Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Systèmes multitâches et systèmes temps réels

2
Systèmes temps réel

3
Caractérisation Chaque tâche d'un procédé de type contrôle-commande, est exécuté en réponse à des sollicitations externes ou internes avec des contraintes de temps fixées par l'évolution du procédé à contrôler

4
Contraintes de temps Pour chaque événement Ei, il est nécessaire de calculer un ensemble de fonctions Fj dépendant de l'état Q de la commande. La durée du calcul ty est fonction des algorithmes utilisés et de la puissance du processeur. Le procédé contrôlé fixe une échéance de temps Te pour chaque calcul. La présence de cette échéance (contrainte de temps) caractérise un système temps réel.
 caractérise un système temps réel..")
5
Classification On distingue les systèmes à : Contraintes de temps faible et variées (t très inférieur à Te). Contraintes de temps faible avec quelques événements contraignants, Contraintes de temps fortes (t voisin de Te).
..")
6
Contraintes de temps faibles Peut être solutionné par une programmation en mode bouclé appelée également gestion des entrées - sorties par scrutation. Les bouclages en arrière en attente d'événements sont interdits. Le programme doit pouvoir scruter en permanence les entrées avec un temps ty < Te

7
Boucle de scrutation L’inconvénient majeur de ce mode de programmation est qu’il fait cohabiter des contraintes de temps faible avec contrainte de temps fortes, ces dernières imposant le temps de cycle. Ce mode de programmation est très utilisé essentiellement du fait de sa simplicité.

8
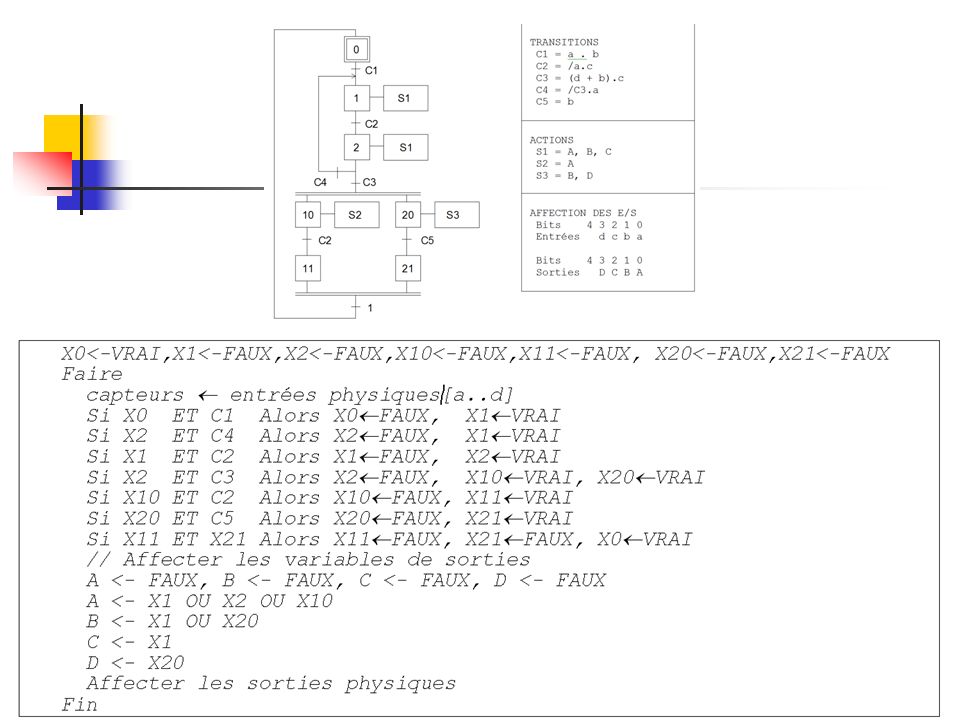
Exemple 1 Programmation d’un grafcet

9
Exemple 1

11
Conséquences L'algorithme montre que les entrées sont échantillonnées à une vitesse fonction du nombre d'instructions situées dans la boucle de scrutation. Les conséquences qui en résultent sont les suivantes : Lors de l'écriture du programme, il est impossible de prévoir l'intervalle de temps séparant deux acquisitions. Tout algorithme temps réel basé sur la vitesse de scrutation est par essence faux. Toutes les entrées sont échantillonnées à la même vitesse ce qui peut être, en fonction du type d'entrée ou inutilement rapide ou trop lent. Tous traitement supplémentaire doit être inclus dans la boucle de scrutation.

12
Exemple 2 Programmation d'un terminal

13
Cahier des charges du terminal Contraintes de temps suivantes : Vitesse de frappe maximale : 10 caractères / secondes ; Vitesse d'affichage constatée sur l'écran : 1000 caractères / secondes ; Vitesse de réception ou d'émission des caractères sur la ligne: 50..38400 Bauds, format 8 bits, 1 bit de start, 1 bit de stop (10 bits au total).
.")
14
Tâches utilisées Le diagramme fait apparaître deux tâches : Une tâche affichant le caractère présent sur le port série. Cette tâche est déclenchée par la réception d'un caractère (tâche lire). Une tâche effectuant l'acquisition et l'envoi des caractères frappés au clavier. Cette tâche est déclenchée par la frappe d'un caractère (tâche afficher).
. Une tâche effectuant l acquisition et l envoi des caractères frappés au clavier. Cette tâche est déclenchée par la frappe d un caractère (tâche afficher)..")
15
Détermination des contraintes de temps Pour une vitesse de réception de 600 Bauds. tâche lire Te1 = 0,1s (indépendant de la vitesse de réception), tâche afficher Te2 = (1+8+1)/600 = 16,7 10-3 s
, tâche afficher Te2 = (1+8+1)/600 = 16, s.")
16
Vérification du respect des contraintes de temps On prend en compte le cas le plus défavorable, c'est à dire lorsque qu'un caractère doit être affiché sur l'écran et qu'un caractère est lu au clavier. Nous supposerons pour simplifier, que le temps scrutation (ty) est essentiellement liée à la vitesse d'affichage (1000 caractères/secondes). Le temps de cycle est donc de :ty = 10 -3 s La contrainte de temps la plus forte est : Te2 = (1 + 8 + 1) / 600 = 16,7 10-3 s. Ce qui vérifie ty << Te2 << Te1.
 est essentiellement liée à la vitesse d affichage (1000 caractères/secondes). Le temps de cycle est donc de :ty = s La contrainte de temps la plus forte est : Te2 = ( ) / 600 = 16, s. Ce qui vérifie ty << Te2 << Te1..")
17
Contrainte non satisfaite Si la vitesse de réception des caractères est 19200 Bauds, la contrainte sera de : Te2 = 10 / 19200 = 0,52 10-3 s; Te < ty Ce qui ne vérifie plus ty << Te2, tout en satisfaisant Te1. La contrainte Te2 n'étant pas satisfaite, le terminal perdra des caractères reçus sur la ligne série mais par contre ne perdra aucun caractère frappé au clavier !

