Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Interprétation des essais cliniques pour la pratique médicale
Michel Cucherat Faculté de médecine Laennec – Lyon

2
Pourquoi faire sa propre évaluation des résultats des essais ?

3
Pourquoi la lecture critique ?
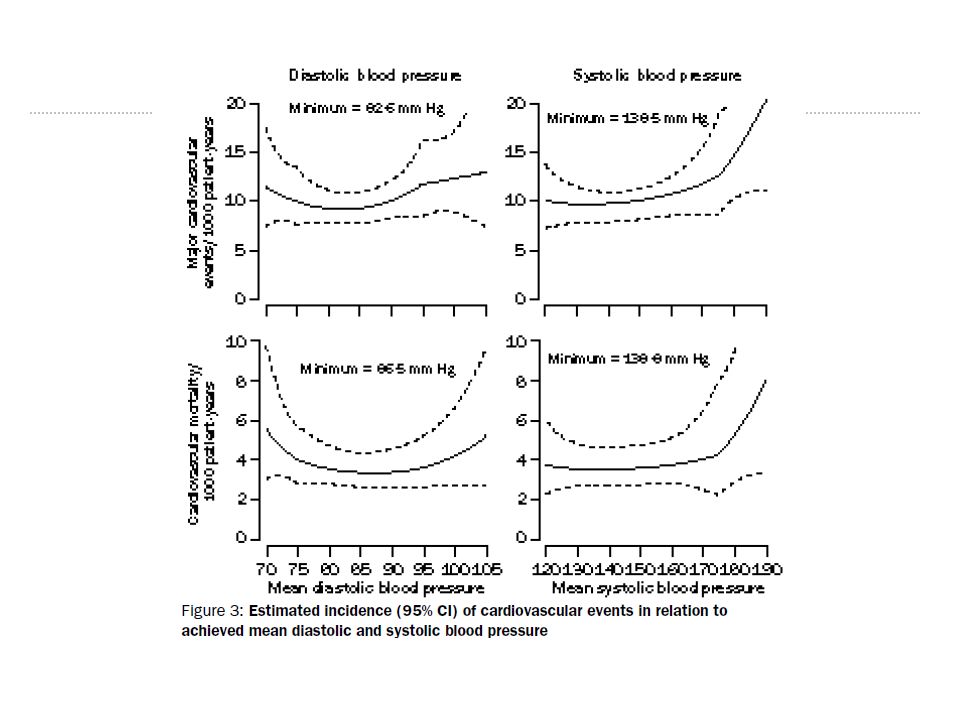
Essai HOT hypertension artérielle recherche de la cible tensionnelle optimale randomisation entre 3 cibles de PAD : <=90, <=85, <=80 mmHg critère de jugement clinique : Ev cardiovasculaires

4
ABSTRACT Interpretation : Intensive lowering of blood pressure in patients with hypertension was associated with a low rate of cardiovascular events. The HOT Study shows the benefits of lowering the diastolic blood pressure down to 82·6 mm Hg

5
Résultat

7
Origine de la conclusion
Analyse d'association statistique entre la valeur obtenue et le risque mise en évidence d'une valeur optimale (82.6 mmHg) = association et non pas causalité
 = association et non pas causalité.")
8
Spin des conclusions Survient sur la conclusion et la discussion
Ne pas lire conclusion et discussion Utiliser le papier comme base informative pour vous faire votre propre opinion des résultats

9
Comment faire sa propre évaluation des résultats des essais thérapeutiques

10
Objectif de la démarche
Déterminer l’intérêt médical d’un traitement Quel(s) bénéfice(s) apporte le traitement ? Chez quels patients ? Au prix de quel(s) risque(s) ? À partir des faits prouvés Dans le but de modifier ou non la pratique médicale
 bénéfice(s) apporte le traitement Chez quels patients Au prix de quel(s) risque(s) À partir des faits prouvés. Dans le but de modifier ou non la pratique médicale.")
11
Deux évaluations Quel degré de confiance peut on avoir dans les résultats ? Les résultats sont-ils fiables ? Quelle est la pertinence médicale des résultats obtenus ? Les résultats représentent-ils une avancées médicales (ont-ils un sens médical)
")
12
Intérêt médical du traitement
Résultats des essais Degré de confiance Résultats démontrés Résultats suggérés Pertinence clinique Intérêt médical du traitement

