Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Introduction à la Phylogénie

2
I. Introduction - Phylogénie
HYPOTHÈSE DE BASE: Tous les êtres vivants descendent d’un ancêtre commun. Sur une période d’au moins 3.8 milliards d’années le premier être vivant sur terre n’a cessé de se séparer en espèces différentes. Les êtres vivants évoluent à partir d’un ancêtre commun par une suite de mutations suivies de spéciations. Tout au long de l’évolution, les gènes accumulent des mutations. Lorsqu’elle sont neutres ou bénéfiques à l’organisme elles sont transmises d’une génération à l’autre.

3
Phylogénie L’isolement d’une population et l’adaptation à son environnement peut entrainer la création d’une nouvelle espèces

4
Phylogénie Étude des relations d’évolution entre des groupes d’organismes (espèces, populations). Basée sur la notion d’ « héritage» Taxonomie: Science qui consiste à classifier identifier et nommer les organismes. Basée sur des caractéristiques communes, différentes du reste de la diversité biologique. Domain, Kingdom, Phylum, Class, Order, Family, Genus, and Species

5
Arbre de Phylogénie The Tree of Life image that appeared in Darwin's On the Origin of Species by Natural Selection, It was the book's only illustration

6
Arbre de Phylogénie Premier objectif des études phylogénétiques: Reconstruire l’arbre de vie de toutes les espèces vivantes à partir des données génétiques observées. NASA:

7
Arbre de Phylogénie Les arbres de phylogénie sont également utilisés pour représenter l’évolution commune d’une famille de gènes, ou de virus comme le HIV ou l’influenza. Observation de corrélations entre les mutations du gène Myosin avec certains changements anatomiques dans la lignée humaine. MYH16 chez l’humain très divergeant des autres copies du gène.

8
II. Définitions formelles
Arbre: Graphe connexe acyclique; Ensemble de nœuds (ou sommets) connectés par des arêtes (ou branches) de telle sorte que toute paire de nœuds est reliée par exactement un chemin. Arbre raciné: Un nœud est désigné comme étant la racine; permet d’orienter la lecture de l’arbre; le temps s’écoule de la racine vers les feuilles. H G O M C C G O H M
 connectés par des arêtes (ou branches) de telle sorte que toute paire de nœuds est reliée par exactement un chemin. Arbre raciné: Un nœud est désigné comme étant la racine; permet d’orienter la lecture de l’arbre; le temps s’écoule de la racine vers les feuilles. H. G. O. M. C. C. G. O. H. M.")
9
Définitions formelles
Arbre raciné binaire: Chaque nœud interne a deux fils. Dans le cas d’un arbre d’espèces : Les feuilles représentent les espèces (ou séquences) actuelles La racine représente l’ancêtre commun Les nœuds internes représentent les événements de spéciation. H G O M C
 actuelles. La racine représente l’ancêtre commun. Les nœuds internes représentent les événements de spéciation. H. G. O. M. C.")
10
Définitions formelles
Un arbre phylogénétique peut-être binaire ou non-binaire. Un nœud non-binaire représente généralement un nœud non-résolu de l’arbre NJ tree (with weighting) of 119 Bacteria. Asterisks denote anomalously positioned taxa.
 of 119 Bacteria. Asterisks denote anomalously positioned taxa.")
11
Définition formelle Les nœuds ou arêtes d’un arbre de phylogénie peuvent être étiquetés. Les étiquettes représentent généralement le taux de mutations survenu, ou la date de spéciation R.V. Samonte & Evan E. Eichler Nature Reviews Genetics 3, (January 2002)
")
12
Monophylie/Paraphylie/Polyphylie
Marsupiaux Euthériens Monotrèmes Mammifères Tétrapodes: animal du sous-embranchement des vertébrés dont le squelette comporte deux paires de membres et dont la respiration est normalement pulmonaire.

13
Monophylie/Paraphylie/Polyphylie
T: arbre raciné. Soit M un groupe d’espèces (actuelles et ancestrales) M Groupe Monophylétique si le LCA e de M, ainsi que tous ses descendants sont dans M. Autrement dit, M détermine un sous- arbre de T. Exemple dans l’arbre des tétrapodes: Mammifères M Groupe Paraphylétique si le LCA e de M est dans M, mais que M n’est pas complet, i.e. n’inclue pas toutes les espèces du sous- arbres de racine e. Les Reptiles M Groupe Polyphylétique si le LCA de M n’est pas dans M. Les tétrapodes à sans chaud ou héméothermes (Mammifères et oiseaux). L’ancêtre des amniotes n’était pas héméotherme.
 M Groupe Monophylétique si le LCA e de M, ainsi que tous ses descendants sont dans M. Autrement dit, M détermine un sous- arbre de T. Exemple dans l’arbre des tétrapodes: Mammifères. M Groupe Paraphylétique si le LCA e de M est dans M, mais que M n’est pas complet, i.e. n’inclue pas toutes les espèces du sous- arbres de racine e. Les Reptiles. M Groupe Polyphylétique si le LCA de M n’est pas dans M. Les tétrapodes à sans chaud ou héméothermes (Mammifères et oiseaux). L’ancêtre des amniotes n’était pas héméotherme.")
14
III. Les caractères ou marqueurs utilisés
Une région spécifique de l’ADN, Une protéine Un caractère morphologique L’ordre des gènes dans le génome … Les caractères choisis doivent être homologues Hypothèse généralement considérée: Chaque caractère évolue indépendamment des autres.

