Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Les moyens vu au chapitre 2 (Techno CISC,RISC,VLIW) ont tous le meme objet, aller plus vite :
Traiter simultanément les bits. Les processeurs ont traité les bits par 12, 18, 24, 32, 60, 64. Les microprocesseurs les traitaient par 8 dans les années 1970, par 16 dans les années 1980, par 32 dans les années 1990, par 64 aujourd'hui. Il ne semble pas que l'on puisse gagner grand chose avec des mots plus longs, du moins les concepteurs ne l'ont pas tenté. Le mot de 64 bits parait correspondre au format utile le plus grand. Traiter simultanément les mots. On s'intéresse à deux causes de lenteur. Celle qui est due au traitement des instructions. Les deux étapes longues sont leur décodage et leur exécution. Pour leur décodage, on utilise un ou plusieurs pipelines qui tirent parti au mieux de l'indépendance relative entre les instructions successives. Pour le traitement, on remplace l'unité arithmétique et logique unique par des opérateurs spécialisés. L'autre cause est due à l'alimentation du processeur en mots d'instructions et de données. On a vu dans le chapitre précédent que la mémoire bon marché est lente, on duplique une partie de son contenu dans des mémoires plus rapides nommées caches. Les deux techniques du pipeline et du cache ont été généralisées dans les années 1990. Traiter simultanément les processus (Cf cours de Mr LELEVE)
")
2
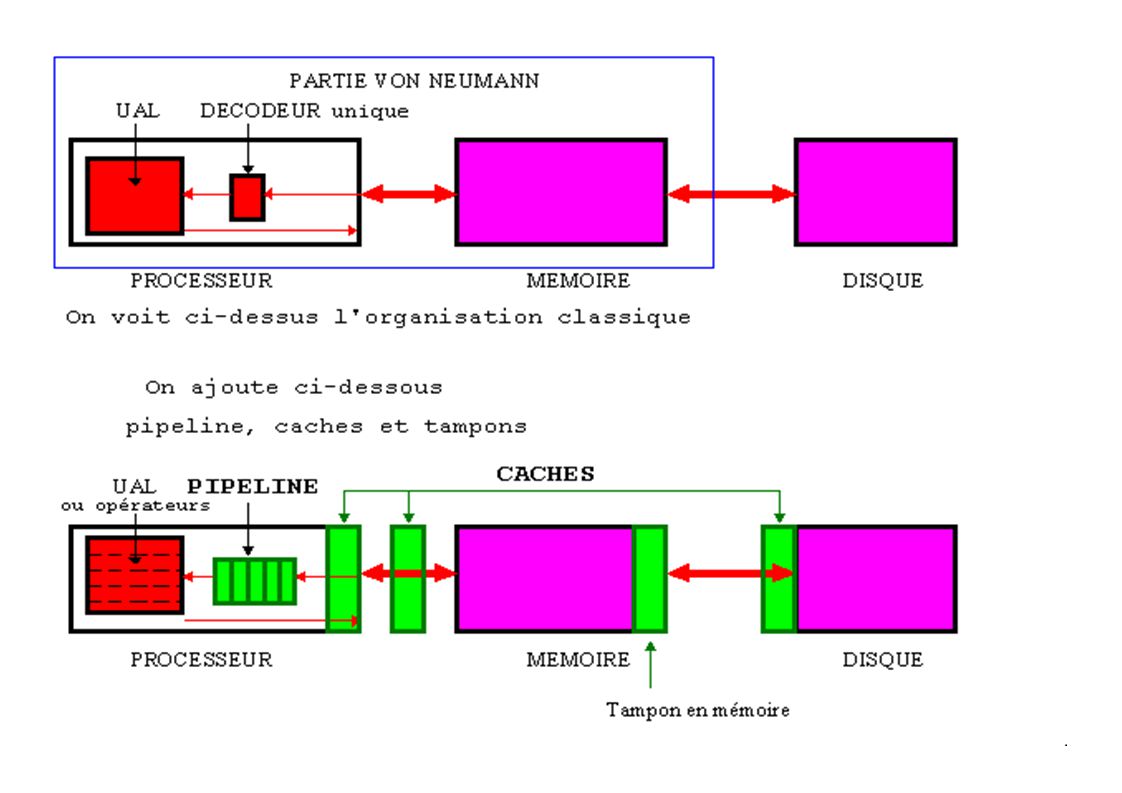
Introduction aux pipelines et aux caches
Parmi les prescriptions de Von Neumann, on trouve : La deuxiéme : "Le programme et les données sont logés dans une meme mémoire découpée en cellules." Cette unicité est-elle indispensable ? Peut-on s'affranchir de cette règle ? Pour cela, quelles précautions supplémentaires devraient-elles etre prises ? La cinquième : "L'exécution de chaque instruction est achevée avant que la suivante soit prise en compte." On est ainsi certain d'éviter des collisions dommageables. Peut-on s'affranchir de cette règle ? Pour cela, quelles précautions supplémentaires devraient-elles etre prises ? Les deux techniques inventées à cet effet sont illustrées par le schéma suivant.

