Télécharger la présentation
1
ELEMENTS DE COURS 1. LERIDON H., TOULEMON L. (1997) – Démographie. Approche Statistiques et dynamique des populations. Paris, Economica. 2. FALISSARD B. (2005) Comprendre et utiliser les statistiques dans les sciences de la vie. Masson (3ème Edition) 3. TOULEMON L. (1995) Régression logistique et régression sur les risques. Documents de travail n°46 - INED
 Comprendre et utiliser les statistiques dans les sciences de la vie. Masson (3ème Edition) 3. TOULEMON L. (1995) Régression logistique et régression sur les risques. Documents de travail n°46 - INED.")
2
2. Un outil de standardisation
Pourquoi un enseignement de régression logistique en Master 1 de démographie ? 1. Outil de plus en plus courant en sciences humaines et sociales et utilisé par les démographes 2. Un outil de standardisation Raisonnement «toutes choses égales par ailleurs » 3. Typique des modèles de régression multivariées

3
Principes des modèles de régression
Une variable Y que l’on cherche à expliquer … Elle est dite « à expliquer », « dépendante » « endogène » … par des variables X. Elle sont dites : « explicatives », « indépendantes » « exogènes»

4
Modèles qui varient selon la nature de la variable à expliquer
Si la variable à expliquer est quantitative continue : La régression suit un modèle linéaire Si la variable à expliquer est dichotomique ou multinominale La régression suit un modèle dit « logistique » ou « log-linéaire »

5
Régression logistique : quel lien avec l’analyse démographique (1)
En analyse démographique, on étudie classiquement : l’arrivée d’un événement dans une population à différentes durées ou encore le risque couru par des individus d’une population donnée de connaître un événement donné. La mesure de l’intensité d’un phénomène à événement renouvelable se mesure par un nombre moyen d’événements connus par un individu à une durée donnée…. …. Ce nombre moyen peut être la variable « à expliquer », quantitative continue à expliquer. Dans ce cas utilisation d’un modèle linéaire MAIS ATTENTION UNE DIFFERENCE FONDAMENTALE : Un des buts de l’analyse démographique est de mesurer une intensité en l’absence de phénomène perturbateur ce que ne permet en rien la régression logistique.

6
Régression logistique : quel lien avec l’analyse démographique (2)
Si le phénomène étudié se manifeste par un événement non renouvelable : La mesure de l’intensité d’un phénomène à événement non renouvelable se mesure par une proportion…. …. proportion de personne qui est dans un état donné ou qui a connu un événement donné à une durée donnée Derrière la notion « Être ou non dans un état » peut se lire une variable Y Indicatrice (1 ou 0) que l’on chercher à expliquer. D’où l’utilité d’une régression logistique MAIS ATTENTION UNE DIIFERENCE FONDAMENTALE : Un des buts de l’analyse démographique est de mesurer une intensité en l’absence de phénomène perturbateur ce que ne permet en rien la régression logistique.
 que l’on chercher à expliquer. D’où l’utilité d’une régression logistique. MAIS ATTENTION UNE DIIFERENCE FONDAMENTALE : Un des buts de l’analyse démographique est de mesurer une intensité en l’absence de phénomène perturbateur ce que ne permet en rien la régression logistique.")
7
L’intérêt de l’approche multivariée (1)
Pour juger de la corrélation entre deux variables vous savez : Si 2 variables qualitaties : utiliser le test du Khi-2 Si 2 variables quantitatives : utiliser la régression et corrélation linéaire (R²) Possible de multiplier les croisements de couples de variables connues MAIS : Risques d’interprétations erronées Jamais un raisonnement « toutes choses égales par ailleurs »
 Possible de multiplier les croisements de couples de variables connues MAIS : Risques d’interprétations erronées. Jamais un raisonnement « toutes choses égales par ailleurs »")
8
L’intérêt de l’approche multivariée (2)
La régression multivariée permet : de démêler l’impact des différentes caractéristiques d’un individu sur son comportement de repérer quelles variables sont les plus influentes, « toutes choses égales par ailleurs », sur la probabilité , de survenue d’un phénomène étudié d’être/avoir telle ou telle caractéristique.