15
Les caractères ou marqueurs utilisés
Caractères les plus utilisés pour les études d’évolution: Séquences de nucléotides ou d’AA. Séquences orthologues dans les espèces étudiées Effectuer un alignement multiple des séquences Les caractères représentés par les colonnes de l’alignement et les états du caractère sont les nucléotides (ou AA observés) dolphin ATGACCAACATCCGAAAAACACACCCTCTAATAAAAATCCTC giant sperm whale ATGACCAACATCCGAAAATCACACCCATTAATAAAAATCATT bowhead whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATTATT right whale ATGACCAACATCCGAAAAACACACCCAGTAATAAAAATTATT minke whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATTATC fin whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATCGTC blue whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATCATC humpback whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATTATC
 dolphin ATGACCAACATCCGAAAAACACACCCTCTAATAAAAATCCTC. giant sperm whale ATGACCAACATCCGAAAATCACACCCATTAATAAAAATCATT. bowhead whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATTATT. right whale ATGACCAACATCCGAAAAACACACCCAGTAATAAAAATTATT. minke whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATTATC. fin whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATCGTC. blue whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATCATC. humpback whale ATGACCAACATCCGAAAAACACACCCACTAATAAAAATTATC.")
16
Choix de marqueurs (séq. d’ADN)
Comment choisir une région de l’ADN qui « reflète » l’évolution de tout le génome? Caractéristiques gagnantes: Marqueur « non-recombinant ». Pour éviter ce problème, choisir des marqueurs uni-parentaux, comme les seq. de mitochondries et de chloroplastes: transmission par la mère uniquement. Marqueur en copie unique, pour éviter de choisir de mauvais « paralogues » ou: Marqueurs en copie multiples subissant une « évolution concertée » permettant d’uniformiser toutes les copies. ARNr: Marqueurs très utilisés pour les études phylogénétiques: Régions répétées de l’ADN subissant une évolution concertée Parmi les familles de gènes les plus conservées dans la cellule Alignements multiples faciles à faire Permet la comparaison d’espèces très éloignées.

17
IV. L’arbre caché dans la forêt
Arbre non raciné (binaire) de n feuilles: n-2 nœuds internes, n-3 branches internes, et 2n-3 branches. Chaque branche définit une bipartition de l’ensemble des feuilles. Arbre définit par n-3 bipartitions non-triviales. n=2: 1 2 1 2 Arbre non raciné unique Arbre raciné unique
 de n feuilles: n-2 nœuds internes, n-3 branches internes, et 2n-3 branches. Chaque branche définit une bipartition de l’ensemble des feuilles. Arbre définit par n-3 bipartitions non-triviales. n=2: Arbre non raciné unique. Arbre raciné unique.")
18
L’arbre caché dans la forêt
Arbre non raciné (binaire) de n feuilles: n-2 nœuds internes, n-3 branches internes, et 2n-3 branches. Chaque branche définit une bipartition de l’ensemble des feuilles. Arbre définit par n-3 bipartitions non-triviales. 3 n=3: 1 2 1 3 1 2 3 2 Arbre non raciné unique 3 arbres racinés 1 3 2
 de n feuilles: n-2 nœuds internes, n-3 branches internes, et 2n-3 branches. Chaque branche définit une bipartition de l’ensemble des feuilles. Arbre définit par n-3 bipartitions non-triviales. 3. n=3: Arbre non raciné unique. 3 arbres racinés")
19
L’arbre caché dans la forêt
Arbre non raciné (binaire) de n feuilles: n-2 nœuds internes, n-3 branches internes, et 2n-3 branches. Chaque branche définit une bipartition de l’ensemble des feuilles. Arbre définit par n-3 bipartitions non-triviales. 2 1 3 4 1 2 3 4 1 3 2 4 1 2 3 4 1 2 3 4 n=4: 1 2 4 3 1 2 3 4 1 2 4 3 3 Arbre non racinés 15 arbres racinés
 de n feuilles: n-2 nœuds internes, n-3 branches internes, et 2n-3 branches. Chaque branche définit une bipartition de l’ensemble des feuilles. Arbre définit par n-3 bipartitions non-triviales n=4: Arbre non racinés. 15 arbres racinés.")
20
L’arbre caché dans la forêt
Donc le problème d’inférence d’arbres se pose à partir de 3 feuilles pour les arbres racinés, et de 4 feuilles pour les arbres non-racinés. Cavalli-Sforza et Edwars (1967) ont montré que le nombre Br d’arbres racinés à n feuille est: Br = (2n-3)!/ 2n-2 (n-2)! Le nombre Bu d’arbres non racinés à n feuilles est égal au nombre d’arbres racinés à n-1 feuilles, donc: Bu = (2n-5)!/ 2n-3 (n-3)! Le nombre d’arbres augmente très rapidement avec le nbre de feuilles: Pour n=10, il existe plus de 34 millions d’arbres racinés possibles. Un seul représente la réalité!!
 ont montré que le nombre Br d’arbres racinés à n feuille est: Br = (2n-3)!/ 2n-2 (n-2)! Le nombre Bu d’arbres non racinés à n feuilles est égal au nombre d’arbres racinés à n-1 feuilles, donc: Bu = (2n-5)!/ 2n-3 (n-3)! Le nombre d’arbres augmente très rapidement avec le nbre de feuilles: Pour n=10, il existe plus de 34 millions d’arbres racinés possibles. Un seul représente la réalité!!")
21
Enracinement La plupart des méthodes de reconstruction phylogénétiques produisent des arbres non racinés. Pour un arbre non raciné de n feuilles, 2n-3 enracinements possibles. Plusieurs méthodes existent: Enracinement au barycentre: positionner la racine au milieu du chemin séparant les deux feuilles les plus éloignées. Hypothèse de l’horloge moléculaire.Applicable uniquement aux arbres valués. Enracinement en utilisant un « outgroup ». Méthode la plus utilisée. Consiste à rajouter à l’ensemble des séquences des espèces étudiées, une séquence homologue appartenant à une espèce non-apparentée.

