Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
METHODES D’EVALUATION DES PROGRAMMES
Cellule d’Analyse de Politiques Economiques du CIRES ATELIER DE FORMATION DES RESPONSABLES DE LA PROGRAMMATION ET DU SUIVI ET EVALUATION DES ADMINISTRATIONS PUBLIQUES ET PRIVEES Thème : METHODES D’EVALUATION DES PROGRAMMES DE DEVELOPPEMENT 9-10 septembre 2009, Grand-Bassam Dr. Alban A. E. AHOURE Dr. Wautabouna OUATTARA

2
Lecture 0: Contexte, Objectifs et Résultats Attendus
Contexte et Justification Rareté des ressources nationales/ internationales affectées aux programmes de développement. Orienter celles-ci vers des projets ayant un impact réel sur les populations DSRP/PPTE Gestion Par les Résultats Comment Évaluer les Résultats / L’Impact ?

3
Objectifs Développement des connaissances sur les méthodes d’évaluation des programmes de Developpement Favoriser la compréhension des méthodes d’évaluation des projets de développement par les participants. Permettre aux participants de maîtriser les méthodes d’évaluation apprises. Permettre aux participants d’analyser ces méthodes, de dégager celles applicables aux projets dans leur institution et de savoir les utiliser. 3

4
Résultats attendus Les principes de base des Méthodes d’Évaluation des Programmes de Développement sont maîtrisés. Les processus d’évaluation des programmes sont connus et maîtrisés. Les participants sont en mesure d’évaluer les programmes de développement dans leurs structures respectives à partir méthodes apprises. 4

5
LA PROBLEMATIQUE DE L’EVALUATION DES POLITIQUES DE DEVELOPPEMENT
LECTURE 1 LA PROBLEMATIQUE DE L’EVALUATION DES POLITIQUES DE DEVELOPPEMENT

6
PLAN I. SUIVI ET EVALUATION DES PROJETS : Cadre Conceptuel
II. CONTEXTE III. LES DEUX APPROCHES METHODOLOGIQUES IV. QUELQUES NOTIONS SUR LES METHODES V. REVUE DE TRAVAUX EMPIRIQUES DANS LES PVD

7
I. SUIVI ET EVALUATION DES PROJETS : Cadre Conceptuel

8
II. CONTEXTE Demande croissante de preuves concernant les politiques de développement mises en œuvre : Ces politiques ont-elles les effets attendus ? Les effets sont-ils significatifs ? Domaines très variés : programme de bien-être, programmes de formation, programmes de subvention des salaires, programme de nutrition, programmes d’éducation, etc.

9
• Etudes sur documents, revues, interviews, données secondaires, etc.
A. REPONSES QUALITATIVES INSUFFISANTES • Etudes sur documents, revues, interviews, données secondaires, etc. • Etablir les inférences causales sur la base de processus (A B C). • Limites : Subjectivité dans la collecte des données, l’absence de groupe de comparaison et absence de robustesse statistique.
. • Limites : Subjectivité dans la collecte des données, l’absence de groupe de comparaison et absence de robustesse statistique.")
10
B. QUESTIONS SOULEVEES Quelle serait la situation des individus participant à un programme en l’absence du programme ? Quelle serait la situation des non exposés au programme s’ils en étaient bénéficiaires ? Ces deux questions ont un point commun : l’absence d’un don d’ubiquité. En d’autres termes, on ne peut à une date t, participer et ne pas participer au programme. Si existence d’informations sur les situations où le même individu à la fois participe et ne participe pas à un programme pas de problème pour l’évaluation. Besoin d’un contrefactuel

11
C. POURQUOI AVONS-NOUS BESOIN D’UN CONTREFACTUEL ?
Changement dans le Résultat = Dû au Projet + Dû aux Autres Facteurs (environnementaux, personnels) • Comparer les mêmes individus avant et après le projet ne contrôle pas pour les effets environnementaux. Impossibilité d’isoler les effets imputables à des facteurs exogènes au programme. • Comparer seulement des individus similaires mais non identiques au temps t ne contrôle pas pour les différences personnelles • Contrefactuel: contrôle à la fois pour les facteurs environnementaux et personnels. Toutes les évaluations quantitatives d’impact se résument en la construction d’un groupe contrefactuel crédible.
 • Comparer les mêmes individus avant et après le projet ne contrôle pas pour les effets environnementaux. Impossibilité d’isoler les effets imputables à des facteurs exogènes au programme. • Comparer seulement des individus similaires mais non identiques au temps t ne contrôle pas pour les différences personnelles. • Contrefactuel: contrôle à la fois pour les facteurs environnementaux et personnels. Toutes les évaluations quantitatives d’impact se résument en la construction d’un groupe contrefactuel crédible.")
12
III. LES DEUX APPROCHES METHODOLOGIQUES
Les Méthodes Expérimentales : construisent le contrefactuel par assignation randomisée d’un groupe de participants au projet (le groupe de traitement) et d’un groupe de non- participants (groupe témoin). Les Méthodes Non Expérimentales : obtiennent le contrefactuel par des techniques statistiques (Score de Propension et Appariement, Doubles Différences, Variables Instrumentales, Regression Discontinuity Design). Différent dans la manière de construire le contrefactuel.
 et d’un groupe de non- participants (groupe témoin). Les Méthodes Non Expérimentales : obtiennent le contrefactuel par des techniques statistiques (Score de Propension et Appariement, Doubles Différences, Variables Instrumentales, Regression Discontinuity Design). Différent dans la manière de construire le contrefactuel.")
13
IV. QUELQUES NOTIONS SUR LES METHODES
Les expérimentations contrôlées Elles ont débuté aux USA mais se sont étendues aux pays en développement. Pour évaluer un projet: expérimentation contrôlée fondée sur le principe de l’assignation aléatoire à un groupe de traitement et à un groupe de contrôle Le groupe de contrôle et le groupe de traitement sont en principe identiques. Seule la différence de traitement expliquerait les évolutions ultérieures des deux groupes.

14
Les méthodes expérimentales d’évaluation
L’objectif : Mettre en application un programme pour construire des conditions où les bénéficiaires sont entièrement comparables aux non bénéficiaires. Les méthodes expérimentales d’évaluation Les méthodes d’expérimentation contrôlée Proche de l’approche clinique. Repose sur la règle de l’assignation aléatoire. Loterie, Phase-in, Encouragement Les méthodes d’expérimentation naturelle Exploitent l’assignation aux programmes grâce à un évènement naturel survenu indépendamment du chercheur.

15
Portée et limites de l’approche expérimentale
Elle exerce un grand attrait : application transparente grande qualité du contrefactuel, principe simple: nécessite un petit échantillon. Intègre l’implémentation à l’évaluation. MAIS : Les expériences contrôlées ne s’appliquent pas à tous les projets raisons d’ordre éthique, d’ordre pratique : politique expérimentée souvent à une échelle réduite ; il est impossible alors d’extrapoler. La validité interne est fonction de la conception et de l’implémentation: problèmes d’attrition (des individus disparaissent de l’échantillon), spillover, contamination, biais de randomisation.
, spillover, contamination, biais de randomisation.")
16
B. Les évaluations quasi expérimentales
Beaucoup de projets sont mis en œuvre sans un dispositif explicite d’évaluation d’impact. Malgré tout, on veut savoir s’ils ont bien fonctionné : quelle est l’ampleur de leur effet sur les bénéficiaires. L’approche consiste à construire un groupe témoin dont les caractéristiques sont aussi comparables que celles du groupe des bénéficiaires de l’intervention. Comment construire le groupe contrefactuel? Méthodes: Score de Propension et Appariement, Doubles Différences, Variables Instrumentales, Regression Discontinuity Design.

17
Les Méthodes d’évaluation expérimentales
Les méthodes dites de « Discontinuity Design », Tirent profit des “discontinuités naturelles” dans la règle d’assignation des individus au traitement. Les méthodes d’appariement (matching) Cherchent à reproduire le groupe de traitement parmi les non bénéficiaires afin de reconstituer les conditions d’un cadre expérimental, et cela en s’appuyant sur les variables observables. Les méthodes de variables instrumentales Plus proches de celles de l’approche structurelle. Reposent sur des restrictions d’exclusion pour parvenir à l’identification. Le choix des paramètres d’intérêt dépend de l’environnement particulier dans lequel la politique est mise en œuvre. Les méthodes de fonction de contrôle Ces méthodes sont plus proches de celles de l’économétrie. Modélisent directement la règle d’assignation afin de contrôler la sélection dans les données d’observation .
 Cherchent à reproduire le groupe de traitement parmi les non bénéficiaires afin de reconstituer les conditions d’un cadre expérimental, et cela en s’appuyant sur les variables observables. Les méthodes de variables instrumentales. Plus proches de celles de l’approche structurelle. Reposent sur des restrictions d’exclusion pour parvenir à l’identification. Le choix des paramètres d’intérêt dépend de l’environnement particulier dans lequel la politique est mise en œuvre. Les méthodes de fonction de contrôle. Ces méthodes sont plus proches de celles de l’économétrie. Modélisent directement la règle d’assignation afin de contrôler la sélection dans les données d’observation .")
18
Portée et Limites des Méthodes Non- Expérimentales
• Pratiques applicables à presque tous les types d’intervention et peuvent quelque fois être appliquées de façon rétrospective. MAIS • Peuvent entraîner des biais dûs à la sélection des échantillons (pas de contrôle parfait) et/ou à la spécification des modèles. • Peuvent comprendre des données très intensives nécessitant des calculs compliqués.
 et/ou à la spécification des modèles. • Peuvent comprendre des données très intensives nécessitant des calculs compliqués.")
19
V. Revue de travaux empiriques dans les PVD
(1) La nature de l’intervention. -Transferts d’argent aux ménages en contrepartie d’obligations en matière d’éducation et de santé de leurs enfants: programme PROGRESA au Mexique, ou les travaux relatifs à l’Afrique du Sud (Aguiro, Carter et Woohard, 2007) ; Programme de petit déjeuner exécuté dans les écoles rurales (Cueto et alii., 2000) ; - Un paquet sanitaire offert sous la forme d’un déparasitage intestinal (Miguel et Kremer, 2004) ; - Programmes de subvention d’écoles pour la scolarisation des enfants (Behrman & al., 2005).
 La nature de l’intervention. -Transferts d’argent aux ménages en contrepartie d’obligations en matière d’éducation et de santé de leurs enfants: programme PROGRESA au Mexique, ou les travaux relatifs à l’Afrique du Sud (Aguiro, Carter et Woohard, 2007) ; Programme de petit déjeuner exécuté dans les écoles rurales (Cueto et alii., 2000) ; - Un paquet sanitaire offert sous la forme d’un déparasitage intestinal (Miguel et Kremer, 2004) ; - Programmes de subvention d’écoles pour la scolarisation des enfants (Behrman & al., 2005).")
20
(2) Les populations cibles sont variées: exemple les enfants de moins d’un an à 14 ans en milieu rural ou les parents comme dans le cas des programmes de transfert d’argent en Amérique latine ou en Afrique du Sud. (3) Deux stratégies d’échantillonnage: La sélection randomisée des participants et non participants lorsqu’il s’agit d’une expérimentation contrôlée, L’utilisation d’autres méthodes pour construire des groupes de contrôle lorsqu’on n’a pu en disposer avant le démarrage du programme.
 Deux stratégies d’échantillonnage: La sélection randomisée des participants et non participants lorsqu’il s’agit d’une expérimentation contrôlée, L’utilisation d’autres méthodes pour construire des groupes de contrôle lorsqu’on n’a pu en disposer avant le démarrage du programme.")
21
(4) La taille de l’échantillon.
Elle est souvent faible dans les études expérimentales, même dans les pays développés, par exemple, moins de 150 individus, dans la plupart des études sur l’éducation préscolaire qui ont été menées aux Etats-Unis (Behrman, Cheng, Todd, 2005). Cependant, des échantillons de grande taille sont parfois utilisés comme l’ont fait Chen, Mu et Ravaillion (2006) pour l’évaluation d’un programme de réduction de la pauvreté dans le sud ouest de la Chine (plus de 2000 bénéficiaires et non bénéficiaires). Behrman, Sengupta et Todd (2005), recourant à des données du programme PROGRESA au Mexique, ont construit un échantillon de 30 000 enfants pour étudier l’impact, sur leurs performances scolaires, des transferts d’argent dont leurs ménages ont bénéficié.
. Cependant, des échantillons de grande taille sont parfois utilisés comme l’ont fait Chen, Mu et Ravaillion (2006) pour l’évaluation d’un programme de réduction de la pauvreté dans le sud ouest de la Chine (plus de 2000 bénéficiaires et non bénéficiaires). Behrman, Sengupta et Todd (2005), recourant à des données du programme PROGRESA au Mexique, ont construit un échantillon de enfants pour étudier l’impact, sur leurs performances scolaires, des transferts d’argent dont leurs ménages ont bénéficié.")
22
(5) La durée d’exposition des bénéficiaires au traitement.
Elle peut être d’un an (Miguel, Kremer, 2004 ; Behrman, Sengupta et Todd, 2005), d’autres peuvent dépasser 10 ans (Chen, Mu et Ravaillion, 2006). (6) les effets attendus: même si le paquet de traitement est le même (par exemple, repas chauds ou déparasitage), les études ne mettent pas toujours l’accent sur. (7) Les indicateurs de performance : une grande variabilité. Certains insistent sur les impacts relatifs au statut nutritionnel mesuré par des indicateurs anthropométriques (poids-âge, taille-âge, ou taille-poids), d’autres s’intéressent à l’état sanitaire (Huerta, 2006) ou à l’éducation (Newman et al., 1994).
, d’autres peuvent dépasser 10 ans (Chen, Mu et Ravaillion, 2006). (6) les effets attendus: même si le paquet de traitement est le même (par exemple, repas chauds ou déparasitage), les études ne mettent pas toujours l’accent sur. (7) Les indicateurs de performance : une grande variabilité. Certains insistent sur les impacts relatifs au statut nutritionnel mesuré par des indicateurs anthropométriques (poids-âge, taille-âge, ou taille-poids), d’autres s’intéressent à l’état sanitaire (Huerta, 2006) ou à l’éducation (Newman et al., 1994).")
23
(8) L’effet moyen du traitement ou son effet marginal?.
Effet Moyen: la valeur de la variable d’impact du groupe de traitement est comparée à celle du groupe de comparaison. Effet marginale: l’effet marginal du traitement est mesuré, soit par la différence entre les effets moyens estimés à deux dates différentes, soit en comparant les valeurs prises par la variable d’impact pour des groupes de participants qui différent par leur durée d’exposition au traitement.

24
(9) Les méthodes utilisées: Les différences dans les stratégies d’échantillonnage et les types d’effets à mesurer une grande diversité : Certains travaux comparent les effets du groupe de traitement à ceux d’un groupe de contrôle en recourant à des techniques du traitement binaire comme les doubles différences ou les modèles de choix discret (Essama, 2006 ; Maluccio, Flores, 2005) D’autres recourent à des méthodes qui permettent de se passer de l’existence d’un groupe de contrôle et se concentrent sur le groupe de traitement (Imbens, 2004 ; Aguiro, Carter et Woohard, 2007).
 D’autres recourent à des méthodes qui permettent de se passer de l’existence d’un groupe de contrôle et se concentrent sur le groupe de traitement (Imbens, 2004 ; Aguiro, Carter et Woohard, 2007).")
25
(10) Quelques Résultats La plupart des travaux reportent des effets positifs des programmes sur la nutrition et le statut sanitaire. Miguel et Kremer (2004) ont évalué un projet kényan dans lequel un traitement de déparasitage de masse a été appliqué, par phases, à des élèves d’écoles choisies de manière randomisée. Le programme a enregistré une réduction de l’absentéisme d’un quart et stimulé la participation. QU’EST-CE QUE LA RANDOMISATION? QUELLES EN SONT LES PRINCIPES? POURQUOI CETTE METHODE CONNAIT-T-ELLE UN GRAND INTERET AUPRES DES ECONOMISTES DU DEVELOPPEMENT, AUJOURD’HUI?
 ont évalué un projet kényan dans lequel un traitement de déparasitage de masse a été appliqué, par phases, à des élèves d’écoles choisies de manière randomisée. Le programme a enregistré une réduction de l’absentéisme d’un quart et stimulé la participation. QU’EST-CE QUE LA RANDOMISATION QUELLES EN SONT LES PRINCIPES POURQUOI CETTE METHODE CONNAIT-T-ELLE UN GRAND INTERET AUPRES DES ECONOMISTES DU DEVELOPPEMENT, AUJOURD’HUI")
26
Je Vous Remercie Pour Votre Attention