18
Conclusions La programmation par scrutation ne convient pas dans les cas de contraintes de temps hétérogènes. On en conclut qu'il faut dissocier les tâches à fortes contraintes de temps, de celles à faibles contraintes de temps, par un traitement hors de la boucle scrutation.

19
Contraintes de temps faibles avec quelques événements contraignants Si le temps de cycle de la boucle de scrutation ne permet pas de satisfaire un nombre réduit de contraintes, on associe les fonctions concernées par ces contraintes à des interruptions matérielles. Chaque interruption peut être liée à un ou plusieurs événements. Lorsque l'événement se produit, l'interruption arrête l'exécution de la boucle de scrutation et lance un programme appelé tâche matérielle. Le calculateur sera ainsi synchronisé sur ces événements et exécutera les traitements liés aux interruptions en suspendant le programme en exécution

20
Intérêt de cette solution Les événements liés aux interruptions ne nécessitent aucune attention dans la boucle de scrutation. La durée de la boucle n'a pas d'importance par rapport à l'événement considéré si elle ne gère pas un procédé possédant des contraintes de temps. La boucle de scrutation n'est plus ralentie par le test systématique de présence d'événements asynchrones, l'efficacité du traitement réalisé s'en trouve accru. Le rythme d'échange des informations est fixé par le dispositif lié aux interruptions en non par des contraintes de programmation de la boucle de scrutation.

21
Conséquences de la présence des interruptions Lorsque survient une interruption, la boucle de scrutation est stoppée et peut même s'arrêter complètement si plusieurs interruptions surviennent à un rythme très rapide. La programmation des échanges de données entre la boucle de scrutation et le(s) programme(s) d'interruption peut s'avérer délicate. Il n'est pas trivial de réaliser des échanges fiables entre des programmes fonctionnant de façon asynchrone. Ce point sera particulièrement abordé par la suite.
 programme(s) d interruption peut s avérer délicate. Il n est pas trivial de réaliser des échanges fiables entre des programmes fonctionnant de façon asynchrone. Ce point sera particulièrement abordé par la suite..")
22
Vérification des contraintes de temps Le traitement d'une interruption allonge le temps de cycle du programme interrompu. Plusieurs cas doivent êtres envisagés selon que les interruptions sont emboîtées ou non.

23
Cas d'une seule interruption (I1) de récurrence f1=1/T1 Soient deux procédés possédant des contraintes de temps hétérogènes. Le traitement du procédé à forte contrainte (P1) est géré par interruption, le traitement du procédé à faible contrainte de temps (P0) est géré dans la boucle de scrutation : On connaît : T1 période de l’interruption I1. Ce temps correspond à l’échéance de temps fixé par le procédé à contrôler : Te1 ty1 temps de calcul (continu) de la fonction P1. Te0 échéance de temps du procédé géré par P0 Pour ne pas perdre des signaux d'interruptions ou pour éviter une récursion infinie ont doit avoir : ty1 < T1
 est géré par interruption, le traitement du procédé à faible contrainte de temps (P0) est géré dans la boucle de scrutation : On connaît : T1 période de l’interruption I1. Ce temps correspond à l’échéance de temps fixé par le procédé à contrôler : Te1 ty1 temps de calcul (continu) de la fonction P1. Te0 échéance de temps du procédé géré par P0 Pour ne pas perdre des signaux d interruptions ou pour éviter une récursion infinie ont doit avoir : ty1 < T1.")
24
Cas d'une seule interruption (I1) de récurrence f1=1/T1 Lorsque le programme doit gérer plusieurs interruptions simultanées, deux cas sont à envisager : interruptions traitées séquentiellement interruptions traitées parallèlement.
 de récurrence f1=1/T1 Lorsque le programme doit gérer plusieurs interruptions simultanées, deux cas sont à envisager : interruptions traitées séquentiellement interruptions traitées parallèlement.")
25
Cas de plusieurs interruptions traités de façon séquentielles Soient : T1, période de l’interruption I1, fréquence f 1 = 1 / T 1 ty1, temps de calcul (continu) de la fonction P1. T2, période de l’interruption I2, fréquence f 2 = 1 / T 2, et T2 < T1. ty2, temps de calcul (continu) de la fonction P2. Te0, échéance de temps du procédé géré par P0
 de la fonction P2. Te0, échéance de temps du procédé géré par P0.")
27
Cas d'interruptions emboîtées Dans ce modèle, une interruption peut être exécutée durant l'exécution d'une interruption moins prioritaire. L'interruption la plus prioritaire doit être celle de récurrence la plus élevée : Soient : T1, période de l’interruption I1, ty1,temps de calcul (continu) de la fonction P1. T2, période de l’interruption I2, et T2 < T1 ty2,temps de calcul (continu) de la fonction P2. Te0,échéance de temps du procédé géré par P0
 de la fonction P1. T2, période de l’interruption I2, et T2 < T1 ty2,temps de calcul (continu) de la fonction P2. Te0,échéance de temps du procédé géré par P0.")
28
Cas d'interruptions emboîtées (2)
")
29
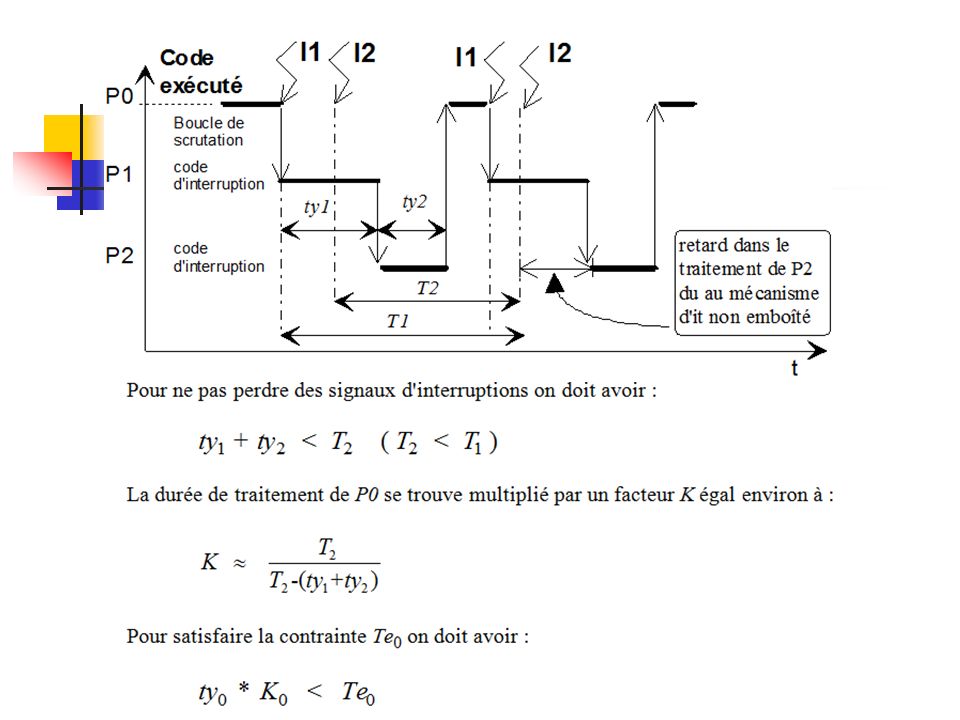
Cas d'interruptions emboîtées Pour ne pas perdre de signaux d'interruptions et pour éviter une récursion infinie ont doit avoir : ty2 < T2 Le traitement de l'interruption P2 emboîtée dans T1 allonge le temps de traitement ty1 d'un facteur K2 égal à : Pour satisfaire la contrainte T1 doit avoir : Le traitement de l'interruption P1 allonge à son tour le temps de traitement de la boucle P0 d'un facteur: Pour satisfaire la contrainte Te0 doit avoir :

