Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
L ’ANALYSE MULTIDIMENSIONNELLE DES DONNEES
Méthodes analytiques d’étude des tableaux de données de grande taille

2
L ’analyse en composantes principales (ACP)
L ’analyse factorielle des correspondances (AFC) L ’analyse des correspondances multiples (ACM) Les analyses typologiques Suivant la nature des variables traitées nous utiliserons l’une des méthodes ci-dessus Les trois premières sont des méthodes de description de phénomène complexe La dernière est une méthode de création de groupe homogène d’individus ou de variables Mais toutes ses méthodes quelques soient leurs finalités sont fondées sur le même principe De plus ces méthodes permettent le traitement de tableau de grande taille On définit un tableau de grande taille comme un tableau décrivant beaucoup d’individu (ligne) par le biais de beaucoup de variable (colonnes) Tirer des conclusions pertinentes à partir d’un tableau 5 lignes 2 colonnes est un exercice relativement simple. Mais lorsque le tableau fait 100 lignes et 20 colonnes cela devient plus complexes. Les méthodes d’analyses factorielles, visesnt à permettre une représentation plus accessible de la structure des données en ne retenant que l’essentiel de l’information.
 L ’analyse des correspondances multiples (ACM) Les analyses typologiques. Suivant la nature des variables traitées nous utiliserons l’une des méthodes ci-dessus. Les trois premières sont des méthodes de description de phénomène complexe. La dernière est une méthode de création de groupe homogène d’individus ou de variables. Mais toutes ses méthodes quelques soient leurs finalités sont fondées sur le même principe. De plus ces méthodes permettent le traitement de tableau de grande taille. On définit un tableau de grande taille comme un tableau décrivant beaucoup d’individu (ligne) par le biais de beaucoup de variable (colonnes) Tirer des conclusions pertinentes à partir d’un tableau 5 lignes 2 colonnes est un exercice relativement simple. Mais lorsque le tableau fait 100 lignes et 20 colonnes cela devient plus complexes. Les méthodes d’analyses factorielles, visesnt à permettre une représentation plus accessible de la structure des données en ne retenant que l’essentiel de l’information.")
3
L ’analyse en composantes principales (ACP)
Objectifs Nature des données Objectifs : Extraire l’essentiel de l’information contenu dans un tableau de grande taille Fournir une représentation imagée (graphique) se prêtant plus facilement à l’interprétation Etudier le tableau des données du point de vue de la ressemblance entre les individus ou des liaisons entre variables Nature des données: Tableau à n lignes (individus) et p colonnes (variables). Toutes les variables doivent être métriques. Le tableau doit être homogènes dans sa forme afin d’éviter l’effet unité (mètre vs km vs mm). On peut centrer réduire toutes les données (moyenne de chaque variable ramenée à zéro par simple soustraction tandis que l’écart type est rapporté à une unité en divisant la variance initiale). Mais pas besoin avec SPSS il le fait automatiquement.
