Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
J’ai trop de variables :
comment trouver les variables les plus pertinentes pour expliquer ou prédire un phénomène ? Comment dealer avec le fait d’avoir trop de variables. D’un côté, vous n’êtes pas être capable de tous les analyser, Vous avez un intuition et une expérience qui vous rassurent sir certaine variables, mais vous voulez éviter d’oublier des variables importantes pour expliquer un phénomène. Le cas ou vous recevez des variables externes de Stat Can, Psyte, Optima, Generation 5 On va y aller de façon très pratique, sans trop entrer dans les concepts théoriques étant donnée que la majorité pour s’adapté à la majorité du groupe. Il faut quand même connaître un minimum de concepts plus théorique pour faire ceci et on tentera de vulgariser le plus possible ces concepts;

2
Paul Légaré de PJL Inc, Generation5, paul.legare@pjldata.com
PAR Paul Légaré de PJL Inc, Generation5, Eugène Robitaille, Senior consultant, Eugene Robitaille & Associates, consultants. Voici nos coordonnées dans le cas où vous désirez nous contacter.

3
Plan de la présentation :
Présentation des données de Generation5; Qu’est-ce qu’un modèle prédictif ou explicatif; Notre exemple sur SAS EM; Le choix des variables à inclure et les différents niveaux de granularité des variables; Ce qu’il faut dans le dataset pour débuter; Attention (1) =l’erreur de type II; Brève introduction aux arbres de décision; EM Input node; Attention (2) = Les variables catégoriques qui contiennent beaucoup de modalités; EM data partition node; EM Tree node; Attention (2) pour corriger les variables catégoriques qui contiennent trop de modalités Attention (3) = Quelques problèmes rencontrés; Pour faire cet exemple, on a utilisé les données de Generation 5. On va seulement prendre des données externes pour l’exemple actuel. On peux pas prendre un exemple spécifique d’une compagnie, parce que les données internes d’une compagnie, parce que les modèles d’une compagnie, c’est très secret. Donc, je vais laisser Paul vous expliqué un peu c’est quoi les données de Generation 5 pour faire la première mise en contexte..
 =l’erreur de type II; Brève introduction aux arbres de décision; EM Input node; Attention (2) = Les variables catégoriques qui contiennent beaucoup de modalités; EM data partition node; EM Tree node; Attention (2) pour corriger les variables catégoriques qui contiennent trop de modalités. Attention (3) = Quelques problèmes rencontrés; Pour faire cet exemple, on a utilisé les données de Generation 5. On va seulement prendre des données externes pour l’exemple actuel. On peux pas prendre un exemple spécifique d’une compagnie, parce que les données internes d’une compagnie, parce que les modèles d’une compagnie, c’est très secret. Donc, je vais laisser Paul vous expliqué un peu c’est quoi les données de Generation 5 pour faire la première mise en contexte..")
4
Introduction Caractéristiques des données
Partie A – données de Génération 5 Introduction Caractéristiques des données mises à jour annuelles couverture : plus de variables granularité des données : chaque variable est estimés pour chaque code postal à six caractères du Canada: Au total : matrice de x

5
Granularité des estimés au code postal : impact
Revenu annuel moyen ménages: $ 50,266 Valeur moyenne des logements : $ 196,698 AD

6
H2C1X2 : Revenu : $ 36,393 Logement : $ 146,308 H2C1X5 : Revenu : $ 63,908 Logement : $ 288,990

7
Description des bases de données
Super census : Caractéristiques des particuliers, des ménages et des logements (n > 1,500 ) Famex : dépenses sur les habitudes de dépenses des ménages ( n > 390) RAE/RTS BBM : données comportementales sur les habitudes de consommation et média (n > 2, 200) Enquête PMB : données sur les préférences des consommateurs et patterns de consommation (n > 4,300)
 Famex : dépenses sur les habitudes de dépenses. des ménages ( n > 390) RAE/RTS BBM : données comportementales sur. les habitudes de consommation et média (n > 2, 200) Enquête PMB : données sur les préférences des. consommateurs et patterns de consommation (n > 4,300)")
8
MOSAIC : Modèles de segmentation géo démographique
Classifications des codes postaux en une grille de 20 Groupes et de 150 micro segments. Classifications basée à 80% sur les comportements et 20% sur les dimensions démographiques, sociales et économiques. Plus de 300 variables sont utilisées pour configurer chaque Groupe et chaque micro segments.

