Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Analyse Exploratoire des Données Géographiques ESDA Analyse Exploratoire des Données Géographiques ESDA Didier JOSSELIN ESPACE, UMR 6012, CNRS, Avignon, France didier.josselin@univ-avignon.fr Tél.: 04 90 16 26 93

2
Introduction Quelques outils de base de l’EDA Méthodes à noyaux Filtres spatiaux robustes Variogrammes robustes Autocorrélation spatiale Filtres adaptatifs Médienne, Distogramme Rapport SIG / outils de Statistique ARPEGE, LAVSTAT ConclusionPLAN

3
Exploratory Spatial Data Analysis : Application de l’EDA à l’analyse spatiale

4
L’enjeux principal de l’analyse spatiale et donc … de l’ESDA - L’analyse d’ensemble locale d’objets géographiques… points surfaces lignes objets complexes - Pour rechercher les : relations statistiques relations spatiales relations à travers les échelles relations « statistico-spatiales » à travers…

5
L’ E D A et la statistique “classique”

6
Analyse des données

7
La voie de l’EDA

8
Histogramme, branchage, boîte à pattes, dot plot...

9
Question : quels sont les qualités et les défauts de l’histogramme ? Question : quels sont les qualités et les défauts de l’histogramme ?

10
Les qualités... -Mode de représentation synthétique -Mathématiquement bien étudié et établi -Permet de nombreux tests de dépendance statistique (contingence) - Méthodes de discrétisations « automatiques » +
 - Méthodes de discrétisations « automatiques » +.")
11
Les défauts... -Sensibilité au nombre de classes -Mélange d’individus différents par classe -Contrainte de surfaces proportionnelles aux fréquences formes « bizarres » - Méthodes de discrétisations « automatiques » -

12
Réponse apportée par le branchage (Stem and leaf)
")
13
Réponse apportée par des graphiques simples Dot Plot Stacked Plot Jittered Plot

14
Réponse apportée par la boîte à pattes intérieursadjaçents proches lointains Distance Inter Quartile (dIQ) 1,5 x (Q3-Q2) Q2 Q1 Q3 minmax
 1,5 x (Q3-Q2) Q2 Q1 Q3 minmax")
15
Réponse apportée par l’histogramme dynamique (ex : le distogramme, Josselin, 1999)
")
16
Démo histogramme dynamique et boîte à pattes

17
Question : quels sont les qualités et les défauts des méthodes classiques de comparaison de distributions (Khi2, Kolmogorov-Smirnov...) sur tableau de contingence ?
 sur tableau de contingence")
18
Les qualités... -Utilisent l’histogramme -Sont synthétiques et font appel à des tests de probabilité -Mathématiquement bien étudié et établi +

19
Les défauts... -Sensibilité au nombre de cases -On perd l’individu -On ne peut pas évaluer la forme de la distribution - Plusieurs valeurs peuvent correspondre à des réalités significativement différentes -

20
La réponse du QQ Plot Valeurs x i classées par ordre croissant (i est l’indice) Quantiles théoriques suivant une loi normale
 Quantiles théoriques suivant une loi normale")
21
Démo QQ-Plot

22
Ré-expression de variable, régressions robustes, Lowess

23
Question : quels sont les qualités et les défauts des régressions de type “moindres carrés”, linéaires ou non linéaires ?

24
Les mêmes qualités que d’habitude... et les mêmes défauts... -Sensibilité aux valeurs extrêmes… -Nécessité de normalité des résidus et bonne répartitions des individus en X et Y

25
Une première réponse : la ré-expression des données L’échelle de puissance de Tukey PuissanceTransformée 4X 4 3X 3 2X 2 1X ½racine(X) 0log(X) -½-1/racine(X) -1-1/X -2-1/X 2 -3-1/X 3 Log(x)
 0log(X) -½-1/racine(X) -1-1/X -2-1/X /X 3 Log(x)")
26
La réponse de la “droite résistante” à la régression linéaire (ex :grigri-plot, A. Banos, 1999) Régression Moindres carrés Résistant line
 Régression Moindres carrés Résistant line.")
27
Principe de la droite résistante u On regroupe les individus en 3 paquets d’effectifs égaux (en fonction de X) u On calcule pour chaque groupe l’individu robuste {médiane des X, médiane des Y} u On ajuste la droite sur les 2 points médians extrêmes, puis sur le point médian central
 u On calcule pour chaque groupe l’individu robuste {médiane des X, médiane des Y} u On ajuste la droite sur les 2 points médians extrêmes, puis sur le point médian central")
28
Démo Droite Résistante

