Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Francesca Palma, Alexandra Volanschi, Natalie Kübler Equipe de recherche CLILLAC-ARP – Université Paris Diderot Développer un outil d’aide à la rédaction en communication scientifique - Une étude basée sur un corpus anglais pour les biologistes

2
L'anglais : langue internationale des sciences
700 millions de locuteurs dont < 50 % LM (Brumfit 2001) Science Citation Index: Anglais (95 %), Français, Allemand et Russe (4.9 %), Autres langues (0.7 %) Lingua franca (Gnutzmann 2000) ou global language (Crystal 1997) mais aussi un «Tyrannosaurus rex » (Swales 1997) - Perte de genres spécialisés - Certains auteurs bénéficient d'un statut privilégié «Publish in English or perish» (Volanschi 2008) 1, Il est un fait bien connu que l'EN est devenu la langue internationale des sciences. Pour prendre un seul exemple, 95% des publications indexées par le Science Citation Indes sont en EN. Cette réalité n'est pas sans controverse. D'une part, l’anglais est considéré comme une lingua franca, qui a rendu possible le progrès scientifique, mais d'autre part, le monopole de la langue anglaise sur la communication scientifique publié est perçue comme un phénomène nuisible - une sorte de Tyrannosaurus Rex - car il peut conduire à la perte des registres spécialisés et des genres en "langues autrement en bonne santé", et aussi parce qu'il a conduit certains utilisateurs de bénéficier d'un statu privilégié. Dans le domaine de la biologie, ce qui nous avons travaillé sur, les deux motifs de préoccupation semble être justifiés : d'une part, il est pratiquement impossible de trouver des articles de recherche dans ce domaine écrits en français. D'autre part, les statistiques basées sur le corpus que nous utilisons montrent que les auteurs anglophones ont une meilleure chance d'être publié. Depuis le slogan «publier ou périr» peut être lu aujourd'hui «publier en anglais ou périr», nous avons décidé de commencer à travailler sur un outil d'aide à la rédaction.
 Science Citation Index: Anglais (95 %), Français, Allemand et Russe (4.9 %), Autres langues (0.7 %) Lingua franca (Gnutzmann 2000) ou global language (Crystal 1997) mais aussi un «Tyrannosaurus rex » (Swales 1997) - Perte de genres spécialisés. - Certains auteurs bénéficient d un statut privilégié. «Publish in English or perish» (Volanschi 2008) 1, Il est un fait bien connu que l EN est devenu la langue internationale des sciences. Pour prendre un seul exemple, 95% des publications indexées par le Science Citation Indes sont en EN. Cette réalité n est pas sans controverse. D une part, l’anglais est considéré comme une lingua franca, qui a rendu possible le progrès scientifique, mais d autre part, le monopole de la langue anglaise sur la communication scientifique publié est perçue comme un phénomène nuisible - une sorte de Tyrannosaurus Rex - car il peut conduire à la perte des registres spécialisés et des genres en langues autrement en bonne santé , et aussi parce qu il a conduit certains utilisateurs de bénéficier d un statu privilégié. Dans le domaine de la biologie, ce qui nous avons travaillé sur, les deux motifs de préoccupation semble être justifiés : d une part, il est pratiquement impossible de trouver des articles de recherche dans ce domaine écrits en français. D autre part, les statistiques basées sur le corpus que nous utilisons montrent que les auteurs anglophones ont une meilleure chance d être publié. Depuis le slogan «publier ou périr» peut être lu aujourd hui «publier en anglais ou périr», nous avons décidé de commencer à travailler sur un outil d aide à la rédaction.")
3
Questionnaire UFR Sciences de la Vie - Univ. Paris Diderot (Volanschi 2007) 56 réponses (sur environ 300 questionnaires envoyés) L'anglais est véritablement une langue de travail : 96 % des documents sont rédigés en anglais 95 % des chercheurs rédigent directement en anglais 53 % des chercheurs « pensent » en anglais 2, Afin de mieux évaluer et répondre aux besoins des utilisateurs, ma collègue Alexandra Volanschi envoyé un questionnaire aux membres du Département Sciences de la vie et à notre grande surprise nous avons reçu 56 réponses d'une population cible de 300 membres. Le questionnaire a montré que l'anglais est vraiment une langue de travail, puisque 96% de toutes les productions écrites sont en EN. En fait, les seuls textes écrits en français sont thèses de doctorat et de matériel de cours. 95% des participants d'écrire directement en anglais, mais à peine la moitié d'entre eux indique qu'ils pensent en anglais (ce qui signifie que l'autre moitié passer par l'acte mental de la traduction). 3
. 3.")
4
Questionnaire/2 Difficultés:
grammaire (62,5 %), expressions idiomatiques (69,64 %), influence de la langue française (64,28 %), termes spécialisés (14,28 %) Solutions: collocations en Langue Scientifique Générale (Pecman 2004) (87 %) et terminologiques (83 %), structures prédicatives (73%) et concordances (55 %) 3, Les difficultés rencontrées sont sur tout au niveau de la grammaire, des expressions idiomatiques, mais - comme nous nous y attendions – moins au niveau de la terminologie, parce que celle-ci est acquise par la lecture de la littérature du domaine. Et lorsqu'on leur a demandé quelles sortes d'outils d'aide à la rédaction pourraient les aider, nos utilisateurs potentiels ont répondu qu'ils seraient intéressés principalement par les collocations terminologiques et langue scientifique générale, ainsi que par les structures prédicatives, MAIS beaucoup moins par les concordances - ce qui semble suggérer que les utilisateurs n'ayant pas une formation linguistique sont moins susceptibles de généraliser au-delà un ensemble d'exemples.
, expressions idiomatiques (69,64 %), influence de la langue française (64,28 %), termes spécialisés (14,28 %) Solutions: collocations en Langue Scientifique Générale (Pecman 2004) (87 %) et terminologiques (83 %), structures prédicatives (73%) et concordances (55 %) 3, Les difficultés rencontrées sont sur tout au niveau de la grammaire, des expressions idiomatiques, mais - comme nous nous y attendions – moins au niveau de la terminologie, parce que celle-ci est acquise par la lecture de la littérature du domaine. Et lorsqu on leur a demandé quelles sortes d outils d aide à la rédaction pourraient les aider, nos utilisateurs potentiels ont répondu qu ils seraient intéressés principalement par les collocations terminologiques et langue scientifique générale, ainsi que par les structures prédicatives, MAIS beaucoup moins par les concordances - ce qui semble suggérer que les utilisateurs n ayant pas une formation linguistique sont moins susceptibles de généraliser au-delà un ensemble d exemples.")
5
Le projet ESIDIS-ARTES (Kübler & Pecman) Étude des Spécificités et Invariants des DIscours Scientifiques – Aide à la Rédaction de TExtes Scientifiques Outils et méthodes pour l'étude des collocations dans différents domaines scientifiques (Sciences de la Terre, Médecine, Chimie, Biologie, Informatique ...) Dictionnaire combinatoire sous forme de base de données bilingue de la phraséologie en anglais scientifique interdisciplinaire Corpus bilingue de référence pour différents genres scientifiques (article de recherche, communication orale, dissertation, ouvrage de vulgarisation ...) Saisie des données et interface d'interrogation en ligne Pour répondre à ces besoins, notre équipe de recherche dirigée par Natalie Kubler, a mis en place un projet de recherche que nous avons appelé Esidis-ARTES, un acronyme français pour Étude des Spécificités et Invariants des Discours Scientifiques - Aide à la Rédaction de Textes scientifique. Le but du projet est à la fois d’étudier les invariants et les variations concernant les phénomènes collocationnels dans divers domaines scientifiques (sciences de la Terre, médecine, chimie, biologie, informatique), mais aussi de construire un outil d’aide à la rédaction ou à la traduction en langue scientifique. Plus précisément, nous cherchons à construire une base de données bilingue combinatoire inter-disciplinaire basée sur l'étude d'un corpus de référence bilingue couvrant différents genres scientifiques (par exemple, l'article de recherche, communication orale, des thèses, la vulgarisation, et ainsi de suite).
 Dictionnaire combinatoire sous forme de base de données bilingue de la phraséologie en anglais scientifique interdisciplinaire. Corpus bilingue de référence pour différents genres scientifiques (article de recherche, communication orale, dissertation, ouvrage de vulgarisation ...) Saisie des données et interface d interrogation en ligne. Pour répondre à ces besoins, notre équipe de recherche dirigée par Natalie Kubler, a mis en place un projet de recherche que nous avons appelé Esidis-ARTES, un acronyme français pour Étude des Spécificités et Invariants des Discours Scientifiques - Aide à la Rédaction de Textes scientifique. Le but du projet est à la fois d’étudier les invariants et les variations concernant les phénomènes collocationnels dans divers domaines scientifiques (sciences de la Terre, médecine, chimie, biologie, informatique), mais aussi de construire un outil d’aide à la rédaction ou à la traduction en langue scientifique. Plus précisément, nous cherchons à construire une base de données bilingue combinatoire inter-disciplinaire basée sur l étude d un corpus de référence bilingue couvrant différents genres scientifiques (par exemple, l article de recherche, communication orale, des thèses, la vulgarisation, et ainsi de suite).")
6
Le projet ESIDIS-ARTES (Kübler & Pecman) Étude des Spécificités et Invariants des DIscours Scientifiques – Aide à la Rédaction de TExtes Scientifiques Publics visés : traducteurs, spécialistes de la recherche d'information, rédacteurs techniques, scientifiques, jeunes chercheurs, étudiants, linguistes, épistémologue, spécialistes de la recherche d’information Applications pratiques visées : applications pédagogiques, applications lexicographiques, aide à la rédaction ou à la traduction, recherche d'informations ciblées pour l'information scientifique et technique Les publics visés sont d’une part les utilisateurs, d’autre part les spécialistes. L’accès diffère selon les application, per exemple les applications pédagogiques ne sont pas publiques.

