Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Introduction à la tolérance aux défaillances
Joffroy Beauquier LRI CNRS – Université Paris Sud

3
Défaillances

4
Motivation Accroissement du nombre des composants
Impossibilité de relancer le système chaque fois qu’une défaillance se produit Le problème se pose aussi dans le cas séquentiel

5
Trois approches Algorithmes robustes Auto-stabilisation
Etats de reprise et retours en arrière

6
Les hypothèses (algorithmes robustes)
Les défaillances n’affectent qu’une partie du système Utilisation de la redondance par la multiplication Mais problème du consensus Bien entendu les défaillances peuvent frapper l’algorithme de consensus

7
Types de défaillances (algorithmes robustes)
Processus initialement morts Défaillances définitives Omissions Comportement byzantin (malveillant) Hiérarchie de défaillances
 Hiérarchie de défaillances.")
8
Les hypothèses (auto-stabilisation)
Les défaillances peuvent frapper tout ce qui n’est pas fixe dans le système (mémoires, canaux mais pas le code) Les défaillances sont peu fréquentes (par rapport au temps de récupération)
 Les défaillances sont peu fréquentes (par rapport au temps de récupération)")
9
Algorithmes robustes L’effet des défaillances est masqué
La correction est maintenue tout au long de l’exécution Le surcoût dû au contrôle est très important Approche réservée à des systèmes critiques (aviation civile, contrôle de centrales nucléaires, navette spatiale)
")
10
Algorithmes auto-stabilisants
L’effet des défaillances n’est pas masqué Après des défaillances, le comportement cesse d’être correct, mais après un certain délai, il le redevient, sans intervention extérieure ou centralisée Le surcoût en phase stabilisée est faible

11
Auto-stabilisation Défaillances Etats Etats légitimes Temps

12
Problèmes de décision (alg. robustes)
Chaque processus dispose d’une valeur d’entrée Chaque processus (correct) doit écrire de manière irréversible une valeur de sortie La valeur de décision dépend des valeurs d’entrée
 doit écrire de manière irréversible une valeur de sortie. La valeur de décision dépend des valeurs d’entrée.")
13
Consensus sur les entrées
Calculs répliqués sur plusieurs machines (au début d’un pas, les valeurs d’entrée sont identiques) Pour chaque pas de calcul, on obtient donc autant de résultats que de réplications En l’absence de défaillances tous les résultats sont identiques Avec des défaillances ils peuvent être différents. On veut que les processus non défaillants tombent d’accord sur la valeur à utiliser pour le pas suivant
 Pour chaque pas de calcul, on obtient donc autant de résultats que de réplications. En l’absence de défaillances tous les résultats sont identiques. Avec des défaillances ils peuvent être différents. On veut que les processus non défaillants tombent d’accord sur la valeur à utiliser pour le pas suivant.")
14
Consensus : exemples L’effet d’un capteur défectueux, qui donne des résultats différents de ceux des capteurs en bon état, doit être neutralisé La navette spatiale

15
1 1 1 1 1 1 1 Voteur 1

16
Diffusion fiable

17
Diffusion fiable Un diffuseur doit envoyer une valeur à tous les autres processus Chaque processus doit décider une valeur Tous les processus corrects doivent décider la même valeur Si le diffuseur est non-défaillant, la valeur décidée doit être la valeur du diffuseur

18
Commit/abort

19
Commit-Abort Base de données répliquée
Une transaction impliquant plusieurs sites doit être exécutée (commit) soit sur tous les sites, soit sur aucun (abort) Vote des sites (oui ou non) Si tous les sites votent oui chacun doit décider oui Si un des sites vote non chacun doit décider non
 soit sur tous les sites, soit sur aucun (abort) Vote des sites (oui ou non) Si tous les sites votent oui chacun doit décider oui. Si un des sites vote non chacun doit décider non.")
20
Election Un des processus doit décider d’être le leader et les autres de ne pas l’être Régénération du jeton d’un token ring Désignation d’un serveur