29
La réponse du “Lowess” à la régression non linéaire

30
Principe du lowess (lissage robuste d’un nuage de points) u On définit une distance et on calcule, pour chaque point les poids des points voisins u On calcule la régression locale sur chaque point (polynôme) u On calcule les résidus et on applique un ajustement robuste par la médiane, pour éliminer les résidus trop importants
 u On définit une distance et on calcule, pour chaque point les poids des points voisins u On calcule la régression locale sur chaque point (polynôme) u On calcule les résidus et on applique un ajustement robuste par la médiane, pour éliminer les résidus trop importants")
31
La voie de l’ESDA ?

32
Démo Lowess, filtres robustes sur données

33
ESDA : outils existants

34
Question : Comment lisser, homogénéiser, simplifier et analyser à travers les échelles... un phénomène observé ?

35
Filtres spatiaux robustes

36
Principe u On promène un filtre d’amplitude a choisi par l’utilisateur u En chaque valeur de la série, on applique la fonction f (pour nous la médiane) : X a=5, t=2 X-1 X-2 X+1 X+2
 : X a=5, t=2 X-1 X-2 X+1 X+2")
37
Médiane mobile

38
Filtres spatiaux Même principe que sur série, mais s’applique en 2D Degré de contiguïté Distance

39
Contiguïté 1 2 3 4 5 5 zones Matrice de contiguïté (i,j) Cij = 1 si i et j ont une frontière commune 0 sinon On peut aussi définir des degrés de contiguïté : - d'ordre k (supérieur à 1) - d'ordre infèrieur à k I J
 Cij = 1 si i et j ont une frontière commune 0 sinon On peut aussi définir des degrés de contiguïté : - d ordre k (supérieur à 1) - d ordre infèrieur à k I J")
40
Distance 1 2 3 4 5 5 zones Matrice de contiguïté (i,j) Cij = 1/d ij si i j avec > 1 0 sinon On peut aussi d ₫ finir des pond ₫ rations dans la distance en jouant sur I J = 1
 Cij = 1/d ij si i j avec > 1 0 sinon On peut aussi d ₫ finir des pond ₫ rations dans la distance en jouant sur I J = 1")
41
Filtres spatiaux

42
Estimateurs de densité A. Banos, F. Huguenin-Richard, 1999 Application aux accidents de la route en 1996 dans la CUDL Source : CUDL, 1996

43
Estimation de densité par fonction de Kernel et les fenêtres mobiles adaptatives u Principe général : - estimation en tout point de l’espace de l’intensité d’un phénomène (nombre d’accidents) - balayage systématique de la zone d’étude par une fenêtre circulaire mobile de rayon r défini par l’utilisateur ou auto-adaptative - pondération du nombre d’accidents en fonction de la distance de chaque accident au centre de la fenêtre circulaire D’après Bailey T., Gatrell, A., 1995 A. Banos, F. Huguenin-Richard, 1999

44
Estimation de densités locales. Représentation surfacique Densités estimées à partir de 20 000 fenêtres mobiles fixes de rayon 1000 m Densités estimées à partir de 20 000 fenêtres mobiles adaptatives de rayon 1000 m Source : CUDL, 1996 A. Banos, F. Huguenin-Richard, 1999

45
Estimation de densités locales. Représentation 3D Source : CUDL, 1996 Densités estimées à partir de 20 000 fenêtres mobiles fixes de rayon 1000 m Densités estimées à partir de 20 000 fenêtres mobiles adaptatives de rayon 1000 m A. Banos, F. Huguenin-Richard, 1999

46
u Soit une population de référence : l’ensemble des accidents en 1996 dans la Cudl Population de référence Sous-population u Constat visuel : forme de la distribution spatiale des 2 semis de points semble identique u Question : - existent-t ils dans la sous-population des concentrations locales non identifiables à l’œil nu ? u Extraction d’une sous-population : les accidents ayant impliqué au moins un piéton enfant Les clusters A. Banos, F. Huguenin-Richard, 1999

