Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
MISE EN PLACE D’UN PIPELINE DE TRAITEMENT
DESS Bioinformatique ( ) MISE EN PLACE D’UN PIPELINE DE TRAITEMENT DE SEQUENCES ISSUES DE BANQUES ENRICHIES EN SEQUENCES MICROSATELLITES ASSOCIE A UNE BASE DE DONNEES Alexis DEREEPER Université Montpellier II CIRAD – Programme Biotrop Encadrement : Jean-François Rami, Claire Billot, Manuel Ruiz
 MISE EN PLACE D’UN PIPELINE DE TRAITEMENT. DE SEQUENCES ISSUES DE BANQUES ENRICHIES EN SEQUENCES MICROSATELLITES. ASSOCIE A UNE BASE DE DONNEES. Alexis DEREEPER. Université Montpellier II. CIRAD – Programme Biotrop. Encadrement : Jean-François Rami, Claire Billot, Manuel Ruiz.")
2
PLAN I - Introduction II – Contexte biologique III – Mise en place du pipeline IV – Base de données V – Interface web VI – Conclusions et perspectives

3
Besoin d’un pipeline de traitement automatique
I - Introduction CIRAD : Organisme scientifique français spécialisé en recherche agronomique appliquée aux régions chaudes. Programme BIOTROP : Utilisation de la biologie moléculaire pour étudier la diversité génétique des plantes (marqueurs moléculaires, cartographie) réalisation de banques enrichies en séquences microsatellites séquençage Obtention de marqueurs microsatellites exploitables Analyse des séquences Besoin d’un pipeline de traitement automatique
 réalisation de banques enrichies en séquences microsatellites. séquençage. Obtention de marqueurs microsatellites exploitables. Analyse des séquences. Besoin d’un pipeline de traitement automatique.")
4
Plante A Plante B (GT)8 (GT)12 II – Contexte biologique
Microsatellite : courte séquence de motifs d’ADN répétés en tandem Unité de répétition variant de 1 à 6 pb : (CA)n, (CTT)n… polymorphisme multiallélique détecté par PCR puis électrophorèse du locus (microsat + régions flanquantes) GTGTGTGTGTGTGTGT CACACACACACACACA Plante A Plante B GTGTGTGTGTGTGTGTGTGTGTGT CACACACACACACACACACACACA Primer 1 Primer1 Primer 2 amplification PCR A B (GT)8 (GT)12 2 allèles
n, (CTT)n… polymorphisme multiallélique détecté par PCR puis électrophorèse du locus (microsat + régions flanquantes) GTGTGTGTGTGTGTGT. CACACACACACACACA. Plante A. Plante B. GTGTGTGTGTGTGTGTGTGTGTGT. CACACACACACACACACACACACA. Primer 1. Primer1. Primer 2. amplification PCR. A. B. (GT)8. (GT)12. 2 allèles.")
5
REALISATION DE BANQUES
GTGTGTGT TGTGTGTG RsaI Digestion enzymatique par RsaI GTGTGTGT TGTGTGTG Ligation d’adaptateurs et PCR TGTGTGTG Dénaturation et hybridation avec un oligonucléotide biotinylé GTGTGTGT REALISATION DE BANQUES Capture du microsatellite avec un complexe avidine/bille magnétique TGTGTGTG GTGTGTGT aimant Lavage, élution puis amplification par PCR GTGTGTGT clonage TGTGTGTG

6
Obtention d’une banque enrichie en séquences microsatellites
CULTURE + SELECTION Obtention d’une banque enrichie en séquences microsatellites Gène de la β-galactosidase SEQUENCAGE Gène de résistance à un antibiotique GTGTGTGTTGTGTGTG amorce forward amorce reverse CHAÎNE DE TRAITEMENT ANALYSE DES SEQUENCES Chromatogrammes de séquence

7
III - Mise en place du pipeline
Chaîne de traitement : les différentes étapes Chromatogrammes de séquence Séquences d’ADN brute Base-calling Séquences d’ADN nettoyée Élimination du vecteur et des adaptateurs Fragments de digestion ayant un microsatellite Digestion enzymatique in silico + recherche de microsatellites Séquences consensus Clustering, contigage Couples d’amorces de PCR Définition d’amorces d’amplification

