Télécharger la présentation
1
STATISTIQUES ANALYTIQUES (suite)
SÉANCE 9 STATISTIQUES ANALYTIQUES (suite) Analyses de régression Considérations économétriques Tests statistiques Formes fonctionneles Exemples 17 mars 2006
 Analyses de régression. Considérations économétriques. Tests statistiques. Formes fonctionneles. Exemples. 17 mars")
2
Modèles et formes fonctionnelles
Régression (OLS) Linéaire et non-linéaire Très utilisées, conviennent bien lorsque résultats de l’échantillon s’applique à la population, cependant biaisées et paramétriques Autoregressif (SAR ou SARS) Maximum de vraisemblance Récemment utilisées, préférés lorsque la dimension spatiale et temporelle affecte le phénomène, nécessite coordonnées, réduit les erreurs et fournit de paramètres fiables. Artificial Neural Networks (ANNs) Récemment utilisées, permet de mieux modéliser, suit le du cerveau humain, cependant problèmes de «Over-Fitting » et « Black-Box ». Il n’est pas encore tout à fait connu. Abductive Learning Networks(ALNs) Même principe que ANNs, cependant «Over-Fitting » résolu, ne tient pas compte des bruits d’informations contrairement à ANNs. Il reste à en savoir plus. Case-Based Reasoning (CBR) Fonctionne selon une approche multicritère, conditions spécifiées dans une table de critères référencée à la base de données utilisées. Semble être moins bon que OLS.
 Linéaire et non-linéaire. Très utilisées, conviennent bien lorsque résultats de. l’échantillon s’applique à la population, cependant biaisées et paramétriques. Autoregressif (SAR ou SARS) Maximum de vraisemblance. Récemment utilisées, préférés lorsque la dimension spatiale. et temporelle affecte le phénomène, nécessite coordonnées, réduit les erreurs et fournit de paramètres fiables. Artificial Neural Networks (ANNs) Récemment utilisées, permet de mieux modéliser, suit le du. cerveau humain, cependant problèmes de «Over-Fitting » et. « Black-Box ». Il n’est pas encore tout à fait connu. Abductive Learning Networks(ALNs) Même principe que ANNs, cependant «Over-Fitting » résolu, ne tient pas compte des bruits d’informations. contrairement à ANNs. Il reste à en savoir plus. Case-Based Reasoning (CBR) Fonctionne selon une approche multicritère, conditions. spécifiées dans une table de critères référencée à la base. de données utilisées. Semble être moins bon que OLS.")
3
« Méthode des moindres carrés ordinaires »
Régression linéaire « Méthode des moindres carrés ordinaires » Y = B0 + (B1 * D) + (B2 * S) + (B3 * R) + (B4 * T) + E où Y Valeur marchande ; D Structurel ; S Spatial ; R Socio-économique ; T Temporel; B0 et B1,2,3,4 Coefficients de la régression; E part d’erreur dans le modèle.
 + (B2 * S) + (B3 * R) + (B4 * T) + E. où. Y Valeur marchande ; D Structurel ; S Spatial ; R Socio-économique ; T Temporel; B0 et B1,2,3,4 Coefficients de la régression; E part d’erreur dans le modèle.")
4
STRUCTUREL SPATIAL SOCIO-ÉCONOMIQUE TEMPOREL Superficie habitable
Type de propriété (Bungalow, Cottage,…) Garage Piscine Foyer Climatisation STRUCTUREL (CUM) SPATIAL (SIG et statistiques) SOCIO-ÉCONOMIQUE (RECENSEMENT et SIG) TEMPOREL (CUM et statisques) Distances : centre-ville, emploi, commerce, école, … Proximités : parc, fleuve, autoroute, chemin de fer, industrie, … Positions : municipalités et divers secteurs. Revenus Scolarité Origine ethnique Taux de chômage Autocorrélation spatiale Mois écoulés depuis la transaction Saison de vente Cycle immobilier Autocorrélation temporelle
 Garage. Piscine. Foyer. Climatisation. STRUCTUREL. (CUM) SPATIAL. (SIG et statistiques) SOCIO-ÉCONOMIQUE. (RECENSEMENT et SIG) TEMPOREL. (CUM et statisques) Distances : centre-ville, emploi, commerce, école, … Proximités : parc, fleuve, autoroute, chemin de fer, industrie, … Positions : municipalités et divers secteurs. Revenus. Scolarité. Origine ethnique. Taux de chômage. Autocorrélation spatiale. Mois écoulés depuis la transaction. Saison de vente. Cycle immobilier. Autocorrélation temporelle.")
