Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Architecture et programmation des ordinateurs
Jacques Lonchamp IUT Nancy Charlemagne – DUT Informatique 1A

2
L’ architecture de base (von Neumann, 1946)
Processeur ou unité de traitement Entrée Sortie Mémoire auxiliaire Périphériques Unité d’ échange données & instructions (d&i) d&i Mémoire centrale Bus programme instr. 1 instr. N données donnée 1 donnée N Unité de commande Unité arithmétique et logique résultats Signaux de commande L’ architecture de base (von Neumann, 1946) Ordinateur = machine de traitement automatique de l’information à programme enregistré en mémoire.
 d&i. Mémoire centrale. Bus. programme. instr. 1. instr. N. données. donnée 1. donnée N. Unité de commande. Unité arithmétique et logique. résultats. Signaux de commande. L’ architecture de base (von Neumann, 1946) Ordinateur = machine de traitement automatique de l’information à programme enregistré en mémoire.")
3
Mémoire centrale Valeur binaire (donnée ou instruction)
adresse 1 2 999 1000 1001 Registre d’adresse (RA) 4369 Registre Mot (RM) val Valeur binaire (donnée ou instruction) Lecture ou écriture (signal de commande) Sélection d’adresse mot
 Registre Mot (RM) val. Valeur binaire (donnée ou instruction) Lecture ou écriture (signal de commande) Sélection d’adresse. mot.")
4
Types de mémoire ‘Mémoires vives’ ou RAM (Random Access Memory)
Les données sont perdues en absence d’alimentation électrique ‘Mémoires vives’ ou RAM (Random Access Memory) SRAM (RAM statiques) utilise le principe des bascules (rapides, chères) DRAM (RAM dynamiques) nécessitent un rafraîchissement périodique de l’information (moins rapides, moins chères) ‘Mémoires mortes’ ou ROM (Read Only Memory) Ne s’efface pas en absence d’alimentation électrique Les ROM véritables dont le contenu est défini lors de la fabrication. Les PROM (Programmable ROM) sont programmables une seule fois par l’utilisateur (fusibles). Les EPROM (Erasable Programmable ROM) sont effaçables en plaçant la mémoire dans une machine spéciale et programmables. Les EEPROM (Electrically Erasable Programmable ROM) sont effaçables électriquement et programmables
 SRAM (RAM statiques) utilise le principe. des bascules (rapides, chères) DRAM (RAM dynamiques) nécessitent un. rafraîchissement périodique de l’information. (moins rapides, moins chères) ‘Mémoires mortes’ ou. ROM (Read Only Memory) Ne s’efface pas en absence. d’alimentation électrique. Les ROM véritables dont le contenu est défini lors de la fabrication. Les PROM (Programmable ROM) sont programmables une seule fois par l’utilisateur (fusibles). Les EPROM (Erasable Programmable ROM) sont effaçables en plaçant la mémoire dans une machine spéciale et programmables. Les EEPROM (Electrically Erasable Programmable ROM) sont effaçables électriquement et programmables.")
5
Mémoire cache Mémoire centrale requête requête Processeur Cache mot
bloc Rapide, chère, faible capacité (SRAM) (DRAM) Principe : si le mot est dans le cache on y accède rapidement; sinon, on accède a la mémoire centrale et on range dans le cache un bloc de K mots autour du mot désiré, car il y a une bonne probabilité que ce mot ou un mot proche soit utile rapidement après (localité spatiale et localité temporelle). Un algorithme de remplacement décide quel bloc présent dans le cache est remplacé par le nouveau bloc : le plus ancien (‘first in first out' ou FIFO), le plus anciennement utilisé (‘last recently used' ou LRU), le moins fréquemment utilisé (‘least frequently used ou LFU), un pris au hasard, etc.
 (DRAM) Principe : si le mot est dans le cache on y accède rapidement; sinon, on accède a la mémoire centrale et on range dans le cache un bloc de K mots autour du mot désiré, car il y a une bonne probabilité que ce mot ou un mot proche soit utile rapidement après (localité spatiale et localité temporelle). Un algorithme de remplacement décide quel bloc présent dans le cache est remplacé par le nouveau bloc : le plus ancien (‘first in first out ou FIFO), le plus anciennement utilisé (‘last recently used ou LRU), le moins fréquemment utilisé (‘least frequently used ou LFU), un pris au hasard, etc.")
6
Hiérarchie des mémoires
Rapidité & Coût Registre Cache Mémoire centrale Disque ou SSD Capacité Registre Cache Mémoire centrale Disque Capacités typiques <Ko Mo Go >To Temps d'accès (ns) Coût relatif ,001
 Coût relatif ,001.")
7
Unité de commande (UC) Décode les instructions et les transforme en une série de micro-commandes qui activent les autres composants de l’ordinateur. Horloge Séquenceur top Séquence de signaux de commande Registre instruction (RI) Code opération Adresses opérandes instruction Compteur ordinal (CO) Adresse de la prochaine instruction à exécuter Recherche en mémoire
 Code opération. Adresses opérandes. instruction. Compteur ordinal (CO) Adresse de la prochaine instruction à exécuter. Recherche. en mémoire.")
8
Le cycle ‘chercher-décoder-exécuter’
Principe d‘exécution d'un programme : répétition du même cycle d'opérations, appelé cycle ‘chercher-décoder-exécuter' : répéter chercher l'instruction dont l'adresse est dans CO et la mettre dans RI; incrémenter de 1 CO; décoder le contenu de RI ; s'il y en a, chercher le (les) opérande(s) dont on a l'(les) adresse(s); exécuter l'opération correspondant au code opération; si c'est un branchement CO est remodifié fin
 opérande(s) dont on a. l (les) adresse(s); exécuter l opération correspondant au code opération; si c est un branchement CO est remodifié. fin.")
9
CISC et RISC Processeurs CISC (‘Complex Instruction Set Computer'), comme les processeurs Intel : lenteur de la mémoire => intérêt d’avoir des opérations complexes => moins nombreuses et moins d’accès aux données. Mais 80% des programmes générés par les compilateurs font appel a seulement 20% des instructions machine. D'ou l'idée de l'architecture RISC de réduire le jeu d'instructions a ces 20% d'instructions les plus utilisées, en cherchant a les optimiser au maximum avec des séquenceurs câblés. CISC RISC jeu d'instructions large jeu d'instructions réduit instructions complexes instructions simples instructions de tailles différentes instructions de mêmes tailles instructions de durées différentes instructions de mêmes durées séquenceur micro-programmé séquenceur câblé Richesse du langage machine Efficacité du langage machine
, comme les processeurs Intel : lenteur de la mémoire => intérêt d’avoir des opérations complexes => moins nombreuses et moins d’accès aux données. Mais 80% des programmes générés par les compilateurs font appel a seulement 20% des instructions machine. D ou l idée de l architecture RISC de réduire le jeu d instructions a ces 20% d instructions les plus utilisées, en cherchant a les optimiser au maximum avec des séquenceurs câblés. CISC RISC. jeu d instructions large jeu d instructions réduit. instructions complexes instructions simples. instructions de tailles différentes instructions de mêmes tailles. instructions de durées différentes instructions de mêmes durées. séquenceur micro-programmé séquenceur câblé. Richesse du langage machine. Efficacité du langage machine.")
10
Nécessite instructions de calcul à 3 adresses mémoire
Unité arithmétique et logique (UAL) Opérande1 (mémoire centrale) Opérande2 Résultat (mémoire centrale) Circuits de calcul de l’UAL Code opération Registre d’état (RE) {drapeaux ou ‘flags’} Nécessite instructions de calcul à 3 adresses mémoire ( => mots très longs) : code_opération +adresse_opérande1+adresse_opérande2+adresse_résultat
 Opérande1. (mémoire centrale) Opérande2. Résultat (mémoire centrale) Circuits de calcul de l’UAL. Code opération. Registre d’état (RE) {drapeaux ou ‘flags’} Nécessite instructions de calcul à 3 adresses mémoire. ( => mots très longs) : code_opération +adresse_opérande1+adresse_opérande2+adresse_résultat.")
11
Circuits de calcul de l’UAL
Architecture avec registre accumulateur : Opérande 1 (mémoire centrale) 1 3 Résultat (mémoire centrale) Accumulateur (ACC) Circuits de calcul de l’UAL Code opération Registre d’état (RE) 2 Opérande2 (mémoire centrale) Nécessite trois instructions à une seule adresse mémoire : charger opérande1 dans ACC calcul avec ACC et opérande2, résultat dans ACC transfert de ACC dans mot d’adresse résultat. 1 2 3
 Résultat. (mémoire centrale) Accumulateur. (ACC) Circuits de calcul de l’UAL. Code opération. Registre d’état (RE) 2. Opérande2 (mémoire centrale) Nécessite trois instructions à une seule adresse mémoire : charger opérande1 dans ACC. calcul avec ACC et opérande2, résultat dans ACC. transfert de ACC dans mot d’adresse résultat")
12
L’organisation avec accumulateur a été utilisée par les
premiers microprocesseurs 8 bits (Intel 8080 et Motorola 6800). Dans les microprocesseurs 16 bits (Intel 8086, Motorola 68000) l'accumulateur a été remplacé par un petit nombre de registres généraux. Pour repérer un registre parmi 4 (R1, R2, R3, R4) 2 bits suffisent dans les instructions : 1. transfert de l'opérande 1 dans un des 4 registres généraux (Ri), 2. opération avec Ri et l'opérande 2, résultat dans Ri, 3. transfert de Ri en mémoire. Les microprocesseurs les plus récents (Pentium, PowerPC, ALPHA, SPARC, MIPS) utilisent uniquement des registres et plus aucune adresse dans les instructions de calcul : 1. transfert de l'opérande 1 dans un registre Ri, 2. transfert de l'opérande 2 dans un registre Rj, 3. opération avec Ri et Rj, résultat dans Rk, 4. rangement de Rk en mémoire. Il peut alors y avoir un grand nombre de registres adressés par quelques bits chacun.
