Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Comparaisons multiples
Comprendre pourquoi il faut des procédures spéciales pour faire des comparaisons multiples quel danger y-a-t-il à faire des comparaisons multiples comment s’en sortir comprendre les principes de ces procédures savoir appliquer les différents tests de comparaisons multiples

2
S Addition Rimes Adjectifs Images Intentionel 9 7 11 12 10 8 13 19 6
16 14 5 4 23 3 15 S 70 69 110 134 120 M 7.00 6.90 11.00 13.40 12.00 DS 1.83 2.13 2.49 4.50 3.74 données de la page 341, explications en pages

3
Un F significatif est équivoque
Il y a autant de comparaisons à faire que Tester ces comparaisons fait augmenter la probabilité de commettre une erreur sur l’ensemble des comparaisons le seuil de .05 équivaut à 1/20, mais ne vaut que pour 1 comparaison Dans l’exemple d’Eysenck comparaisons de 2 moyennes à la fois parmi 5 C5/2 = 5! / 2! (5-2)! = 5! / 2! (3!) = (5x4) / 2 = 10 il y aurait 10 comparaison 2 x 2 à faire.
! = 5! / 2! (3!) = (5x4) / 2 = 10. il y aurait 10 comparaison 2 x 2 à faire.")
4
Rappel de notions du chapitre 4

5
Que font les tests d’inférence statistique? (1)
paramétrique le paramètre est-il fréquent ou rare selon la distribution théorique? <= fréquent=> rare

6
Les erreurs d’inférence
État de la nature Décision du chercheur ou de la chercheure Erreur de type I = faux positif en jugement clinique puissance statistique

7
La probabilité de faire l’erreur de type I peut s’interpréter comme le nombre de conclusions erronnées produites par 100 répétitions de la même expérience.

8
Les décisions prises à partir de tests d’inférence sont des décisions basées sur des probabilités
Probabilité de faire une erreur de type I; en recherche, les conclusions sont incertaines

9
Fin du rappel

10
Problème des comparaisons multiples
Chaque comparaison a son taux d’erreur (EC) Sur l’ensemble des comparaisons (EE), le taux d’erreur augmente: Cette évolution est plus lente que la simple addition des taux d’erreur (Loi d’inégalité de Bonferroni) si nous faisons toutes les 10 comparaisons 2x2, chacune à .05, la probabilité de faire au moins 1 erreur de type alpha n’est pas de .05 mais de 1 – (1-.05)**10 = 1 – (.95)**10 = = !!!! La solution de Bonferronni .05/10 = .005 alors 1 – (.995)**10 = 1 - 0, = 0,
 Sur l’ensemble des comparaisons (EE), le taux d’erreur augmente: Cette évolution est plus lente que la simple addition des taux d’erreur (Loi d’inégalité de Bonferroni) si nous faisons toutes les 10 comparaisons 2x2, chacune à .05, la probabilité de faire au moins 1 erreur de type alpha n’est pas de .05 mais de 1 – (1-.05)**10 = 1 – (.95)**10 = = !!!! La solution de Bonferronni .05/10 = alors 1 – (.995)**10 = 1 - 0, = 0,")
11
La solution de Bonferroni au problème des comparaisons multiples
Il suffit de diviser le taux d’erreur choisi pour l’ensemble par le nombre de comparaisons et donc d’adopter ce taux (divisé) pour chaque comparaison
 pour chaque comparaison.")
12
La solution de Bonferroni au problème des comparaisons multiples
Solution très conservatrice pour a qui réduit la puissance statistique celle-ci dépend taille de l’échantillon (n) taille de l’effet a <= fréquent=> rare
 taille de l’effet. a. <= fréquent=> rare.")
13
Procédures de comparaisons multiples a priori: les procédures réduisant EE (1)
Les test t et F sur les contrastes ne protègent pas contre l’élévation de l’erreur de type I Dunn-Bonferroni suggèrent une procédure pour obtenir cette protection t’ En fait t’ = t à alpha/c