5
Analyse de corrélation – test bilatéral (2-tailed)
Il y a corrélation entre deux variables du modèle lorsque les valeurs prises par les deux fluctuent simultanément dans le même sens (corrélation positive ou inverse (corrélation négative). En recherche, le seuil de signification statistique des corrélations est habituellement en dessous de 5 %. Dans le tableau qui suit, la plus forte relation est entre la superficie du terrain et son frontage, soit 75,8 % (et le test est très significatif).
. En recherche, le seuil de signification statistique des corrélations est habituellement en dessous de 5 %. Dans le tableau qui suit, la plus forte relation est entre la superficie du terrain et son frontage, soit 75,8 % (et le test est très significatif).")
6
Analyse de régression : considérations économétriques et tests statistiques
1. Test R² : Test du Coefficient de détermination (pourcentage de la variation totale de la variable dépendante expliquée par les variables prédictives). Plus il est élevé, plus il capte la majorité des variations du phénomène. Les résidus (erreurs d’estimation) auront également un poids plus faible. 2. Test F : Test de Ficher est une mesure globale qui nous indique qu’on peut ou non rejeter l’hypothèse nulle, au risque de se tromper 5 fois sur 100, selon laquelle aucune variable du modèle n’exerce une influence sur la variable explicative. Lorsque F = 0, on garde l’hypothèse nulle, si F > 0, il y a au moins une variable explicative qui a un effet sur la variable dépendante. Plus F est grand, mieux c’est. 3. Test ESE ou SEE Test d’erreur standard d’estimation nous donne une idée sur la performance prédictive de l’équation de régression. C’est comme une sorte de « résidu moyen » ou « erreur de prévision » du modèle (comparer ce test au moyen des prix). Plus ESE est petit, mieux c’est. 4. Test t ou Student t C’est l’erreur standard de chacun des coefficients estimés. Il nous indique si on peut rejeter ou non l’hypothèse nulle selon laquelle il n’y a pas de relation entre le coefficient estimé de la variable explicative et la variable dépendante. La valeur obtenue du Test t est comparée à une valeur critique dans les tables. Plus Test t est grand, mieux c’est. 5. Test VIF (variation inflation factor) Détecte les problèmes de multicolinéarité et identifie les variables qui en sont la cause. Un VIF < 5 est admis pour dire que le problème de multicolinéarité est réduit. Proche de 1, c’est l’idéale. En dessus de 10, c’est problématique.
. Plus il est élevé, plus il capte la majorité des variations du phénomène. Les résidus (erreurs d’estimation) auront également un poids plus faible. 2. Test F : Test de Ficher est une mesure globale qui nous indique qu’on peut ou non rejeter l’hypothèse nulle, au risque de se tromper 5 fois sur 100, selon laquelle aucune variable du modèle n’exerce une influence sur la variable explicative. Lorsque F = 0, on garde l’hypothèse nulle, si F > 0, il y a au moins une variable explicative qui a un effet sur la variable dépendante. Plus F est grand, mieux c’est. 3. Test ESE ou SEE. Test d’erreur standard d’estimation nous donne une idée sur la performance prédictive de l’équation de régression. C’est comme une sorte de « résidu moyen » ou « erreur de prévision » du modèle (comparer ce test au moyen des prix). Plus ESE est petit, mieux c’est. 4. Test t ou Student t. C’est l’erreur standard de chacun des coefficients estimés. Il nous indique si on peut rejeter ou non l’hypothèse nulle selon laquelle il n’y a pas de relation entre le coefficient estimé de la variable explicative et la variable dépendante. La valeur obtenue du Test t est comparée à une valeur critique dans les tables. Plus Test t est grand, mieux c’est. 5. Test VIF (variation inflation factor) Détecte les problèmes de multicolinéarité et identifie les variables qui en sont la cause. Un VIF < 5 est admis pour dire que le problème de multicolinéarité est réduit. Proche de 1, c’est l’idéale. En dessus de 10, c’est problématique.")