8
Objectifs Mettre en place un pipeline = chaîne de traitement reliant plusieurs logiciels afin d’effectuer une tâche Sauvegarde automatique des résultats en base de données à chaque étape du pipeline traçabilité des séquences Outil convivial et paramétrable : Possibilité pour l’utilisateur de choisir les étapes à effectuer Possibilité d’une double digestion Interfaçage du pipeline et de la base de données

9
Chromatogrammes de séquence
Modélisation Un module Perl par étape, par logiciel utilisé Chromatogrammes de séquence Phred.pm Séquences d’ADN brute

10
Base-calling : module Phred.pm
>DW0AI001ZA05FM1.SCF TATCATATGGGACTGGCCGAGTGCATCTCCGCGC Fichier séquence .seq Fichier qualité .qual >DW0AI001ZA02RM1.SCF

11
Un module Perl par étape, par logiciel utilisé
Modélisation Un module Perl par étape, par logiciel utilisé Chromatogrammes de séquence Phred.pm Séquences d’ADN brute Séquences d’ADN nettoyée Lucy.pm

12
Nettoyage des séquences : module Lucy.pm
Détection de la position du vecteur Détection des régions de mauvaise qualité >DW0AI001ZA05FM1.SCF TATCATATGGGACTGGCCGAGTGCATCTCCGCGCAGGCCG Méthode retrait_vecteur(): Retrait du vecteur en fonction de la sortie de Lucy
: Retrait du vecteur en fonction de la sortie de Lucy.")
13
Un module Perl par étape, par logiciel utilisé
Modélisation Un module Perl par étape, par logiciel utilisé Chromatogrammes de séquence Séquences d’ADN brute Séquences d’ADN nettoyée Lucy.pm Phred.pm Digestion.pm + Select_ssr.pm Fragments de digestion ayant un microsatellite

14
Digestion enzymatique : module Digestion.pm
Utilisation du module Bioperl Bio::Tools::RestrictionEnzyme Utilisation de la fonction cut_seq() @fragment = $re1->cut_seq($seq); Sélection des fragments contenant un microsatellite: module Select_ssr.pm Utilisation d’un script de recherche de microsatellites >DW0AI001ZA05FM ac GCACATATGTGAAGTCCATTCAGTGGCCACTGGAGCAAGGT AACCAACGACACACACACACACACAGGT
; Sélection des fragments contenant un microsatellite: module Select_ssr.pm. Utilisation d’un script de recherche de microsatellites. >DW0AI001ZA05FM ac GCACATATGTGAAGTCCATTCAGTGGCCACTGGAGCAAGGT. AACCAACGACACACACACACACACAGGT.")
15
Un module Perl par étape, par logiciel utilisé
Modélisation Un module Perl par étape, par logiciel utilisé Chromatogrammes de séquence Séquences d’ADN brute Séquences d’ADN nettoyée Lucy.pm Phred.pm Digestion.pm + Select_ssr.pm Fragments de digestion ayant un microsatellite Séquences consensus Stackpack.pm, Cap3.pm

16
Clustering : module Stackpack.pm
Clustering : premier regroupement des séquences selon leur similarité relative Stackpack : pipeline de contigage clustering contigage analyse d2_cluster phrap craw Contigage : module Stackpack.pm ou Cap3.pm Alignement des séquences regroupées au sein d’un cluster forward reverse consensus Séquences consensus

17
Un module Perl par étape, par logiciel utilisé
Modélisation Un module Perl par étape, par logiciel utilisé Chromatogrammes de séquence Séquences d’ADN brute Séquences d’ADN nettoyée Lucy.pm DataBase.pm Base de données Requêtes Phred.pm Digestion.pm + Select_ssr.pm Fragments de digestion ayant un microsatellite Stackpack.pm, Cap3.pm Séquences consensus Couples d’amorces de PCR Primer3.pm

18
Définition d’amorces : module Primer3.pm
Utilisation du logiciel ePrimer3 de EMBOSS Cible d’amplification : positions du microsatellite sur le consensus # Start Len Tm GC% Sequence 1 PRODUCT SIZE: 116 FORWARD PRIMER GTACCCTGTGTCTCTCCTTG REVERSE PRIMER TGGTATGAAGGGTGTAGCTC

