Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
du génome aux protéomes « in silico »
Bioinformatique Institut Suisse de Bioinformatique Groupe Swiss-Prot novembre 2004

2
La bioinformatique, c’est quoi ?
L’utilisation de l’informatique pour l’analyse de l’ADN et des protéines de tous les êtres vivants.

3
Acquérir puis stocker les informations biologiques sous la forme d’encyclopédies appelées bases de données; Développer des programmes de prédiction et d’analyse en utilisant les informations contenues dans les bases de données; Analyser/Interpréter/Prédire: utiliser ces programmes pour analyser de ‘nouvelles’ données biologiques et prédire in silico par exemple la fonction potentielle d’une protéine; Visualiser: développer des programmes pour visualiser la structure en trois dimensions des protéines et de l’ADN, pour shématiser des voies métaboliques ou des arbres phylogénétiques.

4
Bioinformatique - application 1: acquisition de données
Exemples: lecture d’images de gels 2D, spectrométrie de masse (MS), séquençage ADN... Détection de signaux ou d’images Absence de contexte biologique.
, séquençage ADN... Détection de signaux ou d’images. Absence de contexte biologique.")
5
Informatique instrumentale
Séquençage d’ADN Informatique instrumentale Programme pour analyser les données d’un séquenceur ADN Exemple: pregap4 de Rodger Staden