9
La notion d’échelle de mesure
Il existe au moins 4 échelles de mesure pour comparer des valeurs. Nous traiterons ici de(s) l’échelle additive (linéaire), Les échelles multiplicatives L’échelle logistique OBJECTIF : décrire et comprendre la logique et les propriétés de l’échelle logistique
 l’échelle additive (linéaire), Les échelles multiplicatives. L’échelle logistique. OBJECTIF : décrire et comprendre la logique et les propriétés de l’échelle logistique.")
10
Année de naissance des enfants
L’exemple Comment mesurer l’évolution des inégalités sociales devant l’école ? Année de naissance des enfants Proportion de bacheliers selon la profession du père et l’année de naissance Cadre 35 % 50 % Manœuvre 4 % 8 % Source : Laurent Toulemon, Dossiers et Recherches n°46, Ined, 1995.

11
Année de naissance des enfants
Proportion de bacheliers selon la profession du père et l’année de naissance Cadre 35 % 50 % Manœuvre 4 % 8 % Source : Laurent Toulemon, Dossiers et Recherches n°46, Ined, 1995. Trois dimensions dans ce tableau L’origine sociale La génération L’accès aux études Quelles conclusions ? 1 – Inégalité quelle que soit la génération 2 – Augmentation de la réussite quelle que soit l’origine sociale

12
Mais qu’en est-il de l’évolution des inégalités ?
Ont-elles augmenté ou diminué ? La proportion de bacheliers a-t-elle davantage augmenté chez les enfants de cadres que chez les enfants de manœuvres ? Il faut pour cela comparer les « distances » entre : 4% par rapport à 35% = inégalité pour la 1ère génération 8% par rapport à 50% = inégalité pour la 2ème génération

13
Le raisonnement est le suivant
Quelle serait la proportion p* de fils de cadres bacheliers dans la génération 1915 qui correspondrait à une inégalité constante, les trois autres proportions restant inchangées ? Ensuite on compare cette proportion p* à p, celle observée dans la réalité (c'est-à-dire 50%=p) Cas 1 : p* >p. L’inégalité a. diminué Cas 2 : p* <p. L’inégalité a augmenté. Cas 2 : p* = p. L’inégalité est stable Suivant l’ l’échelle que l’on va choisir on va observer des valeurs de p* différentes et on arrive à des conclusions contradictoires.
 Cas 1 : p* >p. L’inégalité a. diminué. Cas 2 : p* <p. L’inégalité a augmenté. Cas 2 : p* = p. L’inégalité est stable. Suivant l’ l’échelle que l’on va choisir on va observer des valeurs de p* différentes et on arrive à des conclusions contradictoires.")
14
Posons le problème Soit « X » la propension à obtenir son Bac dans la population La relation entre p et X est positive Quand la propension X augmente, « p » augmente La relation s’écrit p = f(X) Si l’inégalité entre les deux groupes est constante alors f(X1) = f(X2) à une date « t » donnée. Avec X1 la propension pour les enfants de cadres et X2 pour les enfants de manœuvres
 Si l’inégalité entre les deux groupes est constante alors f(X1) = f(X2) à une date « t » donnée. Avec X1 la propension pour les enfants de cadres et X2 pour les enfants de manœuvres.")
15
Si on retient une échelle additive
« a » est positif La relation s’écrit p = f(X)
")
16
Echelle additive

17
Si pas d’inégalité croissante, alors
Devient Si a = 1 et b=0 Et Si pas d’inégalité croissante, alors p* = 35% + (8% - 4%) P* = 39,0%
 P* = 39,0%")
18
Echelle multiplicative

19
Si on retient une échelle multiplicative
Posons pour simplifier a = 1 et b=0

20
Si pas d’inégalité croissante, alors
OU BIEN Soit : p* = 70,0%

21
Echelle multiplicative en (1-p)
")
22
Si on retient une échelle multiplicative en (1-p)
Posons pour simplifier a = 1 et b=0

23
Si pas d’inégalité croissante, alors
Soit : 1-p*= 62,3% p* = 37,7%

24
Finalement La comparaison sur une échelle additive est adaptée si les proportions sont moyennes La comparaison sur une échelle multiplicative est adaptée si les proportions sont faibles (phénomènes rares) La comparaison sur une échelle multiplicative en (1-p) est adaptée si les proportions sont fortes (phénomènes fréquents)
 La comparaison sur une échelle multiplicative en (1-p) est adaptée si les proportions sont fortes (phénomènes fréquents)")
25
Si les proportions varient sur un large spectre
C’est l’échelle logistique qui permettra de comparer des évolutions entre proportions. C’est le cas dans notre exemple.