47
Principe de la méthode des clusters u Comparaison statistique de la distribution spatiale de la sous- population avec sa distribution théorique associée, construite sous hypothèse d’une répartition spatiale aléatoire u Application de la loi de Poisson pour tester la significativité des écarts observés entre les 2 distributions u Couverture de la zone d’étude par des fenêtres mobiles circulaires - nombre défini par l’utilisateur - rayon variable, choisi au hasard dans un intervalle fixé par l’utilisateur

48
Identification de concentrations locales P( , ) < 0.05P( , ) < 0.01 P( , ) < 0.005P( , ) < 0.001 A. Banos, F. Huguenin-Richard, 1999

49
Démo Filtres spatiaux robustes

50
Question : Comment quantifier la variation d’un phénomène dans l’espace, à travers les échelles, en changeant de résolution spatiale ?

51
Variogrammes... robustes

52
Principe sur une maille fixe (Modèles Numériques de Terrain) d 2d Z1Z1 ZnZn 2.2 0.5.d Z 20 Croiser variance et distance pour identifier des structures spatiales
 d 2d Z1Z1 ZnZn d Z 20 Croiser variance et distance pour identifier des structures spatiales")
53
Possible aussi sur semis de points sans structure

54
Méthode 1 - On détermine la matrice des distances d ij entre tous les couples de points {i,j} 2 – Pour toutes les valeurs de distance d ij (réparties en classes, multiples de d ou non), on calcule la variance de la variable Z 3 – On réalise un nuage de points croisant cette variance (Y) et les distances (d ij )
, on calcule la variance de la variable Z 3 – On réalise un nuage de points croisant cette variance (Y) et les distances (d ij )")
55
Variogramme « classique » et « robuste » avec i et j les points considérés d la résolution spatiale Z la variable à étudier n d le nombre de couples de points à la résolution d u Le Variogramme « classique » u (Matheron) u Et ses équivalents « robustes » (Cressie)
 u Et ses équivalents « robustes » (Cressie)")
56
Exemple : population communale Quantiles Amplitudes égales 1 : variogramme classique 2 : variogramme robuste 1 3 variogramme robuste 2 1 2 3 1,2 3 forte faible

57
Variogramme exploratoire We propose to use a spatio-temporal co-occurrence matrice in order to : assess spatio-temporal autocorrelation look for spatio-temporal patterns based on pullulation scores local relations and organization in timeWe propose to use a spatio-temporal co-occurrence matrice in order to : assess spatio-temporal autocorrelation look for spatio-temporal patterns based on pullulation scores local relations and organization in time Log (abs (Zi – Zj)) (abs (Zi – Zj)) Log (dij) Dij Lowess
) (abs (Zi – Zj)) Log (dij) Dij Lowess")
58
Autocorrélation spatiale

59
Question : Comment mesurer à quel point des individus proches géographiquement se ressemblent ?

60
Buts et usages de la mesure d'autocorrélation spatiale u Mesurer des contrastes sur une carte ou une image u Evaluer globalement ou localement la structure d'un phénomène u Identifier des zones homogènes vs hétérogènes u Aider à la détection de discontinuïtés spatiales et des frontières

61
Disciplines et domaines concernés u Analyse spatiale, géographie quantitative u Géostatistiques (phénomènes continus et discrets) u Traitement d'images u Analyse des réseaux u Economie spatiale u Archéologie u Ecologie u Etc.
 u Traitement d images u Analyse des réseaux u Economie spatiale u Archéologie u Ecologie u Etc.")
62
Les individus proches se ressemblent... (autocorrélation +)
")
63
Les individus proches sont différents... (autocorrélation -)
")
64
De quoi ai-je besoin pour mesurer l'autocorrélation spatiale ? - D'une (ou de) variable(s) à mesurer - D'une méthode pour mesurer la distance ou la contigu ï té : * choix d'une mesure * calcul d'une matrice de distance ou contigu ï té - D'une méthode pour évaluer l'autocorrélation sous contrainte de distance / contigu ï té * choix d'une mesure * choix d'une fen ê tre d'application - D'une méthode de validation, visualisation
 variable(s) à mesurer - D une méthode pour mesurer la distance ou la contigu ï té : * choix d une mesure * calcul d une matrice de distance ou contigu ï té - D une méthode pour évaluer l autocorrélation sous contrainte de distance / contigu ï té * choix d une mesure * choix d une fen ê tre d application - D une méthode de validation, visualisation.")
65
Indices de MORAN u L’indice de MORAN global est défini comme suit (Moran) : avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une condition, 0 sinon M<0 ou Mi<0si l’autocorrélation est négative M>0 ou Mi>0si l’autocorrélation est positive u Et son équivalent local (LISA, Anselin) :
 : avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une condition, 0 sinon M<0 ou Mi<0si l’autocorrélation est négative M>0 ou Mi>0si l’autocorrélation est positive u Et son équivalent local (LISA, Anselin) :")
66
Indices de GEARY u L’indice de GEARY global est défini comme suit (Geary): avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une contrainte, 0 sinon G ou Giplus la valeur est grande et plus l’autocorrélation est forte u Et son équivalent local (LISA, Anselin) :
: avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une contrainte, 0 sinon G ou Giplus la valeur est grande et plus l’autocorrélation est forte u Et son équivalent local (LISA, Anselin) :")
67
Démo LISA