6
Bioinformatique - application 2: Assemblage des séquences d’ADN
Nature 409, (2001) Les méthodes actuelles de séquençage ne permettent pas d’obtenir des séquences fiables de plus de 1000 bp !
 Les méthodes actuelles de séquençage ne permettent pas d’obtenir des séquences fiables de plus de 1000 bp !")
7
Bioinformatique - application 2: Assemblage des séquences d’ADN
-> Reconstruire la séquence complète d’un génome ou d’un morceau de chromosome (« contig ») à partir de séquences de 1000 bp; Pas du tout trivial parce que: (a) il y a des erreurs de séquence; (b) il y a des régions répétitives. Chromosome Y trop de répétition: impossible de séquencer plusieurs individus (différences repeat polymorphismes) “Celera-generated shotgun data set consisted of 27 million sequencing reads …” Whole-genome shotgun assembly and comparison of human genome assemblies. PNAS 101(7): (2004)
 à partir de séquences de 1000 bp; Pas du tout trivial parce que: (a) il y a des erreurs de séquence; (b) il y a des régions répétitives. Chromosome Y trop de répétition: impossible de séquencer plusieurs individus (différences repeat polymorphismes) Celera-generated shotgun data set consisted of 27 million sequencing reads … Whole-genome shotgun assembly and comparison of human genome assemblies. PNAS 101(7): (2004)")
8
2.7 milliards de $ (coût en 2000)
CCCCTGACGACCGATTCAAAAACCACTTTCCTCTTTTACGGCGCCCTAGCGCTATGGCGGTGAAGACTGCTTGACATTAACATGCCTGTTGAGGCTAGAGAATCCATGCGAAGGCGGTTCGGAAACTGCTTCGAAGGCGTGGGGTGGTGCGGGGGGTGGGATTTGAACCCACGCAGGCCTACGCCATCGGGTCCTAAGCCCGACCCCTTTGGCCAGGCTCGGGCACCCCCGCACCGTGTAGTCTTTAGGTTTAGCTTTCAGGGTTAAAACGGTTTAACACTCATGAGTATCACTGGGCTGGCTGTGACTGGGCTCTGCATTCCCGAGGCCATGCTGCCCGTGAGGAATAACGGGTCTGAGGAGCCGTTGACAGGTTGCCATTTGGCCTTGCCCCCAAAAGTGATGCTGTGGATCACGACCTCCTCGGAGGAGGGGAGCCTCAGCATACACTTTATAATGAAGGCTTTAAGGGTTTAGCCGGATAATGTTGTTGGGGCGTGCAGCGGCAAGTGCTGCAGCTCATGGGTATGGTATGCGGCTTTGCCTGGTGATGCGGTTTGGCCCCCGTTGTCTGCGACGTCTGCGGTGTTAGGAGGGCTGTGGTGCTGCAGCGCCACACGGGAAGGCGGCTCTGCAGGGAGTGCTTTAGGGAGGATATAGTGGGGAGGGTCAGGAGGGAGGTTGAGAGGTGGGGGATGATAGGCCCTGGGGAGACGGTCCTCCTAGGCCTGAGCGGCGGTAAGGACAGCTATGTCCTGCTGGACGCCCTCTCCGAGATAGTCGGGCCCTCGAGGCTGGTGGCGGTGTCTATAGTGGAGGGCATACCGGGGTACAACAGGGAGGGAGATATCGAGAAGATCAGGAGGGTGGCCGCGGCTAGGGGCGTCGACGTGATAGTGACGAGCATAAGGGAGTACGTGGGGGCCAGCCTCTATGAGATATACTCCAGGGCCCGAGGGAGGGGGGCGGGCCACGCCGCCTGCACCTACTGCGGCATAAGCAGGAGGAGGATACTTGCCCTCTACGCCCGCCTCTACGGCGCCCACAAGGTCGCTACGGCCCACAACCTCGACGACGAGGCGCAGACAGCTATAGTGAACTTCCTCAGGGGGGACTGGGTTGGCATGCTGAAAACACACCCCCTCTACAGGAGCGGGGGCGAGGACCTGGTTCCAAGGATAAAGCCTCTTAGGAAAGTCTACGAGTGGGAGACGGCCAGCTACGTGGTACTCCACCGCTACCCCATCCAGGAGGCTGAATGCCCCTTCATAAACATGAACCCAACCCTCAGGGCGAGGGTGAGGACGGCCCTGAGGGTGCTAGAGGAGAGGAGCCCGGGCACCCTGCTCAGGATGATGGAGAGGCTCGACGAGGAGCTGAGGCCGCTGGCCCAGGCCATGAAGCCCTCCTCCCTAGGCAGGTGCGAGAGATGCGGGGAGCCGACCAGCCCGAAGAGGAGGCTCTGCAAGCTCTGCGAGCTCCTGGAGGAGGCCGGGTTCCAGGAGCCCATCTACGCGATCGCAGGGAGAGGCAAGAGATTAAGGCTTCAGAGCCCCACCGCTAGCCCTGGGTGAACGCGCTATGGCAAAGCCAAAGGTTAGCCTGCCGGAGGATGTGGAGCCCCCCAAGGCTATAGTCAAGAAGCCTAGGCTAGTGAAGCTAGGCCCCGTAGACCCGGGGGTCAGGAGGGGAAGGGGGTTCAGCCTAGGCGAGCTCGCGGAGGCTGGGCTAGACGCTAAAAAGGCGAGGAAGCTTGGCCTGCACGTGGACACGAGGAGGAGGACGGTCCACCCGTGGAACGTGGAGGCCCTCAAGAAGTATATAGAGAGGCTTAGAGAGGCGGGCGTAGAGGTCTAGACCCCGGGGCTATATACTACCACTTCGCCCTCCCCATTATACTATCCACATCCACCCTGGCCCTCCCCACCTCCAGGACCTCAATATCCCCCTCAGCCCTGGTGTACACGCTCAAAGACGGCTCCCTGTAGGAGGCCCTGGTCACCACCCCCACGTGAATCACCCCTCCCGCGTGTACGGCGGCTATAAGCCCCCTCTCCCAGCCCTCCCGGAGGACGCGGAGCCCGGAGCCTACTCCGACCCTACCGCCCCTCCTCGCCACAACCACTATGTCCCCGTCAACACTCTCACCATAGAGGGCGGCTGGGTGTAGGGCCTTGAGGGCCTCGTGGGCCAGAGGCTCCCCCCGGAATATCGGCGCGCCAACTATCTCGGCCTCGCCGGGCCTGACCCTCCTCTCCCTCCCTCCCGAGGTCCTAAGGGCTATCAGCCTCTCCCTATGAAGAGCCCTCTCCCCCCGGCTCTTGCCCGCCTCTCCAGCCAGCCTCTCCACAGACAGAGTGTCAAGCCCCCACACCCTCTCGAGCAGCCTGGCCCGTCGGCTGGCTATGCCCACCGCGACTACAAGCCTTGCTCTAGAGGCTATGGCGAGGGCTGCCTTAGACTCGAGCCCCTCCCACAGTGATATCCAGCCATCTGTATCCACTACCACCTGGCTGGCCAGTGAGGCCAATCTAGATGCGCAGGCGAGGTAGCGGGACTCCGACCCCCGGGGGGTGAAGCCGCCGACGAAACACGGCTCGACACTCGAGAACGAGTCGTCTAGGCCCGGGACGGCCACGCCCTGTGGAGACGCCAGCGCCATAAACCCCGGGGCGAAGACCTCGTTCTGGCCTATATCCGCCGACAGCAGTCTATACCCACCACCGCCCCTGTTAACTATCCAAGCCGCTAGTGTGCTCTTACCGGAGTCGCTCGGCCCCACAATAGCCACCCTGCCCCGCTGAGAGGCCTCCCTGGCTATGGAGTCGAACCTGTTGTAAGCCTCCTCCACGCCCCCTGTGGAGACTACACCGGACACAATAGCCCTCCCCTCAACCCTGGCGAGCACCGACCTGCCTGCAGGGACCACTAGAGTAGAGCCCTCCCCCAGCCTTCCACCCAAAACCTCTGCAGCACCCTCTACAACCTCTATCCTCCCCGGGCCGCGGACTAGCGCCGAGCCCCATGCAATCTCCACAGGCAAAGCTTTAAACCCCCAGTGGTAAGATATGTGAACCGGGCCGCGGTAGTATAGCCTGGACTAGTATGCGGGCCTGTCAAGGGCCCCGCCTCCGCCCCACCCTCATTCTACTACACGCTTATCAGGATAAACAGCCGGGCAAACGTTTTTAACCCCGCCGAAATTCATACTCTTCCCGGGGCGGAGGCGGGCCTGCGGAGAGCCCGTGACCCGGGTTCAAATCCCGGCCGCGGCGCCAATAATCCTCGCGGCCCGCCTTCAAGACTCACTAAACCCCGGTTGAGCACCCGCAGCATCGATGCTAAGGCTCGAGCCATGCATAGTGCCCGCGGGGGGTGGGGGGATTTGGCGAGGCCTGTTGAGGCGGTAAAGAGGCTGCTGGAGAGGTGGCTGGAGGGTAGGAGGAGGGGTTATGTCCTTACGCTTGTAGCTCTTAGAAGGCTTGAGGAGAGGGGGGAGGAGGCTACTGTAGAGAGGGTTAGGGAGGAGGGCCTGAGGATTCTGGAGAGGACGGAGGGGAGGATAGACTGGGGTGTTACTAGGGATGAGTACACTGTCAACATGGTCTCCAGCGTTCTTCGCGAGCTGGCCGAGAGCGGCCTTGTCGAGATGGTGGACGGCGGGAGGAGTATCGTCAGGTACAGGATAGCGAGGGATGCTGAGGAGGAGTTCCTCTCCAGCTTCGGCCACCTCCTGCAGCTTGTGAGGATGCCGAAGTAGCGTTAAAGCCCTAGGTGCCAGAGGCCGCCGGAGGCTAAGAGGCCGATGAAGGCCTTGAGAGGCTCTGCCGCCAAGCTATCCCTATCCCTGCTGCTCTTTTGGGCTAGCTACTCGATCTACTACACTATAACGAGGCGTGCTGTAGAGGAGGGCCTAGGAGAGGGATCCTACCTCCTGGGCGTCTTGATGTCGGGGGCTGAGGAGGCGCCGCTCGCGGCGTCAATAGTCCTTGGCTACCTGGCGGACAGGCTAGGCTACCGCTTACCCCTGGCCCTGGGCCTGTTTGAGGCTGGGCTGGTCGCTGCAATGGCCTTCACCCCCCTAGAGACCTACCCCATACTGGCTGGGGCTGCGTCGCTAGTCTACGCCCTCTCATACTCCGCCCTAATGGGCCTCGTCCTGGGTGAGAGCGGGGGGAGCGGCTTCAGGTACAGTGTTATAGCAGCCTTCGGCAGCCTTGGCTGGGCTCTCGGCGGGTTGGCGGGGGGAGCGGCTTACTCCCGCCTGGGGTCACTGGGGCTCCTAGTGGCCGCAGCCCTCATGGCCGCCTCATACCTAGTCGCCCTCTCAGCCTCGCCCCCCCGCGGCGGCGCGGCGCCCAGTGTGGGGGAGACGATAACCGCTCTGAAGGGGGTTCTGCCCCTATTTGCAAGCCTCTCAACCAGCTGGGCGGCCTTGGGCTTCTTCTTCGGGGCTGCCAGCATAAGGCTTAGCGAGGCGCTCGAGAGCCCTATCGCCTACGGGCTAGTGCTGACCACCGTCCCCGCACTCCTAGGCTTCCTGGCGAGGCCTGCGGCGGGCAGGCTGGTCGACAAGGCCGGGGCTGTGGCAGTGCTTGCGTTGTCCAACGCGGCATACTCCCTTCTCGCCCTAGTTTTCGGCCTGCCCACCAGTCCGGCCCTGCTGGCCCTTGCATGGAGCCTGCCCCTATACCCCTTTAGGGATGCCGCCGCGGCCATCGCAGTTAGCAGCAGGCTTGAGAGGAGGCTGCAGGCGACGGCCGCGGGGCTGCTCTCAGCGAGCGAGAGCGTCGGCGGCGCTGCAACCCTTGCCCTGGCACTGCTCCTGGATGGGGGGTTTAGGGAGATGATGACGGCTTCAATAGCCCTTATGCTCCTCTCCACCCTACTCCTGGCCGCAGACCACTCTACGGCTCCACGCCGAGAGCCCTGTCCCCGGCGTCGCCAAGGCCCGGCACTATGAAGTAGTTCTCGTCCAGCTCGGGGTCTAGGGCTAGCGTGTATATGGGGGTGTCGCCGTAGAGGGATGATATGTACTCGACGCCCTGCCTGGACGCTATTATAGAGCCTATAACGACCTTGCTGGCCCCCCTGTCTCTGGCCAGCCTCACGGCCTCCGCCACAGTCTTGCCCGTGGCCAGCATCGGGTCTAGAACGACGGCGGGGCCGTCGAACATGCGGGGTAGCCTGGAGTAGTAGACCTCTATCTTGAGCCTGCCCGGCTCCTCGACCCTCCTGGCTGCTACGAGGGCTATCCTCGCCTCCGGCATCATCGAGGCGAAACCCTCTACCATGGGGAGGCTAGCCCCGAGTATCCCTACGAGGTAGACGGGCCCCGCTGGCGCCAGCTCCTTGGCCTTAGCCCCCAGGGGGGTCTCCACCTCCTCCTCCACCCACCCGAGCTCGCCCGCAATGTACACCGCCAGTATGGAGCCCGCTATCCTGACGTACCTCCTAAACTCCGGGAACCCGGTTGTCCGGTCCCTGAGAACCTTGAGGACGTAGCGCGCTAGGGGTGTTTCGCCCCCAATAACCCTAACTGCCGCCACCATGGGAACCTCTAGGTAGTGGTTGAGGCTCCGGAGCTTAAGAGGGTTAAACTCCAGGATGGCCACCTGGGTGCCGCCGGGGATTGGACAGTAGGGTTCTAGAGTCCGCGTTGAGAGCCCTATCCCGCTACCCCCTCTGCGACCGCTGCCTCGGCAGGCTCTTCGCTAGGCTTGGGAGAGGCTGGAGCAATAGGGAGCGGGGAGAGGCTGTCAAGAGGGTTCTGGTGATGGAGCTTCACAGGAGGGTCCTCGAGGGGGATGAGGCGGCGTTGAAAACCCTGGTCTCTGCAGCTCCGAACATAGGGGAGGTGGCAAGGGATGTCGTGGAGCACCTCTCCCCAGGTTCCTACAGGGAGGGCGGCCCATGCGCTGTCTGCGGCGGGCGGCTGGAGAGTGTTATAGCCTCAGCGGTGGAGGAGGGGTACAGGCTGCTAAGGGCTTACGATATCGAGAGGTTCGTAGTCGGGGTCCGGCTAGAGAGAGGTGTTGCCATGGCTGAGGAGGAGGTAAAGCTGGCCGCCGGCGCCGGGTACGGCGAGTCCATTAAGGCTGAGATCAGGAGGGAGGTGGGCAAGCTCCTGGTGAGCCGGGGTGGAGTGACCGTGGACTTCGACAGCCCTGAAGCGACCCTAATGGTGGAGTTCCCCGGGGGCGGGGTTGACATACAGGTCAACAGCCTGCTCTACAAGGCTAGGTACTGGAAGCTTGCCAGGAACATAAGCCAGGCATACTGGCCCACGCCAGAGGGGCCGAGGTACTTCAGCGTGGAGCAGGCTCTATGGCCGGTTCTAAAGCTCACTGGGGGGGAGAGGCTGGTTGTACACGCTGCTGGCAGGGAGGATGTAGACGCCAGGATGCTGGGCAGCGGGAGGCCCATGATAGTCGAGGTCAAGTCGCCTAGGCGCAGGAGGATCCCGCTTGAGGAGCTGGAGGCGGCCGCCAACGCCGGCGGGAAGGGGCTGGTTAGGTTCAGGTTCGAGACGGCTGCCAAGCGTGCCGAGGTCGCGCTTTACAAGGAGGAGACTGCGAGGGTTAGGAAGGTGTACCGCGCCCTGGTAGCGGTGGAGGGTGGTGTTAGTGAGGTGGATGTTGAAGGGTTGAGGAGGGCTCTCGAGGGCGCGGTTATAATGCAGAGGACGCCCTCCAGGGTCCTCCATAGGAGGCCGGATATACTGAGGAGGCGGAGGCTCTACAGCCTAGACTGCAGCCCCCTGGAGGGGGCGCCTCTGATGGAGTGCATATTGGAGGCGGAAGGGGGTCTCTACATCAAGGAGCTGGTCAGCGGTGATGGCGGGAGAACCAGGCCAAGCTTCGCTGAGGTCCTCGGCAGGGAGGCTGTGTGTATAGAGCTCGACGTGGTGTGGGTGGAGCATGAAGCTCCAGCCGCACCCGGCTAAAGCTAAATTAAGCTGGGCTGAGCAAAATACCGGGGGGAGCGTAGGTTGGTCAAGGCACCTAGAGGCTATAGGAACAGGACTAGGAGGCTGTTGAGGAAGCCTGTGAGGGAGAAGGGCAGCATACCCAGGCTCAGCACCTACCTTAGGGAGTACAGGGTGGGCGATAAGGTGGCTATAATCATAAACCCCTCCTTCCCAGACTGGGGCATGCCCCACAGGAGGTTCCACGGGCTGACGGGAACCGTGGTGGGGAAGAGGGGCGAGGCCTACGAGGTAGAGGTCTATCTGGGTAGGAAGAGGAAGACCCTCTTCGTCCCCCCCGTGCACCTCAAACCCCTCAGCACAGCCGCCGAGAGGCGGGGCAGCTAGAGCTGTCCCCACGGTTCCACGCTGGAGTAGGGGGTGCTAGTGTTGGAGAGGAGGATCCTAGAGTATAAGGCGGTGCCCTACCAGGTAGCCAAGAAGTATATGTACGAGAGGGTTAGGGAGGGCGACATAATATCGATACAGGAGTCGACTTGGGAGTACTTCAGGAAGGTAGTGTTCTGGGACGACCCGGAGGCTGCCTCCGAGCTTGTTGAGGAGATTGTGAAGGAGGGTGTCAGCCGTGAGGCGCGGCGAACATCGCGAGCATATGCCCCAAGACCGAGGGCGAGCTCAGGAGCATTCTCGAGATGGACAGGAGCATAACCTCCGTACACGAGATGGCTAGCAAACTGTACCCCATAGTTTCCAAATACTGCAAGGACTAGACCCCGCCCCCCTTCAGCCCGGGGATTAACAGTTTAATCTCCGCGTCCCAACCATATTTATGTTGATAGCGGCTGTACGGAGAGTGTTGAGAAGTGTCTAGACAGCCCCGCCCCCGCGACAGGAAGCCCCCCCACCAGGGGAGGCCGCAGCCCCACATCGCCGCCCTTGAGGTGGAGGCTATAGTTCTGGACTACATACCCGAGGGCTACCCGAGAGACCCCCACAGGGAGCACCGCAGTAAGCCCGTCGTTCAGGGTCTCGGGGTTAGGAGGCTGCACCTAGTCGACGGTGTCCCCCTCCATGAGGTCGATATACTGGAGCGGGTCACCCTGGCTAGGGAGGTTGTGTATAGCGTCCCCATAGTGGCCCGGCTCCCCGGGGGGGTCGAGAGGAGGGTGAAAAGTGTTACCGTCGCGGTAACATGCCTCCCCGGCCAGGCGCGGGAGGGCGGGGTCAGGGAGATATACTGCTACCCCCTCTCCTACGCCGACCAGGCGACCCTGGAGGCGCTGCAGCAGCTCCTGGGTGAGGGGGACGAGAGGCACAGGTATATACTTGTGGACTCCCCCGACAAGCTCTCCGAGGTGGCCAGAGGTCACGGCCTCTCGGGGAAGATAGTGAGCACGCCCAGAGACCCTATATCCTACCAGGACCTCACCGACGTCGCCAGGGCTACGCTGCCGGACGCTGTGAGGAAGCTGGTCAGGGAGAGGGAGGACTTCTTCGTGGAGTTCTTCAACGTGGCCGAGCCGATAAACATAAGGATACACGCGCTGGAGGCCCTAAAGGGTGTGGGTAAGAAGATGGCTAGGCACCTCCTCCTCGAGAGGGAGAGGCGTAGGTTCACGAGTTTCGAGGAGGTGAAGAAGATTCTGAAGATAGACCCCGCAGAGGCCCTGGCCGAGAAGATAATGGAGGAGATAGAGTGTAGGGACACTGTGAAATACTACTTCTTCGTCGAGCCCTGCGACCCCTCCAAGCCCTACCTAGGCTACACGGAGAGGATGTGGAAGGCCTATGCC Génome humain 3.2 milliards de pb 2.7 milliards de $ (coût en 2000) 100 $ (coût en 2008 ?)
 100 $ (coût en 2008 )")
9
Le génome humain (3ème version)
contient actuellement encore 341 « trous » (essentiellement vers les centromères/télomères, régions répétitives) Nature (oct 2004), 431, 931
 Nature (oct 2004), 431, 931.")
10
Contenu des banques de données de séquences en acides nucléiques
EMBL/GenBank/DDBJ Octobre 2004 Craig Venter Ex: mer des Sargasses 1 milliard pb/semaine