7
La phraséologie en anglais scientifique
Phraséologie dans la langue de spécialité (Volanschi 2009)* 8 années : travaux des étudiants de Master PRO ILTS (bases des données terminologiques dans différents domaines) termes et collocations - Problème d'exploitation des ressources sur longue période * Le projet vise à étudier la phraséologie spécifique à chaque discipline (ma collègue Alexandra Volanschi a par exemple travaillé sur la construction d'un dictionnaire combinatoire pour la biologie). Au cours des 8 dernières années, les étudiants de 2e année en traduction spécialisée ont travaillé sur une base de données Access terminologiques. Celle-ci contient au moment termes et collocations. Aussi 1ère année les étudiants de Master produire des fiches terminologiques dans le cadre du cours de linguistique de corpus appliquée à la traduction spécialisée. Naturellement, le regroupement de toutes ces ressources, et leur amélioration, est actuellement un sujet de préoccupation, et la construction d'une base de données qui puisse les regrouper est l'un des principaux objectifs du projet Esidis-ARTES.
* 8 années : travaux des étudiants de Master PRO ILTS (bases des données terminologiques dans différents domaines) termes et collocations. - Problème d exploitation des ressources sur longue période. * Le projet vise à étudier la phraséologie spécifique à chaque discipline (ma collègue Alexandra Volanschi a par exemple travaillé sur la construction d un dictionnaire combinatoire pour la biologie). Au cours des 8 dernières années, les étudiants de 2e année en traduction spécialisée ont travaillé sur une base de données Access terminologiques. Celle-ci contient au moment termes et collocations. Aussi 1ère année les étudiants de Master produire des fiches terminologiques dans le cadre du cours de linguistique de corpus appliquée à la traduction spécialisée. Naturellement, le regroupement de toutes ces ressources, et leur amélioration, est actuellement un sujet de préoccupation, et la construction d une base de données qui puisse les regrouper est l un des principaux objectifs du projet Esidis-ARTES.")
8
La phraséologie en anglais scientifique
Phraséologie dans la Langue Scientifique Générale (Pecman 2004) Collocations restrictives : working, reasonable, attractive hypothesis to support / test / suggest a hypothesis Formules regroupées selon leur fonction rhetorique ex. “anonymous reference”: il est courant de penser que... il est communément / généralement / unanimement admis / reconnu que... on admet que, on a longtemps pensé / cru que, on a souvent dit que..., etc. it is commonly / generally / universally / widely accepted that... it is widely / well known that... it [is / has been] (often) asserted / noted / recognised / believed / claimed / argued that... Néanmoins, en outre que l'étude de la phraséologie spécifique à chaque discipline, le projet ARTES se concentre également sur ce qui est commun à toutes les disciplines, c’est-à-dire la phraséologie de la «langue scientifique générale». Et nous sommes intéressés dans les deux collocations propres à l'anglais scientifique (dans le sens restrictif) et dans les formules typiquement utilisés dans le discours scientifique. Ces formules seront regroupés selon leur fonction rhétorique / communication. Ainsi, par exemple, des formules telles que l'IL EST courant de ... doit être couplé avec ... il est communément sous la rubrique «faire une référence anonyme».
 Collocations restrictives : working, reasonable, attractive hypothesis. to support / test / suggest a hypothesis. Formules regroupées selon leur fonction rhetorique. ex. anonymous reference : il est courant de penser que... il est communément / généralement / unanimement admis / reconnu que... on admet que, on a longtemps pensé / cru que, on a souvent dit que..., etc. it is commonly / generally / universally / widely accepted that... it is widely / well known that... it [is / has been] (often) asserted / noted / recognised / believed / claimed / argued that... Néanmoins, en outre que l étude de la phraséologie spécifique à chaque discipline, le projet ARTES se concentre également sur ce qui est commun à toutes les disciplines, c’est-à-dire la phraséologie de la «langue scientifique générale». Et nous sommes intéressés dans les deux collocations propres à l anglais scientifique (dans le sens restrictif) et dans les formules typiquement utilisés dans le discours scientifique. Ces formules seront regroupés selon leur fonction rhétorique / communication. Ainsi, par exemple, des formules telles que l IL EST courant de ... doit être couplé avec ... il est communément sous la rubrique «faire une référence anonyme».")
9
Le projet ESIDIS-ARTES http://www. eila. univ-paris-diderot

