Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Analyse de la variance à effets mixtes
Michel Tenenhaus

2
Exemple 4 (Milliken & Johnson) Rythmes cardiaques
Rythme cardiaque pour trois groupes de traitements et quatre instants de mesure - Facteurs fixes : Traitement, Temps - Facteur aléatoire : Sujet(Traitement)
")
3
Extrait des données

4
Moyennes des rythmes cardiaques par produit et par instant

5
Les modèles Modèle 1 Yijk = + i + j + ij + sk(i) + ijk
Produit Temps * Sujet (Produit) Résidu Effets fixes Effets aléatoires avec : sk(i) ~ N(0, s2) s2 = Variance inter-sujets ijk ~ N(0, 2) 2 = Variance intra-sujets Les aléas sont indépendants. Les variances peuvent dépendre du traitement. La variance intra-sujets peut dépendre du traitement et du temps.
 Résidu. Effets fixes. Effets aléatoires. avec : - sk(i) ~ N(0, s2) s2 = Variance inter-sujets. - ijk ~ N(0, 2) 2 = Variance intra-sujets. Les aléas sont indépendants. Les variances peuvent. dépendre du traitement. La variance intra-sujets. peut dépendre du traitement et du temps.")
6
Modèle 2 Yijk = + i + j + ij + ijk avec :
Produit Temps * Résidu avec : i.k = (i1k, i2k, i3k, i4k ) ~ N(0, ) Les i.k sont indépendants entre eux. La matrice de covariance peut dépendre du traitement. L’utilisateur doit choisir le type de la matrice .
 ~ N(0, ) - Les i.k sont indépendants entre eux. La matrice de covariance peut dépendre du traitement. L’utilisateur doit choisir le type de la matrice .")
7
Quelques types de matrice

8
Quelques types de matrice (suite)
etc...

9
Modèle 3 Yijk = + i + j + ij + sk(i) + ijk avec :
Produit Temps Sujet (Produit) Résidu Produit * Temps avec : sk(i) ~ N(0, s2) ijk ~ AR(1) (*) (*) ijk = i(j-1)k + aijk , où les aijk suivent une loi N(0, a2) et sont indépendants entre eux.
 Résidu. Produit. * Temps. avec : - sk(i) ~ N(0, s2) - ijk ~ AR(1) (*) (*) ijk = i(j-1)k + aijk , où les aijk suivent une loi N(0, a2) et sont indépendants. entre eux.")
10
Étude du modèle 1 Yijk = + i + j + ij + sk(i) + ijk
Produit Temps * Sujet (Produit) Résidu avec : sk(i) ~ N(0, s2) ijk ~ N(0, 2) + indépendance Dans le modèle 1, les corrélations entre les mesures sont positives.
 Résidu. avec : - sk(i) ~ N(0, s2) - ijk ~ N(0, 2) + indépendance. Dans le modèle 1, les corrélations entre les mesures sont positives.")
11
Le modèle 1 est un modèle 2 avec de type « compound symmetry » et covariance positive
Yijk = + i j ij sk(i) ijk Produit Temps * Sujet (Produit) Résidu est de type « Compound Symmetry » avec covariance positive.
 + ijk. Produit. Temps. * Sujet. (Produit) Résidu. est de type « Compound Symmetry » avec covariance positive.")
12
Formulaire Modèle : Estimation : (Utiliser Method = REML)
y = X + Zu + avec : u ~ N(0, G), ~ N(0, R), et Cov(u, ) = 0 Il est préférable qu’un facteur aléatoire ait au moins 5 modalités. Sinon, passer en fixe. - Var(y) = V = ZGZ´ + R y ~ N(X, V) Estimation : (Utiliser Method = REML) 1) Les matrices G et R sont estimées par maximum de vraisemblance restreint.
, ~ N(0, R), et Cov(u, ) = 0. Il est préférable. qu’un facteur. aléatoire ait. au moins. 5 modalités. Sinon, passer en. fixe. - Var(y) = V = ZGZ´ + R. - y ~ N(X, V) Estimation : (Utiliser Method = REML) 1) Les matrices G et R sont estimées par maximum. de vraisemblance restreint.")
13
Formulaire (suite) Modèle : Test : Statistique utilisée :
y = X + Zu + avec : u ~ N(0, G), ~ N(0, R), et Cov(u, ) Test : H0 : K + Mu = 0 (Inférerence : Large / étroite) Statistique utilisée :
, ~ N(0, R), et Cov(u, ) Test : H0 : K + Mu = 0. (Inférerence : Large / étroite) Statistique utilisée :")
14
Calcul de par la méthode de Satterthwaite (Méthode par défaut de SPSS)
- Permet de retrouver les résultats du GLM pour le test d’un contraste. Le ddl du dénominateur ne dépend pas du nom de l’effet aléatoire. - Permet de généraliser l’approche de Satterthwaite aux modèles mixtes.