19
IV – Base de données Existence d’une base de données renfermant des informations communes: séquence brute, séquence nettoyée, contigs… Modification par ajout de nouvelles tables spécifiques

20
1 1..* 1 1..* 0..1 1..* 0..* 1..* 0..* Projet + nom_projet
+ date_creation + description Seq_init + nom_seq + source_fichier_chromato + sequence_brute + sequence_qualite + sequence_nettoyee + qual_nettoyee + nom_espece 1 1..* Cluster_element + Id_element + nom_element + sequence_consensus + num_cluster + nom_contig + longueur + align_phrap + res_align + align_craw + longest 1..* 0..1 1 A_pour_origine Seq_dig + nom_seq_dig + sequence_dig + qual_dig + enzyme + pres_micro 1..* Est_amplifié_par 1..* Primer + Id_primer + primer_compt + forw_nom + forw_seq + forw_temp + forw_size + rev_nom + rev_seq + rev_temp + rev_size + prod_size + prod_start + prod_end + valide + forw_infosblast + rev_infosblast 0..* Possède 0..* Microsat + Id_microsat + ssr_num + ssr_type + ssr + size + start + end

21
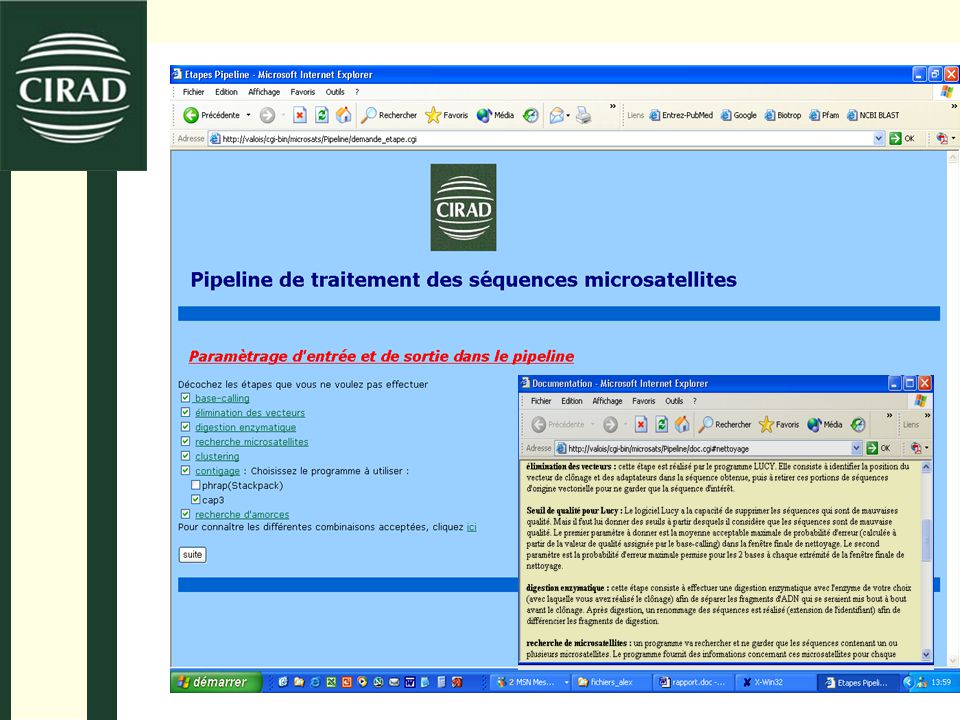
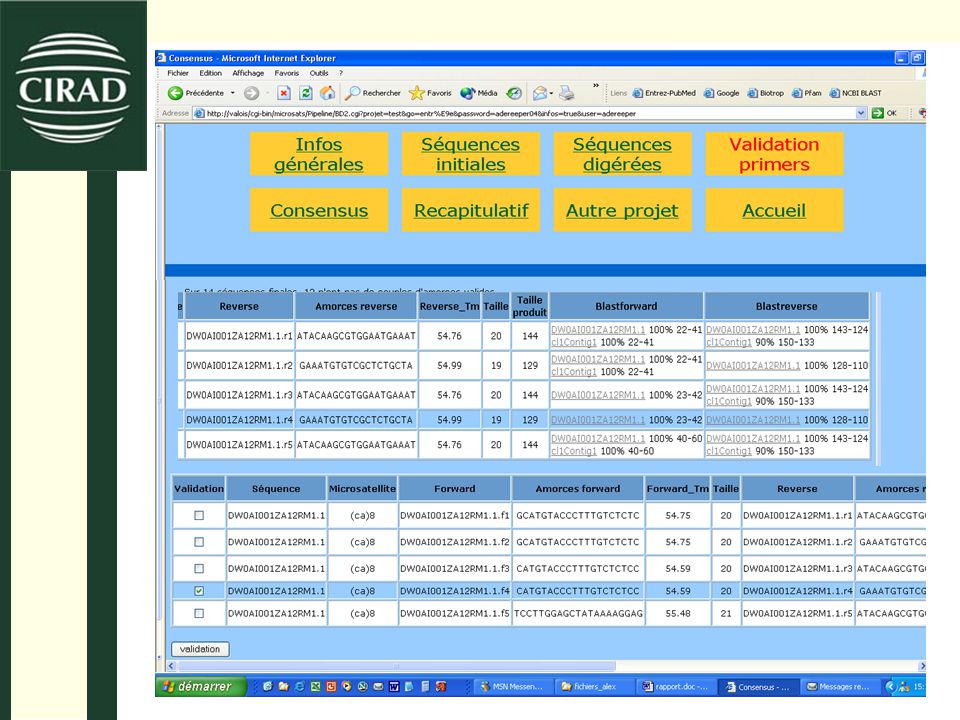
V – Interface web Nécessité d’une interface web commune au pipeline et à la base de données Manipulation de pages web par l’utilisation de scripts CGI Utilisation de feuilles de styles L’interface doit permettre de : Paramétrer le pipeline Lancer le pipeline Consulter les résultats d’un projet stockés en base de données Visualiser directement les résultats du pipeline

