Télécharger la présentation
1
La régression simple Michel Tenenhaus

2
2 La régression simple Étude de la liaison linéaire entre deux variables numériques : - une variable explicative X - une variable à expliquer Y

3
3 Étude du lien entre deux variables X et Y Variable Y à expliquer Variable X explicative

4
Cas Prix dun appartement

5
5

6
6 Identification des outliers au niveau du Prix au mètre carré 28N = Prix du mètre carré 9000 8000 7000 6000 5000 4000 3000 2000 Jardins de l'observatoire Panthéon (10) Ile saint-louis
 Ile saint-louis")
7
7 La droite des moindres carrés

8
8 Les données z Y = Variable à expliquer numérique (ou dépendante) z X = Variable explicative numérique ou binaire (ou indépendante) Le tableau des données XY 1x 1 y 1 ix i y i nx n y n
 z X = Variable explicative numérique ou binaire (ou indépendante) Le tableau des données XY 1x 1 y 1 ix i y i nx n y n")
9
9 La droite des moindres carrés xixi yiyi erreur e i * On cherche minimisant valeur observée valeur prédite

10
10 Résultats SPSS

11
Pour le modèle avec constante on a aussi : Modèle : Prix calculé = -29.466 + 5.353 Surface

12
12 Coefficient de détermination R 2, Coefficient de corrélation R A) Formule de décomposition Somme des carrés totale (Total Sum of Squares) Somme des carrés expliquée (Regression Sum of Squares) Somme des carrés résiduelle (Residual Sum of Squares) B) R 2 = C) R = signe( )
 Formule de décomposition Somme des carrés totale (Total Sum of Squares) Somme des carrés expliquée (Regression Sum of Squares) Somme des carrés résiduelle (Residual Sum of Squares) B) R 2 = C) R = signe( )")
13
13 Résultats SPSS |R| R

14
14 Le R 2 mesure la force de la liaison linéaire entre X et Y 1)0 R 2 1 2) R 2 = 1 Y X * * * * * * * 3) R 2 = 0 Y X * * * * * * * * * *
0 R 2 1 2) R 2 = 1 Y X * * * * * * * 3) R 2 = 0 Y X * * * * * * * * * *")
15
15 Le R 2 mesure la force de la liaison linéaire entre X et Y Modèle non linéaire: Y = aX 2 + bX

16
16 La corrélation R mesure la force et le sens de la liaison linéaire entre X et Y ** * * * * * * * * X Y X Y * * * *

17
17 Calcul direct de R Résultat SPSS : Karl Pearson

18
18 La corrélation R est-elle significative au risque = 0.05 ? zNotations - = Corrélation au niveau de la population - R = Corrélation au niveau de léchantillon zTest : H 0 : = 0 H 1 : 0 z Règle de décision On rejette H 0 au risque = 0.05 de se tromper si (Bonne approximation pour n > 20)
.")
19
19 La corrélation R est-elle significative au risque ? zNotations - = Corrélation au niveau de la population - R = Corrélation au niveau de léchantillon zTest : H 0 : = 0 H 1 : 0 z Règle de décision On rejette H 0 au risque de se tromper si z Niveau de signification Plus petit conduisant au rejet de H 0.

20
Table 6

21
21 Exemple de corrélation non significative En rouge la droite des moindres carrés, en bleu la droite y = prix au m 2 moyen On a 30,9 chances sur 100 de se tromper en affirmant quil existe une liaison linéaire entre le prix au m 2 et la surface. On considère donc que la corrélation (.199) entre le prix au m 2 et la surface nest pas significative.
 entre le prix au m 2 et la surface nest pas significative..")
22
22 Le modèle statistique de la régression simple zChaque valeur observée y i est considérée comme une réalisation dune variable aléatoire Y i définie par : Y i = ax i + b + i où i est un terme aléatoire suivant une loi normale N(0, ). zOn suppose que les les aléas i sont indépendants les uns des autres.

23
23 Le modèle de la régression simple Modèle : Y = aX + b +, avec N(0, ) X Y y = ax + b x x = ax+b x + 1.96 x - 1.96 95% des valeurs de Y Loi de Y * * Lécart-type représente à peu près le quart de lépaisseur du nuage
 X Y y = ax + b x x = ax+b x x % des valeurs de Y Loi de Y * * Lécart-type représente à peu près le quart de lépaisseur du nuage")
24
24 Estimation de a, b et zEstimation de a et b : zEstimation de :

25
25 Prévision de Y zModèle : Y = aX + b +, avec N(0, ) x = E(Y | X = x) = ax + b zProblème 1 : Calculer une estimation et un intervalle de confiance au niveau de confiance 95 % de la moyenne x de Y lorsque X est fixé à x. zSoit y une future valeur de Y pour X fixé à x. zProblème 2 : Calculer une prévision et un intervalle contenant 95 % des futures valeurs de Y lorsque X est fixé à x.

26
26 Résultat pour x zEstimation de x = E(Y | X=x) : zIntervalle de confiance de x au niveau 95 % : Formule approchée :
 : zIntervalle de confiance de x au niveau 95 % : Formule approchée :")
27
27 Résultats SPSS Surface moyenne = 82.32 Variance de la surface = 3266.3

28
28 Résultat graphique pour les intervalles de confiance Prix vs Surface (28 obs.) : Intervalle de confiance à 95%
 : Intervalle de confiance à 95%")
29
29 Intervalle de confiance de la moyenne x = ax + b pour une liaison non significative La droite y = appartient à la zone de confiance des Y moyens. Donc la liaison entre Y et X nest pas significative.