11
constamment remis à jour !
Tous ces sites sont constamment remis à jour !

12
Bioinformatique - application 3: Analyse de séquence ADN
Détection des régions codantes; Recherche de similarité (BLAST) Analyse des sites de restriction (enzymes); Traduction ADN en protéine; Détection de régions de basse complexité; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences de tARN et autres types de ARN (exemples: rARN, uARN, tmARN).
 Analyse des sites de restriction (enzymes); Traduction ADN en protéine; Détection de régions de basse complexité; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences de tARN et autres types de ARN (exemples: rARN, uARN, tmARN).")
13
Détection des régions codantes (gènes)
Problème assez facile chez les bactéries; très difficile chez les eucaryotes “supérieurs” (homme, drosophile, etc.); Chez l’homme: moins de 5 % du gènome est « codant » (transcrit en mARN). Techniques diverses: recherche de signaux, approches statistiques (biais des codons); similarité avec des séquences connues….
; Chez l’homme: moins de 5 % du gènome est « codant » (transcrit en mARN). Techniques diverses: recherche de signaux, approches statistiques (biais des codons); similarité avec des séquences connues….")
14
Recherche de « signaux » dans une petite partie du promoteur
Premiers exons TATA box GC et CAT box Région régulatrices Recherche de « signaux » dans une petite partie du promoteur d’une protéine (apo AII)
")
16
Une séquence ADN de C.elegans) (~25’000 bp)
…

