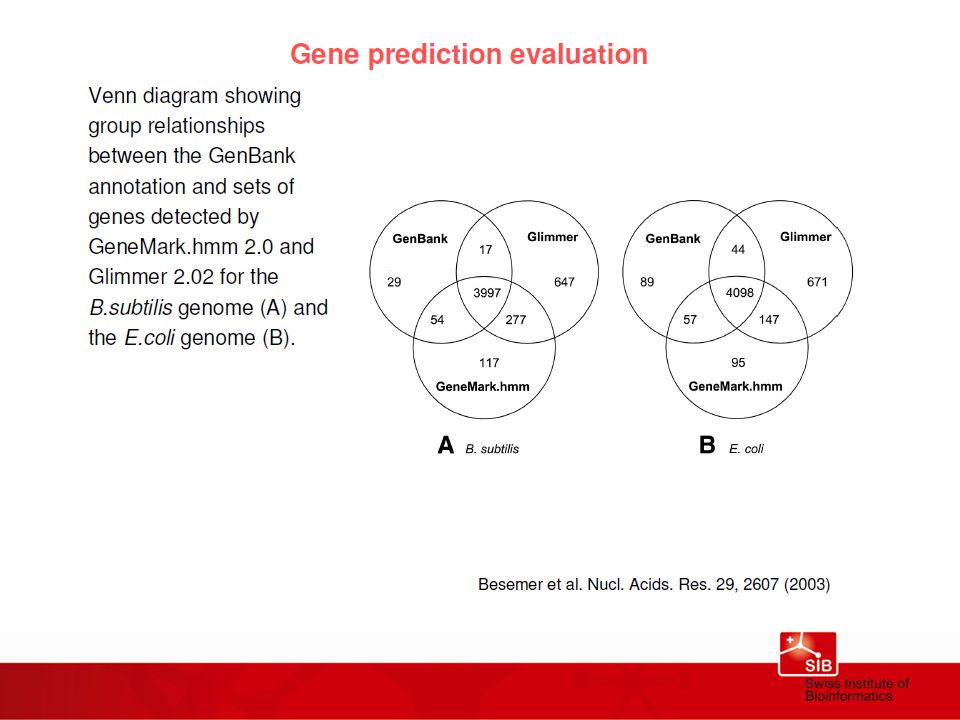
Assemblage d’un génome….un challenge…

9
Analyse des séquences ADN et ARN
Prédiction de gène Détection des régions codant pour des protéines Détection des régions codant pour des ARN fonctionnels (exemples: tRNA, rARN, miRNA). Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Analyse des sites de restriction (enzymes); Traduction ADN en protéine;
. Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Analyse des sites de restriction (enzymes); Traduction ADN en protéine;")
10
Analyse des séquences ADN et ARN
Prédiction de gène Détection des régions codant pour des protéines Détection des régions codant pour des ARN fonctionnels (exemples: tRNA, rARN, miRNA). Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Analyse des sites de restriction (enzymes); Traduction ADN en protéine;
. Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Analyse des sites de restriction (enzymes); Traduction ADN en protéine;")
11
Exemple: Genscan (http://genes.mit.edu/GENSCAN.html)
Biais des codons, conservation des dicodons (hexamers) Exemple: Genscan (
 Exemple: Genscan (")
12
Detect signals…. splicing Poly (A) tail Primary RNA transcript
ATG AATAAA Terminator Codon for protein synthesis (TGA, TAA, TAG) Primary RNA transcript AUG Poly (A) tail Stop splicing Mature mRNA AUG Stop Poly (A) tail
 Primary RNA transcript. AUG. Poly (A) tail. Stop. splicing. Mature mRNA. AUG. Stop. Poly (A) tail.")
13
Jigsaw prediction for the human genome (chromosome 1)

16
Prédiction de gène Détection des régions codant pour des protéines Détection des régions codant pour des ARN fonctionnels (exemples: tRNA, rARN, miRNA). Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Analyse des sites de restriction (enzymes); Traduction ADN en protéine;
. Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Analyse des sites de restriction (enzymes); Traduction ADN en protéine;")
20
Reading frames 5’-ATGGTAACATGGC-3’ 3’-TACCATTGTACCG-5’ Forward strand:
Frame 1: ATG GTA ACA TGG C..

