Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
SYSTÈME D’EXPLOITATION I
SIF-1015

2
Contenu du cours 8 Systèmes de fichiers Concepts et opérations de base
Concepts et opérations avancées Implémentation LECTURES: Chapitres 10 et 11 (OSC) Chapitres 3 et 7 (Mitchell) Chapitre 6 (Card)
 Chapitres 3 et 7 (Mitchell) Chapitre 6 (Card)")
3
Concepts et opérations de base
Les fichiers sous LINUX (ou UNIX) sont organisés sous forme d’un arbre. Le sommet de l’arbre, le répertoire racine (/) et chacun des nœuds est un répertoire pouvant contenir des sous-répertoires ou des fichiers (feuilles) Chaque répertoire contient un catalogue de noms, chaque entrée de ce catalogue décrivant un fichier ou un répertoire. Deux entrées particulières existent dans chaque répertoire: . représente le répertoire lui-même et .. le répertoire père Chaque fichier ou répertoire est représenté par un nom absolu. Ce nom correspond aux répertoires (chacun séparé par un /) à parcourir depuis la racine pour atteindre l’objet. Exemple: /usr/bin/cc (fichier cc) Les fichiers peuvent aussi être exprimés de façon relative
 sont organisés sous forme d’un arbre. Le sommet de l’arbre, le répertoire racine (/) et chacun des nœuds est un répertoire pouvant contenir des sous-répertoires ou des fichiers (feuilles) Chaque répertoire contient un catalogue de noms, chaque entrée de ce catalogue décrivant un fichier ou un répertoire. Deux entrées particulières existent dans chaque répertoire: . représente le répertoire lui-même et .. le répertoire père. Chaque fichier ou répertoire est représenté par un nom absolu. Ce nom correspond aux répertoires (chacun séparé par un /) à parcourir depuis la racine pour atteindre l’objet. Exemple: /usr/bin/cc (fichier cc) Les fichiers peuvent aussi être exprimés de façon relative.")
4
Concepts et opérations de base
Organisation hiérarchique des fichiers

5
Concepts et opérations de base
Organisation hiérarchique des fichiers

6
Concepts et opérations de base
Organisation hiérarchique des fichiers

7
Concepts et opérations de base
Organisation hiérarchique des fichiers

8
Concepts et opérations de base
Types de fichiers: Chaque fichier dans l’arborescence est aussi représenté par son type, qui est utilisé par le système pour déterminer l’utilisation qui en sera faite Répertoire: catalogue de noms de fichiers Fichier normal: fichier contenant des données appartenant aux utilisateurs (fichiers texte, source, exécutable) Lien symbolique: pointeur sur un autre fichier Fichier spécial: fichier associé à un pilote de périphérique intégré dans le noyau. Un accès à un fichier spécial correspond en fait à un accès au périphérique physique qui lui est associé Tube nommé: canal de communication pouvant être utilisé par plusieurs processus pour échanger des données
 Lien symbolique: pointeur sur un autre fichier. Fichier spécial: fichier associé à un pilote de périphérique intégré dans le noyau. Un accès à un fichier spécial correspond en fait à un accès au périphérique physique qui lui est associé. Tube nommé: canal de communication pouvant être utilisé par plusieurs processus pour échanger des données.")
9
Concepts et opérations de base
Types de fichiers

10
Concepts et opérations de base
Attributs de fichiers: Chaque fichier est associé à plusieurs attributs: Sa taille en octets L’identificateur de l’utilisateur ayant créé le fichier L’identificateur du groupe d’utilisateurs propriétaires du fichier Le nombre de liens Ses droits d’accès (Read, Write, eXecute) Exprimé par un triplet Permissions de l’utilisateur Permissions du groupe propriétaire Permissions des autres utilisateur Les dates d’accès et de modification Dernier accès (atime) Dernière modification du contenu (mtime) Dernière modification du fichier (ctime)
 Exprimé par un triplet. Permissions de l’utilisateur. Permissions du groupe propriétaire. Permissions des autres utilisateur. Les dates d’accès et de modification. Dernier accès (atime) Dernière modification du contenu (mtime) Dernière modification du fichier (ctime)")
11
Concepts et opérations de base
Attributs de fichiers (Windows XP)
")
12
Concepts et opérations de base
Attributs de fichiers (LINUX)
")
13
Concepts et opérations de base
Droits d’accès Répertoire: Droit de lecture permet de lister son contenu, le droit d’écriture permet de créer et supprimer des entrées dans ce répertoire, le droit d’exécution indique que l’on peut traverser le répertoire Quand un processus qui accède à un fichier, LINUX compare alors les droits requis par l’opération et les permissions associées au fichier