. Dans les microprocesseurs 16 bits (Intel 8086, Motorola 68000) l accumulateur a été remplacé par un petit nombre de registres généraux. Pour repérer un registre parmi 4 (R1, R2, R3, R4) 2 bits suffisent dans les instructions : 1. transfert de l opérande 1 dans un des 4 registres généraux (Ri), 2. opération avec Ri et l opérande 2, résultat dans Ri, 3. transfert de Ri en mémoire. Les microprocesseurs les plus récents (Pentium, PowerPC, ALPHA, SPARC, MIPS) utilisent uniquement des registres et plus aucune adresse dans les instructions de calcul : 1. transfert de l opérande 1 dans un registre Ri, 2. transfert de l opérande 2 dans un registre Rj, 3. opération avec Ri et Rj, résultat dans Rk, 4. rangement de Rk en mémoire. Il peut alors y avoir un grand nombre de registres adressés par quelques bits chacun.")
13
Cycle d’exécution d’une instruction
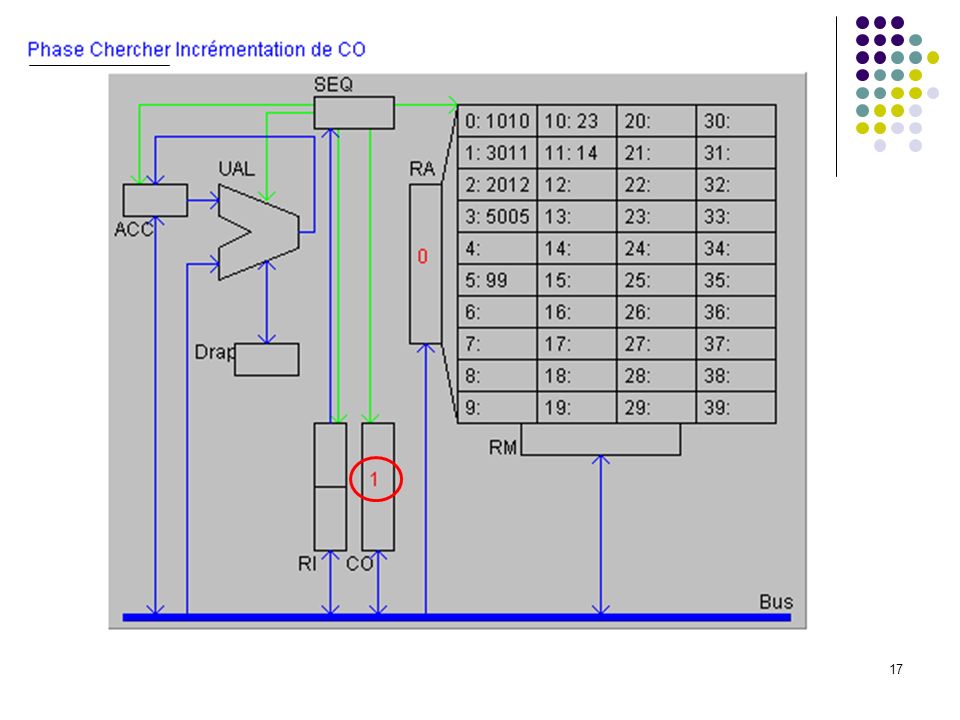
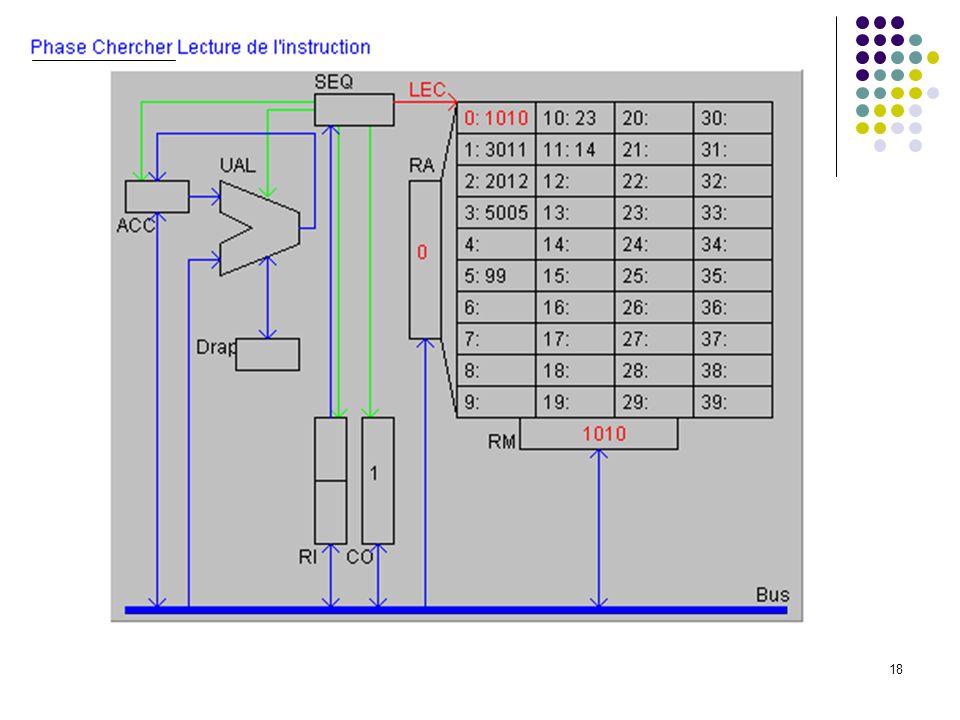
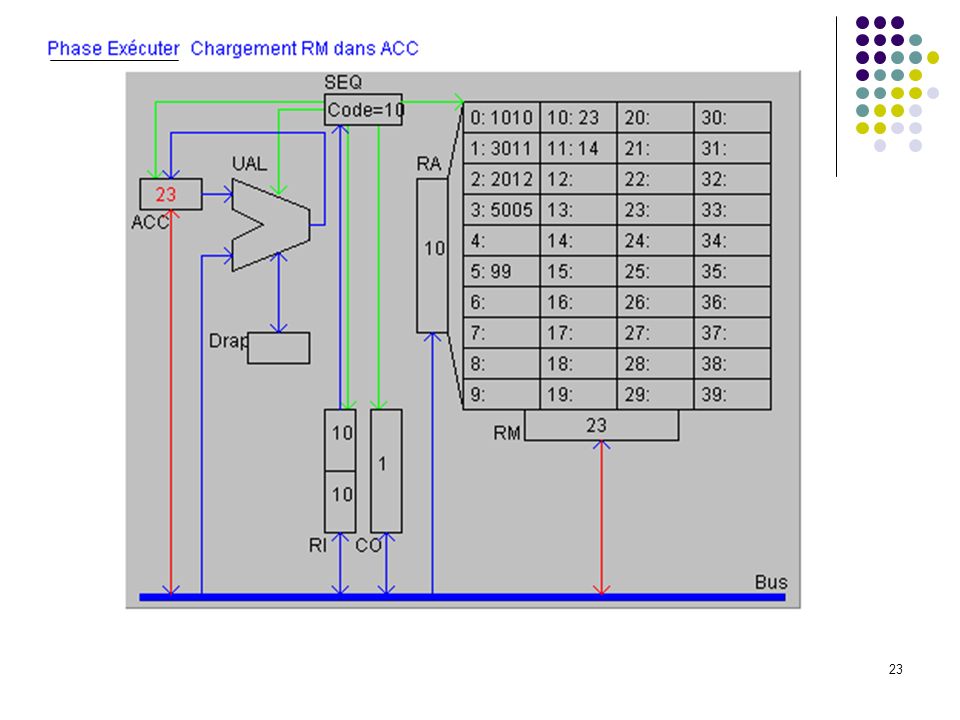
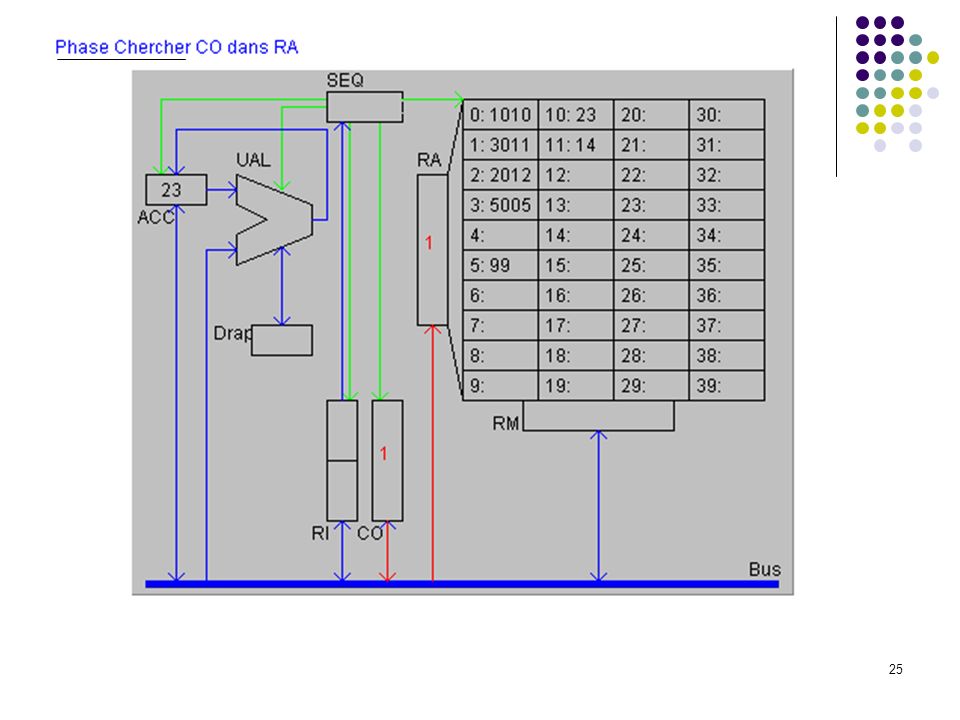
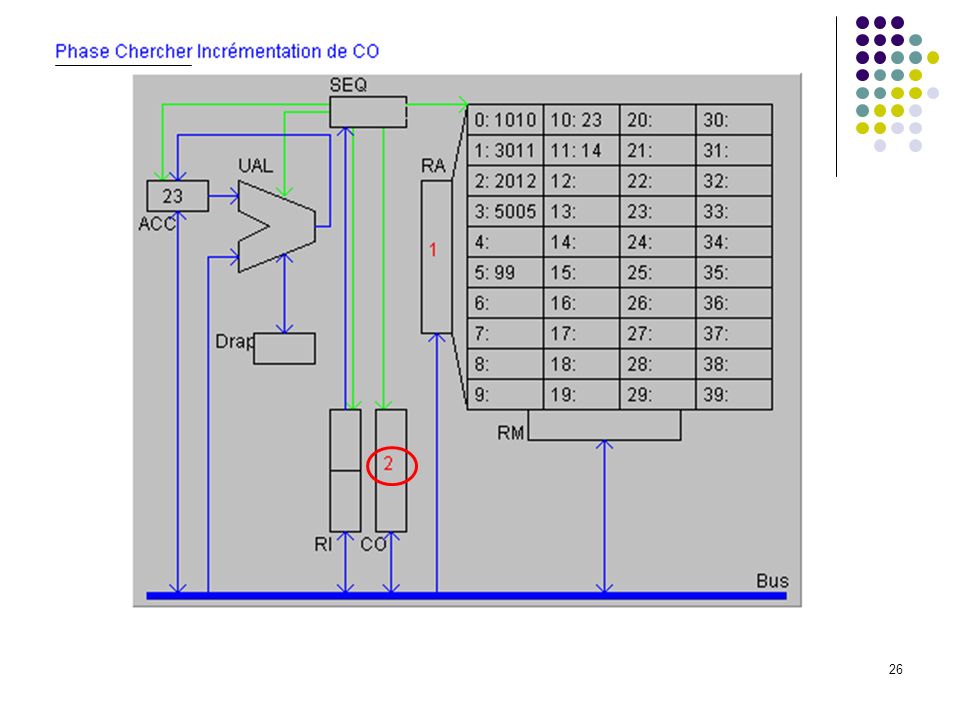
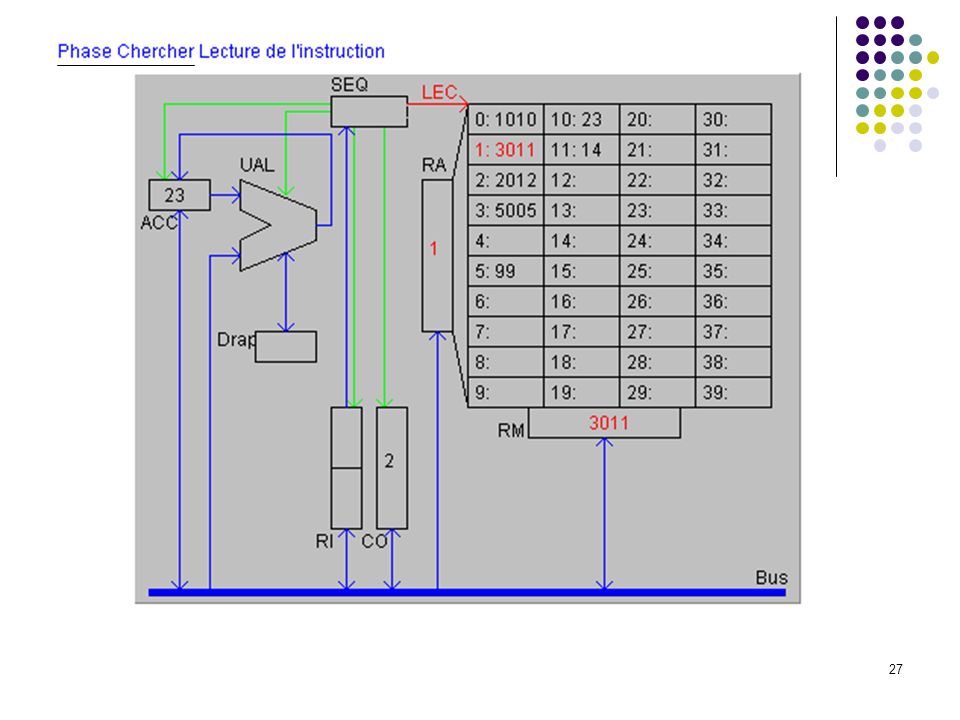
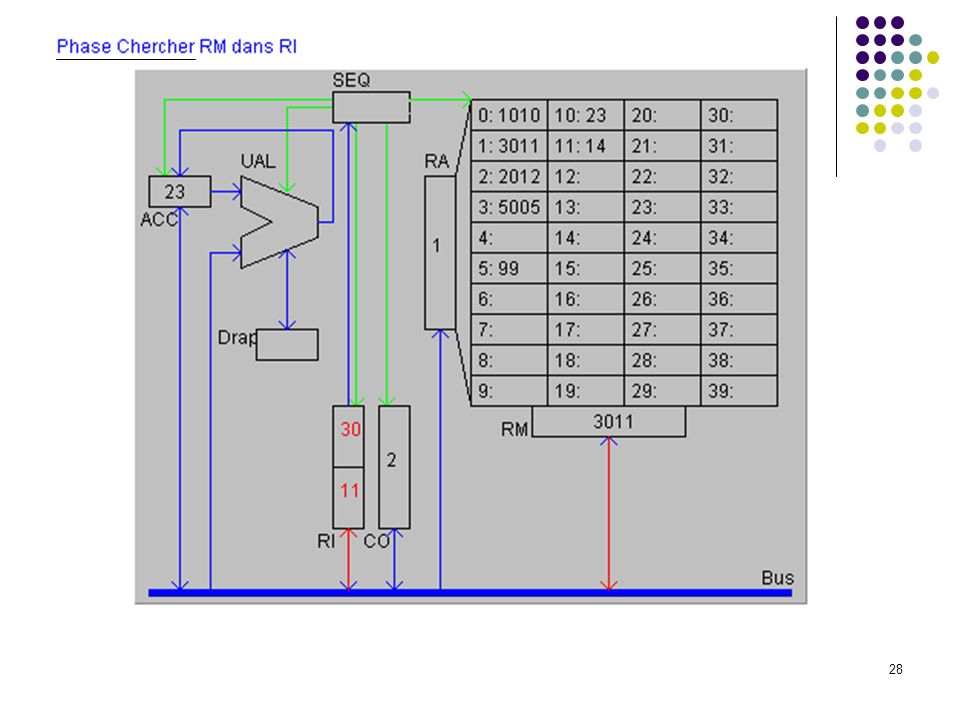
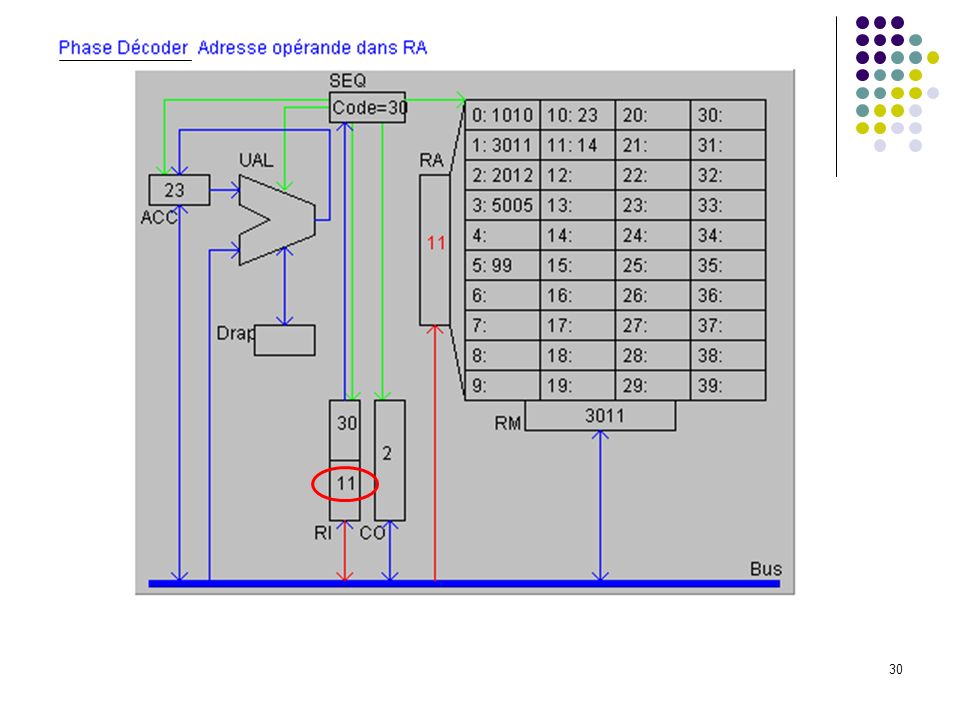
A1 : CO dans RA (adresse prochaine instruction dans RA) A2 : incrémentation de 1 de CO (prochaine instruction à l’adresse suivante) A3 : lecture de l’instruction et rangement dans RM CHERCHER A4 : transfert de l’instruction de RM à RI