Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

2
Trachéotomie précoce (oui/non)
")
3
3 hopitaux VM >18 ans Duree prévisible de VM>14 j APACHE II>25 Informed consent Pas de CI à la trachéo ou d’indication formelle

4
Que pensez vous de la méthode d’allocation dans cette étude contrôlée et de la façon dont elle est rapportée 1- parfait 2- peut aboutir à des biais 3- violation de l’aveugle possible 4- violation de l’aveugle possible et imprécision franche 5- rien

5
Si vous avez à randomiser 120 patients dans 2 hôpitaux… 1.Vous utilisez une randomisation électronique et vous équilibrez le tirage au sort comme suit: précoce/tardif/précoce/tardif/tardif/précoce/précoce/tardif (équilibré tous les 2 patients) 2.Vous utilisez une randomisation téléphonique et vous équilibrez comme suit: précoce/tardif/tardif/précoce/précoce/précoce/tardif/tardif/précoce/t ardif/précoce/tardif (équilibré tous les 4 patients) 3.Vous utilisez une randomisation téléphonique et une randomisation équilibré tous les 3 patients 4.Vous utilisez des blocs de taille importante (4 ou 6) de façon à rendre le clinicien totalement « aveugle » (par téléphone ou par voie électronique) 5.Vous utilisez une pièce de monnaie dans chaque centre?
 2.Vous utilisez une randomisation téléphonique et vous équilibrez comme suit: précoce/tardif/tardif/précoce/précoce/précoce/tardif/tardif/précoce/t ardif/précoce/tardif (équilibré tous les 4 patients) 3.Vous utilisez une randomisation téléphonique et une randomisation équilibré tous les 3 patients 4.Vous utilisez des blocs de taille importante (4 ou 6) de façon à rendre le clinicien totalement « aveugle » (par téléphone ou par voie électronique) 5.Vous utilisez une pièce de monnaie dans chaque centre")
6
Trachéo précoce dans les 48 h N=60 Pas de trachéo avant J14 (50 tracheo tardive) N=60 Protocole: Epreuve de sevrage Désédation tous les jours Tirage au sort Critère de jugement principal: VAP ???(probablement)
 N=60 Protocole: Epreuve de sevrage Désédation tous les jours Tirage au sort Critère de jugement principal: VAP (probablement)")
8
Le critère de jugement principal 1.Vous paraît être précis et reproductible 2.Vous paraît peu précis mais reproductible 3.Vous paraît précis mais peu reproductible 4.Vous paraît peu précis et peu reproductible et ne pas mesurer au mieux l’effet souhaité du traitement

9
Au vu des résultats, le calcul du nb de sujets nécessaires vous paraît? Bidon La puissance est très faible mais peu importe puisque la différence est significative totalement non adapté ce qui fait remettre en question le message de cette étude La puissance de cette étude est encore meilleure puisque la différence obtenue est très significative J’sais pas

10
La puissance La puissance (power) 1.C’est la chance de conclure à tort qu’il y a une différence alors qu’il n’y en a pas 2.C’est la chance de conclure à tort qu’il n’y a pas de différence alors qu’il y en a une 3.C’est la chance de trouver une différence alors qu’il y en a une 4.C’est la chance de ne pas trouver de différence alors qu’il n’y en a pas 5.C’est le nombre de patients que j’inclus dans chaque groupe de randomisation
 1.C’est la chance de conclure à tort qu’il y a une différence alors qu’il n’y en a pas 2.C’est la chance de conclure à tort qu’il n’y a pas de différence alors qu’il y en a une 3.C’est la chance de trouver une différence alors qu’il y en a une 4.C’est la chance de ne pas trouver de différence alors qu’il n’y en a pas 5.C’est le nombre de patients que j’inclus dans chaque groupe de randomisation")
11
Résultats:

12
Que pensez vous de la comparaison entre les 2 groupes 1.Elle est relativement précise et suffisante 2.On aurait du tester les différences (p values) 3.Elle aurait du mentionner les unités mais est suffisante 4.Elle n’apporte rien puisque l’on randomise 5.J’sais pas!
 3.Elle aurait du mentionner les unités mais est suffisante 4.Elle n’apporte rien puisque l’on randomise 5.J’sais pas!")
13
Que pensez vous de la valeur de l’APACHE II dans les 2 groupes 1.Il indique une violation des critères d’inclusion dans moins de 5% des cas ce qui est bien 2.Il indique une violation des critères d’inclusion dans moins de 20% des cas ce qui est bien 3.Il indique une violation des critères d’inclusion dans plus de 20% des cas 4.Il indique une violation des critères d’inclusion dans plus de 80% des cas 5.J’sais pas!