14
Concepts et opérations de base
Descripteurs d’I/O fichier Un descripteur d’I/O est alloué par LINUX pour chaque fichier ouvert (open()) sur lequel s’effectue des opérations de lecture ou d ’écriture et est désalloué lors de la fermeture du fichier (close()) Le processus qui agit sur un fichier doit fournir son descripteur à chaque opération de d’I/O (read() et write()) Ces descripteurs sont des entiers qui représentent un index (une entrée) dans une table de descripteurs. Chaque descripteur est composé d’informations de contrôle correspondant aux fichiers ouverts, que le noyau utilise pour gérer les I/O sur les fichiers Descripteur d’I/O 0 représente l’entrée standard associée au clavier Descripteur d’I/O 1 représente la sortie standard associée à l ’écran Descripteur d’I/O 2 représente la sortie d’erreur associée à l ’écran
) sur lequel s’effectue des opérations de lecture ou d ’écriture et est désalloué lors de la fermeture du fichier (close()) Le processus qui agit sur un fichier doit fournir son descripteur à chaque opération de d’I/O (read() et write()) Ces descripteurs sont des entiers qui représentent un index (une entrée) dans une table de descripteurs. Chaque descripteur est composé d’informations de contrôle correspondant aux fichiers ouverts, que le noyau utilise pour gérer les I/O sur les fichiers. Descripteur d’I/O 0 représente l’entrée standard associée au clavier. Descripteur d’I/O 1 représente la sortie standard associée à l ’écran. Descripteur d’I/O 2 représente la sortie d’erreur associée à l ’écran.")
15
Concepts et opérations de base
Appels système (I/O sur fichiers) Sauvegarde des données modifiées: lors d’une écriture dans un fichier, les données sont d’abord écrites dans des tampons mémoire par le buffer cache, puis sauvegardées régulièrement sur disque par le processus update. Si le fichier est ouvert avec l’option O_SYNC, les modifications sont écrites immédiatement sur le disque La sauvegarde dans des tampons mémoire est avantageuse: Les processus écrivant dans des fichiers ne sont pas suspendus, le noyau se charge d’écrire les données sur disque de manière asynchrone Lorsque plusieurs processus accèdent aux mêmes fichiers, seule la première lecture est effectuée sur le disque, les lectures suivantes des mêmes données s’effectuent par un transfert de données entre les tampons mémoire du buffer cache et les espaces d’adressage des différents processus L’écriture asynchrone est problématique dans les cas de panne (perte de données entre l’appel à write() et l’écriture réelle)
 Sauvegarde des données modifiées: lors d’une écriture dans un fichier, les données sont d’abord écrites dans des tampons mémoire par le buffer cache, puis sauvegardées régulièrement sur disque par le processus update. Si le fichier est ouvert avec l’option O_SYNC, les modifications sont écrites immédiatement sur le disque. La sauvegarde dans des tampons mémoire est avantageuse: Les processus écrivant dans des fichiers ne sont pas suspendus, le noyau se charge d’écrire les données sur disque de manière asynchrone. Lorsque plusieurs processus accèdent aux mêmes fichiers, seule la première lecture est effectuée sur le disque, les lectures suivantes des mêmes données s’effectuent par un transfert de données entre les tampons mémoire du buffer cache et les espaces d’adressage des différents processus. L’écriture asynchrone est problématique dans les cas de panne (perte de données entre l’appel à write() et l’écriture réelle)")
16
Concepts et opérations de base
Appels système (I/O sur fichiers) Changement de taille d’un fichier #include <unistd.h> int truncate(const char *pathname, size_t length); int ftruncate(int fd, size_t length); length: nouvelle taille du fichier en octets (descripteur d’I/O: fd; nom: pathname) truncate() permet de modifier la taille d’un fichier. Si le fichier est plus grand que length son contenu est tronqué, s’il est plus petit son contenu est étendu Droits d’accès sur un fichier #include <sys/types.h> #include <sys/stat.h> int chmod(const char *pathname, mode_t mode); int fchmod(int fd, mode_t mode); chmod() permet de modifier les droits d’accès (mode) d’un fichier. Ces appels sont autorisés pour l’utilisateur propriétaire et le super-utilisateur
 Changement de taille d’un fichier. #include <unistd.h> int truncate(const char *pathname, size_t length); int ftruncate(int fd, size_t length); length: nouvelle taille du fichier en octets (descripteur d’I/O: fd; nom: pathname) truncate() permet de modifier la taille d’un fichier. Si le fichier est plus grand que length son contenu est tronqué, s’il est plus petit son contenu est étendu. Droits d’accès sur un fichier. #include <sys/types.h> #include <sys/stat.h> int chmod(const char *pathname, mode_t mode); int fchmod(int fd, mode_t mode); chmod() permet de modifier les droits d’accès (mode) d’un fichier. Ces appels sont autorisés pour l’utilisateur propriétaire et le super-utilisateur.")
17
Concepts et opérations de base
Appels système (I/O sur fichiers) Création de répertoires #include <sys/types.h> #include <fcntl.h> #include <unistd.h> int mkdir(const char *pathname, mode_t mode); mkdir() permet de créer un répertoire pathname avec les droits d’accès (mode) correspondant Suppression de répertoires int rmdir(const char *pathname); rmdir() permet de supprimer un répertoire pathname vide
 Création de répertoires. #include <sys/types.h> #include <fcntl.h> #include <unistd.h> int mkdir(const char *pathname, mode_t mode); mkdir() permet de créer un répertoire pathname avec les droits d’accès (mode) correspondant. Suppression de répertoires. int rmdir(const char *pathname); rmdir() permet de supprimer un répertoire pathname vide.")
18
Concepts et opérations de base
Appels système (I/O sur fichiers) Établir le répertoire courant #include <unistd.h> int chdir(const char *pathname); int fchdir(int fd); chdir() permet d’établir le répertoire pathname comme répertoire courant Exploration de répertoires #include <sys/types.h> #include <dirent.h> DIR *opendir(const char *pathname); struct dirent *readdir(DIR *dir); int closedir(DIR *dir); LINUX ne permet pas l’accès par un read() au catalogue des répertoires
 Établir le répertoire courant. #include <unistd.h> int chdir(const char *pathname); int fchdir(int fd); chdir() permet d’établir le répertoire pathname comme répertoire courant. Exploration de répertoires. #include <sys/types.h> #include <dirent.h> DIR *opendir(const char *pathname); struct dirent *readdir(DIR *dir); int closedir(DIR *dir); LINUX ne permet pas l’accès par un read() au catalogue des répertoires.")
19
Concepts et opérations de base
Appels système (I/O sur fichiers) Exploration de répertoires Le type DIR est définit dans <dirent.h> et représente un descripteur de répertoire ouvert. Son contenu n’est pas accessible de la même façon que le type FILE utilisée par la librairie libc opendir() permet l’ouverture d’un répertoire pathname en lecture et retourne un descripteur de répertoire ouvert (DIR) readdir() effectue la lecture d’une entrée du répertoire dont le descripteur est passé dans le paramètre dir et retourne un pointeur sur une structure dirent contenant les caractéristiques de l’entrée courante du répertoire (NULL si la fin du répertoire est atteinte) struct dirent{ long d_ino; // numéro d’inode de l’entrée unsigned short d_reclen; // taille de la structure retournée char [] d_name; // nom du fichier contenu dans l’entrée }
 Exploration de répertoires. Le type DIR est définit dans <dirent.h> et représente un descripteur de répertoire ouvert. Son contenu n’est pas accessible de la même façon que le type FILE utilisée par la librairie libc. opendir() permet l’ouverture d’un répertoire pathname en lecture et retourne un descripteur de répertoire ouvert (DIR) readdir() effectue la lecture d’une entrée du répertoire dont le descripteur est passé dans le paramètre dir et retourne un pointeur sur une structure dirent contenant les caractéristiques de l’entrée courante du répertoire (NULL si la fin du répertoire est atteinte) struct dirent{ long d_ino; // numéro d’inode de l’entrée. unsigned short d_reclen; // taille de la structure retournée. char [] d_name; // nom du fichier contenu dans l’entrée. }")
20
Concepts et opérations de base
Exploration de répertoires (Voir ListeRep.c)
")
21
Concepts et opérations avancées
i-nodes Les utilisateurs représentent les fichiers par des noms, absolus ou relatifs. LINUX utilise des identificateurs internes. Chaque fichier est référencé de façon unique par deux nombres: Le numéro de périphérique qui référence un périphérique et par le fait même le système de fichiers qu’il contient Le numéro de fichier qui référence de manière unique un fichier présent dans le système de fichiers Chaque système de fichiers UNIX conserve une table de descripteurs de fichiers sur disque. Ces descripteurs appelés i-node contiennent les informations (attributs des fichiers, adresses des blocs de données sur disque) de contrôle utilisées pour gérer les fichiers Le numéro de fichier unique est utilisé par le noyau comme index dans la table de i-nodes permettant de le convertir en descripteur de fichier Lorsqu’un processus effectue un appel système en lui fournissant un nom de fichier, le noyau convertit ce nom en descripteur de fichier. Pour ce faire, LINUX explore chacun des répertoires contenu dans le nom de fichier (pathname) et compare chaque entrée de répertoire (nom de fichier, numéro d’i-node) avec le nom simple de l’élément suivant
 de contrôle utilisées pour gérer les fichiers. Le numéro de fichier unique est utilisé par le noyau comme index dans la table de i-nodes permettant de le convertir en descripteur de fichier. Lorsqu’un processus effectue un appel système en lui fournissant un nom de fichier, le noyau convertit ce nom en descripteur de fichier. Pour ce faire, LINUX explore chacun des répertoires contenu dans le nom de fichier (pathname) et compare chaque entrée de répertoire (nom de fichier, numéro d’i-node) avec le nom simple de l’élément suivant.")
22
Concepts et opérations avancées
i-nodes Format d’un répertoire