22
Le kangourou est utilisé comme « outgroup »: Marsupiaux versus mammifères placentaires.
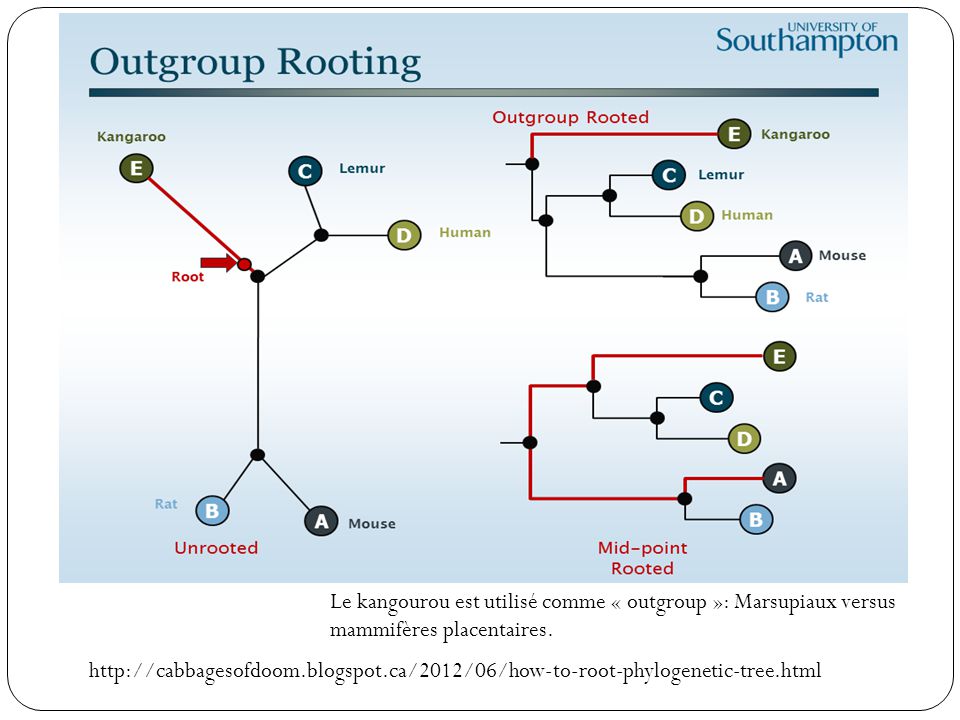
23
Distance topologique Comment comparer deux arbres T1, T2 provenant de données différentes? Distance la plus utilisée: Robinson-Foulds. Compte le nombre de bipartitions différentes entre T1 et T2 .