pour décodage B1 : analyse du code instruction; envoi des signaux de commande DECODER B2 : adresse de l’opérande dans RA B3 : lecture de l’opérande en mémoire et rangement dans RM EXECUTER C1 : calcul sur opérandes dans RM et ACC (a été précédé par un transfert du 1er opérande de la mémoire vers ACC et est suivie d’un transfert du résultat de ACC vers la mémoire). C1 : branchement adresse est rangée dans CO (devient la prochaine instruction à exécuter). CO RI RA A1 +1 A2 instruction RM A3 A4 Code adresse Séquenceur B1 B2 opérande B3 C1 ACC UAL Mémoire centrale UC Cycle d’exécution d’une instruction OU
 A2 : incrémentation de 1 de CO (prochaine instruction à l’adresse suivante) A3 : lecture de l’instruction et rangement dans RM CHERCHER. A4 : transfert de l’instruction de RM à RI pour décodage. B1 : analyse du code instruction; envoi des signaux de commande DECODER. B2 : adresse de l’opérande dans RA. B3 : lecture de l’opérande en mémoire et rangement dans RM EXECUTER. C1 : calcul sur opérandes dans RM et ACC (a été précédé par un transfert du 1er opérande de la mémoire vers ACC et est suivie d’un transfert du résultat de ACC vers la mémoire). C1 : branchement adresse est rangée dans CO (devient la prochaine instruction à exécuter). CO. RI. RA. A A2. instruction. RM. A3. A4. Code adresse. Séquenceur. B1. B2. opérande. B3. C1. ACC. UAL. Mémoire centrale. UC. Cycle d’exécution d’une instruction. OU.")