23
Concepts et opérations avancées
i-nodes Si le nom spécifié est /usr/src/linux/fs/dcache.c, le noyau effectue les opérations suivantes: i-node racine / est chargé, recherche de l’entrée usr i-node /usr est chargé, recherche de l’entrée src i-node /usr/src est chargé, recherche de l’entrée linux i-node /usr/src/linux est chargé, recherche de l’entrée fs i-node /usr/src/linux/fs est chargé, recherche de l’entrée dcache.c, ce qui fournit le numéro d’i-node désiré Descripteurs d’I/O Les descripteurs d’I/O retournés par la primitive open(), sont utilisés par les appels système d’I/O sur fichiers Le noyau conserve des tables de descripteurs de fichiers ouverts
, sont utilisés par les appels système d’I/O sur fichiers. Le noyau conserve des tables de descripteurs de fichiers ouverts.")
24
Concepts et opérations avancées
Descripteurs d’I/O LINUX gère plusieurs tables en mémoire: Le descripteur de chaque processus (structure task_struct) pointe sur une table des fichiers ouverts par le processus Chaque élément de la table de fichiers ouverts pointe sur un élément d’une table contenant la description de tous les fichiers ouverts dans le système Chaque descripteur de fichier ouvert possède un pointeur sur un élément de la table des i-nodes correspondant aux fichiers en cours d’utilisation Lorsqu’un processus utilise open() pour ouvrir un fichier: Le noyau convertit le nom de fichier en un couple (numéro de périphérique, numéro d’i-node) Il charge ensuite, l’i-node en mémoire s’il n’est pas déjà présent dans la table des i-nodes Un descripteur dans la table de fichiers ouverts est ensuite alloué, est initialisé et le fait pointer sur l’élément de la table des i-nodes déjà alloué Le noyau alloue un descripteur dans la table des fichiers ouverts par le processus, qui pointe sur le descripteur de fichier ouvert
 pointe sur une table des fichiers ouverts par le processus. Chaque élément de la table de fichiers ouverts pointe sur un élément d’une table contenant la description de tous les fichiers ouverts dans le système. Chaque descripteur de fichier ouvert possède un pointeur sur un élément de la table des i-nodes correspondant aux fichiers en cours d’utilisation. Lorsqu’un processus utilise open() pour ouvrir un fichier: Le noyau convertit le nom de fichier en un couple (numéro de périphérique, numéro d’i-node) Il charge ensuite, l’i-node en mémoire s’il n’est pas déjà présent dans la table des i-nodes. Un descripteur dans la table de fichiers ouverts est ensuite alloué, est initialisé et le fait pointer sur l’élément de la table des i-nodes déjà alloué. Le noyau alloue un descripteur dans la table des fichiers ouverts par le processus, qui pointe sur le descripteur de fichier ouvert.")
25
Concepts et opérations avancées
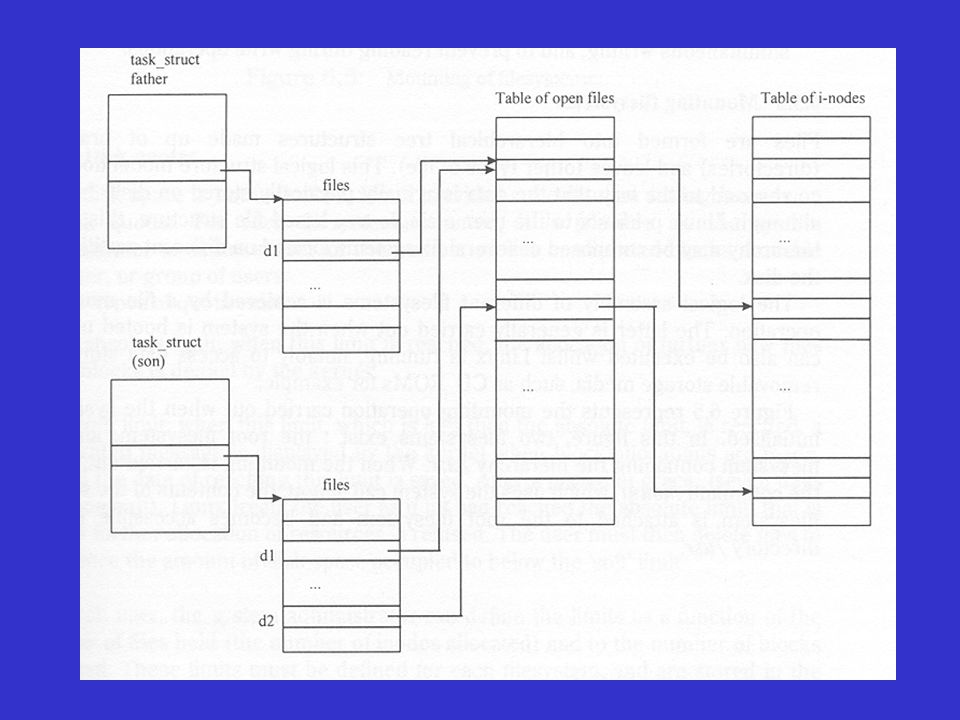
Descripteurs d’I/O Lorsqu’un processus effectue une opération d’I/O en fournissant au noyau un numéro de descripteur d’I/O: LINUX utilise ce numéro comme indice dans la table des fichiers ouverts par le processus Un pointeur permet d’avoir accès à la table de fichiers ouverts Un autre pointeur à partir de la table des fichiers ouverts pointe sur la table des i-nodes L’informations contenues dans le i-node permet au noyau d’accéder au fichier sur disque

