Télécharger la présentation
1
Réseaux de neurones artificiels « la rétropropagation du gradient »
S. Canu, laboratoire PSI, INSA de Rouen équipe « systèmes d’information pour l’environnement » asi.insa-rouen.fr/~scanu

2
Histoire … 1940 : La machine de Turing
1943 : Le neurone formel (McCulloch & Pitts) 1948 : Les réseaux d'automates (Von Neuman) 1949 : Première règle d’apprentissage (Hebb) : Le perceptron (Rosenblatt) 1960 : L'adaline (Widrow & Hoff) 1969 : Perceptrons (Minsky & Papert) les limites du Perceptron besoin d'architectures + complexes, Comment effectuer l'apprentissage ? On ne sait pas ! 1974 : Rétropropagation (Werbos) pas de succès !?!?
 1948 : Les réseaux d automates (Von Neuman) 1949 : Première règle d’apprentissage (Hebb) : Le perceptron (Rosenblatt) 1960 : L adaline (Widrow & Hoff) 1969 : Perceptrons (Minsky & Papert) les limites du Perceptron besoin d architectures + complexes, Comment effectuer l apprentissage On ne sait pas ! 1974 : Rétropropagation (Werbos) pas de succès ! !")
3
Histoire … (suite) 1986 : Rétropropagation (Rumelhart & McClelland)
nouvelles architectures de Réseaux de Neurones applications : reconnaissance de l’écriture - reconnaissance/synthèse de la parole - vision (traitement d’images) 1990 : « Société de l’Information » nouvelles applications recherche/filtrage d’information dans le Web - extraction d’information / veille technologique - multimedia (indexation, …) - data mining besoin de combiner différents modèles
 1990 : « Société de l’Information » nouvelles applications - recherche/filtrage d’information dans le Web - extraction d’information / veille technologique - multimedia (indexation, …) - data mining. besoin de combiner différents modèles.")
4
Plan Rappels : Principe de la rétropropagation
Moindres carrés stochastiques Algorithmes de gradient Perceptron Multicouches Principe de la rétropropagation Algorithmes de rétropropagation

5
Moindres carrés « stochastiques » ADALINE (Widrow Hoff 1960)
impossible (’ ! ) méthode itérative : winit Répéter wnew = wold - Tant qu ’il reste des mals classés ou que le coût n’évolue plus Algorithme itératif de gradient
 méthode itérative : winit. Répéter. wnew = wold - Tant qu ’il reste des mals classés ou que le coût n’évolue plus. Algorithme itératif de gradient.")
6
Algorithme de gradient
Illustration dans le plan (w1 ,w2) Minimum du coût Lignes d’iso-coût : J(W) = constante w2 + Direction du gradient J’(W) Le gradient est orthogonal aux lignes d’iso-coût : argument à la « Taylor » w1
 Minimum du coût. Lignes d’iso-coût : J(W) = constante. w2. + Direction du gradient. J’(W) Le gradient est orthogonal aux lignes. d’iso-coût : argument à la « Taylor » w1.")
7
Algorithme de gradient
Illustration dans le plan (J(w),w) : la « descente » de gradient J(w) Direction du gradient J’(W) w Minimum du coût
,w) : la « descente » de gradient. J(w) Direction du gradient. J’(W) w. Minimum du coût.")
8
3 solutions Le gradient : Approximation linéaire (Adaline)
Perceptron : ’=1 Neurone formel : on remplace par une fonction dérivable ex : (x)=th(x) fonction sigmoïde
=th(x) fonction sigmoïde.")
9
Perceptron Multi-Couches
Réseau feedforward (1986) Fonction de transfert tanh(.) (sauf couche de sortie linéaire) Méthode d’apprentissage (supervisé) usuelle : rétropropagation du gradient x1 xi y xn0
 Fonction de transfert tanh(.) (sauf couche de sortie linéaire) Méthode d’apprentissage (supervisé) usuelle : rétropropagation du gradient. x1. xi. y. xn0.")
10
Notations Biais : avec x0=1 W1=[wji] W2=[wkj]
idem pour toutes les couches (ex : PMC à une couche cachée) W1=[wji] W2=[wkj] x0=1 x0 = 1 (1) xi yk wji wkj i=1:n0 j=1:n1 k=1:n2
![Notations Biais : avec x0=1 W1=[wji] W2=[wkj]](http://slideplayer.fr/slide/1288590/3/images/10/Notations+Biais+%3A+avec+x0%3D1+W1%3D%5Bwji%5D+W2%3D%5Bwkj%5D.jpg "idem pour toutes les couches (ex : PMC à une couche cachée) W1=[wji] W2=[wkj] x0=1. x0 = 1. (1) xi. yk. wji. wkj. i=1:n0. j=1:n1. k=1:n2.")
11
Propagation Calcul des sorties du réseau en propageant les valeurs de x de couche en couche : 1 2 1 wji wkj xi yk 2 xj (1) i=1:n0 j=1:n1 k=1:n2
 i=1:n0. j=1:n1. k=1:n2.")
12
Algorithme de propagation
Function y = propag(x,w1,w2) a1 = [x ones(n,1)]*W1; x1 = tanh(a1); a2 = [x1 ones(n,1)]*W2; y = a2; Parallélisé sur les exemples (si x est une matrice, ça marche !)
 a1 = [x ones(n,1)]*W1; x1 = tanh(a1); a2 = [x1 ones(n,1)]*W2; y = a2; Parallélisé sur les exemples. (si x est une matrice, ça marche !)")
13
Calcul de l ’erreur Fonction de coût :
on présente un exemple x=[x1... xn0] (avec ydes sortie désirée) on calcule la sortie correspondante y =[y1... yn2] erreur : coût associé à l ’exemple : coût global :
 on calcule la sortie correspondante y =[y1... yn2] erreur : coût associé à l ’exemple : coût global :")
14
Calcul du gradient Mise à jour de wji et wkj selon une règle delta:
Problème = calcul de et

