Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Formation aux technologies du Web sémantique CCSD, Lyon, 8-10 septembre 2010

2
Présentation de la formation
Objectif : découvrir les technologies du Web sémantique tant du point de vue théorique que pratique Jour 2 Aspect pratique et Ontologie Jour 3 PHP et Web sémantique Jour 1 Aspect théorique et Web de données

3
Du Web de documents au Web de données
Plan de la journée Du Web de documents au Web de données Les technologies du Web sémantique Comparaisons avec XML et BDR Présentation du Linked Data

4
Il était une fois le modèle en couches….
Protocoles Application Telnet, FTP, SMTP, HTTP Transport TCP, UDP, TP4, Routage Internet IP Interfaces Sous-réseau Ethernet, X25, FDDI Token Ring Liaison HDLC, PPP, SLIP, CSLIP Physique 10Base2/5/T, RS232, V35, fibre

5
…et une des applications d’Internet : le Web
Source :

6
Les quatre composantes du Web
Qu’est-ce-que le Web ? Un dispositif technologique pour mettre à disposition, lier et partager des documents sur un réseau de machines connectées. Les quatre composantes du Web Un mécanisme d’identification Un protocole Un principe Un langage HTTP URL/URI L’hypertexte HTML

7
Les quatre caractéristiques du protocole HTTP
Qu’est-ce-que le Web ? Un dispositif technologique pour mettre à disposition, lier et partager des documents sur un réseau de machines connectées. Les quatre caractéristiques du protocole HTTP Client-serveur Dissociation IHM Stockage données Sans état Requête unitaire Pas de mémoire Mise en mémoire Optimisation sollicitation serveur Code à la demande Ajax

8
Les trois bases de l’architecture du Web
Qu’est-ce-que le Web ? Un dispositif technologique pour mettre à disposition, lier et partager des documents sur un réseau de machines connectées. Les trois bases de l’architecture du Web Ressource URI URI Identifiant Représentations

9
1994 : 1ère conférence WWW et premières idées
« The Need for Semantics in the Web », Tim Berners-Lee Passer d’un Web de documents « sans relief » peu compréhensible par les machines à…. un Web de choses relié à la réalité et compréhensible par les machines Source :

10
1997-2001 : Les premières briques du Web sémantique
Tim Berners-Lee « The Semantic Web is a web of data, in some ways like a global database » « The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation. » Source : Acte de naissance auprès du grand public Le layer cake ou Web semantic stack 1er brouillon de la recommandation le 2 octobre 1997 Tim Berners-Lee, James Hendler, Ora Lassila « Semantic Web », Scientific American, mai 2001 Source :

11
Aujourd’hui : « appelez le plutôt Web de données »
Tim Berners-Lee, « On the next Web », Conférence TED, Février 2009 « Raw Data now ! » Source : Source : D’un Web de documents Documents reliés par des liens Pas de structuration sémantique Pas de requêtes structurées à un Web d’applications Données exposées à travers API API valable que pour un Silo Pas d’ineropérabilité entre les silos à un Web de données Web de données = espace unifié Liens entre les données APIs remplacés par standards ouverts Le Web de données est un espace unifié, global, commun On peut faire des liens d'une donnée à une autre Les données ne sont plus isolées dans des silos Les APIs propriétaires sont remplacées par des standards ouverts (RDF, SPARQL, HTTP...)
")
12
Sortir de la logique de silos de données…
Les technologies ont eu tendance jusqu’à maintenant à enfermer les données dans des silos : logiciels, processus, APIs, protocoles spécifiques… Siège social d’Oracle, l’éditeur du SGBDR le plus utilisé dans le monde, dans la Silicon Valley « But the second big trend then is to decouple the data from the application or the application services, so that in that sense what you can do is write your application or create services independent of the data sources they have to deal with, which comes full circle back to having a virtual layer between application services and data. The application can go out and find whatever data sources are best to use for that particular question. That’s what semantic technology provides for enterprise information management. » Robert Shimp, vice Président, Oracle

13
…pour libérer les données sur le Web…
Il ne s’agit pas de « Webifier » les bases de données existantes pour les rendre accessible aux utilisateurs Déployer des protocoles spécifiques qui limitent l’utilisation des données voire ne respectent pas les principes du Web Il s’agit de Placer les données sur le Web, juste le Web Rendre le Web invisible visible

14
…et envisager une nouvelle évolution dans l’architecture des SI
B A Silos de services B A Silos applicatifs indépendants et non connectés Indépendance des trois niveaux (applicatif, service, données)
")
15
Les technologies du Web sémantique
Plan de la journée Du Web de documents au Web de données Les technologies du Web sémantique Comparaisons avec XML et BDR Présentation du Linked Data