13
Quel degré de confiance peut on avoir dans les résultats ?

14
Un résultat peut être faux en raison :
D’une erreur aléatoire (due au hasard) D’un biais Fait courir le risque de fausse découverte (résultat faux positif) L’exactitude d’un résultat est impossible à établir Car on ne connait pas la réalité Il a été inventé des méthodes qui empêchent la survenue de ces résultats faux positifs Outils statistiques Contrôlent le risque de fausses découvertes dues au hasard Principes méthodologiques Empêchent la survenue de biais
 D’un biais. Fait courir le risque de fausse découverte (résultat faux positif) L’exactitude d’un résultat est impossible à établir. Car on ne connait pas la réalité. Il a été inventé des méthodes qui empêchent la survenue de ces résultats faux positifs. Outils statistiques. Contrôlent le risque de fausses découvertes dues au hasard. Principes méthodologiques. Empêchent la survenue de biais.")
15
Si l’essai a mis en œuvre ces outils
Faible risque de fausses découvertes On aura donc confiance dans le résultat Le résultat est démontré ATTENTION: à juger résultat par résultat Si l’essai n’utilise pas / ou mal ces outils Risque de faux positif inconnu On aura une faible confiance dans le résultat Le résultat est seulement suggéré et non démontré

16
Contrôle satisfaisant du risque de faux positif dus au hasard
Résultat statistiquement significatif (p<0.05) Pas de situation de multiplicité Résultat obtenu sur le CJ principal (défini a priori) Ou approche séquentielle hiérarchique (hiérarchie établie a priori) Résultat non issu d’un sous groupe Résultat non issu d’une analyse intermédiaire non protégée Résultat non issu d’un processus de « pêche à la ligne »
 Pas de situation de multiplicité. Résultat obtenu sur le CJ principal (défini a priori) Ou approche séquentielle hiérarchique (hiérarchie établie a priori) Résultat non issu d’un sous groupe. Résultat non issu d’une analyse intermédiaire non protégée. Résultat non issu d’un processus de « pêche à la ligne »")
17
N Engl J Med 2008;358:

18
The significance level used in the pairwise comparisons between the groups receiving experimental treatment and the group receiving standard treatment was on the basis of the Bonferroni correction for multiple comparisons, corresponding to an overall type I error rate of 0.05.

19
Multiplicité des critères de jugement - Exemple
In women, however (Table 2), a positive effect on BMD was observed at several sites (mostly trabecular bone zones), namely the femoral neck and the Ward’s triangle in the 60–69 y group, and upper and total radius in the 70–79 y group.
, a positive effect on BMD was observed at several sites (mostly trabecular bone zones), namely the femoral neck and the Ward’s. triangle in the 60–69 y group, and upper and total radius in the 70–79 y group.")
20
Lancet 2005; 365: 176–86