31
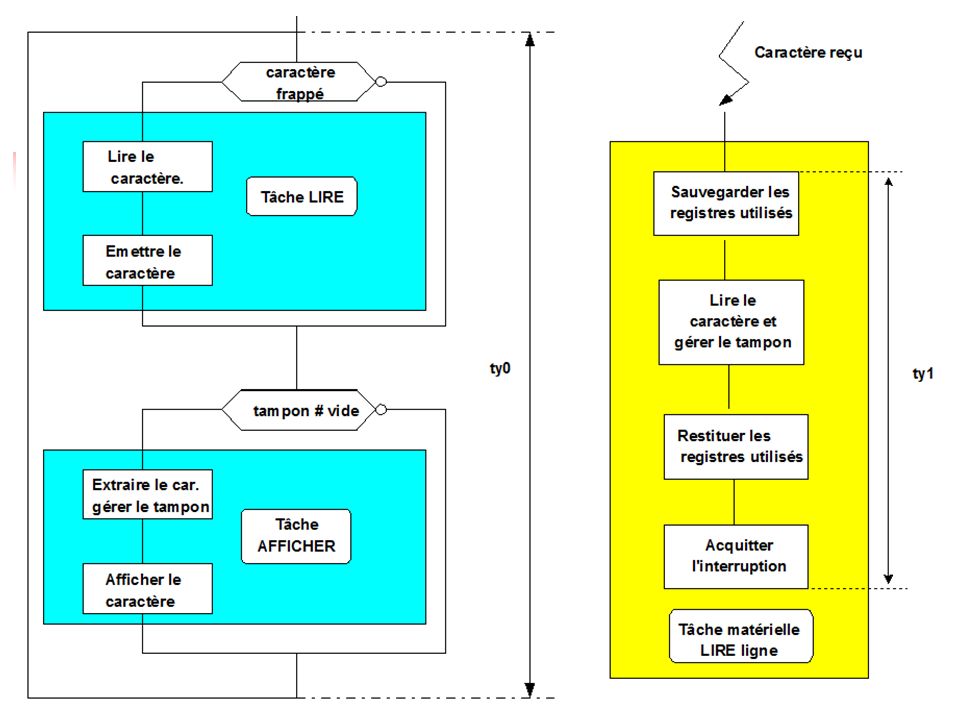
Exemple 3 Terminal avec réception de caractères à vitesse élevée

32
Le diagramme comporte trois tâches : Une tâche déclenchée par l'interruption liée à la réception d'un caractère (tâche lire_ligne). Celle-ci place le caractère reçu dans un tampon (FIFO). Le débordement du tampon n'est pas envisagé. Une tâche, dont l'exécution dépend d'une condition interne (taux de remplissage du tampon) : afficher. Une tâche dont l'exécution dépend de conditions externes non liées à une interruption (caractère frappé) : lire.
. Le débordement du tampon n est pas envisagé. Une tâche, dont l exécution dépend d une condition interne (taux de remplissage du tampon) : afficher. Une tâche dont l exécution dépend de conditions externes non liées à une interruption (caractère frappé) : lire..")
35
SYSTÈMES MULTITÂCHES ET NOYAU TEMPS RÉEL

