Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Utilisation de corpus de langage oral avec d’autres logiciels
Christophe Parisse, Inserm, Modyco/CNRS Université Paris Ouest Nanterre

2
Téléchargements Elan: http://tla.mpi.nl/tools/tla-tools/elan/download/
Présentation des données en partitions, codage des gestes, des interactions et représentation temporelle fine des données Clan: Codage textuel complet du langage oral (en particulier acquisition du langage). Présentation textuelles avec données secondaires. Commandes annexes. Transcriber: Codage textuel des interactions. Transcription au kilomètre. Pas de données secondaires. Praat: Logiciel de traitement et affichage de sons. Excel ou LibreOffice: Logiciels de manipulation de tableau de données R: Le logiciel libre de statistique, de traitement de corpus, de création de graphiques TXM: Un logiciel de textométrie permettant l’import de multiples fichiers textes Le Trameur: Un autre logiciel de textométrie possédant des caractéristiques différentes (seulement sous Windows) Jedit, Notepad++, TextWrangler Editeurs de texte brut permettant de modifier et de corriger semi-automatiquement les corpus de texte ou les tableaux en texte séparés par des tabulations ou des virgules
. Présentation textuelles avec données secondaires. Commandes annexes. Transcriber: Codage textuel des interactions. Transcription au kilomètre. Pas de données secondaires. Praat: Logiciel de traitement et affichage de sons. Excel ou LibreOffice: Logiciels de manipulation de tableau de données. R: Le logiciel libre de statistique, de traitement de corpus, de création de graphiques. TXM: Un logiciel de textométrie permettant l’import de multiples fichiers textes. Le Trameur: Un autre logiciel de textométrie possédant des caractéristiques différentes (seulement sous Windows) Jedit, Notepad++, TextWrangler. Editeurs de texte brut permettant de modifier et de corriger semi-automatiquement les corpus de texte ou les tableaux en texte séparés par des tabulations ou des virgules.")
3
Utilisation de tableur, de logiciels de textométrie (TXM), de statistiques (R), avec des corpus de langage oral Plan du cours Extraction depuis des corpus: Vers du texte en lignes et colonnes (pour tableur) Vers du texte –avec des séparateurs– (pour textométrie) Vers des fichiers structurés (XML simplifié) Utilisation de logiciel de textométrie Lexique Concordances Cooccurrences Autres fonctions Utilisation avec un tableur Codage Passage vers un logiciel de statistiques Retour vers un logiciel de transcription
 Vers du texte –avec des séparateurs– (pour textométrie) Vers des fichiers structurés (XML simplifié) Utilisation de logiciel de textométrie. Lexique. Concordances. Cooccurrences. Autres fonctions. Utilisation avec un tableur. Codage. Passage vers un logiciel de statistiques. Retour vers un logiciel de transcription.")
4
Exportations

5
Extraction de corpus La plupart des logiciels d’alignement de corpus ont des outils permettant l’export vers des formats textes ou csv (données séparées par des virgules ou des tabulations) Cette exportation permet de travailler avec des outils de statistiques, de textométrie, ou des tableurs. Il est parfois nécessaire, selon l’outil que l’on va utiliser de faire des ajustements sur les fichiers obtenus Changement d’encodage (format des accents) Insertion d’entete de fichiers Insertion ou modification des formats de lignes ou de mots La conversion peut être l’occasion d’utiliser d’outils (analyse syntaxique par exemple)
 Cette exportation permet de travailler avec des outils de statistiques, de textométrie, ou des tableurs. Il est parfois nécessaire, selon l’outil que l’on va utiliser de faire des ajustements sur les fichiers obtenus. Changement d’encodage (format des accents) Insertion d’entete de fichiers. Insertion ou modification des formats de lignes ou de mots. La conversion peut être l’occasion d’utiliser d’outils (analyse syntaxique par exemple)")
6
Exemples de corpus Le tutoriel est basé sur des exemples de corpus de plusieurs origines et formats: Transcriber: Corpus du français parlé parisien ( ) Clan: Corpus de Madeleine (Morgenstern – Paris corpus : Childes – ) Praat: Corpus Rhapsodie ( Elan: Corpus Rhapsodie après convertion par ELAN
 Clan: Corpus de Madeleine (Morgenstern – Paris corpus : Childes – ) Praat: Corpus Rhapsodie ( Elan: Corpus Rhapsodie après convertion par ELAN.")
7
Conversion depuis Transcriber
Les conversions de Transcriber vers du format texte peuvent se faire facilement en passant par ELAN ou par CLAN. TXM permet aussi l’import direct depuis Transcriber. ELAN ne permet toutefois pas le traitement de multiples fichiers Transcriber Fichiers à convertir un par un Passer de Transcriber à Clan Un outil est disponible (à télécharger sur la page du workshop : Conversion.jar – attention nécessite Java) Il permet une conversion vers Clan de répertoires complets
 Il permet une conversion vers Clan de répertoires complets.")
8
Conversions.jar (nécessite Java)
Cliquer sur: Convertir de Transcriber Vers CLAN Choisir dossier ou fichiers Convertir !

9
Conversion depuis CLAN
Les conversions depuis CLAN se réalisent à l’aide des commandes de CLAN CLAN permet de traiter en une seule fois tout un ensemble de fichiers CLAN permet de choisir les parties à extraire Il est aussi possible de nettoyer les corpus des codes spécifiques CHAT qu’ils peuvent contenir et mettre les énoncés dans une seule ligne (ou paragraphe) Les commandes CLAN permet aussi une conversion vers un format TABLEUR
 Les commandes CLAN permet aussi une conversion vers un format TABLEUR.")
10
Commandes CLAN d’extraction de Texte
FLO crée une ligne secondaire %flo contenant la transcription orthographique sans les codes spécifiques de CHAT L’option -d supprime la ligne principale et la remplace par la ligne sans code L’option -cm filtre la ligne principale de manière parallèle à la ligne %mor: LONGTIER crée un fichier CLAN sans retour à la ligne (tous les tiers sont mis sur une seule ligne) – cette option facilite le traitement par certains logiciels KWAL permet d’extraire certaines parties d’un corpus selon ses besoins
 – cette option facilite le traitement par certains logiciels. KWAL permet d’extraire certaines parties d’un corpus selon ses besoins.")
11
Enchainement des commandes clan
CLAN permet d’enchainer plusieurs commandes de suite D’abord FLO, puis LONGTIER, puis KWAL Chaque commande traite tous les fichiers et crée un nouveau fichier avec le résultat Soit crée un nouveau fichier avec une nouvelle extension Soit remplace l’ancien fichier (attention à avoir fait une copie !). Par exemple: Andre-Morange.cha … puis après FLO Andre-Morange.flo.cex … puis après LONGTIER Andre-Morange.flo.longtr.cex … puis après KWAL Andre-Morange.flo.longtr.kwal.cex
. Par exemple: Andre-Morange.cha … puis après FLO. Andre-Morange.flo.cex … puis après LONGTIER. Andre-Morange.flo.longtr.cex … puis après KWAL. Andre-Morange.flo.longtr.kwal.cex.")
12
Commande KWAL La commande kwal est la commande fondamentale pour extraire des données au format texte depuis des fichiers CLAN. Elle est utilisée pour le texte et pour l’insertion dans un tableur. Elle possède 18 paramètres dont 3 sont fondamentaux pour l’exportation: +d’valeur’ : paramètre réglant le format de sortie +d sortie au format texte brut +d4 sortie au format tableur +t’valeur’ : spécifie les champs à rechercher et afficher +t*NOM cherche les lignes principales du locuteur NOM +t%tier cherche les lignes secondaires de nom %tier -t*NOM cherche les lignes principales sauf celles du locuteur NOM -t%tier cherche les lignes secondaires sauf celles de nom %tier