26
Echelle logistique

27
Si on retient une échelle logistique

28
La différence entre X2 et X1 est appelée contraste logistique entre p2 et p1
en anglais : ln(odds- ratio), appelée « α » et… l’exponentielle du contraste logistique est ce que l’on appelle l’ODDS-Ratio .
, appelée « α » et… l’exponentielle du contraste logistique est ce que l’on appelle l’ODDS-Ratio .")
29
Si pas d’inégalité croissante, alors

30
P*= 52,9%

31
Finalement (proportions en %) Valeur théorique Comparaison
Modèle (échelle) p* p<p* Additif Multiplicatif Multiplicatif en 1-p Logistique 39,0% 70,0% 37,7% 52,9% Non Oui Valeur réelle (p) 50,0% - L’échelle logistique ou log linéaire permet de comparer des pourcentage pour toutes les valeurs de l’échelle de mesure : très faible comme l’échelle multiplicative, moyens comme l’échelle additive et très élevée comme l’échelle multiplicative de (1-p).
 p* p<p* Additif. Multiplicatif. Multiplicatif en 1-p. Logistique. 39,0% 70,0% 37,7% 52,9% Non. Oui. Valeur réelle (p) 50,0% - L’échelle logistique ou log linéaire permet de comparer des pourcentage pour toutes les valeurs de l’échelle de mesure : très faible comme l’échelle multiplicative, moyens comme l’échelle additive et très élevée comme l’échelle multiplicative de (1-p).")
32
La notion d’odds-ratio
Dans le cas de l’étude des variables dichotomiques suivantes tirées d’une enquête auprès de femmes âgées de 25 ans : le fait d’être ou non déjà mère le fait de vivre ou non en couple Être mère Oui Non Vie en couple 115 (A) 142 (B) Ne vit pas en couple 19 (C) 131(D)
 142 (B) Ne vit pas en couple. 19 (C) 131(D)")
33
La notion d’odds-ratio
Être mère Oui Non Vie en couple 115 142 Ne vit pas en couple 19 131 Interprétation : A 25 ans, il y a 5,6 fois plus de mères par rapports à des non mères chez les jeunes femmes en couple que de mère par rapport aux non mères chez celles ne vivant pas en couple.

34
Notion proche : le risque relatif
Être mère Oui Non Vie en couple 115 142 Ne vit pas en couple 19 131 Interprétation : Le « risque » ou la probabilité d’être mère est 3,5 fois plus fort si on est en couple que si on ne l’ai pas.

35
La notion de modèle (1) On postule qu’il existe une relation (corrélation) entre la valeur de la variable Y « à expliquer » et les valeurs des variables X explicatives. Cette relation prend la forme d’un relation mathématique (modèle) dont on doit choisir la forme : linéaire, logistique,… Cette relation s’écrit comme ceci : Yi = f (X1, X2, X2, …., Xk) Avec : Les Xi sont les valeurs observées pour les variables Xi La valeur de Yi est celle estimée par le modèle.
 entre la valeur de la variable Y « à expliquer » et les valeurs des variables X explicatives. Cette relation prend la forme d’un relation mathématique (modèle) dont on doit choisir la forme : linéaire, logistique,… Cette relation s’écrit comme ceci : Yi = f (X1, X2, X2, …., Xk) Avec : Les Xi sont les valeurs observées pour les variables Xi. La valeur de Yi est celle estimée par le modèle.")
36
La notion de modèle (2) Trois notions centrales REGRESSION, PREDICTION
La construction d’un modèle consiste à déterminer, selon une relation mathématique les coefficients ou paramètres a attribuer à chacune des variables explicatives « Xi » tel que La distance totale entre les valeurs observées et les valeurs théoriques soit minimum : on parle d’ajustement. Trois notions centrales REGRESSION, PREDICTION AJUSTEMENT TEST