24
Distance topologique Distance la plus utilisée: Robinson-Foulds. Compte le nombre de bipartitions différentes entre T1 et T2 . Bipartitions non-triviales D E D E F B C C A A F B CD|ABEF EF|ABCD AB|CDEF CD|ABEF EB|ACDF AF|BCDE

25
Distance topologique Distance la plus utilisée: Robinson-Foulds. Compte le nombre de bipartitions différentes entre T1 et T2 . Bipartitions non-triviales D E D E F B C C A A F B CD|ABEF EF|ABCD AB|CDEF CD|ABEF EB|ACDF AF|BCDE Disance topologique dT (T1,T2)= 4
= 4.")
26
RF(T1,T2) = dT(T1,T2)/dM(T1,T2)
Distance topologique Distance la plus utilisée: Robinson-Foulds. Compte le nombre de bipartitions différentes entre T1 et T2 . Un arbre non raciné de n feuilles a n-3 branches internes (bi- partitions non-triviales). Donc distance topologique maximale entres deux arbres non racinés est dM (T1,T2)=2(n-3) Généralement, la distance tolologique est normalisée: RF(T1,T2) = dT(T1,T2)/dM(T1,T2)
. Donc distance topologique maximale entres deux arbres non racinés est. dM (T1,T2)=2(n-3) Généralement, la distance tolologique est normalisée: RF(T1,T2) = dT(T1,T2)/dM(T1,T2)")
27
VI. Modèles d’évolution moléculaire
Distance évolutive d entre deux séquences: nombre moyen de substitutions/site s’étant produites depuis la divergence de ces deux séquences à partir d’un ancêtre commun. Estimation des distances évolutives à la base de la plupart des méthodes de reconstructions phylogénétiques. Construction d’une matrice de distance contenant les distance évolutives entre paire de séquences: Première étape des méthodes phylogénétiques.

28
Divergence observée Calculée directement à partir de la distance d de Levenshtein ou de Hamming (substitutions) entre deux séquences (ADN ou protéines). Taux de divergence = d/n où n est la taille des séquences. Pour deux séquences aléatoires d’ADN, le taux de divergence est égal à 0.25 Divergence observée: seule mesure directement accessible. Pas un bon estimateur à part pour les séquences très proches: tendance à sous-estimer la distance évolutive réelle.
 entre deux séquences (ADN ou protéines). Taux de divergence = d/n où n est la taille des séquences. Pour deux séquences aléatoires d’ADN, le taux de divergence est égal à Divergence observée: seule mesure directement accessible. Pas un bon estimateur à part pour les séquences très proches: tendance à sous-estimer la distance évolutive réelle.")
29
Modèle markovien de l’évolution
Calcul d’une probabilité de transition d’un état à un autre Calcul d’une matrice 4x4: mij (i ≠j) : taux de substitution instantané de l’état i à l’état j. 1-mi : taux de conservation instantané du nucléotide i. Q: matrice des taux du precessus de Markov. La somme sur chaque colonne est 0.
 : taux de substitution instantané de l’état i à l’état j. 1-mi : taux de conservation instantané du nucléotide i. Q: matrice des taux du precessus de Markov. La somme sur chaque colonne est 0.")
30
Modèle de Jukes et Cantor (JC69)
Modèle markovien de substitution le plus simple. Considère le même taux de substitution instantané pour chacun des changements possible, et un seul taux de conservation global. m/4: taux moyen instantané de substitution.

31
Modèle de Kimura (K80) Transitions et transversions ont des taux différents. Transitions: A G, C T Transversions: A T, T G, A C, C G k rapport entre le taux de transitions et le taux de transversions.

32
Sélection naturelle Processus par lequel certaines modifications apparaissant par hasard chez certains individus dans une population sont favorisées et fixées, tandis que d’autres sont défavorisées et perdues. Concept initialement formulé par Darwin, basée sur une observation des phénotypes, mais la sélection naturelle affecte également le génotype. Peut mener à la création de nouvelles espèces.

33
Distance synonyme/non-synonyme pour les séquences codantes
Les gènes sont soumis à plusieurs types de sélection naturelle: Sélection positive: Processus qui encourage la rétention des mutations qui sont bénéfiques pour un individu. Sélection négative ou purificatrice: Processus qui tend à faire disparaître des mutations nuisibles. Sélection neutre: Absence de sélection positive ou négative. Dans le cas de séquences qui ne sont affectées par aucune pression sélective. Peuvent être modifiées sans conséquences sur l’organisme.