13
Commande Kwal: suite +o’valeur’ : spécifie les champs à produire en dehors de ceux concernés par +t +o*MOT produit le locuteur MOT même s’il n’est pas recherché par +t +o%sit produit les lignes secondaires %sit même si elles ne sont pas recherchées par +t +s’motif’ : spécifie un motif à rechercher dans les éléments indiqués par +t/-t permet de n’extraire qu’une partie des données +u combine tous les fichiers en un seul +w’x’ -w’x’ produit des énoncés avant ou après les éléments recherchés +xCNT produit seulement les énoncés de C(><=)N(nombre)T(w,c,m) contenant un nombre de mots, caractères, morphèmes, inférieur, supérieur ou égal au nombre demandé Exemple: +x<3w seulement les énoncés de moins de trois mots
N(nombre)T(w,c,m) contenant un nombre de mots, caractères, morphèmes, inférieur, supérieur ou égal au nombre demandé. Exemple: +x<3w seulement les énoncés de moins de trois mots.")
14
Exemples CLAN Extraire tous les énoncés de l’adulte
flo +d *.cha kwal -t*CHI +d +f *.flo.cex longtier *.flo.kwal.cex chstring -w +s"+" "-" +y +1 *.cex remplace les + par des - Extraire les énoncés de l’enfant et les lignes phonétiques pour utilisation dans un tableur kwal +t*CHI +t%pho +d4 +f *.flo.cex

15
Conversion depuis ELAN vers des fichiers textes
Les conversions en masse (tout un ensemble de fichier d’un domaine) vers les logiciels tels que les tableurs (Excel, LibreOffice) et les logiciels de textométrie ou statistiques (Le Trameur, Lexico 3, TXM, R) se font par l’intermédiaire de fichiers texte. ELAN propose les options suivantes Texte séparé par des tabulations Les temps de début et de fin + Le contenu des acteurs + Le nom des fichiers Liste d’annotations Le contenu des acteurs Liste de mots Le lexique (avec choix des séparateurs de mots) Principes communs On doit sélectionner quels acteurs on veut récupérer et on génère un fichier en mentionnant son encodage (UTF8 recommandé)
 vers les logiciels tels que les tableurs (Excel, LibreOffice) et les logiciels de textométrie ou statistiques (Le Trameur, Lexico 3, TXM, R) se font par l’intermédiaire de fichiers texte. ELAN propose les options suivantes. Texte séparé par des tabulations. Les temps de début et de fin + Le contenu des acteurs + Le nom des fichiers. Liste d’annotations. Le contenu des acteurs. Liste de mots. Le lexique (avec choix des séparateurs de mots) Principes communs. On doit sélectionner quels acteurs on veut récupérer et on génère un fichier en mentionnant son encodage (UTF8 recommandé)")
16
Export vers un tableur Sélectionner : « exporter fichiers multiples en tant que » puis « texte délimité par des tabulations … » Choisir un nom de domaine comme pour une recherche Attention: tous les fichiers iront un seul document résultat pour traiter les fichiers un par un passer par « exporter vers » Choisir les acteurs et tiers que l’on veut exporter On peut cocher un par un Choisir uniquement dans les acteurs “racine” Sélectionner des acteurs: par nom de tiers par nom de type par nom de participant par nom d’annotateurs

17
Fenêtre de choix du format de sortie
On peut limiter l’intervalle de temps exporté On peut inclure le temps du média principal (pour les décalages et les synchronisations) On peut exclure les noms de tiers ou des participants ou avoir une colonne séparée par piste: les tiers ayant les mêmes débuts et fins sont mis sur la même ligne On peut choisir le type d’information temporelle fournie
 On peut exclure les noms de tiers ou des participants. ou avoir une colonne séparée par piste: les tiers ayant les mêmes débuts et fins sont mis sur la même ligne. On peut choisir le type d’information temporelle fournie.")
18
Exemple d’insertion dans excel
On extrait un seul fichier (Madeleine ) et seulement les données de CHI On choisi de ne pas exclure les noms des participants et tiers On prend toutes les informations temporelles On met en UTF8 dans le fichier mad1.txt
 et seulement les données de CHI. On choisi de ne pas exclure les noms des participants et tiers. On prend toutes les informations temporelles. On met en UTF8 dans le fichier mad1.txt.")
19
Résultat

20
Avec les champs superposés sur une même ligne (sur des colonnes différentes)
")
21
Insertion dans Excel Créer une feuille vierge dans Excel
Aller dans « Données » et « à partir du texte » Choisir le fichier Choisir l’encodage (UTF8) Choisir délimité par des tabulations seulement Insérer dans la fenêtre courante
 Choisir délimité par des tabulations seulement. Insérer dans la fenêtre courante.")
22
Insertion dans Excel