21
Group membership Systèmes en ligne (contrôle du traffic aérien, système d’exploitation) Les composants défectueux doivent être réparés Nécessité de reconfigurer le groupe des processeurs actifs

22
Consensus : spécification
Terminaison : tout processus non défaillant décide une valeur Accord : deux processus non défaillants ne décident pas deux valeurs différentes Non-trivialité : si les valeurs initiales des processus non défaillants sont égales, c’est la seule valeur de décision possible

23
Consensus : résultat d’impossibilité
Il n’existe pas d’algorithme résolvant le consensus dans un système asynchrone où les défaillances se réduisent à une seule panne « crash »

24
Contourner le résultat d’impossibilité
Introduire des hypothèses de synchronisme partiel Détecteurs de défaillances Solutions probabilistes

25
Les détecteurs de défaillances
Chandra et Toueg (1996) Peut-être! P en panne? Oracle Réseau
 Peut-être! P en panne Oracle. Réseau.")
26
Les détecteurs de défaillances
Défaillances de type « crash » Un détecteur de défaillances est un module qui fournit une liste de processus suspectés de crash Détecteur le plus faible pour résoudre le consensus : il existe un instant à partir duquel il existe un processus correct qui n’est jamais suspecté

27
Auto-stabilisation Auto-stabilisation Etats Etats Temps Temps
Défaillances Défaillances Etats Etats Etats légitimes Etats légitimes Temps Temps

28
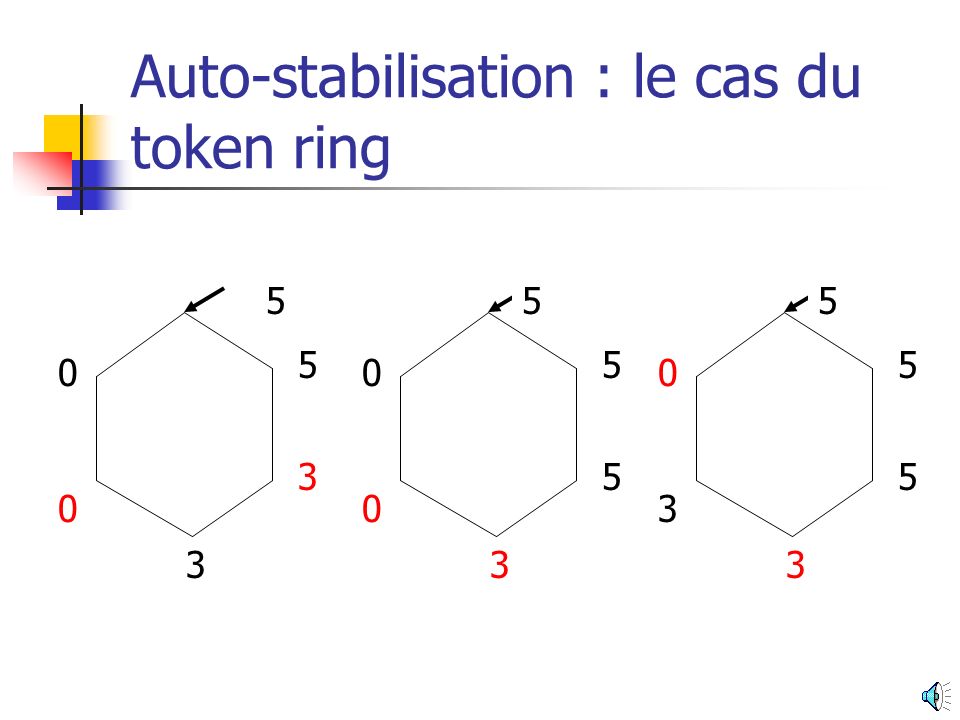
Auto-stabilisation : le cas du token ring
Chaque processus possède une seule variable de type {0, 1, 2, 3, 4, 5} 5 4 3 3