14
Procédures de comparaisons multiples a priori: les procédures réduisant EE (2)
Des solutions à la procédure de Dunn-Bonferroni jugée trop conservatrice Sidak Holm Lazarlee & Mulaik ajuster progressivement selon l’ordre de grandeur des différences Shaffer ibid. mais exclut les résultats illogiques Sidak: 1 – (1-.05)**(1/10) = 1 – (.95)**(1/10) = 1 - 0, = 0, Problème où trouver , dans nos tableaux??? solution: ordinateur!!! ex. Holm et Lazarlee et Mulaik, supposons 2 groupes de comparaisons parmi les 10, groupe A est formé de 4 comparaisons et le groupe B est de 6, la somme des alpha individuel ne doit pas dépasser .05, comment faire? 1 solution chaque comparaison du groupe A est à .01 (somme = .04), alors il reste .01 pour les 6 comparaisons du groupe B, leur alpha individuel est de .01/6 = 0, En fait la composition est arbitraire, il faut savoir la défendre.
**(1/10) = 1 – (.95)**(1/10) = 1 - 0, = 0, Problème où trouver , dans nos tableaux solution: ordinateur!!! ex. Holm et Lazarlee et Mulaik, supposons 2 groupes de comparaisons parmi les 10, groupe A est formé de 4 comparaisons et le groupe B est de 6, la somme des alpha individuel ne doit pas dépasser .05, comment faire 1 solution chaque comparaison du groupe A est à .01 (somme = .04), alors il reste .01 pour les 6 comparaisons du groupe B, leur alpha individuel est de .01/6 = 0, En fait la composition est arbitraire, il faut savoir la défendre.")
15
Deux autres notions à propos des comparaisons multiples
Comparaisons prévues: a priori ou non a posteori + nombreuses Comparaisons directes de moyennes comme le test t ou par combinaison linéaire de moyennes

16
Procédure de comparaisons multiples a priori: le test t
le test t standard le test t adapté à l’ANOVA dl = n1 + n2 – 2 dl = dl associé à CMerreur

17
Particularité des combinaisons linéaires
Il faut savoir choisir les coefficients leur nombre ~ dltraitement deux avantages peuvent se calculer directement sous forme de SC peuvent être formulés de façon orthogonale seulement dans ce cas

18
Procédure de comparaisons multiples a priori: les combinaisons linéaires
Définition d’une combinaison linéaire Chaque contraste peut être testé