9
MOSAIC Modèle Assurances Modèle Finances Modèle commerce de détail
Modèle général

10
Qu’est ce qu’un modèle prédictif ou explicatif?
J’ai une question qui doit être transformée sous forme d’une variable (colonne) binaire, nominale ou continue: Quels sont mes clients les plus à risque de demander une réclamation d’assurance? Parmi les patients diagnostiqués du cancer, quels sont ceux qui en mourront ? Quel sont les clients qui achèteront un produit X? Quel sont les clients qui quitteront notre entreprise bientôt ? Quel sont les personnes qui fraudent le plus les impôts ? Etc. TXT Quel sont les clients qui achèteront un produit. Pour être en mesure de comparer quelques choses, il faut avoir tous les cas possible dans mon échantillon. Pour ce qui touche la variable dépendante de type binaire (oui, non), De préférence en proportion assez identique 50%, ou au moins 25% de chaque cas. Donc voici les exemples de variables dépendantes…. Donc, il me faut des personnes qui ont acheter et des personnes qui personnes qui n’ont pas acheté. Dans ces cas-ci, ma variable dépendante est : Mort ou encore en vie; À acheté le produit n’a pas acheter le produit; Est toujours client / à quitter ? As fait une réclamation, n’a jamais fait de réclamation Variables indépendantes peuvent être age du conducteur, son expérience, l’endroit ou il reste, le type de véhicule qu’il conduit,… Les variables dépendantes peuvent être nominal où continu….
 binaire, nominale ou continue: Quels sont mes clients les plus à risque de demander une réclamation d’assurance Parmi les patients diagnostiqués du cancer, quels sont ceux qui en mourront Quel sont les clients qui achèteront un produit X Quel sont les clients qui quitteront notre entreprise bientôt Quel sont les personnes qui fraudent le plus les impôts Etc. TXT. Quel sont les clients qui achèteront un produit. Pour être en mesure de comparer quelques choses, il faut avoir tous les cas possible dans mon échantillon. Pour ce qui touche la variable dépendante de type binaire (oui, non), De préférence en proportion assez identique 50%, ou au moins 25% de chaque cas. Donc voici les exemples de variables dépendantes…. Donc, il me faut des personnes qui ont acheter et des personnes qui personnes qui n’ont pas acheté. Dans ces cas-ci, ma variable dépendante est : Mort ou encore en vie; À acheté le produit n’a pas acheter le produit; Est toujours client / à quitter As fait une réclamation, n’a jamais fait de réclamation. Variables indépendantes peuvent être age du conducteur, son expérience, l’endroit ou il reste, le type de véhicule qu’il conduit,… Les variables dépendantes peuvent être nominal où continu….")
11
Qu’est ce qu’un modèle prédictif ou explicatif?
On veux prédire quelque chose ou expliquer quelque chose On part du passé Pour expliquer ou prédire un comportement futur Je tente d’établir une relation entre la variable dépendante (target) et les variables indépendantes (Input); Il me faut au moins une variable dépendante (target); et des variables indépendantes (input); Pour continuer cette mise en contexte, à tous les fois qu’on veux prédire quelques choses, on parle de modèle prédictif et explicatif. je parts d’un échantillon du passé J’ai déjà observé le phénomène et je part de cette expérience passé pour tenté d’expliquer le futur
 et les variables indépendantes (Input); Il me faut au moins une variable dépendante (target); et des variables indépendantes (input); Pour continuer cette mise en contexte, à tous les fois qu’on veux prédire quelques choses, on parle de modèle prédictif et explicatif. je parts d’un échantillon du passé. J’ai déjà observé le phénomène et je part de cette expérience passé. pour tenté d’expliquer le futur.")
12
Notre exemple sur SAS / EM
Mon entreprise désire trouver des nouveaux clients, Quels sont les clients qui sont le plus enclin à acheter le produit X ? Quelles sont les variables importantes pour expliquer ce comportement d’achat? ,

