Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
vers une base libre de corpus annotés
La FReeBank : vers une base libre de corpus annotés Susanne Salmon-Alt (ATILF – CNRS) Eckhard Bick (University of Southern Denmark) Laurent Romary (LORIA – INRIA) Jean-Marie Pierrel (ATILF – CNRS)
 Eckhard Bick (University of Southern Denmark) Laurent Romary (LORIA – INRIA) Jean-Marie Pierrel (ATILF – CNRS)")
2
Trois constats Manque de corpus annotés réutilisables
modélisation, apprentissage, évaluation retard important par rapport à l’anglais Initiatives d’annotation au-delà de la morphologie syntaxe (Abeillé 2003, Vilnat & al. 2003) anaphores (Tutin & al. 1999, Popescu-Belis 1999, Salmon-Alt 2002) sémantique (Projet Evalda Média) majorité de ressources sous droits et/ou non normalisées Initiatives de mise en ligne de ressources libres lexiques : tables LADL/IGM, LEFFF, ABU, Papillon corpus : Asila, GDR Sémantique, Ananas, Text®, ABU mais peu de ressources annotées problèmes d’interfaçage et de mise à jour
 anaphores (Tutin & al. 1999, Popescu-Belis 1999, Salmon-Alt 2002) sémantique (Projet Evalda Média) majorité de ressources sous droits et/ou non normalisées. Initiatives de mise en ligne de ressources libres. lexiques : tables LADL/IGM, LEFFF, ABU, Papillon. corpus : Asila, GDR Sémantique, Ananas, Text®, ABU. mais peu de ressources annotées. problèmes d’interfaçage et de mise à jour.")
3
Un objectif Espace ouvert de dépôt de ressources libres
pas un simple espace de méta-données (cf. OLAC) téléchargement et dépôt de données brutes ou annotées dépôt d’annotations sur ressources existantes méta-annotations annotations concurrentes corrections, affinages annotation d’extraits pas de validation a priori des annotations documentation schémas pratiques
 téléchargement et dépôt de données brutes ou annotées. dépôt d’annotations sur ressources existantes. méta-annotations. annotations concurrentes. corrections, affinages. annotation d’extraits. pas de validation a priori des annotations. documentation. schémas. pratiques.")
4
… et un rêve Annotations « stand-off » Annotations normalisées
séparation entre données primaires et annotations souhaitables pour annotations concurrentes : comparaison de deux étiqueteurs annotations non hiérarchiques : antécédents complexes Annotations normalisées suivi des recommandations (TEI, ISO TC37/SC4, RNIL) indispensables pour interfaçage avec outils TAL évaluation des ressources partage d’outils de traitement de corpus pérennisation documentation partagée
 indispensables pour. interfaçage avec outils TAL. évaluation des ressources. partage d’outils de traitement de corpus. pérennisation. documentation partagée.")
5
Du rêve à la réalité… Corpus : Le Père Goriot (chap. I) texte_brut
Madame Vauquer, née De Conflans , est une vieille femme qui, depuis quarante ans, tient à Paris une pension bourgeoise établie rue Neuve-Sainte-Geneviève , entre le quartier latin et le faubourg Saint-Marceau . Cette pension, connue sous le nom de la Maison-Vauquer , admet également des hommes et des femmes, des jeunes gens et des vieillards, sans que jamais la médisance ait attaqué les mœurs de ce respectable établissement. Mais aussi depuis trente ans ne s'y était-il jamais vu de jeune personne, et pour qu'un jeune homme y demeure, sa famille doit-elle lui faire une bien maigre pension. Néanmoins, en 1819, époque à laquelle ce drame commence, il s'y trouvait une pauvre jeune fille. En quelque discrédit que soit tombé le mot drame par la manière abusive et

6
Du rêve à la réalité… Corpus : Le Père Goriot (chap. I) texte_brut
<tt> <ut> <p> <seg> <er type="person-oeuvre" id2="p1" id="1"> Madame Vauquer , née De Conflans </er> , est une vieille femme qui , depuis quarante ans , tient à <er type="place-ville" id2="pl1" id="2"> Paris </er> <er type="org-oeuvre" id2="or1" id="6"> une pension bourgeoise établie <er type="place-rue" id2="pl2" id="3"> rue Neuve - Sainte - Geneviève </er> , entre <er type="place-quartier" id2="pl3" id="4"> le quartier latin </er> et le <er type="place-rue" id2="pl4" id="5"> faubourg Saint - Marceau </er> </er> . </seg> texte_balisé_tei entités_nommées référence