68
Filtres temporels et spatiaux robustes

69
Les individus proches se ressemblent... (autocorrélation +)
")
70
Les individus proches sont différents... (autocorrélation -)
")
71
Même principe, que filtres spatiaux lien l ij Degré de contiguïté (l ij = c ij )Distance (l ij = d ij )
Distance (l ij = d ij )")
72
Indices de MORAN u L’indice de MORAN global est défini comme suit (Moran) : avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une condition, 0 sinon M<0 ou Mi<0si l’autocorrélation est négative M>0 ou Mi>0si l’autocorrélation est positive u Et son équivalent local (LISA, Anselin) :
 : avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une condition, 0 sinon M<0 ou Mi<0si l’autocorrélation est négative M>0 ou Mi>0si l’autocorrélation est positive u Et son équivalent local (LISA, Anselin) :")
73
Indices de GEARY u L’indice de GEARY global est défini comme suit (Geary): avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une contrainte, 0 sinon G ou Giplus la valeur est grande et plus l’autocorrélation est forte u Et son équivalent local (LISA, Anselin) :
: avec u la moyenne des valeurs nle nombre d’individus l ij =1 si i et j contigus ou répondent à une contrainte, 0 sinon G ou Giplus la valeur est grande et plus l’autocorrélation est forte u Et son équivalent local (LISA, Anselin) :")
74
Démo LISA

75
Principe u On promène un filtre d’amplitude a choisi par l’utilisateur u En chaque valeur de la série, on applique la fonction f : X a=5, t=2 X-1 X-2 X+1 X+2

76
Filtres sur série temporelle

77
Filtres spatiaux Même principe, mais s’applique en 2D Degré de contiguïté Distance

78
Les outils du marché... SIG, logiciels de cartographie ou logiciels de Statistique ?

79
Des logiciels de statistique très élaborés... u La variété et la puissance des modèles et des logiciels statistiques disponibles u L ’intégration des outils classiques et de l ’EDA u L ’existence de modèles statistiques et de logiciels spécifiques en EDA spatiale (ESDA)+
+.")
80
… qui intègrent peu le spatial. u Il n ’existe que des « viewers » de données géographiques u Les « grands » logiciels de statistique intègrent peu les modèles de l ’ESDA u L ’approche générale reste de type Entrée- Sortie-

81
Des logiciels de cartographie conviviaux... u L ’interactivité u La facilité d ’utilisation u La qualité de la sémiologie u L ’association à des représentations statistiques+

82
u Outils relativement fermés u Pas de structure de données accessible u Pas de langage de requête autre que graphique u Absence de modèle topologique- … avec cependant quelques limites...