30
30 Résultat pour y zPrévision de y pour x fixé : zIntervalle de prévision de y à 95 % pour x fixé : Formule approchée :

31
31 Surface 3002001000 Prix (en milliers dEuros) 1600 1400 1200 1000 800 600 400 200 0 Jardins de lObservatoire Ile Saint-louis Observations atypiques Résultat graphique pour les intervalles de prévision Intervalle de prévision individuelle à 95%
 Jardins de lObservatoire Ile Saint-louis Observations atypiques Résultat graphique pour les intervalles de prévision Intervalle de prévision individuelle à 95%")
32
32 Observation atypique zUne observation est atypique (outlier) si elle nappartient pas à son propre intervalle de prévision : zEn utilisant la formule approchée : zConclusion : Une observation i est un outlier si son résidu standardisé est supérieur à 2 en valeur absolue.
 si elle nappartient pas à son propre intervalle de prévision : zEn utilisant la formule approchée : zConclusion : Une observation i est un outlier si son résidu standardisé est supérieur à 2 en valeur absolue.")
33
Résultats SPSS

34
34 Élimination des observations atypiques zPour rendre la prévision plus opérationnelle, on peut restreindre le champ dapplication du modèle en éliminant des observations atypiques, mais en le justifiant par des considérations extra-statistiques. zCompléter le tableau suivant jusquà élimination de toutes les données atypiques Nombre dobservations Corrélation R Écart-type du résidu Observations atypiques Intervalle de prévision à 95 % du prix dun 100 m 2 28 26

35
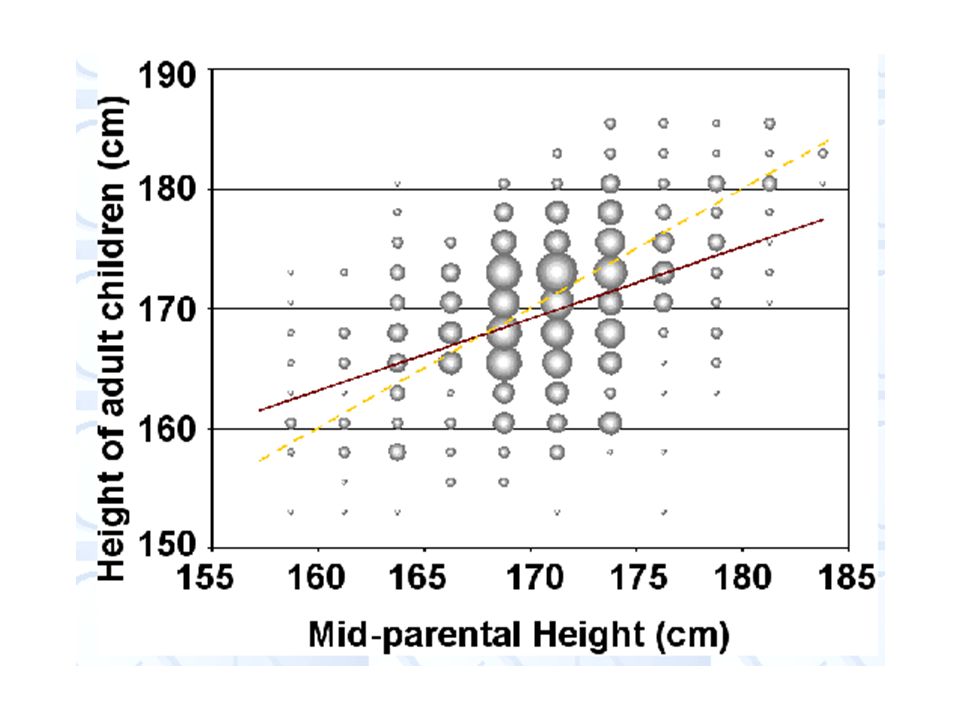
REGRESSION TO THE MEAN Regression to the mean was first identified by Sir Francis Galton: half-cousin of Charles Darwin, geographer, meteorologist, tropical explorer, founder of differential psychology, inventor of fingerprint identification, pioneer of statistical correlation and regression, convinced hereditarian, eugenicist, proto-geneticist, and best-selling author (1822-1911). He correlated the heights of 930 adult children and their respective 250 parents, "correcting" for sex by increasing female heights by a factor of 1.08.

37
He accounted for genetic contribution of both parents by taking their mean (corrected) heights. He plotted the data (see below) and performed a least squares straight line fit (red line), but found that its slope was less than that expected if the height of children was on average the same as that of their parents (yellow line). He observed: "It appeared from these experiments that the offspring did not tend to resemble their parents in size, but always to be more mediocre than they - to be smaller than than the parents, if the parents were large; - to be larger than than the parents, if the parents were small."
 and performed a least squares straight line fit (red line), but found that its slope was less than that expected if the height of children was on average the same as that of their parents (yellow line). He observed: It appeared from these experiments that the offspring did not tend to resemble their parents in size, but always to be more mediocre than they - to be smaller than than the parents, if the parents were large; - to be larger than than the parents, if the parents were small. .")


![[number 1-100].](/1/172887/big_thumb.jpg "[number 1-100].>")

 r =>")


.>")





 et dénombrer (Entoure dans la bande numérique.>")