7
Du rêve à la réalité… Corpus : Le Père Goriot (chap. I) texte_brut
<tt><ut><p><seg> <rs type="person-oeuvre" id="p1"> <name type="person-oeuvre" key="Mme Vauquer">Madame Vauquer</name>née <name type="person-oeuvre" key="De Conflans">De Conflans</name> </rs>, est une vieille femme qui, depuis quarante ans, tient à <rs type="place-ville" id="pl1"> <name type="place-ville" key="Paris">Paris</name> </rs> … </seg></p> </ut></tt> texte_balisé_tei entités_nommées référence texte_balisé_tei entités_nommées référence

8
Du rêve à la réalité… Corpus : Le Père Goriot (chap. I) texte_brut
<word id="word_27">Madame</word> <word id="word_28">Vauquer</word> <word id="word_29">,</word> <word id="word_30">née</word> <word id="word_31">De</word> <word id="word_32">Conflans</word> <word id="word_33">,</word> <word id="word_34">est</word> <word id="word_35">une</word> <word id="word_36">vieille</word> <word id="word_37">femme</word> <word id="word_38">qui</word> texte_segmenté texte_balisé_tei entités_nommées référence texte_balisé_tei entités_nommées référence

9
Du rêve à la réalité… Corpus : Le Père Goriot (chap. I) texte_brut
morpho-syntaxe <w span="word_24" msd="DTN:m:s" lemma="un"></w> <w span="word_25" msd="SBC:_:s" lemma="pension"></w> <w span="word_26" msd="ADJ:f:s" lemma="bourgeois"></w> <w span="word_27" msd="SBC:_:s" lemma="madame"></w> <w span="word_28" msd="SBP" lemma="vauquer"></w> <w span="word_29" msd=" " lemma=","></w> <w span="word_30" msd="ADJ2PAR:f:s" lemma="naître"></w> <w span="word_31" msd="PREP" lemma="de"></w> <w span="word_32" msd="SBP" lemma="conflans"></w> <w span="word_33" msd=" " lemma=","></w> texte_segmenté texte_balisé_tei entités_nommées référence texte_balisé_tei entités_nommées référence

10
Du rêve à la réalité… Corpus : Le Père Goriot (chap. I) texte_brut
morpho-syntaxe <w span="word_24" msd="DETIFS" lemma="un"></w> <w span="word_25" msd="NCFS" lemma="pension"></w> <w span="word_26" msd="ADJFS" lemma="bourgeois"></w> <w span="word_27" msd="NCFIN" lemma="madame"></w> <w span="word_28" msd="INC" lemma="Vauquer"></w> <w span="word_29" msd="PCTFAIB" lemma=","></w> <w span="word_30" msd="VPARPFS" lemma="naître"></w> <w span="word_31" msd="PREP" lemma="de"></w> <w span="word_32" msd="INC" lemma="Conflans"></w> <w span="word_33" msd="PCTFAIB" lemma=","></w> <w span="word_34" msd="VINDP3S" lemma="être"></w> texte_segmenté morpho-syntaxe texte_balisé_tei entités_nommées référence texte_balisé_tei entités_nommées référence