14
Premières étapes : PLoS *
20 millions de mots Open Access et XML IMRaD standard => 4 sous-corpus 6 revues : Genetics Pathogens Biology Computational Biology Medicine Neglected Tropical Diseases (3 nouvelles revues : Plos One, Plos Current, Plos Clinical Trials) En fait, tout en travaillant sur ce projet gigantesque, et afin de répondre à un certain nombre de questions méthodologiques, nous avons mené une expérience sur le corpus de 20M des mots d'articles de recherche en biologie. Nous avons choisi de travailler sur les textes du journal PLoS parce qu'ils sont dans le même temps par les pairs, libre de droits et encodés au format XML qui les rend faciles à exploiter. Ils ont en outre l'avantage d'être structuré selon la norme IMRAD, qui permet de facilement diviser le corpus en 4 sous-corpus et de se concentrer sur les différentes sections des articles de recherche: Introduction, Méthodes, Résultats, Discussion. Nous aurions voulu choisir seulement les articles écrits par locuteurs natifs des revues PLOS 6. Comme cette information est difficile à vérifier, nous avons fait une approximation: nous n'avons utilisé que les articles ayant au moins un auteur affilié à une institution siegée dans un Pays anglophone. * Public Library of Science:
 En fait, tout en travaillant sur ce projet gigantesque, et afin de répondre à un certain nombre de questions méthodologiques, nous avons mené une expérience sur le corpus de 20M des mots d articles de recherche en biologie. Nous avons choisi de travailler sur les textes du journal PLoS parce qu ils sont dans le même temps par les pairs, libre de droits et encodés au format XML qui les rend faciles à exploiter. Ils ont en outre l avantage d être structuré selon la norme IMRAD, qui permet de facilement diviser le corpus en 4 sous-corpus et de se concentrer sur les différentes sections des articles de recherche: Introduction, Méthodes, Résultats, Discussion. Nous aurions voulu choisir seulement les articles écrits par locuteurs natifs des revues PLOS 6. Comme cette information est difficile à vérifier, nous avons fait une approximation: nous n avons utilisé que les articles ayant au moins un auteur affilié à une institution siegée dans un Pays anglophone. * Public Library of Science:")
15
Le corpus PLoS Le pourcentage d'articles ayant au moins un auteur basé dans un pays de langue FR dans les revues PLOS (qui ont un niveau relativement élevé Facteur d'impact) est très élevé, dans certains cas de près de 100%.
 est très élevé, dans certains cas de près de 100%.")
16
Statistiques d'affiliation dans PLoS
Et si tous les auteurs publiés dans les revues PLOS sont considérés ensemble, le pourcentage des auteurs basés aux États-Unis, au Royaume-Uni et en Australie sommes jusqu'à 66% (deux tiers de tous les auteurs publiés dans PLoS). 16
. 16.")
17
L'article de recherche dans l’approche théorique de l’analyse des genres
On sait bien que l'article de recherche est la forme la plus prestigieuse de communication scientifique écrite et qu'il doit répondre à certaines normes pour être publié. Les codes et les conventions liées à l'article de recherche et leur impact sur le choix de la phraséologie ont été délinéé par la théorie des genres. Nous avons donc décidé d'adopter cette théorie et d'explorer sa capacité d'adaptation de l'outil aide à la rédaction que nous cherchons à construire.