17
Approche 1: Genebuilder

18
Schéma récapitulatif 5 ’ 3 ’ Genebuilder prédiction 2 3 1 4 exons 1 2
1083 1003 1305 1406 1452 1661 1914 1997 2 3 1 4 5 ’ 3 ’ exons 1 2 3 4 ADN génomique Splicing / Epissage « in silico » 1 2 3 4 mARN mature EST => cDNA

19
Bioinformatique - application 3: Analyse de séquence ADN
Détection des régions codantes; Recherche de similarité (BLAST) Analyse des sites de restriction (enzymes); Traduction ADN en protéine; Détection de régions de basse complexité; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences de tARN et autres types de ARN (exemples: rARN, uARN, tmARN).
 Analyse des sites de restriction (enzymes); Traduction ADN en protéine; Détection de régions de basse complexité; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences de tARN et autres types de ARN (exemples: rARN, uARN, tmARN).")
20
Qu’est-ce qu’un BLAST ? Qu’est-ce que les ESTs ?
Approche 2: Aligner la séquence génomique avec des mARNs (BLAST contre ESTs) Qu’est-ce qu’un BLAST ? Outil informatique très efficace, permettant de faire des recherche de similarité à partir d'une séquence (protéine ou nucléique) sur les séquences existantes (banques de données) Qu’est-ce que les ESTs ? “Expressed sequence tags” : cDNAs (mARNs) qui ont été rapidement séquencés, souvent incomplets. -> Très utiles pour connaître les régions génomiques “actives” (transcrites) et la structure des gènes. (~24 mo de séquences “publiques”; 6 mo (homme))
 Qu’est-ce qu’un BLAST Outil informatique très efficace, permettant de faire des recherche de similarité. à partir d une séquence (protéine ou nucléique) sur les séquences existantes (banques de données) Qu’est-ce que les ESTs Expressed sequence tags : cDNAs (mARNs) qui ont été rapidement séquencés, souvent incomplets. -> Très utiles pour connaître les régions génomiques actives (transcrites) et la structure des gènes. (~24 mo de séquences publiques ; 6 mo (homme))")
22
Approche 2: Aligner la séquence génomique avec des mARNs (BLAST contre ESTs)
Intron ?

23
Mature mARN (-> EST)
exons 1 2 3 4 gDNA Splicing 1 2 3 4 Mature mARN (-> EST) EST => cDNA
 EST => cDNA.")
24
Séquence codante de notre « gène »
1083 1003 1305 1406 1452 1661 1914 1997 2 3 1 4 Séquence codante de notre « gène » (sans les introns = correspondant au mARN)
")
25
Bioinformatique - application 3: Analyse de séquence ADN
Détection des régions codantes; Recherche de similarité (BLASTN) Analyse des sites de restriction (enzymes); Traduction ADN en protéine; Détection de régions de basse complexité; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences de tARN et autres types de ARN (exemples: rARN, uARN, tmARN).
 Analyse des sites de restriction (enzymes); Traduction ADN en protéine; Détection de régions de basse complexité; Détection de séquences « repeats » comme les microsatellites, minisatellites, Alu repeats, etc.; Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; Détection de séquences de tARN et autres types de ARN (exemples: rARN, uARN, tmARN).")
26
Les 3 phases de lecture…

27
Traduction avec « traduction multiple » http://www. infobiogen
Met Stop

28
Recherche de similarité (contre les séquences de protéines déjà connues: BLAST)
")
29
Conclusion de l’analyse
La séquence de la protéine est MKVETCVYSGYKIHPGHGKRLVRTDGKVQIFLSGKALKGAKLRRNPRDIR WTVLHRIKNKKGTHGQEQVTRKKTKKSVQVVNRAVAGLSLDAILAKRNQT EDFRRQQREQAAKIAKDANKAVRAAKAAANKEKKASQPKTQQKTAKNVKT AAPRVGGKR Bonne prédiction par tous les logiciels, bons ESTs Notre gène inconnu est en fait déjà connu: il code pour une protéine ribosomale de type L24.