15
Couche de sortie Calcul de pour un exemple fixé posons wkj yk xj
(1) yk j=1:n1 k=1:n2
 yk. j=1:n1. k=1:n2.")
16
Couche cachée wji Calcul de pour un exemple fixé xi i=1:n0 j=1:n1

17
Algorithme de rétropropagation
Function grad = retropropag(x,yd,w1,w2) ... a1 = [x ones(n,1)]*W1; x1 = tanh(a1); a2 = [x1 ones(n,1)]*W2; y = a2; ERRk = -(yd-y).*(1-y.*y); GradW2 = [x1 ones(n,1)]'* ERRk ; ERRj = (w2(1:n2-1,:)*ERRk')'.*(1-x1.*x1); GradW1 = [x ones(n,1)]'* ERRj ; w1 = w1 - pas1 .* GradW1; w2 = w2 - pas2 .* GradW2;
 ... a1 = [x ones(n,1)]*W1; x1 = tanh(a1); a2 = [x1 ones(n,1)]*W2; y = a2; ERRk = -(yd-y).*(1-y.*y); GradW2 = [x1 ones(n,1)] * ERRk ; ERRj = (w2(1:n2-1,:)*ERRk ) .*(1-x1.*x1); GradW1 = [x ones(n,1)] * ERRj ; w1 = w1 - pas1 .* GradW1; w2 = w2 - pas2 .* GradW2;")
18
Exemple 1/4 x = [0.5 1] ydes = [0.5 1] W1=[ ; ] (pas de biais) W2=[1 1 ; 1 1] x1 (1) x1= 0.5 y1 = a(1)=[ ] x(1)=[ ] a(2)=[ ] y = [ ] x2= 1 y2 = x2 (1) n0=2 n1 =2 n2 =2
![Exemple 1/4 x = [0.5 1] ydes = [0.5 1] W1=[ ; ] (pas de biais) W2=[1 1 ; 1 1]](http://slideplayer.fr/slide/1288590/3/images/18/Exemple+1%2F4+x+%3D+%5B0.5+1%5D+ydes+%3D+%5B0.5+1%5D+W1%3D%5B+%3B+%5D+%28pas+de+biais%29+W2%3D%5B1+1+%3B+1+1%5D.jpg "x1. (1) x1= 0.5. y1 = a(1)=[ ] x(1)=[ ] a(2)=[ ] y = [ ] x2= 1. y2 = x2. (1) n0=2. n1 =2. n2 =2.")
19
Exemple 2/4 ERRk = [ ] GradW2 = [ ; ] ERRj = [ ] GradW1 =[ ; ] x1 (1) err1 = x1= 0.5 x2= 1 err2 = x2 (1) n0=2 n1 =2 n2 =2
![Exemple 2/4 ERRk = [ ] GradW2 = [ ; ] ERRj = [ ] GradW1 =[ ; ]](http://slideplayer.fr/slide/1288590/3/images/19/Exemple+2%2F4+ERRk+%3D+%5B+%5D+GradW2+%3D+%5B+%3B+%5D+ERRj+%3D+%5B+%5D+GradW1+%3D%5B+%3B+%5D.jpg "x1. (1) err1 = x1= 0.5. x2= 1. err2 = x2. (1) n0=2. n1 =2. n2 =2.")
20
Exemple 3/4 MAJ de W1 et W2 Nouvelle propagation, etc...