11
Du rêve à la réalité… Corpus : Le Père Goriot (chap. I) texte_brut
morpho-syntaxe <root label="UTT" idref="nt_1_6" /> <nt id="nt_1_0" cat="np"> <edge label="DN" href="tt.xml#xptr(id(msd_4))"/> <edge label="H" href="tt.xml#xptr(id(msd_5))"/> </nt> <nt id="nt_1_1" cat="pp"> <edge label="H" href="tt.xml#xptr(id(msd_3))"/> <edge label="DP" idref="nt_1_0" /> </nt>… </root> texte_segmenté morpho-syntaxe syntaxe texte_balisé_tei entités_nommées référence texte_balisé_tei entités_nommées référence
) /> <edge label= H href= tt.xml#xptr(id(msd_5)) /> </nt> <nt id= nt_1_1 cat= pp > <edge label= H href= tt.xml#xptr(id(msd_3)) /> <edge label= DP idref= nt_1_0 /> </nt>… </root> texte_segmenté. morpho-syntaxe. syntaxe. texte_balisé_tei. entités_nommées. référence. texte_balisé_tei. entités_nommées. référence.")
12
Concepts fondamentaux
Corpus : Le Père Goriot (chap. I) texte_brut morpho-syntaxe texte_segmenté morpho-syntaxe texte_balisé_tei entités_nommées référence syntaxe texte_balisé_tei entités_nommées référence
 texte_brut. morpho-syntaxe. texte_segmenté. morpho-syntaxe. texte_balisé_tei. entités_nommées. référence. syntaxe. texte_balisé_tei. entités_nommées. référence.")
13
Concepts fondamentaux
Corpus : Le Père Goriot (chap. I) texte_brut morpho-syntaxe texte_segmenté morpho-syntaxe texte_balisé_tei entités_nommées référence syntaxe texte_balisé_tei entités_nommées référence
 texte_brut. morpho-syntaxe. texte_segmenté. morpho-syntaxe. texte_balisé_tei. entités_nommées. référence. syntaxe. texte_balisé_tei. entités_nommées. référence.")
14
Concepts fondamentaux
Corpus : Le Père Goriot (chap. I) texte_brut morpho-syntaxe texte_segmenté morpho-syntaxe texte_balisé_tei entités_nommées référence syntaxe texte_balisé_tei entités_nommées référence
 texte_brut. morpho-syntaxe. texte_segmenté. morpho-syntaxe. texte_balisé_tei. entités_nommées. référence. syntaxe. texte_balisé_tei. entités_nommées. référence.")
15
Concepts fondamentaux
« Couverture linguistique » conditions de production & contenu linéaire « Je sais que le langage courant est plein de pièges. » => S. de Beauvoir, 1976; M. Yaguello, 1978; TALN 2004 « Corpus » collection de données caractérisée par une même couverture linguistique Goriot, chap. I Le Monde 09/1986 articles sportifs du Monde 09/1986 corpus contingent vs. intentionnel (Sinclair 1996, Habert et al 1997, Véronis 2000) « Ressource » unité physique de dépôt de données relatives à un corpus Goriot scanné (image) Goriot texte brut (Word) Goriot étiqueté + arboré (XML Tiger) Corpus contingent (décalage entre compilateur et utilisateur) vs. intentionnel => méta-données : compilateur (celui qui compile le corpus)
 « Ressource » unité physique de dépôt de données relatives à un corpus. Goriot scanné (image) Goriot texte brut (Word) Goriot étiqueté + arboré (XML Tiger) Corpus contingent (décalage entre compilateur et utilisateur) vs. intentionnel. => méta-données : compilateur (celui qui compile le corpus)")
16
Concepts fondamentaux
« Niveau de description » ensemble cohérent d’informations explicitées relatif à un corpus fichier audio, texte brut, texte formaté, texte balisé TEI, texte segmenté, morpho-syntaxe, syntaxe, référence, discours analyse humaine ou traitement automatique instancié par un schéma d’annotation (Ide & Romary, 2001) données primaires et secondaires considération pratique : reconstitution de la couverture continuum théorique (texte balisé TEI ?) « Méta-données » identification et gestion des données articulation des notions, pas à plat… caractérisation des notions dans un base (méta-données) .
