Télécharger la présentation
1
Optimisation non linéaire sans contraintes Recherche opérationnelle GC-SIE

2
Moindres carrés

3
Michel Bierlaire3 Moindres carrés g i : IR m IR r(i) est continûment différentiable, i=1,…,m On a souvent r(i) = 1.
 est continûment différentiable, i=1,…,m On a souvent r(i) = 1.")
4
Moindres carrésMichel Bierlaire4 Moindres carrés Exemple : Estimation des paramètres dun modèle Soit un modèle mathématique z=h(x,y) x est le vecteur des paramètres inconnus. y est le vecteur dentrée du modèle. z est le vecteur de sortie du modèle. On dispose de m observations (y i,z i )
.")
5
Moindres carrésMichel Bierlaire5 Moindres carrés Question : quelles sont les valeurs des paramètres telles que le modèle reproduise le mieux les observations ?

6
Moindres carrésMichel Bierlaire6 Moindres carrés Exemple : On veut mesurer la résistivité du cuivre. On dispose dune barre de 1m de cuivre, de section 1cm 2. Lexpérience consiste à envoyer des courants de diverses intensités et de mesurer la différence de potentiel. Le modèle mathématique est donné par la loi dOhm.

7
Moindres carrésMichel Bierlaire7 Moindres carrés Paramètre inconnu : résistance R Entrée du modèle : intensité I Sortie du modèle : diff. potentiel V Modèle mathématique : V = R I = ( /S) I où est la longueur, S la section et la résistivité du cuivre.
 I où est la longueur, S la section et la résistivité du cuivre..")
8
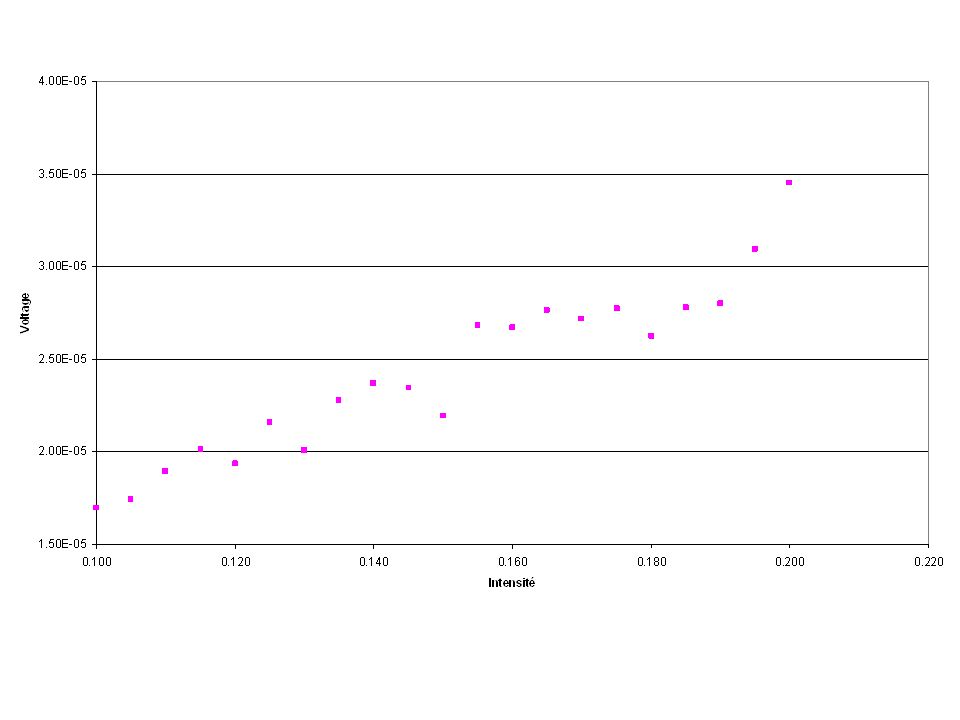
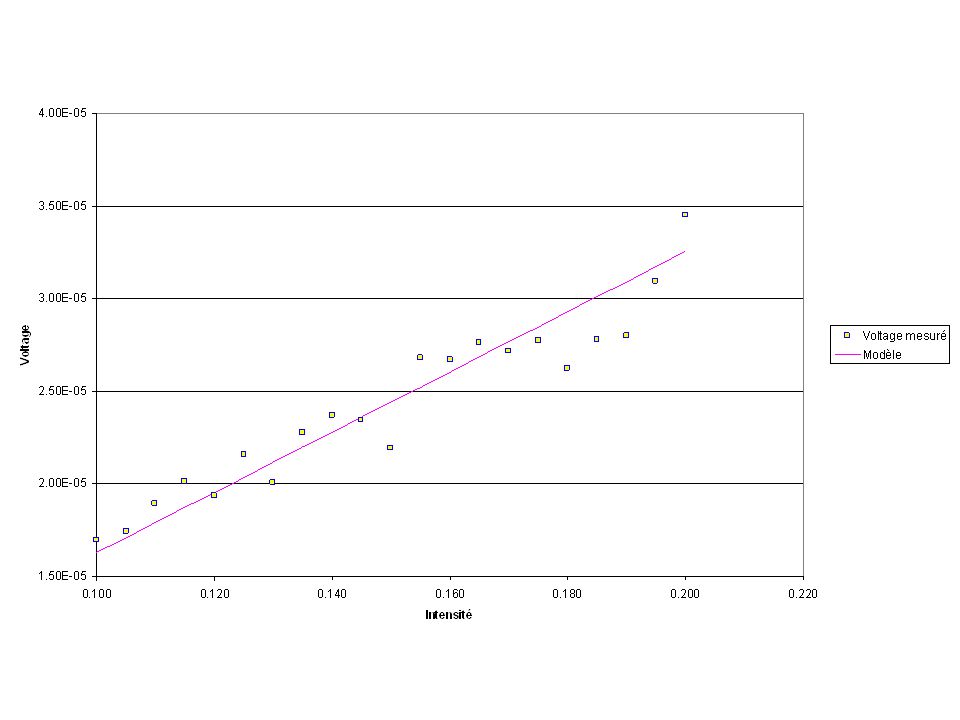
Moindres carrésMichel Bierlaire8 Moindres carrés Données récoltées :

