Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
VALEURS MANQUANTES Quelle proportion? Aléatoires - Non aléatoires?
Importante - Non importante? Aléatoires - Non aléatoires? Quel « pattern » suivent les valeurs manquantes?

2
Valeurs manquantes Une solution simple : Généralisation?
écarter les « sujets » avec des réponses incomplètes : « analyse des cas disponibles ou des cas complets » utilisation non efficiente de l ’information cas complets peuvent être très différents Généralisation? Représentativité?

3
Valeurs manquantes Classification
Exemple : 2 variables Y = revenu, X = Age Complètement aléaloires (Missing Completely At Random = MCAR) : données manquantes = échantillon représentatif de l’ensemble complet de données Probabilité que revenu soit récolté la même pour tous les individus MCAR
 : données manquantes = échantillon représentatif de l’ensemble complet de données. Probabilité que revenu soit récolté la même pour tous les individus MCAR.")
4
Valeurs manquantes Classification
Exemple : 2 variables Y = revenu, X = Age Aléatoires (Missing At Random = MAR) : probabilité qu’une donnée soit manquante dépend des valeurs des variables mesurées Probabilité que revenu soit récolté dépend de l’âge des répondants mais ne varie pas en fonction du revenu des répondants au sein des groupes d’âge MAR
 : probabilité qu’une donnée soit manquante dépend des valeurs des variables mesurées. Probabilité que revenu soit récolté dépend de l’âge des répondants mais ne varie pas en fonction du revenu des répondants au sein des groupes d’âge MAR.")
5
Valeurs manquantes Classification
Exemple : 2 variables Y = revenu, X = Age Valeurs manquantes non aléatoires (Missing Not At Random = MNAR) : l’occurrence des valeurs manquantes d’une variable dépend de la valeur réelle mais non observée de la variable. Si probabilité que revenu varie aussi en en fonction du revenu dans les groupes d’âge MNAR
 : l’occurrence des valeurs manquantes d’une variable dépend de la valeur réelle mais non observée de la variable. Si probabilité que revenu varie aussi en en fonction du revenu dans les groupes d’âge MNAR.")
6
Valeurs manquantes Classification MCAR et MAR = « missing ignorable »
MNAR = « missing non ignorable »

7
VALEURS MANQUANTES Méthodes d’analyse Deux grands types d’approches
Imputation Basées sur la vraisemblance (Likelihood – «Expectation-Maximization » algorithm). Estimation de paramètres par maximum de vraisemblance à partir des données incomplètes.
. Estimation de paramètres par maximum de vraisemblance à partir des données incomplètes.")
8
Différence principale entre les deux approches
Méthodes d’analyse Différence principale entre les deux approches imputation complète les «missing » approche basée sur le Likelihood : pas d’estimation explicite des « missing » mais spécification d’un modèle et logiciels moins facilement disponibles pour certaines analyses Si grands échantillons, résultats semblables avec les deux méthodes; si petits échantillons, MI supérieur?

9
Valeurs manquantes IMPUTATION: Imputation simple Imputation multiple

10
VALEURS MANQUANTES Imputation simple
Valeur basée sur la connaissance à priori moyenne des observations disponibles pour les autres sujets avec des caractéristiques identiques valeurs prédites par régression ou régression stochastique (valeurs manquantes remplacées par valeurs prédites + résidus pour refléter l’incertitude sur la valeur prédite)
")
11
Valeurs manquantes Imputation simple
Hot Deck : valeur imputée sélectionnée à partir de la distribution estimée pour chaque valeur manquante Cold deck : remplacer une valeur manquante par une valeur constante provenant d’une source extérieure (ex : étude antérieure)
")
12
Imputation simple Étude longitudinale : dernière valeur observée (LOCF) Substitution : remplacer des unités sélectionnées par d’autres non sélectionnées dans l’échantillon (stade expérimental) …………
 …………")
13
VALEURS MANQUANTES Imputation simple : problèmes
Connaissance à priori : OK si nb. Missing petit et chercheur expérimenté L’analyse de la base de données complétée comme si les mesures ajoutées étaient des mesures réelles ne tient pas compte de l’incertitude liée au processus d’imputation Les erreurs standards sont en général sous-estimées

14
VALEURS MANQUANTES Imputation multiple (MI) N’ajoute pas des valeurs
Analyse de plusieurs ensembles de données « complets » Simulations nb. M d’imputations répétées = 3, suffisant si 20% de missing

15
Valeurs manquantes Imputation multiple
Sauf si % « missing » très grand : peu de bénéfice avec + de 10 imputations – 5 imputations = recommandé Ajuste les statistiques pour tenir compte de l’incertitude liée à l’imputation

16
Valeurs manquantes Remarque
Méthodes choisies pour traiter les missings dans les essais cliniques ont un impact sur les calculs de taille d’échantillons

17
VALEURS MANQUANTES Quelques situations
Analyses avec des modèles classiques Essais cliniques Etudes longitudinales ………..