36
Diagramme d’état d’une tâche

37
Politiques d'ordonnancement à priorité circulaire

38
Politiques d'ordonnancement à priorité pure

39
Politiques d'ordonnancement à priorité mixte

40
Systèmes avec ou sans réquisition du processeur Les systèmes multitâches et les noyaux temps réels se divisent en deux catégories : Noyaux sans réquisition du processeur (no preemptive scheduling) ou encore appelés systèmes coopératifs, Noyaux avec réquisition du processeur (preemptive scheduling).
 ou encore appelés systèmes coopératifs, Noyaux avec réquisition du processeur (preemptive scheduling).")
41
Systèmes coopératifs Avec un noyau coopératif, le programmeur décide de l’instant de commutation par un appel explicite. Selon la situation présente lors de l'appel, l'ordonnanceur décide, en fonction des priorités des tâches en cours, si celle-ci doit ou non se poursuivre. Si la priorité des tâches éligibles est supérieure à la tâche courante, le noyau la suspend et lance la tâche de priorité maximale. Ce type de noyau est très efficace mais moins tolérant aux erreurs de conception. Si pour une raison quelconque une tâche se bloque (erreur de programmation ou erreur matérielle), l'ensemble des tâches se bloque également. Windows 3.1 est un exemple typique de système coopératif.
, l ensemble des tâches se bloque également. Windows 3.1 est un exemple typique de système coopératif..")
42
Noyau préemptif Un noyau avec réquisition du processeur alloue celui- ci de façon transparente aux tâches (toujours en fonction des priorités en cours). La tâche qui se trouve préemptée n'a aucune possibilité de le savoir. Ce mécanisme est réalisé par un programme d'interruption à forte priorité activé par une horloge. Ce programme d'interruption explore les files de tâches prêtes ou suspendues et attribue le processeur à l'une d'elle suivant une politique d'ordonnancement adoptée.

43
Temps de commutation, temps de latence Le temps de commutation est le temps mis par l’ordonnanceur pour commuter une nouvelle tâche. Les sections de code non interruptibles perturbent le fonctionnement des systèmes coopératifs et surtout préemtif. Ces sections doivent être très courtes de façon à diminuer le temps s'écoulant en apparition d'une interruption et son traitement effectif. Si ce temps est prédictif le système multitâches est du type temps réel durs, dans le cas contraire il est qualifié de temps réels mou.

44
Temps de commutation Application comportant deux tâches avec le même niveau de priorité

45
Temps de latence Temps de retard maximal s’écoulant entre l'apparition d'une d'interruption et son début de traitement. Ce temps est généralement plus cours que le temps de commutation.

46
Temps réel dur, temps réel mou Un noyau temps réel mou ne spécifie ni les temps de commutation de contexte, ni les temps de latence. Un noyau temps réel dur garanti un temps maximal de commutation de contexte et un temps de retard maximal entre l'apparition d'une d'interruption et son début de traitement. Les temps de commutation de contexte sont de l'ordre de 1 à 100 microsecondes (en fonction du noyau et du processeur), soit 10000 commutations / secondes dans le cas le plus défavorable. Le temps de latence est généralement inférieur à 50 microsecondes.
, soit commutations / secondes dans le cas le plus défavorable. Le temps de latence est généralement inférieur à 50 microsecondes..")
47
Etude d’un noyau temps réel : Mtr86 Mtr86 est un noyau temps réel conçu en 1986 à l’origine pour les processeurs Intel et pour MsDos ®. Depuis il existe pour différents processeurs et différentes plateformes. Les principales versions sont : Mtr86 Dos (temps réel dur) Mtr86-68K (temps réel dur) Mtr86Win32 (temps réel mou) Mtr86Objet (temps réel mou)
 Mtr86-68K (temps réel dur) Mtr86Win32 (temps réel mou) Mtr86Objet (temps réel mou).")
48
Primitives de création des tâches Lancement du noyau, création des tâches, activation des tâches La priorité peut être égale à PRIORITE_NORMALE ± 3, PRIORITE_MINIMALE, PRIORITE_MAXIMALE La taille de la pile doit être de 10K au minimum int start ( TACHE_ADR ard tache_init, int taille_pile ); HANDLE cree ( TACHE_ADR tache_adr, unsigned priorite, unsigned taillePile); void active ( HANDLE tache ); Identification des tâches La tâche est identifié à la création par un HANDLE, ce HANDLE peut être relu par la tâche en exécution (primitive tache_c). On peut associer un entier une tâche à partir de son HANDLE (tâche init = N° 1) HANDLE tache_c ( void); DWORD tache_id ( HANDLE hTache);
 HANDLE tache_c ( void); DWORD tache_id ( HANDLE hTache);.")
49
Primitives de gestion des tâches Réglage du la durée du quantum (d_tic) La durée du quantum est par défaut de 10 ms sur NT4 est de 15 ms avec XP (10 ms avec XP SP2). La durée du quantum est réglable de 50 à 1 ms par pas de 1 ms Suspension et destruction d’une tâche Une tâche s’auto suspend par la primitive dort(durée) avec durée en ms (0 correspond à un temps infini). La primitive retourne TIM ou OK suivant e mode de réveil (voir reveille) reveille(handle_tache) permet de relancer une tache suspendue. L’appel de cette pimitive fait retourner OK à la primitive dort. Réglages des priorités du processus et des tâches la priorité du processus est réglée par la primitive classe_priorite(classe). On consultera le fichier mtr86Win32.h pour connaitre les classes possibles. la priorité des tâches est réglée par tache_priorite(handle_tâche, priorité). DWORD dort ( DWORD t ); void reveille ( HANDLE hTache ); void classe_priorite ( DWORD dwPrioriteClasse ); void tache_priorite ( HANDLE hTache, DWORD dwPrioriteTache );
 avec durée en ms (0 correspond à un temps infini). La primitive retourne TIM ou OK suivant e mode de réveil (voir reveille) reveille(handle_tache) permet de relancer une tache suspendue. L’appel de cette pimitive fait retourner OK à la primitive dort. Réglages des priorités du processus et des tâches la priorité du processus est réglée par la primitive classe_priorite(classe). On consultera le fichier mtr86Win32.h pour connaitre les classes possibles. la priorité des tâches est réglée par tache_priorite(handle_tâche, priorité). DWORD dort ( DWORD t ); void reveille ( HANDLE hTache ); void classe_priorite ( DWORD dwPrioriteClasse ); void tache_priorite ( HANDLE hTache, DWORD dwPrioriteTache );.")
50
Structure d’une application multitâche Mtr86Win32 Fichiers à inclure

51
Structure d’une application multitâche Mtr86Win32 (2)
")
52
Structure d’une application multitâche Mtr86Win32 objet

53
Problèmes posés par l’accès concurrent

54
Sections critiques Une section critique est une zone de programme où se produit un accès concurrent et dont le résultat des traitements est fonction de l’ordonnancement des tâches ou des processus. Un programme multitâche ou multiprocessus absolument verrouiller l’accès aux sections critiques en en autorisant l’accès à une seule tâche à la fois. La multiplicité des sections critiques produit à un code peu efficient du fait des appels au noyau destiné à verrouiller les sections critiques.