 se prêtant plus facilement à l’interprétation. Etudier le tableau des données du point de vue de la ressemblance entre les individus ou des liaisons entre variables. Nature des données: Tableau à n lignes (individus) et p colonnes (variables). Toutes les variables doivent être métriques. Le tableau doit être homogènes dans sa forme afin d’éviter l’effet unité (mètre vs km vs mm). On peut centrer réduire toutes les données (moyenne de chaque variable ramenée à zéro par simple soustraction tandis que l’écart type est rapporté à une unité en divisant la variance initiale). Mais pas besoin avec SPSS il le fait automatiquement.")
4
L ’analyse en composantes principales (ACP)
G On peut identifier l’information (la différence entre les individus) comme la distance qui les sépare L’information totale du phénomène peut être représentée par l’inertie du nuage de point
 comme la distance qui les sépare. L’information totale du phénomène peut être représentée par l’inertie du nuage de point.")
5
L ’analyse en composantes principales (ACP)
A B 2 1 y2b y2a y1b y1a d2(A,B) = (y1a-y1b)2 + (y2a-y2b)2
 = (y1a-y1b)2 + (y2a-y2b)2.")
6
L ’analyse en composantes principales (ACP)
A B 2 1 y2b y2a y1b y1a a b y1’a y1’b 1’ d(A,B) = d(a,b) d(a,b) = y1’b – y1’a En utilisant la technique de la rotation projection On passe de deux axes à un seul et on explique (dans notre cas) la même choses Géométriquement un principe veut qu’une distance lors d’une projection ne peut que diminuer On va dons perdre un peu d’information pour gagner en simplicité Ce principe peut être généralisé à n dimension
 = d(a,b) d(a,b) = y1’b – y1’a. En utilisant la technique de la rotation projection. On passe de deux axes à un seul et on explique (dans notre cas) la même choses. Géométriquement un principe veut qu’une distance lors d’une projection ne peut que diminuer. On va dons perdre un peu d’information pour gagner en simplicité. Ce principe peut être généralisé à n dimension.")
9
L ’analyse factorielle des correspondances (AFC)
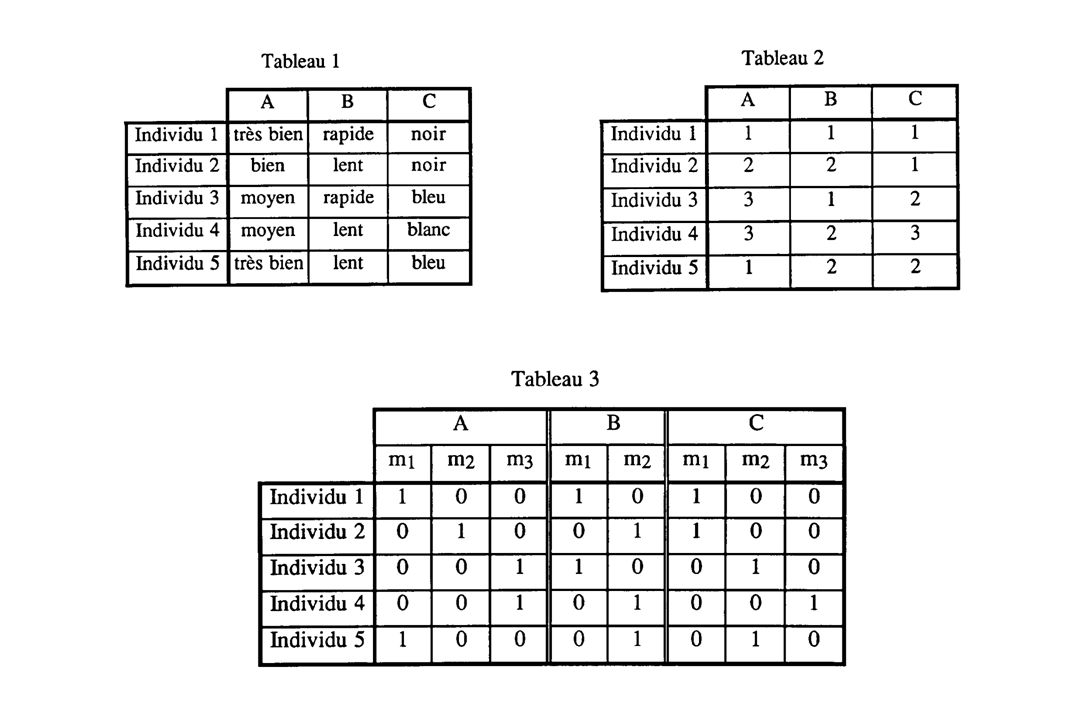
Objectifs Nature des données Objectifs: Extraire l’essentiel de l’information contenu dans un tableau de grande taille Fournir une représentation imagée (graphique) se prêtant plus facilement à l’interprétation L’AFC cherche à représenter, à l’aide d’axes communs, les nuages des individus et des variables d’une manière simplifiée. Travaillant sur les deux nuages en même temps, l’AFC permet de situer les individus et les variables dans un même espace par rapport aux même axes. Il devient donc facile d’établir les relations de proximité, non seulement entre variables d’une part ou entre individus d’autre part, mais aussi et surtout entre les deux. Nature des données: Tableau à n lignes (individus) et 2 colonnes (variables) représenté sous la forme d’un tableau de contingence ou d’un tableau disjonctif Toutes les variables doivent être qualitative.
 se prêtant plus facilement à l’interprétation. L’AFC cherche à représenter, à l’aide d’axes communs, les nuages des individus et des variables d’une manière simplifiée. Travaillant sur les deux nuages en même temps, l’AFC permet de situer les individus et les variables dans un même espace par rapport aux même axes. Il devient donc facile d’établir les relations de proximité, non seulement entre variables d’une part ou entre individus d’autre part, mais aussi et surtout entre les deux. Nature des données: Tableau à n lignes (individus) et 2 colonnes (variables) représenté sous la forme d’un tableau de contingence ou d’un tableau disjonctif. Toutes les variables doivent être qualitative.")
10
Tableau de contingence