27
Dr. Wautabouna OUATTARA
Cellule d’Analyse de Politiques Economiques du CIRES Atelier de formation des responsables de la programmation et du suivi et évaluation des administrations publiques et privées Lecture 2 : LA RANDOMISATION Dr. Wautabouna OUATTARA 9 septembre 2009, Grand-Bassam

28
REFERENCES Duflo, Esther, Rachel Glennerster, Michael Kremer (2008), “Using randomization in development economics research: a toolkit”, In Handbook of Development Economics, Volume 4, ed. T. Paul Schultz and John Strauss, 3895–3962. Amsterdam and Oxford: Elsevier, North-Holland. Imbens, Guido and Jeffrey Wooldridge (2009), “Recent developments in the econometrics of program evaluations”, JEL, 47(1), 5-86. Abadie, Alberto (2005), “Semiparametric Difference-in- differences estimators”, Review of Economic Studies 72(1), 28
, Using randomization in development economics research: a toolkit , In Handbook of Development Economics, Volume 4, ed. T. Paul Schultz and John Strauss, 3895–3962. Amsterdam and Oxford: Elsevier, North-Holland. Imbens, Guido and Jeffrey Wooldridge (2009), Recent developments in the econometrics of program evaluations , JEL, 47(1), Abadie, Alberto (2005), Semiparametric Difference-in- differences estimators , Review of Economic Studies 72(1),")
29
PLAN DE LA LECTURE I°/ GENERALITES SUR LA RANDOMISATION
2°/ INTERET DU RECOURS A LA RANDOMISATION 3°/ FORMALISATION DE LA RANDOMISATION 4°/ DIFFERENTES FORMES DE LA RANDOMISATION 5°/ EXEMPLE PRATIQUE AVEC LES DOUBLES DIFFERENCES 6°/ CONCLUSION 29

30
1. GENERALITES SUR LA RANDOMISATION
Depuis la fin des années 90, certains économistes du développement (notamment Michael Kremer, Esther Duflo, Abhijit Barnerjee…) ont développé des outils pour appréhender les faits des politiques économiques. Ils ont propulsé la théorie de la randomisation (évaluation aléatoire) et insistent sur les micro-projets comme stratégie de développement efficace quand on s'y prend rationnellement. 30
 ont développé des outils pour appréhender les faits des politiques économiques. Ils ont propulsé la théorie de la randomisation (évaluation aléatoire) et insistent sur les micro-projets comme stratégie de développement efficace quand on s y prend rationnellement. 30.")
31
Shanta Devarajan : La randomisation (ou application par répartition aléatoire) des programmes d’aide est actuellement considérée comme la « règle d’or » permettant d’évaluer l’impact de chaque projet et de trouver les schémas d’intervention les plus efficaces possible. Esther Duflo : La randomisation est une méthode qui est utilisée pour essayer d’évaluer l’impact d’un programme ou d’un projet dans des domaines tels que l’éducation, la santé, la corruption, le crédit, etc., . Le principe général: s’approcher au mieux de la méthode de l’essai clinique. On compare des gens qui ont bénéficié d’un traitement et des gens qui n’en ont pas bénéficié. Cela suppose que les personnes dans l’échantillon d’étude ont des similitudes). 31
. 31.")
32
L’objectif de l’expérience randomisée
Travailler avec les partenaires de terrain (ONG, Gouvernements locaux, Compagnies privées etc.) qui veulent mettre en application un programme pour construire des conditions où ceux qui bénéficient du programme soient entièrement comparables à ceux qui n’en bénéficient pas dans un premier temps. Exemple: Si un gouvernement a de quoi financer la construction de 100 écoles, on va choisir 200 villages au lieu de choisir les 100 qu’il aurait choisi de toute façon. Et après, on collecte des données sur les 200 depuis le début, ce qui permet de comparer par exemple la scolarisation des enfants sur les deux types de villages. Puis, en général, quand l’expérience est terminée, on construit des écoles partout. 32
 qui veulent mettre en application un programme pour construire des conditions où ceux qui bénéficient du programme soient entièrement comparables à ceux qui n’en bénéficient pas dans un premier temps. Exemple: Si un gouvernement a de quoi financer la construction de 100 écoles, on va choisir 200 villages au lieu de choisir les 100 qu’il aurait choisi de toute façon. Et après, on collecte des données sur les 200 depuis le début, ce qui permet de comparer par exemple la scolarisation des enfants sur les deux types de villages. Puis, en général, quand l’expérience est terminée, on construit des écoles partout. 32.")
33
1. Relation de causalité de nature déterministe
LES RELATIONS DE CAUSALITE 1. Relation de causalité de nature déterministe En général, on parle d’une relation de causalité de nature déterministe lorsque la présence de la cause implique l’effet et réciproquement, si on observe l’effet, la cause est présente au départ. Exemple : En supposant qu’une seule variable soit suffisante pour causer un phénomène, alors l’observation de cette caractéristique implique nécessairement le phénomène. D’autre part si on observe le phénomène chez un individu, alors celui-ci possède la caractéristique. Le lien entre la variable explicative et le phénomène apparaît comme un lien de causalité de nature déterministe. 33

34
2. Relation de causalité de nature probabiliste
Si la cause est présente, l’effet suit avec une certaine probabilité. Réciproquement si on observe l’effet, la cause est présente au départ avec une certaine probabilité. Exemple. Le fait de recevoir une subvention pour un ménage, n’entraîne pas nécessairement la scolarisation des enfants en âge d’aller à l’école. Un ménage n’ayant pas reçu la subvention, par ailleurs, peut scolariser ses enfants. La liaison entre le facteur et son effet est souvent exprimée par des mesures statistiques d’association, comme la différence de probabilité de scolariser les enfants entre deux ménages ou l’écart moyen entre les mesures d’une certaine variable dans les deux groupes. 34