29
Auto-stabilisation : le cas du token ring
5 5 5 4 3 3 3 3

30
Auto-stabilisation : le cas du token ring
5 5 5 5 5 5 3 5 5 3 3 3 3
31
Auto-stabilisation : le cas du token ring
5 5 5 5 5 5 5 5 5 3 3 5 3 5 5

32
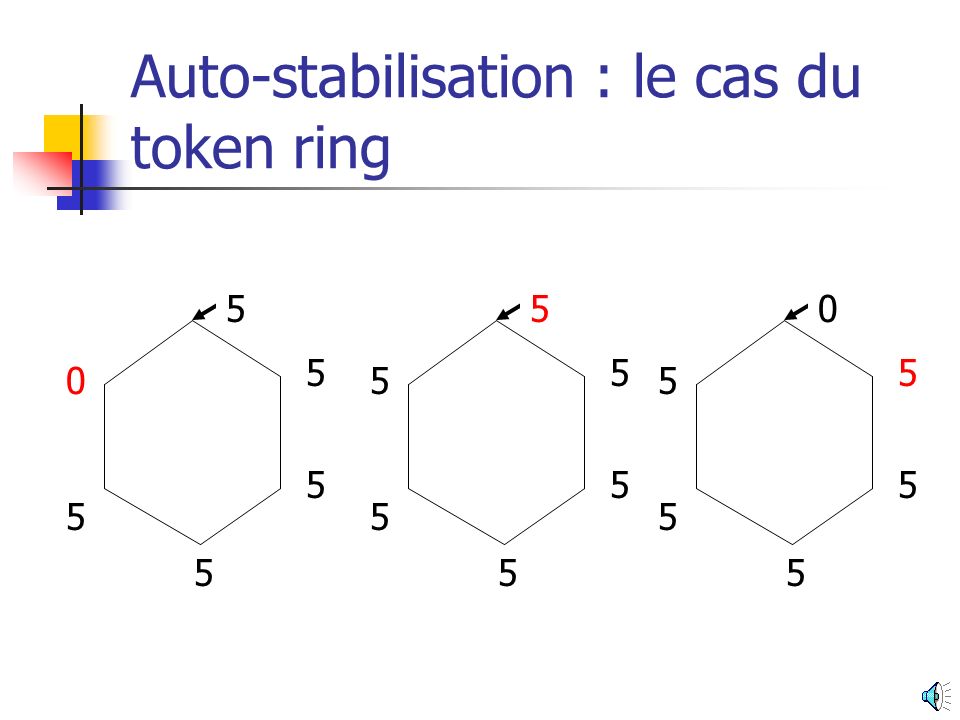
Auto-stabilisation : le cas du token ring
5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5
33
Avantages de l’auto-stabilisation (1)
Pas besoin d’initialisation Adaptée par nature aux réseaux dynamiques Pas besoin de reset ni d’intervention extérieure a pas de centralisation Très faible surcoût en phase stabilisée : les échanges sont purement locaux Tolérance suffisante pour les applications non critiques

34
Avantages de l’auto-stabilisation (2)
Pas de diffusions coûteuses Solutions à mémoire bornée Solutions time-adaptive Technique éprouvée et incontournable La formalisation permet d’obtenir des outils génériques qui simplifient la programmation

35
Conclusion (1) Deux aspects critiques des systèmes répartis actuels : fiabilité et sécurité Pour la fiabilité, deux approches : Réplication + consensus : coûteux, mais les défaillances sont masquées Auto-stabilisation : moins coûteux, mais la correction n’est pas garantie durant la phase de stabilisation

36
Conclusion (2) La solution réside sans doute dans la complémentarité des deux approches (Cf. Projet de maison intelligente de Microsoft) Il existe aussi d’autres techniques à base de points de reprise

Présentations similaires











 adaptable pour les systèmes à composants : application à un gestionnaire de données Phuong-Quynh Duong, Elizabeth Pérez-Cortés,>")







>")