23
Insertion dans LibreOffice
Equivalent gratuit de Excel (Calc) Moins de fonction mais gratuit et n’a pas de bugs dans la gestion des codepages (accents). Aussi efficace que CLAN pour la saisie et la mise en forme Ouvrir le fichier .csv ou .xls dans LibreOffice Attention ne fonctionne pas pour les fichiers .txt, car LibreOffice croit que c’est un fichier Document de type “Word”(il faut alors le renommer avec une extension .csv) Utiliser l’utilitaire d’importation de texte pour choisir: Le codepage (UTF8) Les délimiteurs (tabulation et autres) Le type de chaque colonne
 Moins de fonction mais gratuit et n’a pas de bugs dans la gestion des codepages (accents). Aussi efficace que CLAN pour la saisie et la mise en forme. Ouvrir le fichier .csv ou .xls dans LibreOffice. Attention ne fonctionne pas pour les fichiers .txt, car LibreOffice croit que c’est un fichier Document de type Word (il faut alors le renommer avec une extension .csv) Utiliser l’utilitaire d’importation de texte pour choisir: Le codepage (UTF8) Les délimiteurs (tabulation et autres) Le type de chaque colonne.")
24
Edition de texte Tous les extractions de texte brut sont lisibles et peuvent être éditées par des logiciels dits d’édition de texte brut comme: Notepad++ (windows) JEdit (Windows, Mac, Linux) TextWrangler (Mac) Notepad++ et TextWrangler permettent de modifier le codepage (la gestion des accents) pour corriger des incompatibilités apparaissant avec les autres logiciels Si les fichiers sont au format tableur avec une séparation de colonnes réalisée avec une tabulation, alors il est possible de faire directement des copier-coller vers les tableurs (et inversement) Ils permettent des modifications rapides et systématiques avec des macros (Notepad++, JEdit).
 JEdit (Windows, Mac, Linux) TextWrangler (Mac) Notepad++ et TextWrangler permettent de modifier le codepage (la gestion des accents) pour corriger des incompatibilités apparaissant avec les autres logiciels. Si les fichiers sont au format tableur avec une séparation de colonnes réalisée avec une tabulation, alors il est possible de faire directement des copier-coller vers les tableurs (et inversement) Ils permettent des modifications rapides et systématiques avec des macros (Notepad++, JEdit).")
25
UTILISATION DE TXM

26
Utilisation de logiciels de textométrie
Avantages: Conçus pour analyser des grandes quantités de texte. Permettent de construire des lexiques, d’utiliser des concordanciers, de chercher des cooccurrences, d’analyser les textes et dans certains cas de faire le lien avec des logiciels de statistiques. Inconvénients: Pas toujours conçus pour travailler sur les interactions ou nécessite une adaptation des données. L’utilisation de fichiers structurés ou d’analyse syntaxique nécessite souvent une mise au point semi-manuelle.

27
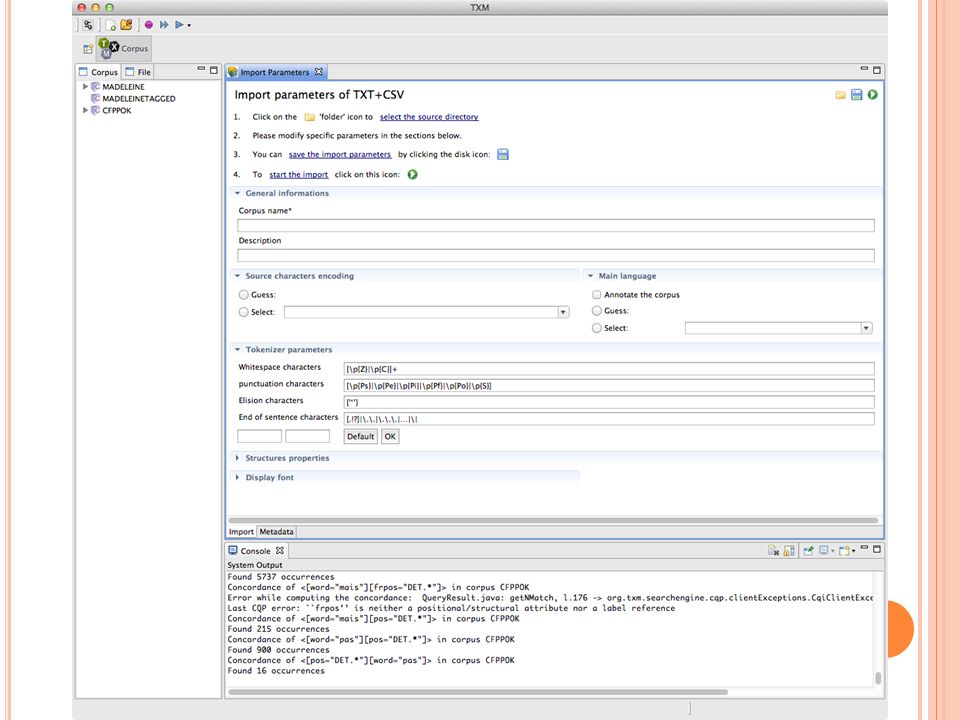
Installation de TXM TXM s’installe de façon simple et automatique.
Seule l’installation de TreeTagger doit se faire séparément à la main pour des raisons de droit de licence (TreeTagger est limité à l’utilisation non commerciale, ce qui n’est pas le cas de TXM). Voir Trois étapes: Installer le programme dans un répertoire de votre choix Télécharger et dézipper Installer les fichiers paramètres linguistiques (les données de l’analyseur) Aller dans TXM, Préférences, TXM, Advanced, NLP, TreeTagger et préciser les emplacements ou vous avez dézippé le programme et les données Il est possible d’utiliser l’apprentissage de TreeTagger spécifique pour l’oral développé à Nancy:
. Voir Trois étapes: Installer le programme dans un répertoire de votre choix. Télécharger et dézipper. Installer les fichiers paramètres linguistiques (les données de l’analyseur) Aller dans TXM, Préférences, TXM, Advanced, NLP, TreeTagger et préciser les emplacements ou vous avez dézippé le programme et les données. Il est possible d’utiliser l’apprentissage de TreeTagger spécifique pour l’oral développé à Nancy:")
28
Chargement depuis TXM TXM permet une importation simple depuis un ensemble de fichiers texte On va créer deux corpus, un contenant les productions de l’enfant, l’autre celles des personnes qui entourent l’enfant Corpus de Madeleine (Paris Corpus, CHILDES) flo -d *.cha kwal +t*CHI +d +fchi *.flo.cex kwal -t*CHI +d +fadu *.flo.cex longtier *.flo.chi.cex longtier *.flo.adu.cex Renommer tous les fichiers dans une extension .txt Peut se faire avec les commandes de clan: ren *.flo.chi.longtr.cex *_chi.txt +tTEXT ren *.flo.adu.longtr.cex *_adu.txt +tTEXT chstring -w +s"+" "-" +y +1 *.txt remplace les + par des - Résultat: 35 fichiers *_chi.txt et 35 fichiers *_adu.txt
 flo -d *.cha. kwal +t*CHI +d +fchi *.flo.cex. kwal -t*CHI +d +fadu *.flo.cex. longtier *.flo.chi.cex. longtier *.flo.adu.cex. Renommer tous les fichiers dans une extension .txt. Peut se faire avec les commandes de clan: ren *.flo.chi.longtr.cex *_chi.txt +tTEXT. ren *.flo.adu.longtr.cex *_adu.txt +tTEXT. chstring -w +s + - +y +1 *.txt. remplace les + par des - Résultat: 35 fichiers *_chi.txt et 35 fichiers *_adu.txt.")
29
Importation depuis TXM
TXM importe tous les fichiers d’un répertoire en une seule passe. Il faut donc organiser les données en fonction de l’importation désirée. On peut plus tard créer dans TXM des sous-corpus. Plusieurs formats sont possibles: Texte brut XML/w (fichier contenant des balises <w>) Transcriber A l’importation il est possible d’indiquer: Le codepage, la langue (nécessaire !) La manière de découper en mots (valeurs pour les espaces, les ponctuations, les élisions, les fins d’énoncés) Il est possible de joindre des métadonnées
 Transcriber. A l’importation il est possible d’indiquer: Le codepage, la langue (nécessaire !) La manière de découper en mots (valeurs pour les espaces, les ponctuations, les élisions, les fins d’énoncés) Il est possible de joindre des métadonnées.")
31
Utilisation de TXM L’espace de travail est divisé en trois zones
Corpus Présentation des données Console (information, notification des erreurs)
")
32
Fonctions principales de TXM
Accessible en faisant un clic droit de la souris sur le nom d’un corpus dans la partie gauche Variable selon les commandes possibles pour un corpus Description Lexique Index Concordance Cooccurrences