14
La mortalité est de 61.7% sur le tableau et de 30 % sur le graphe.. 1.C’est normal, car les malades sont sortis vivants (censure) 2.C’est normal car il meurent très tôt et ne sont pas pris en compte dans la courbe de survie à J28 3.C’est lié à l’information apportée par la censure 4.C’est parce que les courbes de survies ont été stoppées bien avant la fin du suivi hospitalier 5.C’est une erreur des auteurs
 2.C’est normal car il meurent très tôt et ne sont pas pris en compte dans la courbe de survie à J28 3.C’est lié à l’information apportée par la censure 4.C’est parce que les courbes de survies ont été stoppées bien avant la fin du suivi hospitalier 5.C’est une erreur des auteurs.")
15
La mortalité … 1.A J30 est identique en taux brut et en courbe de survie: c’est impossible 2.Est identique en brut et en censuré car la censure n’est pas informative 3.Est différente à J15 4.N’est différente que par l’existence d’une surmortalité tardive 5.J’sais pas Erratum CCM; 2004:32: 2566

16
Test du logrank : p<0.005…ça signifie… P<0.005 1.Que la mortalité à J30 est significativement différente 2.Que la mortalité à J15 est significativement différente mais ça ne se voit pas sur la courbe 3.Que indépendamment du temps de suivi, la mortalité est inférieur dans le bras trachéo précoce 4.Que, en moyenne sur l’ensemble des temps de suivi, la mortalité est inférieure dans le bras trachéotomie 5.Que les auteurs racontent n’importe quoi, il n’y a qu’a regarder les courbes des survie à J15 qui sont identiques alors qu’on est à 13 jours après la trachéo précoce!!!

17
Au total Une réponse fausse: 1.Le papier répond à vos attentes car il est randomisé 2.Tous les critères importants sont mesurés 3.Tous les patients randomisés sont inclus dans l’analyse 4.La signification clinique et statistique des résultats est discutée (bien que moyennement…) 5.Les patients de l’étude sont semblables aux votre 6.Cette prise en charge thérapeutique est réalisable en pratique
 5.Les patients de l’étude sont semblables aux votre 6.Cette prise en charge thérapeutique est réalisable en pratique")
19
LES META-ANALYSES Sont toujours des revues systématiques de l’ensemble de la littérature publiée Sont toujours basées sur les données individuelles publiées ou non sur un sujet donné Se limitent à une analyse retrospective des résultats publiés Peuvent inclure des données non randomisées Sont synonymes des revues « narratives » de la litterature

21
La sélection des études passant de 15950 à 5 Vous paraît être une bonne chose vu la qualité des études Vous paraît être du bidouillage de methodologiste Vous paraît être délétère pour les conclusions mais globalement basée sur les critères de sélection pré-définis Vous parait beaucoup trop sévère

22
Les résultats de la méta-analyse 1.La taille des carrés représente le poids de l’étude 2.Les barres horizontales sont l’intervalle de confiance des différences observées 3.En abscisse, c’est l’odds ratio pour les différentes études 4.Le chi2 mesure la significativité de la différence entre les 2 bras ici p pour 3 ddl= 0.02

23
Le tirage au sort dans les études randomisées Fondamental, le plus tard possible / inclusion La randomisation est la seule méthode qui vous permet d’équilibrer 2 échantillons et d’éviter les facteurs de confusion En effet la randomisation équilibre non seulement sur les facteurs de risque connus du critère de jugement mais aussi sur les facteurs inconnus ou non mesurés +++ La méthode la plus classique est la méthode des blocs AABB BBAA ABAB BABA ABBA AABBAB AAABBB BABABA ABABAB AAABBB …

24
Taille des blocs Si vous prenez un bloc trop petit, on peut deviner le prochain AB BA -Si vous prenez un bloc trop grand… Vous pouvez creer des déséquilibres ABABAB BBBAAA AAA…arrêt de l’étude 9 A et 6 B pour 15 malades