14
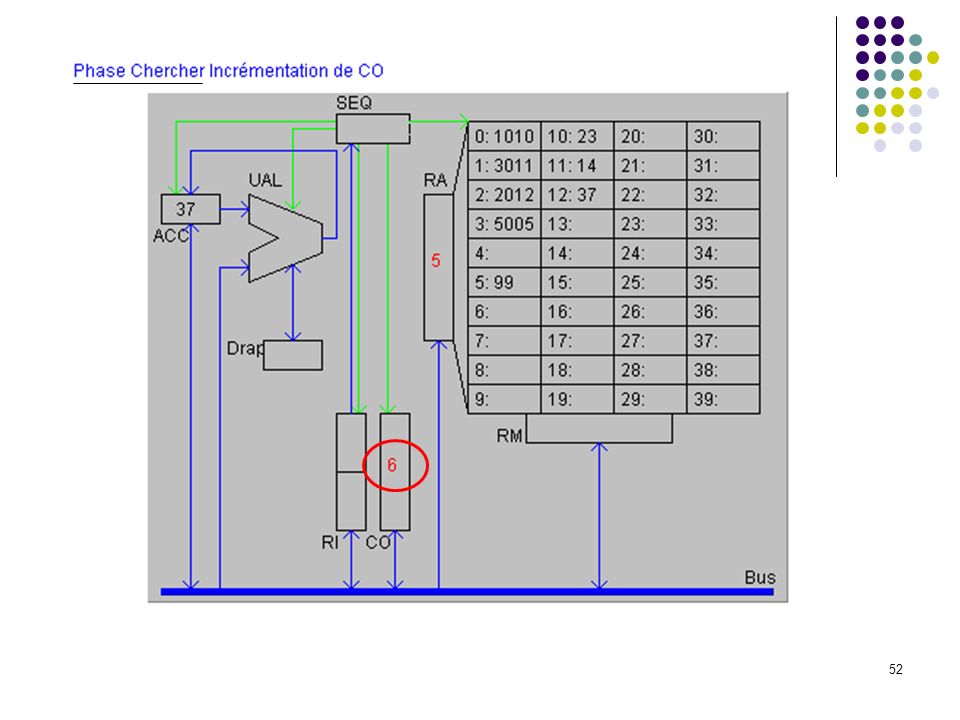
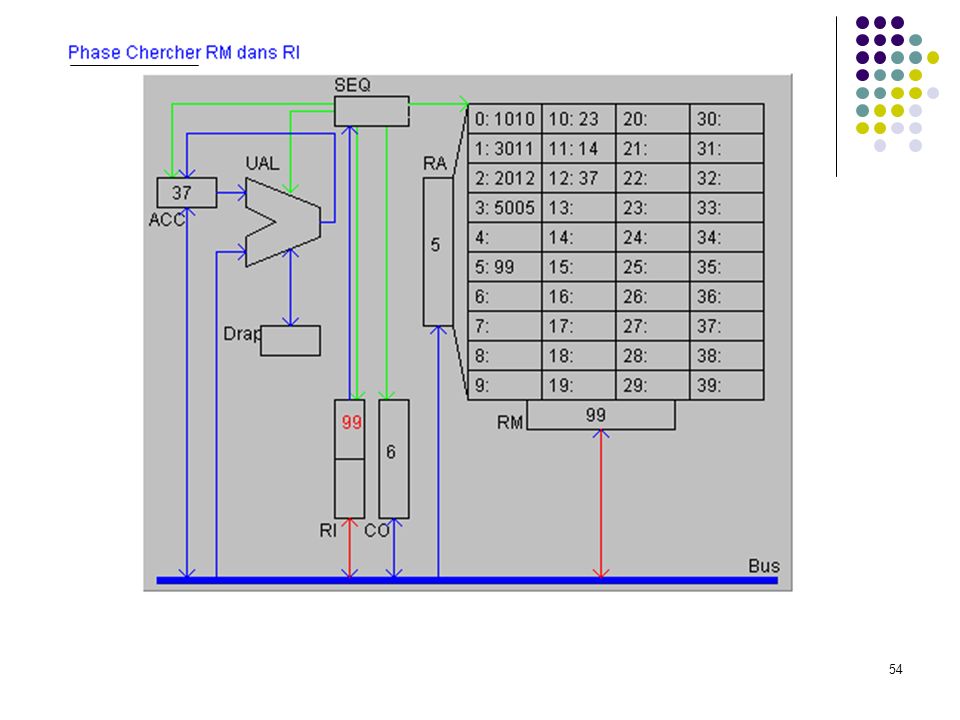
Programme complet sur machine élémentaire
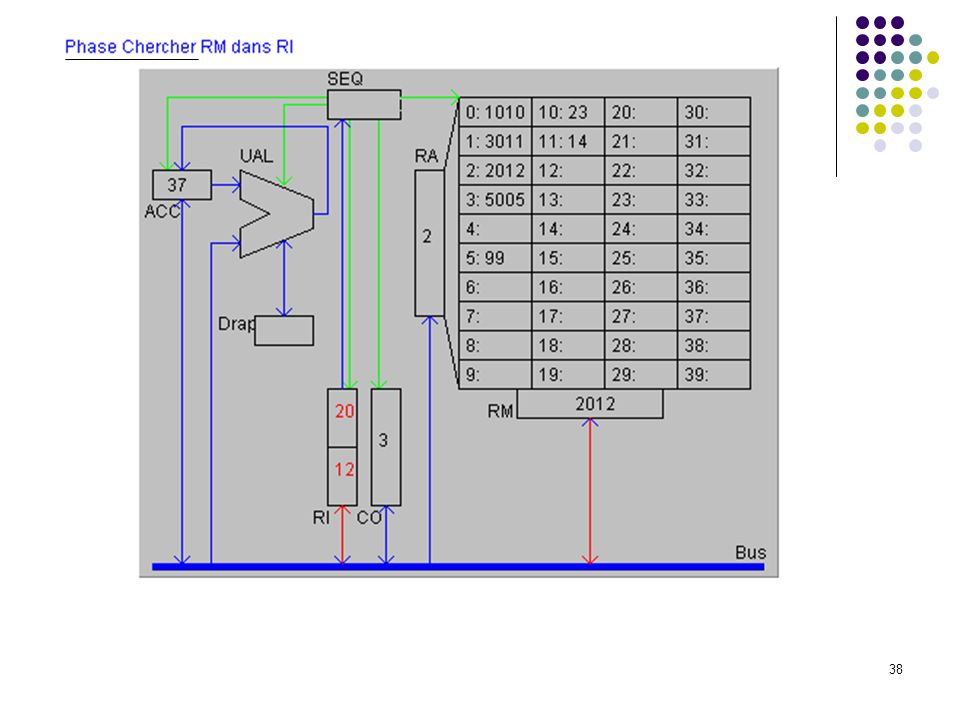
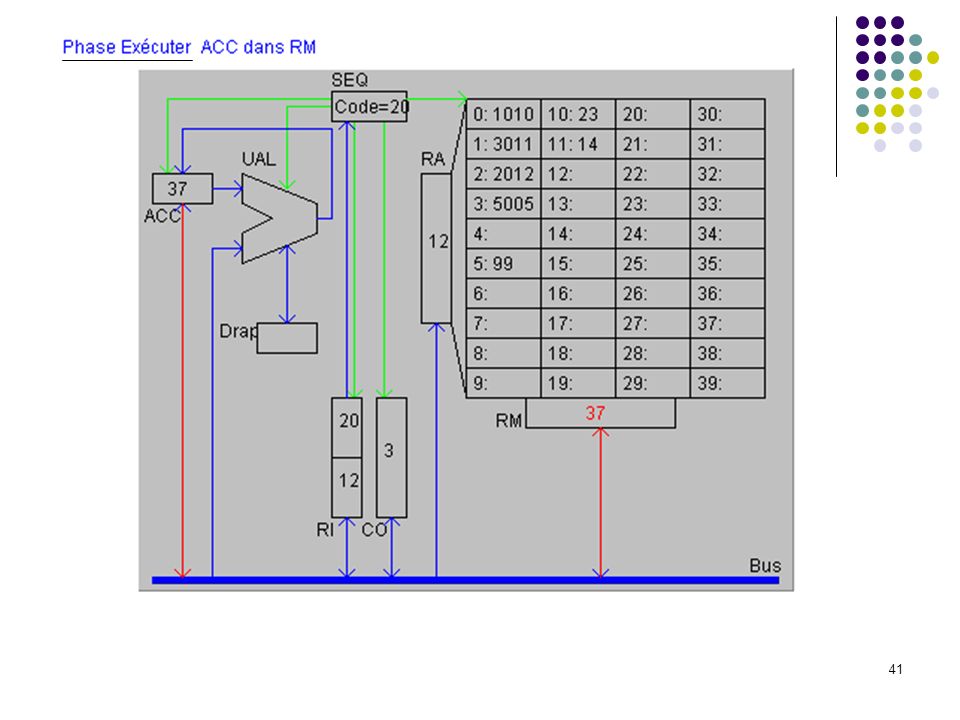
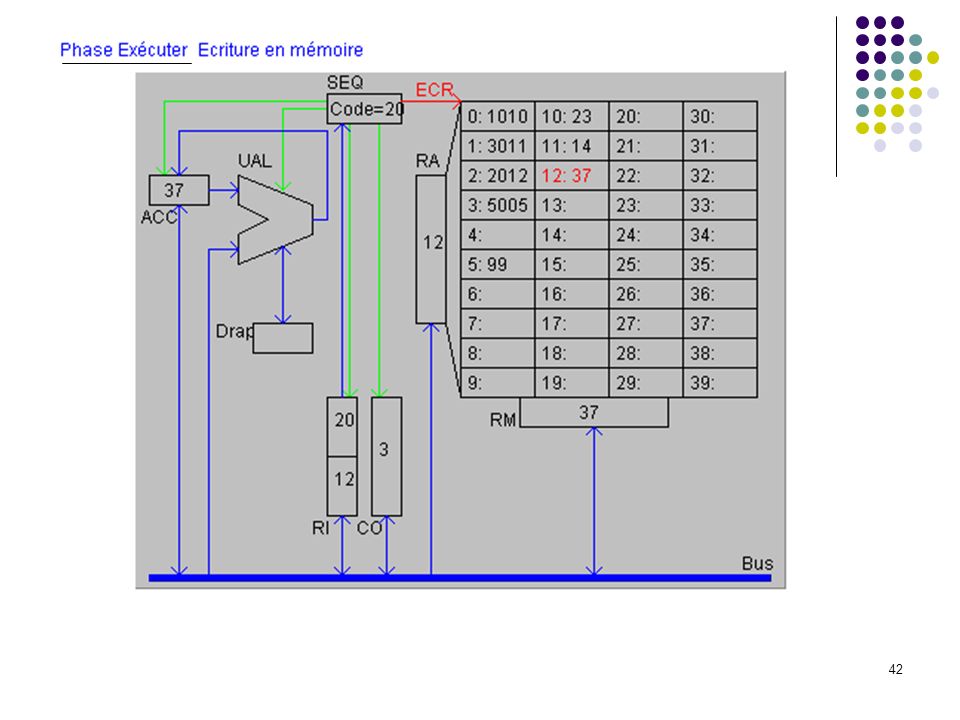
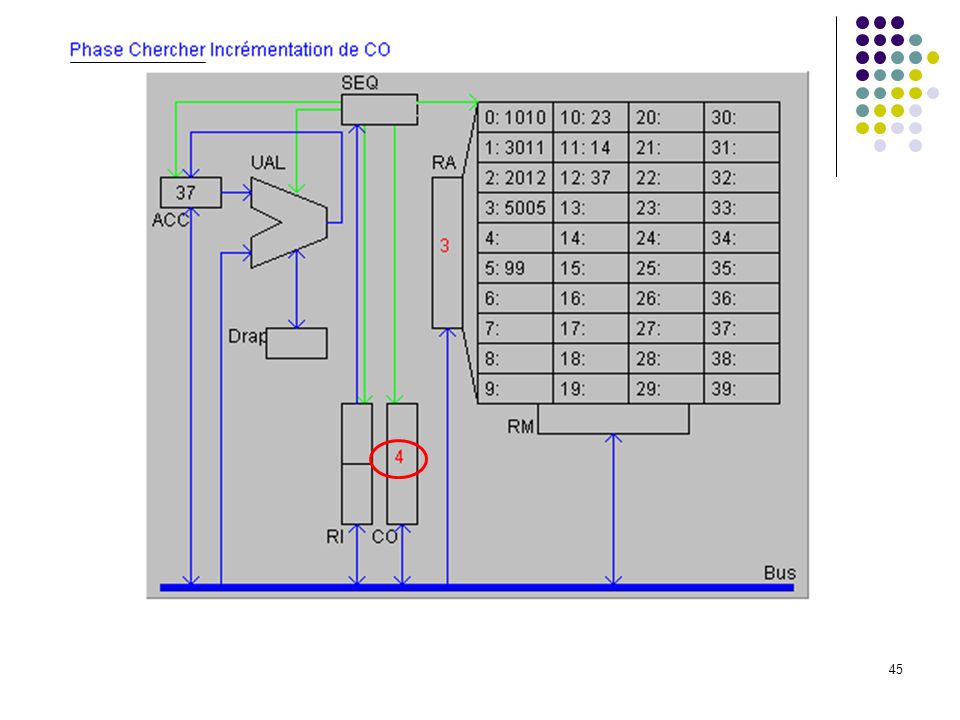
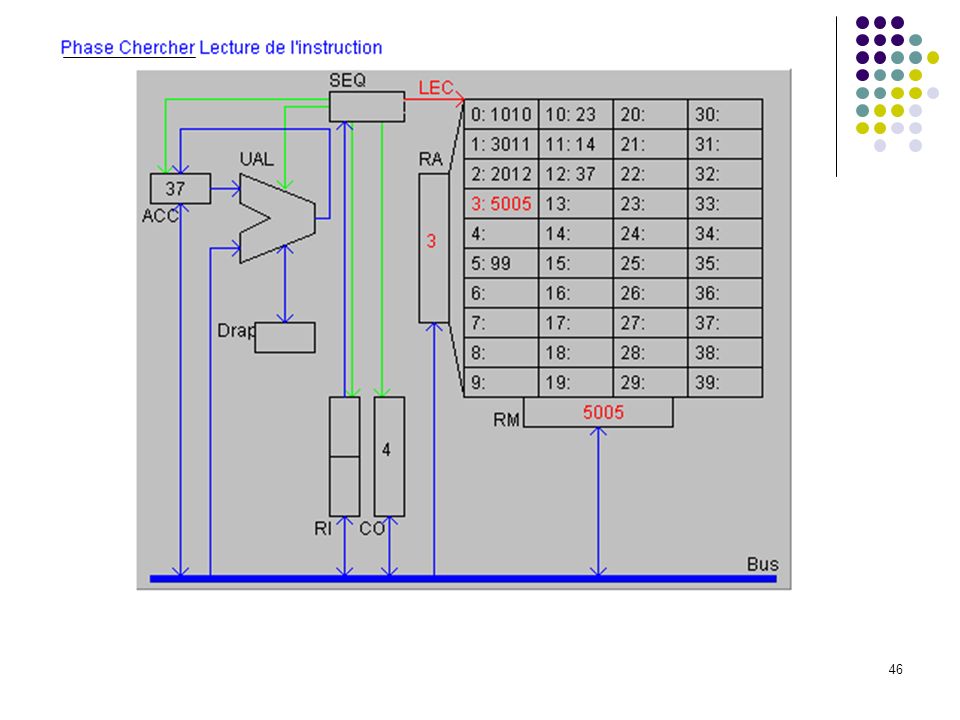
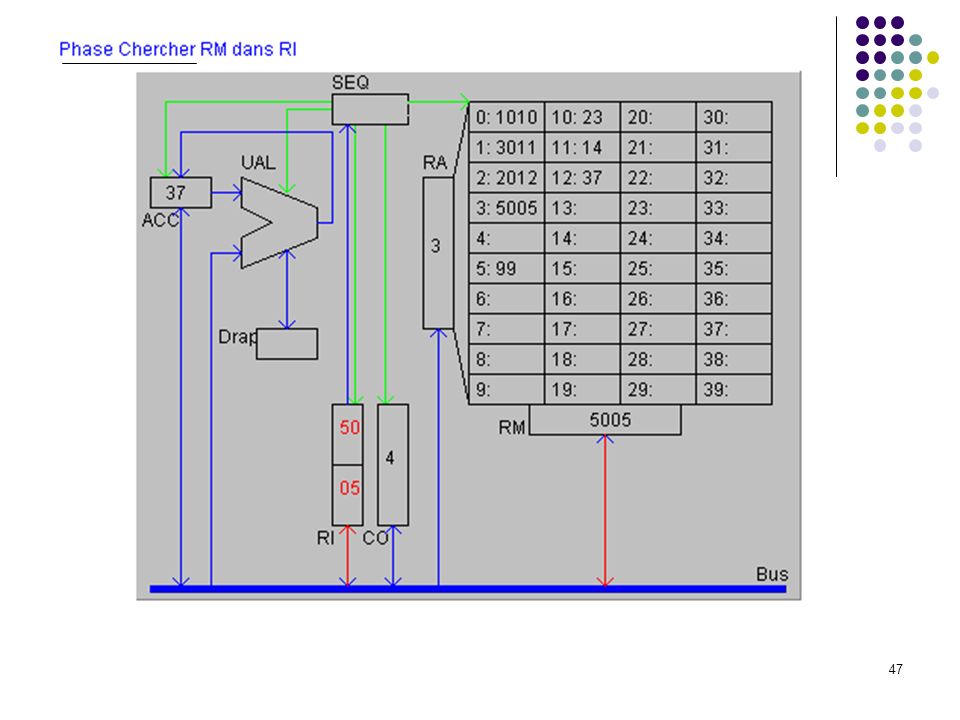
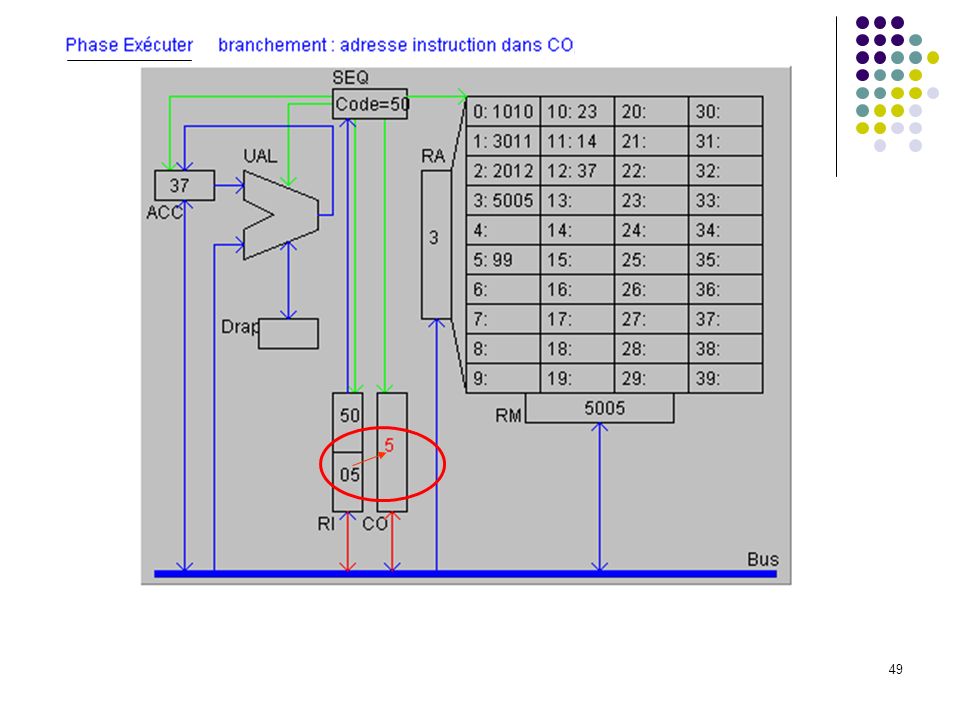
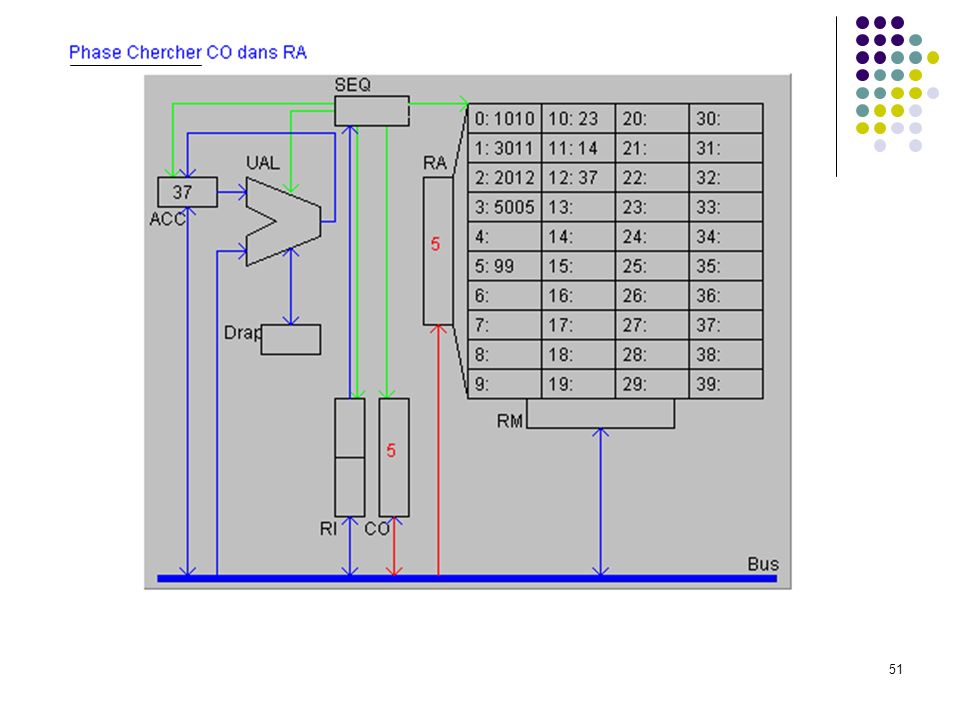
Définition du langage : Codes Instructions 10 chargement dans ACC du mot indiqué (ex : 1025 chargement dans ACC du mot 25) 20 rangement de ACC dans le mot mémoire indiqué 30 addition de ACC et du mot mémoire indiqué 50 saut inconditionnel a l'adresse indiquée (ex : 5012) 99 arrêt du programme Le programme exemple : adresses 0: charger dans ACC mot 10 (valeur 23) 1: additionner ACC et mot 11 (valeur 37) 2: ranger ACC dans mot 12 3: sauter à l’adresse 5 (sert uniquement à montrer un saut) 4: 5: arrêter 6: … 10: 23 donnée 1 11: 14 donnée 2 12: 37 doit apparaître ici Exécution pas à pas
 20 rangement de ACC dans le mot mémoire indiqué. 30 addition de ACC et du mot mémoire indiqué. 50 saut inconditionnel a l adresse indiquée (ex : 5012) 99 arrêt du programme. Le programme exemple : adresses. 0: 1010 charger dans ACC mot 10 (valeur 23) 1: 3011 additionner ACC et mot 11 (valeur 37) 2: 2012 ranger ACC dans mot 12. 3: 5005 sauter à l’adresse 5 (sert uniquement à montrer un saut) 4: 5: 99 arrêter. 6: … 10: 23 donnée 1. 11: 14 donnée 2. 12: 37 doit apparaître ici. Exécution pas à pas.")
15
Etat initial de la machine : programme chargé à l’adresse 0 et CO = 0

16
(prépare la lecture de la 1ère instruction)
")
19
(prépare le décodage de la 1ère instruction)
")
20
(10 = charger ACC avec opérande)
")
21
(prépare l’accès à l’opérande)