21
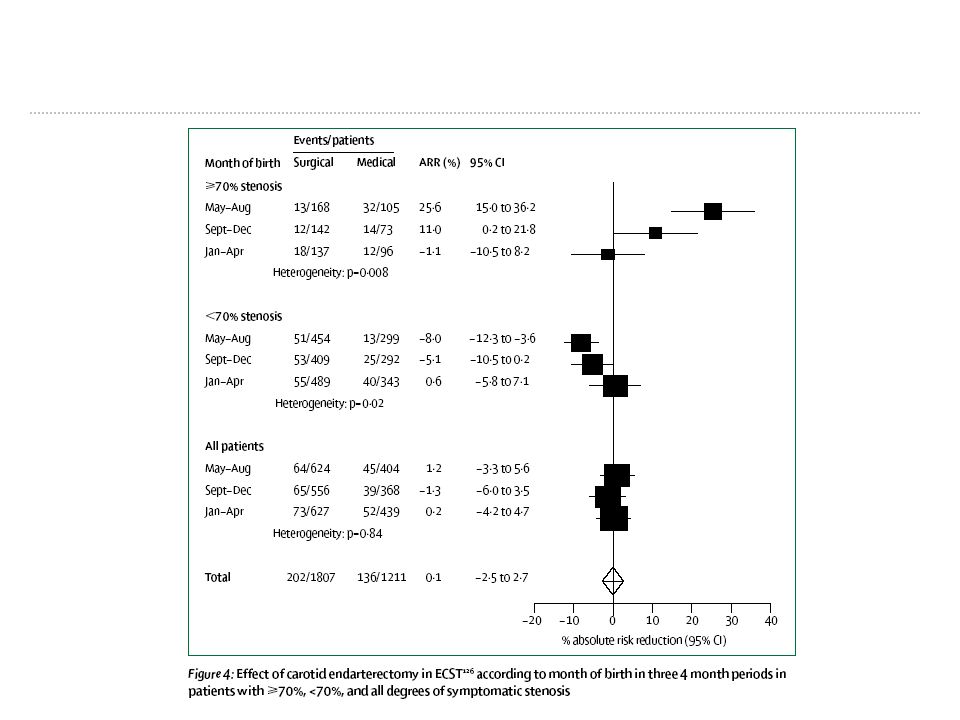
Utilisation des sous groupes – recherche d’une interaction

23
Treatment A -

24
Lancet 2005; 365: 176–86

25
Critère principal Conclusion que si le critère principal est significatif Critères secondaires : explicatifs Trt A

26
Différence non significative
Impossible de conclure Ne pas conclure à l’absence de différence «L’absence de preuve n’est pas la preuve de l’absence» Absence réelle d'effet Résultat non significatif ? Manque de puissance

27
Validité méthodologique
Respect de la démarche hypothetico-déductive Confirmatory study Expérience entreprise spécialement pour tester une hypothèse formulée à priori Résultat post hoc Hypothèse formulée d'après les résultats Vérifiée sur les mêmes données Situation tautologique

30
Introduction

37
Contrôle satisfaisant du risque de faux positif dus de biais
(Prise en compte des facteurs de confusion) Randomisation imprévisible Double aveugle Analyse en ITT avec remplacement des données manquantes
 Randomisation imprévisible. Double aveugle. Analyse en ITT avec remplacement des données manquantes.")
38
Biais Biais Essai biaisé
Le résultat observé peut provenir d’une autre cause que le traitement la méthodologie empêche la survenue de biais Essai biaisé Il existe un défaut dans la méthodologie ou la réalisation qui est susceptible d’entraîner une différence au niveau du critère de jugement, même en l’absence d’effet du traitement Impossible de savoir si un essai est effectivement biaisé déterminer si la méthode utilisée protège contre les biais

39
Exemple de biais patent
Ev. cardiovasculaires Diabétique 15% 6% Traitement 10% Diabétique 45% La différence de fréquence des ev. cardiovasculaires peut provenir de la différence de pronostic et non pas de l’effet traitement Biais potentiel : il y a un défaut dans la méthodologie qui n’empêche pas de sélection les patients dans les groupes

40
Les différents biais Un biais de sélection est évoqué
quand le résultat présenté peut provenir d’une différence dans le pronostic de base des patients Biais de réalisation différence dans le suivi et les soins appliqués aux patients Biais de mesure différence dans l'évaluation du critère de jugement Biais d'attrition différence au niveau des "sorties" d‘analyse