25
Faut-il stratifier? Oui si la population est constituée de sous groupe homogènes… Hôpital 1 population incluable mortalité de 72% Hôpital 2 population incluable mortalité de 36% Si vous ne stratifiez pas par centre vous risquez de déséquilibrer les groupes de traitement par centre et vous diminuerez la puissance des tests statistiques Si vous effectuez trop de stratification, vous risquez de déséquilibrer les effectifs…

26
Par exemple Bloc de 6/ 8 hôpitaux/120 malades A 15 B13 A32 B28 A3 B0 A8 B4 A6 B6 A0 B0 A0 B1 A1 B0 Tt A: 65 et Tt B 52 Taille des blocs env. 5 à 10 fois inf à la taille de vos strates En général bloc de 4 (bon compromis)
.")
27
Un bon critère de jugement doit être.. Unique Mesurer le mieux l’effet attendu du traitement (éviter les « surrogate markers: VAP DC ») De définition exacte précise et reproductible Mesuré de la même façon dans les 2 groupes +++ A quel moment le mesure-t-on?
 De définition exacte précise et reproductible Mesuré de la même façon dans les 2 groupes +++ A quel moment le mesure-t-on .")
28
Nombre de sujets nécessaires, alpha bêta

29
4 situations: Null hypothesis = TRUE Null hypothesis = FALSE Reject null hypothesisType I error= Correct decision Accept null hypothesisCorrect decisionType II error= Erreur de Type I = Rejeter l’hypothèse nulle quand elle est vraie (cf faux positifs) On peut éviter cette erreur en diminuant le seuil de significativité du test (par ex:p<0.01) Erreur de Type II = accepter l’hypothèse nulle quand elle est fausse (cf faux négatifs) La puissance c’est la probabilité 1- , de découvrir une différence alors qu’il y en a réèlement une. (par ex: 0.10, puissance 90%). Puissance = probabilité d’aboutir à une différence significative (en quelque sorte la « sensibilité » de l’étude) Augmenter ma puissance: augmenter la taille de l’échantillon,
. Puissance = probabilité d’aboutir à une différence significative (en quelque sorte la « sensibilité » de l’étude) Augmenter ma puissance: augmenter la taille de l’échantillon,.")
30
Pour calculer le nombre de sujets nécessaires, Il faut décider à priori: L’erreur de type I ( ; généralement 0.05 L’erreur de type II ou son complémentaire la puissance 1- généralement; La mesure des objectifs de l’étude: Quelle différence est biologiquement ou cliniquement intéressante (ou utile) et faisable? Il est en plus parfois nécessaire d’avoir une idée sur la distribution de la variable (écart type): échantillon préliminaire, analyse de la littérature.
: échantillon préliminaire, analyse de la littérature..")
31
Remarques sur , et n Théoriquement les 2 risques devraient être pris en compte dans chaque analyse statistique (« si p=0.06, combien j’ai de chance de conclure à l’absence de différence alors qu’il y en a une ») –Consensus tacite pour prioriser le status quo à la démonstration d’une différence En théorie: il faut ( ), et n avant tout test – : seuil en deçà duquel il n’est plus utile de démontrer une différence – , : fixés subjectivement En réalité: n=coût de l’expérience=contrainte le choix de , et souvent basé sur des critères douteux: on prend le delta minimum pour avoir un nombre de sujets raisonnables et une puissance à la limite du catastrophique !!! (0.8)
.")
32
Variables aléatoires Fluctuations d ’échantillonnage

