Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
INFERENCE STATISTIQUE

2
Recensement ou Échantillon
Recensement = vérité l’information que l’on désire est disponible pour tous les individus de la population étudiée. Échantillon = estimation de la vérité l’information n’est disponible que pour un sous-ensemble des individus de la population étudiée.

3
Avantages d’un échantillon Coût réduit Rapidité accrue
Offre plus de possibilités dans certains cas il peut être impossible de faire un recensement (ex: contrôle de qualité)
")
4
Limites du recours à l’échantillon:
Erreur d’échantillonnage Difficulté de désignation de l’échantillon

5
Les résultats obtenus dépendent de l ’échantillon prélevé.
Si les échantillons sont prélevés selon les règles de l ’art, tous les résultats devraient se ressembler. Pour un tirage aléatoire simple, chaque individu de la population a la même chance d ’être sélectionné à chaque tirage. Pour un tirage aléatoire simple, il y a plusieurs échantillons possibles et qui sont différents. Tous les échantillons possibles de même taille ont la même chance d ’être sélectionnés.

6
L’ECHANTILLONNAGE La théorie de l’échantillonnage consiste à déterminer des propriétés sur des échantillons prélevés dans une population dont on connaît déjà des propriétés. On ne considère ici que des échantillons aléatoires, c’est à dire constitués d’éléments pris au hasard dans une population.

7
Le tirage des éléments d’un échantillon peut être fait sans remise; On dit qu’il est exhaustif.
Sinon si le tirage est fait avec remise, on dit qu’il est non exhaustif ; dans ce cas les tirages sont indépendants. Dans la plupart des cas, la population ayant un grand effectif, dans laquelle on tire une faible proportion d’éléments, on assimile un tirage sans remise à un tirage avec remise.

8
BASE D’ÉCHANTILLONNAGE
Liste à partir de laquelle on peut sélectionner tous les individus qui composent l'univers opérationnel: Annuaires téléphoniques Liste des abonnés à une revue, association, etc.

9
MÉTHODES D’ÉCHANTILLONNAGE
C'est le comment choisir les individus Méthodes probabilistes: Chaque personne à une probabilité connue d'être choisie Méthodes non-probabilistes: On ne connaît pas la probabilité qu'un individu soit choisi

10
MÉTHODES D'ÉCHANTILLONNAGE NON-PROBABILISTES

11
Méthode de convenance Principe : on obtient un tel échantillon quand rien n’a été fait pour s’assurer que les individus qui le composent posséderont bien certaines caractéristiques désirés. Il est constitué d’individus qui se trouvait à l’endroit et au moment où l’information a été collectée Intérêt : Simplicité.

12
Méthode des quotas Principe : Consiste à ce que la structure de l’échantillon suit exactement la structure de la population entière selon certains critères (variables de contrôle) que l’on a préalablement choisis et qui expliquent le comportement de l’enquêté suivant la variable d’intérêt. Remarque: Pour être retenue comme variable de contrôle, il faut simultanément : - avoir une distribution statistique connue ; - être facile d'observation ; - être fortement corrélée avec la ou les variables étudiées
 que l’on a préalablement choisis et qui expliquent le comportement de l’enquêté suivant la variable d’intérêt. Remarque: Pour être retenue comme variable de contrôle, il faut simultanément : - avoir une distribution statistique connue ; - être facile d observation ; - être fortement corrélée avec la ou les variables étudiées.")
13
INCONVENIENTS: Pas de fondements théoriques suffisants
Intérêt : -la méthode n’exige pas l’existence d’une base de sondage - Moindre coût INCONVENIENTS: Pas de fondements théoriques suffisants Elle ne permet pas de calculer la précision

14
Pour la méthode des quotas, le principal :
- inconvénient est de laisser trop d'initiative à l'enquêteur ; - avantage est de ne pas nécessiter de base de sondage. La méthode des itinéraires essaye de combiner les deux ! - Le principe : Méthode surtout utilisée pour tirer un échantillon de ménages ou de logements. Elle consiste à imposer un itinéraire où sont indiqués les lieux où doivent être réalisées les interviews. (Exemple : un immeuble sur trois, un étage sur deux, porte de gauche )
")
15
=> les conditions sont peu différentes d'un sondage aléatoire
chaque logement (lieu d'interview) est repéré par ses coordonnées géographiques Intérêt : Permet de contrôler l’enquêteur et de se rapprocher du cadre aléatoire.
 est repéré par ses coordonnées géographiques. Intérêt : Permet de contrôler l’enquêteur et de se rapprocher du cadre aléatoire.")
16
MÉTHODES D'ÉCHANTILLONNAGE PROBABILISTES