35
Toutefois, ces mesures n’indiquent pas nécessairement une relation de cause à effet. Elles peuvent seulement témoigner d’une relation statistique. Avant qu’une association observée entre une politique (ou un traitement) et un résultat ne soit déclarée causale, certaines précautions doivent être prises pour établir un tel jugement. En particulier, il faut s’assurer que les groupes soient comparables par rapport à toute caractéristique des sujets (âge, genre, etc.) qui peut influencer l’association. Seul le traitement doit faire la différence. 35
 et un résultat ne soit déclarée causale, certaines précautions doivent être prises pour établir un tel jugement. En particulier, il faut s’assurer que les groupes soient comparables par rapport à toute caractéristique des sujets (âge, genre, etc.) qui peut influencer l’association. Seul le traitement doit faire la différence. 35.")
36
Objet: Relation causale des traitements
2. INTERET DU RECOURS A LA RANDOMISATION Objet: Relation causale des traitements Traitement: programme de bien-être, programmes de formation, transferts, dons, programme de nutrition, programmes d’éducation, etc. Traités vs Non Traités (groupe de contrôle) Expériences randomisées avec assignation aléatoire (indépendante des résultats et des variables) vs méthode post-évaluation à partir de données observationnelles. 36
 Expériences randomisées avec assignation aléatoire (indépendante des résultats et des variables) vs méthode post-évaluation à partir de données observationnelles. 36.")
37
Problèmes de l’inférence causale
Comparer le même individu dans deux situations différentes tandis qu’une seule est observable. Au cours du temps, les autres facteurs peuvent changer. Recourir à un groupe de comparaison, mais il peut exister des différences initiales (biais de sélection ou programme administré à un groupe particulier). La randomisation permet de corriger le biais de sélection. D’autres méthodes non expérimentales: contrôler les observables, Regression Discontinuity Design, Doubles-Différences, Effets Fixes. Pas de consensus sur la méthode la plus robuste. 37
. La randomisation permet de corriger le biais de sélection. D’autres méthodes non expérimentales: contrôler les observables, Regression Discontinuity Design, Doubles-Différences, Effets Fixes. Pas de consensus sur la méthode la plus robuste. 37.")
38
: le résultat pour l’ individu i sans traitement
3. FORMALISATION DE LA RANDOMISATION : le résultat pour un individu i traité (exemple: recevoir des livres à l’école) : le résultat pour l’ individu i sans traitement : résultat moyen du traitement sur les individus traités : résultat moyen de l’absence de traitement sur les individus non-traités (le groupe de comparaison). 38
 : le résultat pour l’ individu i sans traitement. : résultat moyen du traitement sur les individus traités. : résultat moyen de l’absence de traitement sur les individus non-traités (le groupe de comparaison). 38.")
39
Effet du Traitement et Biais de Sélection
E[YiT-YiC|T]= Effet Moyen du Traitement sur les Traités C’est la différence entre le résultat réel des traités et le résultat potentiel des non-traités si le traitement a lieu. E[YiC|T]- E[YiC|C]= Biais de Sélection, la différence dans les résultats potentiels des non-traités s’ils avaient été traités et leurs résultats réels (en tant que groupe de comparaison). Problème: E[YiC|T] (résultat moyen du traitement sur les individus non-traités) n’est pas observable. D’où la nécessité de construire un factuel (groupe d’individus similaires qui ne reçoit pas le traitement. 39
. Problème: E[YiC|T] (résultat moyen du traitement sur les individus non-traités) n’est pas observable. D’où la nécessité de construire un factuel (groupe d’individus similaires qui ne reçoit pas le traitement. 39.")
40
Que Mesure l’Effet Total ou l’Effet Partiel ?
Les résultats des évaluations randomisées donnent une forme réduite des impacts du traitement, c-à-d les effets totaux. Nous pouvons être intéressés par des effets partiels (ceteris paribus). Pour cela, nous avons besoin d’un modèle structurelle qui explique les différences entre les effets totaux et les effets partiels. Exemple : Si un enfant reçoit les livres scolaires, les parents peuvent accroître ou décroître l’offre domestique d’inputs éducationnels. Ce qui accroît ou décroît l’effet partiel du programme de dons de livres. 40
. Pour cela, nous avons besoin d’un modèle structurelle qui explique les différences entre les effets totaux et les effets partiels. Exemple : Si un enfant reçoit les livres scolaires, les parents peuvent accroître ou décroître l’offre domestique d’inputs éducationnels. Ce qui accroît ou décroît l’effet partiel du programme de dons de livres. 40.")
41
4. LES DIFFERENTES FORMES DE RANDOMISATION
1. Méthode de loterie. Exemple : Crédit de consommation élargi en Afrique du Sud. Approbation aléatoire des demandes de prêts. Trois groupes: approbation totale, approbation partielle et rejet total. Cela n’est valable que pour un groupe marginal. 2. Randomisation ordonnée ou phase-in Exemple : Programme de déparasitage intestinal dans des écoles au Kenya. 75 premières écoles ont été sélectionnées de façon aléatoire en écoles sélectionnées commencent le programme en 1998 et sont comparées au 50 autres. Un autre groupe de 25 écoles commencent le programme en Ainsi, les 50 écoles qui reçoivent le traitement sont comparées aux 25 dernières en Les 25 dernières écoles reçoivent le traitement en 2000. Cette méthode se focalise sur les effets de court terme. Si le phase-in est très rapide, les effets peuvent ne pas avoir le temps nécessaire pour leur maturité. Problème lie au traitement futur escompte, attendu par les groupes. 41

42
3. La randomisation within-group
Exemple : Programme de tutorat (balsakhi) dans les écoles des zones urbaines pauvres en Inde. Un (1) balsakhi est assigné de façon aléatoire aux classes dans chaque école. Problème: contamination des écoles de comparaison. (les directeurs font une réallocation des ressources dans les classes des Balsakhi) 4. Les plans d’encouragement Exemple : les agriculteurs sont invités de façon aléatoire à participer à des formations sur l’utilisation des engrais au Kenya. Cela accroît la probabilité du traitement 42
 dans les écoles des zones urbaines pauvres en Inde. Un (1) balsakhi est assigné de façon aléatoire aux classes dans chaque école. Problème: contamination des écoles de comparaison. (les directeurs font une réallocation des ressources dans les classes des Balsakhi) 4. Les plans d’encouragement. Exemple : les agriculteurs sont invités de façon aléatoire à participer à des formations sur l’utilisation des engrais au Kenya. Cela accroît la probabilité du traitement. 42.")
43
5. EXEMPLE PRATIQUE AVEC LES DOUBLES DIFFERENCES
43 43

44
44 44

45
45 45

46
46 46

47
47 47

48
EXEMPLE ILLUSTRATIF Le gouvernement souhaite subventionner les lycées de plus de 500 élèves. L’objectif est d’apprécier les effets de cette subvention sur les résultats scolaires afin de généraliser le projet à tous les établissements du pays, à terme. On considère une Ville Pilote regroupant 50 lycées supposés identiques. 25 lycées (Groupe B des traités) reçoivent la subvention à la date (t). 25 lycées (Groupe A de contrôle) ne sont pas sont à l’expérimentation à la même date (t). 48 48
 reçoivent la subvention à la date (t). 25 lycées (Groupe A de contrôle) ne sont pas sont à l’expérimentation à la même date (t)")
49
La variable d’intérêt est le Résultat Scolaire (RS). Avec:
EXEMPLE ILLUSTRATIF La variable d’intérêt est le Résultat Scolaire (RS). Avec: : output moyen du groupe des traités à la date 1. : output moyen du groupe des traités à la date 2. : output moyen du groupe de contrôle à la date 1. : output moyen du groupe de contrôle à la date 2. Problème 1: Si on considère les traités uniquement : ne suffit pas à capter l’effet de la politique. Problème 2: Si on considère la période post traitement uniquement : Une des solutions réside dans l’approche de la double différence qui conduit à des estimateurs sans biais. 49 49
. Avec: : output moyen du groupe des traités à la date 1. : output moyen du groupe des traités à la date 2. : output moyen du groupe de contrôle à la date 1. : output moyen du groupe de contrôle à la date 2. Problème 1: Si on considère les traités uniquement : ne suffit pas à capter l’effet de la politique. Problème 2: Si on considère la période post traitement uniquement : Une des solutions réside dans l’approche de la double différence qui conduit à des estimateurs sans biais")
50
CONCLUSION Les conclusions tirées d’un test de randomisation sont strictement valables seulement pour les sujets utilisés dans l’expérience (validation interne). Ces conclusions peuvent être inférées à une population mère si les sujets sont un échantillon aléatoire de la population mère. Malheureusement, ceci est souvent impossible en pratique. 50
. Ces conclusions peuvent être inférées à une population mère si les sujets sont un échantillon aléatoire de la population mère. Malheureusement, ceci est souvent impossible en pratique. 50.")
51
Sans randomisation, il n’est pas possible d’assurer la comparabilité des groupes. Dans les études d’observations, pour passer de l’association statistique à la causalité, le chercheur doit faire appel à un certain nombre de critères auxilliaires. Voici les plus connus: Constance de l’association observée. Des études conduites en des moments et des lieux différents surt d’autres populations produisant des résultats semblables accréditent l’hypothèse de causalité. Intensité de l’association. L’action des biais sur l’association se fait vraisemblablement moins sentir lorsque l’intensité ou la force de l’association est grande. En ce sens, une plus forte intensité favorise le jugement de causalité. 51

52
Cohérence chronologique. La cause doit précéder l’effet.
Le chercheur doit aussi faire appel à d’autres critères auxilliaires tels que : Spécificité de l’association. Plus un facteur est exclusif, plus l’interprétation causale est plausible. Cohérence chronologique. La cause doit précéder l’effet. Présence d’une relation dose-effet. L’effet augmente lorsque la dose augmente. Cohérence avec les connaissances. 52

53
53 53

54
Modélisation Structurelle des Equations de Sélection
LECTURE 3 Modélisation Structurelle des Equations de Sélection Dr. Alban A. E. AHOURE

55
PLAN I. MOTIVATION II. FORMALISATION III. ESTIMATION IV. APPLICATIONS

56
I. MOTIVATION 1.1. Echantillon aléatoire Lors de l’inférence classique : on tire un échantillon aléatoire de la population d’intérêt (2) on spécifie une relation entre les variables à expliquer et les variables explicatives (3) on estime les paramètres d’intérêt (e.g. effets marginaux, élasticité) (4) on prédit les variables d’intérêt pour des valeurs des variables explicatives, sachant les paramètres estimés
 on spécifie une relation entre les variables à expliquer et les variables explicatives. (3) on estime les paramètres d’intérêt (e.g. effets marginaux, élasticité) (4) on prédit les variables d’intérêt pour des valeurs des variables explicatives, sachant les paramètres estimés.")
57
Exemple: Equation de salaires : Supposons qu’on soit intéressé par l’estimation de l’équation de salaire de gens en âge de travailler (dans un pays quelconque). La population en question comprend tous les gens en âge de travailler, non seulement ceux qui travaillent mais aussi ceux qui ne travaillent pas.