4
Un cache atténue les différences de performances entre deux voisins.
Le parallélisme spatial consiste à dupliquer les données, soit pour y accéder séparément soit pour utiliser des mémoires aux caractéristiques meilleures. Ce sont les caches. Un cache atténue les différences de performances entre deux voisins. La simultanéité temporelle consiste à décoder par morceaux plusieurs instructions dans le meme temps. On verra son application au processeur unique. La simultanéité apportée par plusieurs processeurs travaillant de conserve sera examinée dans les chapitres 10 à 12 (Mr LELEVE). On a nommé ces structures qui apportent une simultanéité anticipation et recouvrement, plus rarement chaîne d'assemblage, on dit aujourd'hui pipeline. Le pipeline augmente les performances du processeur seul.
. On a nommé ces structures qui apportent une simultanéité anticipation et recouvrement, plus rarement chaîne d assemblage, on dit aujourd hui pipeline. Le pipeline augmente les performances du processeur seul.")
5
Pipelines: Origine et principe de fonctionnement.
L'anticipation et le recouvrement sont issus du constat que le chargement d'une instruction et le début au moins de son décodage ne dépendent pas du résultat de l'exécution de l'instruction précédente, sauf cas de branchement. Le mot pipeline est apparu dans les documents du projet STRETCH, lancé à partir de 1956 par IBM. Les premières réalisations ont été faites dans l'IBM 7030 du projet STRETCH L'idée première du pipeline est sans obscurité. Une instruction doit etre lue en mémoire, décodée et exécutée. Il y a là au mois trois étapes, plus encore si l'on décompose certaines d'entre elles. On va faire en sorte que chaque étape soit traitée dans un étage (slot en anglo-saxon); l'étage précédant traite l'étape précédente de l'instruction suivante, au lieu d'attendre la fin de l'exécution de l'instruction en cours.
; l étage précédant traite l étape précédente de l instruction suivante, au lieu d attendre la fin de l exécution de l instruction en cours.")
6
En suivant les instructions dans le temps, vision diachronique

7
En suivant les étages dans le temps, vision synchronique

8
Terminologie Nous traitons ici du pipeline d'instructions simple à une sortie. Chaque étage fonctionne indépendamment des autres sous les réserves ultérieures. Un signal d'horloge unique est utilisé pour la commande des transferts entre étages. Sa période est supérieure ou égale au délai propre à l'étage le plus lent. On observe couramment des réalisations de 5 à 12 étages. Dans un étage est réalisée une étape du traitement. Le nombre d'étages est aussi nommé profondeur du pipeline. Dans le cas idéal, à tout instant, chaque étage opère sur une instruction différente. Un pipeline de profondeur k, contient donc au mieux k instructions successives. Image Le mot pipeline est peut etre mal usité, car dans un pipeline (oléoduc, tuyau,...) le fluide y est véhiculé sans subir de transformation. Ce qui n'est pas le cas ici, à chaque étape, l'état change.
 le fluide y est véhiculé sans subir de transformation. Ce qui n est pas le cas ici, à chaque étape, l état change.")
9
L'accélération apportée par un pipeline
Nous présentons les calculs sous plusieurs hypothèses. Soit t le temps total de décodage sans pipeline. Soit tl le temps de traitement de l'étape la plus longue. Soit k le nombre d'étages. Le temps de transit d'une instruction sans pipeline est t Le temps de transit d'une instruction dans le pipeline est kxtl Supposons le pipeline vide au début, il sera rempli pendant le temps de transit de la première instruction soit kxtl. Dès que le pipeline est plein, un résultat est obtenu toutes les tl secondes. Si le nombre d'instructions à exécuter est n, le temps total d'exécution est kxtl + (n-1)xtl = (n+k-1)xtl L'accélération est alors S= nxt/(k+n-1)xtl Si n est très grand S devient proche de t/tl
xtl = (n+k-1)xtl. L accélération est alors S= nxt/(k+n-1)xtl. Si n est très grand S devient proche de t/tl.")