13
Les variables Indépendantes : Le niveau de granularité des données
Le niveau de granularité des données est un synonyme de sa qualité. Si une variable est pertinente, plus la granularité est petite, plus elle sera discriminante. Par exemple, le revenu exact d’une personne est plus discriminant pour expliquer son comportement d’achat que le revenu du quartier ou de la province dans lequel il habite; Quelques granularités : La personne; Le ménage (la famille où la famille élargie,…) L’adresse ; L’immeuble (block appartement); Les voisins rapprochés; Le code postal; L’aire de diffusion; Le RTA; etc. Si vous êtes capable de diminuer le niveau de granularité de vos données, vous pouvez améliorer grandement votre modèle Maintenant on commence à entrer dans le vif du sujet et de parlé des variables indépendantes. Comme on a dis, on ne peux pas prendre des variables internes à une compagnie pour faire ceci, c’est trop secret. Pour ceci on a pris seulement des variables d’une entreprise externes. (Generation 5). Dans les cas réelles, vous avez un mélange des variables internes et externes. Et quelques variables internes ressortiront comme étant vraiment les plus importantes et une ou deux variables externes pourrais ajouter seulement un peu plus de précision. Et ça c’est le premier point à faire, le gros avantage que vous pourrez apporter à votre entreprise, Ce n’ai pas d’être capable d’utilisé EM, ni d’être capable de traité 5000 variables. C’est VRAIMENT dans la transformation et le choix des variables interne où externes que vous allez choisir d’inclure dans votre dataset. Les variables Internes, c’est spécifique à un secteur d’activité et c’est très secret. Mais il y a des règles générales que vous pouvez suivre afin de vous aider à optimisé vos variables internes. Une de ces règles à suivre, c’est ce que Paul disais sur ce qu’il appel la Granularité. TXT Si on suit cette idée, vous devez toujours visée la plus petite granularité. si vous êtes capable d’augmenter le niveau de précision en dimimuant le niveau de granularité de vos données, vous pouvez améliorer grandement votre modèle. Ceci semble évident, mais si on poursuit cette logique de granularité, ça a pour conséquence que vous devez souvent vous creuser les méninge pour obtenir des variables plus précise. Et c’est là le gros avantage de l’analyste. Puis je vais vous donner un exemple de ceci.
 L’adresse ; L’immeuble (block appartement); Les voisins rapprochés; Le code postal; L’aire de diffusion; Le RTA; etc. Si vous êtes capable de diminuer le niveau de granularité de vos données, vous pouvez améliorer grandement votre modèle. Maintenant on commence à entrer dans le vif du sujet et de parlé des variables indépendantes. Comme on a dis, on ne peux pas prendre des variables internes à une compagnie pour faire ceci, c’est trop secret. Pour ceci on a pris seulement des variables d’une entreprise externes. (Generation 5). Dans les cas réelles, vous avez un mélange des variables internes et externes. Et quelques variables internes ressortiront comme étant vraiment les plus importantes et une ou deux variables externes pourrais ajouter seulement un peu plus de précision. Et ça c’est le premier point à faire, le gros avantage que vous pourrez apporter à votre entreprise, Ce n’ai pas d’être capable d’utilisé EM, ni d’être capable de traité 5000 variables. C’est VRAIMENT dans la transformation et le choix des variables interne où externes que vous allez choisir d’inclure dans votre dataset. Les variables Internes, c’est spécifique à un secteur d’activité et c’est très secret. Mais il y a des règles générales que vous pouvez suivre afin de vous aider à optimisé vos variables internes. Une de ces règles à suivre, c’est ce que Paul disais sur ce qu’il appel la Granularité. TXT. Si on suit cette idée, vous devez toujours visée la plus petite granularité. si vous êtes capable d’augmenter le niveau de précision en dimimuant le niveau de granularité de vos données, vous pouvez améliorer grandement votre modèle. Ceci semble évident, mais si on poursuit cette logique de granularité, ça a pour conséquence que vous devez souvent vous creuser les méninge pour obtenir des variables plus précise. Et c’est là le gros avantage de l’analyste. Puis je vais vous donner un exemple de ceci.")
14
Les variables Indépendantes : Le niveau de granularité des données