18
L'introduction de l'article de recherche : le modèle CARS (Swales 1990)
Move 1: Establishing a research territory step 1: Claiming centrality, and/or step 2: Placing your research within the filed, and/or step 3: Reviewing items of previous research Move 2: Establishing a niche step 1a: Counter-claiming, or step 1b: Indicating a gap in current research, or step 1c: Question raising, or step 1d: Continuing a tradition Move 3: Occupying the niche step 1a: Outlining purposes, or step 1b: Announcing present research step 2: Announcing principle findings step 3: Indicating research article structure Permettez-moi de vous rappeler de la Création d'un modèle d'espace de recherche pour l'introduction d'articles scientifiques conçus par John Swales. En 1990, Swales a analysé un corpus d'articles de recherche dans différentes disciplines, et il a identifié une tendance commune dans la description de l'information: les auteurs suivent en fait un chemin standard, qui Swales organisée en moves et steps. Selon cette théorie, l’introduction de l’article recherche doit nécessairement contenir 3 moves. Ces objectifs sont atteints par un certain nombre des steps. DEFINTION:Un MOVE est «un segment de texte qui est en forme et encadrée par un fonction spécifique de communication», selon Holmes, et STEP est-pour ainsi dire-le moyen pour atteindre l'objectif qui sous-tendent la communication.

