Le Signal Vocal Notions sur l’audition Allure temporelle Production du signal ; Modèles de production Notions sur l’audition Allure temporelle Analyse en fréquence Typologie des signaux Représentation Temps-Fréquence, spectrogramme Transmission , Synthèse, Reconnaissance Détection de la mélodie, de l’intonation Analyse « cepstrale » et par prédiction linéaire Analyse des formants et de leur évolution Principe de la synthèse de parole Données utilisées en reconnaissance de parole http://tcts.fpms.ac.be/cours/1005-08/speech/parole.pdf http://svr-www.eng.cam.ac.uk/~ajr/SA95/node87.html
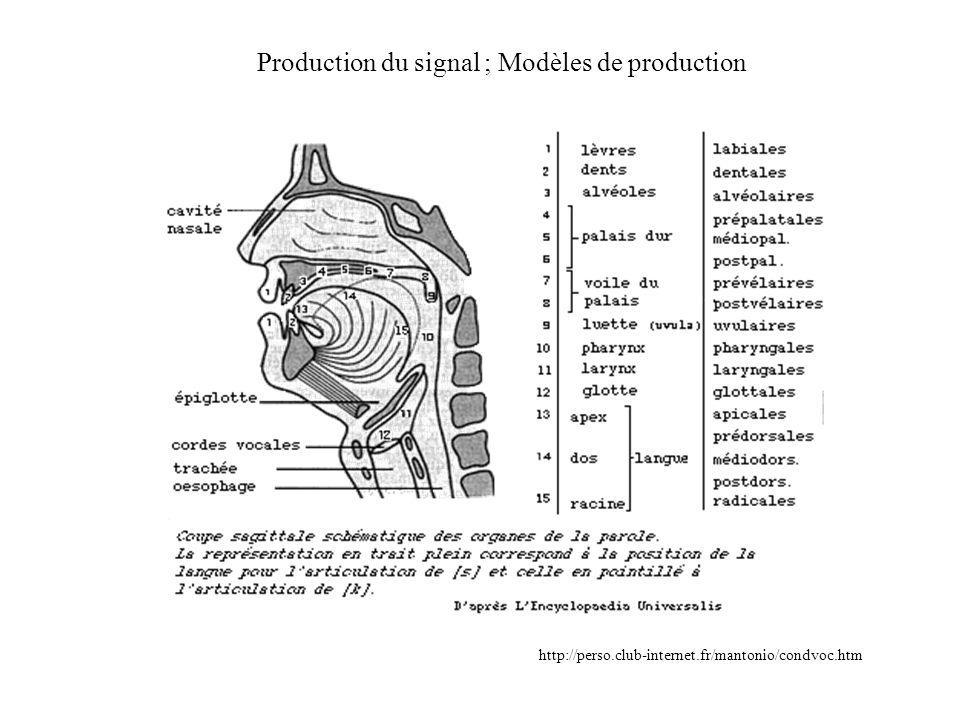
Production du signal ; Modèles de production http://perso.club-internet.fr/mantonio/condvoc.htm
http://perso.club-internet.fr/mantonio/condvoc.htm
temps http://perso.club-internet.fr/mantonio/condvoc.htm
Wolfgang von Kempelen (1770) http://www.ling.su.se/staff/hartmut/kemplne.htm
guimbarde, chants diphoniques, arc à bouche, didgeridoo clics en langue xhosa en Afrique du sud
Synthèse numérique (ou équivalent analogique) Signal synthétisé Impulsions des cordes vocales (intonation) ou bruit (fricatives) Filtre récursif Filtre linéaire variant lentement dans le temps représentant les évolutions temporelles des résonances du conduit vocal (Sa réponse en fréquence correspond au spectre du signal vocal)
temps Cordes vocales intonation Conduit vocal résonances Signal sonore synthétique fréquence
Audition http://www.iurc.montp.inserm.fr/cric/audition/
http://www.iurc.montp.inserm.fr/cric/audition/
Phénomène de masquage (mp3) x(n) = sinusoïde masquante q(n) = sinusoïde masquée fréquence fréquence Sx(f) = DSP du signal Sm(f) = Seuil de masquage http://tsi.enst.fr/~moreau/activites_enseignement.html
Analyse spectrale à court terme temps fréquence spectre Spectre (log) Spectre échelle mel fréquence fréquence
Spectre de la portion analysée : formants Signal vocal Zoom temps Spectre de la portion analysée : formants fréquence
spectre Deux secondes de signal temporel Analyse d ’une portion de 100 ms temps Module de la transformée de Fourier fondamental Formants (résonnances) harmoniques fréquence spectre
Allure temporelle des signaux Voyelles et consonnes voisées a, e, oe, i, o, u, ou, é, è, l, r Voyelle et consonnes nasalisées m, n, on, an, in, un Fricatives f, s, ch Fricatives voisées v, z, j Plosives p, t, k Plosives voisées b, d, g +sons « doubles », diphtongues, ... w, ll
‘ eu ’ ‘ a ’ ‘ o ’ ‘ ai ’ temps temps fréquence fréquence temps temps
‘ i ’ ‘ u ’ temps temps fréquence fréquence
‘ (ll)an ’ ‘ on ’ ‘ in ’ temps temps fréquence fréquence temps
(a)ll ‘ m ’ temps temps fréquence fréquence ‘ n ’ temps fréquence
‘ po ’ ‘ ta ’ ‘ co ’ ‘ b ’ ‘ g ’ ‘ d ’ temps temps temps fréquence
‘ f ’ ‘ s ’ ‘ ch ’ ‘ v ’ ‘ z ’ ‘ j ’ temps temps temps fréquence
spectrogramme fréquence perspective temps amplitude fréquence temps chronogramme
Spectrogramme, sonogramme, sonagramme Evolution au cours du temps de l ’analyse spectrale à court terme fréquence amplitude fréquence temps temps mise en évidence des formants (résonances du conduit vocal)
ph o n e t i c i an fréquence temps
- Analyse de la fréquence fondamentale chant, intonation Le « cepstre » - Analyse de la fréquence fondamentale chant, intonation - Paramètres de base pour la reconnaissance « temps » fréquence
Analyse de la fréquence fondamentale chant, intonation . 4 temps fréquence fondamental harmoniques