11
Tableau disjonctif complet

12
Dimension 2 Dimension 1 1,0 ,5 0,0 -,5 -1,0 -1,5 -2,0 2 1 -1 -2 -3
-1 -2 -3 Amérique Latine Moyen Orient Afrique Pacifique/Asie Europe de l'Est OCDE Tribal Taoïste Protest. Othodoxe Musulman Juif Hindou Catho. Bouddh. Animiste

13
L ’analyse des correspondances multiples (ACM)
Objectifs Nature des données Objectifs: Extraire l’essentiel de l’information contenu dans un tableau de grande taille Fournir une représentation imagée (graphique) se prêtant plus facilement à l’interprétation On parle de généralisation de l’AFC ou d’ACP sur variables qualitatives Nature des données: Tableau à n lignes (individus) et p colonnes (variables). Toutes les variables doivent être qualitatives.
 se prêtant plus facilement à l’interprétation. On parle de généralisation de l’AFC ou d’ACP sur variables qualitatives. Nature des données: Tableau à n lignes (individus) et p colonnes (variables). Toutes les variables doivent être qualitatives.")
15
Quantifications Dimension 2 Dimension 1 2,0 1,5 1,0 ,5 0,0 -,5 -1,0
-1,5 Dimension 2 -2,0 Tendance politique Est-ce ce que la mar ijuana doit être lég Pour ou contre la pe ine de mort ? Sexe du répondant Activité professionn elle Conservateur Plutôt Conservateur Modérée plutôt Libérale Libérale Non Oui Contre Pour Femme Homme Autre Au foyer Etudiant Retraité Sans emploi Travail temporaire Travail à temps partiel Travail à temps complet

16
Les analyses typologiques
Objectifs Nature des données Etant donné "n" observations, comment puis-je les regrouper en un certain nombre de groupes (disons k) de façon à ce que les groupes obtenus soient constitués d'observations semblables et que les groupes soient le plus différents possible entre eux. C'est la réponse à cette question que veulent fournir les méthodes de classification automatique. La diversité des méthodes en classification automatique est déconcertante au premier abord. Des volumes entiers ont étés publiés sur le sujet. Nous nous bornerons ici à énoncer les grands principes qui sous-tendent toutes ces méthodes. Il est important de bien cerner ce qui distingue la classification automatique des analyses factorielles. Dans l'AF, les groupes sont connus à priori. En classification automatique, il n'y a pas de groupes à priori. La méthode cherche dans le nuage de points les zones denses qui formeront des groupes qu'il restera à interpréter par la suite en utilisant par exemple les AF. La classification procède séquentiellement en regroupant les observations les plus `semblables' en premier lieu (méthodes hiérarchiques) ou bien elle regroupe en k groupes toutes les observations simultanément (méthodes non-hiérarchiques).
 de façon à ce que les groupes obtenus soient constitués d observations semblables et que les groupes soient le plus différents possible entre eux. C est la réponse à cette question que veulent fournir les méthodes de classification automatique. La diversité des méthodes en classification automatique est déconcertante au premier abord. Des volumes entiers ont étés publiés sur le sujet. Nous nous bornerons ici à énoncer les grands principes qui sous-tendent toutes ces méthodes. Il est important de bien cerner ce qui distingue la classification automatique des analyses factorielles. Dans l AF, les groupes sont connus à priori. En classification automatique, il n y a pas de groupes à priori. La méthode cherche dans le nuage de points les zones denses qui formeront des groupes qu il restera à interpréter par la suite en utilisant par exemple les AF. La classification procède séquentiellement en regroupant les observations les plus `semblables en premier lieu (méthodes hiérarchiques) ou bien elle regroupe en k groupes toutes les observations simultanément (méthodes non-hiérarchiques).")
17
Méthodes hiérarchiques
L'algorithme de base est le suivant : 1. a-t-on plus d'un groupe (si non, on termine) 2. calculer les `ressemblances' entre toutes les paires de groupes. 3. fusionner les deux groupes montrant la plus grande ressemblance (similarité) ou la plus faible dissemblance (dissimilarité). Historiquement, elles furent les premières développées, principalement en raison de la simplicité des calculs. elles demeurent d'utilisation courante en raison de leur capacité d'organiser les ressemblances suivant une hiérarchie, ce qui est le principe de classification habituel lorsqu'on parle d'espèces animales ou végétales.
 2. calculer les `ressemblances entre toutes les paires de groupes. 3. fusionner les deux groupes montrant la plus grande ressemblance (similarité) ou la plus faible dissemblance (dissimilarité). Historiquement, elles furent les premières développées, principalement en raison de la simplicité des calculs. elles demeurent d utilisation courante en raison de leur capacité d organiser les ressemblances suivant une hiérarchie, ce qui est le principe de classification habituel lorsqu on parle d espèces animales ou végétales.")
18
Technique du plus proche voisin
Technique du voisin le plus éloigné