37
La régression (linéaire)
Considérons 3 variables (Y, X1 et X2) observées auprès d’individus d’un échantillon de taille n leurs valeurs sont notées (yi, x1i, x2i) pour « i » allant de 1 à n. Effectuer une régression linéaire de « Y » à partir de X1 et X2 c’est : 1- rechercher a0, a1,et a2 tels que
 observées auprès d’individus d’un échantillon de taille n. leurs valeurs sont notées (yi, x1i, x2i) pour « i » allant de 1 à n. Effectuer une régression linéaire de « Y » à partir de X1 et X2 c’est : 1- rechercher a0, a1,et a2 tels que.")
38
La régression (linéaire)
et Avec « ei » le résidu. La série des « ai » est obtenue à partir d’un algorithme sous la contrainte de minimiser le terme suivant :

39
Le cas particulier de la régression logistique
La régression logistique combine les avantages de l’échelle logistique et de la régression. Il s’agit de généraliser la notion d’odds-ratio et de test de chi-2 qui permettent de juger de la dépendance entre variables qualitative ou binaires.

40
Le cas particulier de la régression logistique
Soit « Y » la variable dépendante. Chaque individu a pour valeur soit 1, soit 0 selon qu’il est ou non la caractéristique étudiée ou qu’il soit ou non dans l’état étudié. Nombreux exemples en démographie Parmi les variables que l’on cherche à expliquer : La probabilité d’avoir ou non un troisième enfant, de vouloir ou non un troisième enfant. La probabilité de voir son père ou/et sa mère au moins une fois par semaine La probabilité d’utiliser un moyen de contraception dit moderne La probabilité d’avoir eu un enfant avant 25 ans La probabilité de vivre en couple.

41
La mise en place de la régression logistique
Soit « pi » la probabilité pour que Y=1 pour l’individu «i». Au lieu d’utiliser un modèle linéaire qui donnerait des valeurs estimées à l’extérieur des bornes acceptables pour une probabilité [0 ;1], nous utilisons un modèle logit.

42
La mise en place de la régression logistique
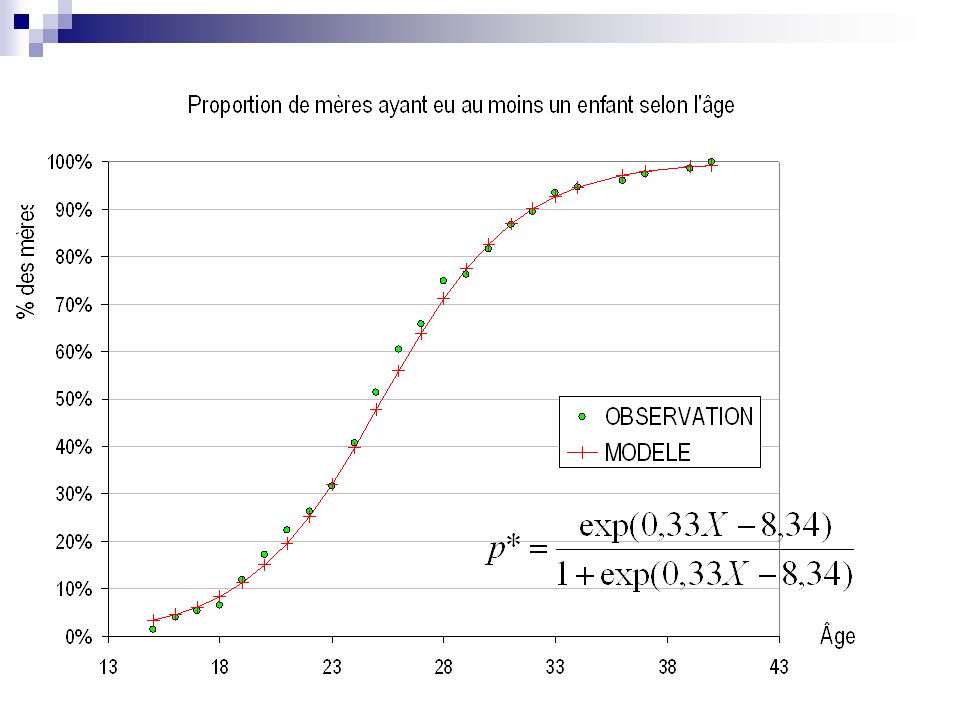
Exemple : Y une variable telle que : Y=1 si la femme a un enfant Y=0 sinon On observe les réponses des 76 femmes de la génération A chaque âge compris entre 15 et 40 ans elles ont deux états possibles : 1 ou 0. On veut ajuster la variable proportion de femmes mères selon l’âge de celles ci avec une équation.

