Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Présentation: Algorithme pour le web Article:« Scalable Techniques for clustering the Web » Professeur:José Rolim Assistant:Matthieu Bouget

2
Sommaire Introduction Deux approches pour le clustering du web Représentation dun document Mesure de similarité Algorithme LSH(locality-sensitive hashing) Clustering Résultats des expériences Références
 Clustering Résultats des expériences Références")
3
Introduction Le clustering est lune des principales méthodes pour traiter la grande quantité dinformation actuelle du web.Avec les milliards de pages sur le web,des algorithmes de clustering fortement scalables sont nécessaires.

4
Deux approches pour le clustering du web Les approches pour le clustering du web peuvent être divisées en deux catégories: Offline Clustering: il sagit de grouper les pages indépendamment des questions de recherche. Cest à dire quon essaie de construire des ensembles de pages relatives en se basant sur une certaine métrique(la plupart du temps une notion de similarité).
..")
5
Deux approches pour le clustering du web(suite) Online Clustering: Dans ce cas le clustering est fait par rapport aux questions de recherche selon une matière donnée. cette approche utilise deux méthodes: le méthode basé lien et la méthode basée texte.

6
Ces deux méthodes pour le clustering online ont donné de bons résultats pour trouver des pages qui parlent dun même sujet. Mais la méthode basée texte nest en général pas scalable pour le clustering offline de web entier. Et la méthode basée lien est souvent confrontée aux habituelles techniques de filtrage collaboratif:

7
Au moins quelques pages se dirigeant à deux pages sont nécessaires afin de fournir l'évidence de la similitude entre les deux. Ceci empêche des moteurs de recherche de trouver les relations tôt dans la vie de la page, par exemple, quand elle est crawlée en premier. Des pages sont considerées comme semblables seulement quand un nombre suffisant de pages les co-citent.

8
les méthodes basées lien sont sensibles aux choix spécifiques faits par les auteurs des pages Web ; par exemple certains utilisent CNN pour les informations météo et dautres MSNBC et il se peut très bien quil ny ait aucun lien entre ces deux pages.

9
Pour surmonter les limitations des approches ci-dessus, on introduit lalgorithme LSH( locality-sensitive hashing ) dont lidée de base est deffectuer un hashage des pages web de telle manière que les pages similaires aient une plus grande probabilité de collision.
 dont lidée de base est deffectuer un hashage des pages web de telle manière que les pages similaires aient une plus grande probabilité de collision.")
10
Représentation dun document La plupart du temps un document est représenté comme un vecteur n- dimensionnel, où la dimension i est la fréquence du term i. Dans notre cas un document doc u est représenté par un bag où w u i sont les mots présents dans le bag et f u i les fréquences correspondantes. les fréquences des mots sont calculées grâce à la formule:

11
Avec : la fréquence du mot i dans tout le document N:nombre de documents Et comme avant.

12
Représentation dun document (suite) Deux options pour générer le bag cest pour décider quels mots en font partie: Content-Based Bags dans ce cas le bag est donné par le multi ensemble des mots apparaissant dans le document u. on élimine les commentaires HTML,le code javascript. on utilise aussi une liste de stopword. Anchor-Based Bags Mais lutilisation du contenu des pages est problématique dans la mesure où elle ne prend pas en compte les liens et les images. Cela soulève aussi des problèmes de polysémie et de synonymie.

13
Pour alléger ce problème le bag représentant un document sera un multi ensemble des occurrences des mots près des hyperliens de la page. Donc pour générer ces bag nous procédons comme précédemment sauf quau lieu de construire un sac des mots du documents,on construit un fragment de sac pour chaque URL auquel le document est lié. Chaque fragment de sac comprend le texte dancre de lURL, aussi bien qu'une fenêtre des mots juste avant et juste après le lien Dans les expériences de larticle la taille de la fenêtre est de 8.

14
Mesure de similarité Pour chaque paire durl u et v,leur similarité est donnée par: Exemple:on applique cette mesure de similarité au Anchor-Based bags Expérience:

15
Ils prennent les 12 premiers millions de pages du répertoire du Stanford WebBase à partir dun crawl effectué en 1999. Ces 12 millions de pages permettent la génération de Anchor-Based bags de 35 millions durls. Ils ont choisi aléatoirement 20 urls au deuxième niveau de la hiérarchie Yahoo et ont trouvé les 10 plus proches voisins de chaque url dans la collection de 35 millions durl en se basant sur la mesure de similarité définie plus haut.

16
On parcourt donc les sacs générés pour trouver les 10 plus proches voisins. Trouver des pages similaires deux par deux dans un lot de 35 millions durl ce nest pas très élégant mais nous verrons une manière plus efficace lorsque nous parleront du LSH. Les premiers résultats suggère que le Anchor- Based Bags est une bonne technique pour juger de la similitude des documents.

17
Quelques résultats: 2 sujets: 1.English langage studies 2.food

19
Algorithme LSH Lidée cest de créer une signature pour chaque url pour assurer que les url similaires aient une signature similaire. En admettant que les bags sont des ensembles,on utilise la formule:,où mh est est choisi de manière aléatoire dans la famille des fonctions de Hashage

20
On trouve une MH-signature par min w {h(w)|w appartient S} S est lensemble qui représente B(bag) h(.) est une fonction linéaire de hashage Cette MH-signature a la propriété que la même valeur correspond à des urls similaires. Mais comme la méthode est basée sur des probabilités,on peut avoir des faux positifs et des faux négatifs

21
Cest là quon introduit la LSH-signature qui est la concaténation de k MH-signature provenant dune génération de m MH- signature Cela réduit le nombre de faux positifs mais augmentent les faux négatifs. Pour cela on génère l différents LSH- signature pour chaque url.