16
Présentation des technologies du Web sémantique
Métadonnées Web sémantique RDFS Taxinomie Ontologie Intelligence artificielle Bases de données Web Triples SPARQL URI RDFa SKOS Thésaurus Dublin Core RDF/XML Graphes NTriples RDF Le Web sémantique, conçu comme une extension du Web actuel, est une notion promue par le W3C, l’organisme de normalisation du Web, à la croisée de plusieurs disciplines et pratiques : L’intelligence artificielle ; La logique de description ; La théorie des graphes ; Le traitement automatique des langues et la recherche d’information ; Les bases de données. Sans être assimilable à une de ses disciplines, il leur empreinte certains concepts, visions ou technologies pour atteindre son but : exposer, lier, partager sur le Web des données structurées. A l’image du Web actuel basé sur l’idée de la mise à disposition et la relation entre les documents, le Web sémantique vise à constituer un web de données liées. Pour parvenir à ce but, il s’appuie, à la fois, sur la notion de métadonnées et les systèmes d’organisation de l’information : Vocabulaires contrôlés ; Taxinomie ; Thésaurus ; Ontologie. et sur un ensemble de briques technologiques, dont la première est un modèle de données simple, générique et universel : le RDF (Resource Description Framework), que l’on peut écrire de différentes façons (RDFa, RDF/XML, NTriples…). A partir de ce modèle de base, le W3C et d’autres organismes ont mis au point différentes briques dont nous préciserons au fur et à mesure la place dans cette formation : RDFS (Resource Description Framework Schema) ; OWL (Ontology Web language) ; SKOS (Simple Knowledge Organization System) ; SPARQL ; Dublin Core. OWL TAL Logique de description Vocabulaires contrôlés
, que l’on peut écrire de différentes façons (RDFa, RDF/XML, NTriples…). A partir de ce modèle de base, le W3C et d’autres organismes ont mis au point différentes briques dont nous préciserons au fur et à mesure la place dans cette formation : RDFS (Resource Description Framework Schema) ; OWL (Ontology Web language) ; SKOS (Simple Knowledge Organization System) ; SPARQL ; Dublin Core. OWL. TAL. Logique de description. Vocabulaires contrôlés.")
17
La grammaire du Web sémantique
esource d’une ressource D escription de Description F ramework RDF (Ressource description Framework) est un modèle d’organisation de l’information, recommandation du W3C ( Il est un modèle générique, souple et simple à la base du Web sémantique et constitue l’équivalent d’une grammaire pour un langage orienté « machine ». Cadre/modèle
 est un modèle d’organisation de l’information, recommandation du W3C ( Il est un modèle générique, souple et simple à la base du Web sémantique et constitue l’équivalent d’une grammaire pour un langage orienté « machine ». Cadre/modèle.")
18
La grammaire du Web sémantique
Les trois composants de R D sont : les URI pour identifier ; les triplets pour exprimer ; les graphes pour relier F Le RDF s’appuie sur trois composant de base : Le mécanisme des URIs (Uniform resource identifier, standard IETF RFC 3986 : qui permet d’identifier des ressources au sein d’un réseau (logique ou physique). Il est issu des travaux de l’IETF et du W3C pour identifier et de localiser des ressources sur le Web (URL) Le principe des triplets issu des travaux de la logique des prédicats de premier ordre ( permet d’exprimer des relations entre deux ressources identifiées par des URI. Le principe des graphes issu de la théorie des graphes ( permet de relier les différentes ressources.
. Il est issu des travaux de l’IETF et du W3C pour identifier et de localiser des ressources sur le Web (URL) Le principe des triplets issu des travaux de la logique des prédicats de premier ordre ( permet d’exprimer des relations entre deux ressources identifiées par des URI. Le principe des graphes issu de la théorie des graphes ( permet de relier les différentes ressources.")
19
RDF : les URIs (le principe)
1- Prenez des choses/concepts/entités du monde réel et placez les dans le monde numérique, en les nommant et en les identifiant par des URIs. Terme/signifiant Représentation « Pipe » Objet Concept Smoking_pipe_%28tobacco%29 concept/en/Pipe_SmokingDevice Ressource guid.9202a8c f a8cf37 Identifiant/URI Représentations

20
RDF : les URIs (les règles)
1- Prenez des choses/concepts/entités du monde réel et placez les dans le monde numérique, en les nommant et en les identifiant par des URIs. Uniform Resource Identifier Système d’identifiant mis au point conjointement par l’IETF et le W3C dans le cadre des travaux de normalisation sur l’architecture du Web. La syntaxe Scheme préfixe qui indique le contexte dans lequel les identifiants sont attribués (ex. URN, INFO, HTTP etc.) Pour garantir l’unicité, le scheme doit être enregistré auprès de l’IANA Le scheme est toujours suivi de « : » Authority Désigne l’autorité en charge d’attribuer des noms pour ce scheme Path/Name Nom (ou chemin) attribué par l’autorité nommante Les contraintes d’un identifiant unique ; pérenne ; maîtrisable ; extensible. Pour rappel, la problématique de la stabilité d’une URL (=URI) n’est pas technique, mais organisationnel…
 Pour garantir l’unicité, le scheme doit être enregistré auprès de l’IANA. Le scheme est toujours suivi de « : » Authority. Désigne l’autorité en charge d’attribuer des noms pour ce scheme. Path/Name. Nom (ou chemin) attribué par l’autorité nommante. Les contraintes d’un identifiant. unique ; pérenne ; maîtrisable ; extensible. Pour rappel, la problématique de la stabilité d’une URL (=URI) n’est pas technique, mais organisationnel…")
21
RDF : les URIs (l’exemple)
1- Prenez des choses/concepts/entités du monde réel et placez les dans le monde numérique, en les nommant et en les identifiant par des URIs. Signifié dans le monde réel Signifiant dans le monde numérique Tim Berners-Lee < Une personne < L’article « Semantic Web » de 2001 < est < Un texte < Puisque ces choses/concepts/entités sont identifiés par une URI, ils sont assimilables à des ressources (RFC 3986)
")
22
RDF : le triplet (le principe)
2- Exprimez des relations entre ces ressources sous la forme de triplets ou comment décrire l’information à son niveau de granularité le plus basique, la donnée ? La donnée est encodée dans le cadre d’un document Une série de signes reliés forme une donnée Chien Animal <html> <head> <title>Le chien</title> </head> <body> <p> le chien est un animal </p> </body> </html> doit comprendre la donnée Ne comprend pas la donnée mais qu’il s’agit d’un paragraphe De plus, la donnée est toujours vraie même en dehors de ce document. Machine La machine peut traiter et analyser la donnée car elle est encodée selon une logique formelle. Sujet Objet prédicat animal est chien Chaque membre du triplet est une ressource identifiée par une URI. C’est le principe du modèle RDF. La donnée elle-même est encodée sous la forme d’un triplet.

23
RDF : le triplet (l’exemple)
2- Exprimez des relations entre ces ressources sous la forme de triplets ou comment décrire l’information à son niveau de granularité le plus basique, la donnée ? Structure d’un triplet RDF = Structure d’une phrase simple Sujet Verbe Complément = (Sujet, Prédicat, Objet) L’article « Semantic Web » de 2001 est un texte (< < < L’article Semantic Web de 2001 a pour créateur Tim Berners-Lee (< < < Tim Berners-Lee est une personne (< < <
 L’article « Semantic Web » de 2001 est un texte. (< id=the-semantic-web>, < < L’article Semantic Web de 2001 a pour créateur Tim Berners-Lee. (< id=the-semantic-web>, < < Tim Berners-Lee est une personne. (< < <")
24
RDF : le graphe orienté (le principe)
3- Représentez et reliez les triplets sous la forme de graphes orientés Nœud 1 Nœud 1 Sujet Nœud 1 Entités Prédicat Arc 1 Arc 1 Arc 2 Arc 2 Relation Nœud 2 Objet Nœud 3 Nœud 3 Arc 1 Nœud 4

25
RDF : le graphe orienté (l’exemple)
3- Représentez et reliez les triplets sous la forme de graphes orientés < < < < < « Timothy Berners-Lee » < < < < < <