19
Comparaisons multiples a priori:
exemple de calculs (1) Gr. : 1. Addition 2. Rimes 3. Adjectifs 4. Images 5. Intentionel Moy 7.00 6.90 11.00 13.40 12.00 ÉT 1.83 2.13 2.49 4.50 3.74 H1: Intentionnel meilleur rappel que tous les autres groupes H2: Tous les autres groupes sont semblables L1: L2.1: L2.2: L2.3: Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes)? De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes
 Gr. : 1. Addition. 2. Rimes. 3. Adjectifs. 4. Images. 5. Intentionel. Moy ÉT H1: Intentionnel meilleur rappel que tous les autres groupes. H2: Tous les autres groupes sont semblables. L1: L2.1: L2.2: L2.3: Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT. Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes) De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes.")
20
Comparaisons multiples a priori:
exemple de calculs (2) Gr. : 1. Addition 2. Rimes 3. Adjectifs 4. Images 5. Intentionel Moy 7.00 6.90 11.00 13.40 12.00 ÉT 1.83 2.13 2.49 4.50 3.74 L1: L2.1: L2.2: L2.3: L1 = L2.1 = L2.2 = L2.3 = Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes)? De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes
 Gr. : 1. Addition. 2. Rimes. 3. Adjectifs. 4. Images. 5. Intentionel. Moy ÉT L1: L2.1: L2.2: L2.3: L1 = 9.7. L2.1 = L2.2 = L2.3 = 0.1. Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT. Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes) De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes.")
21
Comparaisons multiples a priori:
exemples de calculs (3) Gr. : 1. Addition 2. Rimes 3. Adjectifs 4. Images 5. Intentionel Moy 7.00 6.90 11.00 13.40 12.00 ÉT 1.83 2.13 2.49 4.50 3.74 Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes)? De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes L1 = 9.7 => SC1 = ((10) (9.7)2) / 20 = (9.7)2) / 2 = L2.1 = 10.5 => SC2 = ((10) (10.5)2) / 4 = / 4 = L2.2 = => SC3 = ((10) (-2.4)2) / 2 = / 2 = L2.3 = => SC4 = ((10) (0.1)2) / 2 = / 2 =
 Gr. : 1. Addition. 2. Rimes. 3. Adjectifs. 4. Images. 5. Intentionel. Moy ÉT Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT. Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes) De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes. L1 = 9.7 => SC1 = ((10) (9.7)2) / 20 = (9.7)2) / 2 = L2.1 = 10.5 => SC2 = ((10) (10.5)2) / 4 = / 4 = L2.2 = -2.4 => SC3 = ((10) (-2.4)2) / 2 = 57.6 / 2 = L2.3 = 0.1 => SC4 = ((10) (0.1)2) / 2 = 0.1 / 2 =")
22
Comparaisons multiples a priori:
exemple de calculs (3) Gr. : 1. Addition 2. Rimes 3. Adjectifs 4. Images 5. Intentionel Moy 7.00 6.90 11.00 13.40 12.00 ÉT 1.83 2.13 2.49 4.50 3.74 voir p. 313 Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes)? De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes L1 = 9.7 => / 9.67 = 4.86 L2.1 = 10.5 => / 9.67 = 28.49 L2.2 = => / 9.67 = 2.98 L2.3 = => 0.05
 Gr. : 1. Addition. 2. Rimes. 3. Adjectifs. 4. Images. 5. Intentionel. Moy ÉT voir p Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT. Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes) De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes. L1 = 9.7 => / 9.67 = L2.1 = 10.5 => / 9.67 = L2.2 = -2.4 => 28.8 / 9.67 = L2.3 = 0.1 =>")
23
Le tableau d’analyse de variance
Source de variation SC dl CM F p Traitement 351,52 4 87,88 9,08 < ,05 Contraste 1 47,04 1 4,86 Contraste 2 275,62 28,49 Contraste 3 28,80 2,98 > ,05 Contraste 4 0,05 0,005 erreur 435,30 45 9,67 Total 786,82 49

24
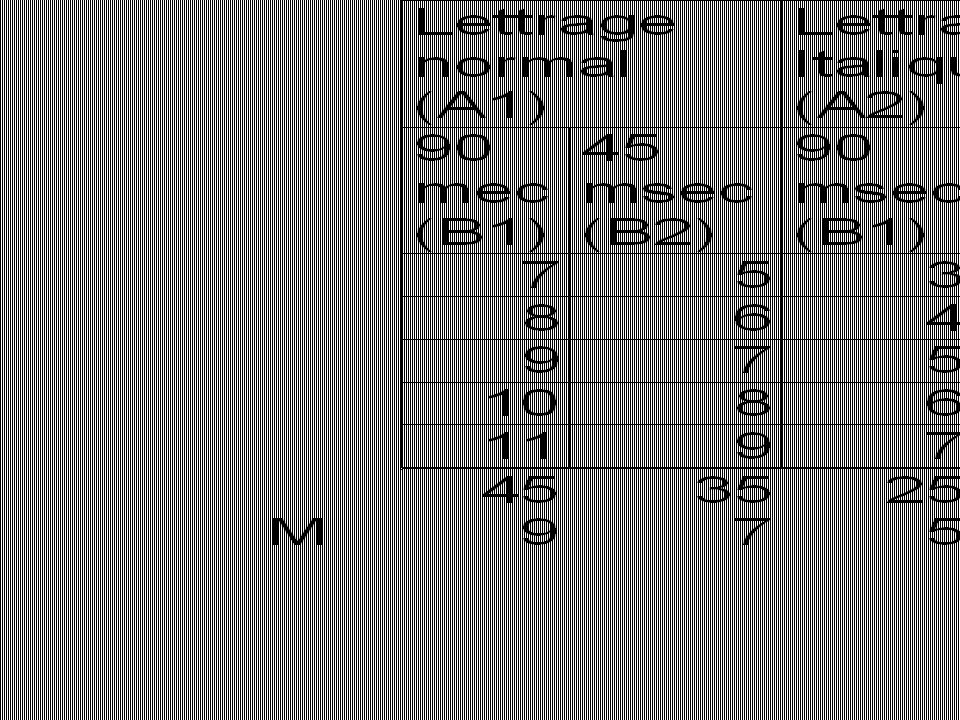
Un exemple de calcul I. Lettré, une chercheure de réputation internationale, présente des mots simples de type CVC (ex.: bol) en lettrage conventionnel ou en italique en des temps d’exposition courts et très courts. Elle enregistre le nombre d’erreurs d’identification de mots faites par les participants et participantes
 en lettrage conventionnel ou en italique en des temps d’exposition courts et très courts. Elle enregistre le nombre d’erreurs d’identification de mots faites par les participants et participantes.")
25
Le tableau d’analyse de variance