 données primaires et secondaires. considération pratique : reconstitution de la couverture. continuum théorique (texte balisé TEI ) « Méta-données » identification et gestion des données. articulation des notions, pas à plat… caractérisation des notions dans un base (méta-données) .")
17
Organisation linguistique
Couverture Caractérisations supplémentaires … Corpus Niveau de description 1..1 0..n est composé de dépend de 0..n 0..1 Laurent : animation : corpus niv. de description ressource (efface description) synthèse méta-donnée corpus : cf. TEI 1. couverture linguistique (dépendant du type de corpus) 2. descripteur additionnel (size, genre, ressource ID dépôt, … - lien direct entre corpus et niveau d’annotation ? cardinalités Res-Niv ? 0..n , puisqu’on peut avoir des ressources sans niveaux d’annotation veut dire que les méta-données Res doivent couvrir entièrement celles qu’on souhaite attacher à une ressource « primaire » est-ce que ça peut poser prb pour des codages élémentaires tels que TEI, time stamps etc (que Laurent ne considère pas comme des annotations) ? cardinalité Niv-Niv ? 0..n si 1 niveau peut dépendre de plusieurs niveaux, 0..1 sinon localisation des méta-données : format de codage (Word, XML, SGML, …) au niveau de la ressource ou des niveaux ? - conditions de recueil au niveau de la ressource ou des niveaux ? schéma d’annotation/catégorie de données : pointeur sur norme ? DTD ? DCS ? ou attacher les méta-données sur l’évaluation et la révision ? fait non explicité pour l’instant : plusieurs annotateurs d’un même niveau de description linguistique => si ça revient à avoir plusieurs ressources (nécessairement ???), pas de pb, mais sinon, on est mal… Notion de « primaire / secondaire » : attaché à la ressource (pour le dépôt) Attaché au niv de description : dépendance conceptuelle Aux deux ??? Pas de parallélisme : cf. TIGER (uniquement dépendance conceptuelle) Cf. RAF : si markables séparés des liens… Typologie informationnelle Source Schéma d’annotation Évaluation
 synthèse. méta-donnée. corpus : cf. TEI. 1. couverture linguistique (dépendant du type de corpus) 2. descripteur additionnel (size, genre, ressource. ID dépôt, … lien direct entre corpus et niveau d’annotation cardinalités Res-Niv 0..n , puisqu’on peut avoir des ressources sans niveaux d’annotation. veut dire que les méta-données Res doivent couvrir entièrement celles qu’on souhaite attacher à une ressource « primaire » est-ce que ça peut poser prb pour des codages élémentaires tels que TEI, time stamps etc (que Laurent ne considère pas comme des annotations) cardinalité Niv-Niv 0..n si 1 niveau peut dépendre de plusieurs niveaux, 0..1 sinon. localisation des méta-données : format de codage (Word, XML, SGML, …) au niveau de la ressource ou des niveaux - conditions de recueil au niveau de la ressource ou des niveaux schéma d’annotation/catégorie de données : pointeur sur norme DTD DCS ou attacher les méta-données sur l’évaluation et la révision fait non explicité pour l’instant : plusieurs annotateurs d’un même niveau de description linguistique. => si ça revient à avoir plusieurs ressources (nécessairement ), pas de pb, mais sinon, on est mal… Notion de « primaire / secondaire » : attaché à la ressource (pour le dépôt) Attaché au niv de description : dépendance conceptuelle. Aux deux Pas de parallélisme : cf. TIGER (uniquement dépendance conceptuelle) Cf. RAF : si markables séparés des liens… Typologie informationnelle. Source. Schéma d’annotation. Évaluation.")
18
Organisation opérationnelle
