Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
La pondération de l’enquête Sans Domicile 2012
Colloque Sondages La pondération de l’enquête Sans Domicile 2012 Ensai Novembre 2012 Lionel Viglino et Sylvain Quenum

2
Proba d’inclusion des contacts
Le vif du sujet : Proba d’inclusion des contacts

3
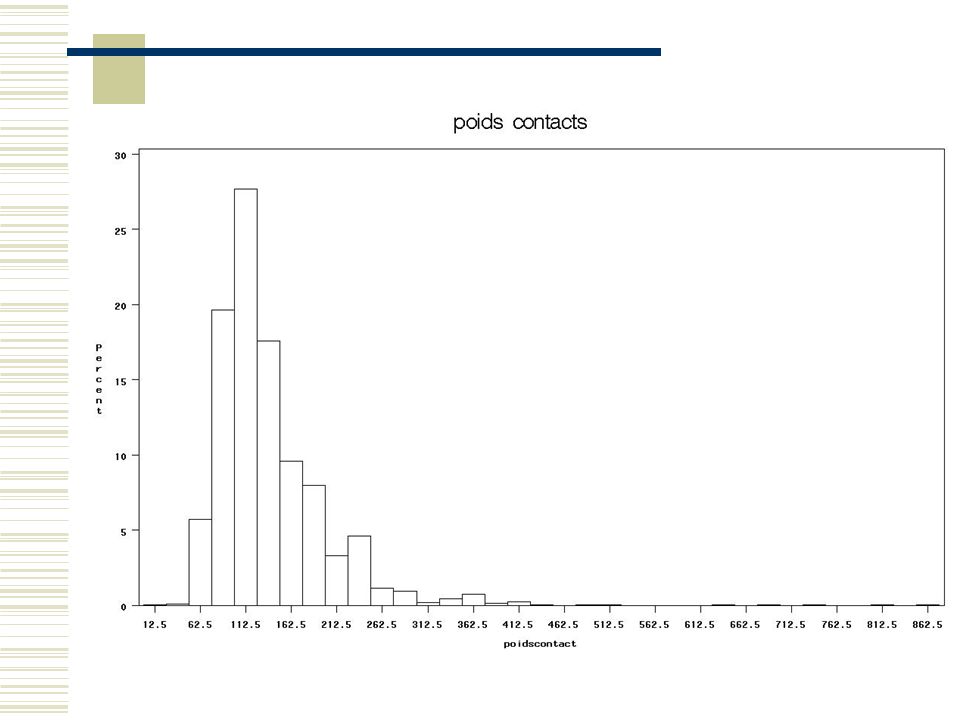
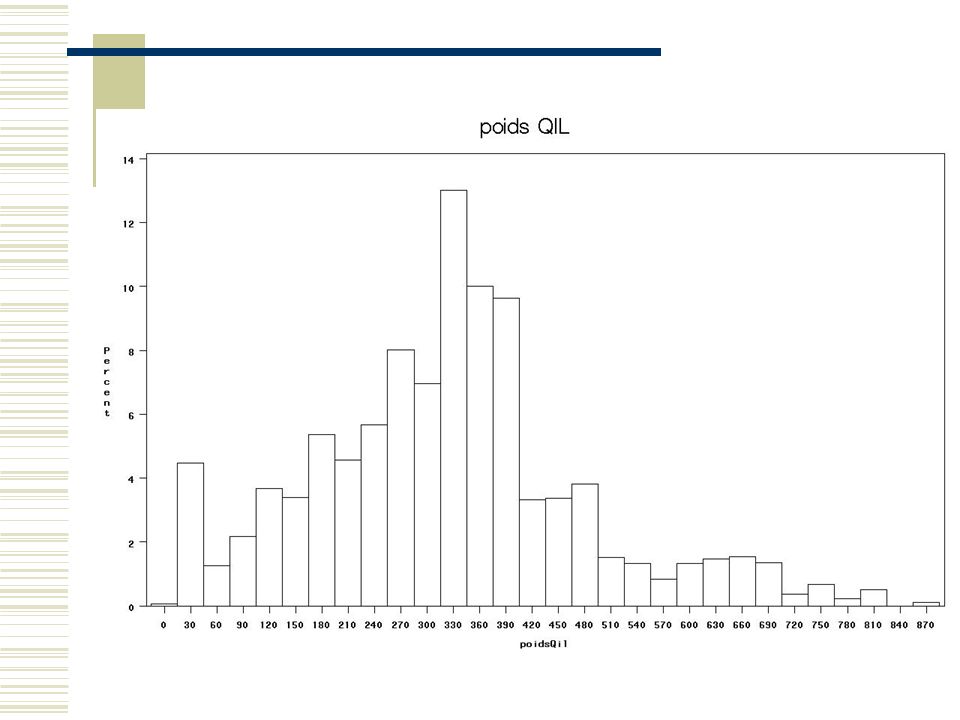
Le vif du sujet : Poids des (questions des) QIL :
on répartit le poids des contacts francophones sur les QIL

4
Proba d’inclusion des (questions des) QIL :
Le vif du sujet : Proba d’inclusion des (questions des) QIL :
 QIL :")
5
Le vif du sujet : Le nombre de Sans Domicile francophones :
avec les QIL car le semainier est de meilleure qualité Nombre de SD (sur agglo ) avec la somme du poids des contacts/nb de lien (mais semainier moins précis) Nombre de SD France entière avec les agglos de – : - plus grossier : nombre de SD et prorata selon fréquentation déclarée dans la base de sondage - modèle selon taille pour et on prolonge - utilisation de la collecte INED sur , test sur constance du nombre de liens, remplacement info de la base de sondage sur les communes enquêtées...