15
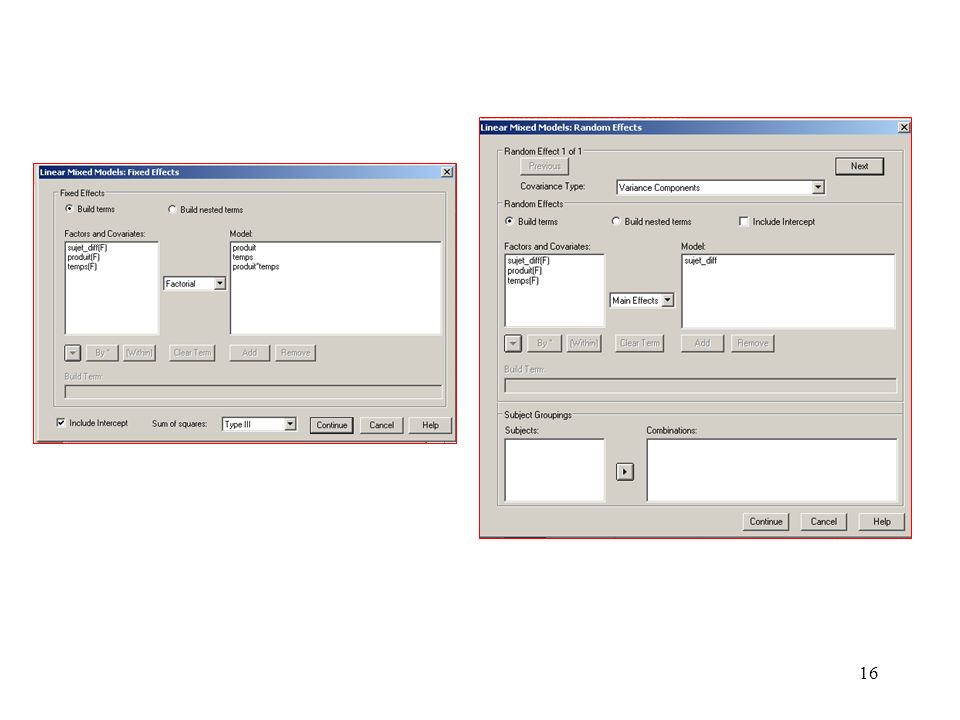
Etude du modèle 1 Yijk = + i + j + ij + sk(i) + ijk
Produit Temps * Sujet (Produit) Résidu Utilisation de SPSS
 Résidu. Utilisation de SPSS.")
17
Résultats Modèle 1

18
Résultats Modèle 1 (suite)
")
19
Résultats Modèle 1 (suite)
")
20
Résultats Modèle 1 (Proc Mixed de SAS)
Estimated V Matrix for sujet(produit) 1 1 Row Col Col Col Col4 Estimated V Correlation Matrix for sujet(produit) 1 1
 1 1. Row Col1 Col2 Col3 Col Estimated V Correlation Matrix. for sujet(produit)")
21
Résultats Modèle 1 (suite)
")
22
Résultats Modèle 1 (SAS)
Solution for Random Effects Std Err Effect sujet produit Estimate Pred DF t Value Pr > |t| sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) <.0001 sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) = 0 = 0 = 0
 sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) < sujet(produit) sujet(produit) sujet(produit) sujet(produit) sujet(produit) = 0. = 0. = 0.")
23
Résultats Modèle 1 (suite)
")
24
Comparaison des moyennes
Modèle : T T T T4 Estimation de 11 - 31 : Test : H0 :