18
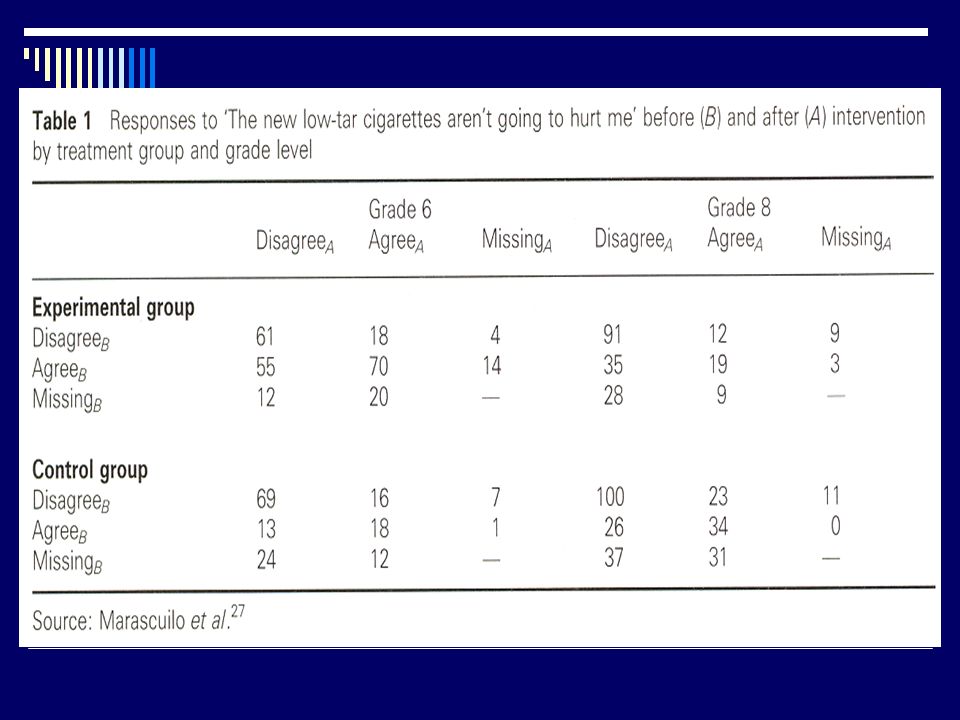
Valeurs manquantes Exemple 1
Developing a prognostic model in the presence of missing data: an ovarian cancer case study Taane G. Clark*, Douglas G. Altman Journal of Clinical Epidemiology 56 (2003) 28–37 Valeurs manquantes pour 8 des 10 facteurs prognostiques potentiels : 2-43% Temps de survie connus
 28–37. Valeurs manquantes pour 8 des 10 facteurs prognostiques potentiels : 2-43% Temps de survie connus.")
19
Valeurs manquantes Exemple 1 - étapes de la procédure
1. Investigating the missing data a. Quantifying the multivariate patterns of the missing data. b. Plotting the proportion of missing data for each potential prognostic factor against diagnosis year to show time trends in measurement practice.

20
Valeurs manquantes Exemple 1 - étapes de la procédure
1. Investigating the missing data c. Exploring the relationship between missing data of potential prognostic factors with other prognostic variables, survival information [i.e., (log) survival time and the censoring indicator], and auxiliary variables.
 survival time and the censoring indicator], and auxiliary variables.")
21
Valeurs manquantes Exemple 1 - étapes de la procédure
2. Specifying an imputation model. 3. Using the model to generate (via a random sampling procedure) M sets of imputed values for the missing data points, thus creating M completed datasets.
 M sets of imputed values for the missing data points, thus creating M completed datasets.")
22
Valeurs manquantes Exemple 1 - étapes de la procédure
4. For each completed dataset, carrying out a Cox regression, obtaining estimate of interest and its estimated variance 5. Combining the results from the different datasets to obtain a prognostic model.

23
Valeurs manquantes Exemple 1 - étapes de la procédure
6. Constructing a final “completed data” model (Model 2) by removing the covariate with the highest P-value and repeating steps 4 and 5 until all remaining covariates were significant at a 5% level (backward elimination).
 by removing the covariate with the highest P-value and repeating steps 4 and 5 until all remaining covariates were significant at a 5% level (backward elimination).")
24
Valeurs manquantes Exemple 1 Etape 1 : missing data = MAR
Etapes 2 et 3 = simulation bayésienne Etape 3 : nombre d ’imputations répétées=10

25
Valeurs manquantes Exemple 1 - Etape 1 – Pattern «missing»
Prognostic variable N (%) Grade Unknown (11.7) Ascites Presence (59.5) Absence (35.1) Unknown (5.5) Alkaline phosphatase (66.7)
 Grade. Unknown 139 (11.7) Ascites. Presence 707 (59.5) Absence 417 (35.1) Unknown 65 (5.5) Alkaline phosphatase 793 (66.7)")
26
Valeurs manquantes Exemple 1-Etape 1-Pattern «missing»
The number of patients contributing to a complete case analysis using all the prognostic factors would be 358 (245 deaths). Plots of the proportion of missing data by diagnosis year show that the proportions for ascites, alkaline phosphatase, albumin, grade, and residual disease were constant.
. Plots of the proportion of missing data by diagnosis year show that the proportions for ascites, alkaline phosphatase, albumin, grade, and residual disease were constant.")
27
Valeurs manquantes Exemple 1 - Etape 1-Pattern «missing»
The proportion of missing CA125 data decreased linearly in time from 85 to 21% between 1984 and 1999. The proportion of missing performance status had an increasing trend in time with a minimum of 18% in 1986 and a maximum of 71% in 1995.

28
Valeurs manquantes Exemple 1 - Etape 1 - Evidence of MAR data
An analysis of the survival distributions of non-missing and missing strata within each of the factors (log) CA125, grade, FIGO stage, and performance status showed no visual or statistical evidence of significant differences.
 CA125, grade, FIGO stage, and performance status showed. no visual or statistical evidence of significant differences.")
29
Valeurs manquantes Exemple 1 - Etape 1 - Evidence of MAR data
Difference between the survival distributions of patients with and without missing data for ascites (P .002), albumin (P .003), alkaline phosphatase (P .020) and residual disease (P .020)
, albumin (P .003), alkaline phosphatase (P .020) and residual disease (P .020)")
30
Valeurs manquantes Exemple 1 - Etape 1 - Evidence of MAR data
Those patients missing albumin and alkaline phosphatase results had a better prognosis, suggesting that eliminating the patients with missing values would lead to an underestimate of the true survival of the cohort. The opposite effect was seen for ascites and residual disease.

31
Valeurs manquantes Exemple 1 - Etape 1 - Evidence of MAR data
The univariate logistic models indicated that histology and clinical trial participation were associated with the missingness of all but one prognostic variable.

32
Valeurs manquantes Exemple 1 - Etape 2 à 5 - Imputation
We completed 10 data sets by imputing 2,045 values in each. As a consequence, 6,265 additional real data values were incorporated into each dataset.