Couverture Caractérisations supplémentaires … Corpus 1..1 0..n est composé de Ressource dépend de 0..n 0..1 Typologie informationnelle Source Schéma d’annotation Évaluation Niveau de description 1..1 est composé de 1..1 1..n est composé de Laurent : animation : corpus niv. de description ressource (efface description) synthèse méta-donnée corpus : cf. TEI 1. couverture linguistique (dépendant du type de corpus) 2. descripteur additionnel (size, genre, ressource ID dépôt, … - lien direct entre corpus et niveau d’annotation ? cardinalités Res-Niv ? 0..n , puisqu’on peut avoir des ressources sans niveaux d’annotation veut dire que les méta-données Res doivent couvrir entièrement celles qu’on souhaite attacher à une ressource « primaire » est-ce que ça peut poser prb pour des codages élémentaires tels que TEI, time stamps etc (que Laurent ne considère pas comme des annotations) ? cardinalité Niv-Niv ? 0..n si 1 niveau peut dépendre de plusieurs niveaux, 0..1 sinon localisation des méta-données : format de codage (Word, XML, SGML, …) au niveau de la ressource ou des niveaux ? - conditions de recueil au niveau de la ressource ou des niveaux ? schéma d’annotation/catégorie de données : pointeur sur norme ? DTD ? DCS ? ou attacher les méta-données sur l’évaluation et la révision ? fait non explicité pour l’instant : plusieurs annotateurs d’un même niveau de description linguistique => si ça revient à avoir plusieurs ressources (nécessairement ???), pas de pb, mais sinon, on est mal… Notion de « primaire / secondaire » : attaché à la ressource (pour le dépôt) Attaché au niv de description : dépendance conceptuelle Aux deux ??? Pas de parallélisme : cf. TIGER (uniquement dépendance conceptuelle) Cf. RAF : si markables séparés des liens… Dépositaire Date de dépôt
 synthèse. méta-donnée. corpus : cf. TEI. 1. couverture linguistique (dépendant du type de corpus) 2. descripteur additionnel (size, genre, ressource. ID dépôt, … lien direct entre corpus et niveau d’annotation cardinalités Res-Niv 0..n , puisqu’on peut avoir des ressources sans niveaux d’annotation. veut dire que les méta-données Res doivent couvrir entièrement celles qu’on souhaite attacher à une ressource « primaire » est-ce que ça peut poser prb pour des codages élémentaires tels que TEI, time stamps etc (que Laurent ne considère pas comme des annotations) cardinalité Niv-Niv 0..n si 1 niveau peut dépendre de plusieurs niveaux, 0..1 sinon. localisation des méta-données : format de codage (Word, XML, SGML, …) au niveau de la ressource ou des niveaux - conditions de recueil au niveau de la ressource ou des niveaux schéma d’annotation/catégorie de données : pointeur sur norme DTD DCS ou attacher les méta-données sur l’évaluation et la révision fait non explicité pour l’instant : plusieurs annotateurs d’un même niveau de description linguistique. => si ça revient à avoir plusieurs ressources (nécessairement ), pas de pb, mais sinon, on est mal… Notion de « primaire / secondaire » : attaché à la ressource (pour le dépôt) Attaché au niv de description : dépendance conceptuelle. Aux deux Pas de parallélisme : cf. TIGER (uniquement dépendance conceptuelle) Cf. RAF : si markables séparés des liens… Dépositaire. Date de dépôt.")
19
Méta-données Complémentarité des initiatives internationales
Dublin Core, OLAC, IMDI, TEI convergence sur les descripteurs du TC 37 de l’ISO répertoire de catégories de données : rôles, codes de langue… Méta-données utiles pour la FReeBank pertinence vis-à-vis de corpus, ressource et niveau de description prévoir des méta-données plus fines à terme documentation des étiquettes morpho-syntaxiques caractérisation de données « primaires » / « secondaires » Méta-données codées sous forme d’en-têtes TEI dissémination de bonnes pratiques pour la représentation et la transcription diffusion au format OLAC et IMDI moissonnage de la FReeBank par les portails correspondants

