Télécharger la présentation
1
Le paradoxe Jamais il n’a été aussi facile d’accéder à une masse gigantesque d’information; Jamais il n’a été aussi difficile de ‘trier’ et de synthetiser toute cette information; L’augmentation de la quantité d’information n’a pas comme corollaire une même augmentation de la quantité de connaissances.

2
Un autre écueil: 99.9999% des informations sont en ‘anglais’ Mais en mauvais anglais souvent!

3
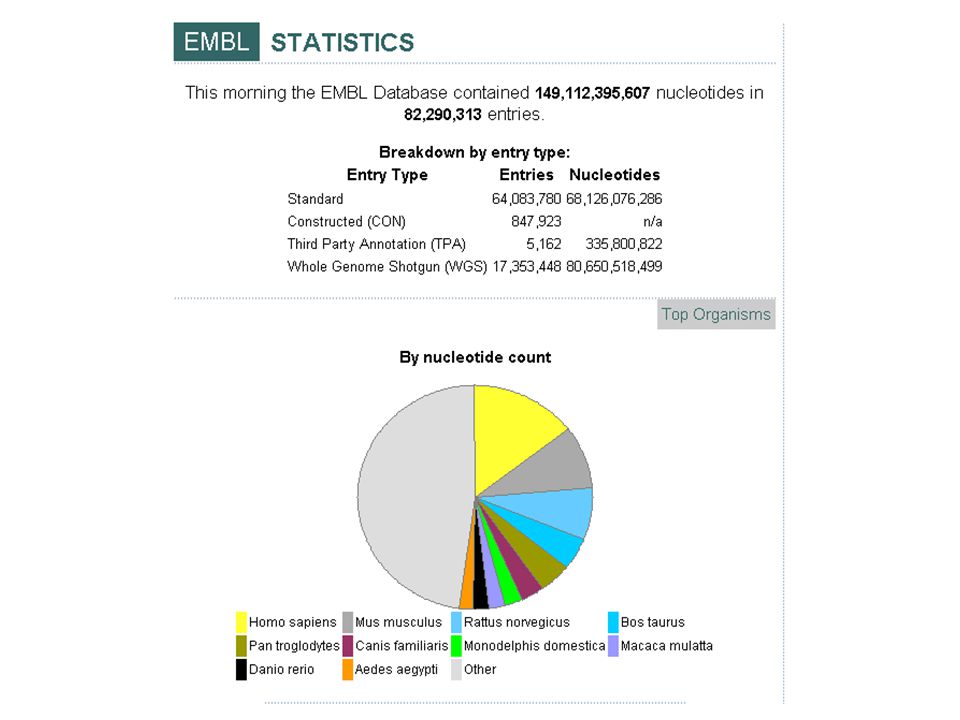
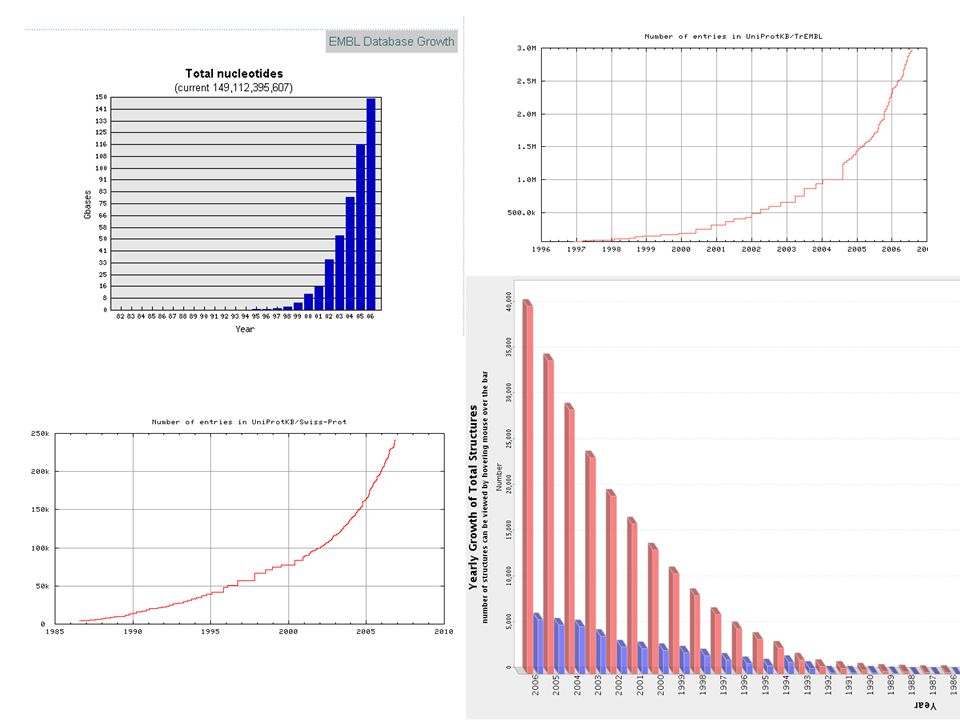
Une avalanche de données En 1954: publication de la 1ère sequence d’une protéine: l’insuline bovine par Frederick Sanger Plus de 50% des données biomoleculaires disponible aujourd’hui ont été produites dans les 2 dernières années; En 1986: 4’000 protéines dans Swiss-Prot; en 2006: 4’000 protéines par jour dans Swiss-Prot+TrEMBL.