58
1.2. Echantillon non-aléatoire ou “choisi” (selected)
Le terme anglais “selected sample” qu’on peut traduire par “échantillon choisi” décrit un échantillon non-aléatoire qui peut l’être pour plusieurs raisons: échantillonnage stratifié (2) non-réponse ou attrition De nombreux mécanismes de sélection donnent lieu à des échantillons non-aléatoires
 non-réponse ou attrition. De nombreux mécanismes de sélection donnent lieu à des échantillons non-aléatoires.")
59
Exemple: Equation de salaires : Dans la pratique, on observe le salaire de ceux qui travaillent (ils ont au préalable pris la décision de travailler). On ne peut pas inclure dans l’estimation les observations de ceux qui ne travaillent pas. Ainsi, se limiter au sous-échantillon de ceux qui travaillent pour prédire le salaire de la population des gens en âge de travailler induit ce qu’on appelle un biais de sélection. Si on s’intéresse à la population de gens qui travaillent, on peut estimer de façon standard l’équation de salaire dans un cadre dit conditionnel.

62
1.4. Exemples d’application
Exemple 1: (Décision d’innover et dépenses d’innovation) Dans des enquêtes d’innovation d’entreprise, souvent on doit modéliser la décision d’une entreprise d’innover, et si elle innove, comment elle détermine ses dépenses d’innovation. Un modèle de sélection est adéquat dans une telle situation. Exemple 2: (Décision de travailler et offre de travail) De façon similaire, il se peut qu’on soit intéressé par l’offre de travail (en nombre d’heures de travail) d’une catégorie d’agents économiques (individus ou ménages). L’offre de travail n’est observée que pour les gens qui ont décidé de travailler. Ainsi, on doit modéliser la décision de travailler et l’offre de travail de ceux qui travaillent. Exemple 3: (Dépenses en biens durables) Dans les modèles à biens durables, les agents prennent une décision d’acheter ou non un certain bien, et s’ils achètent le bien, combien dépenser pour acquérir ce bien. Là encore, un modèle de sélection est adéquat.
 Dans des enquêtes d’innovation d’entreprise, souvent on doit modéliser la décision d’une entreprise d’innover, et si elle innove, comment elle détermine ses dépenses d’innovation. Un modèle de sélection est adéquat dans une telle situation. Exemple 2: (Décision de travailler et offre de travail) De façon similaire, il se peut qu’on soit intéressé par l’offre de travail (en nombre d’heures de travail) d’une catégorie d’agents économiques (individus ou ménages). L’offre de travail n’est observée que pour les gens qui ont décidé de travailler. Ainsi, on doit modéliser la décision de travailler et l’offre de travail de ceux qui travaillent. Exemple 3: (Dépenses en biens durables) Dans les modèles à biens durables, les agents prennent une décision d’acheter ou non un certain bien, et s’ils achètent le bien, combien dépenser pour acquérir ce bien. Là encore, un modèle de sélection est adéquat.")
63
Exemple 4: (Décision d’être locataire ou propriétaire, et dépenses associées au régime) Modèle de regime ou “endogenous switching regression”. Exemple 5 : Effets de la politique active d’emploi sur la durée de chômage des jeunes urbain en Côte d’Ivoire (Dr. Kouakou K. Clément). L’estimation d’un modèle de durée avec instrumentation du passage par le programme d’insertion réfute l’existence d’un effet significatif sur la sortie du chômage dans la situation post programme des jeunes.
. L’estimation d’un modèle de durée avec instrumentation du passage par le programme d’insertion réfute l’existence d’un effet significatif sur la sortie du chômage dans la situation post programme des jeunes.")
72
Quelques Remarques En principe, le modèle Tobit type 3 est plus riche en information que le modèle Tobit type 2 pour estimer l’équation de salaire. (2) L’estimation de β, est-elle plus précise quand on utilise le modèle Tobit type 3? (3) Dans le modèle Tobit type 3, la propension de l’individu à travailler et son offre de travail souhaitée sont confondues
 L’estimation de β, est-elle plus précise quand on utilise le modèle Tobit type 3 (3) Dans le modèle Tobit type 3, la propension de l’individu à travailler et son offre de travail souhaitée sont confondues.")
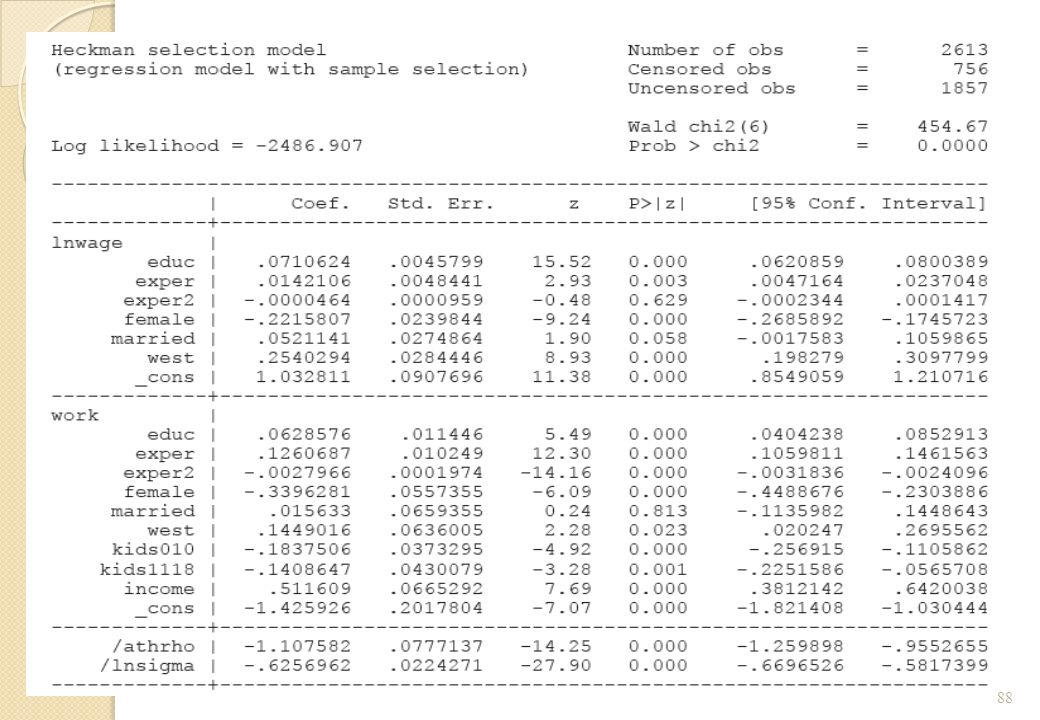
87
IV. APPLICATIONS : DECISION DE TRAVAILLER ET EQUATION DE SALAIRES

89
IV. APPLICATIONS : OFFRE DE TRAVAIL ET EQUATION DE SALAIRES

90
IV. APPLICATIONS : DECISION D’ETRE SYNDIQUE ET EFFET SUR LES SALAIRES

91
Je Vous Remercie Pour Votre Attention

92
Variables Instrumentales et Effets Moyens de Traitement
LECTURE 4 Variables Instrumentales et Effets Moyens de Traitement Dr. Alban A. E. AHOURE

93
PLAN I. MOTIVATION 1.1. Effets moyens de traitement
1.2. Variables instrumentales II. MODELES A VARIABLES ENDOGENE BINAIRE 2.1. Régression 1 2.2. Two-Step IV

