Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Bases de données en biologie (suite)
G. Almouzni (I. Curie)
")
2
Bases de données en biologie
Plan du cours (1) Bases de données en biologie Historique BD séquences généralistes - séquences nucléotidiques - séquences protéiques Rappels de BIO BD spécialisées - par organisme - par thématique (problématique bio) BD bibliographiques Violaine Pillet + Extraction d ’information à partir de textes Des bases de données aux bases de connaissances
 Bases de données en biologie. Historique. BD séquences généralistes. - séquences nucléotidiques. - séquences protéiques. Rappels de BIO. BD spécialisées. - par organisme. - par thématique (problématique bio) BD bibliographiques. Violaine Pillet. + Extraction d ’information à partir de textes. Des bases de données aux bases de connaissances.")
3
Banques de séquences généralistes
Séquences protéiques données expérimentales isolation, séquençage données in silico déduction à partir de la séquence nucléique par simple traduction Banques de séquences protéiques PIR-NBRF Swissprot

4
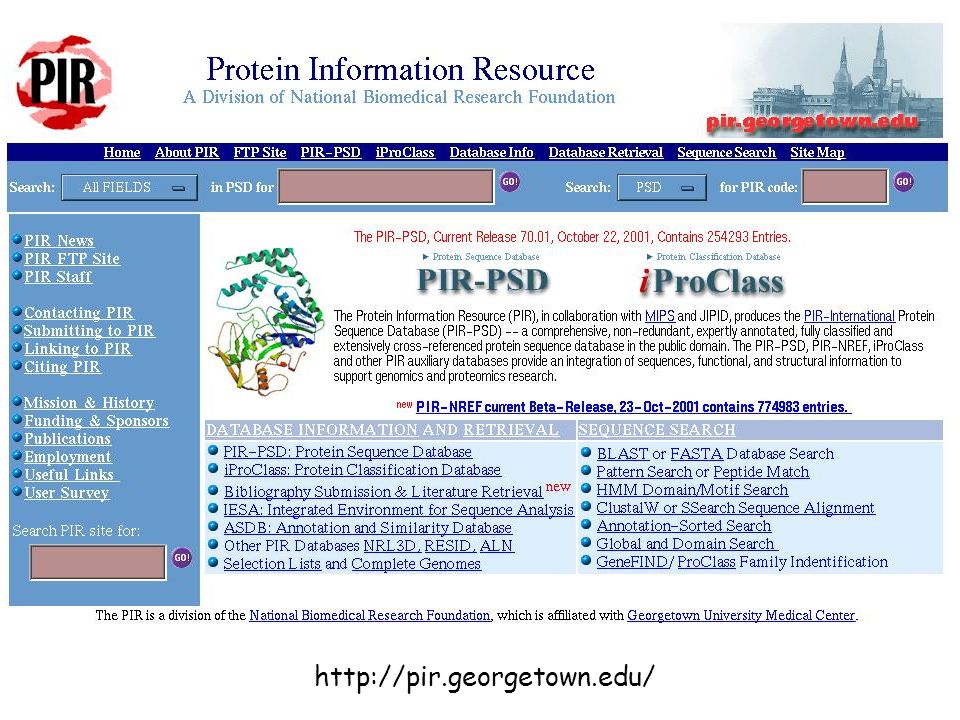
création 1984 données PIR-NBRF
NBRF (National Biomedical Research Foundation) données MIPS (Martinsried Institute for Protein Sequences, Munich) JIPID (Japan International Protein Information Database)
 données. MIPS (Martinsried Institute for Protein Sequences, Munich) JIPID (Japan International Protein Information Database)")
9
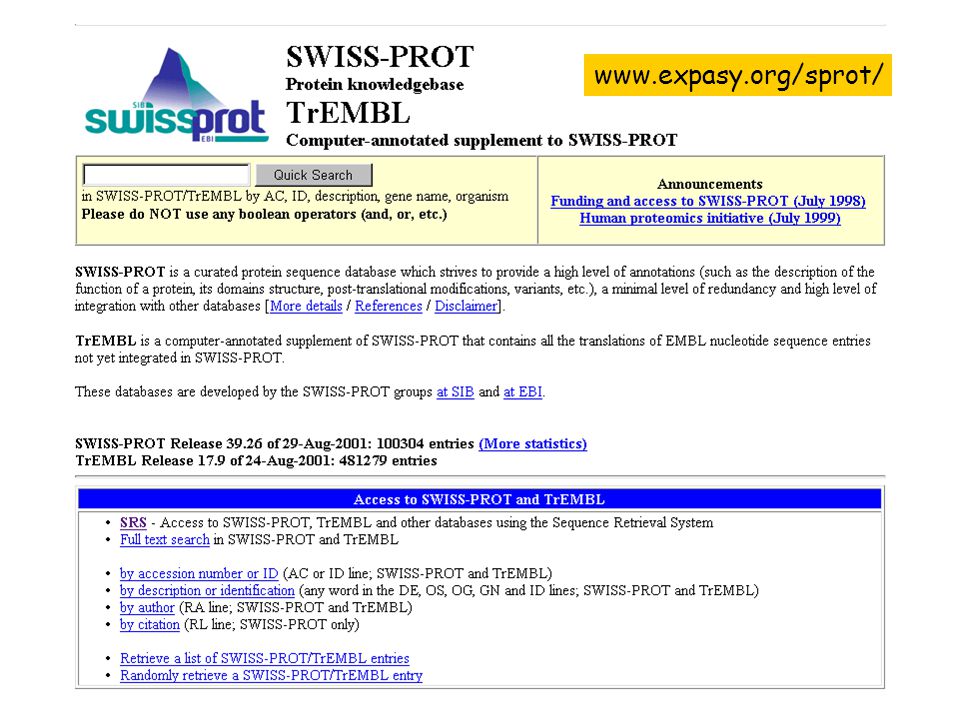
création 1986 données Swissprot Séquences banque PIR-NBRF
Amos Bairoch Université de Genève SIB: Swiss Institute of Bioinformatics Collaboration : SIB + EBI données Séquences banque PIR-NBRF Séquences banque EMBL (traduction) Chaque entrée de la base a été expertisée par un annotateur
 Chaque entrée de la base a été expertisée par un annotateur.")
11
Bases de données en biologie
Plan du cours Bases de données en biologie Historique BD séquences généralistes - séquences nucléotidiques - séquences protéiques Rappels de BIO BD spécialisées - par organisme - par thématique (problématique bio) Des bases de données aux bases de connaissances
 Des bases de données aux bases de connaissances.")
12
Des banques aux bases de séquences (1)
Forte croissance + hétérogénéité des séquences des banques généralistes constitution de bases de données par thématique par organisme espace de connaissances de références