34
Distance synonyme/non-synonyme pour les séquences codantes
Basée sur la comparaison des substitutions synonymes et non- synonymes (effet sur les codons) Substitution non-synonyme (non-silencieuse): substitution provoquant la modification d’un acide aminé. Substitution synonyme (silencieuse): substitution ne provoquant pas la substitution de l’acide aminé initial.
 Substitution non-synonyme (non-silencieuse): substitution provoquant la modification d’un acide aminé. Substitution synonyme (silencieuse): substitution ne provoquant pas la substitution de l’acide aminé initial.")
36
Distance synonyme/non-synonyme pour les séquences codantes
Sites synonymes et non-synonymes: 100% des mutations touchant la 2ème base des codons sont non- synonymes Sous l’hypothèse que les fréquences nucléotidiques sont égales et que les mutations se font au hasard, 95% des mutations touchant la 1ère base et 28% des mutations touchant la 3ème base sont non-synonymes. Distances synonymes et non-synonymes: dS (aussi notée KS): Distance synonyme dN: Distance non-synonyme
: Distance synonyme. dN: Distance non-synonyme.")
37
Distance synonyme/non-synonyme pour les séquences codantes
Identification du type de sélection: Sélection négative: Déficit de substitutions non-synonymes attendu dN/dS < 1 Sélection neutre: Aucun déficit en subst. non-synonymes attendu dN/dS ≈ 1 Sélection positive: Excès de subst. non-synonymes attendu dN/dS > 1

38
Inférence d’arbres phylogénétiques
Méthodes de distance Input: Matrice de distances D Construire un arbre qui « réalise » cette matrice: chaque paire (x,y) de feuilles est reliée par un chemin dont le score est égal à la distance D(x,y) entre x et y. Méthodes de parsimonie: Arbre qui explique l’évolution des espèces par un nombre minimum de mutations. Deux composantes principales: Calcul d’un score d’un arbre donné. Recherche, parmi tous les arbres, l’arbre de score minoimal. Méthodes probabilistes Maximisation de la vraisemblance d’un arbre Inférence Bayésienne, basée sur la probabilité postérieure des hypothèses en fonction des données.
 de feuilles est reliée par un chemin dont le score est égal à la distance D(x,y) entre x et y. Méthodes de parsimonie: Arbre qui explique l’évolution des espèces par un nombre minimum de mutations. Deux composantes principales: Calcul d’un score d’un arbre donné. Recherche, parmi tous les arbres, l’arbre de score minoimal. Méthodes probabilistes. Maximisation de la vraisemblance d’un arbre. Inférence Bayésienne, basée sur la probabilité postérieure des hypothèses en fonction des données.")
39
VII. Méthodes de distance
Étant donnée une matrice de distance, existe-t-il un arbre binaire qui « réalise » la matrice? 1 4 2 A 5 8 12 11 B 9 13 C 6 D 3 E A B C D E 3 A 1 3 B C 2 1 E D

40
Condition des 4 points Théorème: Il existe un arbre réalisant la matrice de distance si et seulement si la matrice satisfait la condition des quatre points. Condition des 4 points: Pour tout choix de 4 feuilles A, B, C, D, deux des sommes suivantes sont égales et supérieures à la 3ème: D(A,B) + D(C,D), D(A,D) + D(B,C) et D(A,C)+D(B,D) B A B A D C B A D C D C
 + D(C,D), D(A,D) + D(B,C) et D(A,C)+D(B,D) B. A. B. A. D. C. B. A. D. C. D. C.")
41
Distances additives Une distance qui satisfait la condition des 4 points est une distance additive. A 3 5 B 4 6 C D A B C D C A 1 1 1 3 2 D B

42
Distance ultramétrique
Condition des 3 points: Pour tout choix de 3 feuilles A, B,C, parmi les trois distances D(A,B), D(A,C) et D(B,C), deux sont égales et supérieures à la troisième. D(A,C) = D(B,C) D(A,B) A B C
, D(A,C) et D(B,C), deux sont égales et supérieures à la troisième. D(A,C) = D(B,C) D(A,B) A. B. C.")
43
Distance ultramétrique
Condition des 3 points: Pour tout choix de 3 feuilles A, B,C, parmi les trois distances D(A,B), D(A,C) et D(B,C), deux sont égales et supérieures à la troisième. Une distance qui satisfait la condition des 3 points est dite ultramétrique. Une distance ultramétrique est une distance additive. Le contraire n’est pas vrai. D(A,C) = D(B,C) D(A,B) A B C
, D(A,C) et D(B,C), deux sont égales et supérieures à la troisième. Une distance qui satisfait la condition des 3 points est dite ultramétrique. Une distance ultramétrique est une distance additive. Le contraire n’est pas vrai. D(A,C) = D(B,C) D(A,B) A. B. C.")
44
Distance ultramétrique
Une distance ultramétrique satisfait l’inégalité ultratriangulaire: Dik ≤ max (Dij, Djk) pour tous i,j,k Tous les chemins de la racine à n’importe quelle feuille de la même longueur. Un arbre « associé » à une distance ultramétrique satisfait la théorie de l’horloge moléculaire: taux de mutation constant sur toutes les branches. D(A,C) = D(B,C) D(A,B) A B C
 pour tous i,j,k Tous les chemins de la racine à n’importe quelle feuille de la même longueur. Un arbre « associé » à une distance ultramétrique satisfait la théorie de l’horloge moléculaire: taux de mutation constant sur toutes les branches. D(A,C) = D(B,C) D(A,B) A. B. C.")
45
Arbre ultramétrique T est un arbre ultramétrique associé à la distance ultramétrique D ssi: T contient n feuilles, chacune étiquetée par une ligne de D; Chaque nœud interne est étiqueté par une case de D et a au moins deux fils; Le long d’un chemin de la racine à une feuille les valeurs des étiquettes des nœuds décroissent strictement; Pour deux feuilles quelconques i, j, D(i,j) est l’étiquette du dernier ancêtre commun de i et j dans T. T, s’il existe, est une représentation compacte de D. Remarque: T a au plus n-1 nœuds internes. Donc, si D a plus de n-1 valeurs, il n’existe pas d’arbre ultramétrique pour .
 est l’étiquette du dernier ancêtre commun de i et j dans T. T, s’il existe, est une représentation compacte de D. Remarque: T a au plus n-1 nœuds internes. Donc, si D a plus de n-1 valeurs, il n’existe pas d’arbre ultramétrique pour .")
46
Algorithme UPGMA UPGMA: Algorithme de classification ascendante hiérarchique. Procède par regroupement des séquences les plus proches. À chaque étape, les deux regroupements les plus « proches » sont fusionnés. Si D est une distance ultramétrique, alors UPGMA construit l’arbre ultramétrique associé.