94
1.1. Effets Moyens de Traitement (EMT)
MOTIVATION 1.1. Effets Moyens de Traitement (EMT) Cadre Général La variable de traitement d est binaire et vaut 1 si l’individu est traité et 0 sinon; elle est observée. La variable d’output y des individus est continue, et on observe y1 pour les individus qui reçoivent le traitement et y0 pour les individus qui n’en reçoivent pas. Autrement dit, pour un individu, y1 ou y0 est observé. On note par x le vecteur de caractéristiques observées des individus (a la fois ceux qui sont traités et ceux qui ne le sont pas).
 Cadre Général. La variable de traitement d est binaire et vaut 1 si l’individu est traité et 0 sinon; elle est observée. La variable d’output y des individus est continue, et on observe y1 pour les individus qui reçoivent le traitement et y0 pour les individus qui n’en reçoivent pas. Autrement dit, pour un individu, y1 ou y0 est observé. On note par x le vecteur de caractéristiques observées des individus (a la fois ceux qui sont traités et ceux qui ne le sont pas).")
95
On s’intéresse au changement moyen de l’output d’un individu non-traité si cet individu devait être traité. Donc, l’effet moyen de traitement (EMT) dans la population est defini par : E(y1 − y0 ) et l’effet moyen de traitement des traités (EMTT) est défini par: E(y1 − y0 |d =1).
 dans la population est defini par : E(y1 − y0 ) et l’effet moyen de traitement des traités (EMTT) est défini par: E(y1 − y0 |d =1).")
96
1.1.2. Hypothèse d’indépendance conditionnelle
Dans le cas où il y a randomisation (expérience contrôlée), le traitement est indépendant de la variable d’output, c’est à dire y1 , y0 ⊥ D. En cas d’absence de randomisation, par exemple dans le cas de données observationnelles, l’hypothèse d’indépendance n’est pas satisfaite, on doit faire alors une hypothèse d’indépendance conditionnelle, c’est à dire y1 , y0 ⊥ D|x. Si l’hypothèse d’indépendance conditionnelle est satisfaite, la variable de traitement est dite exogène et on peut appliquer les méthodes du Score de Propension et du Matching (Appariement). Si l’hypothèse d’indépendance conditionnelle n’est pas satisfaite, la variable de traitement est dite endogène et on doit utiliser des modèles à régimes ou des modèles variables instrumentales.
, le traitement est indépendant de la variable d’output, c’est à dire y1 , y0 ⊥ D. En cas d’absence de randomisation, par exemple dans le cas de données observationnelles, l’hypothèse d’indépendance n’est pas satisfaite, on doit faire alors une hypothèse d’indépendance conditionnelle, c’est à dire y1 , y0 ⊥ D|x. Si l’hypothèse d’indépendance conditionnelle est satisfaite, la variable de traitement est dite exogène et on peut appliquer les méthodes du Score de Propension et du Matching (Appariement). Si l’hypothèse d’indépendance conditionnelle n’est pas satisfaite, la variable de traitement est dite endogène et on doit utiliser des modèles à régimes ou des modèles variables instrumentales.")
97
1.2. Variables Instrumentales
Un Seul Instrument Soit un modèle de régression linéaire: Exemple: (Equation de salaires) Soit y le salaire de personnes qui travaillent à temps plein, x1 le niveau d’études (en années) et x2 le genre de ces personnes. On peut supposer que le niveau d’études est corrélé avec des variables non-observables comme la motivation, l’intelligence, le talent etc.
 Soit y le salaire de personnes qui travaillent à temps plein, x1 le niveau d’études (en années) et x2 le genre de ces personnes. On peut supposer que le niveau d’études est corrélé avec des variables non-observables comme la motivation, l’intelligence, le talent etc.")
98
La variable x1 est donc dite endogène contrairement à la variable x2 qui est dite exogène. Dans ce cas, si on applique MCO à l’équation (1), β0 , β1 et β2 sont non-convergents même si E( ɛ|x2 ) = 0. On peut résoudre ce problème de non-convergence en utilisant l’estimateur de la variable instrumentale (VI). Dans ce cas, on a besoin d’une variable observable z1 qui est absente de l’équation (1) et qui satisfait 2 conditions. E(ɛ|z1 ) = 0 (2) E(x1|z1 ) = 0
. Dans ce cas, on a besoin d’une variable observable z1 qui est absente de l’équation (1) et qui satisfait 2 conditions. E(ɛ|z1 ) = 0. (2) E(x1|z1 ) = 0.")
99
Une telle variable z1 est appelée Variable Instrumentale ou Instrument et s’écrit comme :
La deuxième condition implique θ1 = 0. et la relation de l’équation (2) est appelée forme réduite. C’est à dire que la variable endogène s’écrit comme une projection linéaire de toutes les variables exogènes.
 est appelée forme réduite. C’est à dire que la variable endogène s’écrit comme une projection linéaire de toutes les variables exogènes.")
100
L’équation (1) s’appelle forme structurelle, et la forme réduite associée s’écrit :
Les paramètres α0 , α1 et α2 s’appellent paramètres réduits, β0 , β1 et β2 sont les paramètres structurels.

101
1.2.2. Instruments Multiples
Dans le cas d’instrument unique, on applique l’estimateur VI standard. Si on a plusieurs instruments pour une variable endogène, on peut utiliser l’estimateur VI standard en ignorant certains instruments, mais cet estimateur sera inefficace. L’estimateur VI efficace s’appelle l’estimateur des 2MCO (2SLS) et est défini de la façon suivante: estimer l’équation (2) de la forme réduite, c’est à dire δ0 , δ2 et θ1 par MCO (2) obtenir (3) régresser Les paramètres obtenus sont les paramètres estimés 2MCO
 et est défini de la façon suivante: estimer l’équation (2) de la forme réduite, c’est à dire δ0 , δ2 et θ1 par MCO. (2) obtenir. (3) régresser. Les paramètres obtenus sont les paramètres estimés 2MCO.")
102
II. MODELES A VARIABLES ENDOGENE BINAIRE
2.1. Régression 1 Cadre Général Une façon d’estimer les EMTs ou les EMTTs est d’écrire une régression où y est la variable expliquée et d la variable explicative. Pour cela, on écrit : y = (1 − d)y0 + dy1 (4) = y0 + d(y1 − y0 ) Écrivons l’output des non- traités comme : y0 = µ0 + ν0 (5) et celui des traités comme : y1 = µ1 + ν1 (6)
y0 + dy1 (4) = y0 + d(y1 − y0 ) Écrivons l’output des non- traités comme : y0 = µ0 + ν0 (5) et celui des traités comme : y1 = µ1 + ν1 (6)")
103
Si on remplace les équations (5) et (6) dans (4) on obtient la régression :
où µ1 est la moyenne de l’output des traités, µ0 est la moyenne de l’output des non traités, donc : (µ1 − µ0 ) = EMT, et ν0 + d(ν1 − ν0 ) est la composante stochastique (aléatoire) de la régression. Puisqu’on observe d, et y, on peut estimer l’équation (7), et donc (µ1 − µ0). Comme dans toute régression, on doit faire des hypothèses sur la composante stochastique de l’équation.
 = EMT, et ν0 + d(ν1 − ν0 ) est la composante stochastique (aléatoire) de la régression. Puisqu’on observe d, et y, on peut estimer l’équation (7), et donc (µ1 − µ0). Comme dans toute régression, on doit faire des hypothèses sur la composante stochastique de l’équation.")
104
Par exemple, si on contrôle pour les caractéristiques (supposées exogènes) x de l’individu et qu’on fait l’hypothèse E(ν1 − ν0 |x) = 0, sous hypothèse d’indépendance conditionnelle (unconfoundeness) la variable de traitement est exogène. Dans ce cas, appliquer MCO à l’équation (7) estime de façon convergente l’EMT. Dans notre cas, on ne fait plus l’hypothèse d’indépendance conditionnelle, c’est-à-dire que la variable de traitement est endogène.24
 estime de façon convergente l’EMT. Dans notre cas, on ne fait plus l’hypothèse d’indépendance conditionnelle, c’est-à-dire que la variable de traitement est endogène.24.")
105
L’intuition est que la décision d’un individu de participer à un programme de développement dépend de certaines caractéristiques non-observables de l’individu qui expliquent l’output dû au traitement. C’est ce qu’on appelle la sélection sur les non- observables (selection on unobservables) par opposition à la sélection sur les observables (selection on observables). Exemple: (Niveau d’études et fertilité) Supposons que la variable d’output est la fertilité (nombre d’enfants) des femmes d’un certain pays en âge d’enfanter, et que la variable de traitement est binaire prenant la valeur 1 si la femme a au moins 7 années d’études et 0 sinon. On suppose qu’il existe des instruments collectés dans un vecteur z et que ν1 = ν0 .
 par opposition à la sélection sur les observables (selection on observables). Exemple: (Niveau d’études et fertilité) Supposons que la variable d’output est la fertilité (nombre d’enfants) des femmes d’un certain pays en âge d’enfanter, et que la variable de traitement est binaire prenant la valeur 1 si la femme a au moins 7 années d’études et 0 sinon. On suppose qu’il existe des instruments collectés dans un vecteur z et que ν1 = ν0 .")
106
La régression ainsi obtenue s’appelle régression à variable endogène binaire et s’écrit :