26
Concepts et opérations avancées
Tables des descripteurs d’I/O

27
Concepts et opérations avancées
Partage de descripteurs Lorsqu’un processus se duplique (fork()), le fils hérite de la table de fichiers du père Les deux processus peuvent alors effectuer des I/O sur les fichiers qui ont été ouverts par le processus père Dans l’exemple PartageDesc.c, un processus père ouvre un fichier (avec d1 comme descripteur d’I/O) et ouvre un processus fils qui ouvre un autre fichier (avec d2 comme descripteur d’I/O). Les deux processus peuvent avoir accès au fichier référencé par d1
), le fils hérite de la table de fichiers du père. Les deux processus peuvent alors effectuer des I/O sur les fichiers qui ont été ouverts par le processus père. Dans l’exemple PartageDesc.c, un processus père ouvre un fichier (avec d1 comme descripteur d’I/O) et ouvre un processus fils qui ouvre un autre fichier (avec d2 comme descripteur d’I/O). Les deux processus peuvent avoir accès au fichier référencé par d1.")
30
Représentation des fichiers dans le noyau
Avant un fork: i-node table entries file A file A parent’s per process descriptor table file pos ... refcnt = 1 st_mode ... st_size file B file B file pos ... refcnt = 1 st_mode ... st_size

31
Représentation des fichiers dans le noyau
Après le fork (le processus enfant hérite de la table de fichiers ouverts: parent’s per process descriptor table i-node table entries file A file A file pos ... refcnt = 2 st_mode ... st_size file B file B child’s per process descriptor table file pos ... refcnt = 2 st_mode ... st_size