11
Moindres carrésMichel Bierlaire11 Moindres carrés Réseaux de neurones. Modèle spécifié par un système multi-niveaux. Le niveau consiste en n k unités dactivitation ou neurone. Chaque unité dactivation est une relation entrée-sortie :IR IR

12
Moindres carrésMichel Bierlaire12 Moindres carrés + x j k+1 xskxsk uskusk u0ku0k

13
Moindres carrésMichel Bierlaire13 Moindres carrés La sortie de la j ième unité dactivation du niveau k+1 est notée x j k+1. Lentrée est une fonction linéaire des sorties du niveau k. Donc

14
Moindres carrésMichel Bierlaire14 Moindres carrés Les u k s sont appelés « poids » Ce sont les paramètres à déterminer. Pour un ensemble de paramètres donnés, et si N est le nombre de niveaux, à chaque vecteur dentrée x 0 du niveau 0 correspond un vecteur de sortie x N du niveau N.

15
Moindres carrésMichel Bierlaire15 Moindres carrés Le réseau de neurones peut donc être considéré comme un modèle mathématique z=h(x,y) où – x est le vecteur de poids – y est le vecteur dentrées au niveau 0 – z est le vecteur de sorties au niveau N
 où – x est le vecteur de poids – y est le vecteur dentrées au niveau 0 – z est le vecteur de sorties au niveau N")
16
Moindres carrésMichel Bierlaire16 Moindres carrés La phase dentrainement du réseau, ou phase dapprentissage peut donc être considérée comme la résolution dun problème de moindres carrés. Exemples typiques de fonctions dactivation : Fonction sigmoidale : Fonction hyperbolique tangente :

17
Moindres carrésMichel Bierlaire17 Moindres carrés Le problème dentrainement de réseaux neuronaux est souvent très compliqué. Les fonctions de coûts associées sont non-convexes et possèdent souvent des minima locaux multiples. Exemple à deux paramètres.