30
Des cas moins idéaux… Ex: Chromosome 21

31
Combien de protéines humaines ?
Banques de données de séquences de protéines: (Swiss-Prot + TrEMBL = UniProt) 11’ ’860 22’000 Estimation du nombre de gènes humains: 20’000-25’000 MS proteomics has verified more than 10% of human genes products, but has not identified significant numbers of unpredicted proteins (Southan C, Proteomics, 2004) En cours: « peptide mapping » du génome, R. Aebersold, 21 % protéines humaines « vérifiées »….
 11’ ’860 22’000. Estimation du nombre de gènes humains: 20’000-25’000. MS proteomics has verified more than 10% of human genes products, but has not identified significant numbers of unpredicted proteins (Southan C, Proteomics, 2004) En cours: « peptide mapping » du génome, R. Aebersold, 21 % protéines humaines « vérifiées »….")
32
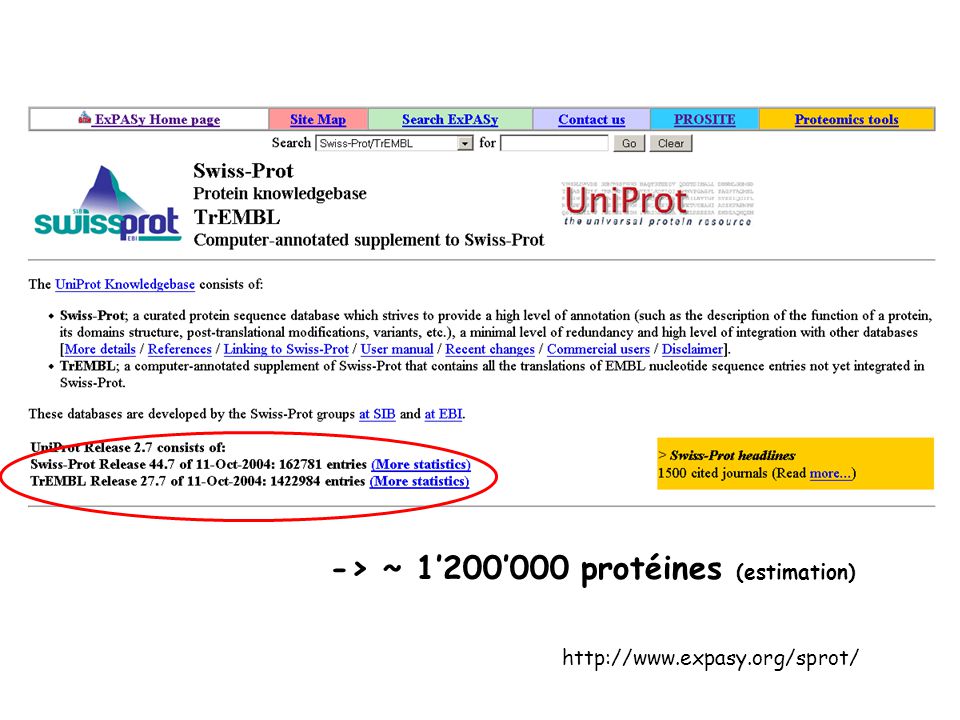
-> ~ 1’200’000 protéines (estimation)
33
C’est pas fini…

34
Bioinformatique- application 4: analyse de la séquence primaire des protéines
Caractérisation physicochimique Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée (“low complexity sequences”);
; Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée ( low complexity sequences );")
36
Séquence d’une protéine « inconnue » de C.elegans
>seq4 MSTNNYQTLSQNKADRMGPGGSRRPRNSQHATASTPSASSCKEQQKDVEH EFDIIAYKTTFWRTFFFYALSFGTCGIFRLFLHWFPKRLIQFRGKRCSVE NADLVLVVDNHNRYDICNVYYRNKSGTDHTVVANTDGNLAELDELRWFKY RKLQYTWIDGEWSTPSRAYSHVTPENLASSAPTTGLKADDVALRRTYFGP NVMPVKLSPFYELVYKEVLSPFYIFQAISVTVWYIDDYVWYAALIIVMSL YSVIMTLRQTRSQQRRLQSMVVEHDEVQVIRENGRVLTLDSSEIVPGDVL VIPPQGCMMYCDAVLLNGTCIVNESMLTGESIPITKSAISDDGHEKIFSI DKHGKNIIFNGTKVLQTKYYKGQNVKALVIRTAYSTTKGQLIRAIMYPKP ADFKFFRELMKFIGVLAIVAFFGFMYTSFILFYRGSSIGKIIIRALDLVT IVVPPALPAVMGIGIFYAQRRLRQKSIYCISPTTINTCGAIDVVCFDKTG TLTEDGLDFYALRVVNDAKIGDNIVQIAANDSCQNVVRAIATCHTLSKIN NELHGDPLDVIMFEQTGYSLEEDDSESHESIESIQPILIRPPKDSSLPDC QIVKQFTFSSGLQRQSVIVTEEDSMKAYCKGSPEMIMSLCRPETVPENFH DIVEEYSQHGYRLIAVAEKELVVGSEVQKTPRQSIECDLTLIGLVALENR LKPVTTEVIQKLNEANIRSVMVTGDNLLTALSVARECGIIVPNKSAYLIE HENGVVDRRGRTVLTIREKEDHHTERQPKIVDLTKMTNKDCQFAISGSTF SVVTHEYPDLLDQLVLVCNVFARMAPEQKQLLVEHLQDVGQTVAMCGDGA NDCAALKAAHAGISLSEAEASIAAPFTSKVADIRCVITLISEGRAALVTS YSAFLCMAGYSLTQFISILLLYWIATSYSQMQFLFIDIAIVTNLAFLSSK TRAHKELASTPPPTSILSTASMVSLFGQLAIGGMAQVAVFCLITMQSWFI PFMPTHHDNDEDRKSLQGTAIFYVSLFHYIVLYFVFAAGPPYRASIASNK AFLISMIGVTVTCIAIVVFYVTPIQYFLGCLQMPQEFRFIILAVATVTAV ISIIYDRCVDWISERLREKIRQRRKGA