19
Méthodes non-hiérarchiques
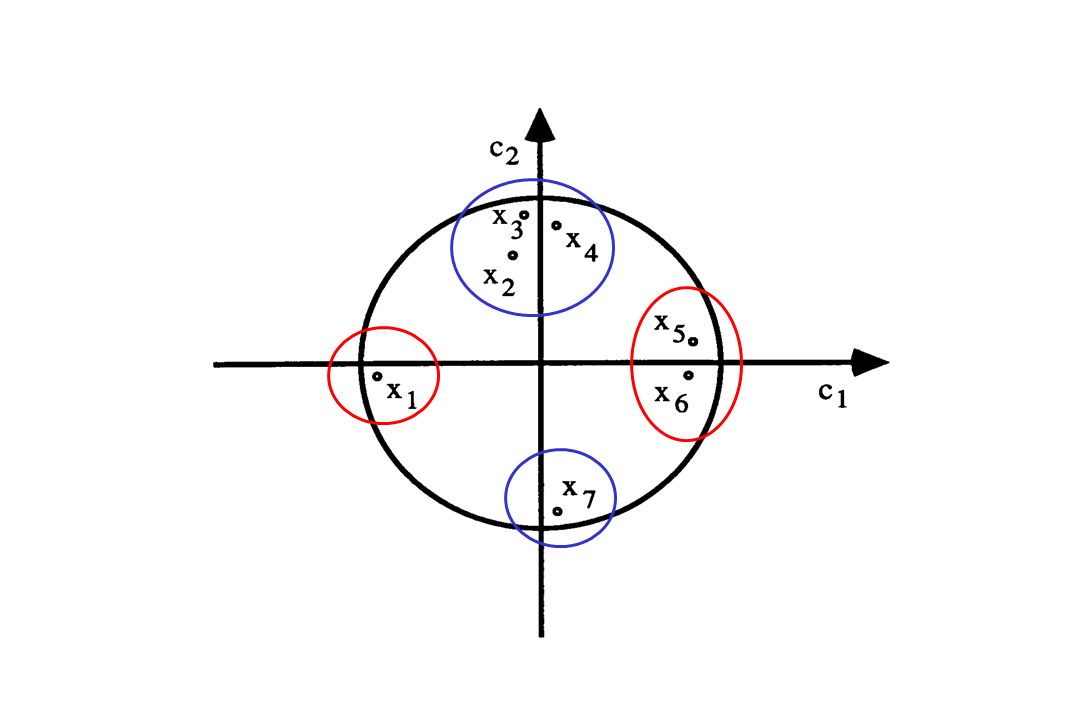
Initialisation 1 on choisit aléatoirement k (à préciser) groupes d'observations avec un nombre donné d'observations dans chaque groupe (disons n/k). Itération 2 on calcule le vecteur moyenne (centre) des k groupes. 3 on calcule pour chaque observation la distance au centre de chaque groupe et on calcule le critère de dispersion présent. Si la dispersion décroît, on continue, sinon on arrête l’algorithme. 4. on affecte chaque observation au groupe dont elle est le plus près; on obtient ainsi k nouveaux groupes et on retourne à l’étape 2. Ces méthodes sont plus proches des méthodes factorielles. Leur essor est relié à la possibilité récente d'effectuer à très faible coût des montagnes de calculs. L'idée sous-jacente consiste à rechercher les zones denses du nuage d'observations.
 groupes d observations avec un nombre donné d observations dans chaque groupe (disons n/k). Itération. 2 on calcule le vecteur moyenne (centre) des k groupes. 3 on calcule pour chaque observation la distance au centre de chaque groupe et on calcule le critère de dispersion présent. Si la dispersion décroît, on continue, sinon on arrête l’algorithme. 4. on affecte chaque observation au groupe dont elle est le plus près; on obtient ainsi k nouveaux groupes et on retourne à l’étape 2. Ces méthodes sont plus proches des méthodes factorielles. Leur essor est relié à la possibilité récente d effectuer à très faible coût des montagnes de calculs. L idée sous-jacente consiste à rechercher les zones denses du nuage d observations.")
20
2 groupes 3 groupes 5 groupes

Présentations similaires



>")


>")
>")












