Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Formation Réseaux et Télécommunication Master 1 Matière : DSP & FPGA Par: ATOUI Hamza

2
Plan du cours µP d’usage général à base d’architecture Von- Neumann (codage CISC). Amélioration vers l’architecture HARVARD (codage RISC). La notion de pipeline.
. La notion de pipeline..")
3
µP d’usage général à base d’architecture Von-Neumann Le µP est le résultat de l’intégration de plusieurs circuits LSI/VLSI pour exécuter un traitement (SOFTWARE) existe dans une mémoire. Le traitement est un ensemble d’instructions l’une après l’autre (séquence), dont le µP prend un temps pour exécuter. Chaque instruction prend une phase ou plusieurs pour exécuter (cycle machine).
, dont le µP prend un temps pour exécuter. Chaque instruction prend une phase ou plusieurs pour exécuter (cycle machine)..")
4
µP d’usage général à base d’architecture Von-Neumann (codage CISC) Soit le µP 8 bits d’espace adressage de 256 octets : CODE/ DATA MUX ADR-REG PC POST-CODE I-REG CMD-CTRL UNIT ALU R0 R1 R2 R3 ZC DATA-REG R-REG INTERNAL 8 bits DATA BUS ADDRESS BUS DATA BUS DECODE UNIT ADDRESSING UNIT EXECUTION UNIT 8 bits 0x00 0xFF MEMORY SPACE
 Soit le µP 8 bits d’espace adressage de 256 octets : CODE/ DATA MUX ADR-REG PC POST-CODE I-REG CMD-CTRL UNIT ALU R0 R1 R2 R3 ZC DATA-REG R-REG INTERNAL 8 bits DATA BUS ADDRESS BUS DATA BUS DECODE UNIT ADDRESSING UNIT EXECUTION UNIT 8 bits 0x00 0xFF MEMORY SPACE")
5
µP d’usage général à base d’architecture Von-Neumann (codage CISC) Ce µP est composé par 3 unités: ADDRESSING UNIT: est composée par le registre PC (pour adresser les instructions dans le CODE), et le registre ADR- REG(pour adresser les données dans le DATA). EXECUTION UNIT: est composée par une banque de registres (R0, R1, R2, R3) pour l’usage général, d’une ALU, de registre DATA-REG (pour stocker les données de l’espace DATA), de 2 flags Z & C (ZERO FLAG, CARRY FLAG), et le registre R-REG (pour stocker le résultat de l’ALU). DECODEING UNIT: est composée par le registre I-REG (contient l’instruction qu’on va exécuter), le registre POST- CODE (contient le deuxième octet de l’instruction), et l’unité de commande et de contrôle (CMD-CTRL UNIT).
 pour l’usage général, d’une ALU, de registre DATA-REG (pour stocker les données de l’espace DATA), de 2 flags Z & C (ZERO FLAG, CARRY FLAG), et le registre R-REG (pour stocker le résultat de l’ALU). DECODEING UNIT: est composée par le registre I-REG (contient l’instruction qu’on va exécuter), le registre POST- CODE (contient le deuxième octet de l’instruction), et l’unité de commande et de contrôle (CMD-CTRL UNIT)..")
6
µP d’usage général à base d’architecture Von-Neumann (codage CISC) Modes d’adressages : Adressage registre: ce mode fait l’échange de données entre les registres d’usage général (exemple: MOVR R0, R1 cette instruction fait le chargement de registre R1 par le contenu le registre R0). Adressage immédiat: ce mode fait le chargement d’un registre d’usage général par une constante sur 8 bits (exemple: MOVK 10, R2 cette instruction fait le chargement de registre R2 par la constante 10). Adressage direct: ce mode fait le chargement d’un registre d’usage général/case mémoire par le contenu d’une case mémoire/registre d’usage général (exemple: LD @50h, R3 cette instruction fait le chargement de registre R3 par le contenu de la case mémoire d’adresse 50h; ST R0, @20h cette instruction fait le chargement de la case mémoire d’adresse 20h par le contenu de registre R0). Adressage indirect: ce mode manipule l’espace mémoire par le biais d’un pointeur, dont le pointeur est un des registres d’usage général (exemple : LD [R3], R0 cette instruction fait le chargement de registre R0 par le contenu de la case mémoire pointée par le registre R3).