37
Bioinformatique- application 4: analyse de la séquence primaire des protéines
Caractérisation physicochimique Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée (“low complexity sequences”);
; Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée ( low complexity sequences );")
38
Déterminer les caractéristiques physico-chimiques

39
Bioinformatique- application 4: analyse de la séquence primaire des protéines
Caractérisation physicochimique Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée (“low complexity sequences”);
; Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée ( low complexity sequences );")
40
Localisation subcellulaire ?
PSORT II

41
Bioinformatique- application 4: analyse de la séquence primaire des protéines
Caractérisation physicochimique Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); Recherche de régions transmembranaires (TM); Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée (“low complexity sequences”);
; Recherche de régions transmembranaires (TM); Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée ( low complexity sequences );")
42
Résumé des différents résultats obtenus par différents programmes de prédiction de TM
grande boucle HMMTOP 1 in 1130 PSORT II 1 1130 TMpred 1 in 1130 TMHMM 1 out 1130

43
Bioinformatique- application 4: analyse de la séquence primaire des protéines
Caractérisation physicochimique Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée (“low complexity sequences”);
; Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée ( low complexity sequences );")
45
Recherche des régions fonctionnelles
Il s’agit probablement d’une ATPase

46
Bioinformatique- application 4: analyse de la séquence primaire des protéines
Caractérisation physicochimique Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée (“low complexity sequences”);
; Recherche de régions transmembranaires; Recherche des régions fonctionnelles (domaines conservés) Recherche de sites de modifications post-traductionelles (PTM). Recherche de régions antigéniques; Recherche de régions dont la composition est biaisée ( low complexity sequences );")
47
Prédiction des sites de phosphorylation
Sequence 484 ISPTTINTC Sequence 487 TTINTCGAI Sequence 499 CFDKTGTLT Sequence 501 DKTGTLTED *T* Sequence 503 TGTLTEDGL *T* Prédiction des sites de phosphorylation (Importance des données expérimentales !)
")
48
Sulfatation Sulfinator Glycosylation

49
Ça me semble biologique …mais reste à le prouver !
Conclucion de l’analyse in silico de notre protéine inconnue Poids moléculaire: 126 kD; Fonction: ATPase potentielle; Localisation subcellulaire: Membrane plasmique. Transmembranaire (~10 hélices); N terminal: intracellulaire; C terminal: intracellulaire) PTM: Phosphorylée Ça me semble biologique …mais reste à le prouver !
; N terminal: intracellulaire; C terminal: intracellulaire) PTM: Phosphorylée. Ça me semble biologique …mais reste à le prouver !")
50
Bioinformatique - application 5: alignement de 2 séquences
Mettre en relation 2 séquences en comparant les acides aminés à chaque position et en tenant compte de leur probabilité de mutation au cours de l’évolution; MY-TAIL--ORIS-RICH- #x #### x#x# #### MONTAILLEURESTRICHE (algorithme pour comparer des chants d’oiseaux)
")
51
BLAST

52
« la pierre angulaire de la bioinformatique »
BLAST « la pierre angulaire de la bioinformatique »

53
Bioinformatique - application 6: Alignement multiple
Exemples: Clustal W, T-coffee tr|Q9N LVLVCNVFARMAPEQKQLLVEHLQDVGQTVAMCGDGANDCAALKAAHAGISLSEAEASIA sp|Q21286|YBF7_CAEEL ITAMCDVYARMAPDQKAQLIGALQEIGAKVSMCGDGANDCAALKAAHAGISLSQAEASIA sp|Q9H7F0|ATY3_HUMAN LMLHGTVFARMAPDQKTQLIEALQNVDYFVGMCGDGANDCGALKRAHGGISLSELEASVA sp|Q9NQ11|ATY1_HUMAN VLVQGTVFARMAPEQKTELVCELQKLQYCVGMCGDGANDCGALKAADVGISLSQAEASVV sp|O74431|ATC9_SCHPO ILLKAQIFARMSPSEKNELVSCFQNLNYCVGFCGDGANDCGALKAADVGISLSEAEASVA sp|Q12697|ATC9_YEAST ILLNSSIYARMSPDEKHELMIQLQKLDYTVGFCGDGANDCGALKAADVGISLSEAEASVA : ::***:*.:* *: :*.: *.:********.*** *. *****: ***:.

54
Alignement multiple et dendogramme
Exemple d’un dendrogramme obtenu à partir d’un résultat de CLUSTALW à l’aide du programme « phylodendron »

55
Bioinformatique - application 7: phylogénétique
Reconstruction de l’évolution moléculaire des familles de protéines; Reconstruction de l’évolution des espèces; création d’arbres taxonomique; Reconstruction de l’évolution des chemins métaboliques.