10
Exemple d'un pipeline pour un additionneur simplifié en virgule flottante :
Soit un flot indéfini d'additions, une fois le pipeline rempli : .l'addition demande 10 cycles, un étage, .l'alignement 5 cycles, un étage, .la normalisation 25 cycles, un étage. Sans pipeline chaque exécution demande = 40 cycles Avec un pipeline à quatre étages aligné sur l'opération la plus longue, 25 cycles, Chaque addition est faite en = 75 cycles Une addition est achevée tous les 25 cycles, L'accélération est 40/25 = 1,6 (en supposant que n très grand) L'efficacité d'un pipeline est fonction de l'étape la plus longue.
 L efficacité d un pipeline est fonction de l étape la plus longue.")
11
LES CONFLITS DANS UN PIPELINE ET LEUR RÉSOLUTION
Les conflits tiennent aux instructions et non pas au pipeline. 1. Conflit tenant aux ressources de la machine, on dit aussi conflits de structure. Deux instructions présentes dans le pipeline doivent utiliser la meme ressource (quelqu'en soit le contenu). Exemples : le bus est sollicité en meme temps pour deux transferts, un registre est sollicité par deux instructions, l'une pour décharger un opérande, l'autre pour faire un chargement. 2. Conflit tenant aux données manipulées. Les temps d'exécution des instructions sont différents. Deux instructions doivent utiliser la meme donnée. Exemple : l'instruction In n'est pas terminée alors que l'instruction In+1 commence. Un opérande de In+1 est le résultat de In, il y a conflit. 3. Conflit tenant à la commande. Il s'agit des branchements qui rompent la séquence. Le branchement inconditionnel peut etre traité assez tôt par une analyse de son code d'opération. Le branchement conditionnel ne peut etre décidé qu'après exécution de l'instruction. Il apporte le risque de devoir décharger le pipeline de presque tout son contenu. Ceci amène une obligation : pouvoir annuler les travaux en cours qui doivent donc etre exécutés de fa₤on réversible et une demande : prévoir la branche qui sera prise.
. Exemples : le bus est sollicité en meme temps pour deux transferts, un registre est sollicité par deux instructions, l une pour décharger un opérande, l autre pour faire un chargement. 2. Conflit tenant aux données manipulées. Les temps d exécution des instructions sont différents. Deux instructions doivent utiliser la meme donnée. Exemple : l instruction In n est pas terminée alors que l instruction In+1 commence. Un opérande de In+1 est le résultat de In, il y a conflit. 3. Conflit tenant à la commande. Il s agit des branchements qui rompent la séquence. Le branchement inconditionnel peut etre traité assez tôt par une analyse de son code d opération. Le branchement conditionnel ne peut etre décidé qu après exécution de l instruction. Il apporte le risque de devoir décharger le pipeline de presque tout son contenu. Ceci amène une obligation : pouvoir annuler les travaux en cours qui doivent donc etre exécutés de fa₤on réversible et une demande : prévoir la branche qui sera prise.")
12
Conflits de structure, point 1, phénomènes et solutions
Le conflit structurel apparaît quand deux opérations devraient utiliser la meme ressource au meme instant. Pour prévoir ce cas, il faut d'abord connaître l'état d'occupation des ressources à chaque instant, ensuite faire une détection préventive. Le tout est faisable en entretenant une table des réservations. Elle doit contenir l'état d'occupation des ressources pour chaque cycle d'horloge. Chaque colonne correspond à un étage du pipeline. Chaque ressource dispose d'une ligne. La case (i,j) est à 1 si la ressource i est utilisée à l'instant j, à zéro sinon. On peut pallie les conflits par la duplication des ressources en cause, par un nouvel ordonnancement des instructions ou par l'attente de libération de la ressource Conflits de dépendance entre les données, point 2, phénomènes et solutions. Elle est d'autant plus critique que des instructions peuvent etre exécutées dans le désordre. La dépendance provient des deux opérations de lecture et d'écriture, il y en a donc 4, nommées en anglo-saxon : RAR Read after Read, WAR Write After Read, RAW Read After Write, WAW Write After Write
 est à 1 si la ressource i est utilisée à l instant j, à zéro sinon. On peut pallie les conflits par la duplication des ressources en cause, par un nouvel ordonnancement des instructions ou par l attente de libération de la ressource. Conflits de dépendance entre les données, point 2, phénomènes et solutions. Elle est d autant plus critique que des instructions peuvent etre exécutées dans le désordre. La dépendance provient des deux opérations de lecture et d écriture, il y en a donc 4, nommées en anglo-saxon : RAR Read after Read, WAR Write After Read, RAW Read After Write, WAW Write After Write.")