18
Source: Bertsekas (1995) Nonlinear programming, Athena Scientific
 Nonlinear programming, Athena Scientific")
19
Moindres carrésMichel Bierlaire19 Gauss-Newton Idée Travailler sur g et non sur f. Linéarisation de g :

20
Moindres carrésMichel Bierlaire20 Gauss-Newton Minimiser la norme de m(x)
")
21
Moindres carrésMichel Bierlaire21 Gauss-Newton Si f(x) = ½ ¦¦m(x)¦¦ 2, alors Le minimum est atteint en si la matrice est inversible.
 = ½ ¦¦m(x)¦¦ 2, alors Le minimum est atteint en si la matrice est inversible.")
22
Moindres carrésMichel Bierlaire22 Gauss-Newton Une itération Gauss-Newton pure est g(x k )g(x k ) est le gradient de ½¦¦g(x)¦¦ 2 en x k Si g(x k ) g(x k ) T est définie positive, nous avons donc une direction de descente.
g(x k ) est le gradient de ½¦¦g(x)¦¦ 2 en x k Si g(x k ) g(x k ) T est définie positive, nous avons donc une direction de descente.")
23
Moindres carrésMichel Bierlaire23 Gauss-Newton Tout comme la méthode de Newton pure pour le cas général, la méthode de Gauss-Newton pure pour les moindres carrés peut ne pas converger. Solution :

24
Moindres carrésMichel Bierlaire24 Gauss-Newton k est choisi par la règle dArmijo. k est une matrice diagonale telle que g(x k ) g(x k ) T + k soit défini positif. Méthode de Levenberg-Marquardt : k = multiple de lidentité
 g(x k ) T + k soit défini positif. Méthode de Levenberg-Marquardt : k = multiple de lidentité.")
25
Moindres carrésMichel Bierlaire25 Gauss-Newton Cas linéaire g(x)=Cx-z g(x) = C T x k+1 = x k -(C T C) -1 C T (Cx k -z) = (C T C) -1 C T z k La solution est obtenue en une itération Note: le système déquations C T Cx=C T z est appelé équations normales.
=Cx-z g(x) = C T x k+1 = x k -(C T C) -1 C T (Cx k -z) = (C T C) -1 C T z k La solution est obtenue en une itération Note: le système déquations C T Cx=C T z est appelé équations normales.")
26
Moindres carrésMichel Bierlaire26 Gauss-Newton Relation avec la méthode de Newton Soit g:IR n IR m f(x)= ½ ¦¦g(x)¦¦ 2
= ½ ¦¦g(x)¦¦ 2")
27
Moindres carrésMichel Bierlaire27 Gauss-Newton Gauss-Newton = Newton en négligeant le second terme

28
Moindres carrésMichel Bierlaire28 Régression orthogonale Moindres carrés Régression orthogonale

29
Moindres carrésMichel Bierlaire29 Régression orthogonale (y,h(x,y)) (y i,z i ) min x min y (y i -y) 2 +(z i -h(x,y)) 2
) (y i,z i ) min x min y (y i -y) 2 +(z i -h(x,y)) 2")
30
Moindres carrésMichel Bierlaire30 Régression orthogonale Notes : Cette régression est utilisée lorsque des erreurs sont présentes aussi dans les entrées du modèle. On suppose que les erreurs dans les entrées et les erreurs dans les sorties sont indépendantes, de moyenne nulle. Même si le modèle est linéaire, le problème de moindres carrés nest pas linéaire.

31
Moindres carrésMichel Bierlaire31 Régression orthogonale Exemples : – Résistivité du cuivre Moindres carrés : r = 1.61046 10 -8 Régression orthogonale : 1.60797 10 -8 – Modèle sphérique : z = x 1 + [x 2 2 -(y-x 3 ) 2 ] ½
![Moindres carrésMichel Bierlaire31 Régression orthogonale Exemples : – Résistivité du cuivre Moindres carrés : r = Régression orthogonale : – Modèle sphérique : z = x 1 + [x 2 2 -(y-x 3 ) 2 ] ½](http://images.slideplayer.fr/5/1628658/slides/slide_31.jpg "Moindres carrésMichel Bierlaire31 Régression orthogonale Exemples : – Résistivité du cuivre Moindres carrés : r = Régression orthogonale : – Modèle sphérique : z = x 1 + [x 2 2 -(y-x 3 ) 2 ] ½")
32
Moindres carrésMichel Bierlaire32 Régression orthogonale Moindres carrés : x 1 = 1.9809 x 2 = 4.7794 x 3 = 2.9938 Orthogonale : x 1 = 3.2759 x 2 = 3.8001 x 3 = 3.0165 Modèle réel : x 1 = 3 x 2 = 4 x 3 = 3





















.>")