56
Computational Challenges from the Tree of Life
The biology community has embarked on an enormously ambitious project, the assembly of the Tree of Life -- the phylogeny of all organisms on this planet. This project presents a true computational grand challenge: - current phylogenetic methods can barely handle a few hundred organisms. yet the Tree of Life has an estimated million organisms. November 8, 17:15, EPFL INM 202 Bernard Moret University of New Mexico Albuquerque, USA

57
Bioinformatique - application 8 analyse de la structure secondaire & modélisation des protéines
MSTNNYQTLSQNKADRMGPGGSRRPRNSQHATASTPSASSCKEQQKDVEH EFDIIAYKTTFWRTFFFYALSFGTCGIFRLFLHWFPKRLIQFRGKRCSVE NADLVLVVDNHNRYDICNVYYRNKSGTDHTVVANTDGNLAELDELRWFKY RKLQYTWIDGEWSTPSRAYSHVTPENLASSAPTTGLKADDVALRRTYFGP NVMPVKLSPFYELVYKEVLSPFYIFQAISVTVWYIDDYVWYAALIIVMSL YSVIMTLRQTRSQQRRLQSMVVEHDEVQVIRENGRVLTLDSSEIVPGDVL VIPPQGCMMYCDAVLLNGTCIVNESMLTGESIPITKSAISDDGHEKIFSI DKHGKNIIFNGTKVLQTKYYKGQNVKALVIRTAYSTTKGQLIRAIMYPKP ADFKFFRELMKFIGVLAIVAFFGFMYTSFILFYRGSSIGKIIIRALDLVT IVVPPALPAVMGIGIFYAQRRLRQKSIYCISPTTINTCGAIDVVCFDKTG TLTEDGLDFYALRVVNDAKIGDNIVQIAANDSCQNVVRAIATCHTLSKIN NELHGDPLDVIMFEQTGYSLEEDDSESHESIESIQPILIRPPKDSSLPDC ? Structure d’une protéine Séquence d’une protéine

58
Bioinformatique - application 8 analyse de la structure secondaire & tertiaire des protéines
Détermination de la structure tertiaire à partir de la séquence (“ab-initio”); problème non-résolu ! Prédiction de la structure secondaire (hélices…) Modélisation par homologie: prédire la structure d’une nouvelle protéine ressemblant à une dont la structure est déjà connue; en plein développement… Programme de visualisation pour la structure 3D Prédiction de “docking” entre protéines ou entre une protéine et une petite molécule (« drug design »)
; problème non-résolu ! Prédiction de la structure secondaire (hélices…) Modélisation par homologie: prédire la structure d’une nouvelle protéine ressemblant à une dont la structure est déjà connue; en plein développement… Programme de visualisation pour la structure 3D. Prédiction de docking entre protéines ou entre une protéine et une petite molécule (« drug design »)")
59
Exemple de données de cristallographie aux rayons X Coordonnées atomiques - données expérimentales
CRYST P CA 82 ORIGX CA 83 ORIGX CA 84 ORIGX CA 85 SCALE CA 86 SCALE CA 87 SCALE CA 88 ATOM N TRP CA 89 ATOM CA TRP CA 90 ATOM C TRP CA 91 ATOM O TRP CA 92 ATOM CB TRP CA 93 ATOM CG TRP CA 94 ATOM CD1 TRP CA 95 ATOM CD2 TRP CA 96 ATOM NE1 TRP CA 97 ATOM CE2 TRP CA 98 ATOM CE3 TRP CA 99 ATOM CZ2 TRP CA 100 ATOM CZ3 TRP CA 101 ATOM CH2 TRP CA 102 …….

60
Programme de visualisation de la structure tridimentionnelle
(Chime, Rasmol, PDB viewer…) Interaction entre un facteur de transcription (dimère) et l’ADN
 Interaction entre. un facteur de transcription (dimère) et l’ADN.")
61
C’est beau…mais y a du boulot !

62
HIV: exemple d’application de la bioinformatique
1984: identification du virus; 1985: séquençage du génome de HIV-1 ; (4 laboratoires dont Montagnier/France et Gallo (USA) (??)) : caractérisation des protéines; 1989: structure X-ray de la protéase; 1990: premiers inhibiteurs modélisés à partir de la structure 3D de la protéase Novembre 1995: premier médicament (Invirase) approuvé par la FDA (trithérapie).
 ( )) : caractérisation des protéines; 1989: structure X-ray de la protéase; 1990: premiers inhibiteurs modélisés à partir de la structure 3D de la protéase. Novembre 1995: premier médicament (Invirase) approuvé par la FDA (trithérapie).")
63
Structure 3D de la protease de HIV

64
Structure 3D de la protease de HIV + inhibiteur

65
Conclusions Extraordinaire potentiel de la bioinformatique…
mais ne elle ne remplace(ra) pas les expériences «wet lab» génomiques, protéomiques et autres, ni l’esprit critique humain (contexte biologique) ! La bioinfo fournit des outils performants aux chercheurs… Les données expérimentales des chercheurs permettent d’améliorer les programmes bioinformatiques (prédiction)…
 pas les expériences «wet lab» génomiques, protéomiques et autres, ni l’esprit critique humain (contexte biologique) ! La bioinfo fournit des outils performants aux chercheurs… Les données expérimentales des chercheurs permettent. d’améliorer les programmes bioinformatiques (prédiction)…")
66
Avant … Après …

67
CPTIC 288 Explorer les génomes en classe
Si vous êtes intéressés: CPTIC 288 Explorer les génomes en classe 26 novembre 2004 Acquérir une vue d'ensemble des potentiels “éducatifs” des bases de données (issues du séquençage du génome humain notamment)
")
68
La taille des génomes (en nombre de bases)
Viroide Petit phage (virus infectant une bactérie) ,000 Virus du SIDA ,000 Virus de l’herpès ,000 Mycoplasma genitalium (bactérie parasite) 600,000 Bactérie à 13 millions Levure du boulanger millions Drosophile (mouche) millions Poisson fugu millions Homme milliards Pin milliards Salamandre milliards Amibe milliards
 2,000. Virus du SIDA 10,000. Virus de l’herpès 150,000. Mycoplasma genitalium (bactérie parasite) 600,000. Bactérie 1 à 13 millions. Levure du boulanger 13 millions. Drosophile (mouche) 180 millions. Poisson fugu 360 millions. Homme 3.2 milliards. Pin 68 milliards. Salamandre 81 milliards. Amibe 670 milliards.")
Présentations similaires

















 Nombres (1-100).>")