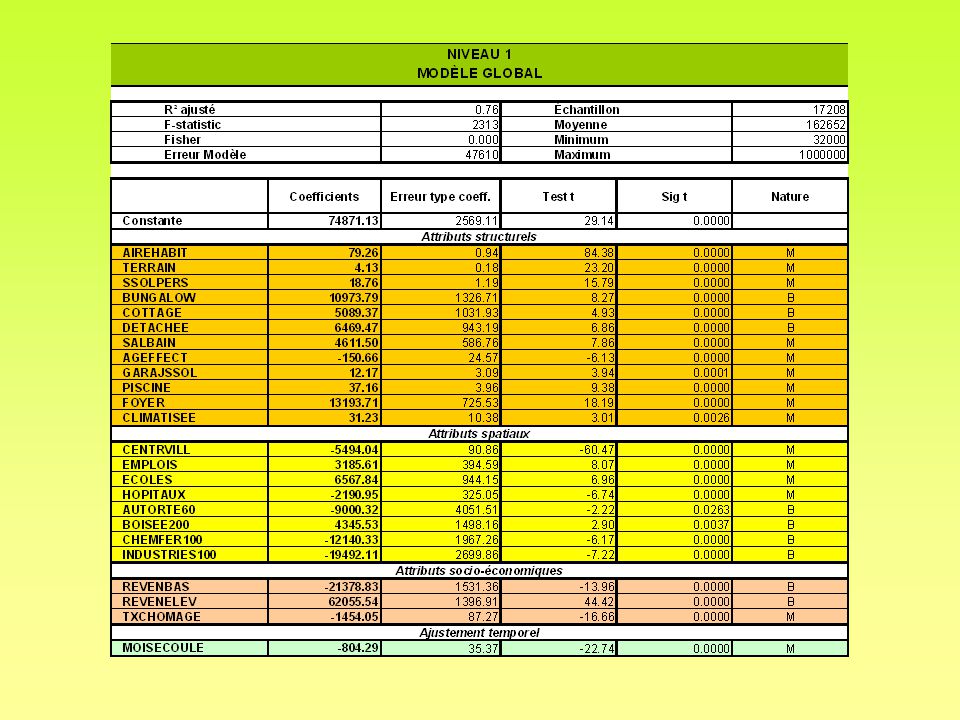
7
Interprétation des résultats – Régression linéaire multiple
C’est le coefficient de corrélation multiple au carré. 63,7 % est la roportion de la variance totale de Y expliquée par l’équation de régression Mesure sur la performance explicative globale du modèle. Coefficient de corrélation multiple Erreur standard d’estimation (ESE) Ici, c’est $. Si on le compare à la moyenne des prix ( $), c’est élevé. En effet, il représente un terme d’erreur d’estimation « moyenne » du modèle de 17,4 % ( / ). On en conclut que l’équation n’explique pas toutes les variations, ce qui est confirmé par Adjusted R Square (62,8 %). On peut retravailler le modèle, par exemple y intégrer d’autres variables explicatives ! « R² ajusté » accomplit la même fonction que R², mais tient compte du nombre de degrés de liberté. DL = n – k – 1, n = nombre d’observations k = nombre de variables explicatives. Si DL > 30, on utilise la table Z, si DL < 30, la table de Student
 Ici, c’est $. Si on le compare à la moyenne des prix ( $), c’est élevé. En effet, il représente un terme d’erreur d’estimation « moyenne » du modèle de 17,4 % ( / ). On en conclut que l’équation n’explique pas toutes les variations, ce qui est confirmé par Adjusted R Square (62,8 %). On peut retravailler le modèle, par exemple y intégrer d’autres variables explicatives ! « R² ajusté » accomplit la même fonction que R², mais tient compte du nombre de degrés de liberté. DL = n – k – 1, n = nombre d’observations. k = nombre de variables explicatives. Si DL > 30, on utilise la table Z, si DL < 30, la table de Student.")