25
Comparaison entre AX23 et Contrôle en T1
Syntaxe SPSS MIXED rythme BY sujet_diff produit temps /CRITERIA = CIN(95) MXITER(100) MXSTEP(5) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED = produit temps produit*temps | SSTYPE(3) /METHOD = REML /TEST = 'mu11 vs mu31' produit produit*temps /PRINT = SOLUTION TESTCOV /RANDOM sujet_diff | COVTYPE(VC) . Résultats
 MXITER(100) MXSTEP(5) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED = produit temps produit*temps | SSTYPE(3) /METHOD = REML. /TEST = mu11 vs mu31 produit produit*temps /PRINT = SOLUTION TESTCOV. /RANDOM sujet_diff | COVTYPE(VC) . Résultats.")
26
Comparaison de deux modèles imbriqués
Modèle M1 Modèle M0 : cas particulier de M1 Les paramètres de M0 ne sont pas sur leurs frontières de définition. Test LRT (Likelihood Ratio Test) : où = Nb de paramètres de M1 - Nb de paramètres de M0. Utiliser plutôt « Method = ML »
 : où = Nb de paramètres de M1 - Nb de paramètres de M0. Utiliser plutôt « Method = ML »")
27
Test d’un effet aléatoire
Test sur le modèle à un effet aléatoire : H0 : s2 = 0 Statistique utilisée : G2 = [-2Log L(Modèle sans effet)] - [-2Log L(Modèle à un effet)] Calcul du niveau de signification : NS = 0.5Prob(2(0) G2) Prob(2(1) G2) (2(0) = 0 avec la probabilité 1) La correction réduit le niveau de signification du test LRT usuel.
] - [-2Log L(Modèle à un effet)] Calcul du niveau de signification : NS = 0.5Prob(2(0) G2) + 0.5Prob(2(1) G2) (2(0) = 0 avec la probabilité 1) La correction réduit le niveau de signification du test LRT usuel.")
28
Application Avec effet sujet Sans effet sujet
G2 = [-2Log L(Modèle sans effet)] - [-2Log L(Modèle à un effet)] = – = NS = 0.5Prob(2(0) G2) Prob(2(1) G2) = 0.5*Prob(2(1) 80) = 0.000
] - [-2Log L(Modèle à un effet)] = – = NS = 0.5Prob(2(0) G2) + 0.5Prob(2(1) G2) = 0.5*Prob(2(1) 80) =")
29
Recherche d’une tendance polynomiale
On exprime le vecteur des moyennes en fonction de polynômes orthogonaux : Constante Linéaire Quadratique Q0, Q1, Q2, Q3 forment une base orthonormée. Cubique

30
Construction des contrastes orthogonaux
On exprime le vecteur des moyennes en fonction des polynômes orthogonaux : Contrastes orthogonaux : Tests : H0 : 1 = 2 = 3 = <==> H0 : 1 = 2 = 3 = 0 H0 : Tendance linéaire <==> H0 : 1 0, 2 = 3 = 0 H0 : Tendance quadratique <==> H0 : 2 0, 3 = 0