y = [ ] x1 (1) y1 = x1= 0.5 x2= 1 y2 = x2 (1) n0=2 n1 =2 n2 =2
 y1 = x1= 0.5. x2= 1. y2 = x2. (1) n0=2. n1 =2. n2 =2.")
21
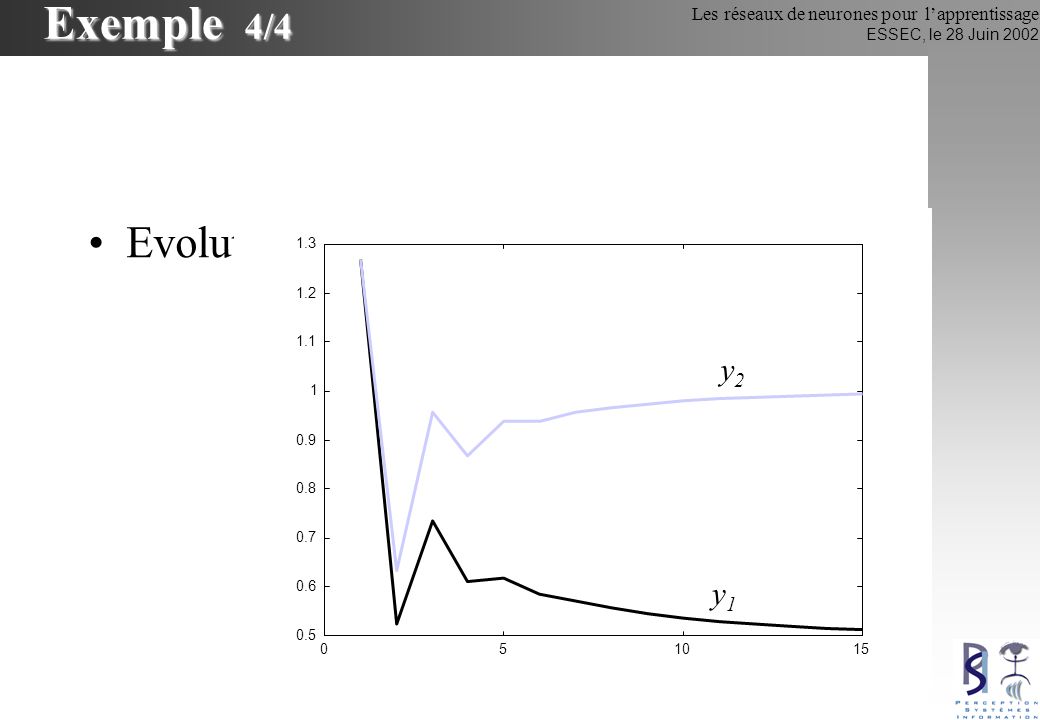
Exemple 4/4 Evolution de y1 et y2 y2 y1 1.3 1.2 1.1 1 0.9 0.8 0.7 0.6
0.5 5 10 15
22
Gradient batch / séquentiel
2 façons d ’appliquer l’algorithme de rétropropagation : « batch » : mise à jour des poids après la présentation de tous les exemples calculs et stockage plus lourds si trop d ’exemples séquentiel : (on-line, stochastique) mise à jour des poids après chaque exemple besoin de tirer l ’exemple au hasard problèmes de convergence
 mise à jour des poids après chaque exemple. besoin de tirer l ’exemple au hasard. problèmes de convergence.")
23
Gradient batch / séquentiel
2 façons d ’appliquer l’algorithme de rétropropagation : « batch » : mise à jour des poids après la présentation de tous les exemples calculs et stockage plus lourds si trop d ’exemples séquentiel : (on-line, stochastique) mise à jour des poids après chaque exemple besoin de tirer l ’exemple au hasard problèmes de convergence Moins de 5000 exemples, Matlab plus de 5000 exemples SNNS, SN, du C
 mise à jour des poids après chaque exemple. besoin de tirer l ’exemple au hasard. problèmes de convergence. Moins de 5000 exemples, Matlab. plus de 5000 exemples. SNNS, SN, du C.")
24
Pas d’apprentissage Pas d’apprentissage : heuristiques courantes :
trop petit = convergence « lente » vers la solution trop grand = risque d’oscillations… heuristiques courantes : diminuer le pas d’apprentissage au fur et a mesure « à la main » en fonction de la forme de la surface d ’erreur approximations : premier ordre Rétropropagation avec un moment d’inertie Delta-Bar-Delta, Rprop, ... second ordre Quickprop Levenberg Marquard