8
Interprétation des résultats – Régression linéaire multiple (suite)
Sur les 449 DL, il y en a 11 qui sont associés au modèle, soit le nombre de variables Nombre d’observations totales : DL + 1 = 450 / 11 = / 438 = Il reste 438 degrés de libertés aux erreurs du modèle. DL = 450 – 11 – 1 = 438 C’est le test Fisher. Ici, on ne se trompe pas 70 fois en disant qu’au moins une des variables affecte le prix. F = / = 70 D’ailleurs, le test de F est très significatif. F > 5 %. Somme des variances élevées au carré expliquées par le modèle / la variation totale R² = / = 63, 7 % On veut que ce total des variances diminuent (erreurs élevées au carré).
.")
9
Interprétation des résultats – Régression linéaire multiple (suite)
Sig t : C’est la signification du test t. Si > 5 %, on rejette la variable. C’est le test t / 7 648 = 10,3 Erreur standard du coefficient estimé Constante de l’équation (b0) Coefficients b1 des X estimés C’est le coefficient de corrélation. Aucun problème dans ce cas, car VIF < 5 J’ai 13,77 % de probabilité de me tromper quand je dis que chaque pi² de SSPERS ajoute 7 $ au prix.
 Coefficients b1 des X estimés. C’est le coefficient de corrélation. Aucun problème dans ce cas, car VIF < 5. J’ai 13,77 % de probabilité de me tromper quand je dis que chaque pi² de SSPERS ajoute 7 $ au prix.")
11
ESTIMATION DE LA TAILLE REQUISE D’UN ÉCHANTILLON
Il est possible d’estimer la tille requise d’un échantillon si l’on connaît ces paramètres : n = ((Z * δ) / E)² où : n = taille requise de l’échantillon Z = valeur de la variable centrée réduite correspondant au coefficient de confiance désiré δ = écart-type de la population E = erreur maximale tolérée de part et d’autre de la moyenne Exemple : Supposons que nous avons recueillie 50 ventes de propriétés résidentielles. L’écart-type de la population de cet échantillon est de $ et que l’erreur tolérée de part et d’autre de la moyenne soit de $ au maximum, alors quelle est la taille optimale de l’échantillon si on voudrait avoir un niveau de confiance de 95 % ? Solution : n = ((Z * δ) / E)² n = ((1,96 * )/ 3 000)² n = ( / 3 000)² n = (10,78)² n = 116 observations !
 / E)² où : n = taille requise de l’échantillon. Z = valeur de la variable centrée réduite correspondant au coefficient de confiance désiré. δ = écart-type de la population. E = erreur maximale tolérée de part et d’autre de la moyenne. Exemple : Supposons que nous avons recueillie 50 ventes de propriétés résidentielles. L’écart-type de la population de cet échantillon est de $ et que l’erreur tolérée de part et d’autre de la moyenne soit de $ au maximum, alors quelle est la taille optimale de l’échantillon si on voudrait avoir un niveau de confiance de 95 % Solution : n = ((Z * δ) / E)². n = ((1,96 * )/ 3 000)². n = ( / 3 000)². n = (10,78)². n = 116 observations !")

 r =>")


>")









 Section 3 Tests dhypothèses et lhypothèse linéaire générale Version: 26 janvier 2007.>")