55
Verrouillage des sections critiques Dans un même processus moniteurs, gestionnaire de ressource, mutex, sémaphores.

56
Verrouillage des sections critiques Entre deux processus mutex, sémaphores.

57
Verrouillage des sections critiques par moniteur (au sein d’un même processus) Permet le verrouillage rapide d’une seule ressource généralement l’écran Moniteurs dans Mtr86 Dos & Mtr86 Win32
 Permet le verrouillage rapide d’une seule ressource généralement l’écran Moniteurs dans Mtr86 Dos & Mtr86 Win32")
58
Verrouillage des sections critiques gestionnaire de ressources (au sein d’un même processus) Méthode plus générale Permet de verrouiller plusieurs ressources Moniteurs dans Mtr86 Dos & Mtr86 Win32
 Méthode plus générale Permet de verrouiller plusieurs ressources Moniteurs dans Mtr86 Dos & Mtr86 Win32")
59
Verrouillage des sections critiques dans Mtr86 Objet (au sein d’un même processus)
")
60
Verrouillage des sections critiques dépassant la frontière des processus Mtr86 Win32 Seuls les sémaphores peuvent être utilisés. La méthode à suivre est la suivante

61
Verrouillage des sections critiques dépassant la frontière des processus Mtr86 Win32 Objet

62
Verrouillage des sections critiques dépassant la frontière des processus Mtr86 Win32

63
Verrouillage des sections critiques dépassant la frontière des processus Mutex Une tâche devient propriétaire d'un mutex après l'opération lock et peut alors effectuer plusieurs fois cette opération sans se bloquer. Par contre toute autre tâche se bloquera sur cette opération. L'opération unlock fait perdre la propriété du mutex à l'auteur de la requête et une autre tâche pourra devenir propriétaire du mutex.

64
Modèles standard d'échanges de données entre taches et processus L'exclusion mutuelle des sections critiques est un mécanisme rudimentaire de verrouillage lorsqu'il est utilisé pour échanger des données. Dans ce type d'échange, il n'y a aucune synchronisation entre les protagonistes. Le seul service fourni par l'exclusion mutuelle est la garantie qu'une donnée est lue ou écrite de façon atomique. Lorsqu'on désire synchroniser les échanges entre protagonistes deux modèles sont utilisés : Le modèle producteur-consommateur Le modèle lecteur-rédacteur

65
Modèle producteur consommateur Ce modèle est la base de nombreux échanges de données que ce soit au cœur d'un système d'exploitation ou au sein d'applications. Son importance est telle que la plupart des noyaux fournissent directement ce type d'échange (tubes, messages,...). Les règles de production et de consommation sont les suivantes : Une donnée ne peut être consommée que si a été produite, Une donnée ne peut être produite que si la donnée précédente a été consommée, Il est résulte qu'une même donnée ne peut être consommée ou produite plusieurs fois. L'implémentation de ce mécanisme est basé sur la propriété des sémaphores.
. Les règles de production et de consommation sont les suivantes : Une donnée ne peut être consommée que si a été produite, Une donnée ne peut être produite que si la donnée précédente a été consommée, Il est résulte qu une même donnée ne peut être consommée ou produite plusieurs fois. L implémentation de ce mécanisme est basé sur la propriété des sémaphores..")
66
Les sémaphores Les sémaphores ont été proposés pour la première fois en 1965 par E. W. Dijkstra. Dijkstra propose de compter le nombre de tâches endormies ou les réveils en attente à l'aide d'une variable appelée sémaphore. Un sémaphore est constitué d'un entier s signé pouvant prendre des valeurs positives et négatives ou nulles et d'une file d'attente mémorisant (indirectement) les contextes des tâches ou processus en attente. L'accès à la variable s est effectué dans une section critique. Deux primitives permettent de manipuler le sémaphore : P(s) et V(s).
 les contextes des tâches ou processus en attente. L accès à la variable s est effectué dans une section critique. Deux primitives permettent de manipuler le sémaphore : P(s) et V(s)..")
67
Les sémaphores (2) Code atomique
 Code atomique")
68
Implémentation des sémaphores dans Mtr86

69
Implémentation des sémaphores dans Mtr86 Win32 Objet

70
Implémentation du modèle producteur consommateur

71
Exemple objet

72
Exemple objet (2)
")
74
Modèle producteur consommateur avec stocks Le modèle producteur consommateur simple est très peut utilisé puisqu'il synchronise son exécution sur l'acteur le plus lent. En mémorisant les données produites dans une file fifo, il devient possible de produire et de consommer les données à des vitesses différentes. lorsque la file est pleine le producteur se synchronise sur le consommateur, lorsque la file est vide le consommateur se synchronise sur le producteur.

75
Modèle producteur consommateur avec stocks (2)
")
76
Modèle producteur consommateur avec stocks (3)
")
77
Modèle producteur consommateur avec stocks (objet)
")
78
Implémentation du modèle producteur consommateur dans les systèmes multitâches Vu l'importance du modèle producteur consommateur, celui-ci est directement implémenté dans la plupart systèmes multitâches et les noyaux temps réel. Cette implémentation porte le nom de tube, pipe,..., messages.

79
Implémentation du modèle producteur consommateur dans Mtr86 : tubes Un tube (ou pipe) est crée par l'appel suivant :
 est crée par l appel suivant :")
80
Implémentation du modèle producteur consommateur dans Mtr86 : tubes (2)
")
81
Tube de communication inter processus dans Mtr86 Jusqu'à la version 2.0, Mtr86 Win32 et Mtr86 Win32 Objet permettaient une communication inter processus très efficace en s'appuyant sur une particularité de l'éditeur de lien de Visual C non implémentés dans les autres environnements de développement. A partir de la version 2.01 la communication inter processus s'appuie sur le mappage en mémoire du fichier de pagination. Cette méthode moins efficace est utilisable avec tous les environnements de développement. Noter que ces détails techniques sont totalement transparent pour l'application.