 avec la somme du poids des contacts/nb de lien (mais semainier moins précis) Nombre de SD France entière avec les agglos de – : - plus grossier : nombre de SD et prorata selon fréquentation déclarée dans la base de sondage. - modèle selon taille pour et on prolonge. - utilisation de la collecte INED sur , test sur constance du nombre de liens, remplacement info de la base de sondage sur les communes enquêtées...")
6
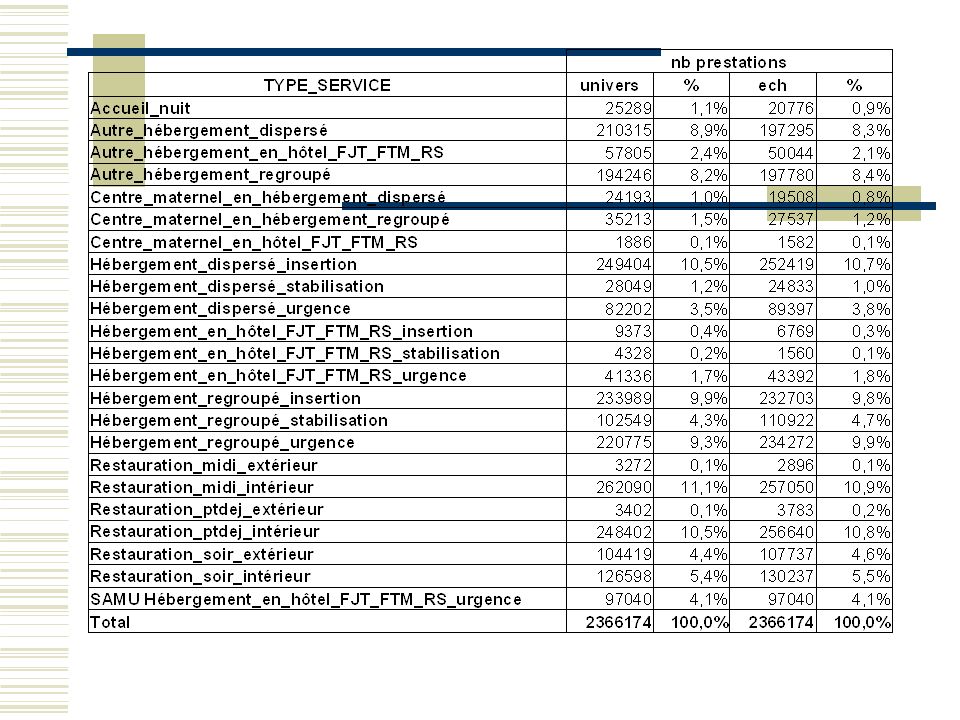
Quelle base de sondage? par définition la population cible n’a pas de résidence propre fixe qu’on puisse sélectionner directement Il existe une solution théorique, le sondage indirect : on échantillonne les lieux que fréquentent régulièrement les personnes ciblées pour arriver ensuite à y sélectionner les individus à enquêter On applique le partage des poids (nbre de liens) Individus à enquêter: (du coup le champ de l’enquête) les personnes adultes qui fréquentent les services d’aide gratuits (ou de l’ordre d’1 euro symbolique). Ne sont pas tous sans-abris au sens habituel des SDF, car peuvent avoir leur logement, mais manger aux restos du cœur. Lieux: services d’hébergement, de distribution de repas (petit déjeuner, déjeuner, diner) ou de halte de nuit.
 Individus à enquêter: (du coup le champ de l’enquête) les personnes adultes qui fréquentent les services d’aide gratuits (ou de l’ordre d’1 euro symbolique). Ne sont pas tous sans-abris au sens habituel des SDF, car peuvent avoir leur logement, mais manger aux restos du cœur. Lieux: services d’hébergement, de distribution de repas (petit déjeuner, déjeuner, diner) ou de halte de nuit.")