17
Sondage aléatoire simple
Principe : chaque membre d'une population a une chance égale d'être inclus à l'intérieur de l'échantillon (n/N). Chaque combinaison de membres de la population a aussi une chance égale de composer l'échantillon. Ce mode de sondage implique 3 conditions: - avoir la liste exhaustive de toute la population (base de sondage à jour) - l'enquête présente un caractère obligatoire ; - le processus de tirage est aléatoire (par tirage au sort)
. Chaque combinaison de membres de la population a aussi une chance égale de composer l échantillon. Ce mode de sondage implique 3 conditions: - avoir la liste exhaustive de toute la population (base de sondage à jour) - l enquête présente un caractère obligatoire ; - le processus de tirage est aléatoire (par tirage au sort)")
18
Avantages : Il fournit : - une estimation et une estimation de la précision de cette estimation - La différence entre l'estimation et la réalité diminue lorsque la taille de l'échantillon augmente Il se prête à des traitement améliorant son efficacité tel que la stratification ; Inconvénient : Nécessite une base de sondage exhaustive et à jour; Le problème de représentativité

19
Sondage stratifié Principe : consiste à construire des groupes homogènes vis à vis de la variable d’intérêt et à faire des Sondages Aléatoires Simples au niveau de chaque groupe. Cette méthode suppose la connaissance de la structure de la population, Pour estimer les paramètres, les résultats doivent être pondérés par l'importance relative de chaque strate dans la population Intérêt : gain en précision.

20
Notion de distribution d’échantillonnage
La distribution d’échantillonnage d’un paramètre donné est la distribution statistique de ce paramètre dans tous les échantillons possibles.

21
Exemple : Une population compte 5 étudiants. Le nombre d'heures passées devant le téléviseur par chacun d'eux est donné ci-dessous: Étudiant a b c d e Heures 7 16 20 12 22 On a donc une moyenne de la population 77/5= Pour calculer la moyenne de la distribution d'échantillonnage des moyennes, on doit former tous les échantillons possibles et calculer la moyenne pour chacun d'eux. On a donc le tableau de calcul suivant:

22
Échantillon Données Moyenne ( ) a b c 7 16 20 14,33 a b d 12 11,67 a b e 22 15,00 a c d 13,00 a c e 16,33 a d e 13,67 b c d 16,00 b c e 19,33 b d e 16,67 c d e 18,00 154,00 La moyenne des moyennes est donc 15,4

23
On doit calculer aussi l’écart type :
On constate donc que la moyenne des moyennes échantillonnales est exactement égale à la moyenne de la population on remarque aussi que ces moyennes échantillonnales se rapprochent de la moyenne de la population On doit calculer aussi l’écart type : Avec σ = l'écart type de la population N = la taille de la population n = la taille de l'échantillon et est un facteur de correction qui tend vers 1 à mesure que N grandit Par conséquent,on a simplement

24
Relation entre paramètres de la population et caractéristiques de l’échantillon

27
Estimation : C’est le problème inverse de l’échantillonnage; c’est à dire connaissant des renseignements sur un on plusieurs échantillons, on cherche à en déduire des informations sur la population totale.

28
Estimation ponctuelle :
1. Moyenne De manière générale, on choisit la moyenne d’un échantillon prélevé au hasard dans une population comme meilleure estimation ponctuelle de la moyenne inconnue m de cette population.

29
2. Proportion De même, on choisit la proportion des éléments possédant une certaine propriété dans un échantillon prélevé aléatoirement dans une population comme meilleure estimation ponctuelle de la proportion inconnue p des éléments de cette population ayant cette propriété.

30
3. Variance. Ecart-type On choisit le nombre où n est l’effectif et s² la variance d’un échantillon prélevé au hasard dans une population, comme meilleure estimation ponctuelle de la variance inconnue de cette population et on prend comme meilleure estimation ponctuelle de l’écart-type inconnue de cette population.

31
C. Estimation par intervalle de confiance
Les estimations ponctuelles sont liées au choix de l’échantillon ; il faut donc rechercher un nouveau type d’estimation de la moyenne d’une population ou d’un pourcentage. On cherche des intervalles qui, généralement, à 95% ou 99% des cas, contiennent la moyenne m inconnue ou le pourcentage p d’une certaine propriété que possède la population.