33
Description Indications générales sur le nombre de mots ou d’unité. Permet de contrôler les structures gérées par TXM.

34
Lexique Affichage de l’ensemble des mots du corpus ou sous-corpus
Trier par ordre alphabétique ou fréquence Filtrer par niveau de fréquence Déterminer la quantité de mots affichés par page Cliquer sur une ligne amène à l’outil Concordances

35
Lexique : autres éléments
Le lexique peut être généré à partir d’autres éléments (cliquer sur edit) Catégories part of speech Lemmes Mots
 Catégories part of speech. Lemmes. Mots.")
36
Index Même type d’affichage que « lexique » mais se construit à partir d’un requête quelconque Combinaison de propriétés Cliquer sur « Editer » Sélectionner les propriétés à gauche pour les mettre à droite et les organiser en hiérarchie. Requêtes CQL [frlemma="pouvoir"]

37
Requêtes Index

38
Concordances Les fenêtres de concordances affichent des items et leurs contextes gauches et droits On peut y accéder en faisant une requête directement dans une visualisation de lexique ou d’index Clic droit de la souris Choisir concordance On peut ouvrir directement une fenêtre de concordances dans le menu corpus

39
Concordances Requête CQL Forme cible Contexte gauche Contexte droit

40
Concordances Choix des propriétés Eléments de tri Trier ! Formes cible

41
Distance entre pivot et mot
Cooccurrences On ouvre directement une fenêtre de concordances dans le menu corpus et on fait une requête CQL (sur un mot simple ou une requête complexe) Requête Mot pivot Propriétés Taille du contexte Cooccurrents Distance entre pivot et mot
 Requête. Mot pivot. Propriétés. Taille du contexte. Cooccurrents. Distance entre pivot et mot.")
42
Paramètres des cooccurrences
Fréquences du mot contexte et de la cooccurrence Fréquence cooccurrent Co-fréquence

43
Paramètres des cooccurrences
Taille du contexte gauche et droit Distance entre pivot et cooccurrence à gauche Distance entre pivot et cooccurrence à droite Accéder aux cooccurrences

44
Affichage des concordances de cooccurrence

45
Requêtes CQL Ces requêtes sont utilisées pour toutes les commandes de recherche de TXM (CQL = Corpus Query Language) Requête de base: Un seul mot sans autre indication ! Requête avancée: Une propriété et une valeur [word="autre"] Plusieurs valeurs de suite [word="autre"][word="fois"] [frpos="DET:pos"][frpos="NOM"] [frpos="det:pos"%c][frpos="nom"%c] la même chose sans tenir compte de la casse Expressions régulières [word="au.*"] mots commençant par au et de fin quelconque [word="au."] mots commençant par au suivis d’une seule lettre [word="au.?"] mots commençant par au suivis de une ou zéro lettre

46
Requêtes CQL ou | et & paix|guerre paix ou guerre
[frpos="NAM|NOM"] catégorie NAM ou NOM et & [frlemma="pouvoir" & frpos="NOM"]