32
Représentation des fichiers dans le noyau
Opérations I/0 (open() et read()):
 et read()):")
33
Implémentation Le Virtual File System (VFS)
LINUX supporte plusieurs types de systèmes de fichiers: Ext2fs (Ext3fs): système de fichiers natifs Minix, MS/DOS: systèmes de fichiers permettant l’accès aux données d’autres systèmes d’exploitation proc: système de fichiers virtuels rendant accessible certaines informations gérées par le noyau (gestion des processus) Pour permettre aux processus d’avoir un accès uniforme aux fichiers, quelque soit le type de système de fichiers qui les contient, le noyau offre une couche logicielle assurant l’interfaçage entre les appels système concernant les fichiers et le code de gestion des fichiers
: système de fichiers natifs. Minix, MS/DOS: systèmes de fichiers permettant l’accès aux données d’autres systèmes d’exploitation. proc: système de fichiers virtuels rendant accessible certaines informations gérées par le noyau (gestion des processus) Pour permettre aux processus d’avoir un accès uniforme aux fichiers, quelque soit le type de système de fichiers qui les contient, le noyau offre une couche logicielle assurant l’interfaçage entre les appels système concernant les fichiers et le code de gestion des fichiers.")
34
Implémentation Le Virtual File System (VFS)
")
35
Implémentation Le Virtual File System (VFS)
")
36
Implémentation Le Virtual File System (VFS)
Quand un processus effectue un appel système sur fichiers, cet appel est dirigé vers le VFS Le VFS fournit les fonctionnalités indépendantes des systèmes de fichiers physiques, il implémente entre autres: Le cache de noms: quand un nom de fichier est converti (exploration des répertoires du chemin d’accès au fichier) en numéro de périphérique et d’i-node, le résultat est mémorisé dans une liste. Les appels suivants sur le même fichier ne nécessitent pas de conversion Le buffer cache: LINUX maintient une liste des tampons mémoire en cours d’utilisation. Lors de la lecture de bloc par un système de fichiers, le contenu du bloc est placé dans un tampon mémoire (buffer). Ce tampon est gardé en mémoire tant que le bloc est en cours d’utilisation et tant que l’espace mémoire qu’il occupe ne doit être alloué à un autre tampon
 en numéro de périphérique et d’i-node, le résultat est mémorisé dans une liste. Les appels suivants sur le même fichier ne nécessitent pas de conversion. Le buffer cache: LINUX maintient une liste des tampons mémoire en cours d’utilisation. Lors de la lecture de bloc par un système de fichiers, le contenu du bloc est placé dans un tampon mémoire (buffer). Ce tampon est gardé en mémoire tant que le bloc est en cours d’utilisation et tant que l’espace mémoire qu’il occupe ne doit être alloué à un autre tampon.")
37
Implémentation Le Virtual File System (VFS)
Le VFS fournit les fonctionnalités indépendantes des systèmes de fichiers physiques, il implémente entre autres: Le buffer cache: Lors d’une modification de données dans un bloc, le changement est est effectué dans le tampon mémoire et le tampon est marqué comme modifié mais n’est pas réécrit immédiatement sur disque. Le processus update() appelle à intervalle régulier la primitive sync() pour forcer la réécriture de tous les tampons modifiés Le VFS gère les appels système selon l’algorithme suivant: Vérification des arguments Conversion du nom de fichier en numéros de périphérique et d’i-node Vérification des permissions Appel de la fonction du type de système de fichiers correspondant
 appelle à intervalle régulier la primitive sync() pour forcer la réécriture de tous les tampons modifiés. Le VFS gère les appels système selon l’algorithme suivant: Vérification des arguments. Conversion du nom de fichier en numéros de périphérique et d’i-node. Vérification des permissions. Appel de la fonction du type de système de fichiers correspondant.")
38
Implémentation Le Virtual File System (VFS) Buffer cache
 Buffer cache")
39
Implémentation Structures du VFS (I-node en cours d’utilisation)
LINUX utilise un descripteur d’i-node pour référencer chaque fichier en cours d’utilisation. Chaque descripteur correspond à une structure inode Les descripteurs d’i-node sont chaînés dans plusieurs listes: Liste globale: first_inode pointe sur le début d’une liste de tous les descripteurs d’i-node Listes de hachage: une fonction de hachage agissant sur l’identificateur de périphérique et le numéro d’i-node permet de placer les descripteurs dans des listes différentes de taille plus réduite ce qui accélère les recherches

40
Implémentation Structures du VFS (I-node en cours d’utilisation)
Structure inode

43
Implémentation Structures du VFS (Fichiers ouverts)
Chaque fichier ouvert dans le système est associé à un descripteur (structure file) Les descripteurs de fichiers sont chaînés dans une liste globale dont le premier élément est pointé par la variable first_file
 Les descripteurs de fichiers sont chaînés dans une liste globale dont le premier élément est pointé par la variable first_file.")
44
Implémentation Structures du VFS (Fichiers ouverts) Structure file
 Structure file")
45
Implémentation Structures du VFS (Fichiers ouverts par un processus)
Chaque processus possède une table de descripteurs (structure files_struct) de fichiers locaux référencée par le champ files de la structure task_struct
 de fichiers locaux référencée par le champ files de la structure task_struct.")
46
Implémentation Structures du VFS (Tampons mémoire du buffer cache)
Le buffer cache gère les tampons mémoire associés aux blocs sur disque La structure buffer_head définit le format des descripteurs des tampons de mémoire