13
La dépendance RAR, lectures successives de la meme donnée, n'apporte pas de conflit.
Dans la dépendance WAR, une instruction de rang I+n écrit dans un registre lu par une instruction de rang I. Si ces instructions sont exécutées dans le désordre, il ne faut pas que la I+n se termine avant que I n'ait lu le registre. Cette dépendance n'apparaît qu'en cas d'exécution dans le désordre. Dans la dépendance RAW, une instruction de rang I+n lit un registre écrit par une instruction de rang I. Il faut attendre que l'instruction I écrive son résultat avant de lire l'opérande de l'instruction I+n. C'est une vraie dépendance qui existe dans un exécution séquentielle. Dans la dépendance WAW, une instruction de rang I+n écrit dans un registre lui-meme écrit par l'instruction de rang I. Si ces instructions sont exécutées dans le désordre, il ne faut pas que la I+n se termine avant que la I ne se termine. Cette fausse dépendance n'apparaît qu'en cas d'exécution dans le désordre. int a = 3; int b = 2; int c = 1; a = b + c; b = a + b; b = a + c; LDI r31,3 ;initialise a, chargement immédiat. LDI r30,2 ;initialise b, idem. LDI r29,1 ;initialise c, idem. ADD r31,r30,r29 i1 ;lit r30 et r29, écrit dans r31 ADD r30,r31,r30 i2 ;lit r31 et r30, écrit dans r30 ADD r30,r31,r29 i3 ;lit r31 et r29, écrit dans r30 En exécution séquentielle : i1 dépend de i2 en WAR, car i2 écrit dans r30, lu par i1. i2 dépend de i3 en WAW, car i1 écrit dans r30, écrit par i3 i2 dépend de i1 en RAW, car i2 lit r31, écrit par i1.

14
Les moyens employés pour prévenir ces risques sont variés :
Le pipeline étant alimenté en séquence, on détecte les situations précédentes par examen de son contenu. Dans tous les cas précités, un couple d'instructions est en cause. La seconde est bloquée dans le pipeline jusqu'à la fin de la première. On dit que le pipeline contient une bulle. Le travail de prévention peut etre confié au compilateur ou à un post processeur de compilation, avec tous les inconvénients associés. Le pipeline contient aussi une bulle. Le court-circuit matériel consiste à prendre le résultat d'une instruction et à fournir en entrée de l'instruction suivante sans dépôt intermédiaire dans un registre. Ce n'est pas toujours efficace. Le technique du renommage des registres consiste à utiliser des registres non visibles, non accessibles au programmeur contenus dans le processeur. Ils sont utilisés pour ranger des résultats intermédiaires. Dans l'exemple ci-dessus, si on peut placer le résultat de i2, prévu pour etre dans r30, dans un autre registre, les deux instructions peuvent etre exécutées simultanément. L La prévention des conflits de dépendance nécessite du matériel supplémentaire. Les bulles sont inévitables. L'accélération maximale n'est en général jamais obtenue.

15
Conflits de commande, point 3, phénomènes et solutions.
Les instructions de branchement ont pour fonction de modifier le cours normal de l'exécution du programme, rompant la séquentialité stricte. Elles consistent en des exécutions conditionnelles proprement dites et les tests de boucles. On estime que les branchements représentent entre 15 et 30% du nombre total d'instructions des programmes. Un branchement est spécifié de trois fa₤ons différentes : · par le test du contenu d'un registre général, · par le test du contenu d'un registre spécial, registre de code de condition, · par une condition spécifiée dans l'instruction. int a; int b; if (a == 0) b = 1; else b = -1; 0008: CMPWI r3,0 ; compare a à C: BNE *+12 ; si différent, va a l'adresse : LDI r3,1,1 ; sinon affecte 1 dans b 0014: BR *+8 ; va a $ C 0018: LDI r31,-1 ; affecte -1 à b 001C: ... BNE est le branchement conditionnel : "Branch if Not Equal" BR est le branchement inconditionnel.
 b = 1; else b = -1; 0008: CMPWI r3,0 ; compare a à 0 000C: BNE *+12 ; si différent, va a l adresse : LDI r3,1,1 ; sinon affecte 1 dans b 0014: BR *+8 ; va a $ C 0018: LDI r31,-1 ; affecte -1 à b 001C: ... BNE est le branchement conditionnel : Branch if Not Equal BR est le branchement inconditionnel.")
16
Il y a de trois grands types de remèdes aux conflits de commande.