82
Tube de communication inter processus dans Mtr86

83
Modèle lecteur - rédacteur Contrairement au modèle producteur - consommateur, le modèle lecteur - rédacteur fait appel à plusieurs rédacteurs et plusieurs lecteurs simultanés. Le modèle lecteur - rédacteur est le modèles de base dans les applications de type client serveur. Il se conforme aux règles suivantes : Une donnée peut être lue simultanément par plusieurs lecteurs sans consommation de celle-ci. Un seul rédacteur à la fois peut modifier une donnée. Lorsqu'un rédacteur est actif, tous les lecteurs sont interdit de lecture. Lorsqu'un ou plusieurs lecteurs sont actifs tous les rédacteurs sont interdit d'écriture. Le problème se trouve simplifié lorsque le nombre de lecteurs et de rédacteurs et connu par avance et que le noyau autorise les opérations P et V avec un nombre différents de 1.

84
Modèle lecteur – rédacteur (2) Hypothèses : L'implémentation des sémaphores permet que les opérations P et V avec un incrément de 1. Problème posé : Un nombre de lecteurs et de rédacteurs connus par avance, lisent et écrivent de façon concurrente dans une zone de mémoire commune :

85
Modèle lecteur – rédacteur (3) Le modèle lecteur – rédacteur est implémenté dans quatre fonctions : demande_ de_lecture demande_ecriture fin_de_lecture fin_ecriture avant d'effectuer un accès à la donnée, le lecteur et le rédacteur appellent respectivement une fonction demande_ de_lecture et demande_ecriture à la fin de l'accès à la donnée, le lecteur le lecteur et le rédacteur appellent respectivement une fonction fin_de_lecture et fin_ecriture
 Le modèle lecteur – rédacteur est implémenté dans quatre fonctions : demande_ de_lecture demande_ecriture fin_de_lecture fin_ecriture avant d effectuer un accès à la donnée, le lecteur et le rédacteur appellent respectivement une fonction demande_ de_lecture et demande_ecriture à la fin de l accès à la donnée, le lecteur le lecteur et le rédacteur appellent respectivement une fonction fin_de_lecture et fin_ecriture")
86
Modèle lecteur – rédacteur (4) Etude préalable : 1. Chaque lecteur et chaque rédacteur effectuant une tentative d'accès à la donnée alors qu'un rédacteur est actif se bloque sur une opération P. 2. Si aucun rédacteur est actif, tout lecteur peut accéder à la donnée. 3. Si au moins un lecteur est actif, tout rédacteur effectuant une tentative d'accès à la donnée se bloque sur une opération P. 4. Lorsqu'un rédacteur a terminé d'accéder à la donnée, il doit ou relancer chaque lecteurs bloqués par une opération V (autant d'opérations que de lecteurs bloqués) ou un des rédacteurs bloqué par une opération V. Deux algorithmes sont possibles : donner la priorité aux lecteurs ou aux rédacteurs. 5. Lorsque le dernier lecteur a terminé d'accéder à la donnée, il doit relancer un rédacteur si au moins un rédacteur est bloqué.
 ou un des rédacteurs bloqué par une opération V. Deux algorithmes sont possibles : donner la priorité aux lecteurs ou aux rédacteurs. 5. Lorsque le dernier lecteur a terminé d accéder à la donnée, il doit relancer un rédacteur si au moins un rédacteur est bloqué..")
87
Modèle lecteur – rédacteur (5) Un sémaphore est attribué aux les lecteurs (sl) et rédacteurs (sr). Des points 1 et 2 on en déduit qu'il faut connaître l'opération en cours : on utilisera une variable d'état r signalant qu'un rédacteur est actif. Des points 3 et 5 on en déduit qu'il faut connaître le nombre de lecteurs actifs et le nombre de rédacteurs bloqués afin de pouvoir appliquer une opération V valide. La variable d'état nl comptera le nombre de lecteurs actifs et rb comptera le nombre de rédacteurs bloqués. Du point 4 on en déduit qu'il faut compter les lecteurs bloqués : On utilisera une variable d'état lb.

88
Modèle lecteur – rédacteur (6) Sans tenir compte des sections critiques on en déduit l'algorithme de demande_de_lecture : Cet algorithme présente des sections critiques : r, lb, nl sont des variables globales modifiés de façon concurrente.
 Sans tenir compte des sections critiques on en déduit l algorithme de demande_de_lecture : Cet algorithme présente des sections critiques : r, lb, nl sont des variables globales modifiés de façon concurrente.")
89
Modèle lecteur – rédacteur (7) En verrouillant les sections critiques avec le gestionnaire de ressource, l'algorithme précédent devient :
 En verrouillant les sections critiques avec le gestionnaire de ressource, l algorithme précédent devient :")
90
Modèle lecteur – rédacteur (8) Cet algorithme présente une erreur subtile: il existe une zone de section critique non verrouillée : il faut un temps non nul entre la fin de l'opération P et le verrouillage effectif de la section critique :
 Cet algorithme présente une erreur subtile: il existe une zone de section critique non verrouillée : il faut un temps non nul entre la fin de l opération P et le verrouillage effectif de la section critique :")
91
Modèle lecteur – rédacteur (9) Finalement l'algorithme correct est donné ci-dessous :
 Finalement l algorithme correct est donné ci-dessous :")
92
Modèle lecteur – rédacteur (10) Fonction fin_de_ lecture
 Fonction fin_de_ lecture")
93
Modèle lecteur – rédacteur (11) Fonction demande_ecriture
 Fonction demande_ecriture")
94
Modèle lecteur – rédacteur (12) Fonction fin_ecriture avec priorité lecteurs
 Fonction fin_ecriture avec priorité lecteurs")
95
Synchronisations des tâches est des processus Problème posé Il s’agit de synchroniser plusieurs tâches ou un processus entre eux. Deux types de mécanisme peuvent être utilisés : Mécanismes de synchronisation directs : ils désignent directement la tâche à synchroniser Mécanismes de synchronisation indirects : désignent indirectement la tâche à synchroniser à travers un objet du noyau.