33
Valeurs manquantes Exemple 1 - étape 2 – Imputation model
For binary variables (e.g., the presence or absence of ascites) we used a logistic model For categorical variables with three or more ordered levels (e.g., performance status) we applied a polytomous (2 levels) logistic model
 we used a logistic model. For categorical variables with three or more ordered levels (e.g., performance status) we applied a polytomous (2 levels) logistic model.")
34
Valeurs manquantes Exemple 1 - Etape 2 - Imputation model
For continuous variables (e.g., log CA125) we used normal linear regression truncated where appropriate to the credible range of values.
 we used normal linear regression truncated where appropriate to the credible range of values.")
35
Valeurs manquantes Exemple 1 - Etapes 2 à 5 - Imputation
The prevalences (%) of categorical prognostic factors in the original data (ignoring missing data) were consistent with those from the 10 imputations.
 of categorical prognostic factors in the original data (ignoring missing data) were consistent with those from the 10 imputations.")
36
Valeurs manquantes Exemple 1 - Etapes 2 à 5 - imputation
Original Completed (a) Prognostic Factor # % Median Range Overall % Grade I – II – III – Unknown — — — Ascites Presence – Absence – Unknown — — — (a) 10 datasets with original data augmented by imputed missing values.
 Prognostic Factor # % Median Range Overall % Grade. I – II – III – Unknown — — — Ascites. Presence – Absence – Unknown 65 0 — — — (a) 10 datasets with original data augmented by imputed missing values.")
37
Valeurs manquantes Exemple 1 - Etapes 2 à 5 - Imputation
The median and range of albumin, log CA125, and alkaline phosphatase in the original data were consistent with the median of the median of the 10 imputation distributions and the extreme values of these distributions, respectively.

38
Valeurs manquantes Exemple 1 - Etape 2 à 5 - imputation
Original Completed Prognostic Median Range Median Range Factor Log CA125 (5.34) (1.79–10.04) –10.04 Albumin (39.0) (20.0–50.0) –50.0 Log Alk. Phos. (4.54) (3.26–7.50) –7.50
 (1.79–10.04) – Albumin (39.0) (20.0–50.0) –50.0. Log Alk. Phos. (4.54) (3.26–7.50) –7.50.")
39
Valeurs manquantes Exemple 1 - Etapes 2 à 5 - Imputation
The narrow ranges of imputation values for each potential prognostic variable coincides with the visual impression that the distributions for each of the potential prognostic factors in the 10 imputed datasets were similar.

40
Valeurs manquantes Exemple 1 - Etape 6 - Fitting the Cox models.
Model 1 : as four factors, each with missing values, were found not to be prognostic, the analysable dataset was 518 (380 deaths). Model 2 : pooled analysis using 10 complete datasets with imputed missing values. Grade and ascites were statistically significant in Model 2, but not in Model 1.
. Model 2 : pooled analysis using 10 complete datasets with imputed missing values. Grade and ascites were statistically significant in Model 2, but not in Model 1.")
41
Valeurs manquantes Exemple 1 - Etape 6 - Fitting the Cox models.
A complete case analysis based on Model 2 would include only 449 patients (319 deaths). The confidence limits are narrower in the augmented data, especially for those with less missing observations in the original dataset.
. The confidence limits are narrower in the augmented data, especially for those with less missing observations in the original dataset.")
42
Exemple 1 - Etape 6 - Fitting the Cox models.
The models applied to completed data (i.e., the 10 datasets with imputed missing values) had better calibration (i.e., greater ability to produce unbiased estimates of outcome) superior discrimination (i.e., improved ability to provide accurate predictions for individual patients) There was little difference between the discrimination measures of Model 1 and Model 2 when applied to the completed data.
 had better calibration (i.e., greater ability to produce unbiased estimates of outcome) superior discrimination (i.e., improved ability to provide accurate predictions for individual patients) There was little difference between the discrimination measures of Model 1 and Model 2 when applied to the completed data.")
43
Exemple 1 - Conclusion Most data are multivariate in nature, so a small proportion of missing data for several variables can lead to a severely depleted complete case analysis. MI seems appropriate in this setting if the original dataset is not too small.

44
Valeurs manquantes Exemple 1 - conclusion
Using imputed data we are incorporating patients that are removed merely because one or more of their prognostic factors are missing and, as a result, increasing power and adding precision to an analysis. our approach may be viewed as a sensitivity analysis, and ultimately we need to use judgement about the plausibility of assumptions in a particular situation to assess which is the primary analysis.

45
Valeurs manquantes Exemple 2 : une étude longitudinale
Attrition in longitudinal studies: How to deal with missing data Jos Twisk*, Wieke de Vente Journal of Clinical Epidemiology 55 (2002) 329–337
 329–337.")
46
Valeurs manquantes Exemple 2 - Conclusion
When MANOVA for repeated measurements is used to analyze a longitudinal dataset with missing data, imputation methods to replace these missing data are highly recommendable (because MANOVA as implemented in the software used (SPSS), uses listwise deletion of cases with a missing value).
, uses listwise deletion of cases with a missing value).")
47
Valeurs manquantes Exemple 2 - Conclusion
When GEE is used to analyze a longitudinal dataset with missing data, not imputing at all may be better than any of the imputation methods applied. If one chooses to impute missing values, longitudinal methods are generally preferred above cross-sectional methods.

48
Valeurs manquantes Exemple 2 - Conclusion
Using the more refined multiple imputation method to impute missing values did not lead to different point estimates than the single imputation techniques. The estimated standard errors were higher than the ones obtained from the complete dataset, which seems to be theoretically justified, because they reflect uncertainty in estimation caused by missing values.