47
Algorithme UPGMA n séquences; Di,j: Distance entre les séquences i et j. dij: Distance entre deux regroupements Ci et Cj. Moyenne des distances des paires de séquences entre les deux regroupements. Si Ck = Ci U Cj et Cl est un autre regroupement, alors:

50
Distance/arbre ultramétrique
Théorème: Si D est une matrice ultramétrique, alors l’arbre ultramétrique de D est unique. Preuve: Dans la construction de l’arbre, les classes sont « forcées », i.e. ne peuvent pas être déterminées autrement, et les positions de ces classes sont forcées aussi. Conséquence: Si D reflète effectivement la distance d’évolution entre les espèces, alors l’arbre obtenu est nécessairement le vrai arbre. Théorème: Si D est ultramétrique, alors l’arbre ultramétrique peut-être construit en temps O(n2). De plus, on peut déterminer en O(n2) si une distance est ultramétrique ou non.
. De plus, on peut déterminer en O(n2) si une distance est ultramétrique ou non.")
51
Que signifient des données ultramétriques?
Distances étiquetant les arbres ultramétriques supposées refléter le temps qui s’est écoulé depuis la séparation des deux espèces. Théorie de l’horloge moléculaire (1960): Pour une protéine donnée, le taux de mutations acceptées par intervalle de temps est constant. Donc, si k mutations acceptées entre les protéines A et B, on peut estimer à k/2 le nombre de mutations survenues sur chaque branche depuis l’ancêtre commun de A et B. Permet d’obtenir des données ultramétriques.
: Pour une protéine donnée, le taux de mutations acceptées par intervalle de temps est constant. Donc, si k mutations acceptées entre les protéines A et B, on peut estimer à k/2 le nombre de mutations survenues sur chaque branche depuis l’ancêtre commun de A et B. Permet d’obtenir des données ultramétriques.")
52
Distance/arbre additif
Soit D une distance pour n séquences. T: Arbre contenant au moins n noeuds (dont les feuilles). Chaque ligne de D correspond à un nœud différent, et les arêtes sont étiquetées. T arbre additif pour D si pour toute paire de nœuds (i,j), le poids total du chemin de i à j est D(i,j).
. Chaque ligne de D correspond à un nœud différent, et les arêtes sont étiquetées. T arbre additif pour D si pour toute paire de nœuds (i,j), le poids total du chemin de i à j est D(i,j).")
53
Distance/arbre additif
Problème: Trouver un arbre additif pour D ou déterminer qu’un tel arbre n’existe pas. Théorème: Il existe un arbre additif pour D ssi D est une distance additive (i.e. vérifie la condition des 4 points). Distance additive: Contrainte moins forte que la contrainte ultramétrique. Une distance ultramétrique est additive. Le contraire n’est pas vrai. Cependant, les données réelles sont rarement additives
. Distance additive: Contrainte moins forte que la contrainte ultramétrique. Une distance ultramétrique est additive. Le contraire n’est pas vrai. Cependant, les données réelles sont rarement additives.")
54
Neighbor-Joining (Saitou et Nei en 1986)
Algorithme glouton qui choisit à chaque étape une paire de feuilles voisines. Obtient un arbre additif correspondant à une distance additive. En général NJ est une approximation du « minimum d’évolution » Minimum d’évolution: Parmi toutes les topologies d’arbres, choisir celle minimisant la somme des longueurs de branche calculées en utilisant la méthode des moindres carrés, i.e. longeurs de branche minimisant: Q = Si<j wij (Dij-dij)2 wij: pondération associée à chaque couple (i,j).
2. wij: pondération associée à chaque couple (i,j).")
55
Neighbor-Joining Paire de feuilles voisines: Deux feuilles de T ayant le même père. Un arbre est déterminé par l’ensemble des (n-2) paires de voisins qu’il contient. 4 3 5 1 6 2 7 (1,2), (6,7), (4,5), ((1,2),3), ((4,5),(6,7)), (((4,5),(6,7)), (1,2),3))
 paires de voisins qu’il contient (1,2), (6,7), (4,5), ((1,2),3), ((4,5),(6,7)), (((4,5),(6,7)), (1,2),3))")
56
Neighbor-Joining Choisir deux objets i, j garantis d’être voisins dans un arbre additif. Supprimer i, j de la liste des objets et rajouter le nœud créé k correspondant au père commun de i et j. Distance de k à une feuille m quelconque: 4 m 3 i 5 1 k 6 j 2 7 D(k,m) = 1/2 (D(i,m) + D(j,m) - D(i,j) )
 = 1/2. (D(i,m) + D(j,m) - D(i,j) )")
57
Neighbor-Joining (1, 2) de distance minimale,
Comment déterminer, à partir de D, deux feuilles qui spmt nécessairement voisines dans un arbre additif de D? Il ne suffit pas de choisir une paire d’objets dont la distance est minimal: 1 2 (1, 2) de distance minimale, mais pas voisines dans l’arbre. 1 1 1 4 4 3 4
 de distance minimale, mais pas voisines dans l’arbre")
58
Neighbor-Joining L: Ensemble des feuilles d’un arbre additif.
Pour tout (i,j), D(i,j): valeur obtenue en soustrayant de D(i,j) la distance moyenne de i et j à toutes les autres feuilles. D(i,j) = D(i,j) – (ri+rj) Théorème: Si T est un arbre additif pour la distance additive D, si (i,j) est une paire de feuille telle que D(i,j) est minimal parmi toutes les paires de feuilles, alors i et j sont voisines dans T.
, D(i,j): valeur obtenue en soustrayant de D(i,j) la distance moyenne de i et j à toutes les autres feuilles. D(i,j) = D(i,j) – (ri+rj) Théorème: Si T est un arbre additif pour la distance additive D, si (i,j) est une paire de feuille telle que D(i,j) est minimal parmi toutes les paires de feuilles, alors i et j sont voisines dans T.")
60
VIII. Méthodes de parcimonie
Basées sur le principe de maximum de parcimonie: La meilleure hypothèse pour expliquer un processus est celle qui fait appel au plus petit nombre d’événements. À la différence des méthodes de distances, considère chaque site d’un alignement multiple individuellement. Sous-entend l’hypothèse d’indépendance des sites. Méthode générale: Considérer toutes les topologies d’arbres possibles sur un ensemble de feuilles; Calculer un poids pour chaque arbre; Sélectionner un arbre de poids minimal.