7
Exhaustivité? Recensement de tous les services d’aides gratuit du champ => enquête téléphonique Ambition d’exhaustivité des services, mais pas indispensable car on cible les usagers Taux de couverture assuré (pas de biais) si pour chaque individu du champ, il existe au moins un service qu’il fréquente dans notre base de services Collecte l’hiver Services du champ: exemple d’exclusion du champ, les haltes de jour (pas de repas servi, tout juste un café, pas suffisant pour présumer d’une situation de grande précarité, cela peut juste être un point de rencontre de chomeurs pour se chauffer ou discuter quelques heures mais qui sont autonomes pour se nourrir et se loger). Pas indispensable exhaustivité des services : exemple, on n’inclut pas dans notre base de sondage finale les services de petits déjeuners accolés à un service d’hébergement où tous (au moins 80%, car pas évident de garantir 100%) les usagers qui mangent, ont aussi dormis sur place. On inclut juste le service d’hébergement, cela suffit pour avoir l’opportunité de sélectionner tous ces usagers au moins une fois. L’inconvénient d’inclure le petit déjeuner est qu’en cas de tirage des 2 services, on a une forte probabilité d’interroger systématiquement 2 fois les mêmes personnes (gachis de taille d’échantillon). On est rassuré aussi, au pire si on rate des services, les résultats ne sont pas biaisés, sauf si on rate des services fréquentés par des individus qui ne fréquentent que ceux-là, donc pas joignable par un de nos services dans notre base. Par précaution, l’effort a été fait pour recenser « tous » les services (le max connu par tous les moyens). On collecte l’hiver pour minimiser le nombre de sans-abris purs, ne dormant dans aucun centre d’hebergement gratuit et ne mangeant dans aucune distribution de repas.
 si pour chaque individu du champ, il existe au moins un service qu’il fréquente dans notre base de services. Collecte l’hiver. Services du champ: exemple d’exclusion du champ, les haltes de jour (pas de repas servi, tout juste un café, pas suffisant pour présumer d’une situation de grande précarité, cela peut juste être un point de rencontre de chomeurs pour se chauffer ou discuter quelques heures mais qui sont autonomes pour se nourrir et se loger). Pas indispensable exhaustivité des services : exemple, on n’inclut pas dans notre base de sondage finale les services de petits déjeuners accolés à un service d’hébergement où tous (au moins 80%, car pas évident de garantir 100%) les usagers qui mangent, ont aussi dormis sur place. On inclut juste le service d’hébergement, cela suffit pour avoir l’opportunité de sélectionner tous ces usagers au moins une fois. L’inconvénient d’inclure le petit déjeuner est qu’en cas de tirage des 2 services, on a une forte probabilité d’interroger systématiquement 2 fois les mêmes personnes (gachis de taille d’échantillon). On est rassuré aussi, au pire si on rate des services, les résultats ne sont pas biaisés, sauf si on rate des services fréquentés par des individus qui ne fréquentent que ceux-là, donc pas joignable par un de nos services dans notre base. Par précaution, l’effort a été fait pour recenser « tous » les services (le max connu par tous les moyens). On collecte l’hiver pour minimiser le nombre de sans-abris purs, ne dormant dans aucun centre d’hebergement gratuit et ne mangeant dans aucune distribution de repas.")
8
Coût limité? Coûts déplacement enquêteur, recensement services
Tirage d’unités primaires : 2 strates : tirage 80 agglomérations de plus de hbts et 80 agglomérations comprises entre 5000 et hbts proportionnellement à leur population municipale 2006 seuil d’exhaustivité à hbts équilibrage sur la capacité Finess, le nombre de sans-abri estimé dans le recensement et les indicatrices des zones 'Sud', 'Est' et 'Reste' Trop couteux de recruter et envoyer des enquêteurs partout en France et pour de petites charges de collecte, donc besoin de concentrer. De plus, trop fastidueux de recenser tous les services partout en France par les DR, donc concentrer sur nombre limité d’agglos. Pas de tirage dans la strate agglos des moins de 5000hbts car pas de service, tout au plus 1 chambre à la paroisse par ci par là, rapport cout/benefice trop important Pop municipale 2006 car pas de source donnant le nombre d’individus du champ (on suppose nb individus champ proportionnel à taille agglo, donc bon cas à proba inegale réduisant la variance de l’estimateur du nombre d’individus). 30 agglomérations sont dans la strate exhaustive, la plus petite étant celle de Brest avec hbts. Equilibrage car capacité finess (de la DREES) ne concerne que les places d’hebergement, sans-abri RP est une source « peu » fiable et sur qu’une partie champ de l’enquete Tirage avec fast cube et un relâchement progressif des contraintes dans l'ordre inverse
. 30 agglomérations sont dans la strate exhaustive, la plus petite étant celle de Brest avec hbts. Equilibrage car capacité finess (de la DREES) ne concerne que les places d’hebergement, sans-abri RP est une source « peu » fiable et sur qu’une partie champ de l’enquete. Tirage avec fast cube et un relâchement progressif des contraintes dans l ordre inverse.")