")
24
Etat à la fin de la première instruction (mot 10 chargé dans ACC)
")
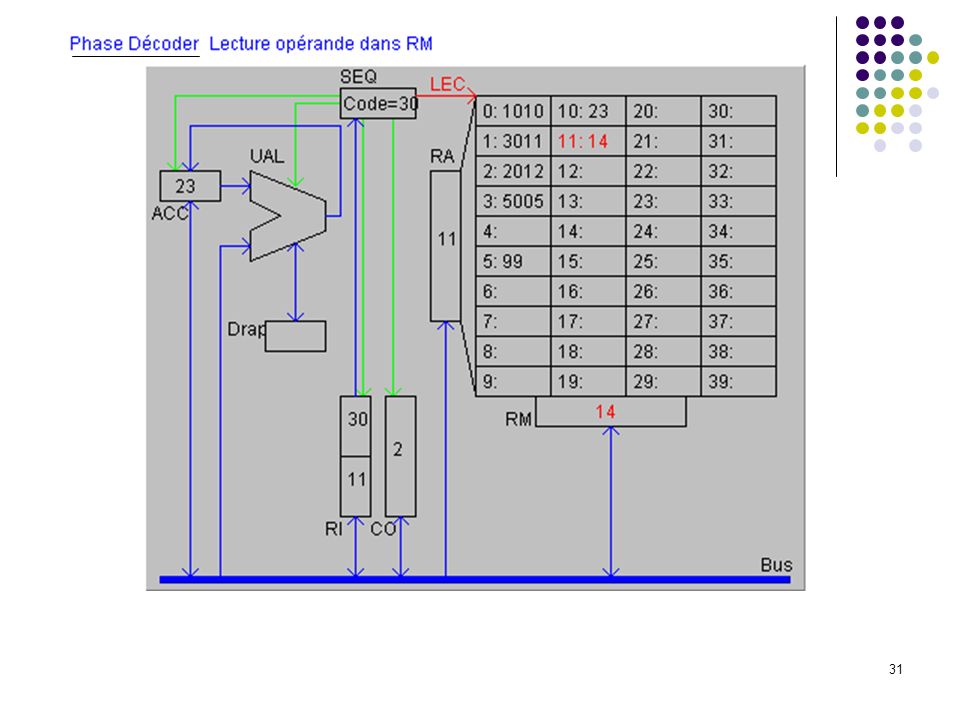
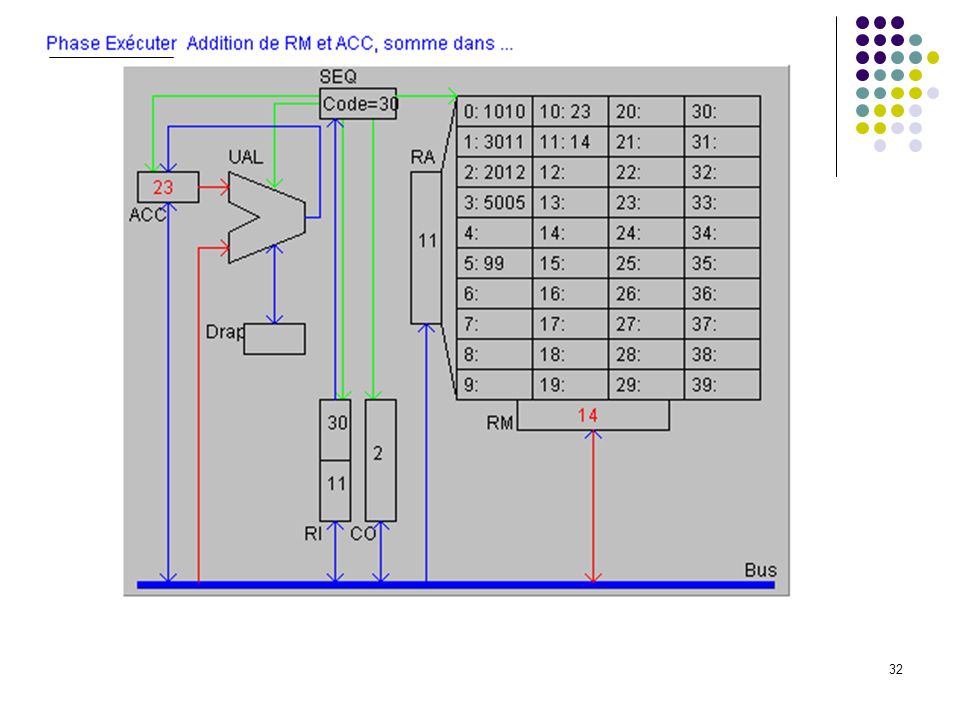
29
(additionner ACC et opérande, résultat dans ACC)
")
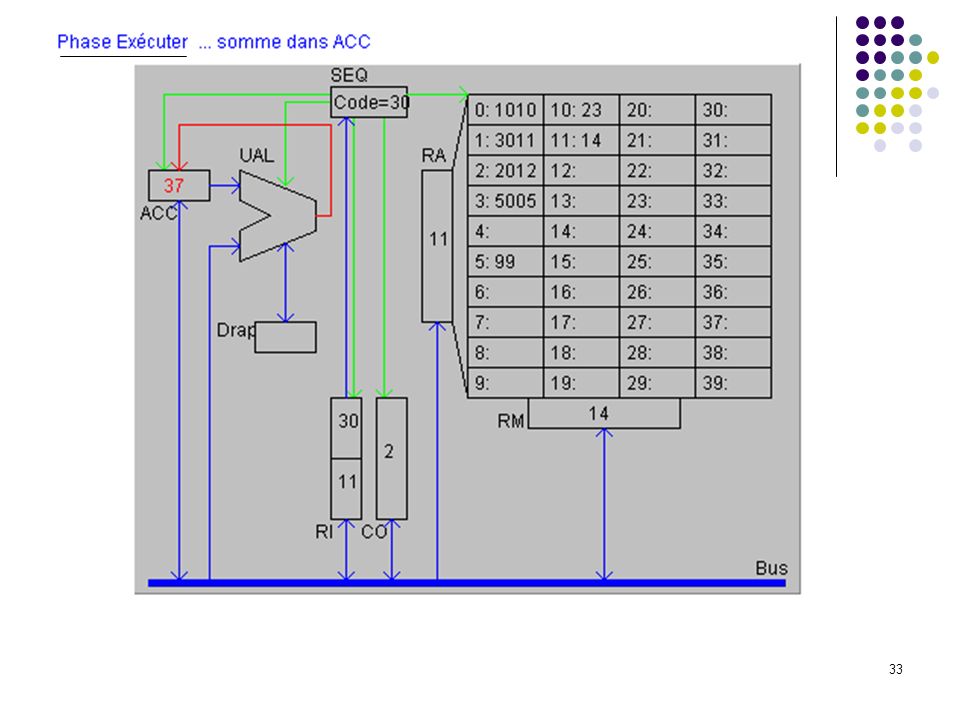
34
Etat après exécution de l’instruction 2 (somme des mots 10 et 11 dans ACC)
")
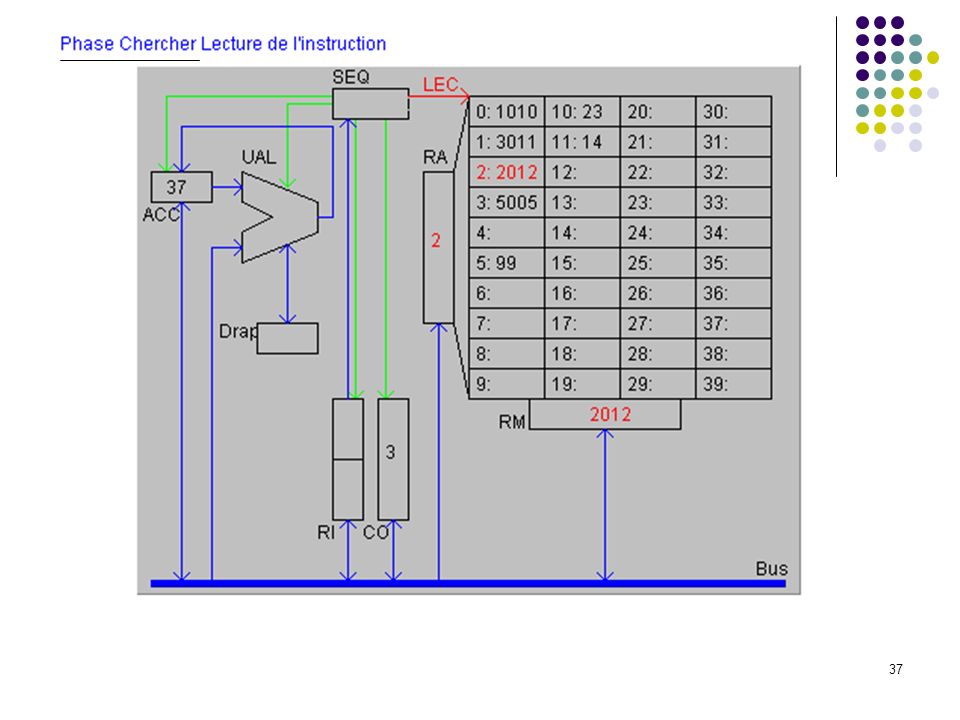
39
(ranger ACC dans opérande)
")
43
Etat après exécution de instruction 3 (somme dans mot 12)
")
48
(saut inconditionnel à opérande)
")
50
Etat après instruction 3 (prêt à exécuter instruction 5)
")
55
(arrêter le programme)
")
56
Etat final du programme

57
Les bus Voie de communication connectant plusieurs composants; support de transmission partagé. Bus internes : de quelque dizaines à plusieurs centaines de lignes par lesquelles transitent en parallèle les bits; lignes de données, lignes d'adresses et lignes pour signaux de contrôle (ou signaux de commandes). Bus d'entrées/sorties : sur PC bus AGP et PCI-EXPRESS pour les cartes graphiques, bus PCI pour les cartes réseaux et son, bus ATA, SATA, SCSI pour les disques, bus USB et FireWire pour les périphériques externes. Un signal émis par un composant peut être reçu par tous les autres composants connectés au bus. Par contre, il faut interdire à deux composants d‘émettre simultanément un signal car ceux-ci pourraient interférer. Une méthode d'arbitrage évitant cette situation doit être mise en place. Cet arbitrage est réalisé soit par un composant spécialisé (le contrôleur de bus), dans le cas d'un arbitrage centralisé, soit par la coopération des composants connectés au bus, dans le cas d'un arbitrage décentralisé.