47
Requêtes CQL sur plusieurs mots
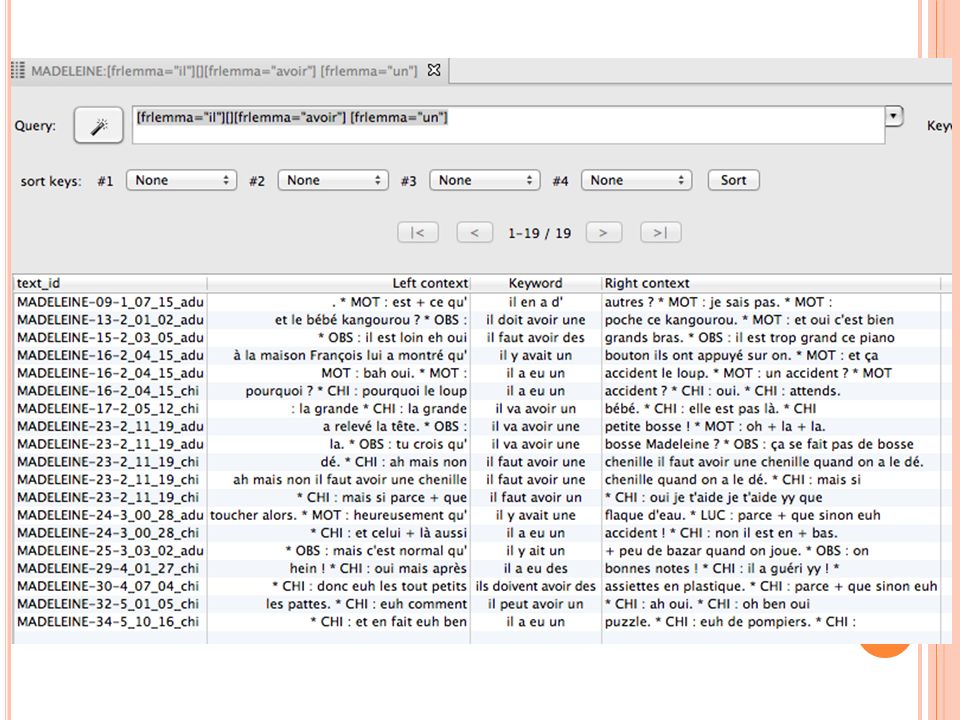
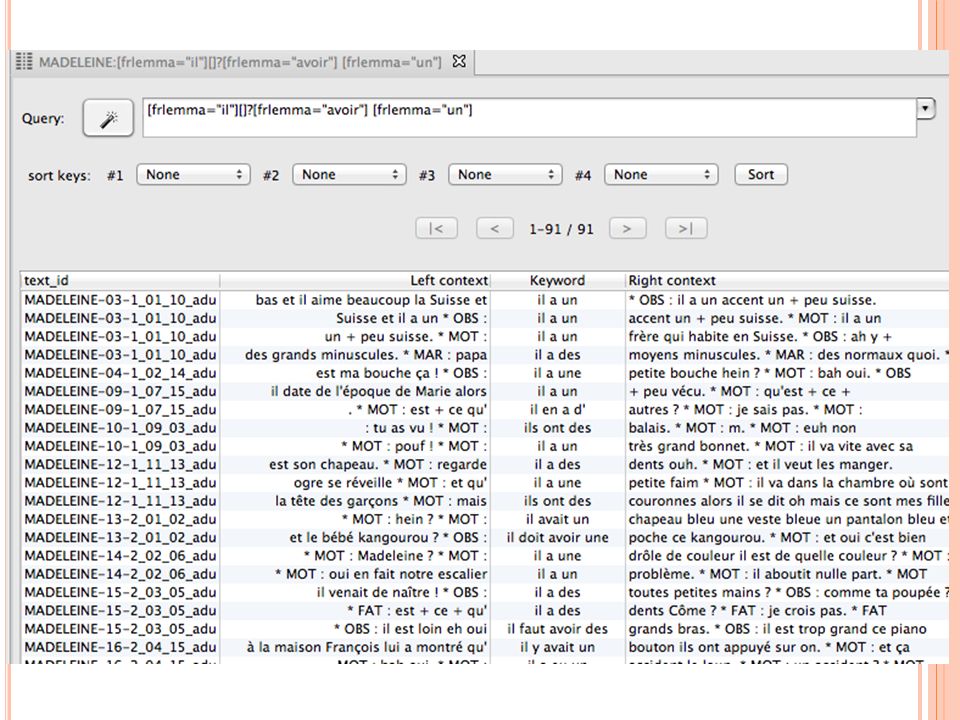
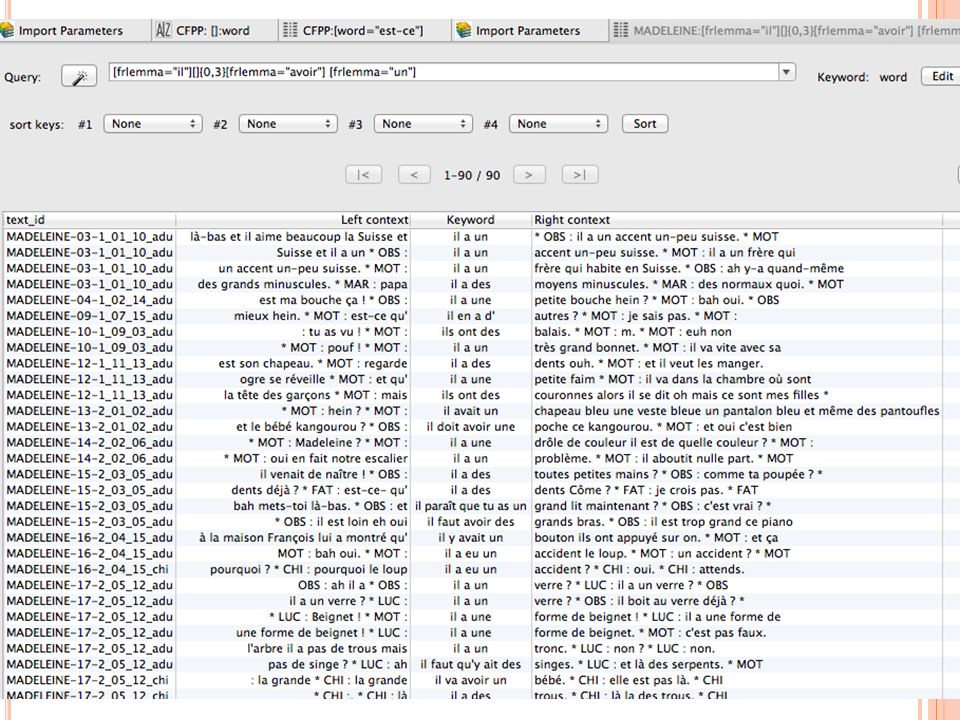
[frlemma="il"][][frlemma="avoir"] [frlemma="un"] Un mot quelconque entre « il » et « avoir un » [frlemma="il"][]?[frlemma="avoir"] [frlemma="un"] Un mot quelconque ou rien entre « il » et « avoir un » [frlemma="il"][][][][frlemma="avoir"] [frlemma="un"] Trois mots quelconques entre « il » et « avoir un » [frlemma="il"][]{0,3}[frlemma="avoir"] [frlemma="un"]

52
French TreeTagger Part-of-Speech Tags -- Achim Stein, April 2003
ABR abreviation PRO:DEM demonstrative pronoun VER:cond verb conditional ADJ adjective PRO:IND indefinite pronoun VER:futu verb futur ADV adverb PRO:PER personal pronoun VER:impe verb imperative DET:ART article PRO:POS possessive pronoun (mien, tien, ...) VER:impf verb imperfect DET:POS possessive pronoun (ma, ta, ...) PRO:REL relative pronoun VER:infi verb infinitive INT interjection PRP preposition VER:pper verb past participle KON conjunction PRP:det preposition plus article (au,du,aux,des) VER:ppre verb present participle NAM proper name PUN punctuation VER:pres verb present NOM noun PUN:cit punctuation citation VER:simp verb simple past NUM numeral SENT sentence tag VER:subi verb subjunctive imperfect PRO pronoun SYM symbol VER:subp verb subjunctive present
 VER:impf. verb imperfect. DET:POS. possessive pronoun (ma, ta, ...) PRO:REL. relative pronoun. VER:infi. verb infinitive. INT. interjection. PRP. preposition. VER:pper. verb past participle. KON. conjunction. PRP:det. preposition plus article (au,du,aux,des) VER:ppre. verb present participle. NAM. proper name. PUN. punctuation. VER:pres. verb present. NOM. noun. PUN:cit. punctuation citation. VER:simp. verb simple past. NUM. numeral. SENT. sentence tag. VER:subi. verb subjunctive imperfect. PRO. pronoun. SYM. symbol. VER:subp. verb subjunctive present.")
53
Autres fonctions avancées de TXM
Progression Graphique montrant la progression des occurrences dans un texte À appeler depuis Lexique ou le menu principal Cumulatif ou non cumulatif