31
Recherche de tendances
- AX23 : Quadratique - BWW9 : Linéaire - Contrôle : Constante

32
Recherche de tendance quadratique pour AX23
Modèle : Tests :

33
Recherche de tendance quadratique pour AX23
Code SPSS : MIXED rythme BY sujet_diff produit temps /CRITERIA = CIN(95) MXITER(100) MXSTEP(5) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED = produit temps produit*temps | SSTYPE(3) /METHOD = REML /TEST = 'ax23,contraste qua.' temps produit*temps /TEST = 'ax23,contraste cub.' temps produit*temps /RANDOM sujet_diff | COVTYPE(VC) . Résultats : ==> Validation de la tendance quadratique
 MXITER(100) MXSTEP(5) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED = produit temps produit*temps | SSTYPE(3) /METHOD = REML. /TEST = ax23,contraste qua. temps produit*temps /TEST = ax23,contraste cub. temps produit*temps /RANDOM sujet_diff | COVTYPE(VC) . Résultats : ==> Validation de la tendance quadratique.")
34
Étude du modèle 2 Yijk = + i + j + ij + ijk
Produit Temps * Résidu avec des i.k = (i1k, i2k, i3k, i4k ) ~ N(0, ) ou N(0, i) et indépendants entre eux Il faut préciser le type de la matrice de covariance .
 ~ N(0, ) ou N(0, i) et indépendants entre eux. Il faut préciser le type de la matrice de covariance .")
35
de type UN (UNSTRUCTURED)
")
36
Résultats SPSS : de type « UNSTRUCTURED »

37
Estimated R Correlation Matrix for sujet(produit) 1 1
Row Col Col Col Col4

39
de type CS (COMPOUND SYMMETRY)
")
40
Résultats SPSS : de type « CS »

41
de type AR(1) (Auto-régressif d’ordre 1)
 (Auto-régressif d’ordre 1)")
42
de type AR(1) (Auto-régressif d’ordre 1)
Estimated R Correlation Matrix for sujet(produit) 1 1 Row Col Col Col Col4
 1 1. Row Col1 Col2 Col3 Col")
43
de type CS hétérogène par temps

44
Résultats SPSS

45
Résultats SPSS

46
Modèle 3 Yijk = + i + j + ij + sk(i) + ijk
Produit Temps Sujet (Produit) Résidu Produit * Temps avec sk(i)~ N(0, s2) et ijk~ AR(1). Syntaxe SPSS MIXED rythme BY produit temps sujet_diff /CRITERIA = CIN(95) MXITER(100) MXSTEP(5) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED = produit temps produit*temps | SSTYPE(3) /METHOD = REML /PRINT = SOLUTION TESTCOV /RANDOM sujet_diff | COVTYPE(VC) /REPEATED = temps | SUBJECT(sujet_diff) COVTYPE(AR1) .
 Résidu. Produit. * Temps. avec sk(i)~ N(0, s2) et ijk~ AR(1). Syntaxe SPSS. MIXED. rythme BY produit temps sujet_diff. /CRITERIA = CIN(95) MXITER(100) MXSTEP(5) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED = produit temps produit*temps | SSTYPE(3) /METHOD = REML. /PRINT = SOLUTION TESTCOV. /RANDOM sujet_diff | COVTYPE(VC) /REPEATED = temps | SUBJECT(sujet_diff) COVTYPE(AR1) .")
48
Estimated R Correlation Matrix
for sujet(produit) 1 1 Row Col Col Col Col4
 1 1. Row Col1 Col2 Col3 Col")
49
Choix du type de matrice
Critère d’Akaike AIC = - 2 (Res) Log likelihood d où d = nombre de paramètres du modèle définissant (Covariance parameters) Critère de Schwartz (BIC) BIC = - 2 (Res) Log likelihood + dLog(n) - For REML, the value of n is chosen to be total number of cases minus number fixed effect parameters and d is number of covariance parameters. - For ML, the value of n is total number of cases and d is number of fixed effect parameters plus number of covariance parameters. On recherche minimisant le BIC.
 Log likelihood + 2d. où d = nombre de paramètres du modèle définissant (Covariance parameters) Critère de Schwartz (BIC) BIC = - 2 (Res) Log likelihood + dLog(n) - For REML, the value of n is chosen to be total number of cases minus number. fixed effect parameters and d is number of covariance parameters. - For ML, the value of n is total number of cases and d is number of fixed effect. parameters plus number of covariance parameters. On recherche minimisant le BIC.")
50
Calcul des critères d’Akaike et de Schwarz pour le modèle 3
Critère d’Akaike d =Nombre de paramètres de = 3 AIC = - 2 (Res) Log likelihood d = = 488.7 Critère de Schwarz (BIC) n = 96 – 12 = et d = 3 BIC = - 2 (Res) Log likelihood + dLog(n) = Log(84) =
 Log likelihood + 2d. = = Critère de Schwarz (BIC) n = 96 – 12 = 84 et d = 3. BIC = - 2 (Res) Log likelihood + dLog(n) = Log(84) =")
51
Choix du meilleur modèle