. Bus d entrées/sorties : sur PC bus AGP et PCI-EXPRESS pour les cartes graphiques, bus PCI pour les cartes réseaux et son, bus ATA, SATA, SCSI pour les disques, bus USB et FireWire pour les périphériques externes. Un signal émis par un composant peut être reçu par tous les autres composants connectés au bus. Par contre, il faut interdire à deux composants d‘émettre simultanément un signal car ceux-ci pourraient interférer. Une méthode d arbitrage évitant cette situation doit être mise en place. Cet arbitrage est réalisé soit par un composant spécialisé (le contrôleur de bus), dans le cas d un arbitrage centralisé, soit par la coopération des composants connectés au bus, dans le cas d un arbitrage décentralisé.")
58
Les disques Adressables par secteur : n° cylindre + n° tête + n° secteur. Doivent être formatés. Concurrencés par SSD (mémoires flash). Plus de moteur…
. Plus de moteur…")
59
Les unités d’échange (UE)
Les périphériques sont très lents par rapport au processeur et à la mémoire (nanosecondes/millisecondes ou secondes). Il faut des UE (ou contrôleurs d'entrées/sorties) entre processeur et périphériques pour gérer leur coordination, le transcodage, la détection des erreurs etc. Il y a 3 techniques pour gérer les entrées/sorties : scrutation : le processeur interroge l‘UE pour savoir si des E/S sont possibles. Tant que ces E/S ne sont pas possibles, le processeur attend puis redemande (boucle de scrutation). Le processeur est souvent en attente et il est complètement occupé par la réalisation de l‘E/S. Ce type d‘E/S est très lent. interruption : une interruption est un signal émis par un dispositif externe au processeur. Celui-ci possède une ou plusieurs entrées réservées pour les interruptions. Avant chaque instruction, le processeur examine s'il y a eu une interruption. Si oui, il interrompt le programme en cours et sauvegarde son état (registres, compteur ordinal...). Puis, il exécute le