26
Le vocabulaire du Web sémantique
RDFS Ressource Description Framework Schema OWL Web Ontology Language RDFS (RDF schema) et OWL (Web Ontology language) sont deux recommandations du W3C (respectivement et pour mettre au point des vocabulaires RDF, c’est-à-dire déclarer et décrire les prédicats et les types de ressources sur lesquels ils peuvent porter.
 et OWL (Web Ontology language) sont deux recommandations du W3C (respectivement et pour mettre au point des vocabulaires RDF, c’est-à-dire déclarer et décrire les prédicats et les types de ressources sur lesquels ils peuvent porter.")
27
Retour sur les systèmes d’organisation des connaissances
Pour appréhender au mieux les connaissances, les hommes ont cherché des moyens de classer et contenir les informations du monde : Vocabulaire contrôlé Taxinomie Animal Mammifère Reptile Reptile Chimpanzé Primates narrower Animal Mammifère Homme Primates Homme Thésaurus Ontologie Pays de langue française Personne Afrique Francophone possède habite Europe Francophone related France Animal Lieu narrower Francophonie est originaire de Suisse Romande

28
Dans notre monde, chaque chose a une nature, un type.
Définir des classes Dans notre monde, chaque chose a une nature, un type. Exemples : Tim Berners-Lee est une personne ; Une personne est un être vivant ; est une page Web Une page Web est un document … Dans le monde RDF, la nature d’une chose/ressource est une « classe » Chose Être vivant Personne Chien Document Page Web Livre En RDF, une ressource appartient toujours à une classe.

29
Définir des propriétés
Dans notre monde, chaque type de choses possède des caractéristiques. Exemples : une personne a un nom ; une personne connaît d’autres personnes ; une page Web a un titre ; une page Web a un créateur ; … Dans le monde RDF, ces caractéristiques sont des propriétés. connaît Personne « une chaîne de caractères » Domaine créateur nom titre Page Web « une chaîne de caractères » Dans ce schéma, une ressource est symbolisée sous la forme d’une ellipse et un litéral (indiquant le type de données attendu) sous la forme d’un rectangle. Co-domaine En RDF, un prédicat est une propriété définie dans un vocabulaire.
 sous la forme d’un rectangle. Co-domaine. En RDF, un prédicat est une propriété définie dans un vocabulaire.")
30
Définir une logique pour déduire
Dans notre monde, chaque caractéristique et chaque type possèdent une logique interne. Exemple : Si un homme A est le frère d’un homme B, alors l’homme B est le frère de la personne A ; … Dans le monde RDF, cette logique est exprimée clairement dans le vocabulaire. Est frère de Homme A Homme B « Est frère de » est une propriété symétrique Est frère de Homme B Homme A En RDF, la logique permet de faire des inférences, c’est-à-dire de créer des nouvelles informations. »

31
Logique de description dans OWL
Source : Fabien Gandon,

32
Quelques vocabulaires et ontologies....
FOAF OAI-ORE Dublin Core RSS 1.0 Basic Geo (WGS84 lat/long) OAI-ORE ( est un vocabulaire pour représenter des ressources Web. FOAF ( est un vocabulaire RDF pour décrire une personne et son réseau social. DOAP ( est un vocabulaire pour décrire les projets de logiciels, en particulier Open Source SKOS ( est un vocabulaire RDF pour décrire les thésaurus. Basic Geo ( est un vocabulaire RDF permettant d’exprimer les coordonnées géographique d’un espace. Il est basé sur WGS84 ( soit le système géodésique mondial dans sa révision de 1984. SIOC ( est un vocabulaire RDF qui permet de décrire des communautés en ligne. Dublin Core est un vocabulaire RDF qui permet d’exprimer une notice bibliographique. Music ontology ( permet de décrire la musique (artistes, albums, pistes, concerts…) Good Relations ( permet de décrire des produits, leurs prix, les entreprises qui les commercialisent RSS 1.0 ( est la version RDF des flux de syndication Pour trouver d’autres vocabulaires RDF ou ontologies, vous pouvez consulter le site : Schemapedia
 OAI-ORE ( est un vocabulaire pour représenter des ressources Web. FOAF ( est un vocabulaire RDF pour décrire une personne et son réseau social. DOAP ( est un vocabulaire pour décrire les projets de logiciels, en particulier Open Source. SKOS ( est un vocabulaire RDF pour décrire les thésaurus. Basic Geo ( est un vocabulaire RDF permettant d’exprimer les coordonnées géographique d’un espace. Il est basé sur WGS84 ( soit le système géodésique mondial dans sa révision de SIOC ( est un vocabulaire RDF qui permet de décrire des communautés en ligne. Dublin Core est un vocabulaire RDF qui permet d’exprimer une notice bibliographique. Music ontology ( permet de décrire la musique (artistes, albums, pistes, concerts…) Good Relations ( permet de décrire des produits, leurs prix, les entreprises qui les commercialisent. RSS 1.0 ( est la version RDF des flux de syndication. Pour trouver d’autres vocabulaires RDF ou ontologies, vous pouvez consulter le site : Schemapedia")
33
Les alphabets du Web sémantique
Syntaxe pour sérialiser le RDF RDF/XML Notation 3 RDFa