47
Implémentation Structures du VFS (Tampons mémoire du buffer cache)
Structure buffer_head

48
Implémentation Buffer cache (Description)
Le buffer cache gère les tampons mémoire qui servent de réservoir de données entre l’usager et les périphériques de masse La gestion du buffer cache interagit aussi avec la gestion de la mémoire puisque les tampons mémoires sont placés dans des pages mémoires et l’état des pages mémoires doit être souvent consulté ou modifié Le buffer cache utilise les champs count (nombre de références à une page), flags (état d’une page) et buffers (adresse du premier descripteur de tampon contenue dans une page) de la structure page
, flags (état d’une page) et buffers (adresse du premier descripteur de tampon contenue dans une page) de la structure page.")
49
Implémentation Buffer cache (Description) Fonctions de gestion
Gestion des listes où sont enregistrées les tampons mémoires Réalisation des I/O Création des tampons mémoire dans les pages mémoire Les I/O sur les pages mémoire Opérations de déverrouillage et de désallocation de tampons (fin d’une I/O) Modifier la taille du buffer cache: Le buffer cache commence ses opérations vide, sans tampon mémoire, de nouvelles pages lui sont allouées lorsque des tampons mémoire sont requis Gestion des périphériques: Des fonctions permettent d’agir sur les tampons mémoire associés à un périphérique
 Modifier la taille du buffer cache: Le buffer cache commence ses opérations vide, sans tampon mémoire, de nouvelles pages lui sont allouées lorsque des tampons mémoire sont requis. Gestion des périphériques: Des fonctions permettent d’agir sur les tampons mémoire associés à un périphérique.")
50
Implémentation Buffer cache (Description) Fonctions de gestion
Services d’accès aux tampons Réécriture des tampons sur disque Gestion des clusters Initialisation du buffer cache

51
Implémentation Systèmes de fichiers supportés (ext2fs => ext3fs => ext4fs)
")
52
Implémentation Systèmes de fichiers supportés
LINUX ne supportait initialement que le système de fichiers MINIX, mais avec des limitations importantes (taille limitée à 64 Mo, nom de fichiers limités à 14 caractères) Pour lever ces limitations, d’autres systèmes de fichiers ont été développés dont ext2fs qui offre une bonne performance (taille maximale 4 To, taille maximale d’un fichier 2 Go, taille maximale d’un nom de fichier 255 caractères, etc.)
 Pour lever ces limitations, d’autres systèmes de fichiers ont été développés dont ext2fs qui offre une bonne performance (taille maximale 4 To, taille maximale d’un fichier 2 Go, taille maximale d’un nom de fichier 255 caractères, etc.)")
53
Implémentation Systèmes de fichiers supportés (Ext2)
Ext2 supporte les fichiers UNIX (fichiers réguliers, répertoires, fichiers spéciaux, liens symboliques) Un système de fichiers comme Ext2 doit être présent sur un périphérique physique (disque dur). De plus, le contenu du périphérique est décomposé logiquement en plusieurs parties Le secteur de boot contient le code machine permettant le chargement du noyau lors du démarrage du système Les ensembles de blocs décomposés eux-mêmes: Une copie du superbloc: Contient les informations de contrôle du système de fichiers (structure du volume) Une table de descripteurs: Contiennent les adresses sur disque des blocs contenant les blocs de bitmap et la table des i-node Un bloc de bitmap (table de bits) pour les blocs de données: Un bit est associé à chaque bloc de l’ensemble (1: bloc alloué, 0: bloc disponible)
 Un système de fichiers comme Ext2 doit être présent sur un périphérique physique (disque dur). De plus, le contenu du périphérique est décomposé logiquement en plusieurs parties. Le secteur de boot contient le code machine permettant le chargement du noyau lors du démarrage du système. Les ensembles de blocs décomposés eux-mêmes: Une copie du superbloc: Contient les informations de contrôle du système de fichiers (structure du volume) Une table de descripteurs: Contiennent les adresses sur disque des blocs contenant les blocs de bitmap et la table des i-node. Un bloc de bitmap (table de bits) pour les blocs de données: Un bit est associé à chaque bloc de l’ensemble (1: bloc alloué, 0: bloc disponible)")
54
Implémentation Systèmes de fichiers supportés (Ext2)
Les ensembles de blocs décomposés eux-mêmes: Un bloc de bitmap (table de bits) pour les i-node: Pour chaque i-node de l’ensemble est associé un bit (1: i-node alloué, 0: i-node disponible) Une table de i-node: Contient une partie de la table des i-node du système de fichiers Blocs de données: Contient les données contenues dans les fichiers et les répertoires
 pour les i-node: Pour chaque i-node de l’ensemble est associé un bit (1: i-node alloué, 0: i-node disponible) Une table de i-node: Contient une partie de la table des i-node du système de fichiers. Blocs de données: Contient les données contenues dans les fichiers et les répertoires.")
55
Implémentation Systèmes de fichiers supportés (Ext2)
Ensembles de blocs

56
Implémentation Systèmes de fichiers supportés (Ext2)
Un système de fichiers est organisé logiquement en fichiers et en répertoires. Un répertoire est un fichier de type particulier dont chaque entrée (structure ext2_dir_entry) contient plusieurs champs: Le numéro d’i-node correspondant au fichier La taille de cette entrée en octets Le nombre de caractères du nom de fichier Le nom du fichier
 contient plusieurs champs: Le numéro d’i-node correspondant au fichier. La taille de cette entrée en octets. Le nombre de caractères du nom de fichier. Le nom du fichier.")
57
Implémentation Systèmes de fichiers supportés (Ext2)
Structure ext2_dir_entry