23
Pour augmenter la qualité de nos résultats et réduire les faux positifs, il y a une étape de filtrage sur les paires produites par l'algorithme d'ExtractSimilarPairs. Pendant cette étape, chaque paire (u,v) est validée en vérifiant si les urls u et v sont daccord sur une fraction de leurs MH-SIGNATURES qui est au moins aussi grande que le niveau désiré de similitude ( 20%). Si la condition ne se tient pas, la paire est jetée.
 est validée en vérifiant si les urls u et v sont daccord sur une fraction de leurs MH-SIGNATURES qui est au moins aussi grande que le niveau désiré de similitude ( 20%). Si la condition ne se tient pas, la paire est jetée..")
24
Clustering Lensemble des paires de documents généré par lalgorithme doit être trié. Il faut noter que chaque paire apparaît 2 fois (u,v),(v,u). Pour former les cluster on utilise un algorithme quon appelle CENTER. Lidée est de considérer les paires similaires comme les arcs dun graphe et les urls sont les nœuds. Lalgorithme partitionne le graphe de telle manière que dans chaque cluster il y a un center Et les autres nœuds du graphe sont « assez proches» cest-à-dire quil existe un arc(il existe une paire similaire(nœud,center)).
,(v,u). Pour former les cluster on utilise un algorithme quon appelle CENTER. Lidée est de considérer les paires similaires comme les arcs dun graphe et les urls sont les nœuds. Lalgorithme partitionne le graphe de telle manière que dans chaque cluster il y a un center Et les autres nœuds du graphe sont « assez proches» cest-à-dire quil existe un arc(il existe une paire similaire(nœud,center))..")
25
L'algorithme parcourt séquentiellement les paires triées. La première fois que le noeud u apparaît dans le parcourt, il est marqué comme centre de cluster. Tous les noeuds v suivants qui apparaissent dans les paires (u,v) sont marqués comme appartenant au cluster de u et ne sont plus considérés.
 sont marqués comme appartenant au cluster de u et ne sont plus considérés..")
26
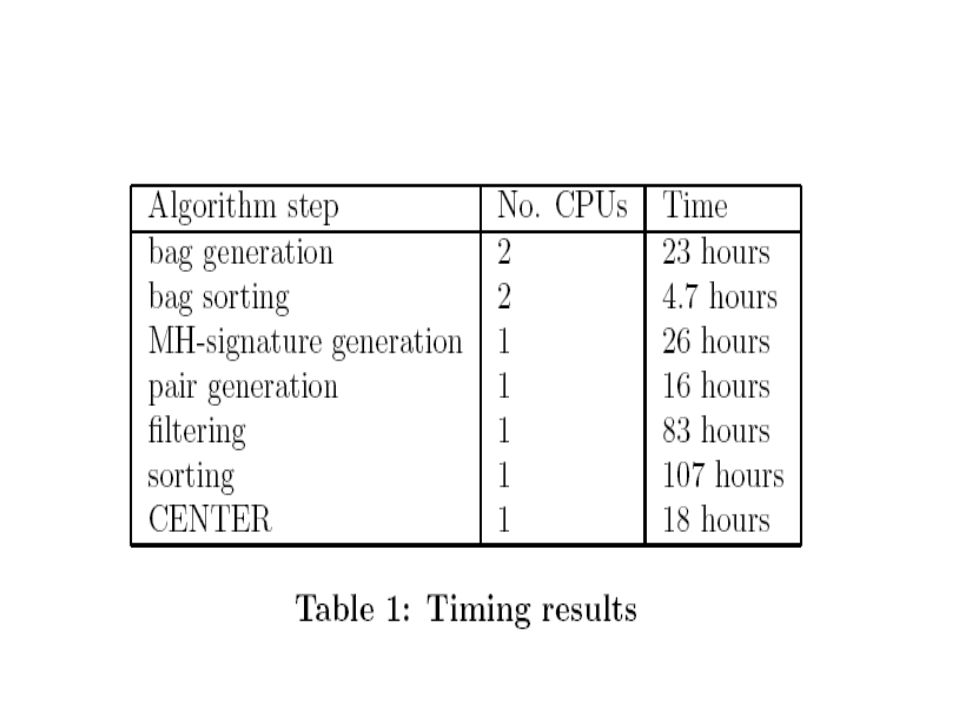
Résultats des expériences Ils ont utilisé lapproche Anchor-Based pour générer les bags de 35 millions durls trouvés partir de 12 millions de pages. Ils appliquent ensuite le Clustering basé sur la technique LSH. Lalgorithme ExtractSimilarPairs est appliquée avec les paramètres suivants: l=125 m=80 k=3 Les temps dexécution de chaque étape sont dans le tableau suivant:

28
Références http://www.med.univ- rennes1.fr/doc/nomindex/http://www.med.univ- rennes1.fr/doc/nomindex/ http://cui.unige.ch/tcs/cours/algoweb/anne eCourante/documentshttp://cui.unige.ch/tcs/cours/algoweb/anne eCourante/documents

Présentations similaires




>")

>")





>")