4
The implications… The Life Sciences have undergone a dramatic revolution in the last 20 years: They used to be rich in hypotheses, well-off in knowledge and poor in data; They are now very rich in data, not so well-off in knowledge and very poor in hypotheses. A list of parts To a complex system How do we go from:

7
La tour de Babel Pas ou peu de standardizations Pas ou peu de nomenclatures (et quand il y en a elles ne sont pas suivies par les biologistes).
.")
9
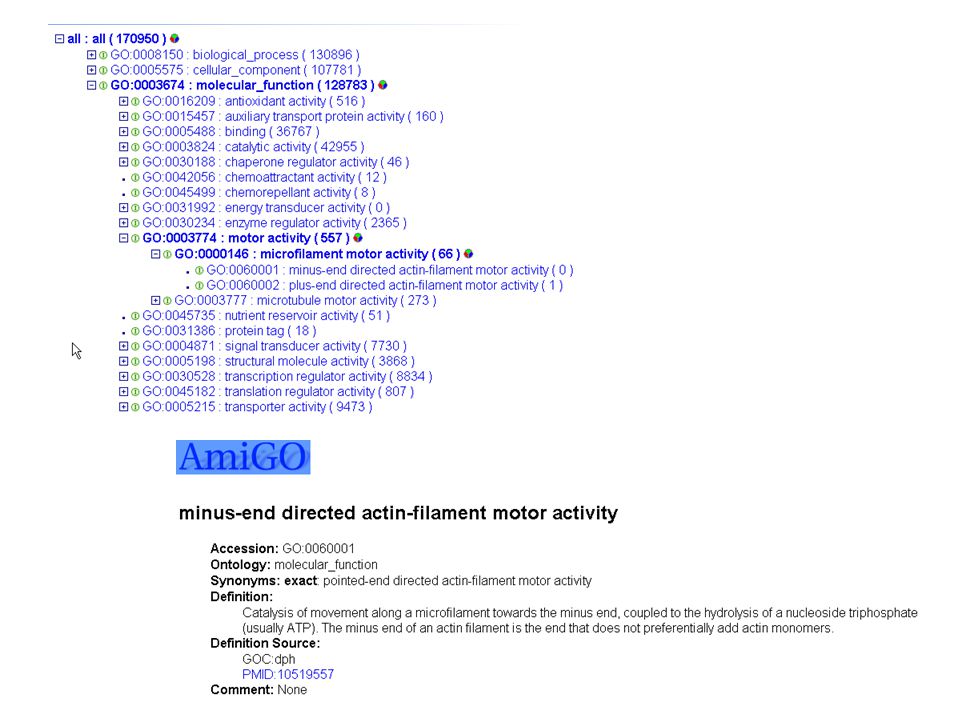
Heureusement il y a des effort pour créer des ontologies….