21
Reading frames 5’-ATGGTAACATGGC-3’ 3’-TACCATTGTACCG-5’ Forward strand:
Frame 1: ATG GTA ACA TGG C.. Frame 2: ..A TGG TAA CAT GGC Frame 3: .AT GGT AAC ATG GC. Reverse strand: Frame 4: GCC ATG TTA CCA T.. Frame 5: ..G CCA TGT TAC CAT Frame 6: .GC CAT GTT ACC AT.

22
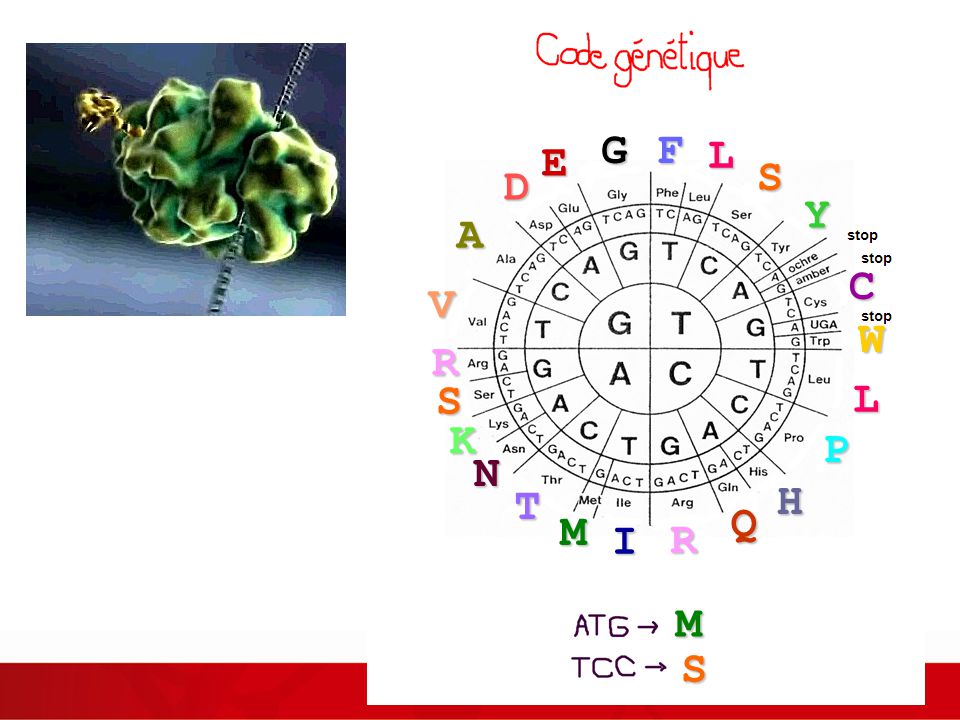
Une séquence de protéine: Met -------- STOP: quelle est la bonne ?