9
Cœur de cible des individus
Les francophones: Questionnaire long QIL face à face en priorité mais inclusion des non francophones dans le champ de l’enquête réédition 2012 Questionnaire auto-administré QAA court traduit Les sans-abri: surreprésentation (5/3) des services de repas extérieurs, haltes de nuit et plans grand froid Un francophone : capable de répondre à un questionnaire long(1h) en français. On peut distribuer un QAA aussi à un francophone, ou un QIC questionnaire face à face court en cas de réinterrogation. Non francophones QAA traduit en 14 langues En 2001, moins de 200 sans-abris parmi 4000 répondants. Donc, en 2012, surreprésentation des lieux qu’ils fréquentent pour en avoir plus Plan grand froid: service d’hebergement ouvert exclusivement en cas de grand froid sur decision du prefet (ou maire de grande ville)
 des services de repas extérieurs, haltes de nuit et plans grand froid. Un francophone : capable de répondre à un questionnaire long(1h) en français. On peut distribuer un QAA aussi à un francophone, ou un QIC questionnaire face à face court en cas de réinterrogation. Non francophones QAA traduit en 14 langues. En 2001, moins de 200 sans-abris parmi 4000 répondants. Donc, en 2012, surreprésentation des lieux qu’ils fréquentent pour en avoir plus. Plan grand froid: service d’hebergement ouvert exclusivement en cas de grand froid sur decision du prefet (ou maire de grande ville)")
10
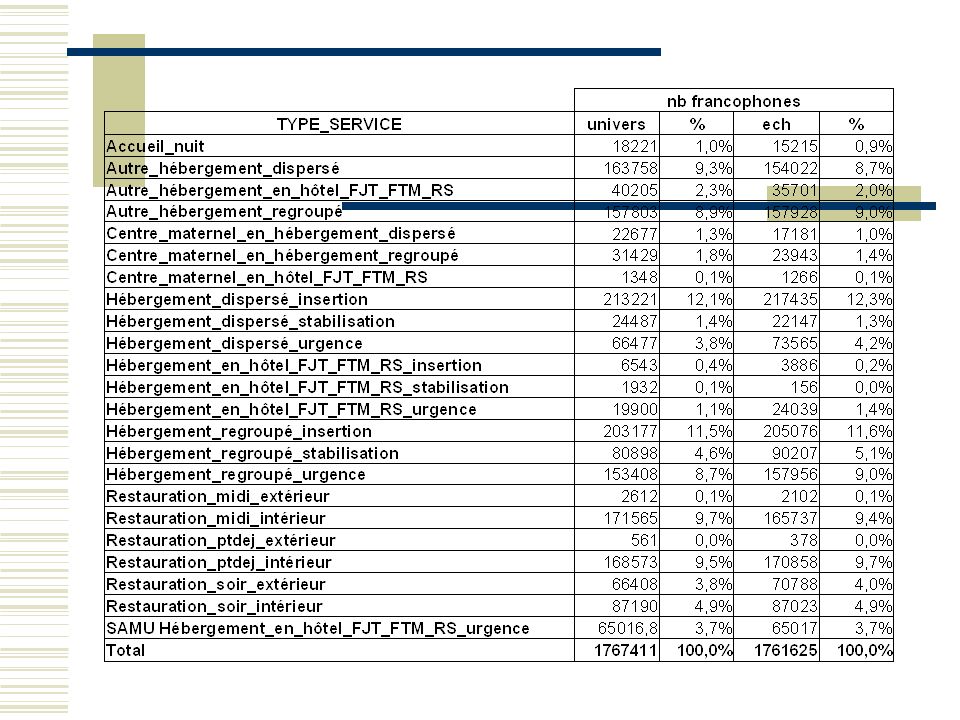
Les non francophones modes de sélection, de questionnement et donc de pondération différenciés pour les francophones F et non francophones NF Dès lors, besoin de connaître les nombres - ou du moins, les proportions - de francophones au sein des services d’aide Proportion NF non connue à l’avance: au moment du tirage des services x jours besoin d’estimation terrain lors de la collecte 1.1.1 Une nouveauté dans l’enquête téléphonique : Les responsables des structures d’aide ont fourni, lors de l’enquête téléphonique, le taux de non francophones pour chaque service. Cependant ces taux sont bien souvent surévalués car ils confondent souvent la nationalité avec la pratique de la langue française. Ainsi, ces responsables peuvent classer un sénégalais comme non francophone, alors même qu’il est francophone. 1.1.2 Une vérification lors du test terrain n°1 : Grâce à un comptage des non francophones réalisé par l’Ined en parallèle de la collecte du test terrain n°1 de janvier 2011, on a pu confirmer cette surestimation : au lieu des 32% de non francophones annoncés par les structures sur l’ensemble, l’Ined en a décompté 7% au total. 1.1.3 Pas de stratification selon ce critère de la langue: On ne retient donc pas le critère de tranche de taux de non francophones pour stratifier. Par ailleurs, l’Ined réalise la collecte des services avec plus de 75% de non francophones (selon l’indication de l’enquête téléphonique), au sein des 5 régions suivantes (potentiellement 21 agglomérations) : Ile-de-France, Alsace, Midy-Pyrénées, Rhône-Alpes, Paca. Du fait que la proportion de non francophones connue a priori est de mauvaise qualité, il n’est pas retenu de stratifier par ce critère pour fixer une allocation par organisme Insee/Ined. On atteindra la taille d’échantillon souhaitée pour l’Insee par simulations successives. Enfin, on tire les services x jours proportionnellement à leur fréquentation totale, et non leur fréquentation en francophones. 1.1.4 Une estimation de la part de non francophones sur le terrain: Lors de la collecte, on va estimer la proportion de non francophones au sein de chaque service visité par une méthode ad hoc, et ainsi pouvoir donner un poids d’échantillonnage à chaque personne francophone interrogée en face à face. Cette méthode va consister à fixer par service un nombre minimum de contacts obligatoires à effectuer à intervalles réguliers dans la file d’attente ou la liste de lits. L’enquêteur prendra alors pour prétexte la distribution d’un questionnaire administré disponible en 15 langues (dont le français) pour distinguer les non francophones, ce qui nous permettra d’estimer a posteriori la proportion de francophones.