14
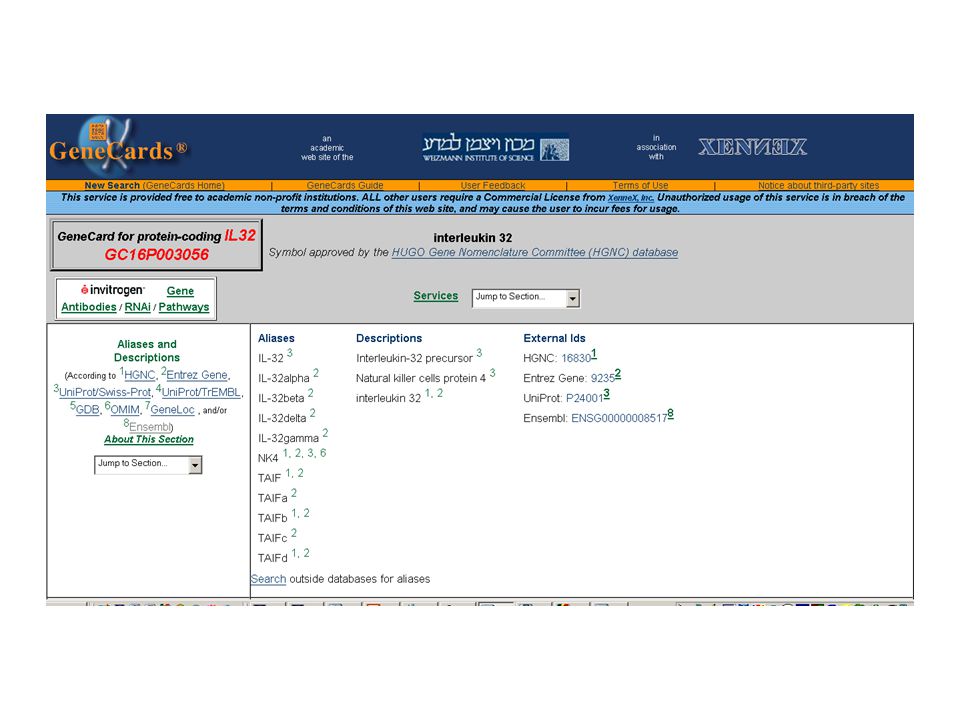
A Swiss-Prot on fait des grand effort pour standardiser beaucoup de choses!