23
Analyse des séquences de protéines

24
>seq4 MSTNNYQTLSQNKADRMGPGGSRRPRNSQHATASTPSASSCKEQQKDVEH EFDIIAYKTTFWRTFFFYALSFGTCGIFRLFLHWFPKRLIQFRGKRCSVE NADLVLVVDNHNRYDICNVYYRNKSGTDHTVVANTDGNLAELDELRWFKY RKLQYTWIDGEWSTPSRAYSHVTPENLASSAPTTGLKADDVALRRTYFGP NVMPVKLSPFYELVYKEVLSPFYIFQAISVTVWYIDDYVWYAALIIVMSL YSVIMTLRQTRSQQRRLQSMVVEHDEVQVIRENGRVLTLDSSEIVPGDVL VIPPQGCMMYCDAVLLNGTCIVNESMLTGESIPITKSAISDDGHEKIFSI DKHGKNIIFNGTKVLQTKYYKGQNVKALVIRTAYSTTKGQLIRAIMYPKP ADFKFFRELMKFIGVLAIVAFFGFMYTSFILFYRGSSIGKIIIRALDLVT IVVPPALPAVMGIGIFYAQRRLRQKSIYCISPTTINTCGAIDVVCFDKTG TLTEDGLDFYALRVVNDAKIGDNIVQIAANDSCQNVVRAIATCHTLSKIN NELHGDPLDVIMFEQTGYSLEEDDSESHESIESIQPILIRPPKDSSLPDC QIVKQFTFSSGLQRQSVIVTEEDSMKAYCKGSPEMIMSLCRPETVPENFH DIVEEYSQHGYRLIAVAEKELVVGSEVQKTPRQSIECDLTLIGLVALENR LKPVTTEVIQKLNEANIRSVMVTGDNLLTALSVARECGIIVPNKSAYLIE HENGVVDRRGRTVLTIREKEDHHTERQPKIVDLTKMTNKDCQFAISGSTF SVVTHEYPDLLDQLVLVCNVFARMAPEQKQLLVEHLQDVGQTVAMCGDGA NDCAALKAAHAGISLSEAEASIAAPFTSKVADIRCVITLISEGRAALVTS YSAFLCMAGYSLTQFISILLLYWIATSYSQMQFLFIDIAIVTNLAFLSSK TRAHKELASTPPPTSILSTASMVSLFGQLAIGGMAQVAVFCLITMQSWFI PFMPTHHDNDEDRKSLQGTAIFYVSLFHYIVLYFVFAAGPPYRASIASNK AFLISMIGVTVTCIAIVVFYVTPIQYFLGCLQMPQEFRFIILAVATVTAV ISIIYDRCVDWISERLREKIRQRRKGA

25
Caractérisation physicochimique (pI, pM, coefficient extinction…)
Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques.
; Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques.")
26
Ça me semble biologique …mais reste à le prouver !
Conclusion de l’analyse in silico d’une protéine inconnue Poids moléculaire: 126 kD; Fonction: ATPase potentielle; Localisation subcellulaire: Membrane plasmique. Transmembranaire (~10 hélices); N terminal: intracellulaire; C terminal: intracellulaire) PTM: Phosphorylée Ça me semble biologique …mais reste à le prouver !
; N terminal: intracellulaire; C terminal: intracellulaire) PTM: Phosphorylée. Ça me semble biologique …mais reste à le prouver !")
27
Comparaison de séquences

28
MY-TAIL--ORIS-RICH- #x #### x#x# #### MONTAILLEURESTRICHE
Mettre en relation 2 séquences en comparant les acides aminés à chaque position et en tenant compte de leur probabilité de mutation au cours de l’évolution; MY-TAIL--ORIS-RICH- #x #### x#x# #### MONTAILLEURESTRICHE (algorithme pour comparer des chants d’oiseaux)
")
29
Matrice de substitution (BLOSUM62)
")
30
Application : Recherche de similarité (BLAST)
Basic Local Alignment Search Tool

31
Recherche de similarité (BLAST)
Outil bioinformatique très efficace, permettant de trouver les séquences similaires à une séquence données (protéine ou nucléique) -> Compare une séquence ‘query’ avec toutes les séquences existantes dans les banques de données (UniProtKB: 26 mo d’entrées). Résultats: une liste d’entrées avec des scores de ‘similarité’
 -> Compare une séquence ‘query’ avec toutes les séquences existantes dans les banques de données. (UniProtKB: 26 mo d’entrées). Résultats: une liste d’entrées avec des scores de ‘similarité’")
33
Probabilité de retrouver la même séquence par hasard…
BLAST ( Est-ce qu’il existe une protéine similaire à l’hémoglobine humaine chez les plantes ? Séquence de l’hémoglobine humaine Probabilité de retrouver la même séquence par hasard…

34
Sur quel chromosome humain se situe le gène HBB ?
Une séquence au hasard (ATGC) se retrouve-t-elle sur le génome ?
 se retrouve-t-elle sur le génome")
35
Probabilité de retrouver la même séquence par hasard…