32
L ’estimation par intervalle de confiance consiste à établir un intervalle de valeurs qui nous permet d ’affirmer, avec un certain niveau de confiance ou de certitude prédéterminé (en général: 90%, 95% ou 99%), que la vraie valeur du paramètre dans la population se trouve dans cet intervalle.
, que la vraie valeur du paramètre dans la population se trouve dans cet intervalle.")
33
Intervalle de confiance pour estimer une proportion p
Exemple: Sur un échantillon de 125 salariés d ’une entreprise interrogés pour savoir s ’ils ont l ’intention de voter aux prochaines élections de leur association, 45 ont répondu positivement.

34
Estimer, de façon ponctuelle, la proportion de l ’ensemble des salariés de cette entreprise qui ont l ’intention de voter aux prochaines élections. f=45/125 = 0.36 Donner une estimation par intervalle de confiance de cette proportion au seuil de confiance de 95%

35
De façon générale, si la taille de l’échantillon n est assez grande, l ’intervalle de confiance au niveau (1 - ) pour estimer la vraie proportion p du caractère à l ’étude dans la population, est donnée par:
 pour estimer la vraie proportion p du caractère à l ’étude dans la population, est donnée par:")
37
Par conséquent, un intervalle de confiance de 95% de certitude pour la proportion de l ’ensemble des salariés de cette institution qui ont l ’intention de voter aux prochaines élections nous est donné par:

38
Comment rapporterait-on les résultats de ce sondage ?
36% des salariés ont l ’intention d ’exercer leur droit de vote aux prochaines élections de l ’association. La marge d ’erreur est de 8,4% avec un niveau de confiance de 95% (ou avec un degré de certitude de 95% ou 19 fois sur 20).
.")
39
Cette formule est approximative et s ’applique uniquement pour les grands échantillons.
Si je prends tous les échantillons aléatoires possibles de taille n et que je calcule pour chacun un intervalle de confiance au niveau de 95%, 95% d’entre eux incluront la vraie proportion p de la population, et donc 5% ne l ’incluront pas.

40
La quantité est appelé marge d ’erreur ou précision, au niveau de confiance 95% (19 fois sur 20).
.")
41
Marge d ’erreur au niveau 95%

42
Calcul de la taille n pour assurer une marge d ’erreur maximale
Si nous voulons estimer la proportion p au niveau de confiance (1-) avec une marge d ’erreur maximale notée e, alors nous avons la relation suivante pour le calcul de la taille n de l ’échantillon:
 avec une marge d ’erreur maximale notée e, alors nous avons la relation suivante pour le calcul de la taille n de l ’échantillon:")
43
Intervalle de confiance pour estimer la moyenne m
De façon générale, si la taille de l’échantillon n est assez grande, l ’intervalle de confiance au niveau (1 - ) pour estimer la vraie moyenne m de la population, est donnée par: Si l’écart type de la population est connu, si non la valeur de z sera lu sur la table de la loi de student à n-1 degré de liberté.
 pour estimer la vraie moyenne m de la population, est donnée par: Si l’écart type de la population est connu, si non la valeur de z sera lu sur la table de la loi de student à n-1 degré de liberté.")
45
Interprétation d’un intervalle de confiance au niveau 95% pour la moyenne m d ’une caractéristique dans la population: Si je prends tous les échantillons aléatoires de taille n et que je calcule pour chacun un intervalle de confiance de 95%, 95% d’entre eux incluront la vraie moyenne m de la population, et donc 5% ne l ’incluront pas.

46
Exemple Afin de connaître la consommation mensuelle moyen d’électricité pour une famille de 4 personnes résidant à Settat, on prélève un échantillon de 50 de ces familles et on note la consommation mensuelle d’électricité. On obtient un montant moyen de 155 dh avec une estimation de l ’écart type de 15 dh.