34
RDF/XML <rdf:RDF xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:rdf=" xmlns:rdfs=" xmlns:dc=" <rdf:Description rdf:about=" <rdf:type rdf:resource=" <foaf:name>Timothy Berners-Lee</foaf:name> <foaf:maker rdf:resource=" <foaf:nick>timbl</foaf:nick> </rdf:Description> </rdf:RDF> RDF peut être « sérialisé », c’est-à-dire écrit en XML. Dans ce cas, c’est évidemment la syntaxe qui nous intéresse et non le modèle XML. Pour autant, un arbre étant un type particulier de graphes, il « suffit » de respecter quelques règles de base pour écrire du RDF en XML. Il est à noter qu’il n’existe aucune DTD ou schéma XML pour valider un fichier RDF en XML, ce qui est compréhensible, puisque l’écriture d’un graphe RDF peut prendre plusieurs formes dans l’arbre XML et que l’attribution d’une URI est complètement libre. L’élément racine est toujours RDF. Le système des espaces de noms qui désignent en XML un élément rattaché à un schéma XML, constitue pour RDF un mécanisme d’abréviations des prédicats. Une ressource décrite est toujours introduite par l’élément <rdf:Description>, l’URI de la resource (le sujet) dans Les éléments enfants sont les prédicats qui se rattachent à cette même ressource. Si l’objet est un litéral, il est représenté sous la forme de la valeur d’un élément. Si l’objet est une ressource, son URI est indiqué dans
 dans Les éléments enfants sont les prédicats qui se rattachent à cette même ressource. Si l’objet est un litéral, il est représenté sous la forme de la valeur d’un élément. Si l’objet est une ressource, son URI est indiqué dans")
35
RDF/XML - alternative <rdf:RDF
xmlns:foaf=" xmlns:rdf=" xmlns:rdfs=" xmlns:dc=" <foaf:Person rdf:about=" foaf:name="Timothy Berners-Lee"> <foaf:maker rdf:resource=" <foaf:nick>timbl</foaf:nick> </foaf:Person> </rdf:RDF> Comme le montre cette exemple, il existe plusieurs alternatives pour sérialiser RDF en XML. Dans cette exemple, l’élément qui introduit la description de la ressource équivaut au type (rdf:type, cf. la diapo précédente) de la ressource et le prédicat est placé en attribut de l’élément introduisant la description.
 de la ressource et le prédicat est placé en attribut de l’élément introduisant la description.")
36
Notation 3 (N3, N-Triples, Turtle)
@prefix rdfs: < . @prefix foaf: < . @prefix rdf: < . @prefix dc: < . < rdf:type foaf:Person ; foaf:name "Timothy Berners-Lee" ; foaf:maker < ; foaf:nick "timbl" . Les différentes notations dites « notation 3 » ont été mises au point pour simplifier le traitement et l’écriture de RDF. Il se rapproche beaucoup plus de la structure d’une phrase dans notre langue. Ainsi, le point virgule signale que le triplet suivant partage le même sujet (non exprimé) que le triplet précédent. Un point termine un ensemble de triplets partageant le même triplet.
 que le triplet précédent. Un point termine un ensemble de triplets partageant le même triplet.")
37
RDFa <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN"
" <html xmlns:foaf=" xmlns=" xmlns:dc=" <head> <title>Description de Timbl en XHTML + RDFa</title> </head> <body> <div typeof="foaf:person" about=" Le <span rel="foaf:maker" href=" du W3C</span> a pour nom <span property="foaf:name">Timothy Berners-Lee</span> et pour surnom <span property="foaf:nick">Timbl</span>. </div> </body> </html> RDFa est une recommandation du W3C depuis octobre 2008 (cf. les traductions en français : et dont le but est d’exprimer des triplets en RDF dans des pages Web grâce à l’ajout d’attributs spécifiques à XHTML. Les attributs ajoutés sont les suivants : @typeof : permet d’indiquer le type de la ressource ; @about : permet d’indiquer l’URI de la ressource en sujet ; @rel : permet d’exprimer le prédicat lorsque l’objet est une ressource ; @href : permet d’indiquer l’URI de la ressource en objet ; @property : permet d’indiquer le prédicat lorsque l’objet est un litéral ; @content : permet d’indiquer l’objet lorsque l’objet est un litéral, en son absence, le contenu de l’élément qui porte est considéré comme l’objet.

38
Le langage de communication du Web sémantique
SPARQL SPARQL Protocol and RDF Query Language Interroger, accéder, transporter les données en RDF Un langage de requêtes Un protocole d’accès SPARQL est à RDF ce que SQL est au base de données relationnelles. Mais, à la différence de SQL qui ne constitue qu’un langage de requêtes, SPARQL intègre aussi un protocole d’accès sous forme de Web service (en REST ou en SOAP) et un format XML pour la structuration des résultats. Ces trois parties de SPARQL sont des recommandations du W3C : Le langage de requêtes : Le protocole : Le format de résultats en XML : Un format XML pour les résultats
 et un format XML pour la structuration des résultats. Ces trois parties de SPARQL sont des recommandations du W3C : Le langage de requêtes : Le protocole : Le format de résultats en XML : Un format XML pour les résultats.")
39
Le langage de requêtes SPARQL : principes
Soit le graphe suivant enregistré dans une base de données RDF (un triple store) : Y 1 6 2 X 8 3 5 4 7 SPARQL permet d’extraire un sous-ensemble de ce graphe par l’expression de contraintes sous la forme d’équations Exemple : Je cherche les ressources liées à 1 par prédicat « rouge » et la chaîne de caractères liée à ces ressources par le prédicat « bleu » : 2. La chaîne de caractère liée à ces ressources par le prédicat 1. Les ressources liées à 1 par le prédicat « rouge » (<1> <rouge> ?resources) ; « bleu » (?resources <bleu> ?string).
 : Y X SPARQL permet d’extraire un sous-ensemble de ce graphe par l’expression de contraintes sous la forme d’équations. Exemple : Je cherche les ressources liées à 1 par prédicat « rouge » et la chaîne de caractères liée à ces ressources par le prédicat « bleu » : 2. La chaîne de caractère liée à ces ressources par le prédicat. 1. Les ressources liées à 1 par le prédicat. « rouge » (<1> <rouge> resources) ; « bleu » ( resources <bleu> string).")
40
Le langage de requêtes SPARQL : exemple
PREFIX foaf: < SELECT ?personnes ?nom Je veux connaître l’URI et les noms des personnes que connaît Tim Berners-Lee FROM < à partir de son fichier FOAF WHERE { < foaf:knows ?personnes. Tim Berners-Lee connaît des personnes. ?personnes foaf:name ?nom. Ces personnes s’appellent ???. } Types de requêtes : ASK, CONSTRUCT, DESCRIBE LOAD, INSERT, DELETE (en cours de normalisation)
")
41
Le format XML pour les résultats
<?xml version="1.0" ?> <sparql xmlns=" xmlns:xsi=" xsi:schemaLocation=" <!-- En-tête --> <head> <variable name="personnes"/> <variable name="nom"/> </head> <!-- Résultats --> <results distinct="false" ordered="true"> <result> <binding name="personnes"><uri> <binding name="nom"><literal>John Seely Brown</literal></binding> </result> <binding name="personnes"><uri> <binding name="nom"><literal>John Gage</literal></binding> </results> </sparql> Rappel des variables déclarées Un élément « result » par combinaisons possibles de variables

42
Pour résumer : le layer cake aujourd’hui
Déjà normalisé ou en cours de normalisation au W3C L’ensemble des briques technologiques du Web sémantique sont représentés par le W3C sous la forme d’un « cake » à plusieurs couches, correspondant à la vision initiale de Tim Berners-Lee. Il évolue au fur et à mesure de la standardisation d’un élément et de l’évolution inhérente à tout domaine de recherche. Il fait apparaître les briques encore manquantes actuellement.