107
Si il y a un seul instrument, on peut appliquer la méthode VI standard pour estimer δ, et β.
Si il y a plusieurs instruments, la méthode VI standard n’est pas efficace, dans ce cas, la méthode VI efficace est la méthode 2MCO.

108
2.2. Modèles à Variable Endogène Binaire: 2-step IV
Si on fait des hypothèses supplémentaires, on peut estimer l’EMT , δ et β de façon encore plus efficace que la méthode 2MCO. Les hypothèses supplémentaires sont les suivantes : P(d = 1|x, z) =P(d = 1|x) P(d = 1|x, z) =F(x, z, γ) a une forme paramétrique connue (par exemple Probit ou Logit) E(u|x, z) = 0 Cette méthode qui permet d’obtenir ces valeurs estimées de , δ et β de façon encore plus précise s’appelle la méthode VI en 2 étapes (2-step IV).
 =P(d = 1|x) P(d = 1|x, z) =F(x, z, γ) a une forme paramétrique connue (par exemple Probit ou Logit) E(u|x, z) = 0. Cette méthode qui permet d’obtenir ces valeurs estimées de , δ et β de façon encore plus précise s’appelle la méthode VI en 2 étapes (2-step IV).")
109
Remarques La méthode fonctionne de la façon suivante :
(1) estimer P(d = 1|x, z) =F(x, z, γ) en utilisant un modèle Probit ou Logit (2) obtenir (3) estimer l’équation (8) en utilisant comme instruments : Remarques Utiliser comme instrument de d n’est pas la même chose qu’utiliser comme régresseur à la place de d (1) dans le premier cas, on n’a pas besoin de corriger les erreur- types (2) dans le second cas, il faut corriger pour les erreur-types
 estimer P(d = 1|x, z) =F(x, z, γ) en utilisant un modèle Probit ou Logit. (2) obtenir. (3) estimer l’équation (8) en utilisant comme instruments : Remarques. Utiliser comme instrument de d n’est pas la même chose qu’utiliser comme régresseur à la place de d. (1) dans le premier cas, on n’a pas besoin de corriger les erreur- types. (2) dans le second cas, il faut corriger pour les erreur-types.")
110
Je Vous Remercie Pour Votre Attention

111
IMPLEMENTATION SUR STATA 10.
LECTURE 5 IMPLEMENTATION SUR STATA 10. Dr. Alban A. E. AHOURE Dr. Wautabouna OUATTARA

112
IMPLEMENTATION SUR STATA 10.
LECTURE 6 IMPLEMENTATION SUR STATA 10. Dr. Alban A. E. AHOURE Dr. Wautabouna OUATTARA

113
DES METHODES D’EVALUATION Dr. Wautabouna OUATTARA
Cellule d’Analyse de Politiques Economiques du CIRES Atelier de formation des responsables de la programmation et du suivi et évaluation des administrations publiques et privées Lecture 7 : COMPARAISON DES METHODES D’EVALUATION Dr. Wautabouna OUATTARA 10 septembre 2009, Grand-Bassam

114
1. CADRE GENERAL Différentes questions empiriques soulevées en Economie et dans les autres Sciences Sociales portent sur l’analyse des causalités des programmes ou politiques. Au cours de deux dernières décennies, différents travaux en économétrie et analyse statistique ont été menés sur les effets de ces programmes ou traitements. Des outils ont été développés pour appréhender les effets des politiques économiques au niveau microscopique ou pour analyser des causalités. 114

115
1. CADRE GENERAL PROBLEME PRINCIPAL: dans la littérature l’évaluation de l’effet de l’assignation d’un ensemble d’agents à un programme ou à un traitement. MAIS: On ne peut à la fois “participer” et “ne pas participer” au projet au même moment Données Manquantes SOLUTION: Construire un groupe témoin (imitateur) de participants. Ce groupe de non participants similaires aux participants est le groupe de contrôle qui sert de contrefactuel. PRINCIPE FONDAMENTAL: Toutes les évaluations quantitatives d’impact se résument en la construction d’un groupe contrefactuel crédible: expérimentation (randomisation) vs post-évaluation (données observationnelles). 115
 de participants. Ce groupe de non participants similaires aux participants est le groupe de contrôle qui sert de contrefactuel. PRINCIPE FONDAMENTAL: Toutes les évaluations quantitatives d’impact se résument en la construction d’un groupe contrefactuel crédible: expérimentation (randomisation) vs post-évaluation (données observationnelles)")
116
2. METHODE EXPERIMENTALE: LA RANDOMISATION
Le principe général: s’approcher au mieux de la méthode de l’essai clinique. On compare des gens qui ont bénéficié d’un traitement et des gens qui n’en ont pas bénéficié. On met tout en œuvre pour que ces gens soient le plus similaire possible. Les fondements: (1) On ne peut comparer le même individu dans deux situations différentes, tandis qu’une seule est observable. (2) Au cours du temps, les autres facteurs peuvent changer. (3) On peut recourir à un groupe de comparaison, mais il peut exister des différences initiales (biais de sélection ou programme administré à un groupe particulier). La randomisation, construction du contrefactuel par assignation aléatoire des groupes de participants et non-participants au projet , permet de corriger le biais de sélection. 116
 On ne peut comparer le même individu dans deux situations différentes, tandis qu’une seule est observable. (2) Au cours du temps, les autres facteurs peuvent changer. (3) On peut recourir à un groupe de comparaison, mais il peut exister des différences initiales (biais de sélection ou programme administré à un groupe particulier). La randomisation, construction du contrefactuel par assignation aléatoire des groupes de participants et non-participants au projet , permet de corriger le biais de sélection")
117
2. METHODE EXPERIMENTALE: LA RANDOMISATION
LES METHODES DE LA RANDOMISATION Méthode de loterie 2. Randomisation ordonnée ou phase-in 3. La randomisation within-group 4. Les Plans d’Encouragement 5. La stratification LES AVANTAGES DE LA RANDOMISATION Grande qualité du contrefactuel Elimination des biais de selection Nécessite un petit échantillon 117