19
L'introduction de l'article de recherche : le modèle CARS (Swales 1990)
Move 1: Establishing a research territory step 1: Claiming centrality, and/or step 2: Placing your research within the filed, and/or step 3: Reviewing items of previous research Move 2: Establishing a niche step 1a: Counter-claiming, or step 1b: Indicating a gap in current research, or step 1c: Question raising, or step 1d: Continuing a tradition Move 3: Occupying the niche step 1a: Outlining purposes, or step 1b: Announcing present research step 2: Announcing principle findings step 3: Indicating research article structure - However, the previously mentioned methods suffer from some limitations... - The first group...cannot treat... and is limited to... - The second group... is time consuming, and therefore expensive, is not sufficiently accurate... Et chaque step est réalisée par un certain nombre de marqueurs linguistiques. Par exemple, le step Indicating a gap, peut être réalisé par un connecteur adversatif (however), des verbe à particule et des adjectifs et adverbes négatifs. Là encore, le GAP peut être signalée lexicalement par le verbe (suffer) ou dans des phrases adjectivales (time consuming) ayant une prosodie sémantique négative.
, des verbe à particule et des adjectifs et adverbes négatifs. Là encore, le GAP peut être signalée lexicalement par le verbe (suffer) ou dans des phrases adjectivales (time consuming) ayant une prosodie sémantique négative.")
20
Travaux sur les articles suivant le modèle IMRAD
Introduction: Swales (1981, 1990), Dudley-Evans (1986), Swales & Najjar (1987), Hughes (1989), Gledhill (1995, 2000), Bathia (1997), Samraj (2002) Abstract: Gledhill (2000), Hyland (2000), Swales & Feak (2009), Bordet (2009) Methods: Weissberg & Buker (1990), Nwogu (1997) Results: Brett (1994), Thompson (1993), Williams (1999), Yang & Allison (2003) Discussion: Belanger (1982), McKinlay (1983), Dudley-Evans (1986, 1994), Hopkins & Dudley-Evans (1988), Holmes (1997, 2001), Peacock (2002) , Ce travail novateur a généré un vaste corpus de littérature qui fournit des indications précieuses sur la structure rhétorique des différentes sections des articles de recherche dans différentes disciplines. Voici quelques-uns d'entre eux, bien que beaucoup d'autres mériteraient d'être mentionnés. Dans le cadre de ma thèse, je vais faire référence à différentes théories proposées par ces auteurs et je vais essayer et de tester leurs modèles sur mon corpus, afin de trouver la meilleure et peut-être l'adapter, ou de combiner un ou plusieurs d'entre eux, ou même de créer un nouveau modèle.
, Dudley-Evans (1986), Swales & Najjar (1987), Hughes (1989), Gledhill (1995, 2000), Bathia (1997), Samraj (2002) Abstract: Gledhill (2000), Hyland (2000), Swales & Feak (2009), Bordet (2009) Methods: Weissberg & Buker (1990), Nwogu (1997) Results: Brett (1994), Thompson (1993), Williams (1999), Yang & Allison (2003) Discussion: Belanger (1982), McKinlay (1983), Dudley-Evans (1986, 1994), Hopkins & Dudley-Evans (1988), Holmes (1997, 2001), Peacock (2002) , Ce travail novateur a généré un vaste corpus de littérature qui fournit des indications précieuses sur la structure rhétorique des différentes sections des articles de recherche dans différentes disciplines. Voici quelques-uns d entre eux, bien que beaucoup d autres mériteraient d être mentionnés. Dans le cadre de ma thèse, je vais faire référence à différentes théories proposées par ces auteurs et je vais essayer et de tester leurs modèles sur mon corpus, afin de trouver la meilleure et peut-être l adapter, ou de combiner un ou plusieurs d entre eux, ou même de créer un nouveau modèle.")
21
Projets similaires AMADEUS (Amiable Article Development for User Support : Aluisio 1994) : seléction de phrases et collocations « standard » fréquents dans les textes scientifiques SCIENTEXT (Univ. Grenoble 3, Lorient, Chambéry) : corpus textes scientifiques principalement en français TYOS (Type Your Own Scripts – Univ. Bordeaux) : outil pédagogique ; corpus restreint (30 textes) ; annotation des « moves », formes verbales, connecteurs du discours, etc. Trois projets connexes doivent être brièvement mentionnées ici: AMADEUS est un outil qui offre un ensemble de phrases standard et collocations qui apparaissent avec une fréquence élevée dans les textes scientifiques. Malheureusement, nous n'avons pas pu le tester, car il n'est pas téléchargeable, mais nous savons qu’il s’adresse aux étudiants brésiliens de l'informatique et la physique. Le deuxième est Scientext , qui met à la disposition des chercheurs et étudiants un large corpus d’écrits scientifiques de manière à permettre l’étude de leurs caractéristiques linguistiques. L’étude linguistique du positionnement et du raisonnement à travers la phraséologie, les marques énonciatives et les marques syntaxiques liées à la causalité a été l’objet principal du projet. Quant aux caractéristiques techniques, Le corpus a été annoté au niveau de l’en-tête (méta-données sur l’annotation et l’origine du corpus), au niveau de la structure (parties de l’article) et au plan morphologique et syntaxique. Et enfin est TYOS, un outil pédagogique très utile: elle consiste en une petite sélection de documents (30 articles de recherche dans de multiples domaines, des lettres à l'éditeur, les résumés, et ainsi de suite). L'introduction et la discussion de chacun des RA ont été annotés pour les moves et des marqueurs linguistiques.
 : seléction de phrases et collocations « standard » fréquents dans les textes scientifiques. SCIENTEXT (Univ. Grenoble 3, Lorient, Chambéry) : corpus textes scientifiques principalement en français. article1. TYOS (Type Your Own Scripts – Univ. Bordeaux) : outil pédagogique ; corpus restreint (30 textes) ; annotation des « moves », formes verbales, connecteurs du discours, etc. Trois projets connexes doivent être brièvement mentionnées ici: AMADEUS est un outil qui offre un ensemble de phrases standard et collocations qui apparaissent avec une fréquence élevée dans les textes scientifiques. Malheureusement, nous n avons pas pu le tester, car il n est pas téléchargeable, mais nous savons qu’il s’adresse aux étudiants brésiliens de l informatique et la physique. Le deuxième est Scientext , qui met à la disposition des chercheurs et étudiants un large corpus d’écrits scientifiques de manière à permettre l’étude de leurs caractéristiques linguistiques. L’étude linguistique du positionnement et du raisonnement à travers la phraséologie, les marques énonciatives et les marques syntaxiques liées à la causalité a été l’objet principal du projet. Quant aux caractéristiques techniques, Le corpus a été annoté au niveau de l’en-tête (méta-données sur l’annotation et l’origine du corpus), au niveau de la structure (parties de l’article) et au plan morphologique et syntaxique. Et enfin est TYOS, un outil pédagogique très utile: elle consiste en une petite sélection de documents (30 articles de recherche dans de multiples domaines, des lettres à l éditeur, les résumés, et ainsi de suite). L introduction et la discussion de chacun des RA ont été annotés pour les moves et des marqueurs linguistiques.")
22
Extraction des formules
Manuellement : annotation des moves, des steps et des marqueurs linguistiques sur un échantillon (Flowerdew ; Kanoksilapatham 2004, 2007) Pour revenir à notre projet, nous avons commencé l'extraction de formules à partir du corpus PLoS. Nous avons commencé à extraire manuellement des formules tout en annotant les moves, les steps, et à réfléchir sur les marqueurs linguistiques d’un petit échantillon de 30 articles. Ce choix s’inspire au travaux remarquables de Flowerdew et Kanoksilapatham. Cette dernière, en particulier, adopte une perspective rhétorique top-down au départ. Dans son étude des articles de recherche en biochimie Kanoksilapatham développe d'abord un cadre d'analyse basé sur le discours à travers l'identification des moves, puis utilise l'analyse multi-dimensionnelle de Biber pour déterminer les caractéristiques linguistiques de chaque move.
 Pour revenir à notre projet, nous avons commencé l extraction de formules à partir du corpus PLoS. Nous avons commencé à extraire manuellement des formules tout en annotant les moves, les steps, et à réfléchir sur les marqueurs linguistiques d’un petit échantillon de 30 articles. Ce choix s’inspire au travaux remarquables de Flowerdew et Kanoksilapatham. Cette dernière, en particulier, adopte une perspective rhétorique top-down au départ. Dans son étude des articles de recherche en biochimie Kanoksilapatham développe d abord un cadre d analyse basé sur le discours à travers l identification des moves, puis utilise l analyse multi-dimensionnelle de Biber pour déterminer les caractéristiques linguistiques de chaque move.")
24
Extraction des formules
Manuellement : annotation des moves, des steps et des marqueurs linguistiques sur un échantillon Semi-automatique: commandes Linux 138 <s> It is important to note that 83 <s> It is interesting to note that 29 <s> It will be interesting to determine 17 <s> It is worth noting that the 16 <s> It will be of interest to 16 <s> It will be interesting to see 16 <s> It is also important to note 55 <s> It should be noted that the 11 <s> It should be noted that our 9 <s> It should be noted that this 21 <s> It should also be noted that 15 <s> It is also worth noting that 13 <s> It is important to point out 9 <s> It is also interesting to note , Au même temps, nous avons utilisé des simples commandes Linux (>>> wget ) sur l'ensemble du corpus afin d'en extraire des formules récurrentes. La liste des exemples donnés ici ont été obtenues par l’extraction des 6 mots qui se trouvent les plus fréquemment en début des phrases.
 sur l ensemble du corpus afin d en extraire des formules récurrentes. La liste des exemples donnés ici ont été obtenues par l’extraction des 6 mots qui se trouvent les plus fréquemment en début des phrases.")
25
Extraction des formules
Manuellement : annotation des moves, des steps et des marqueurs linguistiques sur un échantillon Semi-automatique: commandes Linux 138 <s> It is important to note that 83 <s> It is interesting to note that 29 <s> It will be interesting to determine 17 <s> It is worth noting that the 16 <s> It will be of interest to 16 <s> It will be interesting to see 16 <s> It is also important to note 55 <s> It should be noted that the 11 <s> It should be noted that our 9 <s> It should be noted that this 21 <s> It should also be noted that 15 <s> It is also worth noting that 13 <s> It is important to point out 9 <s> It is also interesting to note It is important / interesting / of interest to note / determine / see / point out that … It should be noted that … It is worth noting / mentioning that A partir de cette liste, nous essayons de trouver de schémas collocationnels, plus faciles à étudier que toute la liste d'exemples. Dans en deuxième temps nous analyserons l'ensemble du corpus à l'aide du logiciel qui se revelera le plus convenable. Nous allons en tester plusieurs en commençant par ConcGram.