43
Les outils pour mettre en œuvre les technos du Web sémantique
Créer des vocabulaires/ontologies avec le logiciel Protege Mettre les données au format RDF Créer des données RDF avec un éditeur RDF (Morla ou Top Braid composer) ou un éditeur XML Transformer des données de XML vers RDF/XML avec XSL Transformer une base de données relationnelle en RDF avec D2R server Stocker les données dans un triple store RDF Mémoire : Corese, Redstore Triple store natif : Mulgara, AllegroGraph, BigOWLIM, 4store, Neo4j BDR paramétrée : Virtuoso, ARC, Oracle 11g, Sesame, 3store Column store : Cstore, Heart, BigData, Cloudera Exploiter les données en RDF En Java (triples) : Jena, Sesame, Trialox SCB, RDF2Go En Java (ORM) : Topaz, RDFReactor, So(m)mer, Elmo, jenabean En PHP : RAP, ARC (généraliste) En C : Redland En Python : RDFlib En Ruby : ActiveRDF En Scala : Scardf Si vous en voulez plus, une liste de 835 outils est disponible : Sweet tools
 ou un éditeur XML. Transformer des données de XML vers RDF/XML avec XSL. Transformer une base de données relationnelle en RDF avec D2R server. Stocker les données dans un triple store RDF. Mémoire : Corese, Redstore. Triple store natif : Mulgara, AllegroGraph, BigOWLIM, 4store, Neo4j. BDR paramétrée : Virtuoso, ARC, Oracle 11g, Sesame, 3store. Column store : Cstore, Heart, BigData, Cloudera. Exploiter les données en RDF. En Java (triples) : Jena, Sesame, Trialox SCB, RDF2Go. En Java (ORM) : Topaz, RDFReactor, So(m)mer, Elmo, jenabean. En PHP : RAP, ARC (généraliste) En C : Redland. En Python : RDFlib. En Ruby : ActiveRDF. En Scala : Scardf. Si vous en voulez plus, une liste de 835 outils est disponible : Sweet tools.")
44
Comparaisons avec XML et BDR
Plan de la journée Du Web de documents au Web de données Les technologies du Web sémantique Comparaisons avec XML et BDR Présentation du Linked Data

45
XML : une logique structurelle
XML est un langage pour encoder une structure documentaire. Modèle d’organisation hiérarchique de l’information Arbre XML Syntaxe Règles 1 2 3 4 5 6 <html> <head> <title> Mon joli document </title> </head> <body> <p> Mon joli paragraphe </p> </body> </html> un élément racine une balise ouvrante, une balise fermante un document XML doit être bien formé Encodage des caractères un document XML peut être valide par rapport à une grammaire (nom des éléments et des attributs, règles de structuration, type de données…) Question : Un ensemble de métadonnées forme-t-il un document ? Forces Limites Pas un format binaire Indépendant outils/systèmes d’exploitation Assure une cohérence dans un domaine précis Respecte la logique du document physique Encodage contextuel au document Enfermement dans la logique documentaire Interopérabilité stricte (grammaire et son application) Le lien est un pointeur Les relations sont implicites
 Question : Un ensemble de métadonnées forme-t-il un document Forces. Limites. Pas un format binaire. Indépendant outils/systèmes d’exploitation. Assure une cohérence dans un domaine précis. Respecte la logique du document physique. Encodage contextuel au document. Enfermement dans la logique documentaire. Interopérabilité stricte (grammaire et son application) Le lien est un pointeur. Les relations sont implicites.")
46
Exemple de la logique XML : retour sur EAD/EAC
EAD est la réponse des archivistes pour encoder le document inventaire selon les principes d’ISAD(G). <ead xmlns="urn:isbn: "> <eadheader> <eadid></eadid> <filedesc> <titlestmt> <titleproper></titleproper> </titlestmt> </filedesc> </eadheader> <archdesc level="fonds"> <did> <unitid countrycode="FR"></unitid> </did> <dsc> <c> <unitid></unitid> <unittitle></unittitle> <unitdate></unitdate> <phystech><p></p></phystech> <controlaccess> <subject></subject> </controlaccess> </c> </dsc> </archdesc> </ead> L’EAD est la stricte transposition du document inventaire dans le monde numérique Outre les avantages de XML, l’EAD a constitué l’opportunité de continuer et de rendre concret le travail engagé avec ISAD(G). Question : Un inventaire constitue-t-il encore un document ou une suite de (méta)données structurées ? Limites La description d’un niveau archivistique n’a du sens que dans le contexte du document XML Les identifiants sont locaux / spécifiques au document XML Une section ne peut être référencé directement depuis un autre inventaire (on ne peut faire qu’un pointeur) Les notices d’autorités sont référencés sous la forme d’une chaîne de caractères Comment lier une notice EAC dans un fichier EAD ? l’interopérabilité avec d’autres systèmes de descriptions impose un mapping sur le plus petit dénominateur commun
. <ead xmlns= urn:isbn: > <eadheader> <eadid></eadid> <filedesc> <titlestmt> <titleproper></titleproper> </titlestmt> </filedesc> </eadheader> <archdesc level= fonds > <did> <unitid countrycode= FR ></unitid> </did> <dsc> <c> <unitid></unitid> <unittitle></unittitle> <unitdate></unitdate> <phystech><p></p></phystech> <controlaccess> <subject></subject> </controlaccess> </c> </dsc> </archdesc> </ead> L’EAD est la stricte transposition du document inventaire dans le monde numérique. Outre les avantages de XML, l’EAD a constitué l’opportunité de continuer et de rendre concret le travail engagé avec ISAD(G). Question : Un inventaire constitue-t-il encore un document ou une suite de (méta)données structurées Limites. La description d’un niveau archivistique n’a du sens que dans le contexte du document XML. Les identifiants sont locaux / spécifiques au document XML. Une section ne peut être référencé directement depuis un autre inventaire (on ne peut faire qu’un pointeur) Les notices d’autorités sont référencés sous la forme d’une chaîne de caractères. Comment lier une notice EAC dans un fichier EAD l’interopérabilité avec d’autres systèmes de descriptions impose un mapping sur le plus petit dénominateur commun.")
47
Différences entre XML et RDF
VS. XML : un modèle d’arbre RDF : un modèle de graphes 1 1 1 2 3 7 6 3 2 4 2 8 5 8 3 5 6 5 4 7 4 7 Description structurée Description formelle La structure est pensée pour le contexte du document (interopérabilité très complexe) Relations entre les nœuds implicites Navigation dans l’arbre pour passer d’un nœud à un autre L’identification des ressources est spécifique au contexte du document Idéal pour exprimer la structure d’un document Les choses sont décrites comme des objets logiques Aucune relation n’est implicite Plus facile de naviguer dans le graphe si les données sont fortement reliées Toutes les ressources sont identifiées par des URI Idéal pour décrire des données
 Relations entre les nœuds implicites. Navigation dans l’arbre pour passer d’un nœud à un autre. L’identification des ressources est spécifique au contexte du document. Idéal pour exprimer la structure d’un document. Les choses sont décrites comme des objets logiques. Aucune relation n’est implicite. Plus facile de naviguer dans le graphe si les données sont fortement reliées. Toutes les ressources sont identifiées par des URI. Idéal pour décrire des données.")
48
Les données archivistiques en RDF
ore:ResourceMap Inventaire (eadheader) foaf:Organization Entrepôt (repository) ore:describes ore:describes ore:Aggregation Composant de haut niveau (archdesc) skos:Concept xsd:string dct:subject ore:isAggregatedBy dct:title dct:coverage xsd:string Composant (c) scopeNote rdfs:XMLLitteral dct:identifier skos:Concept frbr:embodied foaf:topic foaf:Person dct:type event:producedIn ore:isAggregatedBy Objet physique frbr:Item (?) foaf:topic event:Event dct:temporal foaf:Agent dct:description dct:extent event:time foaf:Organization xsd:string time:TemporalEntity xsd:string
 foaf:Organization. Entrepôt (repository) ore:describes. ore:describes. ore:Aggregation. Composant de haut niveau (archdesc) skos:Concept. xsd:string. dct:subject. ore:isAggregatedBy. dct:title. dct:coverage. xsd:string. Composant (c) scopeNote. rdfs:XMLLitteral. dct:identifier. skos:Concept. frbr:embodied. foaf:topic. foaf:Person. dct:type. event:producedIn. ore:isAggregatedBy. Objet physique frbr:Item ( ) foaf:topic. event:Event. dct:temporal. foaf:Agent. dct:description. dct:extent. event:time. foaf:Organization. xsd:string. time:TemporalEntity. xsd:string.")
49
Les limites du modèle relationnel
Voici un modèle relationnel classique décrivant les JO : idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL Analysons les problèmes qu’ils posent