49
Valeurs manquantes Exemple 2 - Limitations
Specific observational longitudinal dataset Four missing data scenarios Limited number of imputation techniques Missingness dependent on the outcome variable Two statistical methods Less advanced multiple imputation estimation pro-cedures)
")
50
Valeurs manquantes Exemple 3 – Un essai clinique
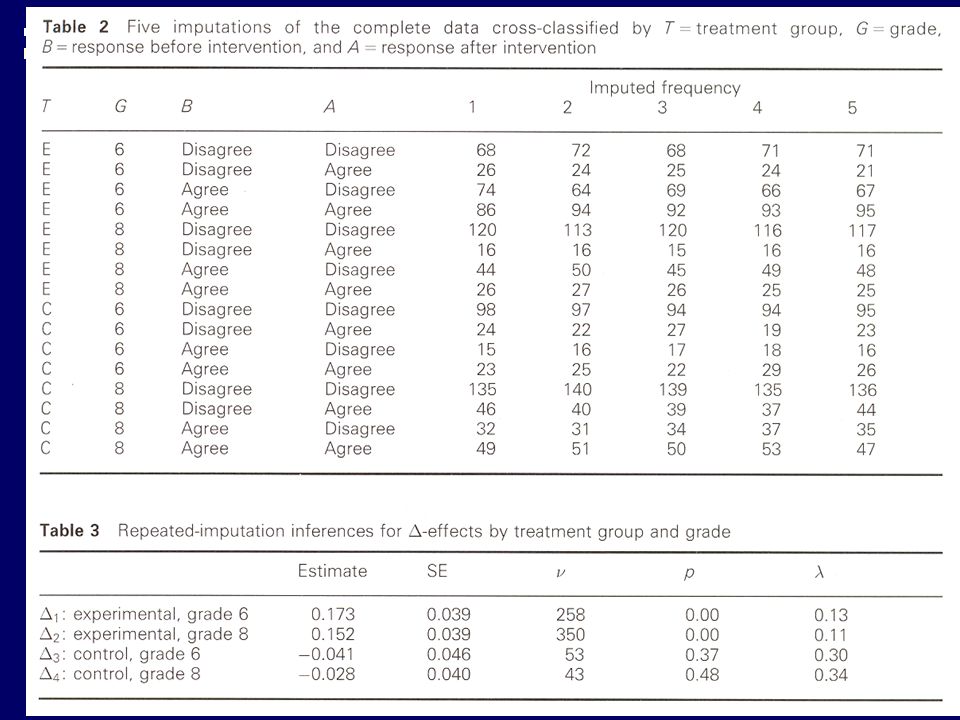
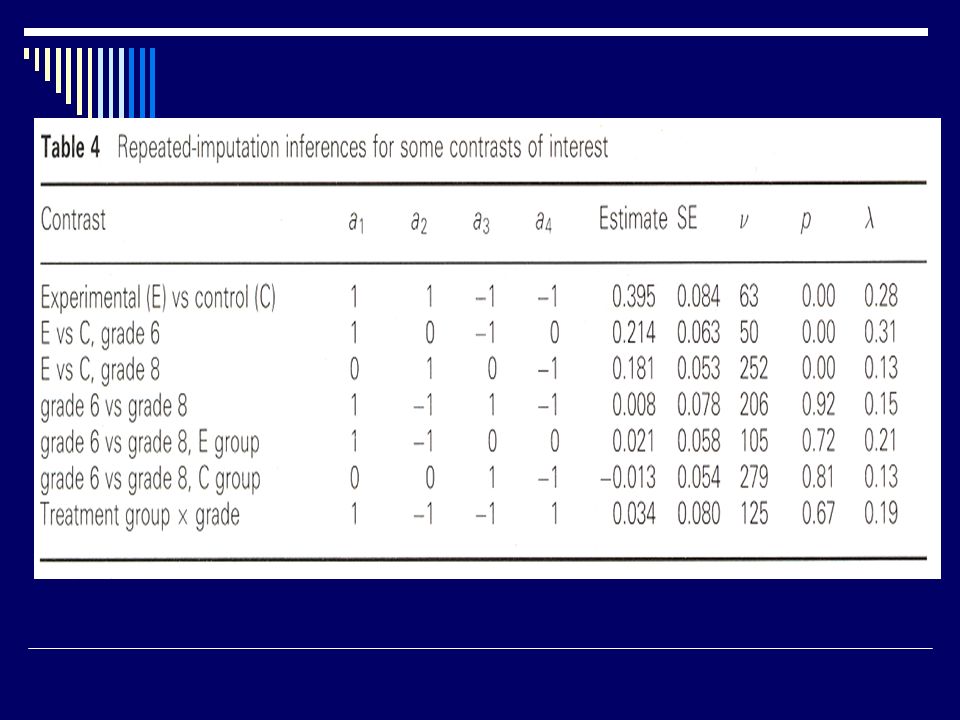
Extrait de « Multiple Imputation : a primer». JL Schafer Statistical Methods in Medical Research, 1999; 8 (1) 3-15
")
54
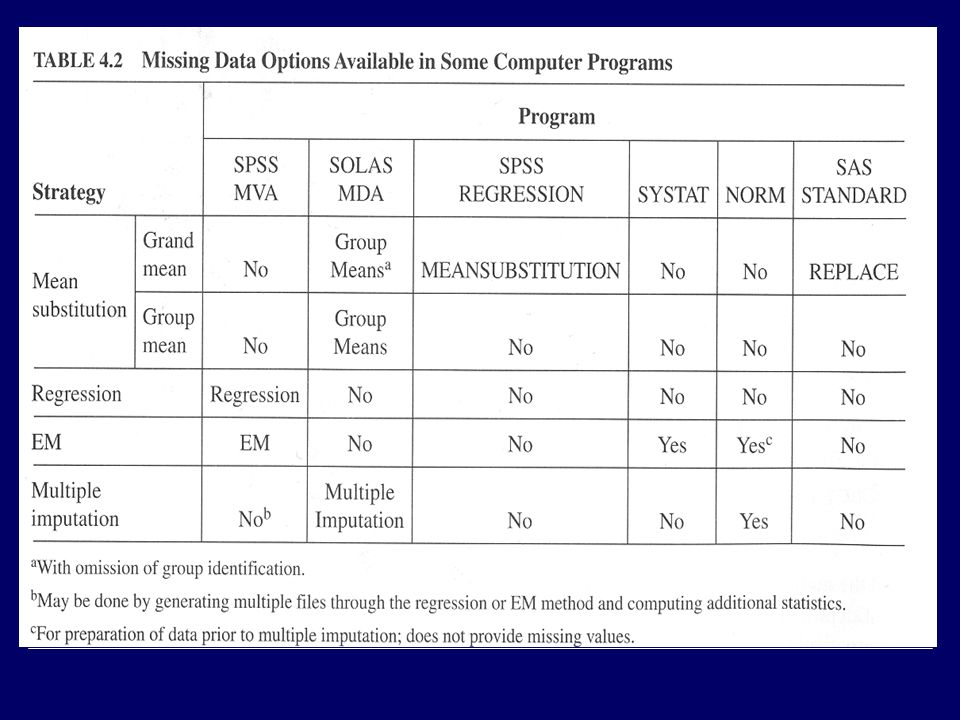
VALEURS MANQUANTES Softwares