26
Accès aux données Par mot Par fonction rhétorique Par moves
Par section (pour l'article de recherche) Quelle est la meilleure façon d'accéder aux données pour un utilisateur n'ayant pas ou ayant peu de formation linguistique ? La question que nous nous posons actuellement est de trouver le moyen le plus efficace pour accéder aux données, que ce soit par mot, fonction rhétorique, moves, section, ou bien une combinaison des 4. Et plus précisément, nous nous demandons quelle est la meilleure façon de structurer l'accès aux données pour un public sans formation linguistique. Maintenant, je vais illustrer les scénarios que nous envisageons ...
 Quelle est la meilleure façon d accéder aux données pour un utilisateur n ayant pas ou ayant peu de formation linguistique La question que nous nous posons actuellement est de trouver le moyen le plus efficace pour accéder aux données, que ce soit par mot, fonction rhétorique, moves, section, ou bien une combinaison des 4. Et plus précisément, nous nous demandons quelle est la meilleure façon de structurer l accès aux données pour un public sans formation linguistique. Maintenant, je vais illustrer les scénarios que nous envisageons ...")
27
Cas de figure 1: accès combiné
Introduction Mat. & Methods Results Discussion Pour le premier scénario, nous supposons que l'accès aux données sera guidé par la section de l’article de recherche

28
Cas de figure 1: accès combiné
Introduction Mat. & Methods Results Discussion Notre utilisateur hypothétique devrait choisir une section parmi celles proposées par l'outil d'aide à rédaction ..

29
Cas de figure 1: accès combiné
Introduction Mat. & Methods Results Discussion Research outcome Contextualizing the study Consolidating results Ensuite, la liste des moves possibles seront proposées pour un autre choix Limitations of the study Further research ...

30
Cas de figure 1: accès combiné
Introduction Mat. & Methods Results Discussion Limitations about the findings Limitations about the methodology Limitations about the claims made Research outcome Contextualizing the study Consolidating results Le choix du move, dans ce cas «limitations of the study », sera suivie d'un choix de steps, par exemple des « limitations about the findings » ou « limitations about the methodology » ou encore sur « limitations about the claims made». Le choix d'un step conduira finalement... Limitations of the study Further research ...

31
Cas de figure 1: accès combiné
Many questions still remain as to how... Introduction Mat. & Methods As yet, we have not detected... Results Discussion Limitations about the findings ...we are unable to provide any new insight into... Limitations about the methodology Limitations about the claims made Research outcome Contextualizing the study Consolidating results à un ensemble de formules, comme ceux illustrés ici : many questions still remain as to how... or As yet, we have not detected... or we are unable to provide any new insight into... Limitations of the study Further research ...