58
Implémentation Systèmes de fichiers supportés (Ext2)
Structure d’un répertoire

59
Implémentation Ext2 (superbloc)
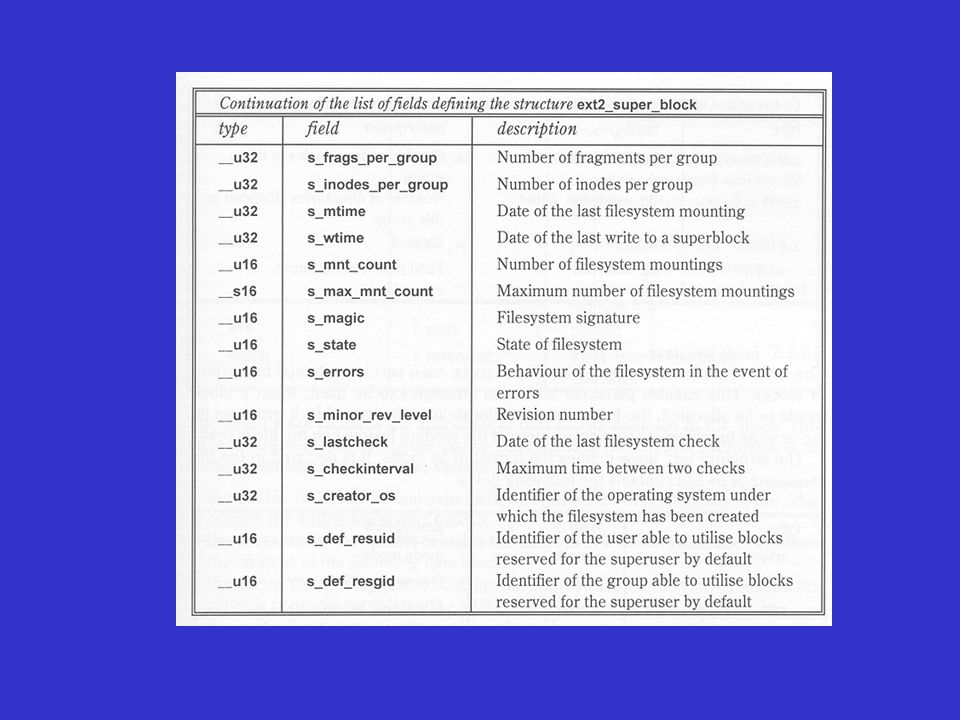
Le superbloc (structure ext2_super_block) contient les informations de contrôle du système de fichiers
 contient les informations de contrôle du système de fichiers.")
61
Ext2 (structure d’un i-node)
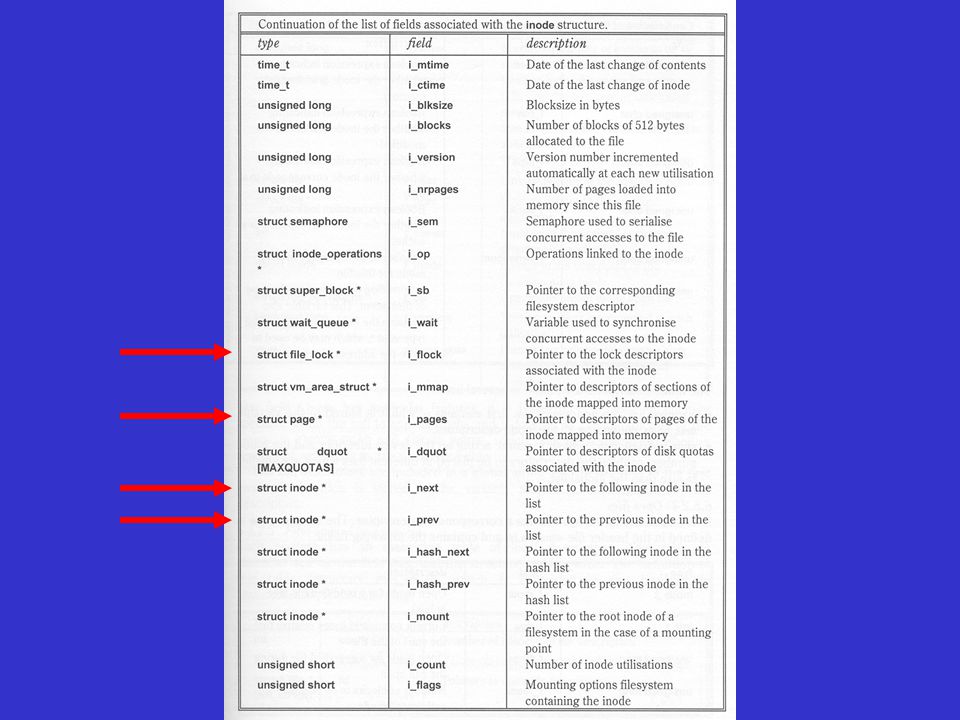
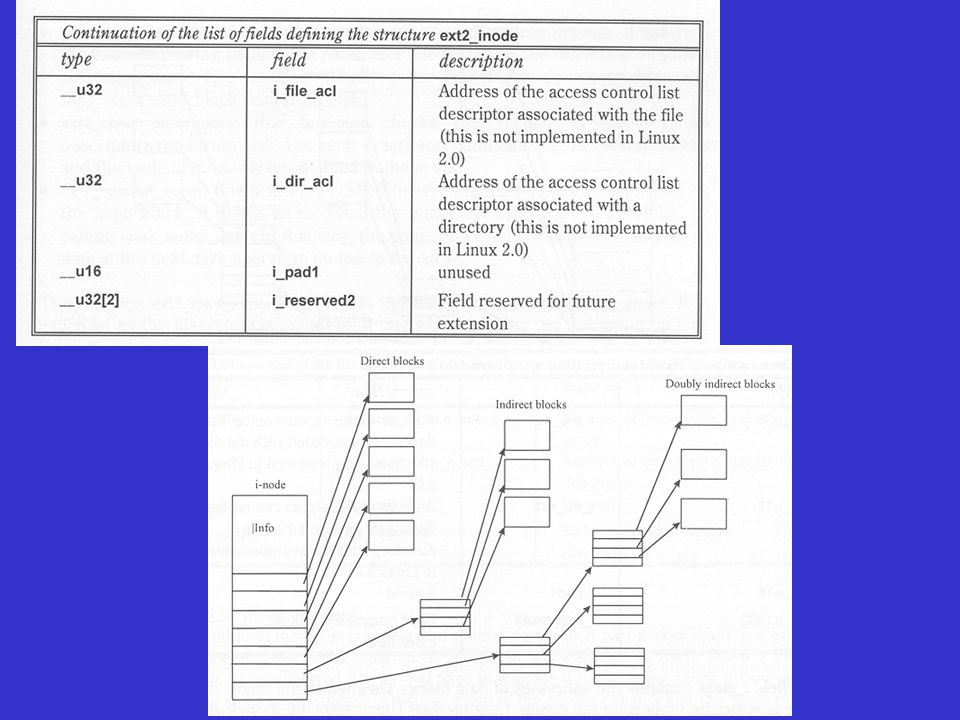
Implémentation Ext2 (structure d’un i-node) Un i-node (structure ext2_inode) décrit chaque fichier dans le système de fichiers Le champ i_block contient les adresses des blocs de données associés à l’i-node
 Un i-node (structure ext2_inode) décrit chaque fichier dans le système de fichiers. Le champ i_block contient les adresses des blocs de données associés à l’i-node.")
63
Implémentation Ext2 (structure d’un i-node)
")
64
Implémentation (UNIX)
Inodes d’UNIX (index node) La structure d’un système de fichiers UNIX Secteur du logiciel de chargement (Boot Block) Super Block contient des informations sur le système de fichier qui sont copiées dans la RAM au boot Dimension maximale Nombre de Inode Nombre de blocs de données Pointeur sur la liste des Inode libres Chaque fichier et répertoire est représenté par une structure inode de 64 octets, contenant des informations de contrôle d’accès et 10 pointeurs directs à des blocs de données Pour des fichiers plus gros, deux pointeurs indirects peuvent pointer chacun sur 10 blocs d’inode donnant ainsi accès à 100 blocs de données
 La structure d’un système de fichiers UNIX. Secteur du logiciel de chargement (Boot Block) Super Block contient des informations sur le système de fichier qui sont copiées dans la RAM au boot. Dimension maximale. Nombre de Inode. Nombre de blocs de données. Pointeur sur la liste des Inode libres. Chaque fichier et répertoire est représenté par une structure inode de 64 octets, contenant des informations de contrôle d’accès et 10 pointeurs directs à des blocs de données. Pour des fichiers plus gros, deux pointeurs indirects peuvent pointer chacun sur 10 blocs d’inode donnant ainsi accès à 100 blocs de données.")
65
Implémentation (UNIX)