La neutralisation. Une fois détectée une instruction de branchement, le pipeline cesse d'etre alimenté jusqu'à la complète exécution de l'instruction. Cette solution prévient toute difficulté. Le temps perdu augmente avec la profondeur du pipeline. Le retard du branchement (delayed branch) En fonction de la profondeur du pipeline, on remplit les étages situés au dessous de l'instruction de branchement par des instructions indépendantes du résultat du branchement, éventuellement par des non opérations. Cette opération de remplissage peut etre faite de trois fa₤ons : · Transporter au delà du branchement des instructions qui le précèdent à condition que la condition de branchement n'utilise pas leurs résultats. · Exécuter des instructions postérieures à l'instruction de branchement qui doivent etre exécutées dans les deux cas. · Exécuter spéculativement les instructions qui suivent le branchement, dans une branche. Cette exécution doit impérativement etre réversible. Pour cela, toutes les modifications apportées aux registres, à la mémoire et à l'état interne de la machine doivent etre notées pour pouvoir annuler ces modifications si besoin est.
 En fonction de la profondeur du pipeline, on remplit les étages situés au dessous de l instruction de branchement par des instructions indépendantes du résultat du branchement, éventuellement par des non opérations. Cette opération de remplissage peut etre faite de trois fa₤ons : · Transporter au delà du branchement des instructions qui le précèdent à condition que la condition de branchement n utilise pas leurs résultats. · Exécuter des instructions postérieures à l instruction de branchement qui doivent etre exécutées dans les deux cas. · Exécuter spéculativement les instructions qui suivent le branchement, dans une branche. Cette exécution doit impérativement etre réversible. Pour cela, toutes les modifications apportées aux registres, à la mémoire et à l état interne de la machine doivent etre notées pour pouvoir annuler ces modifications si besoin est.")
17
La prédiction de branchement.
L'importance du sujet est établie par les évaluations suivantes : La probabilité d'un branchement pour 10 instructions successives est de 50% à 99% selon les programmes. La probabilité qu'il y ait simultanément plus d'un branchement dans un pipeline de taille courante est de 30% à 90% Classe 1 : la prédiction statique C'est la plus simple. Elle était présente dans le PowerPC601. Elle consiste a prédire un branchement selon son action, avant ou arrière, et, s'ils sont de meme nature, selon sa portée courte ou longue (l'une est plus courte que l'autre). Dans le cas avant-arrière, on prédit arrière. Dans le cas avant-avant ou arrière-arrière, on prédit celui dont la portée est la plus courte. Cette prédiction est statistiquement correcte dans 70 % des cas environ.
. Dans le cas avant-arrière, on prédit arrière. Dans le cas avant-avant ou arrière-arrière, on prédit celui dont la portée est la plus courte. Cette prédiction est statistiquement correcte dans 70 % des cas environ.")
18
Classe 2 : la prédiction dynamique
La variété des réalisations est grande. Dans son principe, la prédiction dynamique consiste à prédire le comportement d'un branchement en fonction du passé. Cette prise en compte du passé est faite en gardant le comportement précédent en mémoire. On peut le faire dans une table ou tampon des cibles des adresses de branchement (branch target buffer ou BTB) indexé souvent de fa₤on associative par l'adresse du branchement ou par sa seule partie basse. Chaque entrée de la table contient l'information relative au passé. Régler les conflits de commande nécessite souvent du matériel supplémentaire. La prédiction du bon branchement est essentielle
 indexé souvent de fa₤on associative par l adresse du branchement ou par sa seule partie basse. Chaque entrée de la table contient l information relative au passé. Régler les conflits de commande nécessite souvent du matériel supplémentaire. La prédiction du bon branchement est essentielle.")
19
LES CACHES Mémoire associative Le moyen de désignation d'une donnée dans la mémoire de von Neumann est son adresse. Une fois l'adresse connue, les circuits ont accès au contenu en lecture ou écriture selon la demande. En conséquence, la donnée du contenu : valeur de l'octet, du mot, contenu du secteur etc. n'est pas prévue. Si la donnée est fournie et non l'adresse, il faut faire un balayage et des comparaisons successives pour trouver sa localisation, sauf à avoir construit et entretenu par programmes des tables d'inversion (indexation, hash coding etc.). Pour faire ce type de recherche plus vite, l'idée est venue de fabriquer des mémoires spéciales dites associatives. Leur entrée est un contenu et leur sortie est soit rien soit la donnée associée, adresse, pointeur ou autre si le contenu a été trouvé.
. Pour faire ce type de recherche plus vite, l idée est venue de fabriquer des mémoires spéciales dites associatives. Leur entrée est un contenu et leur sortie est soit rien soit la donnée associée, adresse, pointeur ou autre si le contenu a été trouvé.")