32
Cas de figure 1: accès combiné
Many questions still remain as to how... Introduction Mat. & Methods As yet, we have not detected... Results Discussion Limitations about the findings ...we are unable to provide any new insight into... Limitations about the methodology Limitations about the claims made Research outcome Contextualizing the study Consolidating results , En cliquant sur les formules, les utilisateurs auront accès à des exemples tirés du corpus Limitations of the study Further research Corpus-driven examples ...

33
Cas de figure 2 : Accès par fonction rhétorique / communicative
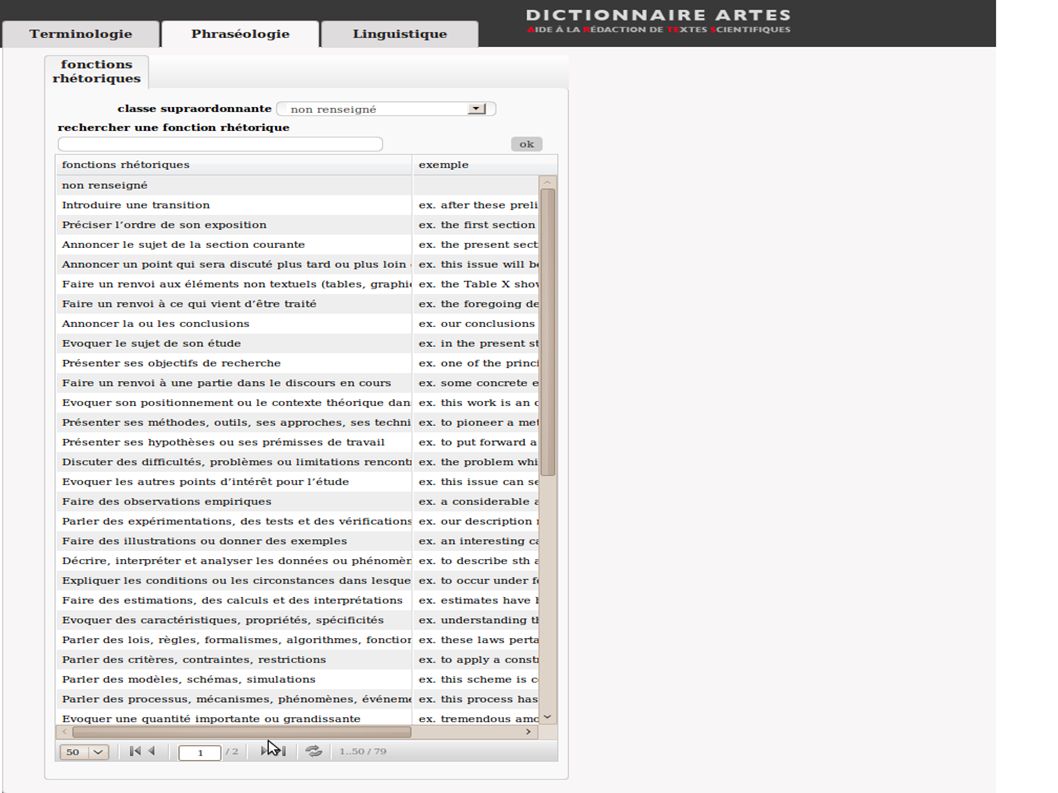
Liste : ~30 fonctions => Hiérarchie des fonctions pour un accès plus simple Le deuxième scénario, qui a été appliqué au projet Esidis-ARTES, est l'accès par fonction rhétorique. Notre liste compte à présent 30 fonctions rhétoriques, mais peut grandir. Et bien, la question à laquelle nous devons répondre maintenant est «est-il possible de construire une hiérarchie de fonctions pour faciliter l’accès aux données? Et comment »?

34
Cas de figure 2 : Accès par fonction rhétorique / communicative
Liste : ~30 fonctions => Hiérarchie des fonctions pour un accès plus simple Referring to a table/figure expression de la découverte Stating results Contextualizing the study Stating limitations of the study Dans ce cas, nous imaginons que l'utilisateur devra simplement choisir parmi une longue liste la fonction rhétorique qui est la plus proche de son objectif communicatif Detailing procedures Confirming a hypothesis Proposing a hypothesis ...

35
Cas de figure 2 : Accès par fonction rhétorique / communicative
Liste : ~30 fonctions => Hiérarchie des fonctions pour un accès plus simple These / Our data / findings are consistent with support Referring to a table/figure expression de la découverte Stating results the hypothesis that Contextualizing the study Stating limitations of the study et ensuite il aura une liste de formules. Detailing procedures Confirming a hypothesis This hypothesis / interpretation is supported by the is consistent with the Proposing a hypothesis ...

36
Cas de figure 3: accès par mot
data Enfin, dans le cas de l'accès par mot(-forme), le choix serait entre donner directement accès à toutes les formules dans lesquelles le mot apparaît,
, le choix serait entre donner directement accès à toutes les formules dans lesquelles le mot apparaît,")
37
Cas de figure 3: accès par mot
A growing body of data shows that... data These data are consistent with... The data presented here suggest that... Our data do not adress the possibility that... We have insufficient data for... The limited data available suggest...