47
à l ’aide d ’un intervalle de confiance de 95% de certitude (on suppose l ’écart type connu à 15dh):
= [150,84;159,16]

48
Remarque : Si l’écart type est inconnue on doit estimer l’écart type de la distribution d’échantillonnage par (écart type de l’échantillon /racine n-1) Si n<30 la valeur de z sera lu sur la table de la loi de student à n-1 degré de liberté, si non elle sera lu sur la table de la loi normale centré réduite.
 Si n<30 la valeur de z sera lu sur la table de la loi de student à n-1 degré de liberté, si non elle sera lu sur la table de la loi normale centré réduite.")
51
Les tests statistiques

52
Principe des tests : Les tests d’hypothèses constituent le second volet de l’inférence statistique. Le premier volet est constitué des problèmes de l’estimation. Ils ont pour but de vérifier, à partir de données échantillonnales, la validité de certaines hypothèses émises à propos d’une population. Les tests cherchent à confronter deux hypothèses exprimant deux tendances différentes au sujet d’un paramètre (moyenne, proportion, variance) ou d’un élément de la population, et à déterminer au regard de l’échantillon observé, laquelle des deux hypothèses est la plus vraisemblable.
 ou d’un élément de la population, et à déterminer au regard de l’échantillon observé, laquelle des deux hypothèses est la plus vraisemblable.")
53
a- Les tests paramétriques :
Les tests se divisent, selon l’objet des hypothèses qui les constituent, en deux catégories : les tests paramétriques et les tests non paramétriques. a- Les tests paramétriques : portent sur des paramètres tels que moyenne, proportion et variance. Les tests paramétriques se subdivisent conventionnellement en deux catégories : les tests de signification et les tests de comparaison.

54
Les tests de signification ont pour objet la comparaison d’un paramètre à une valeur donnée (ou standard, norme), les tests de comparaison ont pour objet la comparaison entre eux de différents paramètres d’un même type.
, les tests de comparaison ont pour objet la comparaison entre eux de différents paramètres d’un même type.")
55
b- Les tests non paramétriques : lorsque les hypothèses ne portent pas sur des paramètres et sont formulées en terme qualitatifs : test d’indépendance, test d’adéquation…

56
Méthodologie des tests :
on définit les hypothèses alternatives H0 et H1 en fonction de la nature de la question posée, l’hypothèse nulle H0 est généralement la même, c’est l’hypothèse alternative H1 qui change:

57
2. On précise la statistique à utiliser et on donne sa loi de probabilité. On considère H0 comme exacte m = 20 ; 3. on se fixe un seuil de probabilité (généralement compris entre 1% et 10%), risque d’erreur que l’on accepte de courir ; = P ( Rejeter H0 / H0 vraie).
, risque d’erreur que l’on accepte de courir ; = P ( Rejeter H0 / H0 vraie).")
58
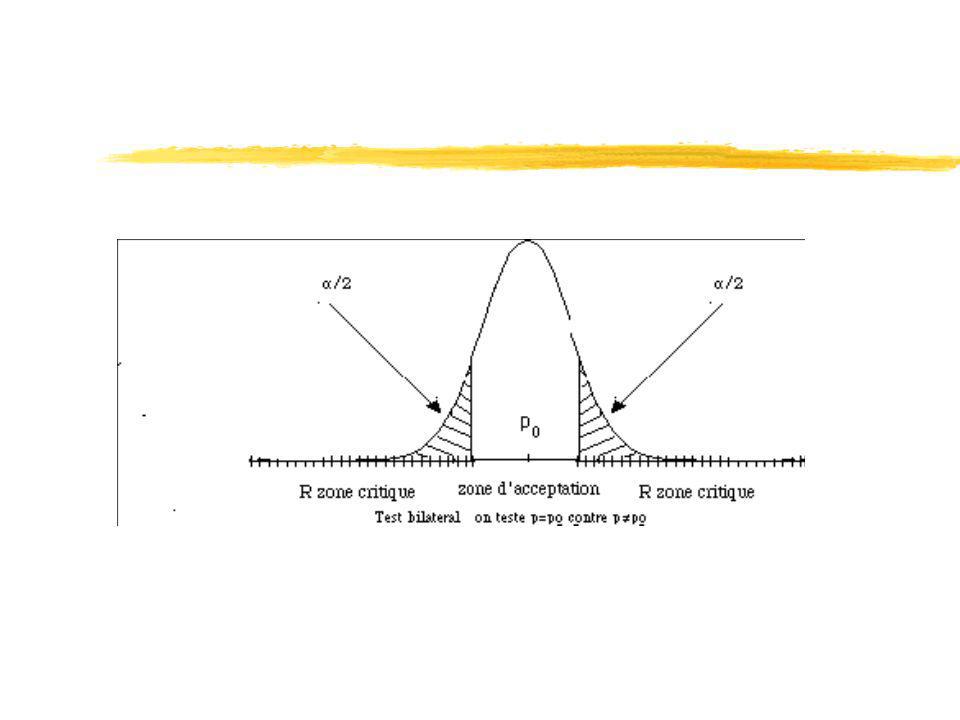
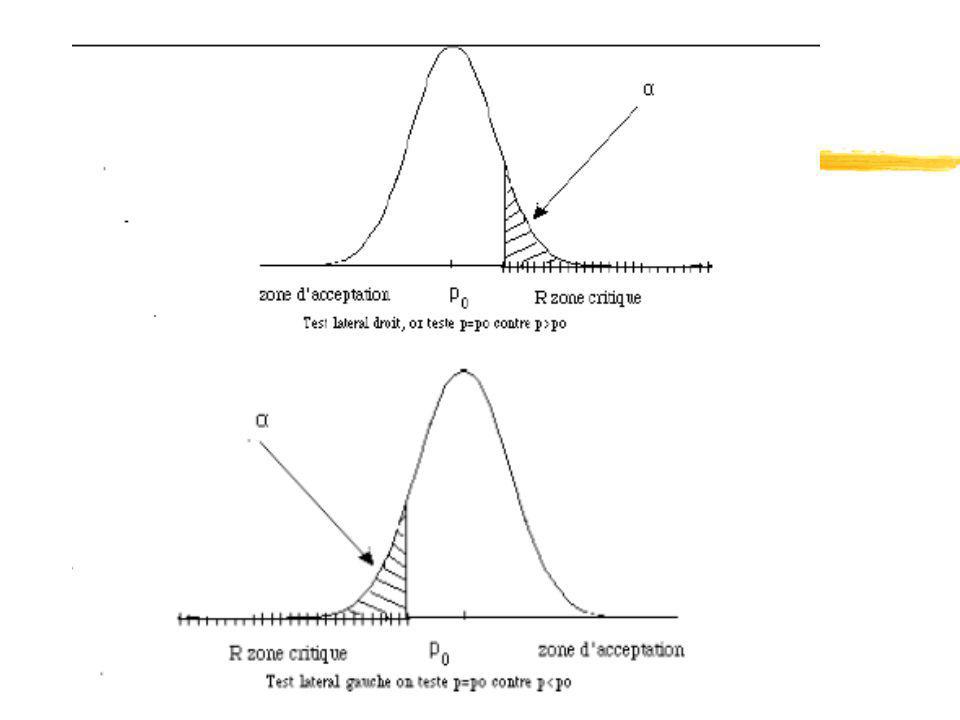
4. On détermine la région critique et la région d’acceptation en calculant une certaine borne (une ou deux en fonction de la forme de l’hypothèse alternative H1) qui sera la frontière entre les deux régions. La région critique d’un test est l’ensemble des valeurs possibles de l’échantillon aléatoire qui entraîne le rejet de H0.

61
5. Observation sur l’échantillon.
Prise de décision (H0 ou H1) Remarque : le fait d’accepter une hypothèse ne prouve pas qu’elle est vraie, mais signifie seulement que les données disponibles ne sont pas en contradiction avec elle.
 Remarque : le fait d’accepter une hypothèse ne prouve pas qu’elle est vraie, mais signifie seulement que les données disponibles ne sont pas en contradiction avec elle.")
62
La validité d’une hypothèse est jugée à partir d’observations échantillonnales, par conséquent, il est toujours possible de prendre une décision erronée. Deux types d’erreur sont possibles : erreur de première espèce :décider que H0 est fausse alors que H0 est en réalité vraie, ce qui est équivalent à dire : décider que H1 est vraie alors que c’est H0 qui l’est. erreur de deuxième espèce : décider que H0 est vraie alors qu’elle est en réalité fausse.

63
Il convient de signaler que les coûts induits par ces deux types d’erreur sont de nature différente. Ainsi, pour l’exemple 1, dans le premier cas, il s’agit d’arrêter la machine, de la vérifier alors que ce n’est pas du tout nécessaire et de subir ainsi une perte de production ; le 2ème cas conduit à fabriquer des pièces défectueuses en proportion pouvant dépasser le seuil tolérable.

64
Test de moyenne : On étudie une variable X de moyenne m. On se propose de tester si la moyenne m, peut être considérée ou non comme égale à une valeur fixée à priori. Le test se fera sur la base de la moyenne calculée sur un échantillon.

65
Démarche : 1. Définition des hypothèses en fonction du problème :

67
3. Pour un niveau de risque fixé, la région d’acceptation est donnée par :
en fonction de l’hypothèse 4. Observation sur échantillon et décision.