54
Progression chez l’enfant

55
Progression chez l’adulte

56
Autres fonctions (suite)
Spécificités Différences entre une partie de corpus et le reste du corpus Spécificité pour le sous-corpus Enfant (obtenu en sélectionnant seulement les transcriptions de l’enfant) et le reste du corpus de Madeleine A utiliser à partir du menu clic droit depuis le sous-corpus
 et le reste du corpus de Madeleine. A utiliser à partir du menu clic droit depuis le sous-corpus.")
57
Autres fonctions (suite)
Références Génère toutes les fréquences pour les différents résultats d’une requête Partitions Création de partitions à partir d’éléments structurels AFC: analyse factorielle des correspondances d’une partition Classification hiérarchique Nécessite une AFC et une partition Table lexicale Unité lexicale d’une partition

58
Exports Il est possible d’exporter les résultats de TXM dans plusieurs formats selon le cas: CSV (résultats) SVG (graphiques) XML (résultats pour réaffichage dans TXM) Utiliser clic droit de la souris dans les objets de gauche ou cliquer sur les icones en haut à gauche (présents en fonction du contexte)
 XML (résultats pour réaffichage dans TXM) Utiliser clic droit de la souris dans les objets de gauche ou cliquer sur les icones en haut à gauche (présents en fonction du contexte)")
59
Edition des corpus à l’aide d’outils automatiques ou semi-automatiques

60
Aller plus loin Pour de nombreux outils, les formats standards issus des conversions depuis les logiciels d’annotation ne suffisent pas. Par TXM tire parti de la structuration de Transcriber mais ne le fait pas pour CLAN et ELAN, ou pour des fichiers textes. Il est possible de manipuler et éditer des textes en utilisant des langages de programmation adaptés: R, Perl, Python, AWK Il est possible de faire certaines manipulations systématiques avec des éditeurs de texte disposant de macros.

61
Exemple: structure des mots dans TXM
Il est intéressant de rajouter de la structure de mots dans TXM pour créer par exemple un corpus mélangeant l’adulte et l’enfant, et pouvoir accéder aux différents âges. L’idée est d’ajouter à chaque mot l’information du locuteur et de l’âge de l’enfant. Le format passe de .txt à .xml Les mots deviennent, par exemple: chat <w loc=‘CHI’ age=‘2_07_07’>chat</w> Une ligne complète devient: *CHI: c’est des épinards . <s loc="CHI "><w who="CHI" age=”2_07_07">c'est</w><w who="CHI" age="2_07_07">des</w><w who="CHI" age="2_07_07">épinards</w><w who="CHI" age="2_07_07">.</w></s>

62
Programmation dans R Traitement d’un fichier par: toxml(‘nomfichier’, nom-reference, age)
toxml <- function(fn, nom, age) { d <- scan(fn, what='char', sep="\n") cat( "<?xml version='1.0' encoding='UTF-8'?>\n" ) cat( "<text titre=\"", nom, "\">\n", sep="" ) for (l in d) { ws <- unlist(strsplit(l, "\\s")) loc <- substr(ws[1], 2, nchar(ws[1])-1) cat( "<s loc=\"", loc,”\">", sep="" ) for (k in ws[2:length(ws)]) { cat( "<w who=\"", loc, "\" age=\"", age, "\">", k, "</w>", sep="" ) } cat("</s>\n") cat("</text>\n")
 { d <- scan(fn, what= char , sep= \n ) cat( < xml version= 1.0 encoding= UTF-8 >\n ) cat( <text titre=\ , nom, \ >\n , sep= ) for (l in d) { ws <- unlist(strsplit(l, \\s )) loc <- substr(ws[1], 2, nchar(ws[1])-1) cat( <s loc=\ , loc, \ > , sep= ) for (k in ws[2:length(ws)]) { cat( <w who=\ , loc, \ age=\ , age, \ > , k, </w> , sep= ) } cat( </s>\n ) cat( </text>\n )")
63
Lancement dans R setwd('/corpusoraux/madeleine_all/')
files <- list.files(pattern="*.txt") for (f in files) { newfn <- substr(f,1,nchar(f)-4) age <- substr(f,14,nchar(f)-4) fnout <- paste(newfn, ".xml", sep="") sink(fnout) toxml(f, newfn, age) sink() }
 for (f in files) { newfn <- substr(f,1,nchar(f)-4) age <- substr(f,14,nchar(f)-4) fnout <- paste(newfn, .xml , sep= ) sink(fnout) toxml(f, newfn, age) sink() }")
64
Départ

65
Résultat Utilisation de XML/w pour l’importation des données

66
Permet de capturer des informations plus précises dans TXM: mot + Locuteur + age

67
En spécifiant l’enfant

68
En interdisant l’enfant

69
D’autres possibilités
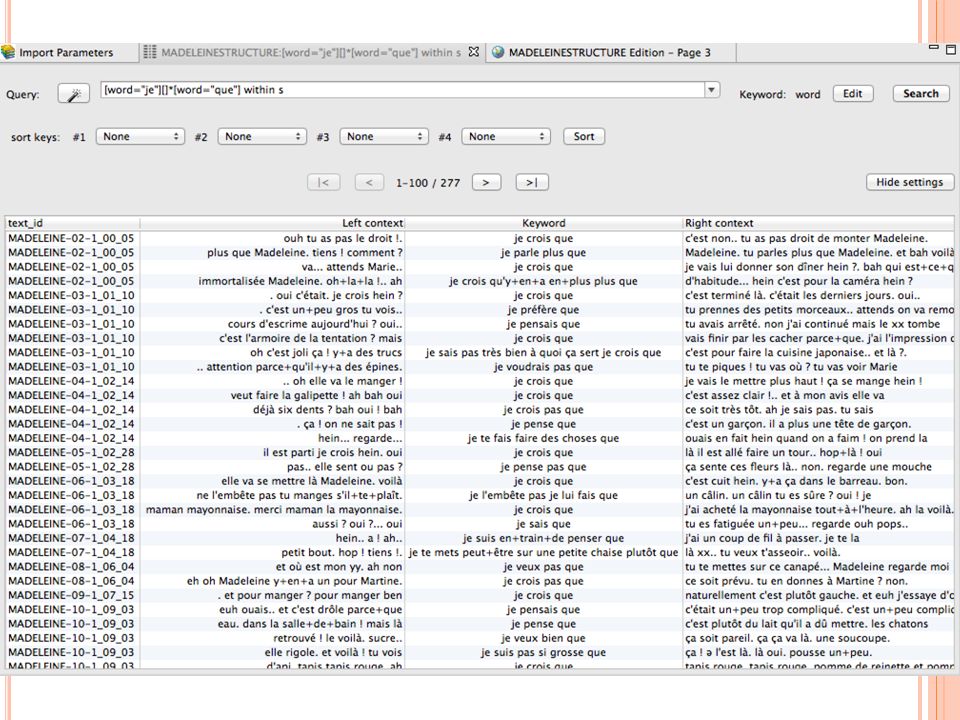
Utiliser les structures d’énoncés inscrites dans le format xml : <s> Facilite la tâche pour faire des sous-corpus ou partitions Permet d’utiliser les limites de l’énoncés dans les recherches [word="je"][]*[word="que"] Recherche de toutes les parties du corpus allant d’un ‘je’ à un ‘que’, y compris à travers des frontières d’énoncés [word="je"][]*[word="que"] within s Recherche de toutes les parties du corpus allant d’un ‘je’ à un ‘que’, mais en limitant à l’intérieur d’un énoncé