52
Modèle 4 Yk(i) = (Yi1k, Yi2k, Yi3k, Yi4k) ~ N(i, )
avec : i = (i1, i2, i3, i4) et Test : H0 : LM = 0 H1 : LM 0 Statistique : - Calcul des niveaux de signification plus précis qu’avec l’approche univariée, et même exact si min(rang L, rang M) 2. - Pas de données manquantes.
 et. Test : H0 : LM = 0. H1 : LM 0. Statistique : - Calcul des niveaux de signification plus précis qu’avec l’approche univariée, et même exact si min(rang L, rang M) 2. - Pas de données manquantes.")
53
Transformation de Rao m = Nombre de groupes, v = N – m
avec : p = rang (M), q = rang (L) m = Nombre de groupes, v = N – m r = v – (p – q + 1)/2, u = (pq –2)/4 t = si p2 + q2 –5 > 0, = 1 sinon. Lorsque l’hypothèse H0 est vraie, F suit approximativement une loi F(pq, rt–2u). La loi est exacte si le minimum de (p, q) est inférieur ou égal à 2.
, q = rang (L) m = Nombre de groupes, v = N – m. r = v – (p – q + 1)/2, u = (pq –2)/4. t = si p2 + q2 –5 > 0, = 1 sinon. Lorsque l’hypothèse H0 est vraie, F suit approximativement une loi F(pq, rt–2u). La loi est exacte si le minimum de (p, q) est inférieur ou égal à 2.")
54
Les données

55
Test de l’effet « Produit »

56
Test de l’effet « Produit »
Syntaxe SPSS GLM rythme1 rythme2 rythme3 rythme4 BY produit /METHOD = SSTYPE(3) /INTERCEPT = EXCLUDE /CRITERIA = ALPHA(.05) /LMATRIX = "Effet Produit" produit ; produit /MMATRIX = "Moyenne" rythme1 .25 rythme rythme rythme4 .25 /DESIGN = produit .
 /INTERCEPT = EXCLUDE. /CRITERIA = ALPHA(.05) /LMATRIX = Effet Produit produit ; produit /MMATRIX = Moyenne rythme1 .25 rythme2 .25 rythme3 .25 rythme /DESIGN = produit .")
57
Test de l’effet « Temps »

58
GLM rythme1 rythme2 rythme3 rythme4 BY produit /METHOD = SSTYPE(3) /INTERCEPT = EXCLUDE /CRITERIA = ALPHA(.05) /LMATRIX = "Moyenne Produit" produit 1/3 1/3 1/3 /MMATRIX = "rythme 2 - rythme 1 " rythme1 -1 rythme2 1 rythme3 0 rythme4 0; "rythme 3 - rythme 1 " rythme1 -1 rythme2 0 rythme3 1 rythme4 0; "rythme 4 - rythme 1 " rythme1 -1 rythme2 0 rythme3 0 rythme4 1 /DESIGN = produit .