Routines pour STATA S-PLUS SAS NORM (free sur INTERNET (Schafer, 1999) SOLAS™ for Missing Data Analysis and Multiple Imputation
 SOLAS™ for Missing Data Analysis and Multiple Imputation.")
55
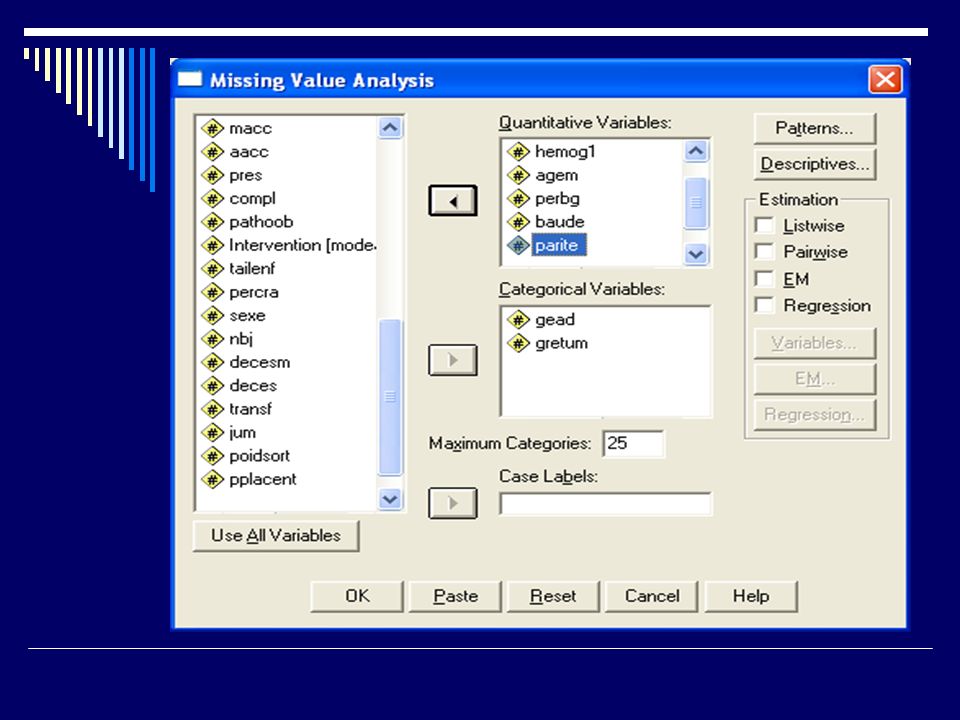
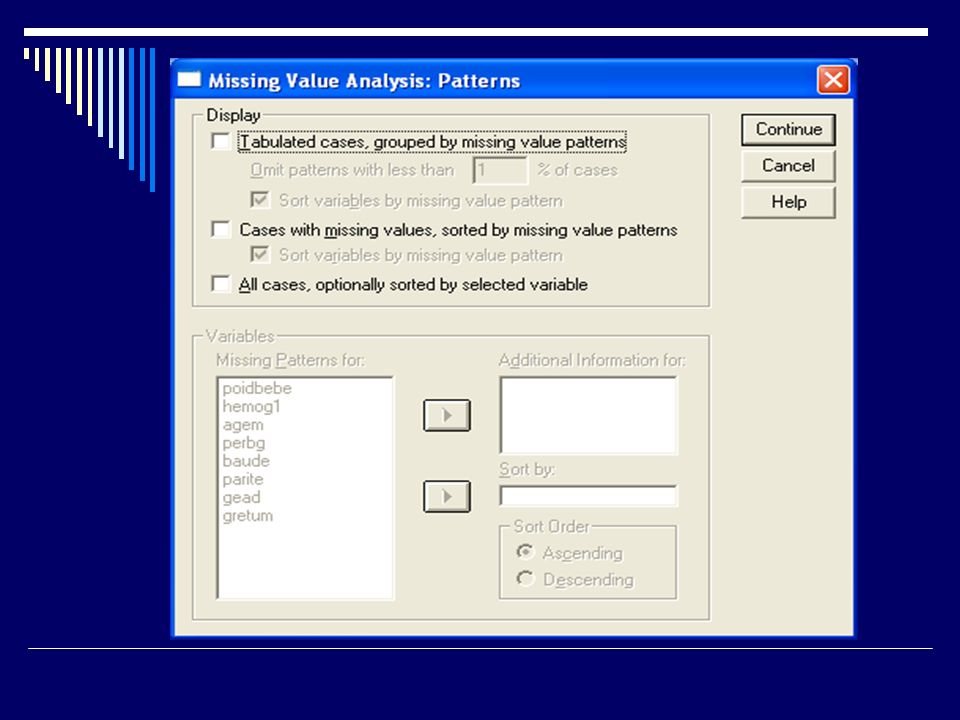
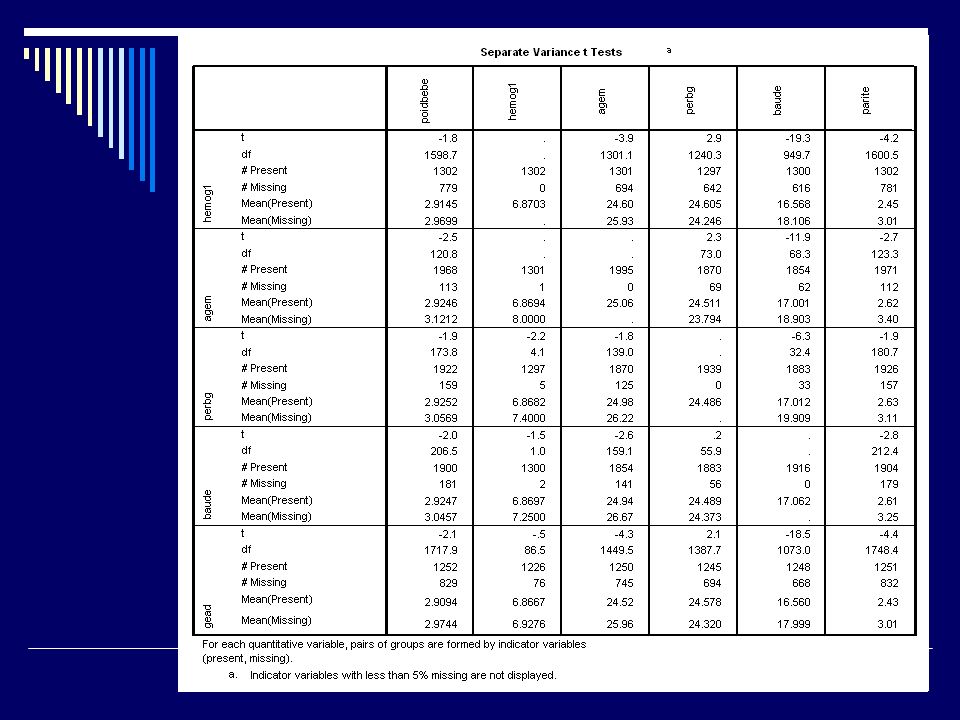
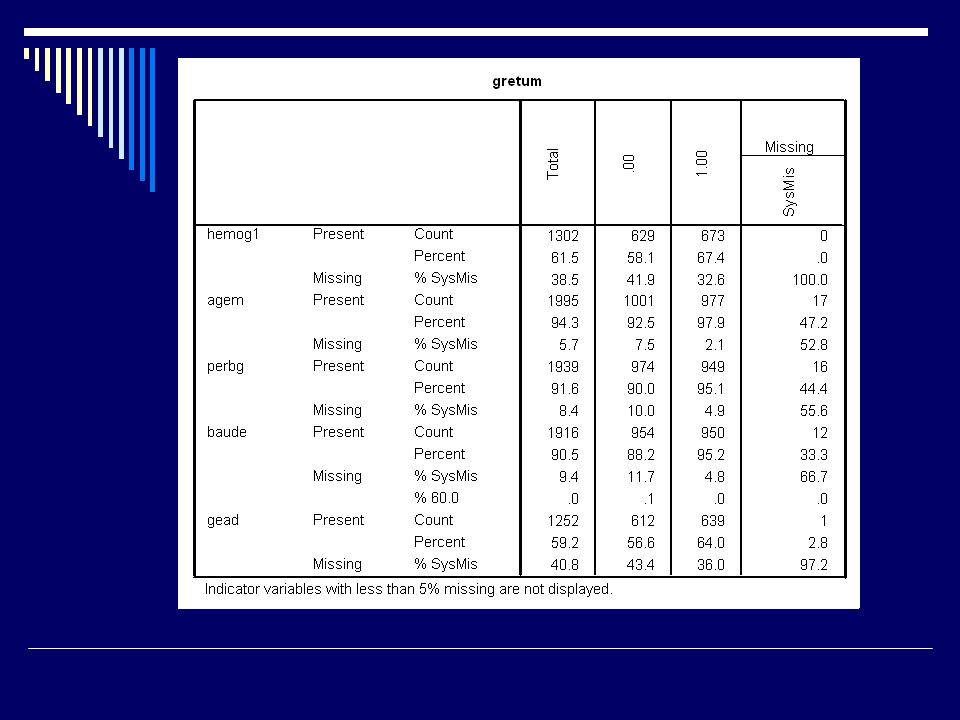