43
Les premières naissances dans la génération 1960 – France – Enquête ERFI ( n=76)
")
44
Les premières naissances dans la génération 1960 – France – Enquête ERFI ( n=76)
")
45
xi 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 36 37 39 40 fi 1% 4% 5% 7% 12% 17% 22% 26% 32% 41% 51% 61% 66% 75% 76% 82% 87% 89% 93% 95% 96% 97% 99% 100%

46
La mise en place de la régression logistique
Il s’agit de déterminer l’équation de la droite qui ajuste le mieux les points (xi, fi). Avec xi = âge Et fi = proportion de mère à l’âge i Au lieu d’utiliser un modèle linéaire (ajustement par une droite) -qui donnerait des valeurs estimées à l’extérieur des bornes acceptables pour une probabilité [0;1] – nous utiliserons un modèle logit.
. Avec xi = âge. Et fi = proportion de mère à l’âge i. Au lieu d’utiliser un modèle linéaire (ajustement par une droite) -qui donnerait des valeurs estimées à l’extérieur des bornes acceptables pour une probabilité [0;1] – nous utiliserons un modèle logit.")
47
Les équations de la régression logistique – une seule variable
Soit : la probabilité que Y=1 si xi=X d’après le modèle Et :

48
Les résultats donnés par SAS
Parameter DF Estimate Error Chi-Square Pr > ChiSq Intercept <.0001 Age <.0001

49
Les résultats donnés par SAS
Age Observé Calculé 15 1,3% 3,3% 16 3,9% 4,5% 17 5,3% 6,1% 18 6,6% 8,3% 19 11,8% 11,2% 34 94,7% 36 96,1% 97,2% 37 97,4% 98,0% 39 98,7% 98,9% 40 100,0% 99,2%

51
Généralisation du modèle logistique
La valeur de «pi» varie selon les valeurs prises par les différentes variables indépendantes synthétisées par un vecteur X selon la relation (équation) de la forme logistique suivante :
 de la forme logistique suivante :")
52
β est un vecteur qui contient les paramètres estimés du modèle.
Le vecteur X contient : La constante du modèle. Elle ne varie pas d’un individu à un autre Un ensemble de valeur pour les variables explicatives du modèle. Ces valeurs peuvent être continues, discrètes ou qualitatives à deux ou plusieurs modalités. Ce sont des valeurs observées. β est un vecteur qui contient les paramètres estimés du modèle.

53
La prévision et l’ajustement
Une fois la relation (équation de l’ajustement) établie, on peut : 1- Prédire la valeur de Yi pour un individu statistique dont on ne connaît que les valeurs de X1 et X2 = établir des prévisions 2- Juger de la relation entre Y et X1 si X2 est constant. Donc permet de juger de la force de la corrélation entre Y et X1, toutes choses, prises en compte par le modèle, égales par ailleurs. On parle d’ajustement de Y sur X2 ATTENTION : 1- Le modèle n’est valable que pour les variables et le contexte (population) considéré DONC attention aux prévisions si on oubli un éléments de prévisions important. 2- Le modèle ne donnera une bonne prévision que pour une proportion d’individus. Plus cette proportion s’approche de 1, plus le modèle va être considéré comme bon.
 établie, on peut : 1- Prédire la valeur de Yi pour un individu statistique dont on ne connaît que les valeurs de X1 et X2. = établir des prévisions. 2- Juger de la relation entre Y et X1 si X2 est constant. Donc permet de juger de la force de la corrélation entre Y et X1, toutes choses, prises en compte par le modèle, égales par ailleurs. On parle d’ajustement de Y sur X2. ATTENTION : 1- Le modèle n’est valable que pour les variables et le contexte (population) considéré DONC attention aux prévisions si on oubli un éléments de prévisions important. 2- Le modèle ne donnera une bonne prévision que pour une proportion d’individus. Plus cette proportion s’approche de 1, plus le modèle va être considéré comme bon.")
54
Le test Lorsque l’on veut tester la liaison entre une variable Y quantitative et une variable X1 avec un ajustement sur les variables X2, X3, …., Xp, Le test va porter sur le coefficient « a1 », appelé aussi paramètre, de la régression de la forme Le test est le suivant : H0 : a1 =0 / : a1 <>0