programme associé à l'interruption avant de revenir au programme interrompu. Dans une E/S avec interruption, le processeur exécute sa requête à l’UE et reprend l'exécution d'un programme (le même ou un autre). Il n'attend donc plus pendant l’E/S. A la fin de l’E/S, l’UE envoie une interruption au processeur qui exécute le traitement associé à l’interruption (par exemple le transfert en mémoire des données lues). Puis il reprend le programme initial.
. Il faut des UE (ou contrôleurs d entrées/sorties) entre processeur et périphériques pour gérer leur coordination, le transcodage, la détection des erreurs etc. Il y a 3 techniques pour gérer les entrées/sorties : scrutation : le processeur interroge l‘UE pour savoir si des E/S sont possibles. Tant que ces E/S ne sont pas possibles, le processeur attend puis redemande (boucle de scrutation). Le processeur est souvent en attente et il est complètement occupé par la réalisation de l‘E/S. Ce type d‘E/S est très lent. interruption : une interruption est un signal émis par un dispositif externe au processeur. Celui-ci possède une ou plusieurs entrées réservées pour les interruptions. Avant chaque instruction, le processeur examine s il y a eu une interruption. Si oui, il interrompt le programme en cours et sauvegarde son état (registres, compteur ordinal...). Puis, il exécute le programme associé à l interruption avant de revenir au programme interrompu. Dans une E/S avec interruption, le processeur exécute sa requête à l’UE et reprend l exécution d un programme (le même ou un autre). Il n attend donc plus pendant l’E/S. A la fin de l’E/S, l’UE envoie une interruption au processeur qui exécute le traitement associé à l’interruption (par exemple le transfert en mémoire des données lues). Puis il reprend le programme initial.")