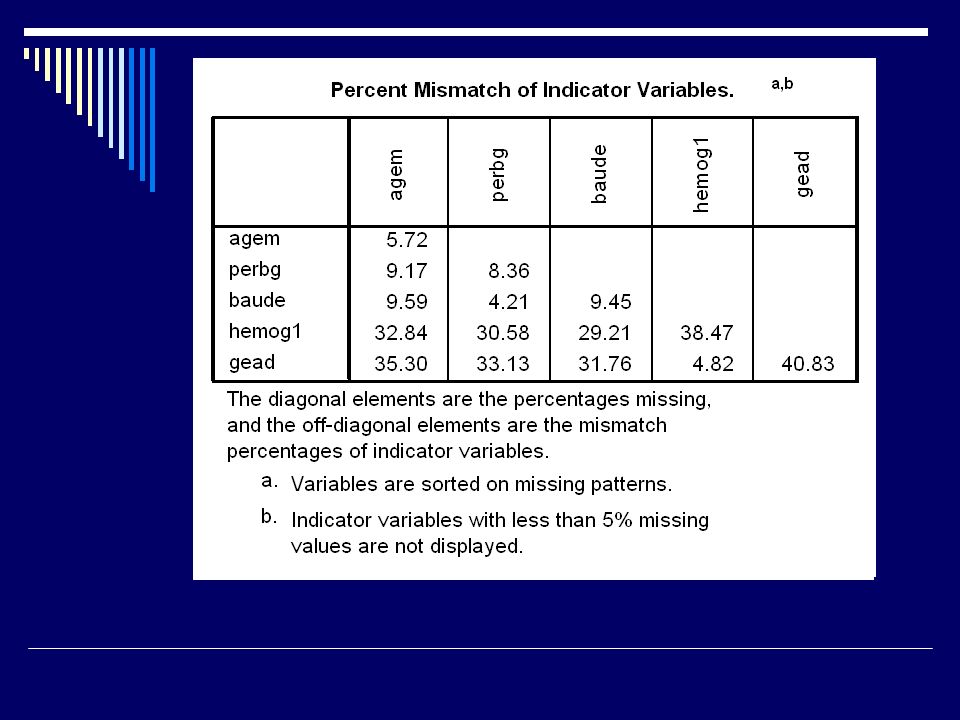
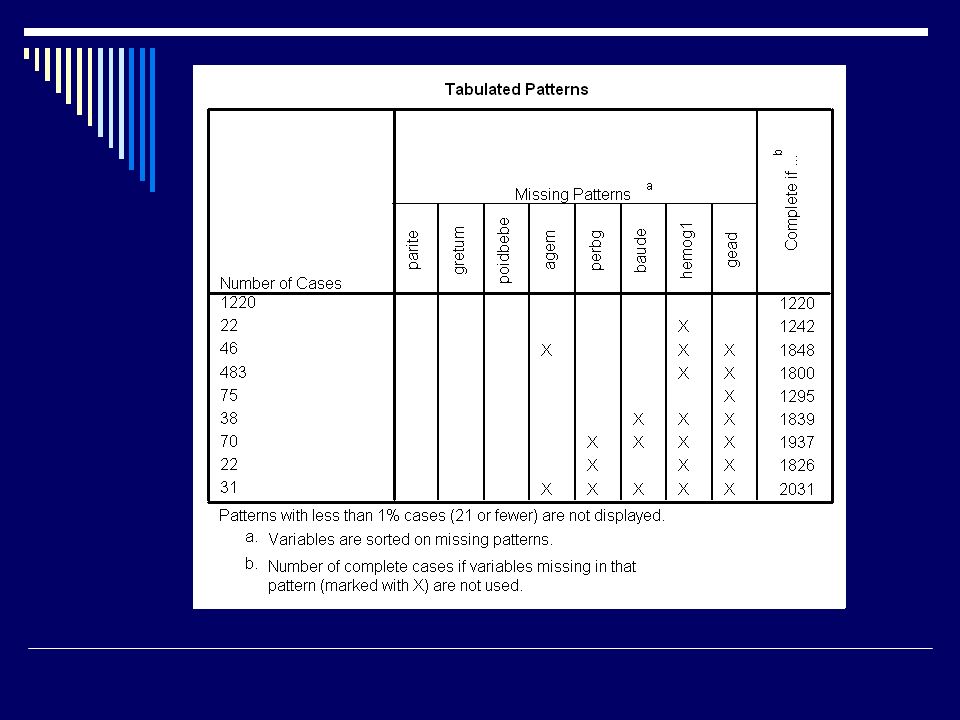
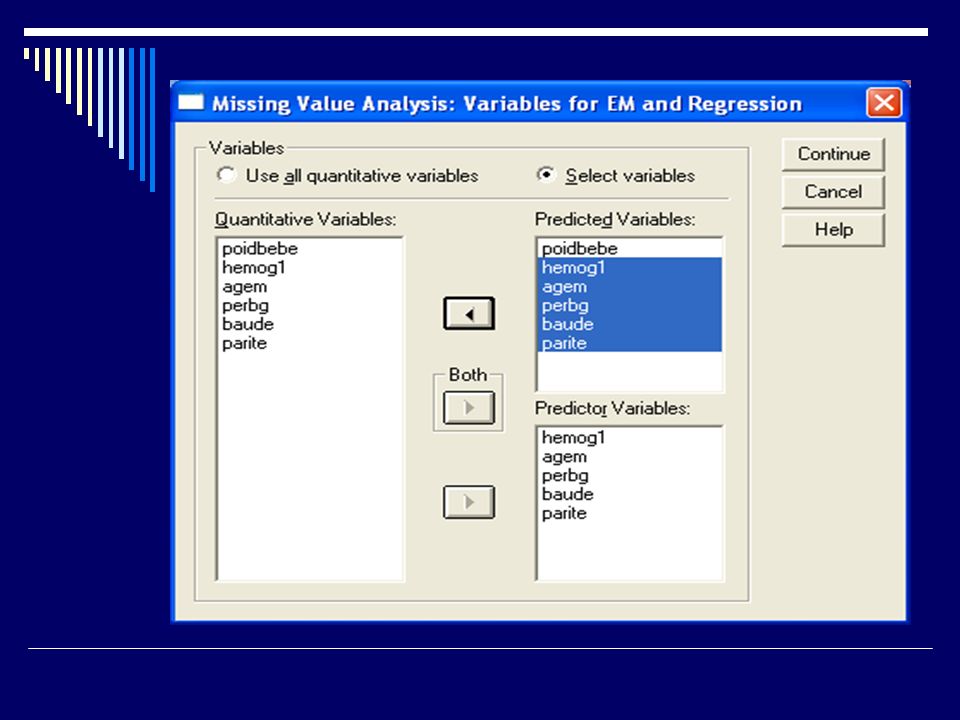
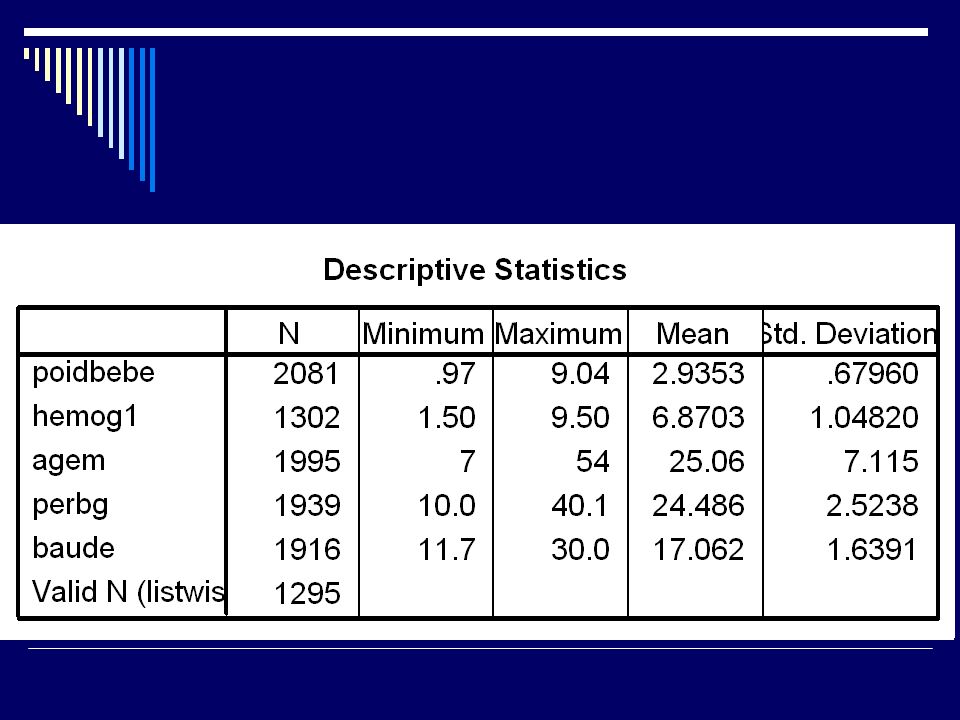
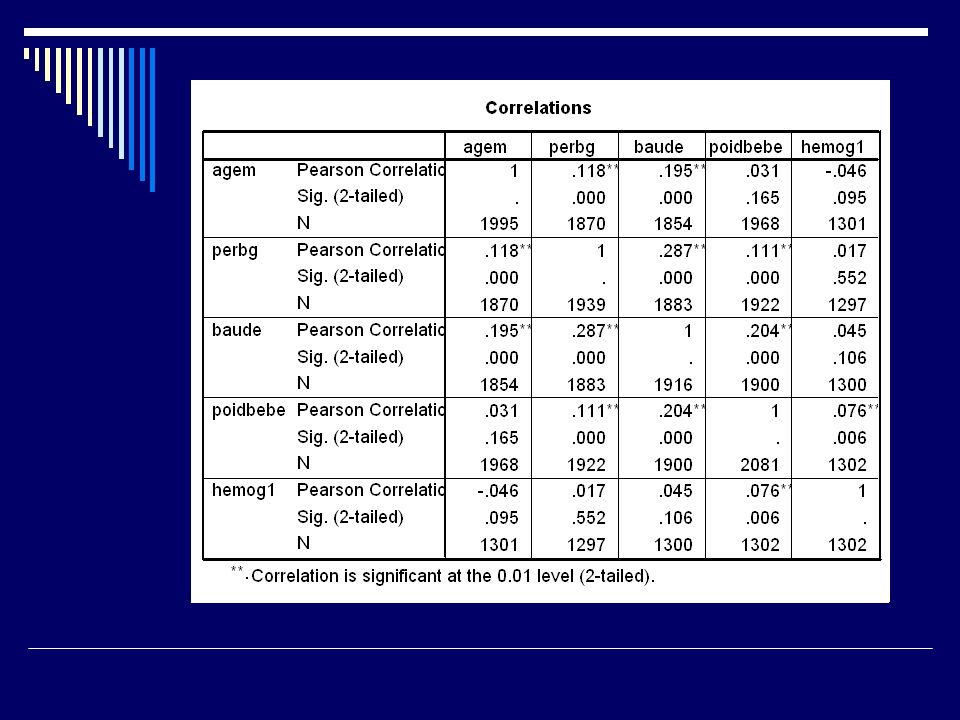
Valeurs manquantes Et SPSS? Module MVA Pattern des missings
Méthodes de substitution : Régression EM