15
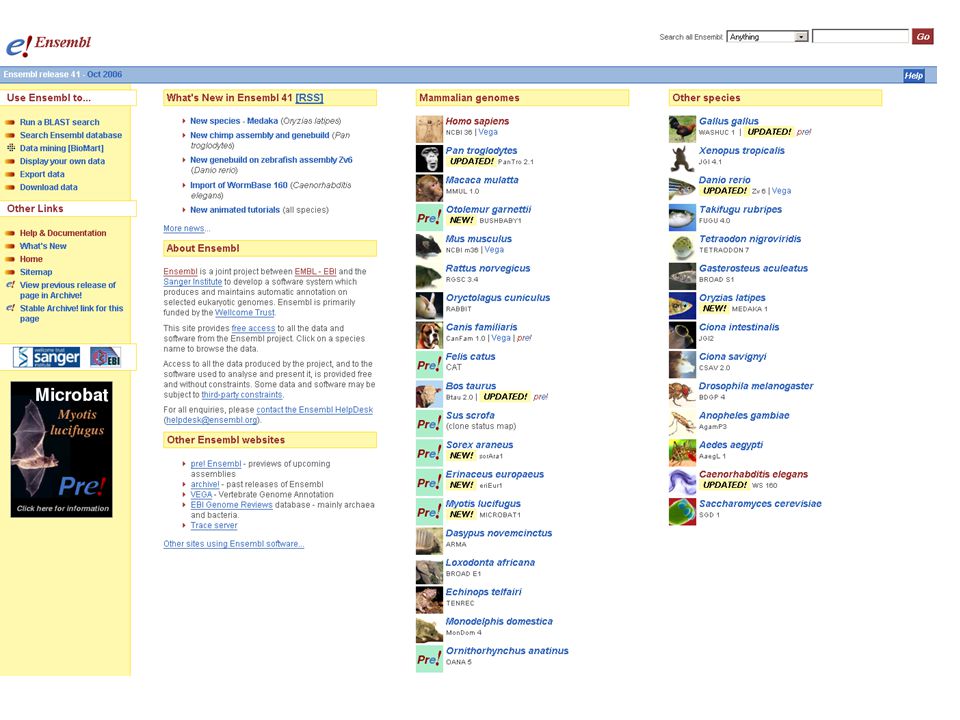
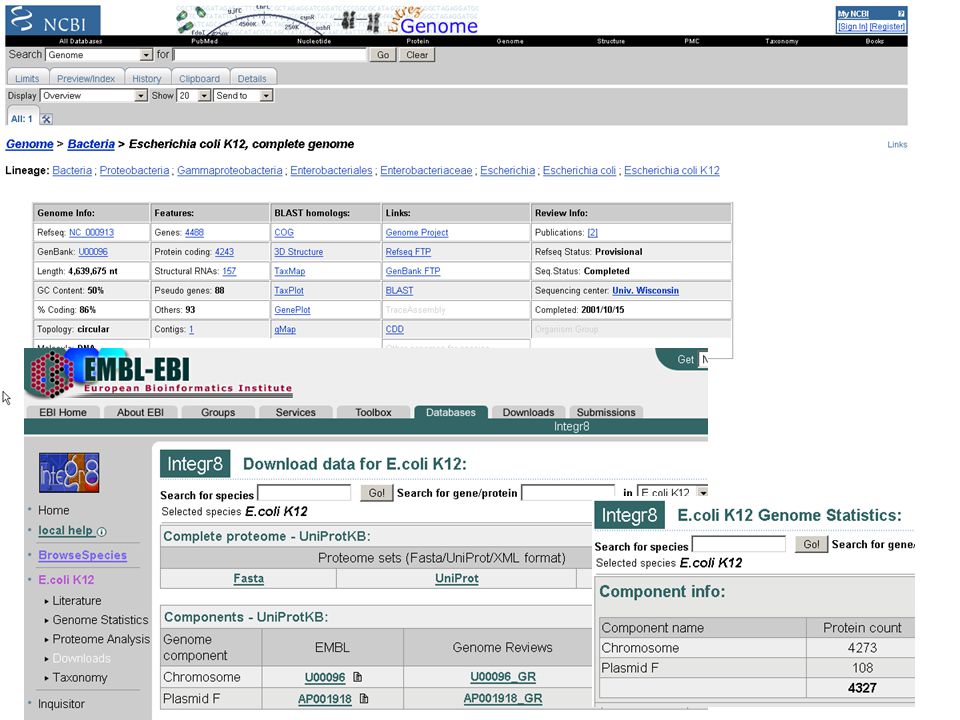
Les génomes Les séquences d’ADN se trouvent toutes dans l’EMBL/GenBank/DDBJ: –C’était vrai, cela ne l’est plus!; –Cela veut dire quoi ‘une séquence’?; –Laquelle de séquence?