60
échange direct avec la mémoire : ce mode permet le transfert de blocs de données entre la mémoire et un périphérique sans passer par le processeur. Pour cela, un circuit appelé contrôleur de DMA (Direct Memory Access) se charge entièrement du transfert des données. Le microprocesseur initialise l’échange en donnant au contrôleur de DMA : le périphérique concerné, le sens du transfert (E ou S), l'adresse du premier et du dernier mot concernés par le transfert. Le contrôleur de DMA est doté d'un registre d'adresse, d'un registre de donnée, d'un compteur et d'un dispositif de commande (c'est un vrai processeur spécialisé). Pour chaque mot échangé, le DMA demande au microprocesseur le contrôle du bus, effectue la lecture ou l‘écriture mémoire à l'adresse contenue dans son registre et libère le bus. Il incrémente ensuite cette adresse et décrémente son compteur. Lorsque le compteur atteint zéro, le dispositif informe le processeur de la fin du transfert par une interruption. Le principal avantage est que pendant toute la durée du transfert des données, le processeur est libre d'effectuer un autre traitement. La seule contrainte est une limitation de ses propres accès mémoire pendant toute la durée de l'opération, puisqu'il doit parfois retarder certains de ses accès pour permettre au DMA d'effectuer les siens (arbitrage pour l'accès au bus).
, l adresse du premier et du dernier mot concernés par le transfert. Le contrôleur de DMA est doté d un registre d adresse, d un registre de donnée, d un compteur et d un dispositif de commande (c est un vrai processeur spécialisé). Pour chaque mot échangé, le DMA demande au microprocesseur le contrôle du bus, effectue la lecture ou l‘écriture mémoire à l adresse contenue dans son registre et libère le bus. Il incrémente ensuite cette adresse et décrémente son compteur. Lorsque le compteur atteint zéro, le dispositif informe le processeur de la fin du transfert par une interruption. Le principal avantage est que pendant toute la durée du transfert des données, le processeur est libre d effectuer un autre traitement. La seule contrainte est une limitation de ses propres accès mémoire pendant toute la durée de l opération, puisqu il doit parfois retarder certains de ses accès pour permettre au DMA d effectuer les siens (arbitrage pour l accès au bus).")
61
Une architecture possible
Mémoire cache Processeur Mémoire centrale Bus local Bus système Contrôleur DMA Bus E/S UE UE UE Une architecture possible Bus externes Disques Ecran graphique Réseau

62
Système d’exploitation
Le rôle du système d’exploitation A l'occasion d'une E/S, un programme bloqué en attente de données peut être remplacé par un autre. Cette idée de partage du processeur et de la mémoire par plusieurs programmes est mise en œuvre par le système d'exploitation (unix, windows, ...). Le système d'exploitation est un programme charge de faciliter l'utilisation de l'ordinateur et d'en optimiser le fonctionnement. Il gère en particulier les ressources (mémoires, processeur, entrées/sorties) pour les partager entre plusieurs programmes en cours d'exécution (processus). L‘étude des systèmes d'exploitation sort du cadre du cours d'architecture des ordinateurs et fera l'objet de cours spécifiques. Applications Système d’exploitation Langage machine Matériel
. Le système d exploitation est un programme charge de faciliter l utilisation de l ordinateur et d en optimiser le fonctionnement. Il gère en particulier les ressources (mémoires, processeur, entrées/sorties) pour les partager entre plusieurs programmes en cours d exécution (processus). L‘étude des systèmes d exploitation sort du cadre du cours d architecture des ordinateurs et fera l objet de cours spécifiques. Applications. Système d’exploitation. Langage machine. Matériel.")
63
Architecture de processeur avancée : pipeline
Le traitement d'une instruction comprend plusieurs phases. Au lieu de les exécuter séquentiellement on peut chercher à les effectuer en parallèle pour plusieurs instructions successives. Supposons que les phases correspondent aux 3 étapes chercher (CH), décoder (DE), exécuter (EX). Dans une machine pipelinée on aura donc : Instructions/étages instri CH DE EX insti CH DE EX instri CH DE EX au lieu de : Instructions/étages insti CH DE EX instri CH DE EX Le gain de rapidité est dû à l'augmentation du flux des instructions traitées et non pas à la rapidité de traitement de chaque instruction. Chaque étage du pipeline a comme durée celle de la phase la plus longue (car les 3 s'exécutent en parallèle). De plus, en cas de branchement conditionnel, on peut commencer le traitement des instructions qui suivent de manière inutile. Dans certains processeurs on tente de prédire si le branchement va avoir lieu ou non en fonction d'une table des exécutions passées des branchements (‘anticipation de branchement').
, décoder (DE), exécuter (EX). Dans une machine pipelinée on aura donc : Instructions/étages instri CH DE EX. insti+1 CH DE EX. instri+2 CH DE EX. au lieu de : Instructions/étages insti+1 CH DE EX. instri+2 CH DE EX. Le gain de rapidité est dû à l augmentation du flux des instructions traitées et non pas à la rapidité de traitement de chaque instruction. Chaque étage du pipeline a comme durée celle de la phase la plus longue (car les 3 s exécutent en parallèle). De plus, en cas de branchement conditionnel, on peut commencer le traitement des instructions qui suivent de manière inutile. Dans certains processeurs on tente de prédire si le branchement va avoir lieu ou non en fonction d une table des exécutions passées des branchements (‘anticipation de branchement ).")
64
Architecture de processeur avancée : superscalaire
Les processeurs superscalaires possèdent plusieurs pipelines qui fonctionnent en parallèle. Un superscalaire de degré n possède n pipelines parallèles. On a donc du parallélisme entre instructions en plus du recouvrement des phases à l'intérieur des instructions. Ce parallélisme est complexe a gérer a cause des synchronisations nécessaires. En outre, il n'est pas toujours possible d'utiliser a plein tous les pipelines. Exemple d'exécution sur un superscalaire de degré 4 : Instructions/étages instri CH DE EX insti CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX instri CH DE EX Ex : Pentium 4 processeur CISC avec instructions décomposées en micro-opérations de taille fixe. Plusieurs pipelines de 20 étages (20 étapes/micro-op).
.")
65
Mesures de performances : théorie
La vitesse de l'horloge cadence les instructions. A partir de là, on peut calculer le temps CPU pour un programme P comme le produit du nombre de cycles nécessaires pour P par le temps de cycle d'horloge (TCH). Pour déterminer le nombre de cycles nécessaires pour P, on peut multiplier le nombre d'instructions exécutées par le processeur (NI) par le nombre moyen de cycles par instruction pour ce processeur (CPI) : tempsCPU = NI x CPI x TCH Pour réduire tempsCPU on peut soit augmenter la fréquence de l'horloge (mais il existe une limite matérielle à l'amélioration de la technologie), soit réduire le CPI (choix du jeu d'instruction ou accès mémoire plus rapides), soit réduire le nombre d'instructions NI (compilateur optimisant). On peut calculer les MIPS (Millions d'Instructions Par Seconde) par : MIPS=FH/CPI, où FH est la fréquence d'horloge en MHz (million de cycles/s). Sur le même modèle existent également les MégaFlops (millions d'instructions flottantes – sur réels- par seconde). Les MIPS et les MégaFlops ne permettent pas réellement de comparer les machines car ils dépendent de la ‘quantité de travail' effectuée par les instructions qui peut varier beaucoup entre les architectures CISC ou RISC. De plus, les performances d'une machine dépendent non seulement du processeur mais de tous les composants qui y sont reliés - bus, UE, mémoire centrale et unités de stockage externe - ainsi que du système d'exploitation.
. Pour déterminer le nombre de cycles nécessaires pour P, on peut multiplier le nombre d instructions exécutées par le processeur (NI) par le nombre moyen de cycles par instruction pour ce processeur (CPI) : tempsCPU = NI x CPI x TCH. Pour réduire tempsCPU on peut soit augmenter la fréquence de l horloge (mais il existe une limite matérielle à l amélioration de la technologie), soit réduire le CPI (choix du jeu d instruction ou accès mémoire plus rapides), soit réduire le nombre d instructions NI (compilateur optimisant). On peut calculer les MIPS (Millions d Instructions Par Seconde) par : MIPS=FH/CPI, où FH est la fréquence d horloge en MHz (million de cycles/s). Sur le même modèle existent également les MégaFlops (millions d instructions flottantes – sur réels- par seconde). Les MIPS et les MégaFlops ne permettent pas réellement de comparer les machines car ils dépendent de la ‘quantité de travail effectuée par les instructions qui peut varier beaucoup entre les architectures CISC ou RISC. De plus, les performances d une machine dépendent non seulement du processeur mais de tous les composants qui y sont reliés - bus, UE, mémoire centrale et unités de stockage externe - ainsi que du système d exploitation.")
66
Mesures de performances : pratique
Mesurer le temps d'exécution de programmes réels. Mais ce temps peut se définir de plusieurs manières : temps total pour terminer la tâche (en incluant les accès disques et mémoire, les opérations d‘E/S, le temps CPU (processeur) utilisé pour la tâche, le temps CPU utilisé par le système d'exploitation pour cette la tâche, etc. En pratique, l'approche la plus réaliste pour mesurer les performances consiste à réaliser des tests (‘benchmarks'). Ils comparent les machines par types d'applications (calculs numériques, jeux, bureautique, etc.) en utilisant des programmes et des données communes. Les résultats de certains tests sont publiés et permettent des comparaisons à peu près fiables entre machines. C'est le cas par exemple des test du SPEC (Standard Performance Evaluation Corporation - utilisés par beaucoup de constructeurs.
 utilisé pour la tâche, le temps CPU utilisé par le système d exploitation pour cette la tâche, etc. En pratique, l approche la plus réaliste pour mesurer les performances consiste à réaliser des tests (‘benchmarks ). Ils comparent les machines par types d applications (calculs numériques, jeux, bureautique, etc.) en utilisant des programmes et des données communes. Les résultats de certains tests sont publiés et permettent des comparaisons à peu près fiables entre machines. C est le cas par exemple des test du SPEC (Standard Performance Evaluation Corporation - utilisés par beaucoup de constructeurs.")
Présentations similaires











>")