36
Alignement multiple

37
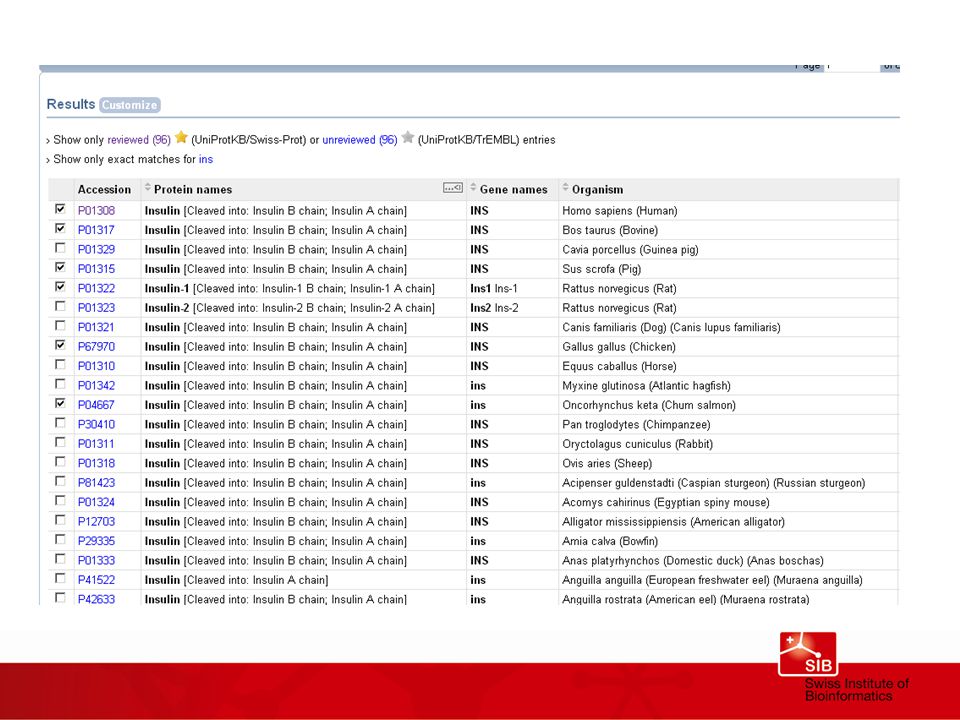
Alignement multiple des séquences d’insuline
Peptide signal Hélice alpha Hélice alpha clustalW, T coffee, muscle…