Analyse de la mélodie (pitch) fondamental fréquence Passe bas temps harmoniques fréquence Passe bande démodulation temps fondamental retrouvé par démodulation fréquence Passe bas sur le résultat temps
Codage de la parole : différents débits en fonction des applications et de la qualité acceptée Codage à bas débit (moins de 15kbits/s) : prédiction linéaire Codage à débit moyen : 16 à 32 kbits/s : modulation delta Téléphonie : 8bits x 8000 éch./s = 64 kbits/s Haute fidélité 16bits x 44100 éch./s = 700 kbits/ MP3 = 144 kbits/s
Échantillonnage à 8kHz quantification sur 8 bits Téléphonie numérique Échantillonnage à 8kHz quantification sur 8 bits Réduire la dynamique Loi « mu »
Codage par modulation delta (parole) pour les débits de 16à 32 kBits/s Quantification de la différence entre le signal et sa prédiction Analyse + _ Transmission Synthèse
Principe du codage MP3 Filtrage des signaux dans différentes bandes de fréquences T. Cos et codage T. Cos et codage T. Cos et codage Emission des données T. Cos et codage T. Cos et codage Sélection des canaux utiles (effet de masquage 1er codage T. Fourier
Analyse par prédiction linéaire Canal vocal Impusions (cordes vocales) Bruit (pour les fricatives) Signal Synthétique Filtre récursif dont la réponse en fréquence est celle du spectre à court terme (~ 20 ms)
- Calcul de 11 coefficients de corrélation sur une portion de 25 ms (200 échantillons) - Application de l ’algorithme de Levinson pour obtenir les coefficients du filtre récursif (sous la forme d ’un filtre en treillis) - Transmission des coefficients et du signal résiduel (erreur de prédiction) au récepteur qui en déduit la synthèse du signal
Codage par prédiction linéaire analyse transmission synthèse calcul de corrélation algorithme de Levinson signal analysé signal synthétisé filtre non récursif A(z) coefficients du filtre A(z) filtre récursif 1/A(z) recherche de périodicité L (max de corrélation) e(t)e(t+L) signal résiduel e(t) signal résiduel e(t) v(t)=e(t)-r.e(t-L) e(t)=v(t)+r.e(t-L) L v(t) v(t) quantification recherche d’un élément ressemblant à un tronçon de v(t) dans un dictionnaire reconstruction de v(t) à partir des d(n) étape de compression d(n) d(n)
Analyse par prédiction linéaire Spectre de la portion de signal analysé fréquence Réponse en fréquence du filtre récursif modélisant le signal vocal
Code Excited Linear Prediction (CELP) Dictionnaire de signaux élémentaires Prédiction à long terme (intonation) Modèle du conduit vocal génération du signal d’entrée du filtre (cordes vocales, bruit)
Illustration de l ’application de la prédiction linéaire au codage de la parole en téléphonie fréquence temps (Ech 11025 Hz) temps
Réponse impulsionnelle du filtre non récursif A(z) Signal modélisé Corrélation : r(n) Coefficients de A(z) Algo de Levinson ou Schur temps temps Réponse impulsionnelle du filtre non récursif A(z) Signal modélisé Réponse impulsionnelle du filtre récursif 1/A(z) temps
Réponse impulsionnelle du filtre récursif temps Zéros de A(z) (pôles de 1/A(z)) Réponse en fréquence du filtre récursif fréquence
Signal résiduel à coder - Recherche de la périodicité (pitch : Spectre du signal résiduel temps Signal résiduel à coder - Recherche de la périodicité (pitch : prédiction à long terme on code x(t)-x(t-L) : estimer L - Quantification vectorielle L fréquence On découpe le signal en tronçons comparaison à des formes de signal mémorisées dont on transmet le numéro + transmission des coefs du filtre temps