Inodes d’UNIX (index node) Structure d’un Inode st_ino est le champ le plus important puisqu’il permet l’accès au premier bloc de données associé à un fichier
 Structure d’un Inode. st_ino est le champ le plus important puisqu’il permet l’accès au premier bloc de. données associé à un fichier.")
66
Implémentation (UNIX)
Inodes d’UNIX (index node) Un système de fichiers est organisé logiquement en fichiers et en répertoires. Un répertoire est un fichier de type particulier dont chaque entrée contient plusieurs champs: Le numéro d’i-node correspondant au fichier La taille de cette entrée en octets Le nombre de caractères du nom de fichier Le nom du fichier Les inodes de fichier contiennent des pointeurs sur des blocs de données Les inodes de répertoire contiennent des pointeurs sur des blocs contenant des listes de numéro d’inode/nom de fichier
 Un système de fichiers est organisé logiquement en fichiers et en répertoires. Un répertoire est un fichier de type particulier dont chaque entrée contient plusieurs champs: Le numéro d’i-node correspondant au fichier. La taille de cette entrée en octets. Le nombre de caractères du nom de fichier. Le nom du fichier. Les inodes de fichier contiennent des pointeurs sur des blocs de données. Les inodes de répertoire contiennent des pointeurs sur des blocs contenant des listes de numéro d’inode/nom de fichier.")
67
Implémentation (UNIX)
Inodes d’UNIX (index node) Forme générale d’un inode
 Forme générale d’un inode.")
68
Implémentation (UNIX)
Inodes d’UNIX (index node) Forme générale d’un inode
 Forme générale d’un inode.")
69
Implémentation (FAT, NTFS, UNIX)
Inodes d’UNIX (index node) Pointeurs d’inode sur des blocs de données
 Pointeurs d’inode sur des blocs de données.")
70
Implémentation (UNIX)
Inodes d’UNIX (index node) Pointeurs d’inode sur des blocs de données et des répertoires
 Pointeurs d’inode sur des blocs de données et des répertoires.")
71
Implémentation (UNIX)
Inodes d’UNIX (index node) Pointeurs d’inode sur des blocs de données et des répertoires
 Pointeurs d’inode sur des blocs de données et des répertoires.")
Présentations similaires




>")



>")
>")