27
Combinaisons a priori (1)
")
28
Combinaisons a priori (2)
")
29
Procédures de comparaisons multiples a posteriori (1)
LSD: la plus petite différence significative suppose l’hypothèse nulle tests t Test de Scheffé test selon contraste linéaire mais ajuste la valeur critique de F par k-1 Pour Scheffé, voir les calculs diapo précédente en fait c’est le critère qui est modifié, au lieu d’avoir F(1, dlerreur) on a (k-1)*F((k-1), dlerreur), ici 4 (2,61) = 10,44 un seul des contrastes précédents est significatif. Pour le calcul fait en classe, les deux contrastes significatifs demeurent significatifs. F de Scheffé = 3 (3,24) = 9,72 c’est-à-dire
 on a (k-1)*F((k-1), dlerreur), ici. 4 (2,61) = 10,44. un seul des contrastes précédents est significatif. Pour le calcul fait en classe, les deux contrastes significatifs demeurent significatifs. F de Scheffé = 3 (3,24) = 9,72. c’est-à-dire.")
30
Procédures de comparaisons multiples a posteriori (2): procédures basées sur la loi de Student
Statistique de Student avec r et dl(erreur) comme dl Test de Newman-Keuls mise en ordre des moyennes selon leur taille comparaison de toutes les paires de moyennes en ajustant la distance entre celles-ci R est la distance entre les moyennes ordonnées sur une ligne Pour la plus grosse et la plus petite, r = k, mais pour les autres r < k Tableau des valeurs de q à la p. 701
 comme dl. Test de Newman-Keuls. mise en ordre des moyennes selon leur taille. comparaison de toutes les paires de moyennes en ajustant la distance entre celles-ci. R est la distance entre les moyennes ordonnées sur une ligne. Pour la plus grosse et la plus petite, r = k, mais pour les autres r < k. Tableau des valeurs de q à la p")
31
Comparaisons multiples a posteori: exemple de calculs (1)
Gr. : 1. Addition 2. Rimes 3. Adjectifs 4. Images 5. Intentionel Moy 7.00 6.90 11.00 13.40 12.00 ÉT 1.83 2.13 2.49 4.50 3.74 a) Réordonner les moyennes Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes)? De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes Gr. : 2. Rimes 1. Addition 3. Adjectifs 5. Intentionel 4. Images Moy 6.90 7.00 11.00 12.00 13.40 ÉT 2.13 1.83 2.49 3.74 4.50
 Réordonner les moyennes. Revenons à l’exemple 11.1 où nous avons les données d’une étude de Eysenck (1974). N.B.: J’utilise ici un exemple différent du livre. RÉÉXPLIQUER L’ÉTUDE BRIÈVEMENT. Les calculs d’ANOVA produisent un test F significatif. Comme ce test F comporte un dl au numérateur supérieur à 1, il est impossible de savoir d’où vient la différence prosduisant L,effet significatif. Assurément les moyennes de 7 et 6.9 sont semblables (je dis cela à cause des Déviations Standards, si celles –ci étaient 10 plus petites, je ne serais pas si sûr de mes conclusions), mais qu’en est-il des autres moyennes (par rapport à ces deux-là et par rapport à elles-mêmes) De plus, Eysenck est peut-être intéressé à certaines de ces comparaisons et pas à toutes. Gr. : 2. Rimes. 1. Addition. 3. Adjectifs. 5. Intentionel. 4. Images. Moy ÉT")