, au sein des 5 régions suivantes (potentiellement 21 agglomérations) : Ile-de-France, Alsace, Midy-Pyrénées, Rhône-Alpes, Paca. Du fait que la proportion de non francophones connue a priori est de mauvaise qualité, il n’est pas retenu de stratifier par ce critère pour fixer une allocation par organisme Insee/Ined. On atteindra la taille d’échantillon souhaitée pour l’Insee par simulations successives. Enfin, on tire les services x jours proportionnellement à leur fréquentation totale, et non leur fréquentation en francophones Une estimation de la part de non francophones sur le terrain: Lors de la collecte, on va estimer la proportion de non francophones au sein de chaque service visité par une méthode ad hoc, et ainsi pouvoir donner un poids d’échantillonnage à chaque personne francophone interrogée en face à face. Cette méthode va consister à fixer par service un nombre minimum de contacts obligatoires à effectuer à intervalles réguliers dans la file d’attente ou la liste de lits. L’enquêteur prendra alors pour prétexte la distribution d’un questionnaire administré disponible en 15 langues (dont le français) pour distinguer les non francophones, ce qui nous permettra d’estimer a posteriori la proportion de francophones.")
11
Les services x jours 80 agglomérations > 20000 hbts:
2 vides de service (dont monaco!), 3 ont trop peu 75 agglos conservées, repondérées 80 agglomérations entre 5000 et hbts: 29 avec au moins 1 service Collecte Ined que dans 13 agglos, inférence à voir Unités secondaires : Tirage de 1300 services x jours, stratifié Proportionnellement à la fréquentation F+NF Tirage d’une visite par service pour les <20000 Plus de 20000: 1302 services trouvés -deux agglos ne comportent aucun service dans le champ : "Cavaillon" et "Menton-Monaco (partie française)". - 3 agglomérations "Chantilly", "Concarneau" et "Eu" sont exclues également du tirage de deuxième degré car : - elles comportent trop peu de services pour justifier le recrutement d’une équipe d’enquêteurs : un maximum de 6 prestations offertes réparties dans seulement 1 à 2 services en base de sondage, a fortiori encore moins dans l’échantillon. De plus, elles sont beaucoup trop éloignées des autres agglomérations pour qu’il soit rentable de faire déplacer une équipe d’enquêteurs basée ailleurs afin d’y réaliser la collecte. Cela conduit à exclure avec leur pondération 132 prestations (soit 0,1%) de la base de sondage, ce qui est acceptable. - l’agglomération de « Saint-Chamond » ne totalise que 4 prestations offertes réparties dans seulement 2 services en base de sondage. Cela conduirait à une seule visite tirée au deuxième degré. Cette agglomération est tout de même conservée car proche de celle de « Saint-Etienne » et de ses enquêteurs. Entre 5000 et 20000hbts: 79 services trouvés Il n’est pas prévu de collecte terrain réalisée par l’Insee au sein des 29 agglomérations non vides en services. Le tirage de deuxième degré s’effectue uniquement dans les 13 agglomérations où l’Ined accepte de réaliser la collecte terrain. Ces 13 agglomérations comportent 41 services d’aide gratuits. Definition service x jour : Il peut y avoir plusieurs services à une même adresse mais chacun de type différent. Un service offre en général ses prestations plusieurs jours par semaine, mais une seule fois au sein d’une même journée : une restauration est par exemple séparée en 3 services de différents types : 1 pour le petit-déjeuner, 1 pour le midi et 1 pour le soir. Le champ de la collecte couvre les jours du lundi au samedi midi, sur la période du 23 janvier au 18 février Ainsi, un service x jour est un couple (service, jour) : par exemple le centre d’hébergement regroupé en urgence à l’adresse X du lundi 23 janvier. La collecte pour un service x jour échantillonné s’effectue lors d’une visite sur site d’une équipe d’enquêteurs le jour prévu. Pour cette raison on assimile aussi un service x jour à une visite. Tirage services x jours : Stratification par agglomération (besoin respect prévision de charge 6 mois avant) et par type de service dans grandes agglos, tri sur fichier pour petites. Autres stratifications, non présentées ici par soucis de simplification. Frequentation NF+F: frequentation habituelle (sans distinction F et NF, car NF non fiable au moment tirage), les responsables de structures nous donnent un seul chiffre de fréquentation habituelle moyenne, ou deux bornes, on prend alors le centre de l’intervalle. 1.1 Les tailles d’échantillons: 1.1.1 les agglomérations de plus de 20 000 hbts : La taille de l’échantillon des services x jours au sein des agglomérations de plus de 20 000 hbts est d’environ 1300 pour les visites réalisées par l’Insee. Ce nombre est déduit de la cible minimale de 4000 personnes francophones répondantes (collecte Insee+Ined), sous la contrainte du coût de la collecte dévolue à l’Insee, et d’une hypothèse de nombre moyen de répondants par visite. Par ailleurs, il est prévu 2 réserves de 10%, soit environ 130 services x jours chacune (cf. partie 5). Le tirage des services x jours s’effectue proportionnellement à leur taille (en fréquentation journalière moyenne en tenant compte des jours d’ouverture). 1.1.2 les agglomérations comprises entre 5 000 hbts et 20 000 hbts : Pour les 13 agglomérations où l’Ined réalise la collecte, tous les services sont visités une seule fois. Le tirage de deuxième degré ne consiste plus qu’à sélectionner un jour de visite pour chaque service, par sondage aléatoire simple. La strate est au niveau du service et la surreprésentation est implicite dans le sens où l’on sélectionne toujours un seul jour, quelle que soit la durée de la période d’ouverture du service (nombre de jours ouverts sur les 4 semaines de collecte). En effet, les fréquentations sont jugées trop faibles (de l’ordre de la vingtaine au maximum) pour y retourner plusieurs fois. L’échantillon des services x jours est de taille 41.