96
Mécanismes de synchronisation directs Ces mécanismes utilisent les primitives dort et réveille : une tâche attend un signal de synchronisation en se suspendant (pour une durée bornée ou non) à l'aide le la primitive dort, une ou plusieurs autres tâches désignent la tâche à relancer à l'aide de la primitive reveille.
 à l aide le la primitive dort, une ou plusieurs autres tâches désignent la tâche à relancer à l aide de la primitive reveille.")
97
Mécanismes de synchronisation directs (2) L'implémentation des primitives dort et reveille est fonction du type de noyau : dans les noyau temps réels "dur", les signaux de réveil ne sont généralement pas mémorisés alors qu'il le sont toujours dans les noyaux "mou". Ce mécanisme très simple est généralement utilisé pour synchroniser une tâche logicielle sur une tâche matérielle. Exemple : Une tâche (logicielle) lance une opération E/S (par interruption) pour se suspend en appelant la primitive dort. Lorsque l'opération E/S est terminée le périphérique concerné lance une tâche matérielle (programme d'interruption) qui relance la tâche logicielle initiatrice le l'opération E/S à l'aide de la primitive reveille.
 lance une opération E/S (par interruption) pour se suspend en appelant la primitive dort. Lorsque l opération E/S est terminée le périphérique concerné lance une tâche matérielle (programme d interruption) qui relance la tâche logicielle initiatrice le l opération E/S à l aide de la primitive reveille..")
98
Mécanismes de synchronisation indirects Ces mécanismes utilisent des objets du noyau par l'intermédiaire desquels s'effectue la synchronisation effective. Les objets utilisable pour cet usage sont les sémaphores, les variables événements, les variables rendez-vous. Synchronisation à l'aide de sémaphores Les sémaphores peuvent êtres utilisés de la même manière que les primitives dort et reveille avec cependant moins d'efficacité du fait de la gestion de la file d'attente du sémaphores. Exemple : Une tâche (logicielle) lance une opération E/S puis se suspend en appelant la primitive P(s) avec s initialisé à 0. Lorsque l'opération E/S est terminée, le périphérique concerné lance une tâche matérielle (programme d'interruption) qui effectue la primitive V(s). La tâche initiatrice le l'opération E/S se trouve relancée et récupère la donnée. Ce mécanisme est plus souple que le précédent : il n'est pas nécessaire de connaître la tâche à relancer, mais uniquement le sémaphore concerné.
 lance une opération E/S puis se suspend en appelant la primitive P(s) avec s initialisé à 0. Lorsque l opération E/S est terminée, le périphérique concerné lance une tâche matérielle (programme d interruption) qui effectue la primitive V(s). La tâche initiatrice le l opération E/S se trouve relancée et récupère la donnée. Ce mécanisme est plus souple que le précédent : il n est pas nécessaire de connaître la tâche à relancer, mais uniquement le sémaphore concerné..")
99
Le repas des philosophes Ce problème de synchronisation a été posé et résolu par Dijkstra en 1965. Cinq philosophes sont réunis pour dîner et pour philosopher. Cinq couverts composés d'une assiette et d'une fourchette sont disposés autour d'une table circulaire. Chaque convive a devant lui un plat de spaghetti tellement glissant qu'il faut deux fourchettes pour les manger. Après réflexion les philosophes décident du protocole suivant : Chaque philosophe reste à une place fixe, Pour manger, un philosophe ne peut emprunter que la fourchette de droite ou de gauche, Initialement tous les philosophes pensent, Un philosophe est dans une des trois situations suivantes : il pense, il a faim, ou il mange. Un philosophe mange durant un temps fini. La solution proposée doit permettre à deux philosophes de manger en même temps.

100
Eléments de solution Un philosophe i réalise les opérations suivantes : penser(); prendre_fourchette(gauche); prendre_fourchette(droite); manger(); poser_fourchette(gauche); poser_fourchette(droite);
; prendre_fourchette(gauche); prendre_fourchette(droite); manger(); poser_fourchette(gauche); poser_fourchette(droite);")
101
Eléments de solution (2) Les philosophes étant simulés par des tâches, il faut trouver une solution permettant à deux philosophes de manger en même temps. Le code ci-dessous présente une solution immédiate :