50
Les limites du relationnel (1) : la structure des données
1- Séparation entre la structure des données et les données elles-mêmes idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL

51
Les limites du relationnel (1) : la structure des données
1- Séparation entre la structure des données et les données elles-mêmes idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL Si on extrait les données de la base, il faut aussi en extraire la structure pour comprendre à quoi correspond chacune des données

52
Les limites du relationnel (1) : la structure des données
1- Séparation entre la structure des données et les données elles-mêmes idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL Une donnée s’applique à un enregistrement car elle est associée à un champ. La relation est induite par la structure de la table.

53
Les limites du relationnel (1) : la structure des données
1- Séparation entre la structure des données et les données elles-mêmes idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL Les données ne sont pas indépendantes les unes des autres. Elles se conçoivent dans le contexte de la base, d’un enregistrement et d’un champ.

54
Les limites du relationnel (1) : la structure des données
2- La structure d’une base de données est rigide idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL

55
Les limites du relationnel (1) : la structure des données
2- La structure d’une base de données est rigide idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-ja birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL Si une donnée est manquante pour un champ dans un enregistrement, une valeur « NULL » fictive est ajoutée.

56
Les limites du relationnel (1) : la structure des données
2- La structure d’une base de données est rigide idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant id athletes Representant2 athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-ja birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL 2 Toto Si une donnée de même nature est en double pour un enregistrement (même pour un seul), il est nécessaire de créer un autre champ ou ...
, il est nécessaire de créer un autre champ ou ...")
57
Les limites du relationnel (1) : la structure des données
2- La structure d’une base de données est rigide id id ville year opened Ceremony Date closed Ceremony Date athletes Number motto 1 1896 1896/04/06 1896/04/15 241 NULL 2 2008 2008/08/08 2008/08/24 11028 One World one Dream idjo idAthleteRepresentant 2 1 id athlete label-fr label-en label-ja birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL 2 Toto … ou une autre table…

58
Les limites du relationnel (1) : la structure des données
2- La structure d’une base de données est rigide idville label-fr label-en label-ja longitude latitude 1 Athènes Athens NULL 2 Pékin Beijing 北京市 id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-ja birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL Pour gérer le multilinguisme, il faut créer de champs correspondant à chacune des langues, alors que la signification du champ est exactement la même ou créer une table spécifique.

59
Les limites du relationnel (1) : la structure des données
3- Les relations entre deux tables sont induites idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-ja birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL

60
Les limites du relationnel (1) : la structure des données
3- Les relations entre deux tables sont induites idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-ja birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL La relation entre les données de deux tables est induite par l’utilisation d’identifiants communs dites clés étrangères. La nature de la relation n’est pas exprimée clairement ni dans la structure, ni dans la donnée.

61
Les limites du relationnel (1) : la structure des données
3- Les relations entre deux tables sont induites idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-ja birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL L’extraction d’une base de données ne met pas en lumière ces relations. Il faut extraire les données des différentes tables pour conserver la relation.

62
Les limites du relationnel (1) : la structure des données
4- L’identifiant d’un enregistrement est une donnée comme les autres idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL

63
Les limites du relationnel (1) : la structure des données
4- L’identifiant d’un enregistrement est une donnée comme les autres idville label-fr label-en longitude latitude 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL L’identifiant d’un enregistrement n’a pas une forme normalisée. Il est dépendant de la base voire de la table (donc de la structure).
.")
64
Les limites du relationnel (2) : l’interopérabilité des données
1- Les identifiants sont locaux et spécifiques à une base de données idville longitude latitude alpha beta idville label-fr label-en 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL Il n’est pas possible d’identifier nativement deux ressources équivalentes entre deux bases de données différentes.

65
Les limites du relationnel (2) : l’interopérabilité des données
2- Les noms des champs sont spécifiques à une base de données idcity name longitude latitude alpha Athènes beta Pékin idville label-fr label-en 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL La structure d’une base de données est locale. Il n’existe pas de normes pour dénommer les propriétés et les rattacher à une normalisation de tel ou tel type de données.

66
Les limites du relationnel (2) : l’interopérabilité des données
3- La structure d’une base ne s’appuie sur aucun mécanisme d’héritages idcity name longitude latitude alpha Athènes beta Pékin idville label-fr label-en 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream La table JO une spécialisation de description d’un événement ? id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL La table athlete une spécialisation de description d’une personne ? Il n’est pas possible de relier une table à un modèle générique de description local ou externe dont il peut hériter les caractéristiques ce qui impose de construire un MCD à zéro ou presque.

67
Les limites du relationnel (2) : l’interopérabilité des données
4- Il n’existe aucune représentation normalisée pour échanger des BDR sur un réseau. idcity name longitude latitude alpha Athènes beta Pékin idville label-fr label-en 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL L’extraction d’une base de données est spécifique pour chaque base, il n’existe aucune syntaxe normalisée pour échanger les données d’une base et les fusionner avec une autre base.