38
Alignement multiple ‘hémoglobine béta’ (HBB) @ UniProt

40
Application: Analyse phylogénétique

41
FIGURE Phylogenetic trees of the three domains of cellular life (upper panel) and of the multicellular Eukarya (lower panel). The universal tree of life (upper panel) is inferred from maximum likelihood analysis of 1620 homologous nucleotide positions of small-subunit ribosomal RNA sequences from each organism. (The tree is redrawn, with permission, from Barns S.M. et al Proc. Natl. Acad. Sci. 93: 9188–9193, ©National Academy of Sciences, U.S.A. The eukaryotic phylogeny is redrawn and modified, with permission, from Pollard T.D. et al Cell Biology, 2nd Edition. Saunders, New York, ©Elsevier.) Common eukaryotic “model” organisms are indicated. Except for the sponge, all indicated species have had their genomes sequenced. (Gray dotted rings) Approximate time before present (mya = millions of years ago). Major groups are indicated by different colors and refer to specific chapters (see text for discussion). The unicellular alveolates (e.g., trypanosomes) and slime mold diverged more than 1 billion years ago. Thus, their branching points are not shown.
. The universal tree of life (upper panel) is inferred from maximum likelihood. analysis of 1620 homologous nucleotide positions of small-subunit ribosomal RNA sequences from each. organism. (The tree is redrawn, with permission, from Barns S.M. et al Proc. Natl. Acad. Sci. 93: 9188–9193, ©National Academy of Sciences, U.S.A. The eukaryotic phylogeny is redrawn and modified, with permission, from Pollard T.D. et al Cell Biology, 2nd Edition. Saunders, New York, ©Elsevier.) Common eukaryotic model organisms are indicated. Except for the sponge, all indicated species have. had their genomes sequenced. (Gray dotted rings) Approximate time before present (mya = millions of. years ago). Major groups are indicated by different colors and refer to specific chapters (see text for discussion). The unicellular alveolates (e.g., trypanosomes) and slime mold diverged more than 1 billion. years ago. Thus, their branching points are not shown.")
43
Il est possible de construire un arbre phylogénétique à partir de différents types de données:
Les données morphologiques (écailles ou plumes, présence de certains os du crâne, forme des feuilles…). Il existe quelques centaines de caractères définis dans ce but par les spécialistes. Les caractères physiologiques (température corporelle…) Mais aussi… L’ordre des gènes (par exemple sur l’ADN des mitochondries) Les données moléculaires (séquences d’ADN ou de protéines). Des mutations modifient les séquences de l’ADN et par conséquent des protéines au cours de l’évolution. toutes les données existantes….(défi scientifique !)
. Il existe quelques centaines de caractères définis dans ce but par les spécialistes. Les caractères physiologiques (température corporelle…) Mais aussi… L’ordre des gènes (par exemple sur l’ADN des mitochondries) Les données moléculaires (séquences d’ADN ou de protéines). Des mutations modifient les séquences de l’ADN et par conséquent des protéines au cours de l’évolution. toutes les données existantes….(défi scientifique !)")
45
Le principe 1. Sélection: set de séquences de protéines ‘homologues’
2. Comparaison: alignement multiple 3. Construction de l’arbre: ‘calculer les différences’ + quelques calculs statistiques…

46
? Actin-related protein 2 Les différentes espèces sont:
ARP2_A MESAP---IVLDNGTGFVKVGYAKDNFPRFQFPSIVGRPILRAEEKTGNVQIKDVMVGDE ARP2_B MDSQGRKVIVVDNGTGFVKCGYAGTNFPAHIFPSMVGRPIVRSTQRVGNIEIKDLMVGEE ARP2_C MDSQGRKVVVCDNGTGFVKCGYAGSNFPEHIFPALVGRPIIRSTTKVGNIEIKDLMVGDE ARP2_D MDSQGRKVVVCDNGTGFVKCGYAGSNFPEHIFPALVGRPIIRSTTKVGNIEIKDLMVGDE ARP2_E MDSKGRNVIVCDNGTGFVKCGYAGSNFPTHIFPSMVGRPMIRAVNKIGDIEVKDLMVGDE *:* :* ******** *** *** . **::****::*: . *::::**:***:* Les différentes espèces sont: Caenorhabditis briggsae Drosophila melanogaster Homo sapiens Mus musculus Schizosaccharomyces pombe Quelle séquence ‘appartient’ à quelle espèce ? ?

47
ARP2_A MESAP---IVLDNGTGFVKVGYAKDNFPRFQFPSIVGRPILRAEEKTGNVQIKDVMVGDE
ARP2_B MDSQGRKVIVVDNGTGFVKCGYAGTNFPAHIFPSMVGRPIVRSTQRVGNIEIKDLMVGEE *:* **:******** *** *** . ***:*****:*: :..**::***:***:* ARP2_C MDSQGRKVVVCDNGTGFVKCGYAGSNFPEHIFPALVGRPIIRSTTKVGNIEIKDLMVGDE ********:* *************:*** ****::*****:*** .************:* ARP2_D MDSQGRKVVVCDNGTGFVKCGYAGSNFPEHIFPALVGRPIIRSTTKVGNIEIKDLMVGDE ************************************************************ ARP2_E MDSKGRNVIVCDNGTGFVKCGYAGSNFPTHIFPSMVGRPMIRAVNKIGDIEVKDLMVGDE ***:**:*:******************* ****::****:**:..*:*:**:******** *:* :* ******** *** .*** . **::*****:*: *.**::***:*****

48
Le principe 1. Sélection: set de séquences de protéines ‘homologues’
2. Comparaison: alignement multiple 3. Construction de l’arbre: ‘calculer les différences’