20
La comparaison entre le contenu du registre et les clefs est faite sur toutes les clefs en une seule fois. Cette recherche simultanée nécessite un câblage particulier et un jeu de comparateurs de la largeur de la clef pour chaque ligne => Un mémoire associative est chère. Les mémoires associatives sont utilisées pour les caches. Les noms : clefs, contenus, adresses sont traditionnels mais la nature du contenu de chaque zone de ligne n'a aucune importance pour le fonctionnement de la mémoire associative. On peut trouver une adresse comme clef et une donnée comme valeur associée Méroire cache ou antémémoire: Il est utilisé en informatique pour désigner une mémoire plus petite qu'une autre et qui contient une partie des données de cette dernière.

21
Origine et emploi des caches
A l'origine de la mémoire cache, il y a une observation et un besoin. L'observation. Les informations lues successivement par un processus, instructions surtout, données dans une proportion moindre, sont le plus souvent à des adresses voisines. Cette observation est parée du nom de principe de localité; c'est une observation et non un principe. La localité a un aspect temporel et un aspect spatial : .aspect temporel, une référence utilisée a beaucoup de chances de l'etre à nouveau dans un futur proche; cet aspect est apporté par les boucles, les piles, les variables temporaires etc. .aspect spatial, les références qui suivent celle qui est en cours d'utilisation ont toutes chances d'etre utilisées dans le futur proche; cet aspect est apporté par la séquentialité. C'est vrai aussi pour les précédentes dans une boucle.

22
Le besoin Les processeurs fonctionnent à des fréquences de plus en plus élevées.On a vu que les DRAM, mémoires dynamiques les plus courantes et les moins chères ont des temps d'accès d'environ 60ns, et des temps de cycle d'environ 120ns. Ces caractéristiques évoluent mais ne suivent pas celles des processeurs. De plus, les temps d'accès sont augmentés d'opérations préalables, comme la transformation de l'adresse logique en adresse physique, le chargement de pages de mémoire virtuelle, etc... Le temps d'accès moyen à un mot aléatoire en mémoire principale peut aller jusqu'à 250 ns. Si l'on ne peut pas diminuer ce délai, supprimons le le plus souvent possible. Les caches sont aujourd'hui d'usage courant. Un cache possède en général son propre bus d'accès autant pour libérer le bus principal autant pour etre plus rapide Pour etre efficace, le cache doit etre géré par le matériel et non par programme. Le programmeur ne le voit pas. Il ne fait pas partie de l'architecture induite par le jeu d'instructions.

23
ORGANISATION DES CACHES ET ACCÈS EN LECTURE ET ÉCRITURE
Modèles d'organisation Il y a trois modèles d'organisation ou trois structures de caches. a) Cache associatif pur ou organisation totalement associative (fully associative). Le cache est une mémoire associative dans laquelle : ·la clef est une adresse, ·le résultat cherché est nommé granule ou ligne de données dans la mémoire associative.
 Cache associatif pur ou organisation totalement associative (fully associative). Le cache est une mémoire associative dans laquelle : ·la clef est une adresse, ·le résultat cherché est nommé granule ou ligne de données dans la mémoire associative.")
24
b)Caches à accès direct (direct mapped cache)
On n'utilise pas une mémoire associative mais une correspondance directe entre les numéros des lignes dans le cache et les adresses en mémoire principale. Une adresse physique en mémoire est considérée comme formée de trois parties : ·la partie haute, numéro de bloc en mémoire, ·la partie intermédiaire, numéro de ligne dans le cache, ·la partie basse, numéro dans la ligne du cache. L'adresse dans le cache est l'adresse en mémoire, modulo la taille du cache

25
c)Caches associatifs par blocs (set associative)
Il s'agit d'une organisation intermédiaire entre les deux précédentes. Dans l'organisation associative par blocs, le cache est divisé en sous ensembles d'emplacements ou blocs. Deux types de réalisations correspondent aux deux techniques de base, l'associativité et l'accès direct ·Chaque bloc est géré comme une mémoire associative et la relation entre les blocs relève de l'accès direct, ·Chaque bloc est géré en accès direct et on utilise l'accès associatif entre les blocs. Résumé : Cache associatif : la ligne peut etre placée n'importe où (couteuse). Cache direct : la ligne ne peut etre placée qu'en un seul endroit (place non utilisée). Cache associatif par blocs : la ligne peut etre placée en N endroits.