Le 10,851 rue Jarry, H3V-4J5 Le 9749 , rue St-André, Anhuntic, H3V-4J5 ANNONCE DANS LE VOIR: À 2 pas du métro Sauvé, 3 ½ à louer, électroménagers non fournis, , Entrée laveuse, sécheuse, 425$ / par mois. (514)XXX-XXXX ANNONCE DANS LA PRESSE : Dans le secteur Ahubtic, grand split-level détaché. 4 chambre à coucher, une toilette, grand garage, construction 1940, poêle à bois au sous-sol, piscine hors terre,demande 149,000$ (514)XXX-XXXX Pour notre exemple sur EM, on va se placé dans le cas d’une entreprise qui désir acquérir des nouveaux clients. Étant donnée qu’il s’agit de nouveaux clients à venir, cette entreprise possède aucune données internes sur ces clients à venir. C’est ce qu’on appel un modèle d’acquisition. De plus, si je vais prendre un exemple qui s’applique beaucoup au grandes entreprises qui ont beaucoup de données (BELL, Desjardins, Banque Nationale,…). La majorité d’entre nous qui travail sur SAS, on travail pour des grosses entreprises.. C’est quoi ce creuser les méninge pour trouver des variables pertinentes et de vous rapprocher de l’unicité de la personne. Dans l’exemple actuel, je n’ai pas de données sur mon groupe cible à cause que c’est des potentiels (non-clients), Mais c’est pas si vrai que ça… Étant donnée que je suis dans une grande entreprise, est ce que je peux prendre des informations internes sur les anciens clients qui était préalablement à cette adresse pour inféré des choses sur les non clients ?, est-ce que je peux avoir des données sur un immeuble, le bloc appartement, ou les quelques voisins qui sont très près ? C’est souvent le cas C’EST SOUVENT LE CAS…
XXX-XXXX. ANNONCE DANS LA PRESSE : Dans le secteur Ahubtic, grand split-level détaché. 4 chambre à coucher, une toilette, grand garage, construction 1940, poêle à bois au sous-sol, piscine hors terre,demande 149,000$ (514)XXX-XXXX. Pour notre exemple sur EM, on va se placé dans le cas d’une entreprise qui désir acquérir des nouveaux clients. Étant donnée qu’il s’agit de nouveaux clients à venir, cette entreprise possède aucune données internes sur ces clients à venir. C’est ce qu’on appel un modèle d’acquisition. De plus, si je vais prendre un exemple qui s’applique beaucoup au grandes entreprises qui ont beaucoup de données (BELL, Desjardins, Banque Nationale,…). La majorité d’entre nous qui travail sur SAS, on travail pour des grosses entreprises.. C’est quoi ce creuser les méninge pour trouver des variables pertinentes et de vous rapprocher de l’unicité de la personne. Dans l’exemple actuel, je n’ai pas de données sur mon groupe cible à cause que c’est des potentiels (non-clients), Mais c’est pas si vrai que ça… Étant donnée que je suis dans une grande entreprise, est ce que je peux prendre des informations internes sur les anciens clients qui était préalablement à cette adresse pour inféré des choses sur les non clients , est-ce que je peux avoir des données sur un immeuble, le bloc appartement, ou les quelques voisins qui sont très près C’est souvent le cas. C’EST SOUVENT LE CAS…")
15
Un exemple avec EM… Créer un dataset spécifique pour le choix des variables; Le dataset doit contenir assez d’observations pour être capable de traiter les variables catégoriques (20,000 observations); Sur échantillonner au besoin : Il doit y avoir un minimum de 25 % de valeurs positives pour la variable dépendante (target) Les clés et la variable dépendante (target) doivent être au début du dataset; On va aller tous de suite sur EM, et revenir à la présentation, parce que aller chercher les données ces long. J,ai débuté mon tests avec 5200 variables,
; Sur échantillonner au besoin : Il doit y avoir un minimum de 25 % de valeurs positives pour la variable dépendante (target) Les clés et la variable dépendante (target) doivent être au début du dataset; On va aller tous de suite sur EM, et revenir à la présentation, parce que aller chercher les données ces long. J,ai débuté mon tests avec 5200 variables,")
16
Choisir les variables les plus pertinentes…ATTENTION (1) !
Nous partons d’un échantillon avec énormément de variables inutiles; Plus il y a de variables plus il y aura de variables inutiles qui sortiront comme étant significatives (erreur de Type II); Comment résoudre ceci : Un test d’hypothèse très petit pour chacune des variables choisies (p < .0001); Un gros dataset (N=20,000); La construction du modèle se fait toujours sur un échantillon différent de celui qui a été utilisé pour trouver les variables; Au bout du compte, vous devez toujours être capable d’expliquer pourquoi une variable est importante; TXT Bon, aujourd’hui on parle un peu des sondage sur le prochain chef du PQ. Vous voyer souvent des Un sondage crop nous dis que 19 fois sur 20 (95%) des 5000 variables = 250 variables sont sortis qui ne devrais pas sortir;