22
Créer un nouvel utilisateur de la BD
biologiste Interface web Consulter la base de données Lancer le pipeline S’identifier « include » Choisir les étapes à effectuer Paramétrer les différentes étapes Faire un paramétrage avancé de Cap3 « extend » Administrateur Créer un nouvel utilisateur de la BD Se connecter sur l’accueil

26
VI – Conclusions et perspectives
Découverte du langage Perl : Perl objet, BioPerl, Perl CGI Découverte d’un nouveau SGBD : MySQL Outil performant de traitement de séquences issues des banques microsatellites Possibilité pour l’utilisateur de choisir les étapes à effectuer. Possibilité de paramétrer chacune des étapes. Enregistrement des résultats en base de données à chaque étape Interface web conviviale et simple d’utilisation permettant de lancer le pipeline ou de consulter les résultats

27
Plusieurs perspectives sont envisageables pour la suite :
Effectuer un blast d’une séquence donnée que ce soit contre GenBank ou contre des banques de séquences des utilisateurs Créer une sortie automatique d’un fichier de soumission pour l’enregistrement direct dans GenBank. Un téléchargement des chromatogrammes sur le serveur pourrait être intéressant pour l’utilisateur au moment où il fournit le chemin de ses chromatogrammes. Fournir un fichier Excel répertoriant l’ensemble des couples d’amorces validés à commander. Enrichir l’interface Web de consultation des résultats par de nouvelles pages d’interrogations de la base de données

28
Merci aux intervenants du DESS pour les cours qu’ils ont enseignés
Merci de votre attention Merci à Jean-François Rami, Claire Billot, Manuel Ruiz, Pierre Larmande, pour m’avoir accueilli et encadré au CIRAD Merci aux intervenants du DESS pour les cours qu’ils ont enseignés

Présentations similaires

 Année 2006-2007 Développement en environnement J2EE de Web services pour l'interopérabilité du projet CASTORE ce stage de fin d’étude a.>")



 Obtention de l’ADN recombinant>")

 polymorphes (entre individus, espèces, …) permettant - l’établissement de cartes.>")