68
Les limites du relationnel (2) : l’interopérabilité des données
5- Il n’existe aucun moyen normalisé de requêter directement une BDR sur le Web. idcity name longitude latitude alpha Athènes beta Pékin idville label-fr label-en 1 Athènes Athens 2 Pékin Beijing id id ville year opened Ceremony Date closed Ceremony Date id athletes Representant athletes Number motto 1 1896 1896/04/06 1896/04/15 NULL 241 2 2008 2008/08/08 2008/08/24 11028 One World one Dream id athlete label-fr label-en label-cn birth Date death Date 1 Zhang Yining 張怡寧 1981/10/05 NULL L’extraction d’une base de données est spécifique pour chaque base, il n’existe aucune syntaxe normalisée pour échanger les données d’une base et les fusionner avec une autre base.

69
Différences entre RDBMS et RDF
VS RDBMS : un modèle de tables RDF : un modèle de graphes 1 Table 2 Id att1 att2 ‘a’ 6 1 ‘b’ ‘c’ 6 Table 1 Id att1 att2 att3 null 42 1 ‘b’ 6 2 8 3 5 4 7 Description orientée enregistrements Description orientée triple pérenne Le modèle relationnel fait la différence entre les relations internes (attributs) et externes (clés) Structure d’une table rigide : valeurs absentes explicites, pas de possibilité de répéter un champ pour une notice Modèle centralisé : les identifiants d’enregistrements ne sont valables que pour la base de données Modèle logique et modèle physique confondu (cf. la forme et l’utilisation de SQL) Idéal pour des relations simples, figées et nécessitant un contrôle d’intégrité a priori Les relations font partie des données Chaque triplet est autonome, absolu et pérenne Contrôle d’intégrité par inférence a posteriori Modèle distribué Séparation entre modèle logique et modèle physique (Cf. RDBMS2RDF et SPARQL) Idéal pour décrire des données avec haut niveau d’organisation, réparties et pérennes Pour en savoir plus sur cette question, cf.
 et externes (clés) Structure d’une table rigide : valeurs absentes explicites, pas de possibilité de répéter un champ pour une notice. Modèle centralisé : les identifiants d’enregistrements ne sont valables que pour la base de données. Modèle logique et modèle physique confondu (cf. la forme et l’utilisation de SQL) Idéal pour des relations simples, figées et nécessitant un contrôle d’intégrité a priori. Les relations font partie des données. Chaque triplet est autonome, absolu et pérenne. Contrôle d’intégrité par inférence a posteriori. Modèle distribué. Séparation entre modèle logique et modèle physique (Cf. RDBMS2RDF et SPARQL) Idéal pour décrire des données avec haut niveau d’organisation, réparties et pérennes. Pour en savoir plus sur cette question, cf.")
70
Différences entre une API Web spécifique et SPARQL
VS Data Data Data Data RDF + SPARQL endpoint API spécifique API spécifique API spécifique Appli SPARQL Data RDF + SPARQL endpoint Application Protocole normalisé pour l’interrogation de données structurées selon le modèle RDF Possibilité (en théorie) d’interroger plusieurs bases RDF décentralisées via une seule requête Requête possible sur toutes les données Langage de requêtes complet L’intelligence de la requête est dans les données et non dans le protocole Le schéma d’exposition n’a pas besoin d’être adapté en fonction du client, c’est le client qui adapte sa requête Protocole pour récupérer des données structurées d’un site API spécifique Langage de requêtes limité aux possibilités de l’API L’intelligence de la requête est dans les verbes de l’API et non dans les données
 d’interroger plusieurs bases RDF décentralisées via une seule requête. Requête possible sur toutes les données. Langage de requêtes complet. L’intelligence de la requête est dans les données et non dans le protocole. Le schéma d’exposition n’a pas besoin d’être adapté en fonction du client, c’est le client qui adapte sa requête. Protocole pour récupérer des données structurées d’un site. API spécifique. Langage de requêtes limité aux possibilités de l’API. L’intelligence de la requête est dans les verbes de l’API et non dans les données.")
71
Différences entre OAI-PMH et SPARQL
VS Cat-OAI OAI-Num OAI-SUDOC Data RDF + SPARQL endpoint Notices oai_dc Notices oai_dc Notices oai_dc Appli SPARQL Service provider Data provider Data RDF + SPARQL endpoint HTTP HTTP HTTP Moteur de recherche Protocole normalisé pour l’interrogation de données structurées selon le modèle RDF Possibilité (en théorie) d’interroger plusieurs bases RDF décentralisées via une seule requête Requête possible sur toutes les données Langage de requêtes complet L’intelligence de la requête est dans les données et non dans le protocole Le schéma d’exposition n’a pas besoin d’être adapté en fonction du client, c’est le client qui adapte sa requête Adapté à l’interrogation de bases de données hétérogènes et distribuées Protocole normalisé pour l’exposition et l’indexation des métadonnées de notices (problème pour la granularité des ressources) Langage de requête très limité Un schéma par défaut de métadonnées OAI_DC basé sur XML Nécessite un service provider pour interroger plusieurs « data provider OAI » : impossible d’interroger directement une base OAI Adapté à l’indexation massive de notices uniformes
 d’interroger plusieurs bases RDF décentralisées via une seule requête. Requête possible sur toutes les données. Langage de requêtes complet. L’intelligence de la requête est dans les données et non dans le protocole. Le schéma d’exposition n’a pas besoin d’être adapté en fonction du client, c’est le client qui adapte sa requête. Adapté à l’interrogation de bases de données hétérogènes et distribuées. Protocole normalisé pour l’exposition et l’indexation des métadonnées de notices (problème pour la granularité des ressources) Langage de requête très limité. Un schéma par défaut de métadonnées OAI_DC basé sur XML. Nécessite un service provider pour interroger plusieurs « data provider OAI » : impossible d’interroger directement une base OAI. Adapté à l’indexation massive de notices uniformes.")
72
Présentation du Linked Data
Plan de la journée Du Web de documents au Web de données Les technologies du Web sémantique Comparaisons avec XML et BDR Présentation du Linked Data

73
Les quatre principes du Linked data
Smoking_pipe_%28tobacco%29 Utiliser des URIs Utiliser des URIs accessibles via HTTP Donner l’accès aux données utiles en utilisant les standards SPARQL et RDF Exprimer l’URI des objets liés Source :