; Comment résoudre ceci : Un test d’hypothèse très petit pour chacune des variables choisies (p < .0001); Un gros dataset (N=20,000); La construction du modèle se fait toujours sur un échantillon différent de celui qui a été utilisé pour trouver les variables; Au bout du compte, vous devez toujours être capable d’expliquer pourquoi une variable est importante; TXT. Bon, aujourd’hui on parle un peu des sondage sur le prochain chef du PQ. Vous voyer souvent des Un sondage crop nous dis que 19 fois sur 20 (95%) des variables = 250 variables sont sortis qui ne devrais pas sortir;")
17
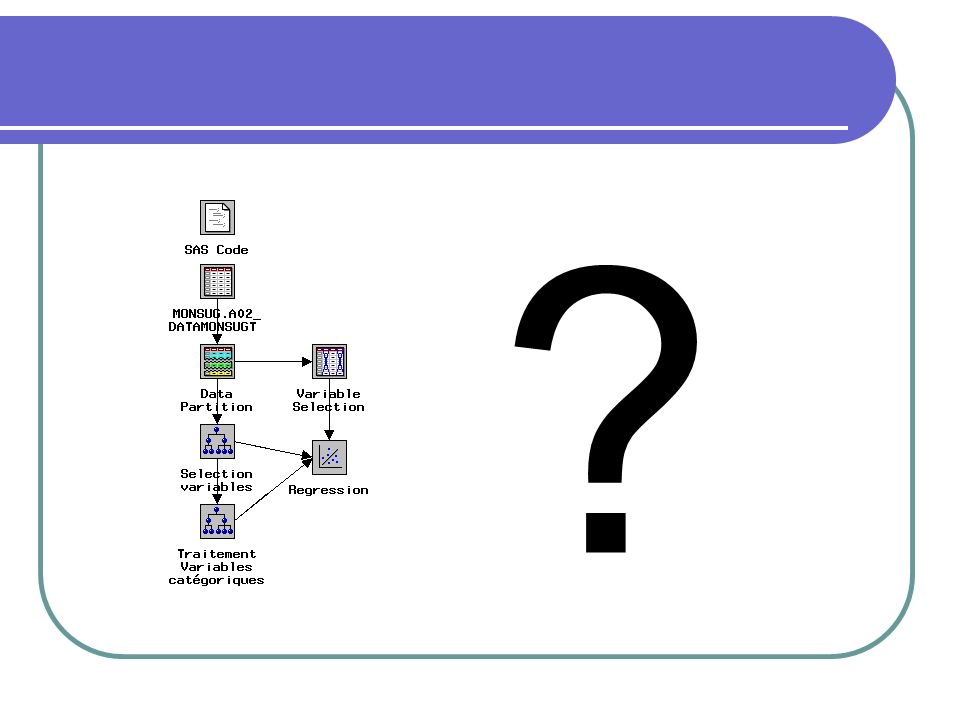
Un exemple avec EM Sur EM, il y a plusieurs façons de choisir des variables. Les deux plus populaires : Le noeud « Variable selection » (Pour plus d’information, voir dans la documentation SAS : SAS prducts\Enterprise miner\exterprise miner reference\variable selection node) Le nœud « Tree » (arbre de décision)
 Le nœud « Tree » (arbre de décision)")
18
Propriétés des arbres de décisions
Non-paramétrique; C’est un test multi-dimentionnel; Très robuste face aux valeurs extrêmes et aux valeurs manquantes; Pas besoin de transformations initiales, pas besoin de linéarité et de normalisation (la structure des données peut être complexe); Peux être utilisé avec variables catégoriques ou continues;
; Peux être utilisé avec variables catégoriques ou continues;")
19
Quand utiliser les arbres de décision
Sélection de variables; Transformer des variables continues en catégorique ou des variables catégoriques en continues; Remplacement des valeurs manquantes (surogates); Comparer des modèles paramétriques ou autres modèles et les expliquer (modèle neural ou autre); Suggérer des points (break points) pour transformer des variables continues en catégoriques; Modélisation; Trouver des prédicateurs concurrents (moins dispendieux) Découvrir les variables d’interaction; Je vous ai mis des exemples de quand utiliser les arbres de décision, c’est hors sujet; Utilise une méthode stepwize pour choisir les variables Réduire le nombre de variables catégoriques ou réduire le nombre de catégories pour les variables catégoriques qui possèdent beaucoup de modalités; C’est ce que nous allons faire aujourd’hui. Les arbres offrent un très bon appuis aux autres outils pour la modélisations, il sont souvent moins bon pour prédire, i y a tout de même des moyens de s’en sortir en construisant des modèles basée sur 100 arbres au lieur de un seul;
; Comparer des modèles paramétriques ou autres modèles et les expliquer (modèle neural ou autre); Suggérer des points (break points) pour transformer des variables continues en catégoriques; Modélisation; Trouver des prédicateurs concurrents (moins dispendieux) Découvrir les variables d’interaction; Je vous ai mis des exemples de quand utiliser les arbres de décision, c’est hors sujet; Utilise une méthode stepwize pour choisir les variables. Réduire le nombre de variables catégoriques ou réduire le nombre de catégories pour les variables catégoriques qui possèdent beaucoup de modalités; C’est ce que nous allons faire aujourd’hui. Les arbres offrent un très bon appuis aux autres outils pour la modélisations, il sont souvent moins bon pour prédire, i y a tout de même des moyens de s’en sortir en construisant des modèles basée sur 100 arbres au lieur de un seul;")
20
Un exemple avec EM… Aller chercher vos données avec le nœud « Input Data Source »; Utiliser le dataset en entier pour effectuer vos vérifications et vos tests (Metadata sample / Size / Change / cocher use complète data as sample)
")
21
Un exemple avec EM… Définissez vos variables
Target (une variable dépendante); Vérifier particulièrement les variables qui sont automatiquement considéré ID par le système (Voir s’agit-il de variables catégoriques contenant beaucoup de modalités ?) ;
; Vérifier particulièrement les variables qui sont automatiquement considéré ID par le système (Voir s’agit-il de variables catégoriques contenant beaucoup de modalités ) ;")
22
Un exemple avec EM… Vérifier l’onglet variables catégoriques afin d’identifier les variables catégoriques contenant beaucoup de modalités (Onglet Class variables / Trier par value)
")
23
Un exemple avec EM… Faire un « count distinct » des variables catégoriques les plus à risques;