25
Premier ordre 1/2 Moment d’inertie (Rumelhart et al. 1986)
avec ||<1 Delta-Bar-Delta (Jacobs 1988) calcul d ’un « gradient moyen » modification du pas d’apprentissage selon la direction du gradient par rapport au gradient moyen on accélère on freine
 calcul d ’un « gradient moyen » modification du pas d’apprentissage selon la direction du gradient par rapport au gradient moyen. on accélère. on freine.")
26
Premier ordre 2/2 Rprop (Riedmiller and Braun 1993)
modification du pas d’apprentissage selon la direction du gradient par rapport au gradient précédent on borne le pas d ’apprentissage un poids n’est modifié que s ’il va « dans le bon sens » on accélère on freine

27
Second ordre 1/2 Développement de Taylor de la fonction de coût :
H = matrice Hessienne, « le Hessien » de du coût Calcul du gradient : on cherche h / le gradient soit nul Problème = calcul de H-1

28
Second ordre 2/2 Approximation du Hessien :
hessien = matrice diagonale Quickprop (Fahlman 1988) on évite de calculer H Il existe d’autres méthodes qui calculent (partiellement) les informations du 2nd ordre méthodes de gradient conjugué
 on évite de calculer H. Il existe d’autres méthodes qui calculent (partiellement) les informations du 2nd ordre. méthodes de gradient conjugué.")
29
Conclusion La rétropropagation est une méthode de gradient
on a un problème d’optimisation à résoudre,… …. Et tous les coups sont bon ! On a un problème d’optimisation non linéaire convexe si la fonction coût est quadratique Soft : matlab (petits problèmes) - SN (gros problèmes)
 - SN (gros problèmes)")
30
Bibliographie Neural Networks : a comprehensive foundation - S. Haykin (Prenctice Hall) Neural Networks : a systematic introduction R. Rojas (Springer) The Handbook of Brain Theory and Neural Networks - M.A. Arbib (MIT Press) Self-Organizing Maps - T. Kohonen (Springer) Réseaux Neuronaux et Traitement du Signal - J. Hérault & C. Jutten (Hermès) Backpropagator ’s review : des informations sur la rétropropagation un petit tutoriel :
 The Handbook of Brain Theory and Neural Networks - M.A. Arbib (MIT Press) Self-Organizing Maps - T. Kohonen (Springer) Réseaux Neuronaux et Traitement du Signal - J. Hérault & C. Jutten (Hermès) Backpropagator ’s review : des informations sur la rétropropagation. un petit tutoriel :")










 J. Brajard, A. Chazottes, M. Crépon, C.>")