, 3 ont trop peu. 75 agglos conservées, repondérées. 80 agglomérations entre 5000 et hbts: 29 avec au moins 1 service. Collecte Ined que dans 13 agglos, inférence à voir. Unités secondaires : Tirage de 1300 services x jours, stratifié. Proportionnellement à la fréquentation F+NF. Tirage d’une visite par service pour les < Plus de 20000: 1302 services trouvés. -deux agglos ne comportent aucun service dans le champ : Cavaillon et Menton-Monaco (partie française) agglomérations Chantilly , Concarneau et Eu sont exclues également du tirage de deuxième degré car : - elles comportent trop peu de services pour justifier le recrutement d’une équipe d’enquêteurs : un maximum de 6 prestations offertes réparties dans seulement 1 à 2 services en base de sondage, a fortiori encore moins dans l’échantillon. De plus, elles sont beaucoup trop éloignées des autres agglomérations pour qu’il soit rentable de faire déplacer une équipe d’enquêteurs basée ailleurs afin d’y réaliser la collecte. Cela conduit à exclure avec leur pondération 132 prestations (soit 0,1%) de la base de sondage, ce qui est acceptable. - l’agglomération de « Saint-Chamond » ne totalise que 4 prestations offertes réparties dans seulement 2 services en base de sondage. Cela conduirait à une seule visite tirée au deuxième degré. Cette agglomération est tout de même conservée car proche de celle de « Saint-Etienne » et de ses enquêteurs. Entre 5000 et 20000hbts: 79 services trouvés. Il n’est pas prévu de collecte terrain réalisée par l’Insee au sein des 29 agglomérations non vides en services. Le tirage de deuxième degré s’effectue uniquement dans les 13 agglomérations où l’Ined accepte de réaliser la collecte terrain. Ces 13 agglomérations comportent 41 services d’aide gratuits. Definition service x jour : Il peut y avoir plusieurs services à une même adresse mais chacun de type différent. Un service offre en général ses prestations plusieurs jours par semaine, mais une seule fois au sein d’une même journée : une restauration est par exemple séparée en 3 services de différents types : 1 pour le petit-déjeuner, 1 pour le midi et 1 pour le soir. Le champ de la collecte couvre les jours du lundi au samedi midi, sur la période du 23 janvier au 18 février Ainsi, un service x jour est un couple (service, jour) : par exemple le centre d’hébergement regroupé en urgence à l’adresse X du lundi 23 janvier. La collecte pour un service x jour échantillonné s’effectue lors d’une visite sur site d’une équipe d’enquêteurs le jour prévu. Pour cette raison on assimile aussi un service x jour à une visite. Tirage services x jours : Stratification par agglomération (besoin respect prévision de charge 6 mois avant) et par type de service dans grandes agglos, tri sur fichier pour petites. Autres stratifications, non présentées ici par soucis de simplification. Frequentation NF+F: frequentation habituelle (sans distinction F et NF, car NF non fiable au moment tirage), les responsables de structures nous donnent un seul chiffre de fréquentation habituelle moyenne, ou deux bornes, on prend alors le centre de l’intervalle. 1.1 Les tailles d’échantillons: les agglomérations de plus de hbts : La taille de l’échantillon des services x jours au sein des agglomérations de plus de hbts est d’environ 1300 pour les visites réalisées par l’Insee. Ce nombre est déduit de la cible minimale de 4000 personnes francophones répondantes (collecte Insee+Ined), sous la contrainte du coût de la collecte dévolue à l’Insee, et d’une hypothèse de nombre moyen de répondants par visite. Par ailleurs, il est prévu 2 réserves de 10%, soit environ 130 services x jours chacune (cf. partie 5). Le tirage des services x jours s’effectue proportionnellement à leur taille (en fréquentation journalière moyenne en tenant compte des jours d’ouverture) les agglomérations comprises entre hbts et hbts : Pour les 13 agglomérations où l’Ined réalise la collecte, tous les services sont visités une seule fois. Le tirage de deuxième degré ne consiste plus qu’à sélectionner un jour de visite pour chaque service, par sondage aléatoire simple. La strate est au niveau du service et la surreprésentation est implicite dans le sens où l’on sélectionne toujours un seul jour, quelle que soit la durée de la période d’ouverture du service (nombre de jours ouverts sur les 4 semaines de collecte). En effet, les fréquentations sont jugées trop faibles (de l’ordre de la vingtaine au maximum) pour y retourner plusieurs fois. L’échantillon des services x jours est de taille 41.")