83
Des Systèmes d ’Information Géographique puissants... Des Systèmes d ’Information Géographique puissants... u Acquérir u Accéder u Afficher u Analyser u Archiver u Abstraire

84
Les fonctionnalités à l’avantage des SIG u Le géocodage de l ’information u Intégration d ’informations hétérogènes u Langages de requête élaborés u Modèles de données structurés u Variété des SIG dédiés ou généralistes u Langage de programmation souvent intégré u Parfois modèle topologique+

85
Mais quelques inconvénients majeurs... u Interactivité faible (sauf requête SQL) u Peu d ’intégration d ’ outils statistiques (sauf gros systèmes) u Souvent empilement d ’informations mal structurées (couches) Anarchie ?-
 u Peu d ’intégration d ’ outils statistiques (sauf gros systèmes) u Souvent empilement d ’informations mal structurées (couches) Anarchie -.")
86
Conclusion : 3 voies sont techniquement possibles u Prendre un outil existant et l ’utiliser, u Marier deux (ou plusieurs) outils pour le meilleur et pour le pire (LAVSTAT) u Développer les besoins spécifiques dans les outils proposés (ARPEGE)
 outils pour le meilleur et pour le pire (LAVSTAT) u Développer les besoins spécifiques dans les outils proposés (ARPEGE)")
87
Exploratory Spatial Data Analysis : nos propositions pour l’enseignement et la recherche

88
Le « Distogramme »

89
Objectifs Rechercher les discontinuités spatiales Analyser les discontinuités dans les valeurs des variables décrivant les individus Chercher la meilleure configuration statistique pour restituer une information cartographique

90
La règle des D u une Double vue : une carte et une distribution statistique u Deux types de Distributions croisées : spatiale et statistique u Un lien Dynamique entre elles u Un outil pour Discrétiser des variables continues u Un outil pour analyser les Discontinuités spatiales et statistiques u Un outil pour transformer les Données (“Distorsion” de valeurs)
")
91
Le Distogramme : un lien dynamique entre une carte et des distributions

92
Démo Distogramme

93
ARPEGE’ pour détecter les objets géographiques composites multiscalaires

94
Hypothèse « Analyser dynamiquement les relations statistiques et spatiales à différentes échelles permet une meilleure compréhension des entités géographies et des relations qu’elles entretiennent (statistiques, spatiales et topologiques) »
 »")
95
Commune A Commune B L’exemple des flux agricoles intercommunaux

96
1 ha 10 ha 360 ha SAU SAU = flux internes + entrants Flux sortants

97
Un enchevêtrement inextricable...

98
Notion de « pertinence territoriale » «Bon» «Mauvais»

99
La « pertinence territoriale » calculée pour la PEZMA (si elle était mal attribuée territorialement)
")
100
Distribution spatiale de la pertinence territoriale communale CommunesCantons

101
Effet de bordure Secret statistique Qualité des données : complétude (Josselin, Bolot, Chatonnay,2000) Qualité des données : complétude (Josselin, Bolot, Chatonnay,2000)
 Qualité des données : complétude (Josselin, Bolot, Chatonnay,2000)")
102
Que cherchons-nous ? Commune aggregate with its key and boundary Commune described by an attribute Commune couple flow Des collections d’objets composites associés par : leurs dépendances sémantiques et/ou statistiques leurs relations spatiales, topologiques et/ou fonctionnelles

103
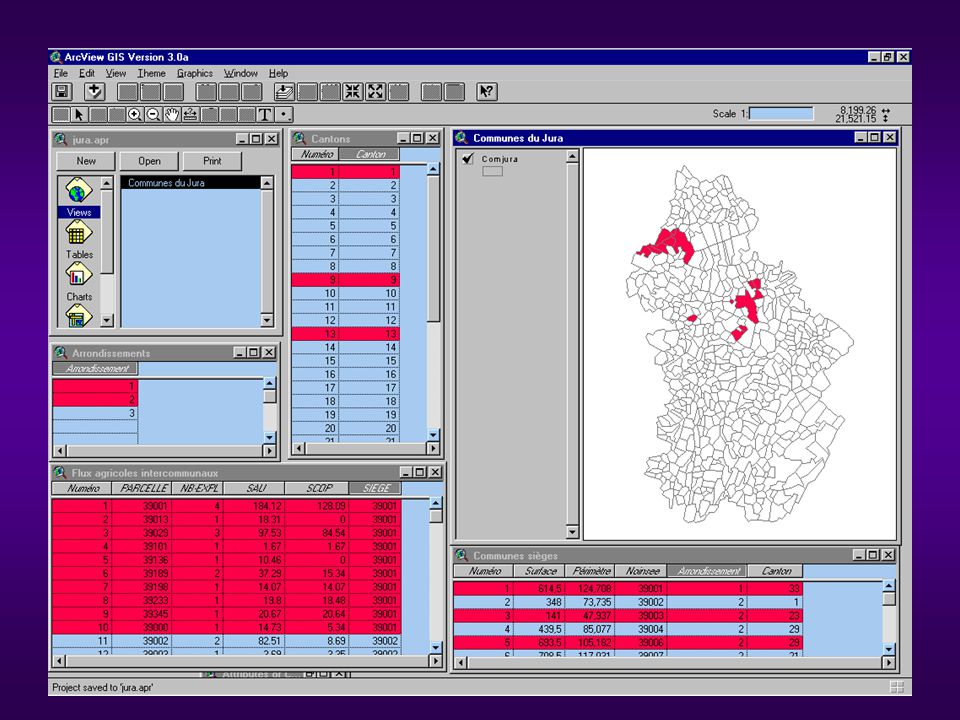
Le « visionneur » d ’ARPEGE’