61
Méthodes de parcimonie
Pondération d’un arbre: Affecter des séquences aux nœuds internes de telle sorte à minimiser le poids total de l’arbre (somme des distances des branches). Exemple: A A A S1: AAG S2: AAA S3: GGA S4: AGA 1 A G A A A A 1 1 S1 S2 S3 S4 S1 S3 S2 S4 S1 S4 S2 S3 A A G A A A G G A A G A Poids de l’arbre: 3
. Exemple: A. A. A. S1: AAG. S2: AAA. S3: GGA. S4: AGA. 1. A. G. A. A. A. A S1. S2. S3. S4. S1. S3. S2. S4. S1. S4. S2. S3. A. A. G. A. A. A. G. G. A. A. G. A. Poids de l’arbre: 3.")
62
Méthodes de parcimonie
Pondération d’un arbre: Affecter des séquences aux nœuds internes de telle sorte à minimiser le poids total de l’arbre (somme des distances des branches). Exemple: A A A AAA AAA S1: AAG S2: AAA S3: GGA S4: AGA 1 A G A A A A AAA AAA AAA AAA 1 1 1 2 1 1 1 2 S1 S2 S3 S4 S1 S3 S2 S4 S1 S4 S2 S3 A A G A A A G G A A G A AAG GGA AAA AGA AAG AGA AAA GGA Poids de l’arbre:
. Exemple: A. A. A. AAA. AAA. S1: AAG. S2: AAA. S3: GGA. S4: AGA. 1. A. G. A. A. A. A. AAA. AAA. AAA. AAA S1. S2. S3. S4. S1. S3. S2. S4. S1. S4. S2. S3. A. A. G. A. A. A. G. G. A. A. G. A. AAG. GGA. AAA. AGA. AAG. AGA. AAA. GGA. Poids de l’arbre:")
63
Parcimonie pondérée (Algorithme de Sankoff)
On ne compte pas juste le nombre de substitutions, mais un poids S(a; b) pour la substitution de a en b. Étiqueter les nœuds internes de telle sorte a minimiser le poids total de l'arbre. Par récurrence: étiquette d'un nœud déduite des étiquettes des nœuds fils. Sk(a): poids du sous-arbre de racine k, sous la condition que k est étiqueté par a.
 pour la substitution de a en b. Étiqueter les nœuds internes de telle sorte a minimiser le poids total de l arbre. Par récurrence: étiquette d un nœud déduite des étiquettes des nœuds fils. Sk(a): poids du sous-arbre de racine k, sous la condition que k est étiqueté par a.")
64
Parcimonie pondérée (Algorithme de Sankoff)
Sk(a) = minb (Si(b) + S(a,b))+ minc (Sj(c)+S(a,c) k: a i j b c Sk(a) = 0 k: a Sk(b) = ∞
 = minb (Si(b) + S(a,b))+ minc (Sj(c)+S(a,c) k: a. i. j. b. c. Sk(a) = 0. k: a. Sk(b) = ∞")
65
Parcimonie pondérée (Algorithme de Sankoff)
")
66
Parcimonie pondérée (Algorithme de Sankoff)
Pour retrouver les nucléotides aux nœuds internes, garder des pointeurs lk(a) et rk(a) pour chaque a et chaque nœud k, et rajouter les deux instructions suivante dans le bloc de récurrence: Poser lk(a) = argminb(Si(b) + S(a,b)) Poser rk(a) = argminb(Sj(b) + S(a,b)) Pour retrouver une assignation correcte pour les nœuds internes, choisir un nucléotide à la racine qui donne lieu à un poids S2n-1(a) minimal, et suivre les pointeurs. Complexité: Pour un nœud donné, il faut calculer 2|S|2 minima. D’où, complexité de l’algorithme en O(n|S|2 ) où n est la taille de l'arbre (nombre de nœuds).
 et rk(a) pour chaque a et chaque nœud k, et rajouter les deux instructions suivante dans le bloc de récurrence: Poser lk(a) = argminb(Si(b) + S(a,b)) Poser rk(a) = argminb(Sj(b) + S(a,b)) Pour retrouver une assignation correcte pour les nœuds internes, choisir un nucléotide à la racine qui donne lieu à un poids S2n-1(a) minimal, et suivre les pointeurs. Complexité: Pour un nœud donné, il faut calculer 2|S|2 minima. D’où, complexité de l’algorithme en O(n|S|2 ) où n est la taille de l arbre (nombre de nœuds).")
67
T T 11 10 S(a,b) = 1 si a ≠b T T,C A,T,C,G T 9 T, G T 7 8 T T, C 1: C
5 3 4 11 A T C G 10 S(a,b) = 1 si a ≠b T T,C 4 3 A,T,C,G T 9 2 T, G T 7 8 T T, C 2 1 2 1 1: C 2: T 3: G 4: T 5: A 6: T ∞ ∞ ∞ ∞ ∞ ∞
 = 1 si a ≠b. T. T,C A,T,C,G. T T, G. T T. T, C : C. 2: T. 3: G. 4: T. 5: A. 6: T. ∞ ∞ ∞ ∞ ∞ ∞")
68
Parcimonie traditionnelle Algorithme de Fitch
Minimiser le nombre de substitutions de caractères. Garder à chaque nœud une liste de nucléotides « valides ». C: poids courant de l’arbre.