24
Choisir les variables les plus pertinentes…ATTENTION (2) !
Les variables catégoriques qui contiennent beaucoup de modalités : 309 RTA 168 villes 76 Types Mosaic sur 149 16 Groupes Mosaic 15,234 Code postaux Comment résoudre ceci (on va le voir plus loin): Il faut pénaliser ces variables… S’il ressortent comme étant pertinentes, transformer ces variables catégoriques en variables continues ou réduire de beaucoup les catégories en faisant des groupes; Valider et tester le modèle,… des pénalités pour lesvariables catégriques à contenant beaucoup de modalités; (les outils de mining travail très mal avec ce genre de varaibles) Les variables catégoriques avec trop de modalités (Code postaux, RTA, villes,…) Il faut quelques fois les éliminer
: Il faut pénaliser ces variables… S’il ressortent comme étant pertinentes, transformer ces variables catégoriques en variables continues ou réduire de beaucoup les catégories en faisant des groupes; Valider et tester le modèle,… des pénalités pour lesvariables catégriques à contenant beaucoup de modalités; (les outils de mining travail très mal avec ce genre de varaibles) Les variables catégoriques avec trop de modalités (Code postaux, RTA, villes,…) Il faut quelques fois les éliminer.")
25
Un exemple avec EM… Faite une partition simple des données (data partition node) Utiliser 65% des données pour créer le modèle et 35% des données pour le valider ceci afin de ne pas faire ressortir que du sur-apprentissage Pourquoi 50 variables, de toute façon vous n’utiliserez jamais 50 variables dans un modèle, c’est certain. Il y a deux but Le but c’est qu’à partir de 50 variables, c’est travaillable, vus pouvez vérifier vos variables. Et le 2e Le but c’est toujours de laisser vos outils décidé et à partir de 50 variables, vous êtes capable d’utilisé les autres modèles pour choisir. Il faut toujours prendre un nouvel échantillon rendu à cet étape-ci, mais Par exemple, vous pourrez utilisé une méthode regressives (AIC, BIC, stepwize reg,…)
")
26
Un exemple avec EM… Faire un arbre de décision qui vise à faire ressortir plus de variables que le nombre désiré dans le modèle; Dans l’onglet « Basic », Splitting criteria = Gini reduction, nombre de surrogate = 2;