41
Biais de sélection Ce qui met à l’abris de ce biais :
randomisation le processus de randomisation ne doit pas être prévisible par les investigateurs : randomisation centralisée Comment évaluer l’absence de biais en fin d’essai imprévisibilité de la rando (comparabilité des groupes)
")
42
Danger des randomisations prévisibles
hypertension, captopril vs traitement standard par diurétique ou bêta-bloquants patients suivis en moyenne 6,1 ans PA initiale : 166.6/103.6 vs 163.3/101.2 mm Hg, p<0·0001

43
Treatment A Treatment B Treatment C

44
Validation empirique des marqueurs de qualité
Concealment of allocation (inadequate or unclear versus adequate) Schultz 1995 0.66 ( ) Moher 1998 0.63 ( ) Kjaergard 2000 0.60 ( ) // Jüni 2000 0.79 ( ) Combined 0.70 ( ) ROR 0.4 0.5 0.6 0.7 0.8 0.9 1 1.2 1.4 1.6 1.8 2 Jüni et al. BMJ 2001;323:42-46
 Schultz ( ) Moher ( ) Kjaergard ( ) // Jüni ( ) Combined ( ) ROR Jüni et al. BMJ 2001;323:")
45
Biais de suivi Ce qui met à l’abris de ce biais :
le double aveugle Comment évaluer l’absence de biais en fin d’essai: Le double aveugle a-t-il été réellement respecté ? Comparer dans les 2 groupes (et particulièrement si essai en ouvert) : violations de protocole, arrêts de traitements, traitements concomitants…
 : violations de protocole, arrêts de traitements, traitements concomitants…")
46
Biais d’évaluation Ce qui met à l’abris de ce biais :
le double aveugle en cas de double aveugle impossible (essai ouvert) évaluation à l’aveugle choix de critères objectifs
 évaluation à l’aveugle. choix de critères objectifs.")
47
Biais de mesure - mécanisme
Prophylaxie des TVP en chirurgie Les HBPM sont considérés comme plus efficace que l'HNF Subjectivement les TVP sont plus facilement suspectées devant des signes cliniques avec l'HNF Recours à la phlébographie plus facile Sensibilité Incidence réelle Test positif HBPM 70% 10% 7% HNF 90% 10% 9%

48
Biais des études en ouvert
Recherche empirique de biais Pour un domaine donné comparaison des résultats des essais en ouvert au essai en double aveugle calcul du rapport des odds ratio (ROR) Jüni P BMJ 2001;323:42-
 Jüni P BMJ 2001;323:42-")
49
Jüni et al. BMJ 2001;323:42-46

50
Biais d’attrition Situation potentiellement biaisée :
Tous les patients randomisés ne sont pas analysés. Ce qui met à l’abris de ce biais : L’analyse en intention de traiter avec remplacement des données manquantes Comment évaluer l’absence de biais en fin d’essai nb malades analysés / nb malades randomisés robustesse du résultat vis à vis de l’hypothèse de biais maximum

51
Biais d'attrition

52
Treatment A Treatment B

53
Biais maximum

54
MMSE Treatment A

55
Essai contrôlé randomisé en double aveugle
Biais d'attrition ITT Grp T Critère Groupe comparable Randomisation Maintient de la comparabilité Grp C Critère Biais de sélection Biais de réalisation Biais d'évaluation Randomisation Double aveugle

56
Cohérence externe

57
Cohérence externe Concordance avec d’autres essais sur le même domaine : un seul essai ne suffit pas intérêt de la méta-analyse (hétérogénéité ?) Concordance avec les autres connaissances dans le domaine (physiopathologie, épidémiologie, pharmacologie, …) Si toutes les études réalisées vont dans le même sens Cela renforce la confiance que l’on peut avoir dans le résultat
 Concordance avec les autres connaissances dans le domaine (physiopathologie, épidémiologie, pharmacologie, …) Si toutes les études réalisées vont dans le même sens. Cela renforce la confiance que l’on peut avoir dans le résultat.")
58
Un essai de grande taille (1000 patients) montre bien l’efficacité du traitement
 montre bien l’efficacité du traitement")
60
2 essais Conclusion le premier mené en Europe de l’Est est concluant
le second réalisé aux USA est non concluant Conclusion l’effet du traitement n’est pas le même aux USA et en Europe car les contextes de soins sont différents avec un sous traitement en Europe de l’est