13
Des banques aux bases de séquences (2)
bases de séquences dédiées à un organisme à des objets biologiques communs à plusieurs organismes travail important correction des erreurs élimination des doublons annotations

14
Bases de séquences spécialisées

16
Génomes procaryotes

17
Mais les données ne se limitent pas aux séquences...

18
BD biologie moléculaire

19
Données structurales : PDB

20
Navigation dans les bases

21
Bases de données en biologie
Plan du cours Bases de données en biologie Historique BD séquences généralistes - séquences nucléotidiques - séquences protéiques Rappels de BIO BD spécialisées - par organisme - par thématique (problématique bio) Des bases de données aux bases de connaissances
 Des bases de données aux bases de connaissances.")
22
Une multiplicité de bases de données hétérogènes
> 1000 BDs Ces BDs sont conçues pour répondre à des objectifs différents. Même si leurs contenues se recouvrent, leurs schémas conceptuels peuvent différer Schéma conceptuel = modèle dont la conception est pilotée par les questions qu’il doit permettre d’aborder Illusoire de penser construire un jour “ le ” système d’informations biologiques universel pluralité des problématiques pluralité des bases de données Mais, conséquences pratiques facheuses...

23
Une multiplicité de BDs hétérogènes : conséquences (1)
Recherche d ’informations Interroger plusieurs bases Relier entre elles les données extraites = Intégrer les données merci Internet Analyse d ’un petit nombre de séquences Démarche fastidieuse Analyse de résultats à grande échelle (génome, protéome, transcriptome,…) Démarche inenvisageable
 Démarche inenvisageable.")
24
Une multiplicité de BDs hétérogènes : conséquences (2)
Problème technique : Diversité des modèles et des formats des bases concernées. Cas favorable : s’adapter au modèle de chacune des bases. Cas moins favorable (mais plus fréquent) : les dites “ bases de données ” sont constituées de simples fichiers munis d’un langage d’interrogation et de manipulation ad hoc. Activité majeure des bioinformaticiens: Ecriture de scripts de lecture et de reformatage de données Pour formuler de bonnes requêtes : Connaître la structure et le schéma conceptuel des bases Souvent: schéma indisponible, inexistant,… Pb :connaître le nom d ’un champ ou d ’un enregistrement est insuffisant
 : les dites bases de données sont constituées de simples fichiers munis d’un langage d’interrogation et de manipulation ad hoc. Activité majeure des bioinformaticiens: Ecriture de scripts de lecture et de reformatage de données. Pour formuler de bonnes requêtes : Connaître la structure et le schéma conceptuel des bases. Souvent: schéma indisponible, inexistant,… Pb :connaître le nom d ’un champ ou d ’un enregistrement est insuffisant.")
25
INTEGRATION Une multiplicité de BDs hétérogènes
Volume de données : non limitant Problème majeur: HETEROGENEITE des données ( nature, formats) INTEGRATION Comment intégrer ces données biologiques, hétérogènes et distribuées, afin qu’elles soient accessibles et exploitables aussi facilement que si elles figuraient dans une seule et même base ?
 INTEGRATION. Comment intégrer ces données biologiques, hétérogènes et distribuées, afin qu’elles soient accessibles et exploitables aussi facilement que si elles figuraient dans une seule et même base")
26
Intégration de données hétérogènes
2 grandes catégories de solutions = ajouter, au-dessus des bases existantes, une couche logicielle offre les interfaces nécessaires entre les bases fait apparaître l’ensemble comme une seule base virtuelle Approche fédérative 1 (+) assure d’accéder à tout instant à des données qui sont à jour Entrepôts de données (data warehousing) 2 = restructurer les données au sein d ’un schéma unique les données des différentes bases concernées sont copiées de leurs bases d’origine (+) temps de traitement des requêtes (-) mises à jours Résoudre les problèmes d ’incompatibilité syntaxique et sémantique
 assure d’accéder à tout instant à des données qui sont à jour. Entrepôts de données (data warehousing) 2. = restructurer les données au sein d ’un schéma unique. les données des différentes bases concernées sont copiées de leurs bases d’origine. (+) temps de traitement des requêtes. (-) mises à jours. Résoudre les problèmes d ’incompatibilité syntaxique et sémantique.")
27
SRS - Sequence Retrieval System
1 Rajouter l ’URL