32
Comparaisons multiples a posteori: exemple de calculs (2a)
Gr. : 2. Ri-mes 1. Ad-dition 3. Ad-jectifs 5. Intentionel 4. Images Valeur critère de q Moy 6.90 7.00 11.00 12.00 13.40 2 Rim ---- 0.1 4.1 5.1 6.5 4.04 1 Add --- 4.0 5.0 6.4 3.79 3 Adj 1.0 2.4 3.44 5 Int 1.4 2.86 LSD: test t standard, utilise la table de t Procédure de Newman-Keuls critère différent selon le pas (distance entre les 2 moyennes à comparer) la valeur q est obtenue à partir de la table de q (Student) la valeur critère est égale au critère ajusté par le CMe (voir formule racine carrée de CMe divisé par n), ici 9.67 / 10, soit la racine carré de .967 0,983 4.04 x .983 = 3.97 2.83 x .983 = 2.78 Le test de Tukey n’utilise qu’une valeur de q et un seul critère. La procédure de Ryan et les autres consiste à calculer q, mais à ajuster le seuil alpha. La procédure de Dunnett utilise sa formule et sa table.
 la valeur q est obtenue à partir de la table de q (Student) la valeur critère est égale au critère ajusté par le CMe (voir formule racine carrée de CMe divisé par n), ici 9.67 / 10, soit la racine carré de , x .983 = x .983 = Le test de Tukey n’utilise qu’une valeur de q et un seul critère. La procédure de Ryan et les autres consiste à calculer q, mais à ajuster le seuil alpha. La procédure de Dunnett utilise sa formule et sa table.")
33
Comparaisons multiples a posteori: exemple de calculs (2b)
Gr. : 2. Ri-mes 1. Ad-dition 3. Ad-jectifs 5. Intentionel 4. Images q Moy 6.90 7.00 11.00 12.00 13.40 2 Rim ---- 0.1 4.2* 5.2* 6.6* 4.04 1 Add --- 4.1* 5.1* 6.5* 3.79 3 Adj 1.0 2.4 3.44 5 Int 1.4 2.86 LSD: test t standard, utilise la table de t Procédure de Newman-Keuls critère différent selon le pas (distance entre les 2 moyennes à comparer) la valeur q est obtenue à partir de la table de q (Student) la valeur critère est égale au critère ajusté par le CMe (voir formule racine carrée de CMe divisé par n), ici 9.67 / 10, soit la racine carré de .967 0,983 4.04 x .983 = 3.97 2.83 x .983 = 2.78 Le test de Tukey n’utilise qu’une valeur de q et un seul critère. La procédure de Ryan et les autres consiste à calculer q, mais à ajuster le seuil alpha. La procédure de Dunnett utilise sa formule et sa table.
 la valeur q est obtenue à partir de la table de q (Student) la valeur critère est égale au critère ajusté par le CMe (voir formule racine carrée de CMe divisé par n), ici 9.67 / 10, soit la racine carré de , x .983 = x .983 = Le test de Tukey n’utilise qu’une valeur de q et un seul critère. La procédure de Ryan et les autres consiste à calculer q, mais à ajuster le seuil alpha. La procédure de Dunnett utilise sa formule et sa table.")
34
Comparaisons multiples a posteori: exemple de calculs (2)