33
Excel: tirage de pièce de monnaie …on refait l’expérience autant de fois que l’on veux

34
pièce de monnaie

36
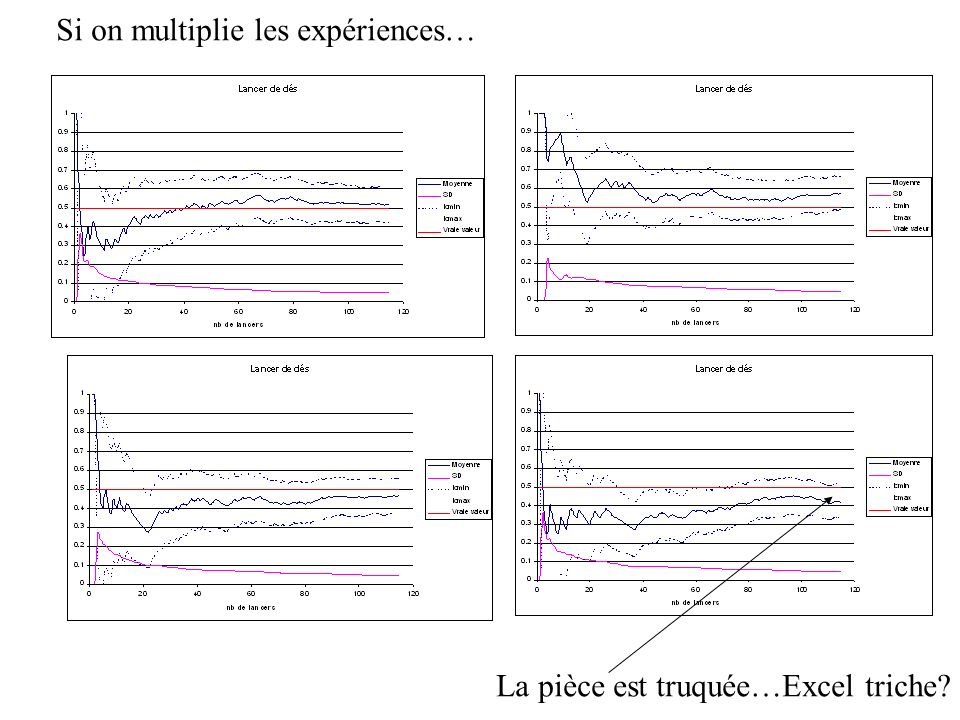
Si on multiplie les expériences… La pièce est truquée…Excel triche?

37
Erreur de première espèce Erreur consentie (proba de n’avoir que des 1 alors qu’il y a 6 faces différentes) Erreur expérimentale: 0.40 Pr (=1) = 1/6 = 0.17 Pr ( 1) = 1 - 0.17 = 0.83 Pr (=1) = 6 * (1/6) 1 * (5/6) 5 = 0.40 Proba d’avoir un 1 si on jette 6 fois les dés?
 Erreur expérimentale: 0.40 Pr (=1) = 1/6 = 0.17 Pr ( 1) = = 0.83 Pr (=1) = 6 * (1/6) 1 * (5/6) 5 = 0.40 Proba d’avoir un 1 si on jette 6 fois les dés")
38
TYPE I ERROR RATE Type I comparisonwise error rate: = 0.05 Type I experimentwise error rate: = 0.232 Pr = 6 * (0.05) 1 * (0.95) 5 = 0.232 p = 0.05 NS p = 0.05 NS
 1 * (0.95) 5 = p = 0.05 NS p = 0.05 NS")
39
Comparaisons multiples Test de Student Nb de comparaisons Risque vrai 1 3 6 10 15 21 0.05 0.1354 0.2321 0.3151 0.3658 0.3764