27
Un exemple avec EM… Dans l’onglet « advance »
Model = (Gini index) Total leaf impurity Sub-tree = The most leaves; Sauvegarder et faire rouler l’arbre
 Total leaf impurity. Sub-tree = The most leaves; Sauvegarder et faire rouler l’arbre.")
28
Un exemple avec EM… Après avoir obtenu le résultat de l’arbre(result / onglet score /variable sélection), choisir plus ou moins les 50 variables plus importantes et laisser tomber les autres;
, choisir plus ou moins les 50 variables plus importantes et laisser tomber les autres;")
29
Choisir les variables les plus pertinentes…ATTENTION (3) !
L’arbre ne fonctionne pas, l’ordinateur ne veut pas me donner de résultat; J’ai des variables que je sais historiquement importantes et elles ne sont jamais ressorties; Mon modèle me semble trop bon Les variables anachroniques; Les variables monotoniques; (pour plus d’information : Dorian Pile, Data preparation for data mining) J’ai beaucoup de variables catégoriques qui sont ressorties comme étant pertinentes; (gros problème) qui grandissent sans frontières, temps, key,) dois être transformé de façon non-monotonique; Variables anachroniques, si c’est trop beau pour être vrais, c’est la raison; (voir p142., 200 remaping circlar discontinuity.
 J’ai beaucoup de variables catégoriques qui sont ressorties comme étant pertinentes; (gros problème) qui grandissent sans frontières, temps, key,) dois être transformé de façon non-monotonique; Variables anachroniques, si c’est trop beau pour être vrais, c’est la raison; (voir p142., 200 remaping circlar discontinuity.")
30
Traitement des variables catégoriques avec beaucoup de modalités
Pour corriger les variables catégoriques qui contiennent trop de modalités : Faire un nouvel arbre de décision avec ces paramètres : Choisir seulement les variables catégoriques en tant qu’input; Onglet variable / mettre le « Status » à use pour les variables « nominal » et la variable « target » status = don’t use pour tous les autres types de variables

31
Traitement des variables catégoriques avec beaucoup de modalités
Onglet « advanced » / dé-cocher Kass P-value adjustment

32
Traitement des variables catégoriques avec beaucoup de modalités
Onglet score/Data cocher Process or score : training, validation and test Faire rouler l’arbre et vérifier le résultat;

33
Traitement des variables catégoriques avec beaucoup de modalités
Onglet score/variables, cocher seulement leaf indentification variable ou prediction (décocher tous le reste) Faire rouler l’arbre
 Faire rouler l’arbre.")
34
Création d’une nouvelle variable catégorique à 5 modalité
La nouvelle variable catégoriques à 5 modalité sera désormais utilisée dans les modèles pour remplacer toutes les autres variables catégoriques

35
?
Présentations similaires
















>")