59
Test de l’interaction « Produit*Temps »

60
Test de l’interaction « Produit*Temps »
GLM rythme1 rythme2 rythme3 rythme4 BY produit /METHOD = SSTYPE(3) /INTERCEPT = EXCLUDE /CRITERIA = ALPHA(.05) /LMATRIX = « Effet produit" produit ; produit /MMATRIX = "rythme 2 - rythme 1 " rythme1 -1 rythme2 1 rythme3 0 rythme4 0; "rythme 3 - rythme 1 " rythme1 -1 rythme2 0 rythme3 1 rythme4 0; "rythme 4 - rythme 1 " rythme1 -1 rythme2 0 rythme3 0 rythme4 1 /DESIGN = produit .
 /INTERCEPT = EXCLUDE. /CRITERIA = ALPHA(.05) /LMATRIX = « Effet produit produit ; produit /MMATRIX = rythme 2 - rythme 1 rythme1 -1 rythme2 1 rythme3 0 rythme4 0; rythme 3 - rythme 1 rythme1 -1 rythme2 0 rythme3 1 rythme4 0; rythme 4 - rythme 1 rythme1 -1 rythme2 0 rythme3 0 rythme4 1. /DESIGN = produit .")
61
Comparaison GLM multivarié / MIXED
- Les F de Rao conduisent à des résultats exacts car Min(rang L, rang M) 2. - Comparaisons inter-sujets : GLM multivarié = MIXED Comparaisons intra-sujets : GLM multivarié MIXED
 2. - Comparaisons inter-sujets : GLM multivarié = MIXED. Comparaisons intra-sujets : GLM multivarié MIXED.")
62
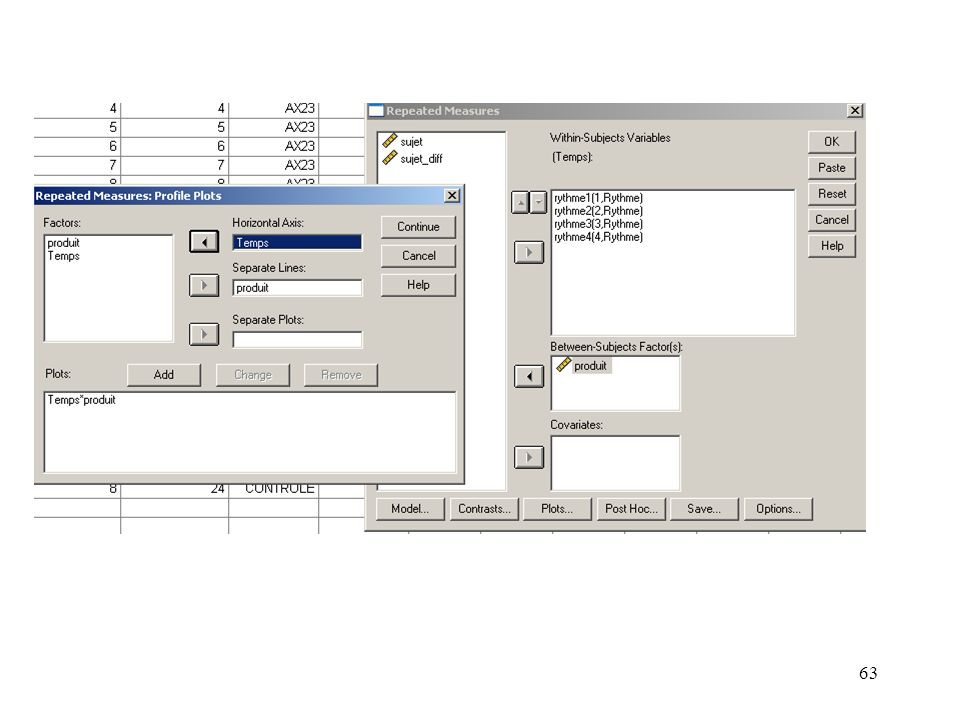
Utilisation de la commande « Repeated Measures » de SPSS

64
Résultats SPSS

65
Résultats SPSS

66
Conclusion : Pour la commande MIXED
Estimation de la structure de covariance entre les données. Estimation correcte des effets fixes et aléatoires. Inférence large et étroite. Possibilité de variances hétérogènes Les résultats justes (au niveau univarié) de la Proc GLM sont retrouvés avec la Proc MIXED. Comparaisons multiples inter-sujets basées sur des moyennes ajustées estimées au niveau de la population. Possibilité de données manquantes.
 de la Proc GLM sont retrouvés avec la Proc MIXED. Comparaisons multiples inter-sujets basées sur des moyennes ajustées estimées au niveau de la population. Possibilité de données manquantes.")
Présentations similaires





















 Michel Tenenhaus.>")