71
Création de sous-corpus ou de partitions
Choisir une structure et la valeur de sa propriété Le résultat est une partie de corpus sur lequel on peut travailler sans spécifier le locuteur Index, concordances, etc.

72
UTILISATION DE TABLEUR

73
Importation depuis excel (fichier avec des tabulations)
Partir d’une feuille de tableur on peut avoir des colonnes avec des indications temporelles des noms d’acteurs ou de tiers des valeurs d’annotation Elan permet de fixer la valeur de chaque colonne lors de l’importation Attention le fichier importé doit être en UTF8

74
Utilisation de tableur
L’extraction de données de textes permet de travailler directement dans un tableur: Permet de coder des données plus complexes que dans certains logiciels de transcription Selon les préférences individuelles on utilisera l’un ou l’autre

75
Utilisation de tableur pour le codage
Avantages: On peut utiliser des contrôles de données (vocabulaire, type de données, intervalles) assez complexes. On peut générer des données complémentaires On peut réaliser des statistiques de base On peut facilement exporter les résultats vers des logiciels de statistiques Inconvénients: Sauf adaptation spéciale, on ne peut plus accéder au sons ou vidéos originales Il est complexe de repartir des données de tableur et de reconstruire des transcriptions classiques
 assez complexes. On peut générer des données complémentaires. On peut réaliser des statistiques de base. On peut facilement exporter les résultats vers des logiciels de statistiques. Inconvénients: Sauf adaptation spéciale, on ne peut plus accéder au sons ou vidéos originales. Il est complexe de repartir des données de tableur et de reconstruire des transcriptions classiques.")
76
Exemple de macros excel pour accéder aux vidéos
Si on dispose du nom du film et du nombre de seconde correspondant à un énoncé (ce format peut être obtenu avec Elan à condition d’éditer le fichier résultat), on peut utiliser un outil vidéo pour jouer directement la vidéo ou le son. Conditions: Première colonne de Excel donne le nom du fichier média Deuxième colonne de Excel donne le nombre de secondes correspondant à la scène Fichier de type “excel”.xlsm permettant l’usage des macros et macros autorisées (voir fichier exemple ‘utilisation_excel.xlsm’ à utiliser comme base dans la quelle ajouter les nouvelles informations)
, on peut utiliser un outil vidéo pour jouer directement la vidéo ou le son. Conditions: Première colonne de Excel donne le nom du fichier média. Deuxième colonne de Excel donne le nombre de secondes correspondant à la scène. Fichier de type excel .xlsm permettant l’usage des macros et macros autorisées (voir fichier exemple ‘utilisation_excel.xlsm’ à utiliser comme base dans la quelle ajouter les nouvelles informations)")
77
Contenu de la macro Public Sub affvideo() ActiveCell.EntireRow.Select
ActiveCell.Offset(0, 1).Select ActiveCell.Offset(0, -1).Select f = ActiveCell.Value l = ActiveCell.Value #If Mac Then chemin = Replace(ActiveWorkbook.Path, ":", "/") p = "do shell script ""/Applications/VLC.app/Contents/MacOS/VLC " & "\""VOLUMES/" & chemin & "/" & f & "\"" --start-time=" & l & " --video-on-top --aspect-ratio 16:9""" MacScript (p) #Else p = "C:\Program Files (x86)\VideoLAN\VLC\vlc.exe """ & ActiveWorkbook.Path & "\" & f & """ --start-time=" & l & " --video-on-top --aspect-ratio 16:9" Shell (p) #End If End Sub
.Select. ActiveCell.Offset(0, -1).Select. f = ActiveCell.Value. l = ActiveCell.Value. #If Mac Then. chemin = Replace(ActiveWorkbook.Path, : , / ) p = do shell script /Applications/VLC.app/Contents/MacOS/VLC & \ VOLUMES/ & chemin & / & f & \ --start-time= & l & --video-on-top --aspect-ratio 16:9 MacScript (p) #Else. p = C:\Program Files (x86)\VideoLAN\VLC\vlc.exe & ActiveWorkbook.Path & \ & f & --start-time= & l & --video-on-top --aspect-ratio 16:9 Shell (p) #End If. End Sub.")
78
Exemple de codage et d’utilisation
Etude de la structure argumentale sur 6 verbes Codage: Verbe Forme grammaticale Temps Personne Argument Nombre d’arguments