18
Toute recherche étendue généralement commence là:

19
Mais de plus en plus elle commence:

20
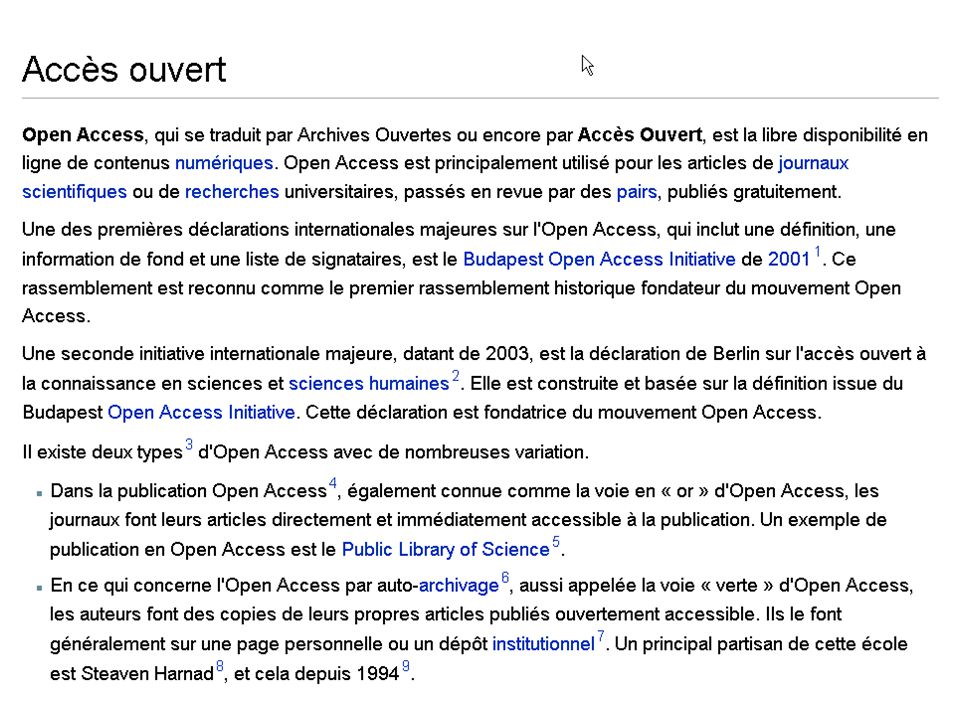
Quelques problèmes Trouver les bons articles (parmis plus de 2000 journaux de qualités variable): –Etre sur que l’on a vraiment cherché ce que l’on voulait chercher; –Etre sur que l’on a effectivement trouvé ce que l’on cherchait; –Faire un tri avant de tout lire! Accéder au «full text»: –Ou se trouve t’il? –Est il disponible gratuitement (Accès ouvert - Open Access)?; –Ma bibiiothèque as t’elle un abonnement?; –Le fichier est-il indexable (PDF image ou PDF texte); –Est ce que j’ai des chances de retouver cet article dans ‘x’ années (ou devrais je le sauver localement).
 ; –Ma bibiiothèque as t’elle un abonnement ; –Le fichier est-il indexable (PDF image ou PDF texte); –Est ce que j’ai des chances de retouver cet article dans ‘x’ années (ou devrais je le sauver localement)..")
23
From pull to push.. For now more than 20 years we have been «pulling» information and knowledge from various sources, but mainly from literature; It is now time to make sure that the next 20 years will be defined by the fact that researchers «push» their results and the interpretation of their results in the knowledgebase.

24
How to transition from pull to push? To do this we can: –Use wikipedia-type approaches (‘adopt a protein’); –Collaborate with open access publishers that are building the tools that will allow (and force) authors to structure their paper and the accompagning data; –Make sure that the appropriate repositories for new data types exist and are approved by the community (Intact, PRIDE, etc); –Get funding agencies to use the carrots and sticks approaches to make scientists abide to the practice of getting their data out.
; –Collaborate with open access publishers that are building the tools that will allow (and force) authors to structure their paper and the accompagning data; –Make sure that the appropriate repositories for new data types exist and are approved by the community (Intact, PRIDE, etc); –Get funding agencies to use the carrots and sticks approaches to make scientists abide to the practice of getting their data out..")
28
La même entrée à 14h11