Synthèse de son ; diphones Difficultés: Enchainement de sons élémentaires Intonation naturelle
Synthèse de parole Découpe d’un son élémentaire (p. ex. diphone) mbrola Découpe d’un son élémentaire (p. ex. diphone) en période de longueur double de la période du pitch Chacun des ~1000 diphones (33x33) est découpé en 10 ou 20 sons élémentaires de 100 à 200 échantillons http://tcts.fpms.ac.be/synthesis/mbrola.html
On peut rajouter ces tronçons après les avoir décalés et amplifiés en fonction de la mélodie, de l ’intonation, ... Plus aigu : diminuer Plus grave : augmenter Modification de l ’amplitude en changeant
Reconnaissance de la Parole fondée sur les Modèles de Markov Cachés Hidden Markov Models 1. Introduction 2. Formulation en reconnaissance de parole 2.1 Reconnaissance (Viterbi) 2.2 Probabilité d’une séquence 2.3 Apprentissage 3. Mise en œuvre 3.1 Analyse spectrale à court terme 3.2 Quantification vectorielle 3.3 Forme usuelle de l’automate http://htk.eng.cam.ac.uk/
2. Automates utilisés dans les modèles de Markov cachés mesures n’ n états m’ m (Probabilités) transition Séquence d’états : Séquence de mesures : probabilité de transition de l’état m’ à l’état m probabilité de mesurer ‘n’ quand l’automate est dans l’état m probabilité que l’état initial soit m
Les trois problèmes : Séquence d’états : Séquence de mesures : 1. Reconnaissance : Y donné quelle est la S la plus probable ? 2. Quelle est la probabilité d’observer Y avec l ’automate (a,b,d) ? 3. Apprentissage : comment calculer a(m,m’), b(m,n) et d(m)
Algorithme de Viterbi Obtention de la séquence la plus probable Calcul par récurrence de Initialisation Récurrence Fin de l’algorithme Etat m « Treillis » pour représenter l ’évolution de l ’automate au cours du temps temps
Probabilité d’observation d’une séquence Y avec (a,b,d) Calcul à t croissant Utilisé pour comparer la pertinence de différents automates (un automate est associé à un mot) (aussi utilisé dans les « turbocodes en détection d ’erreurs »
Apprentissage de mots (cf. notes de cours) Calculer à partir de mesures Y de a(m,m’), b(m,n), d(m) (lourd : nécessite de nombreuses réalisations deY) Automate usuel (Bakis) Défauts de rythmes (doublement ou suppression d’une étape) voir aussi le « dynamic time warping » t’ t
3. Mise en forme des données mesurées sur la parole F o n e t i ch i an Associer à une portion de signal vocal (~20ms) une mesure y(t) : - Analyse spectrale à court terme un vecteur (dim 20) - Quantification vectorielle
Analyse spectrale à court terme Fréquence centrale du filtre linéaire exponentielle Echelle Mel Banc de filtres
Coefficients cepstraux Energie en sortie des différents filtres : C(n) Peuvent être liés aux coefficients de la prédiction linéaire
Quantification vectorielle Passer des c(k) aux y (mesures) Quantification vectorielle Trouver des représentants pour des nuages de points Choisir des centres de classes Assigner à cette classe les points voisins Prendre comme centre de classe le barycentre des points d’une classe réitérer jusqu ’à convergence
Toutefois, beaucoup de réglages et de variantes… Recherche : « comprendre » le signal vocal et l ’information qu ’il contient (et non se contenter d ’une « simple » comparaison) Comprendre le fonctionnement de la cochlée et du système nerveux auditif