. Cache direct : la ligne ne peut etre placée qu en un seul endroit (place non utilisée). Cache associatif par blocs : la ligne peut etre placée en N endroits.")
26
Les échecs sont classés en trois groupes :
·Les échecs inévitables. Le premier accès à un bloc ne peut pas etre fait dans le cache sauf à mettre en place une prévision forcément aléatoire. On peut les appeler échecs de démarrage à froid ou échecs de la première référence. Ils se produiraient meme si le cache était illimité en taille. ·Les échecs dus à une capacité insuffisante. Le cache ne contient pas tous les blocs demandés pendant l'exécution du programme. Il y aura des échecs portant sur des blocs déjà utilisés mais ôtés du cache avant nouvel emploi (voir pour cela le § 3.2.7). ·Les échecs dus à des conflits. Dans les organisation associatives par blocs ou en adressage direct, on trouve des échecs dus à des conflits entre blocs de meme rang en mémoire. On les nomme échecs de collision.
. ·Les échecs dus à des conflits. Dans les organisation associatives par blocs ou en adressage direct, on trouve des échecs dus à des conflits entre blocs de meme rang en mémoire. On les nomme échecs de collision.")
27
Protocoles de remplacement
Placer les données dans le cache et gérer son accès est une chose, continuer à l'alimenter alors qu'il est plein demande une tactique de remplacement. On suppose que toutes les lignes possibles sont occupées par des données valides et qu'il y a lieu de charger un autre élément parce qu'il est demandé. Dans le cache à accès direct, un seul emplacement est possible, il n'y a pas lieu à protocole. ·Le premier entré, premier sorti, encore dite FIFO (First In First Out). Cette tactique est la plus simple à concevoir mais assez compliquée à réaliser. Elle n'est plus utilisée dans les caches de processeurs. ·Le choix aléatoire (random choice) est plus simple à réaliser. La ligne est choisie de manière aléatoire ou plutôt pseudo aléatoire.Cette technique est peu coûteuse en câblage. Elle est loin de l'optimum. ·Le moins récemment utilisé ou LRU (Least Recently Used). Il lui faut un mécanisme matériel qui s'apparente à celui mis en œuvre dans le FIFO. A chaque accès réussi le numéro de ligne est amené en tete de liste. Lors d'un échec, on choisit la ligne dont le numéro est en queue de liste. ·Le non récemment utilisé ou NRU (Not Recently Used). Chaque ligne a un compteur qui contient l'attribut de la ligne pris parmi les suivants : 0 pas d'accès récent, pas modifiée, 1 pas d'accès récent, modifiée, 2 accès récent, pas modifiée, 3 accès récent, modifiée.
. Cette tactique est la plus simple à concevoir mais assez compliquée à réaliser. Elle n est plus utilisée dans les caches de processeurs. ·Le choix aléatoire (random choice) est plus simple à réaliser. La ligne est choisie de manière aléatoire ou plutôt pseudo aléatoire.Cette technique est peu coûteuse en câblage. Elle est loin de l optimum. ·Le moins récemment utilisé ou LRU (Least Recently Used). Il lui faut un mécanisme matériel qui s apparente à celui mis en œuvre dans le FIFO. A chaque accès réussi le numéro de ligne est amené en tete de liste. Lors d un échec, on choisit la ligne dont le numéro est en queue de liste. ·Le non récemment utilisé ou NRU (Not Recently Used). Chaque ligne a un compteur qui contient l attribut de la ligne pris parmi les suivants : 0 pas d accès récent, pas modifiée, 1 pas d accès récent, modifiée, 2 accès récent, pas modifiée, 3 accès récent, modifiée.")
28
Protocoles d'écriture après modification
a)Pour une adresse présente dans le cache, on pratique : 1. L'écriture simultanée (ou write-through). Une ligne du cache modifiée (ou dirty line) est écrite quasi simultanément dans le cache et dans la mémoire qui le suit dans la hiérarchie. La cohérence est garantie entre ces deux niveaux au prix d'une augmentation du trafic sur le bus ou les bus. Dans des systèmes à quatre niveaux : L1, L2, mémoire centrale et disque, il faut préciser quel est le couple ou les couples où l'écriture simultanée est appliquée. On peut avoir écriture simultanée dans L1 et L2 mais pas dans la mémoire centrale, ou encore entre la mémoire et le disque, mais cela relève du système d'exploitation. 2. L'écriture séparée différée (posted-write). Pour éviter que l'UC attende la fin de la ou des écritures, on place la donnée à écrire dans un tampon d'écriture (write-buffer) dont le contenu sera reporté ensuite. Cette technique est nommée posted-write chez Intel. Ce tampon est lui-meme une mémoire spécialisée comme le cache. 3. La recopie (write-back) : la ligne est marquée modifiée et conservée telle quelle dans le cache. Elle sera copiée en mémoire au moment où son emplacement sera demandé pour un remplacement.