79
Exemple de calcul statistique descriptif Création d’une table de donnée
Analyse descriptive Décrire et compter les données en fonction de différentes catégories Exemple du fichier arguments.xlsx Feuille Enfants-6verbes Créer un tableau croisé dynamique (cliquer sur l’icone “tableau croisé dynamique” dans insertion ou données) Oter les variables positionnées par défaut pour démarrer sur un tableau vide
 Oter les variables positionnées par défaut pour démarrer sur un tableau vide.")
80
Mettre des variables dans le tableau
enfant en étiquettes de lignes verbe en étiquettes de colonnes verbe en somme de valeurs (NB: nombre) Remplacer verbe par P (personnes) et nbargs (nombre d’arguments) 147 verbes à la première personne et avec 2 arguments NB sur verbe Étiquettes de colonnes Étiquettes de lignes attendre dire donner enlever mettre tenir Total léonard 4 41 62 2 20 170 madeleine 169 63 47 91 295 756 théophile 24 19 11 38 13 116 197 123 120 104 374 124 1042 NB sur verbe Étiquettes de colonnes 1 Somme 1 2 Somme 2 3 Somme 3 Étiquettes de lignes 4 léonard 7 19 6 32 57 61 12 14 10 37 madeleine 31 113 44 190 230 9 15 286 39 63 théophile 29 27 11 43 20 Total 48 147 52 251 314 18 390 23 64 120
 Remplacer verbe par P (personnes) et nbargs (nombre d’arguments) 147 verbes à la première personne et avec 2 arguments. NB sur verbe. Étiquettes de colonnes. Étiquettes de lignes. attendre. dire. donner. enlever. mettre. tenir. Total. léonard madeleine théophile NB sur verbe. Étiquettes de colonnes. 1. Somme Somme Somme 3. Étiquettes de lignes. 4. léonard madeleine théophile Total")
81
Rapports entre personne et nombre d’arguments
P (personne) en étiquettes de lignes nbargs en étiquettes de colonnes NB sur verbe Étiquettes de colonnes Étiquettes de lignes 1 2 3 4 Total 48 147 52 251 314 14 43 18 390 23 64 29 120 5 10 13 6 7 12 72 22 106 8 9 33 55 (vide) 15 44 66 352 177 361 130 1021
 en étiquettes de lignes. nbargs en étiquettes de colonnes. NB sur verbe. Étiquettes de colonnes. Étiquettes de lignes Total (vide)")
82
pour les trois enfants Mettre une variable (enfant) en filtre de la totalité du tableau Choisir Léonard Choisir Madeleine Choisir Théophile NB sur verbe Étiquettes de colonnes Étiquettes de lignes 1 2 3 Total 7 19 6 32 57 61 12 14 10 37 8 11 4 5 9 (vide) 29 51 160 NB sur verbe Étiquettes de colonnes Étiquettes de lignes 1 2 3 4 Total 31 113 44 190 230 9 15 286 7 39 63 5 58 22 89 8 30 11 48 (vide) 12 6 57 254 126 262 104 747 NB sur verbe Étiquettes de colonnes Étiquettes de lignes 1 2 3 Total 10 15 29 27 4 11 43 20 5 7 8 6 9 (vide) 37 22 48 114
 NB sur verbe. Étiquettes de colonnes. Étiquettes de lignes Total (vide) NB sur verbe. Étiquettes de colonnes. Étiquettes de lignes Total (vide)")
83
Plus grand exemple Corpus de Rhapsodie (http://projet-rhapsodie.fr/ )
Téléchargement possible des fichiers textGrid (Praat), sons, et autres. Tous ces fichiers peuvent être convertis en EAF (ELAN) puis exportés en fichier séparé par des tabulations par ELAN. Ce fichier (.csv) peut être directement importé dans Excel.
, sons, et autres. Tous ces fichiers peuvent être. convertis en EAF (ELAN) puis. exportés en fichier séparé par. des tabulations par ELAN. Ce fichier (.csv) peut être. directement importé dans Excel.")
84
Le tableau contient 163774 éléments (le nombre d’objets Praat de l’ensemble du corpus)
")
85
On peut utiliser les tableaux croisés sur les 163774 lignes pour faire des statistiques

86
Insertion dans R Un des avantages majeurs de l’utilisation de tableurs est de préparer les données pour leur utilisation dans un logiciel de statistiques Enregistrer une feuille en texte (séparateur: tabulation).txt
.txt.")
87
Loading data with R R has a lot of functions that are just build to deal with tables: read.table, write.table table, prop.table, xtabs, … Computing statistical measures Drawing graphics setwd('/corpusoraux/workshop-2013/') t <- read.delim("arguments-enfants.txt") table(t$P, t$nbargs) Same as before with Excel
 t <- read.delim( arguments-enfants.txt ) table(t$P, t$nbargs) Same as before with Excel.")
88
Quelques statistiques
> table(t$enfant,t$nbargs) résultats bruts leonard madeleine theophile > round(prop.table(table(t$enfant,t$nbargs),1),2)*100 pourcentages leonard madeleine theophile > chisq.test(c(65,35,51,19),c(257,129,265,104)) pas de différence entre léonard Pearson's Chi-squared test et madeleine data: c(65, 35, 51, 19) and c(257, 129, 265, 104) X-squared = 12, df = 9, p-value = > chisq.test(c(65,35,51,19),c(38,23,48,7)) pas de différence entre léonard Pearson's Chi-squared test et théophile data: c(65, 35, 51, 19) and c(38, 23, 48, 7) > chisq.test(c(257,129,265,104),c(38,23,48,7)) pas de différence entre madeleine data: c(257, 129, 265, 104) and c(38, 23, 48, 7)
 résultats bruts leonard madeleine theophile > round(prop.table(table(t$enfant,t$nbargs),1),2)*100 pourcentages leonard madeleine theophile > chisq.test(c(65,35,51,19),c(257,129,265,104)) pas de différence entre léonard Pearson s Chi-squared test et madeleine data: c(65, 35, 51, 19) and c(257, 129, 265, 104) X-squared = 12, df = 9, p-value = > chisq.test(c(65,35,51,19),c(38,23,48,7)) pas de différence entre léonard Pearson s Chi-squared test et théophile data: c(65, 35, 51, 19) and c(38, 23, 48, 7) > chisq.test(c(257,129,265,104),c(38,23,48,7)) pas de différence entre madeleine data: c(257, 129, 265, 104) and c(38, 23, 48, 7)")
89
Et un graphique > barplot(prop.table(table(t$enfant,t$nbargs),1), beside=T, legend=c('leonard','madeleine','theophile’)
,1), beside=T, legend=c( leonard , madeleine , theophile’)")
90
Importer de Excel vers Elan
Editer le fichier tableur et exporter la feuille Convertir le format si nécessaire Choisir le format de chaque colonne Résultat dans ELAN

91
Autres importations Il est possible d’importer depuis Transcriber (fichier de transcription), depuis Praat, depuis CLAN. Les importations depuis des CSV (fichiers séparés par des tabulations) peuvent être répétées successivement en tirant parti de la fonction « Fusionner les transcriptions » (menu Fichier) elle permet de superposer deux transcriptions et de mettre le résultat dans un nouveau fichier ce qui permet de faire plusieurs traitements ou transcriptions successives
 peuvent être répétées successivement en tirant parti de la fonction « Fusionner les transcriptions » (menu Fichier) elle permet de superposer deux transcriptions et de mettre le résultat dans un nouveau fichier ce qui permet de faire plusieurs traitements ou transcriptions successives.")
Présentations similaires




>")

 Choisir les données Base Élèves propose 3 sortes de listes, par exemple dans le menu : Elèves : Liste.>")