102
Eléments de solution (3) Cette solution est fausse : Supposons que chaque convive prenne la fourchette de gauche en même temps. Aucun ne peut alors prendre la fourchette de droite. Cette situation s'appelle un inter blocage. En supposant que chaque convive vérifie, avant de prendre la fourchette de droite, que celle-ci est libre, le problème échoue pour d'autres raisons : les philosophes prennent en même temps la fourchette de gauche, puis la reposent en voyant que la fourchette de droite n'est pas disponible et recommencent. Il n'y a pas ici d'inter blocage mais les tâches n'évoluent pas. Cette situation s'appelle une famine (au propre et au figuré !). Il existe une solution ne conduisant ni à un inter blocage, ni à une famine : elle consiste à protéger le code se trouvant entre les lignes 5 et 9 par un mécanisme d'exclusion mutuelle. Cette solution ne répond pas au cahier des charges car elle permet à un seul philosophe de manger à la fois.
. Il existe une solution ne conduisant ni à un inter blocage, ni à une famine : elle consiste à protéger le code se trouvant entre les lignes 5 et 9 par un mécanisme d exclusion mutuelle. Cette solution ne répond pas au cahier des charges car elle permet à un seul philosophe de manger à la fois..")
103
Solution du problème Les philosophes étant simulés par de tâches, associons à chaque philosophe i une variable d'état etat[i] pouvant prendre une des valeurs suivantes en fonction de l'état du philosophe : PENSE AFFAME MANGE Le passage de l'état PENSE à l'état MANGE n'est possible que si : Cette ligne signifie que ni le philosophe assis à droite, ni le philosophe assis à gauche du philosophe i n'a pris de fourchette.
![Solution du problème Les philosophes étant simulés par de tâches, associons à chaque philosophe i une variable d état etat[i] pouvant prendre une des valeurs suivantes en fonction de l état du philosophe : PENSE AFFAME MANGE Le passage de l état PENSE à l état MANGE n est possible que si : Cette ligne signifie que ni le philosophe assis à droite, ni le philosophe assis à gauche du philosophe i n a pris de fourchette.](http://images.slideplayer.fr/29/9503293/slides/slide_103.jpg "Solution du problème Les philosophes étant simulés par de tâches, associons à chaque philosophe i une variable d état etat[i] pouvant prendre une des valeurs suivantes en fonction de l état du philosophe : PENSE AFFAME MANGE Le passage de l état PENSE à l état MANGE n est possible que si : Cette ligne signifie que ni le philosophe assis à droite, ni le philosophe assis à gauche du philosophe i n a pris de fourchette.")
104
Solution du problème (2) Ce test est une séquence critique et doit être protégé à l'aide d'un mécanisme d'exclusion mutuel. Si ce test est faux le philosophe passe à l'état AFFAME (la tâche est suspendue) à l'aide d'une opération P(semp[i]), (avec semp[i] initialisé à 0), semp étant un tableau regroupant les sémaphores associés à chaque philosophe. Pour prendre les fourchettes, un philosophe i exécute la séquence suivante :
 à l aide d une opération P(semp[i]), (avec semp[i] initialisé à 0), semp étant un tableau regroupant les sémaphores associés à chaque philosophe. Pour prendre les fourchettes, un philosophe i exécute la séquence suivante :.")
105
Solution du problème (3) Le passage d'un philosophe i de l'état MANGE à l'état PENSE entraîne le réveil des philosophes (tâches) à gauche et à droite si les conditions suivantes sont remplies : leur état doit être affamé, ils doivent disposer de l'autre fourchette. Ces conditions peuvent êtres vérifiées par un appel du type test(gauche) et test(droite) avec test : Comme cette fonction teste des variables d'état à accès concurrent, l'appel de cette fonction doit être verrouillée.
 et test(droite) avec test : Comme cette fonction teste des variables d état à accès concurrent, l appel de cette fonction doit être verrouillée..")
106
Synchronisation à l'aide de variables événements Un événement est une variable spéciale pouvant être dans un état signalé ou non signalé. Lorsque la variable est dans l’état non signalé, une requête d’attente vers cette variable suspend la tâche ayant effectué cette requête jusqu’à ce qu'une primitive du noyau place la variable dans l'état signalé. Comme pour les sémaphores, plusieurs tâches peuvent se mettre en attente, mais contrairement à l'opération V(s) qui ne relance qu'une seule tâche à la fois, le signal envoyé vers une variable événement relance toutes les tâches en attente de cet événement.
 qui ne relance qu une seule tâche à la fois, le signal envoyé vers une variable événement relance toutes les tâches en attente de cet événement..")
107
Mémorisation des signaux Deux cas sont à considérer : Signaux non mémorisés : un signal envoyé vers une variable événement qui ne l'attend pas est perdu. Ce type de fonctionnement est généralement implémenté dans les noyaux temps réel "dur" et correspond assez bien aux besoins de pilotage des procédés industriels. Exemple : une tâche est chargée de surveiller de façon périodique les capteurs T.O.R. d'un procédé quelconque et signale leurs changement d'état à des variables événement. Comme les signaux ne sont pas mémorisés, ils représentent l'état instantané des capteurs. Dans le cas contraire, ces signaux pourraient être pris en compte bien plus tard et ne refléteraient plus l'état instantané du procédé à contrôler.

108
Mémorisation des signaux Deux cas sont à considérer : Signaux mémorisés : les signaux ne sont pas envoyés vers l'éther, ils sont placés dans une file d'attente associée à chaque variable événement. Chaque opération d'attente sur l'événement extrait un signal de la file d'attente. Ce type de fonctionnement est assez bien adapté à la gestion des périphériques d'un ordinateur. Exemple : une tâche lance une opération E/S (en lançant une tâche logicielle ou matérielle) puis se consacre à un autre travail, parallèlement l'opération E/S se poursuit. Lorsque celle – ci est terminée la tâche signale une variable événement. La tâche initiatrice fini par effectuer une attente sur cette variable sans se préoccuper de la durée effective de l'opération E/S. Si l'opérations E/S est déjà terminée, la tâche franchi sans attente le test de l'événement, par contre si l'opération E/S n'est pas terminée la tâche se suspend.
 puis se consacre à un autre travail, parallèlement l opération E/S se poursuit. Lorsque celle – ci est terminée la tâche signale une variable événement. La tâche initiatrice fini par effectuer une attente sur cette variable sans se préoccuper de la durée effective de l opération E/S. Si l opérations E/S est déjà terminée, la tâche franchi sans attente le test de l événement, par contre si l opération E/S n est pas terminée la tâche se suspend..")
109
Variables événement dans Mtr86 Les signaux ne sont pas mémorisés dans Mtr86 Dos (noyau dur), mais le sont dans Mtr86 Win32 et Mtr86 Objet. Les variables événements n’existent pas de façon isolées mais sous la forme de groupe d‘événements (16 ou 32 bits). Ces bits événements peuvent être combinés sous forme d’opérations ET, OU.
. Ces bits événements peuvent être combinés sous forme d’opérations ET, OU..")
110
Variables événement dans Mtr86 Un groupe d'événements est crée par le code suivant :

111
Variables événement dans Mtr86

112
Synchronisation à l'aide de rendez- vous La synchronisation par rendez-vous permet de résoudre de façon simple la synchronisation d'un nombre connu de tâches. La puissance du mécanisme fait qu'il est incorporé de façon native dans le langage ADA, mais malheureusement dans très peu de noyaux temps réels. Les rendez-vous permettent de résoudre de nombreux problèmes de synchronisation.

113
Rendez – vous dans Mtr86 Lorsqu'un rendez-vous a eu lieu, rv_signal retourne OK ou TIM en cas de "lapin". Le gestionnaire de rendez-vous réinitialise automatiquement les structures de données utilisées pour permettre un nouveau rendez-vous avec le nombre défini lors de la création du rendez-vous. Si le rendez-vous n'a pas lieu (sortie sur timeout) ou si le nombre de rendez est fixé de façon dynamique, il convient d'effectuer une réinitialisation par la primitive rv_init
 ou si le nombre de rendez est fixé de façon dynamique, il convient d effectuer une réinitialisation par la primitive rv_init.")
Présentations similaires





>")







 II (Tanenbaum 2.3)>")
 III (Tanenbaum 2.3)>")