38
Cas de figure 3: accès par mot
data Confirming a hypothesis Stating limitations Indicating source of data ou de filtrer les résultats par fonction rhétorique, Indicating criteria for data selection

39
Cas de figure 3: accès par mot
data Our data do not enable us to... Confirming a hypothesis Our data do not address the possibility that... Stating limitations Indicating source of data , comme illustré ici par une recherche du mot «data». Indicating criteria for data selection We have insufficient data for... The limited data available suggest...

40
Perspectives de recherche
Déterminer quelle est la méthode la plus adaptée Évaluation sur une sélection d'article de différentes disciplines Soumission des différents « cas de figure » à des utilisateurs potentiels Conception de tutoriels pour un public vaste et pour les cours d'anglais de spécialité Création de ressources pour les enseignants d’anglais de spécialité Multilingue Pour conclure, je voudrais illustrer brièvement ce que sont les étapes à venir. Mon projet de thèse devrait fonctionner comme un test pour le projet plus vaste Artes: comme je l'ai dit, il est à son tout début et il faudra le remanier au fil du temps. Je vais donc tester les différents modèles mentionnés il y a quelques minutes sur le corpus, et essayer de produire du matériel pédagogique ainsi que des ressources pour les enseignants et des tutoriels bien sûr, parce que notre publique ne sait pas nécessairement ce que sont les moves, les steps... En outre, j'envisage de travailler sur le contenu terminologique, de manière qu’en cliquant sur un mot l’on puisse accéder, par exemple aux hyponymes, hyperonymes, etc. Donc, dans le cas de «data» l'utilisateur aurait accès à des mots comme taille, poids, chiffres, tableau, pourcentage, etc...)
")
41
Merci de votre attention
Francesca Palma CLILLAC-ARP Université Paris 7 – Paris Diderot

42
Bibliographie / 1

43
Bibliographie / 2

44
Quelques modèles Kanoksilapatham (2004): 15 moves (3 for Introduction, 4 for Methods, 4 for Results and 4 for Discussion section) Nwogu (1997): 11 moves (3 for Introduction, 3 for Methods, 2 for Results and 3 for Discussion section) Peacock (2002): RA discussion sections three-part framework involving a series of move cycles: Introduction, Evaluation, Conclusion combining 2 or more of 8 moves: information, finding, expected or unexpected outcome, reference to previous research, explanation,claim, limitation, reccomandation.
: 11 moves (3 for Introduction, 3 for Methods, 2 for Results and 3 for Discussion section) Peacock (2002): RA discussion sections. three-part framework involving a series of move cycles: Introduction, Evaluation, Conclusion. combining 2 or more of 8 moves: information, finding, expected or unexpected outcome, reference to previous research, explanation,claim, limitation, reccomandation.")
45
Questionnaire Est-ce qu'une liste de combinaisons de termes spécifiques au langage scientifique en général vous serait utile ? Prenons pour illustration le terme method : VERBES : develop a method, describe a method, apply a method, employ a method, use a method, test a method, try (out) a method, complement a method, improve a method, perfect a method, follow a method, establish a method, etc. ADJECTIFS : standard method, genetic method, experimental method, complementary method, obsolete method, out-of-date method, modern method, state-of-the-art method, novel method, cumbersome method, time-consuming method, etc. Oui : 49 (87,5 %), Non : 4 (7,14 %)
 a method, complement a method, improve a method, perfect a method, follow a method, establish a method, etc. ADJECTIFS : standard method, genetic method, experimental method, complementary method, obsolete method, out-of-date method, modern method, state-of-the-art method, novel method, cumbersome method, time-consuming method, etc. Oui : 49 (87,5 %), Non : 4 (7,14 %)")
46
Exemple de fiche terminologique
terme : atrial fibrillation catégorie : nom définition : irregular heart rhythm in which many impulses begin and spread through the atria. auteur de la fiche : SA, étudiant(e) MASTER PRO ILTS sujet : Le syndrôme de Marfan, mémoire terminologie terme(s) équivalent(s) : Français : fibrillation auriculaire terme(s) concurrent(s) : AF, concurrent : synonyme parfait arrhythmia, concurrent : quasi-synonyme auricular fibrillation, concurrent : quasi-synonyme A-fib, concurrent : quasi-synonyme relation(s) indirecte(s) : arrhythmia, indirect : cause/conséquence note : arrythmia is caused by a disruption of the normal functioning of the electrical conduction system of the heart, like AF. Collocation(s) : chronic AF, en : atrial premature beats, en : symptomatic or asymptomatic AF, en : converting AF to sinus rythm, en : paroxysmal AF, en
 MASTER PRO ILTS. sujet : Le syndrôme de Marfan, mémoire terminologie. terme(s) équivalent(s) : Français : fibrillation auriculaire. terme(s) concurrent(s) : AF, concurrent : synonyme parfait. arrhythmia, concurrent : quasi-synonyme. auricular fibrillation, concurrent : quasi-synonyme. A-fib, concurrent : quasi-synonyme. relation(s) indirecte(s) : arrhythmia, indirect : cause/conséquence. note : arrythmia is caused by a disruption of the normal functioning of the electrical conduction system of the heart, like AF. Collocation(s) : chronic AF, en : atrial premature beats, en : symptomatic or asymptomatic AF, en : converting AF to sinus rythm, en : paroxysmal AF, en.")
Présentations similaires



 Jean-Philippe KOTOWICZ (INSA Rouen)>")













 that don’t follow the normal rules. Because of this, we have to learn them by heart. Thankfully,>")