55
Les hypothèses la normalité des résidus « ei ».
L’indépendance de var(« ei ») avec yi et les xj L’indépendance des « ei » avec chacune des variables.
 avec yi et les xj. L’indépendance des « ei » avec chacune des variables.")
56
La robustesse du modèle
La robustesse du modèle est forte si le fait d’enlever une observation fait peu varier les valeurs estimées des paramètres « ai » Les individus qui font le plus varier les valeurs des paramètres doivent être alors discutés après avoir été repérés.

57
Les problèmes de colinéarité
Certaines variables explicatives peuvent être corrélées. La qualité du modèle en sera affectée. Si une des variables est une combinaison linéaire d’autres variables, le modèle devient indéterminé. Par exemple la superficie, la population et la densité densité pour expliquer par exemple le taux de criminalité dans un pays. Il s’agit d’une situation de colinéarité. Dans le moindre doute, il faut retirer une des variables associées du modèle. Il est prudent de tester préalablement au modèle l’ensemble des relations entre les variables 2 par 2.

58
Exercice application 1 Exposition E =1 E=0 M = 1 90 M= 0 450 900
Calculer P(M=1/E=1) ; P(M=0/E=1) ; P(M=1/E=0) ; P(M=0/E=0) Sachant que Odds-ratio = exp( ). Déterminer la valeur de du modèle. Déterminer la valeur de la constante du modèle sachant qu’elle vaut g(Y=1/X=0) 3) Donner l’équation du modèle qui permet de décrire le risque de la maladie M en fonction de l’exposition de E. 4) À partir du modèle logistique décrit en 3) recalculez les différentes probabilités décrites en 1).
 ; P(M=0/E=1) ; P(M=1/E=0) ; P(M=0/E=0) Sachant que Odds-ratio = exp( ). Déterminer la valeur de du modèle. Déterminer la valeur de la constante du modèle sachant qu’elle vaut g(Y=1/X=0) 3) Donner l’équation du modèle qui permet de décrire le risque de la maladie M en fonction de l’exposition de E. 4) À partir du modèle logistique décrit en 3) recalculez les différentes probabilités décrites en 1).")
59
Exercice application 1 Exposition E =1 E=0 M = 1 90 M= 0 450 900
Calculer P(M=1/E=1) ; P(M=0/E=1) ; P(M=1/E=0) ; P(M=0/E=0)
 ; P(M=0/E=1) ; P(M=1/E=0) ; P(M=0/E=0)")
60
Exercice application 1 Exposition E =1 E=0 M = 1 90 M= 0 450 900
1) Sachant que Odds-ratio = exp( ). Déterminer la valeur de du modèle. 2) Déterminer la valeur de la constante du modèle sachant qu’elle vaut g(X=0) 3) Donner l’équation du modèle qui permet de décrire le risque de la maladie M en fonction de l’exposition de E.
 Sachant que Odds-ratio = exp( ). Déterminer la valeur de du modèle. 2) Déterminer la valeur de la constante du modèle sachant qu’elle vaut g(X=0) 3) Donner l’équation du modèle qui permet de décrire le risque de la maladie M en fonction de l’exposition de E.")
61
Parameter DF Estimate Error Chi-Square Pr > ChiSq
Intercept <.0001 E <.0001 Odds Ratio Estimates Point % Wald Effect Estimate Confidence Limits E Association of Predicted Probabilities and Observed Responses Percent Concordant Somers' D Percent Discordant Gamma Percent Tied Tau-a


 r =>")


