28
SRS - Sequence Retrieval System
1 SRS permet d ’accéder à différentes BDs via une interface unique Exemple: ExPASy: SWISS-PROT, TrEMBL (SPTR)
")
29
ENTREZ (NCBI) 1 ENTREZ
 1 ENTREZ")
30
Entrepôt de données 2 = restructurer les données au sein d ’un schéma unique Mise en correspondance des entités modélisées dans différents schémas conceptuels Rappel: la seule connaissance des noms est insuffisante schéma conceptuel accessible et correctement documenté Cependant, dans un schéma conceptuel, description minimale des entités (traitement des requêtes, administration de la base) Parfois, description sous forme de textes dans la documentation associée Expliciter et formaliser les entités manipulées
 Parfois, description sous forme de textes dans la documentation associée. Expliciter et formaliser les entités manipulées.")
31
Des bases de données aux bases de connaissances...
Représentation de connaissances François Rechenmann Danielle Ziébelin : AROM

32
Des bases de données aux bases de connaissances
Modéliser plus finement les classes d’entités, ainsi que les relations qu’elles entretiennent non plus seulement à des fins de requêtes et de gestion mais pour expliciter formellement leurs définitions bases de données base de connaissances Ontologie : formalisation des concepts d’un domaine et des relations qu’ils entretiennent Une ontologie n’est pas réductible à la constitution d’un vocabulaire En pratique, le schéma d’une base de connaissance correspond = mise en œuvre de l’ontologie retenue

33
Bases de connaissances
Les modèles de connaissances offrent une capacité d ’expression permettant d’aborder la représentation de données plus complexes que celles qui apparaissent traditionnellement dans les bases Champs texte (langage naturel) Lisible et interprétable par un humain Exploitation automatique très délicate Ex: champ fonction
 Lisible et interprétable par un humain. Exploitation automatique très délicate. Ex: champ fonction.")
34
• Syntactic Annotation
Genome annotation DNA sequence • gene products • operator families • Sequence similarity • CDSs, RNAs • Regulation signals • Repeats... etc • Syntactic Annotation Feature detection by content Objects Seq • Functional Annotation « function » attribution A brief overview of the different levels in the process of genome annotation: First: the syntactic level aims at detect features. A feature is an entity associated to a nucleic sequence. For instance, CDSs, Regulation signals and so on. Features are detected by content. Then, the functional annotation level, which correpond to function attribution to the features previously detected.For instance, function associated to gene products, ... Usually, this is done by similarity. These entities can be represented by objects. Finally, relational annotation consists in establishing the relations which exist between these entities. It allows, analysis of metabolic pathways or genetic networks. Generally, only the first 2 levels: syntactic annotation and functional annotation are described in sequence databases, like gb, EMBL or SP. Our objective, is to integrate these heterogenous data into a single system in order to represent …. • Relational / Context Annotation ?

35
Relational Annotation
• Comparative genomics • Genetic networks • Molecular assemblies ABC tranporters Fichant et al. • Metabolic pathways

36
Panoramix KBs Proteix Genomix Metabolix EC EC EC EC Chromosome A
Chromosome B Genomix Metabolix molecular assembly biochemical reactions compounds (e.g. sugar...) EC enzyme gene polypeptide
 EC. enzyme. gene. polypeptide.")
37
Fini pour aujourd’hui...

38
ENTREZ - BLAST

39
Les limites des bases de séquences...
Hétérogénéité dans la nature des séquences Variabilité de l ’état des connaissances sur les séquences Erreurs dans les séquences Biais d ’échantillonage A voir ???

40
BDs: ATTENTION ! Databases: nombreuses erreurs (annotation automatique) ! Toutes les BDs ne sont pas disponibles sur tous les serveurs Problème de synchronisation des mises à jour Références croisées Compatibilité syntaxique Format Compatibilité sémantique Biologiste + bio-informaticien

41
Recherche de la BD idéale
Prolifération de BDs Recherche de la BD idéale Analyse de séquences Données de bonne qualité Complète, détaillée Remise à jour Peu redondante Indexée pour pouvoir poser des requêtes compliquées Quel site répond le plus rapidement …….??????

Présentations similaires



>")

 Jean-Philippe KOTOWICZ (INSA Rouen)>")






>")