62
3 essais ont été réalisés pour évaluer le même traitement
ils sont tous négatifs conclusion : ce traitement n’a pas d’efficacité

64
Pertinence clinique

65
La pertinence clinique du résultat
dépend de : Pertinence du comparateur Pertinence du critère de jugement Pertinence de la taille de l’effet Pertinence des patients étudiés De la balance bénéfice – risque

66
Question cliniquement pertinente
Problème médical réel (et non résolu) FSAD (female sexual arousal disorder) créé de toute pièce en 1997 pour créer une utilisation potentielle du sildenafil BMJ 2003;326:45-47
 FSAD (female sexual arousal disorder) créé de toute pièce en pour créer une utilisation potentielle du sildenafil. BMJ 2003;326:")
67
Traitement du groupe contrôle
Placebo en l’absence de traitement de référence Traitement de référence si déjà validé contre placebo choix acceptable ? traitement optimal (posologie, administration) ? Placebo + traitement de référence 2 groupes contrôles différents si « traitement de référence » mal validé
 Placebo + traitement de référence. 2 groupes contrôles différents si « traitement de référence » mal validé.")
68
Critères de jugement Pertinence du critère principal d’évaluation
Critère clinique Et non pas critère intermédiaire Critères cliniques Critères intermédiaires Critères de substitution succès sur CS succès critère clinique !

69
Exemples fluorure de sodium vs placebo
augmentation de la DO p<0.001 fractures vertébrales 163 vs 136 fractures non vertébrales 72 vs 24 p=0.01

70
Pertinence de l'outil de mesure
Artériopathie des membres inférieurs Mesure du périmètre de marche augmentation significative de 20 m quel est le service médical rendu au patient ? Quel intérêt de passer de 200m à 220m Fréquence du succès fréquence des patients retrouvant sous traitement un périmètre de marche de 500m

71
Pertinence des patients
Voir les critères d’éligibilité Voir la population réellement incluse Généralisation des résultats ? Définition de la maladie Critères actuels Examens couramment disponibles Critères d'exclusion Absence de critères d'exclusion arbitraires : age, sexe Origine géo-ethnique différences génétiques différences environnementales

72
Pertinence de la prise en charge médicale
Circonstances de la "vraie vie" Accès aux soins similaire à celui disponible en dehors d'une étude Durée du suivi pertinente Ni trop long, ni trop court

73
Taille et précision de l’effet thérapeutique
Effet représenté avec un IC à 95 % ? Taille de l’effet : pertinence clinique ? Précision de l’effet : la borne péjorative de l’IC représente le plus petit effet du traitement que l’on ne peut raisonnablement exclure cet effet reste-t-il intéressant cliniquement ?

74
Zone de bénéfice insuffisant

75
Pertinence de la taille
Lancet 2001 Essai DAIS Effet du fénofibrate sur la progression des plaques d'athérosclérose coronarien chez le diabétique fénofibrate vs placebo 731 hommes et femmes suivi 3 ans Résultat ralentissement de la progression des plaques le traitement a réduit de 0.04 mm la diminution du diamètre moyen sur 3 ans (p=0.028) Quid des événement clinique ?
 Quid des événement clinique")
76
Évaluation de la balance bénéfice / risque
Effets indésirables de gravité supérieure à la maladie ? Fréquence des effets indésirables trop importante par rapport au bénéfice ? Comparaison avec les effets indésirables des traitements existants

Présentations similaires





















 Relever les biais discutés. Rechercher d’autres biais non pris en compte dans la discussion et Relever leurs conséquences Dr Marie-Christine.>")
 AUTOMEDICATION Facultés de Médecine Toulouse DCEM4 Module 11 Thérapeutique Générale 2011 – 2012 Service de THERAPEUTIQUE.>")