40
Paramètres de position Etendue = range MinMax Med Moy Intervalle interquartile 25 % Écart-type X 2 Sample size = 3659 Lowest value = 5.0000 Highest value = 96.1451 Arithmetic mean = 60.4688 Median = 64.0000 Variance = 318.1196 Standard deviation = 17.8359 Standard error of the mean = 0.2949 Coefficient of Skewness = -0.4953 (P<0.0001) Coefficient of Kurtosis = -0.5501 (P<0.0001) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0.001) Percentiles 95% Confidence Interval 2.5 = 22.0000 21.0000 to 23.0823 25 = 48.1355 47.0000 to 49.6546 75 = 74.3135 74.0000 to 75.0000 97.5 = 88.0000 87.4143 to 88.1833
 Coefficient of Kurtosis = (P<0.0001) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0.001) Percentiles 95% Confidence Interval 2.5 = to = to = to = to")
41
Distribution normale 1923273135 m SD = 4 m ± 2 SD = 95 % m ± SD = 68 % APACHE II: 27 ± 4 (mean ± SD)
")
42
Courbes de survie de Kaplan Meier et test du logrank Soit 2 groupes: Chimio d’un cancer Groupe A n=50: 40 DC, durée moyenne de suivi 48 ± 6 mois Groupe B n=50: 10 DC, durée de suivi 12 ± 3 mois Qu’est ce qui est mieux? 1.Groupe B, DC 20% vs 80%!!test du Chi 2=33.6, p<10 -4 2.Groupe A, durée de suivi plus long (t test: -35.77, p<10 -4 ) 3.C’est pareil 4 fois moins de DC mais 4 fois moins de durée de suivi 4.J’sais pas
 3.C’est pareil 4 fois moins de DC mais 4 fois moins de durée de suivi 4.J’sais pas.")
43
Données censurées/ données brutes Patient 1 Patient 2 Patient 3 Patient 4 Patient 5 Mars 200101/04/0101/05/0101/06/01 01/07/01 01 mois2 mois3 mois4 mois5 mois temps Echelonnement dans le temps de l’inclusion des patients dans la cohorte Description des durées de suivi Durées de suivi (jours) 93 62 65 96 155 Patient 6 Patient 7 Patient 8 Patient 9 Patient 10 Patient 1 Patient 2 Patient 3 Patient 4 Patient 5 temps Patient 6 Patient 7 Patient 8 Patient 9 Patient 10 45 70 34 90 50 Date des dernières nouvelles Date du point Date d’origine
 Patient 6 Patient 7 Patient 8 Patient 9 Patient 10 Patient 1 Patient 2 Patient 3 Patient 4 Patient 5 temps Patient 6 Patient 7 Patient 8 Patient 9 Patient 10 Date des dernières nouvelles Date du point Date d’origine")
44
Estimation de survie Kaplan Meier être encore en vie après un instant t, c’est être en vie juste avant cet instant t et ne pas mourir à cet instant. P(VV à t) /VV juste avant t n i est le nombre de sujets à risque à l’instant t i et d i est le nombre de décès au temps t i.
 /VV juste avant t n i est le nombre de sujets à risque à l’instant t i et d i est le nombre de décès au temps t i..")
45
A 60 mois, la probabilité cumulée de survie est le produit des q i, soit S(t) = 0,889 x 0,875 x 0,857 x 0,667 = 0,445 NB: taux brut de décès = 4/10 (40%) alors que estimation de survie à 60 j =55.5%
 = 0,889 x 0,875 x 0,857 x 0,667 = 0,445 NB: taux brut de décès = 4/10 (40%) alors que estimation de survie à 60 j =55.5%")
46
Méthode de Kaplan-Meier HYPOTHESES: - Censure non informative+++: le risque de survenue de l’événement après la censure pour un sujet i est identique à celui des sujets encore exposés au risque (la malades ne reviennent pas en CS car ils sont guéris!!! Ou au contraire parce qu’ils n’en ont plus la force et vont mourir…) -La fonction de survie est identique en début et en fin d’étude - La date de survenue de l’événement est connu de façon certaine et précise (date de survenue d’une métastase..) 1- Limiter au max les perdus de vue Préférer un temps de suivi fixe (28j) à un temps variable (sortie hôpital) 2- Attention aux durées d’inclusion trop longues 3- Si ça n’est pas le cas faites l’examen diagnostique à intervalle fixe, préférer les méthodes actuarielles
 -La fonction de survie est identique en début et en fin d’étude - La date de survenue de l’événement est connu de façon certaine et précise (date de survenue d’une métastase..) 1- Limiter au max les perdus de vue Préférer un temps de suivi fixe (28j) à un temps variable (sortie hôpital) 2- Attention aux durées d’inclusion trop longues 3- Si ça n’est pas le cas faites l’examen diagnostique à intervalle fixe, préférer les méthodes actuarielles.")
48
Comparaison de courbes de survie: test du Logrank H0: égalité des fonctions de survie dans les groupes Comparaison de la survie observée pour chaque groupe à une proportion attendue identique E A = e a et E B = e b et O a et O b = somme des déces observés Loi Chi2 à 1 ddl

49
Par exemple:

50
P=0.03

51
Test de logrank Vrai si absence de censure informative Il est à préférer au test de Wilcoxon (Gehan) ou au test de peto-prentice (poids différents au décès tardifs) Attention aux courbes de survies qui se croisent (en moyenne le test sera NS mais il existe peut être des intervalles de temps ou un des groupes est supérieur à l’autre Utilisation d’un logiciel recommandé!!!
 ou au test de peto-prentice (poids différents au décès tardifs) Attention aux courbes de survies qui se croisent (en moyenne le test sera NS mais il existe peut être des intervalles de temps ou un des groupes est supérieur à l’autre Utilisation d’un logiciel recommandé!!!")
52
The consort statement – Ann Intern Med 2004; 141:781-788

54
Validité des métanalyses

Présentations similaires