12
Tirage des individus Le troisième degré : tirage en 2 phases
sélection d’un certain nombre d’individus - dits contacts - selon la taille du service (en usagers) et dans la limite de 16. Ils servent à estimer la proportion de non francophones et à fournir des données de calage (sexe) puis, sélection de personnes francophones parmi les individus de la première phase, dans la limite de 4 => QIL, QAA pour autres QIC: questionnaire court si déjà interrogé Protocole astucieux de sélection des rangs de tirage des 16 individus : avec technique de remplacement pour maximiser chance obtention QIL Hypothèse: methode aleatoire, et à la fin, pondération pseudo-calée des Qil : frequentation x (1-txNF) / nbQIL Calage: QIL sur QIL+QAA pour NF et sexe au niveau semi-agrégé, en l’absence de source externe de calage
 et dans la limite de 16. Ils servent à estimer la proportion de non francophones et à fournir des données de calage (sexe) puis, sélection de personnes francophones parmi les individus de la première phase, dans la limite de 4 => QIL, QAA pour autres. QIC: questionnaire court si déjà interrogé. Protocole astucieux de sélection des rangs de tirage des 16 individus : avec technique de remplacement pour maximiser chance obtention QIL. Hypothèse: methode aleatoire, et à la fin, pondération pseudo-calée des Qil : frequentation x (1-txNF) / nbQIL. Calage: QIL sur QIL+QAA pour NF et sexe au niveau semi-agrégé, en l’absence de source externe de calage.")
13
Exemple table de tirage

14
Pondération théorique
Probabilité inclusion au niveau contact(3 degrés) Poids contact (1ere phase): Poids QIL (1ere et 2eme phases)
 Poids contact (1ere phase): Poids QIL (1ere et 2eme phases)")
15
Recherche équipondération
Au sein des agglos de plus de hbts Lors tirage des services x jours (m inconnu) Niveau contact ou francophone? Cœur de cible francophones, mais p non encore connu Donc mise en œuvre niveau contact P0=cste (au facteur alpha de surreprésentation près) On cherche à assurer une équipondération théorique des individus (excepté les surreprésentations définies partie 2.4) pour ne pas donner des poids trop différenciés aux différentes personnes interrogées. On limite ainsi la variance d’échantillonnage qui traduit le fait qu’un individu atypique et avec un gros poids d’échantillonnage peut biaiser fortement les estimations. Le sondage à probabilités inégales apporte un gain en termes de variance d’échantillonnage lorsque que le critère de variabilité des poids est « proportionnel » à la variable d’intérêt. Pour l’enquête Sans Domicile nous ne sommes pas dans une telle configuration.
 Niveau contact ou francophone Cœur de cible francophones, mais p non encore connu. Donc mise en œuvre niveau contact. P0=cste (au facteur alpha de surreprésentation près) On cherche à assurer une équipondération théorique des individus (excepté les surreprésentations définies partie 2.4) pour ne pas donner des poids trop différenciés aux différentes personnes interrogées. On limite ainsi la variance d’échantillonnage qui traduit le fait qu’un individu atypique et avec un gros poids d’échantillonnage peut biaiser fortement les estimations. Le sondage à probabilités inégales apporte un gain en termes de variance d’échantillonnage lorsque que le critère de variabilité des poids est « proportionnel » à la variable d’intérêt. Pour l’enquête Sans Domicile nous ne sommes pas dans une telle configuration.")
16
Calcul des allocations m
On peut fixer un nombre moyen théorique de 8 contacts (les contacts réels variant entre 1 et 16), d’où: - On peut fixer un nombre moyen théorique de 8 contacts (les contacts réels variant entre 1 et 16). Pour certaines grosses agglomérations, les services de taille inférieure à 4 ont été regroupés dans une strate à part et le nombre moyen théorique de contact a été fixé à 2 . Donc au sein des autres strates les contacts varient entre 4 et 16, raison pour laquelle le chiffre moyen de 8 a été choisi pour réduire les écarts de poids maximum à 2 (=16/8) et les écarts de poids minimums à 1/2 (=4/8). Pour la strates du SAMU Social à Paris, les services de taille inférieure à 8 ont été regroupés dans une strate à part et le nombre moyen théorique de contact a été fixé à 4. D’autres stratégies auraient pu être envisagées, comme par exemple prendre la médiane par strate, pour non plus limiter les écarts maximum et minimum, mais plutot recentrer la distribution des écarts. Au final, les seules inconnues sont les mk , les nombres de services x jours à tirer dans chaque strate k.