51
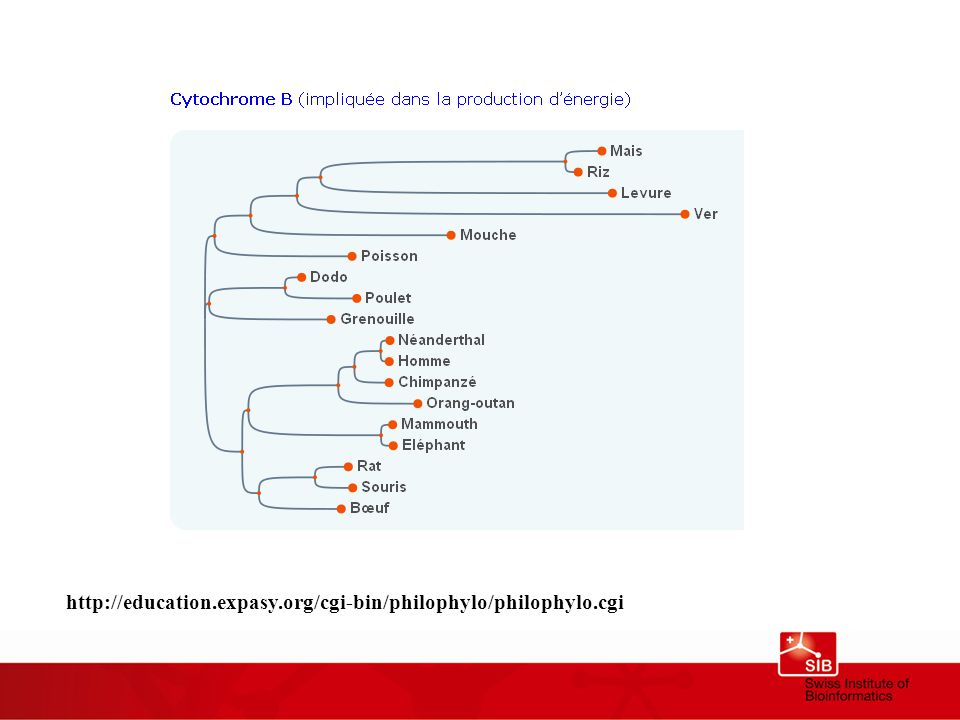
Cladrogramme obtenu à partir de l’analyse phylogénétique de l’alignement multiple des séquences d’insuline - Qui est le cousin de qui ? Qui a un ancêtre commun ?

53
Application: meta-genomics analysis

55
Résumé: la bioinfo c’est…
Acquérir puis stocker les informations biologiques sous la forme d’encyclopédies appelées bases de données; Développer des programmes de prédiction et d’analyse en utilisant les informations contenues dans les bases de données; Analyser/Interpréter/Prédire: utiliser ces programmes pour analyser de ‘nouvelles’ données biologiques et prédire in silico par exemple la fonction potentielle d’une protéine; Visualiser: développer des programmes pour visualiser la structure en trois dimensions des protéines et de l’ADN, pour shématiser des voies métaboliques ou des arbres phylogénétiques.

56
Conclusions Extraordinaire potentiel de la bioinformatique…
mais ne elle ne remplace(ra) pas les expériences «wet lab» génomiques, protéomiques et autres, ni l’esprit critique humain (contexte biologique) …ni le besoin de savoir programmer un minimum ! La bioinfo fournit des outils performants aux chercheurs… mais elle ne peut pas encore tout faire…. Les données expérimentales des chercheurs permettent d’améliorer les programmes bioinformatiques (prédiction)…
 pas les expériences «wet lab» génomiques, protéomiques et autres, ni l’esprit critique humain (contexte biologique) …ni le besoin de savoir programmer un minimum ! La bioinfo fournit des outils performants aux chercheurs… mais elle ne peut pas encore tout faire…. Les données expérimentales des chercheurs permettent. d’améliorer les programmes bioinformatiques (prédiction)…")
57
Avant … Après …

Présentations similaires