68
Exemple : Selon son expérience antérieure, le propriétaire d’une entreprise de vente au détail affirme que la valeur moyenne m des comptes à recevoir de son entreprise est de 2200 DH. Cependant, après avoir discuté avec quelques vendeurs de l’entreprise, un vérificateur (embauché pour vérifier la comptabilité de cette entreprise) est porté à croire que cette valeur moyenne a possiblement augmenté pour l’année en cours, Supposons que l’on accepte que la valeur X des comptes à recevoir de cette entreprise suit une distribution normale d’écart type 400 DH. Pour vérifier l’hypothèse du propriétaire au sujet de m, le vérificateur tire un échantillon aléatoire de 25 comptes à recevoir dans l’ensemble des comptes de l’entreprise, et il observe une valeur moyenne de Est-ce que le vérificateur devrait accepter ou rejeter l’hypothèse du propriétaire au niveau de signification ?
 est porté à croire que cette valeur moyenne a possiblement augmenté pour l’année en cours, Supposons que l’on accepte que la valeur X des comptes à recevoir de cette entreprise suit une distribution normale d’écart type 400 DH. Pour vérifier l’hypothèse du propriétaire au sujet de m, le vérificateur tire un échantillon aléatoire de 25 comptes à recevoir dans l’ensemble des comptes de l’entreprise, et il observe une valeur moyenne de Est-ce que le vérificateur devrait accepter ou rejeter l’hypothèse du propriétaire au niveau de signification")
69
Solution : Définition des hypothèses :

71
La valeur fournie par l’échantillon est de 2280
La valeur fournie par l’échantillon est de Cette valeur appartient à la région d’acceptation ; la décision est d’accepter H0 au seuil 5%, la moyenne des comptes à recevoir n’a pas augmenté. Ceci ne veut pas dire que c’est vrai à 100%, mais tout simplement que les données disponibles ne permettent pas de rejeter H0 et de considérer que la moyenne des comptes a augmenté.

72
2. Test de proportion:

73
Tests non paramétriques :
Tests du KHI- DEUX

Présentations similaires






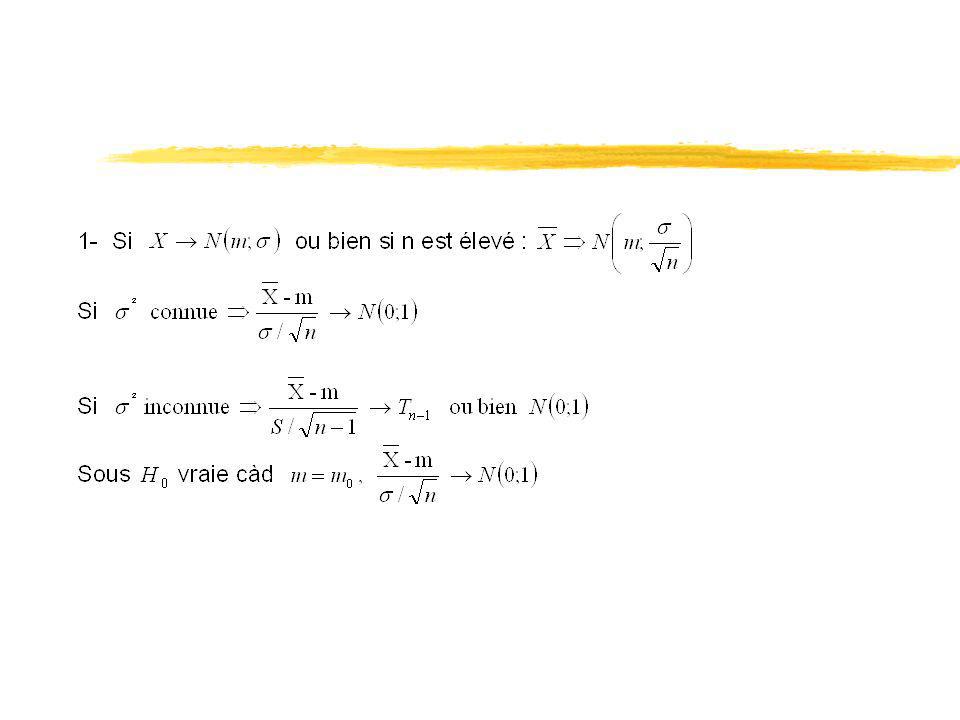






 : LAPPROCHE QUANTITATIVE ET LES TECHNIQUES DENQUETE.>")