Pour une adresse présente dans le cache, on pratique : 1. L écriture simultanée (ou write-through). Une ligne du cache modifiée (ou dirty line) est écrite quasi simultanément dans le cache et dans la mémoire qui le suit dans la hiérarchie. La cohérence est garantie entre ces deux niveaux au prix d une augmentation du trafic sur le bus ou les bus. Dans des systèmes à quatre niveaux : L1, L2, mémoire centrale et disque, il faut préciser quel est le couple ou les couples où l écriture simultanée est appliquée. On peut avoir écriture simultanée dans L1 et L2 mais pas dans la mémoire centrale, ou encore entre la mémoire et le disque, mais cela relève du système d exploitation. 2. L écriture séparée différée (posted-write). Pour éviter que l UC attende la fin de la ou des écritures, on place la donnée à écrire dans un tampon d écriture (write-buffer) dont le contenu sera reporté ensuite. Cette technique est nommée posted-write chez Intel. Ce tampon est lui-meme une mémoire spécialisée comme le cache. 3. La recopie (write-back) : la ligne est marquée modifiée et conservée telle quelle dans le cache. Elle sera copiée en mémoire au moment où son emplacement sera demandé pour un remplacement.")
29
b)Pour une adresse qui n'est pas dans le cache, on pratique :
1. L'écriture attribuée (write-allocate) : la ligne est chargée dans le cache, est modifiée et on applique un des trois protocoles précédents. 2. L'écriture non attribuée (no write-allocate) : la ligne est modifiée directement dans le niveau inférieur de la hiérarchie sans etre chargée dans le cache. Si ce niveau est lui-meme un cache, on applique une des tactiques précédentes. Note sur le blocage des caches Les caches peuvent etre bloquants ou non bloquants comme suit. · Dans un cache non bloquant, les données sont accessibles pendant le traitement d'un défaut de cache. · Dans un cache bloquant, les accès sont impossibles jusqu'à ce que la donnée manquante soit écrite.
 : la ligne est chargée dans le cache, est modifiée et on applique un des trois protocoles précédents. 2. L écriture non attribuée (no write-allocate) : la ligne est modifiée directement dans le niveau inférieur de la hiérarchie sans etre chargée dans le cache. Si ce niveau est lui-meme un cache, on applique une des tactiques précédentes. Note sur le blocage des caches. Les caches peuvent etre bloquants ou non bloquants comme suit. · Dans un cache non bloquant, les données sont accessibles pendant le traitement d un défaut de cache. · Dans un cache bloquant, les accès sont impossibles jusqu à ce que la donnée manquante soit écrite.")
30
OPTIMISATION DES CACHES
Les paramètres constitutifs d'un cache sont : ·sa technique de réalisation et son protocole d'accès associé, ·sa taille totale, ·sa taille utile, ·son ou ses temps d'accès. Les paramètres de performances sont : le taux d'échec, le coût d'un échec, et le temps d'accès en cas de succès. Pour cela, il est bon de : ·augmenter la taille des blocs qui diminuera le nombre de blocs à charger. ·augmenter l'associativité, mais le coût augmente. ·lors d'un échec on peut charger plus d'un bloc en supposant qu'il y a de fortes chances pour que les blocs suivants soient utiles. ·optimiser les programmes en changeant l'ordre d'accès dans les vecteurs, en regroupant des sections de code ou des objets d'usage simultané, ·réduire le coût des échecs par tout moyen. ·découper les blocs et faire que le processeur lise dès que le sous-bloc nécessaire est disponible. ·ajouter un cache de deuxième niveau. ·réduire le temps d'accès avec un cache petit et direct.

31
CONCLUSIONS SUR LA GESTION DE LA MÉMOIRE ET LES CACHES
Les caches, tant de mémoire centrale que de disque, sont de plus en plus nombreux et volumineux, eu égard : .à la baisse du prix des mémoires, meme pour celles qui ont des temps d'accès très courts, .à l'utilité de ces caches en termes de performances observables et .à la plus grande intégration qui autorise l'insertion des caches dans le circuit microprocesseur. Les caches n'ont pas d'utilité intrinsèque. Ils comblent en partie l'écart de performances des deux dispositifs entre lesquels on les place.

Présentations similaires










>")