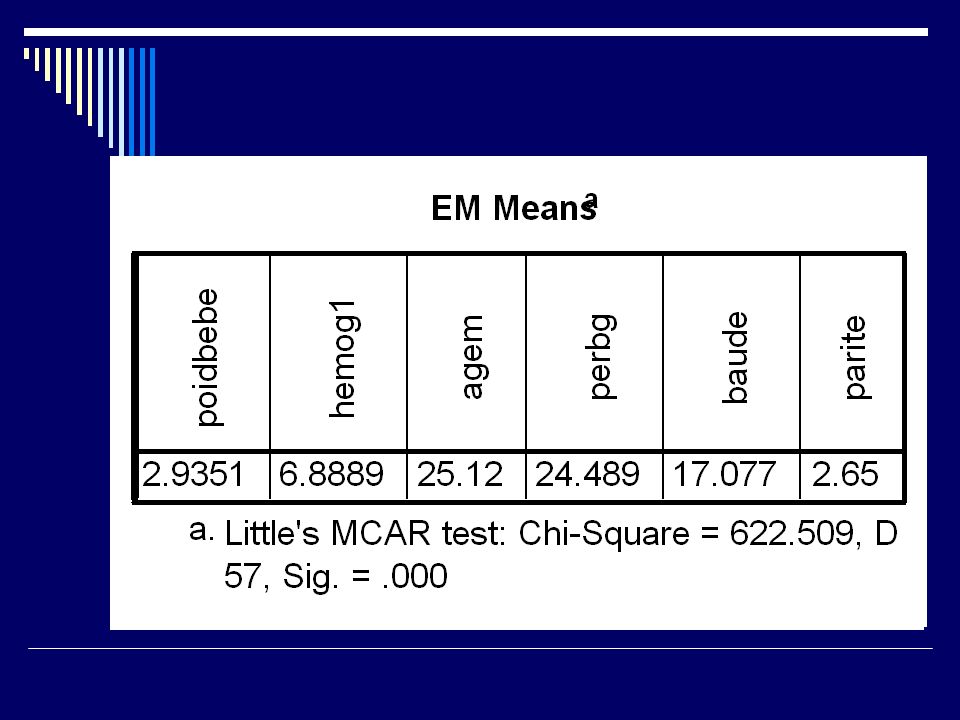
71
Valeurs manquantes EM Deux étapes : E = valeurs attendues des données manquantes; M = estimation des paramètres (corrélations) comme si les valeurs manquantes avaient été complétées Avec SPSS MVA, on peut simuler une imputation multiple
 comme si les valeurs manquantes avaient été complétées. Avec SPSS MVA, on peut simuler une imputation multiple.")
Présentations similaires







 in the Business.>")















 Michel Tenenhaus.>")