20
Exemple « types de discours »
Classification stable dans OLAC drama, formulaic discourse, interactive discourse, language play, oratory, narrative, procedural discourse, singing, unintelligible speech Caractérise la composante « niveau de description » utilisation de <textClass>/<classCode> dans l’en-tête TEI A définir… opérationnalité de la classification percolation vers la composante « corpus » ?

21
Exemple « rôles » Ensemble complexe de rôles dans OLAC
caractérisation des agents intervenant dans la création, gestion et distribution de données linguistiques Distribution vis-à-vis de l’architecture de la FReeBank Corpus Depositor Ressource Depositor, Compiler, Editor, Researcher, Sponsor Niveau de description [Gestion de l’annotation] Editor, Researcher, Annotator, Data inputter, Developer, Sponsor [Contenu informationnel] Author, Translator, Interpreter, Interviewer, Responder, Participant, Performer, Signer, Recorder, Research participant, Singer, Speaker

22
Contenu : amorce Corpus libres de droits État actuel (cf. papier)
Asila (corpus de dialogue) Ananas (corpus annotés en anaphores) GDR Sémantique, L’Arboratoire, Text®, ABU toute contribution est la bienvenue ! État actuel (cf. papier) Genre Taille TEI Seg. Brill Cord. TreeT Synt. GN Coref littérature 100 k () presse science administratif 70 k oral
 Ananas (corpus annotés en anaphores) GDR Sémantique, L’Arboratoire, Text®, ABU. toute contribution est la bienvenue ! État actuel (cf. papier) Genre. Taille. TEI. Seg. Brill. Cord. TreeT. Synt. GN. Coref. littérature. 100 k. () presse. science. administratif. 70 k. oral.")
23
Annotation syntaxique (Arboratoire)
FrAG (French Annotation Grammar, E. Bick)
")
24
Annotation référentielle (Ananas)
Analyse syntaxique étiquetage TreeTagger & constituants + dépendances (VISL) structure arborescente correction manuelle partielle Normalisation format Negra-TIGER + stand-off Extraction GNs TIGER-Search XSL Annotation référentielle filtrage semi-manuel des GN référentiels annotation manuelle (double annotation + évaluation accord)
 structure arborescente. correction manuelle partielle. Normalisation. format Negra-TIGER + stand-off. Extraction GNs. TIGER-Search. XSL. Annotation référentielle. filtrage semi-manuel des GN référentiels. annotation manuelle (double annotation + évaluation accord)")
25
Granularité, versions, corrections
Niveau de description « Jardin à la française » « Jardin botanique » « Forêt vierge » structure (TEI) oui ? étiquetage partiellement non syntaxe référence Nouveau dépôt ressource + niveaux de description méta-données (catégories de données, évaluation, annotateur) extraction de GN => catégorisation entités nommées sur-spécification étiquettes morpho-syntaxiques correction manuelle des dépendances syntaxiques
 oui. étiquetage. partiellement. non. syntaxe. référence. Nouveau dépôt. ressource + niveaux de description. méta-données (catégories de données, évaluation, annotateur) extraction de GN => catégorisation entités nommées. sur-spécification étiquettes morpho-syntaxiques. correction manuelle des dépendances syntaxiques.")
26
Bilan & Perspectives Base évolutive, cohérente et générique
analyse des pratiques linguistiques et des besoins TALN abstraction, modélisation, implémentation suivi des initiatives internationales Outils & Interface outils de restitution visuelle des corpus évaluation de l’accord entre plusieurs annotations statistiques accès & téléchargement gestion des versions Ouverture à d’autres types de ressources lexiques morphologiques, syntaxiques, sémantiques

27
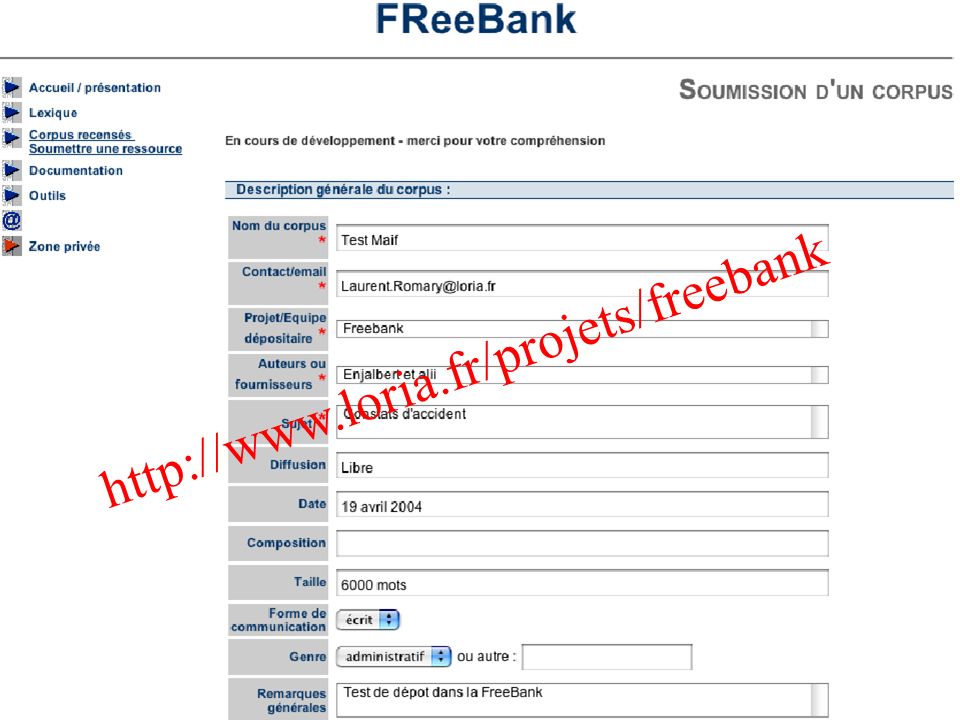
Et en plus, ça existe vraiment…
Présentations similaires


 gestion du référentiel de modélisation.>")








>")



 I N I S T C N R S UPS76>")