29
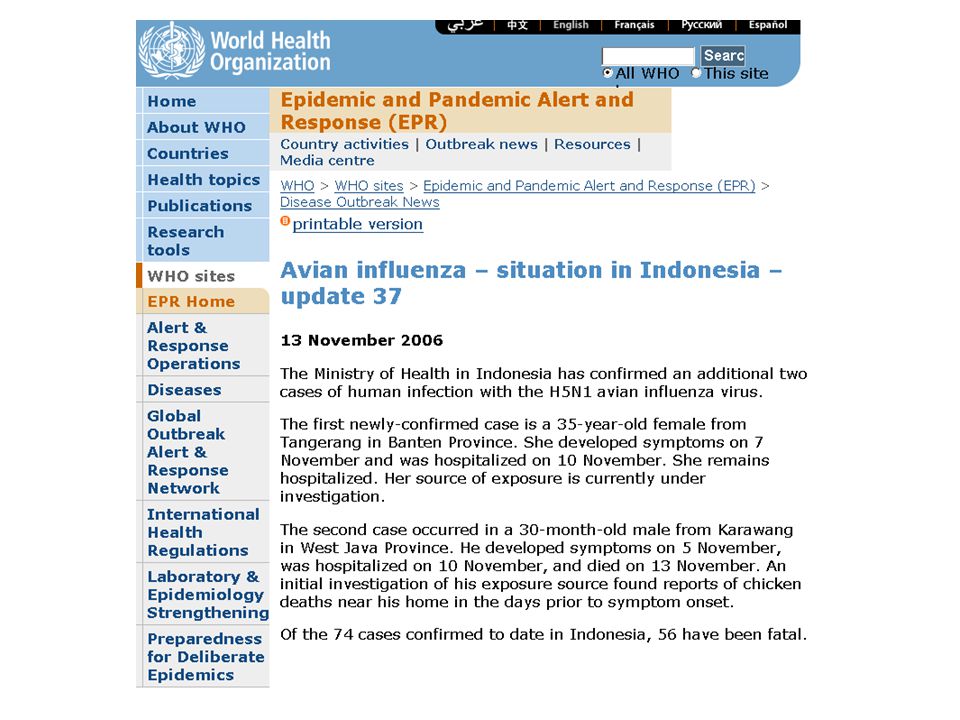
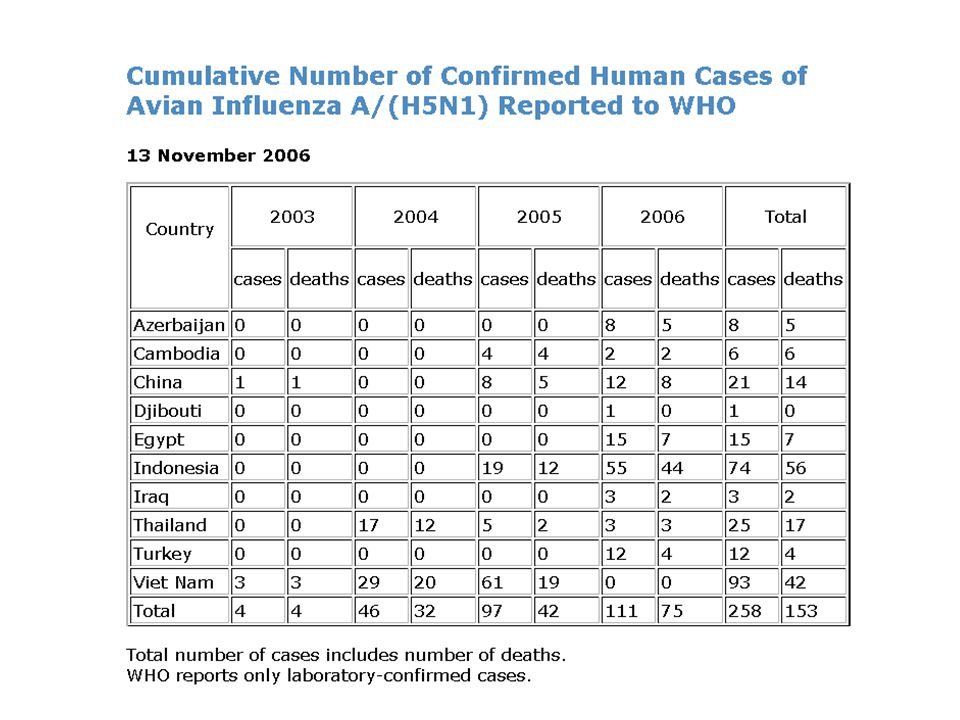
Quand la politique brouilles les cartes L’example de la grippe aviaire

36
www.gisaid.org


























 that don’t follow the normal rules. Because of this, we have to learn them by heart. Thankfully,>")