118
2. METHODE EXPERIMENTALE: LA RANDOMISATION
LES LIMITES DE LA RANDOMISATION Les expériences contrôlées ne s’appliquent pas à tous les projets raisons d’ordre éthique, d’ordre pratique. Ethique: L’identification d’un groupe de contrôle et d’un groupe test suppose que l’on choisit consciemment de ne pas « traiter » tout le monde. Comme le « traitement » est généralement une politique ou de l’aide que l’on juge a priori bénéfique, il est difficile de ne pas voir une injustice à ne pas offrir cette aide à tout le monde. (2) La validité interne est fonction de la conception et de la mise en oeuvre: problèmes d’attrition (des individus disparaissent de l’échantillon), spillover, contamination, biais de randomisation. James Heckman : la validité des expérimentations n’est que conditionnelle. Les résultats ne sont valables que dans le contexte de l’expérimentation (dans le pays, sur l’échantillon traité, selon les conditions macroéconomiques, etc.) . 118
 La validité interne est fonction de la conception et de la mise en oeuvre: problèmes d’attrition (des individus disparaissent de l’échantillon), spillover, contamination, biais de randomisation. James Heckman : la validité des expérimentations n’est que conditionnelle. Les résultats ne sont valables que dans le contexte de l’expérimentation (dans le pays, sur l’échantillon traité, selon les conditions macroéconomiques, etc.)")
119
2. METHODE EXPERIMENTALE : LA RANDOMISATION
L’opposition entre vision micro et macro. Si les méthodes empiriques des macro-économistes ont été discréditées au profit d’analyses micro plus rigoureuses et plus ciblées, les analyses globales (institutions, ouverture commerciale, etc.) n’en restent pas moins pertinentes pour expliquer le développement économique. Deaton et Rodrik: les pays qui se sont développés récemment (et ont sorti de la pauvreté des millions d’individus) ne l’ont pas fait en s’appuyant sur une aide extérieure et encore moins sur des politiques de développement expérimentées au préalable, mais en s’ouvrant au commerce, en garantissant les droits de propriété et en luttant contre la corruption. Banerjee et Duflo: les expérimentations ont pu mettre en lumière l’efficacité sensiblement différente des politiques pour obtenir le même niveau d’éducation. L’enthousiasme, légitime, de ces chercheurs les a amené à considérer l’expérimentation comme l’idéal méthodologique (le « gold standard ») de l’économie empirique mais aussi comme l’espoir d’un renouveau de l’engagement citoyen et la promesse d’un monde meilleur. 119
 n’en restent pas moins pertinentes pour expliquer le développement économique. Deaton et Rodrik: les pays qui se sont développés récemment (et ont sorti de la pauvreté des millions d’individus) ne l’ont pas fait en s’appuyant sur une aide extérieure et encore moins sur des politiques de développement expérimentées au préalable, mais en s’ouvrant au commerce, en garantissant les droits de propriété et en luttant contre la. corruption. Banerjee et Duflo: les expérimentations ont pu mettre en lumière l’efficacité sensiblement différente des politiques pour obtenir le même niveau d’éducation. L’enthousiasme, légitime, de ces chercheurs les a amené à considérer l’expérimentation comme l’idéal méthodologique (le « gold standard ») de l’économie empirique mais aussi comme l’espoir d’un renouveau de l’engagement citoyen et la promesse d’un monde meilleur")
120
3. METHODES NON-EXPERIMENTALES: CADRE GENERAL
120

121
3. METHODES NON-EXPERIMENTALES: SCORE DE PROPENSION ET MATCHING (1)
Idée : Pour chaque individu traité, il faut trouver un individu dans le groupe de contrôle qui lui est similaire dans toutes les observables et comparer les moyennes des résultats entre les deux groupes. Sélection se fonde sur les observables 121

122
3. METHODES NON-EXPERIMENTALES: SCORE DE PROPENSION ET MATCHING (2)
(1) L’exact Matching ou Appariement (impossible si X est de grande dimension ou s’il y a des variations continues) (2) L’appariement par le Score de Propension: Le score de propension est la probabilité (conditionnelle) de recevoir le traitement étant données les co-variables Estimer P[Di=1|Xi] par Probit ou Logit Appariement sur la base du score de propension Nécessaire si X est de grande dimension Avec ou sans remise? (Cela dépend de la taille du groupe de comparaison) Matching à partir du voisin le plus proche, kernel matching, stratification ou matching sur intervalles. 122
 L’exact Matching ou Appariement (impossible si X est de grande dimension ou s’il y a des variations continues) (2) L’appariement par le Score de Propension: Le score de propension est la probabilité (conditionnelle) de recevoir le traitement étant données les co-variables. Estimer P[Di=1|Xi] par Probit ou Logit. Appariement sur la base du score de propension. Nécessaire si X est de grande dimension. Avec ou sans remise (Cela dépend de la taille du groupe de comparaison) Matching à partir du voisin le plus proche, kernel matching, stratification ou matching sur intervalles")
123
3. METHODES NON-EXPERIMENTALES: LES DOUBLES DIFFERENCES (3)
Permet d’obtenir un effet individuel qui soit indépendant du temps. Nécessite des données avant et après le traitement Compare le groupe traité et le groupe de comparaison dans leur différence de résultats avant et après le traitement. En comparant les changements dans le temps des moyennes des 2 groupes, on tient compte à la fois des spécificités des groupes et des périodes Contrôler pour le trend temporel au niveau des 2 groupes. Problème de biais d’attrition 123

124
3. METHODES NON-EXPERIMENTALES: REGRESSION DISCONTINUITY DESIGN (4)
Méthode Quasi-Expérimentale dans laquelle la probabilité de recevoir le traitement est une fonction continue d’une variable à un seuil exogène. Exemple: seuil pour recevoir un traitement Appariement en dessous ou au dessus du seuil 124

125
3. METHODES NON-EXPERIMENTALES: VARIABLES INSTRUMENTALES (5)
Qu’est-ce qui se passe si la sélection dépend de caractéristiques non observables qui peuvent être corrélées avec les non observables de l’équation d’intérêt ? Endogénéité de la variable de sélection. Sélection sur les non–observables: le talent, l’intelligence, la motivation. Estimation par le MV des équations de sélection et d’intérêt avec une distribution jointe des termes d’erreurs. - Heckman en deux étapes (Modèles à Régimes) - 2MCO - IV en deux étapes 125
 - 2MCO. - IV en deux étapes")
126
4. CRITERES DE CHOIX ENTRE METHODES
NON EXPERIMENTALES (1) Identifier les facteurs qui peuvent affecter le résultat et la sélection Les facteurs communs qui affectent à la fois la sélection et le résultat qu’ils soient observables ou non. La quantité et le type de données disponibles: plus on aura à contrôler pour des questions d’endogénéité et/ou de biais de sélection et plus on aura besoin de données. Moins restrictives seront les hypothèses d’indépendance et plus on devra faire des hypothèses sur la forme fonctionnelle des équations de sélection et d’intérêt et sur les distributions des termes d’erreur. 126
 Identifier les facteurs qui peuvent affecter le résultat et la sélection. Les facteurs communs qui affectent à la fois la sélection et le résultat qu’ils soient observables ou non. La quantité et le type de données disponibles: plus on aura à contrôler pour des questions d’endogénéité et/ou de biais de sélection et plus on aura besoin de données. Moins restrictives seront les hypothèses d’indépendance et plus on devra faire des hypothèses sur la forme fonctionnelle des équations de sélection et d’intérêt et sur les distributions des termes d’erreur")
127
4. CRITERES DE CHOIX ENTRE METHODES
NON EXPERIMENTALES (2) Doubles Différences Problème: Perte d’une observation Avantage: Corrige pour les effets individuels Regression Discontinuity Design Problème: Peu d’observations en dessous ou au dessus du seuil Problème: Le seuil doit être exogène 127
 Doubles Différences. Problème: Perte d’une observation. Avantage: Corrige pour les effets individuels. Regression Discontinuity Design. Problème: Peu d’observations en dessous ou au dessus du seuil. Problème: Le seuil doit être exogène")
128
Principales démarches dans la conception et l'exécution
des évaluations d'impact Pendant l'Identification et la Préparation du Projet 1. Déterminer s'il faut nécessairement effectuer une évaluation ou non 2. Clarifier les objectifs de l'évaluation 3. Explorer la disponibilité des données 4. Concevoir l'évaluation 5. Former l'équipe d'évaluation 6. Si des données seront collectées : (a) Conception et sélection des échantillons (b) Développement de l'instrument de collecte des données (c) Recruter et former le personnel de terrain (d) Réaliser l’enquête pilote (e) Collecte de données (f) Gestion et accès aux données Pendant la Supervision du Projet 7. Poursuivre la collecte des données 8. Analyser les données 9. Rendre compte des résultats par écrit et les discuter avec les décideurs et les bailleurs de fonds 10. Incorporer les résultats à la conception du projet.
 Conception et sélection des échantillons. (b) Développement de l instrument de collecte des données. (c) Recruter et former le personnel de terrain. (d) Réaliser l’enquête pilote. (e) Collecte de données. (f) Gestion et accès aux données. Pendant la Supervision du Projet. 7. Poursuivre la collecte des données. 8. Analyser les données. 9. Rendre compte des résultats par écrit et les discuter avec les décideurs et les bailleurs de fonds. 10. Incorporer les résultats à la conception du projet.")
129
129 129

Présentations similaires