69
Parcimonie traditionnelle Algorithme de Fitch
Pour retrouver les nucléotides des nœuds internes: Choisir un nucléotide dans R2n-1(racine) puis descendre dans l'arbre. Si on a choisit a pour k, alors, pour le fils i de k, choisir a si possible, si non choisir un nucléotide au hasard dans Ri. Complexité: O(n|S|) Observation: Le poids minimal d’un arbre calculé par l’algorithme de Fitch est indépenant du choix de la racine. Conséquence: on n’a pas besoin de tester tous les arbres racinés possibles.
 puis descendre dans l arbre. Si on a choisit a pour k, alors, pour le fils i de k, choisir a si possible, si non choisir un nucléotide au hasard dans Ri. Complexité: O(n|S|) Observation: Le poids minimal d’un arbre calculé par l’algorithme de Fitch est indépenant du choix de la racine. Conséquence: on n’a pas besoin de tester tous les arbres racinés possibles.")
70
R11 = {T} C = 0 +1 +1 +1 R10 = {T} R9 = {G,T,A} R7 = {C,T} R8 = {G,T}
R5 = {A} R6 = {T}

71
Parcimonie traditionnelle Algorithme de Fitch
Problème de la parcimonie traditionnelle: Certaines assignations possibles des nœuds internes ne sont jamais considérées.

Présentations similaires











>")