104
Application du prototype ARPEGE’

105
Démo ARPEGE’

106
LAVSTAT Un lien dynamique entre ArcView et XlispStat

107
Objectifs Analyser l’espace de manière systémique Ne pas réinventer la roue Faire coopérer des outils complémentaires

108
ArcView Un SIG associé à ArcInfo u Modèle topologique u Requêtes variées u Tables indexées et liens entre tables u Une connexion SQL (à Access par ex.) u Un langage de « meta-programmation » (Avenue)
 u Un langage de « meta-programmation » (Avenue)")
110
Xlisp-Stat Un environment puissant de programmation statistique u Représentations statistiques multiples u Basé sur méthodes robustes (ESDA) u Un langage de programmation ouvert (LISP Orienté Objet) u Un lien dynamique entre les représentations
 u Un langage de programmation ouvert (LISP Orienté Objet) u Un lien dynamique entre les représentations")
112
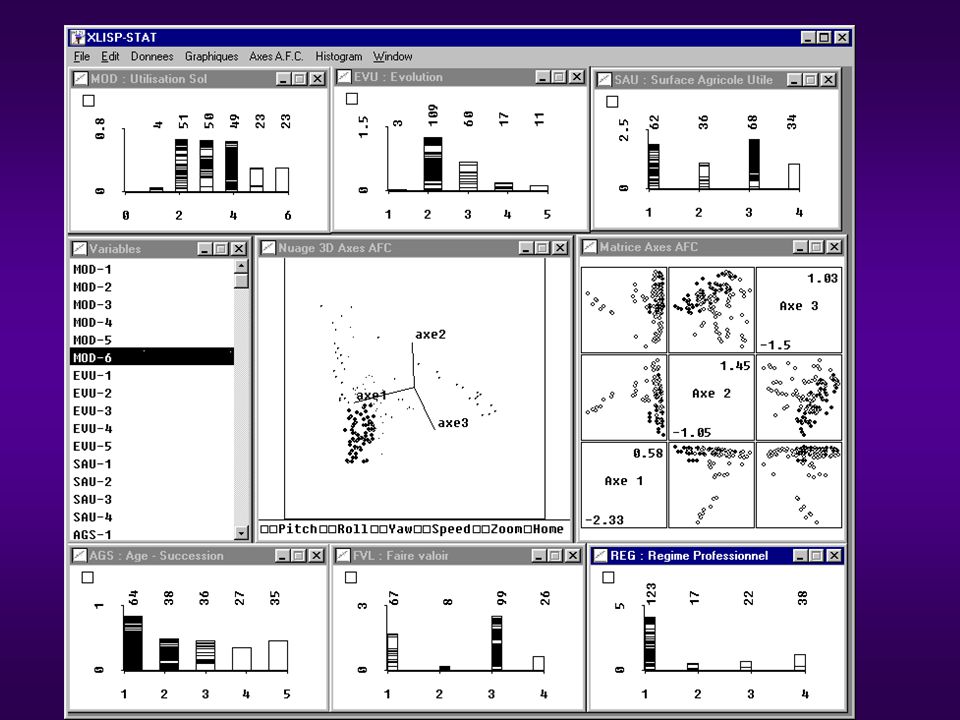
Interaction

113
Méthodologie de lien ArcView Xlisp-Stat Application N Services, DDE Serveur Application 3

114
Application de LAVSTAT

Présentations similaires
 r =>")
>")

