74
Linked data cloud en détail : ressources d’intérêt général

75
Le projet DBPedia DBpedia est une initiative visant à extraire de l’information structurée à partir de Wikipedia et à rendre cette information disponible sur le Web. DBPedia permet de faire des requêtes complexes sur les données de Wikipedia, et de relier d’autres ensembles de données du Web à Wikipedia. 213,000 personnes, 328,000 lieux, 57,000 albums musicaux, 36,000 films, etc. 274 millions d’informations (triplets RDF) Mis au point et maintenu par Universität Leipzig, Freie Universität Berlin et la société OpenLink Software dans le cadre du projet
 Mis au point et maintenu par Universität Leipzig, Freie Universität Berlin et la société OpenLink Software dans le cadre du projet.")
76
Linked data cloud en détail : ressources « sociales »
Ressources d’intérêt général

77
Linked data cloud en détail : ressources géographiques
Ressources « sociales » Ressources géographiques et statistiques Ressources d’intérêt général

78
Geonames et LinkedGeoData
Geonames est un système d’information géographique dont les informations sont libres (CC BY). 8 millions d’emplacements géographiques (villes, monuments, montagnes…) dans le monde sont référencés et géotaggués ce qui en fait un des référentiels géographiques les plus complets. En complément de Web services, les données sont accessibles selon les principes du Linked Data. RDF pour les machines HTML pour les humains LinkedGeoData est à OpenStreetMap ce que Dbpedia est à Wikipedia 320 millions de points géoréférencés 25 millions d’itinéraires
. 8 millions d’emplacements géographiques (villes, monuments, montagnes…) dans le monde sont référencés et géotaggués ce qui en fait un des référentiels géographiques les plus complets. En complément de Web services, les données sont accessibles selon les principes du Linked Data. RDF pour les machines. HTML pour les humains. LinkedGeoData est à OpenStreetMap ce que Dbpedia est à Wikipedia. 320 millions de points géoréférencés 25 millions d’itinéraires.")
79
Les données gouvernementales
A la suite de l’annonce de Barack Obama de mettre à disposition les données publiques américaines, les initiatives dans le domaine se multiplient. Les principes du Linked Data sont au cœur de la réflexion, mais pas forcément utilisés. Data.gov.uk Data.gov Sous la direction de Nigel Shadbolt et Tim Berners-Lee ensembles de données Utilisation des technos du Web sémantique Initiative de Barack Obama 1076 ensembles de données Utilisation des technos du Web sémantique

80
Linked data cloud en détail : ressources multimédia
Ressources « sociales » Ressources géographiques et statistiques Ressources d’intérêt général

81
Les sites de la BBC : exploiter et enrichir le « cloud »
La BBC utilise pour plusieurs de ses sites les données du Linked Data pour construire des sites Web et les enrichit avec ses propres données. BBC Wildlife finder BBC Music Beta Données de la BBC Données de Music Brainz Données de Dbpedia Données de la BBC Données de Dbpedia

82
Linked data cloud en détail : ressources biologiques et médicales
Ressources multimédia Ressources « sociales » Ressources géographiques et statistiques Ressources d’intérêt général Ressources médicales et biologiques

83
Linked data cloud en détail : ressources bibliographiques
Ressources multimédia Ressources « sociales » Ressources bibliographiques Ressources géographiques et statistiques Ressources d’intérêt général Ressources médicales et biologiques

84
LIBRIS (catalogue collectif suédois)
Métadonnées descriptives traditionnelles Lien avec Dbpedia FRBRisation

85
Exemple d’utilisation 1 : Linked book Mashup
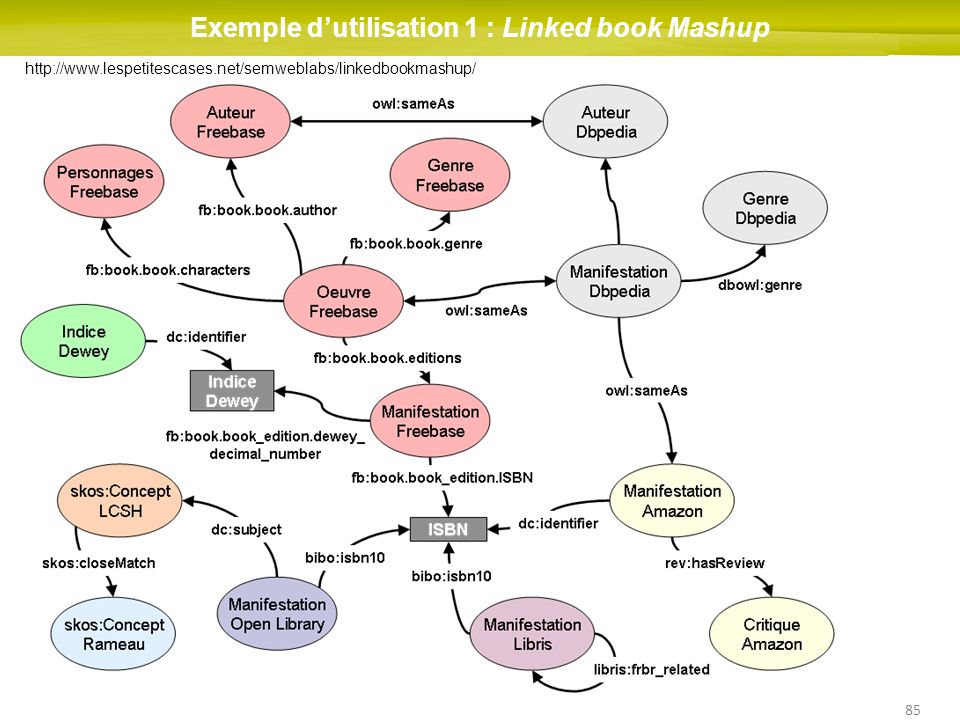
86
Exemple d’utilisation 1 : Linked book Mashup

87
Exemple d’utilisation 2 : Linked My Music

88
Exemple d’utilisation 2 : Linked My Music

89
Avantages du Web de données
Pas de conversion / mapping Chacun utilise son propre de format de métadonnées, ce qui n'empêche pas de rassembler les triplets en RDF Pas de données redondantes Chacun créée les données dont il a besoin, et récupère les informations qui existent déjà Pas de moissonnage / collecte de métadonnées Les données sont disponibles directement sur le Web Pas de problème de traçabilité Grâce aux URI, on peut revenir aux données source, quelle que soit leur origine Pas de développements spécifiques Tout repose sur des standards ouverts comme RDF, SPARQL... pas besoin d'apprendre de nouveaux langages et protocoles

90
Merci pour votre attention
Gautier Poupeau Antidot | GSM: +33 (0) F-75 Paris | mailto: Blog : Les petites cases | Twitter
 F-75 Paris | mailto: Blog : Les petites cases | Twitter")
Présentations similaires



