Gr. : 2. Ri-mes 1. Ad-dition 3. Ad-jectifs 5. Intentionel 4. Images Diffé-rence critique q Moy 6.90 7.00 11.00 12.00 13.40 2 Rim ---- 0.1 4.1* 5.1* 6.5* 3.97 4.04 1 Add --- 4.0* 5.0* 6.4* 3.73 3.79 3 Adj 1.0 2.4 3.38 3.44 5 Int 1.4 2.81 2.86 LSD: test t standard, utilise la table de t Procédure de Newman-Keuls critère différent selon le pas (distance entre les 2 moyennes à comparer) la valeur q est obtenue à partir de la table de q (Student) la valeur critère est égale au critère ajusté par le CMe (voir formule racine carrée de CMe divisé par n), ici 9.67 / 10, soit la racine carré de .967 0,983 4.04 x .983 = 3.97 2.83 x .983 = 2.78 Le test de Tukey n’utilise qu’une valeur de q et un seul critère. La procédure de Ryan et les autres consiste à calculer q, mais à ajuster le seuil alpha. La procédure de Dunnett utilise sa formule et sa table.
 la valeur q est obtenue à partir de la table de q (Student) la valeur critère est égale au critère ajusté par le CMe (voir formule racine carrée de CMe divisé par n), ici 9.67 / 10, soit la racine carré de , x .983 = x .983 = Le test de Tukey n’utilise qu’une valeur de q et un seul critère. La procédure de Ryan et les autres consiste à calculer q, mais à ajuster le seuil alpha. La procédure de Dunnett utilise sa formule et sa table.")
35
Écart studentisé: exemple de calcul (a)
avec r et dl(erreur) comme dl Gr. : Ital. 90 Norm.45 Norm. 90 Ital. 45 q Moy 5 7 9 13 ---- 2 4 8 4.05 Norm. 45 --- 6 3.65 3.00
 comme dl. Gr. : Ital. 90. Norm.45. Norm. 90. Ital. 45. q. Moy Norm")
36
Écart studentisé: exemple de calcul (b)
avec r et dl(erreur) comme dl Gr. : Ital. 90 Norm.45 Norm. 90 Ital. 45 q Moy 5 7 9 13 ---- 2.8 5.6* 11.3* 4.05 Norm. 45 --- 8.5* 3.65 3.00
 comme dl. Gr. : Ital. 90. Norm.45. Norm. 90. Ital. 45. q. Moy * 11.3* Norm *")
37
Écart studentisé: exemple de calcul
avec r et dl(erreur) comme dl Gr. : Ital. 90 Norm.45 Norm. 90 Ital. 45 Diff. critère q Moy 5 7 9 13 ---- 2 4* 8* 2.86 4.05 Norm. 45 --- 6* 2,58 3.65 2,12 3.00
 comme dl. Gr. : Ital. 90. Norm.45. Norm. 90. Ital. 45. Diff. critère. q. Moy * 8* Norm * 2, ,")
38
Procédures de comparaisons multiples a posteriori (3): procédures basées sur la loi de Student
HSD: Test de la différence franchement significative de Tukey ibid. à Newman-Keuls mais n’utlise qu’une seule valeur critique, la plus grande Procédure de Ryan (REGWQ)
")
39
Procédures de comparaisons multiples a posteriori (4)
Comparaisons à un groupe témoin: le test de Dunnett dl = dl associé à CMerreur Table de td, p. 710 Voir table de td

40
Comparaison des procédures
p. 388 dans le nouveau livre

41
Exemple d’effet simple
A1B1 9 A1B2 7 A2B1 5 A2B2 13 Σa2 ΣaX (ΣaX)2 n(ΣaX)2 1 -1 2 4 20 8 64 320 Effets simples
2. n(ΣaX) Effets simples.")
42
Le tableau d’analyse de variance

43
Variations sur combinaisons linéaires
F ou t? Procédures ajustant l’EC Dunn-Bonferronni Sidak Holm Lazarlee & Mulaik ajustement progressif alpha de Sidak = 0,

44
Variations sur les tests a posteori utilisant l’écart studentisé

Présentations similaires





 Combiner des apprenants: le boosting.>")



>")

.>")