, d’où: - On peut fixer un nombre moyen théorique de 8 contacts (les contacts réels variant entre 1 et 16). Pour certaines grosses agglomérations, les services de taille inférieure à 4 ont été regroupés dans une strate à part et le nombre moyen théorique de contact a été fixé à 2 . Donc au sein des autres strates les contacts varient entre 4 et 16, raison pour laquelle le chiffre moyen de 8 a été choisi pour réduire les écarts de poids maximum à 2 (=16/8) et les écarts de poids minimums à 1/2 (=4/8). Pour la strates du SAMU Social à Paris, les services de taille inférieure à 8 ont été regroupés dans une strate à part et le nombre moyen théorique de contact a été fixé à 4. D’autres stratégies auraient pu être envisagées, comme par exemple prendre la médiane par strate, pour non plus limiter les écarts maximum et minimum, mais plutot recentrer la distribution des écarts. Au final, les seules inconnues sont les mk , les nombres de services x jours à tirer dans chaque strate k.")
21
Pondération réelle Probabilité inclusion au niveau contact(3 degrés)
Poids contact (1ere phase): Poids QIL (1ere et 2eme phases)
: Poids QIL (1ere et 2eme phases)")
22
Redressements Services : défaut et refus : règle de trois
QIL + QAA avec la feuille de contact pour : H/F et F/NF car les taux de refus sont peut être différents QIL avec QIL + QAA pour les variables communes. Individu : non car liens encore inconnus A) Redressement au niveau service : -on corrige les défauts de la base de sondage (la déclaration du semainier des QIL va peut indiquer des services qui étaient restés inconnus) - on corrige aussi les refus (du service) On augmente uniformément les poids des services dans l'agglo. (pas d'endo sélection de cette non-réponse) B ) redressement des contacts On redresse : sexe et F/NFrancophone des QIL+QAA répondants avec l'information de la feuille contact. En en effet le taux de refus n'est peut être pas identique entre H/Femme et F/NFrancophones. (Paris; province) x (restauration, hébergement dispersé , hébergement regroupé) C) redressement au niveau QIL On redresse les QIL avec les QIL+QAA_F pour les variables communes (H/Femmes, âge, type d'activité, né en France/né à l'étranger). Le poids QIL ainsi corrigé s'appliquera aux variables QIL qui ne sont pas communes avec les QAA_F. Les variables communes gardent le poids du contact. Le redressement est fait pour (Paris; province) x (restauration, hébergement dispersé, hébergement regroupé) D) Il n'y a pas de redressement au niveau individu, car les liens qui déterminent le poids final ne sont pas connus.
 Redressement au niveau service : -on corrige les défauts de la base de sondage (la déclaration du semainier des QIL va peut indiquer des services qui étaient restés inconnus) - on corrige aussi les refus (du service) On augmente uniformément les poids des services dans l agglo. (pas d endo sélection de cette non-réponse) B ) redressement des contacts. On redresse : sexe et F/NFrancophone des QIL+QAA répondants avec l information de la feuille contact. En en effet le taux de refus n est peut être pas identique entre H/Femme et F/NFrancophones. (Paris; province) x (restauration, hébergement dispersé , hébergement regroupé) C) redressement au niveau QIL. On redresse les QIL avec les QIL+QAA_F pour les variables communes (H/Femmes, âge, type d activité, né en France/né à l étranger). Le poids QIL ainsi corrigé s appliquera aux variables QIL qui ne sont pas communes avec les QAA_F. Les variables communes gardent le poids du contact. Le redressement est fait pour (Paris; province) x (restauration, hébergement dispersé, hébergement regroupé) D) Il n y a pas de redressement au niveau individu, car les liens qui déterminent le poids final ne sont pas connus.")
23
Partage des poids Un individu peut fréquenter plusieurs services d’aides différents voire même être enquêté plusieurs fois On diffusera le nombre d’usagers et non pas de prestations servies On collecte le semainier pour calculer le nombre de fois qu’un individus a fréquenté un service de la base de sondage sur les 4 semaines (nombre de liens)
")
24
réinterrogations Pour un francophone tiré pour un QIL plusieurs fois, on lui passe un QIC les fois suivantes: On recollecte la partie qui varie dans le temps (dont semainier) => 2 systèmes de poids selon les variables On a des informations : date naissance, sexe, … pour apparier les questionnaires du même individu Pas faisable pour les QAA
 => 2 systèmes de poids selon les variables. On a des informations : date naissance, sexe, … pour apparier les questionnaires du même individu. Pas faisable pour les QAA.")
25
Calcul poids final individus
Poids=somme (poids interrogations) / nb liens dans la base de sondage
 / nb liens dans la base de sondage.")
26
dispersion des poids Pendant la collecte, les poids des services jours sont modifiés du fait de fusions, éclatements, rééchantillonnages de visites. L’équipondération des contacts visée initialement est donc perturbée par : Ces modifications Des fréquentations bien plus faibles lors de la visite Le partage des poids

27
MERCI DE VOTRE ATTENTION

Présentations similaires





: Méthodes d'analyse Analyse.>")
 Sondage commandité par le Parlement européen et coordonné par la Direction générale Communication.>")