. Adressage direct: ce mode fait le chargement d’un registre d’usage général/case mémoire par le contenu d’une case mémoire/registre d’usage général (exemple: R3 cette instruction fait le chargement de registre R3 par le contenu de la case mémoire d’adresse 50h; ST cette instruction fait le chargement de la case mémoire d’adresse 20h par le contenu de registre R0). Adressage indirect: ce mode manipule l’espace mémoire par le biais d’un pointeur, dont le pointeur est un des registres d’usage général (exemple : LD [R3], R0 cette instruction fait le chargement de registre R0 par le contenu de la case mémoire pointée par le registre R3)..")
7
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupes & Formats des instructions: Groupe 0: contient les instructions du contrôle ( LJMP, RJMP, JMPC, JMPNC, JMPZ, JMPNZ, NOP, MOVR, MOVK );
 Groupes & Formats des instructions: Groupe 0: contient les instructions du contrôle ( LJMP, RJMP, JMPC, JMPNC, JMPZ, JMPNZ, NOP, MOVR, MOVK );")
8
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 0.
 Groupe 0.")
9
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 0.
 Groupe 0.")
10
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 0.
 Groupe 0.")
11
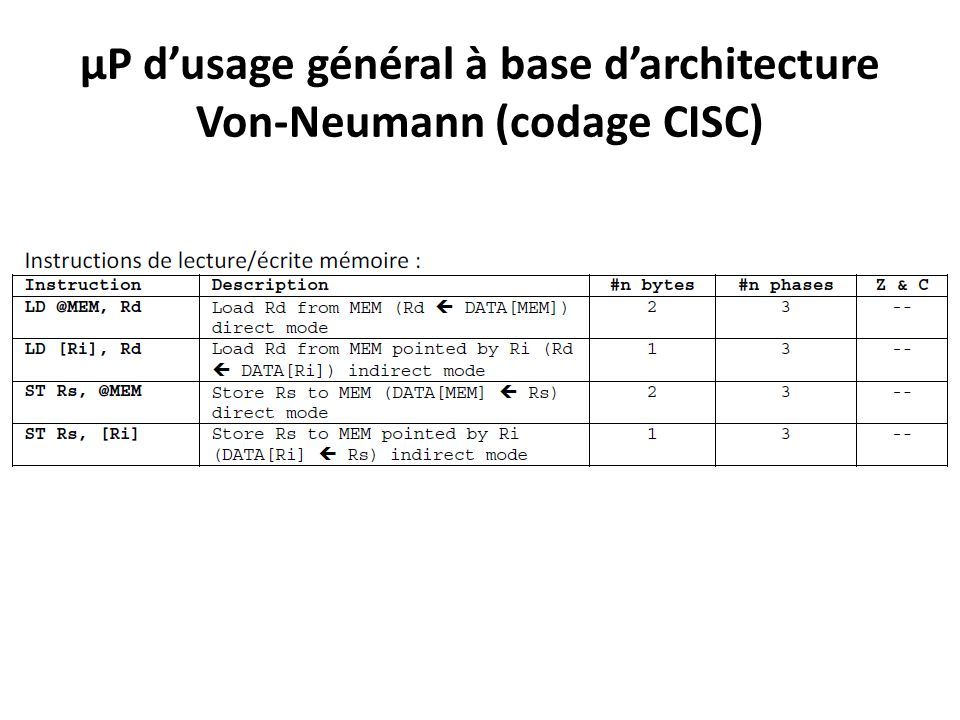
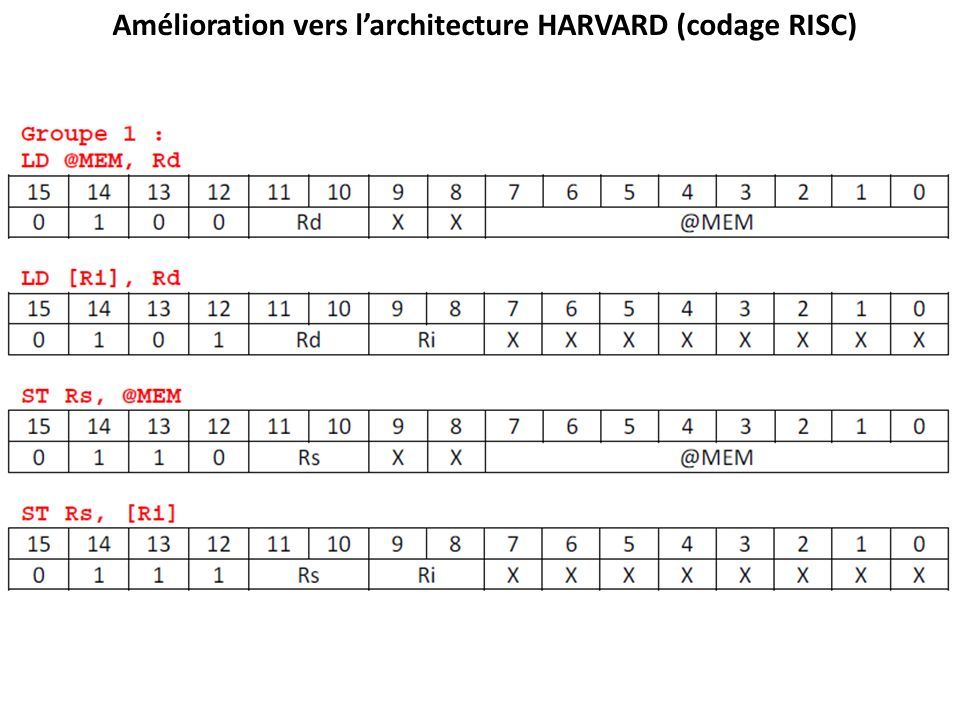
µP d’usage général à base d’architecture Von-Neumann (codage CISC) Groupes & Formats des instructions: Groupe 1: contient les instructions lecture/écriture mémoire ( LD, ST );
 Groupes & Formats des instructions: Groupe 1: contient les instructions lecture/écriture mémoire ( LD, ST );")
12
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 1.
 Groupe 1.")
13
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 1.
 Groupe 1.")
14
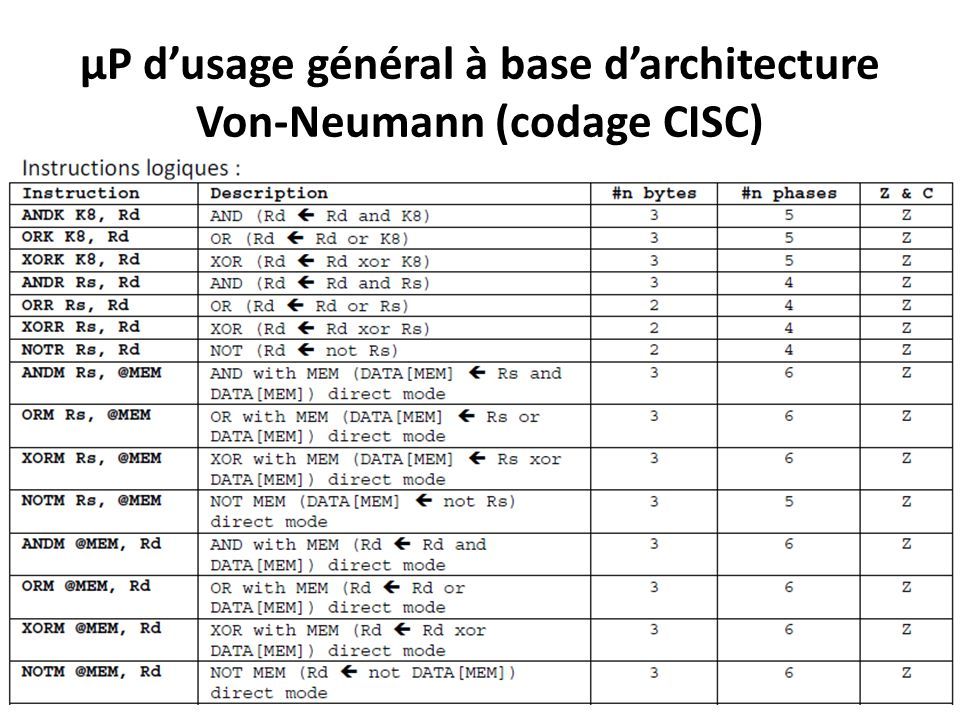
µP d’usage général à base d’architecture Von-Neumann (codage CISC) Groupes & Formats des instructions: Groupe 2: contient les instructions Logiques ( AND, OR, XOR, NOT );
 Groupes & Formats des instructions: Groupe 2: contient les instructions Logiques ( AND, OR, XOR, NOT );")
15
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 2.
 Groupe 2.")
16
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 2.
 Groupe 2.")
17
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 2.
 Groupe 2.")
18
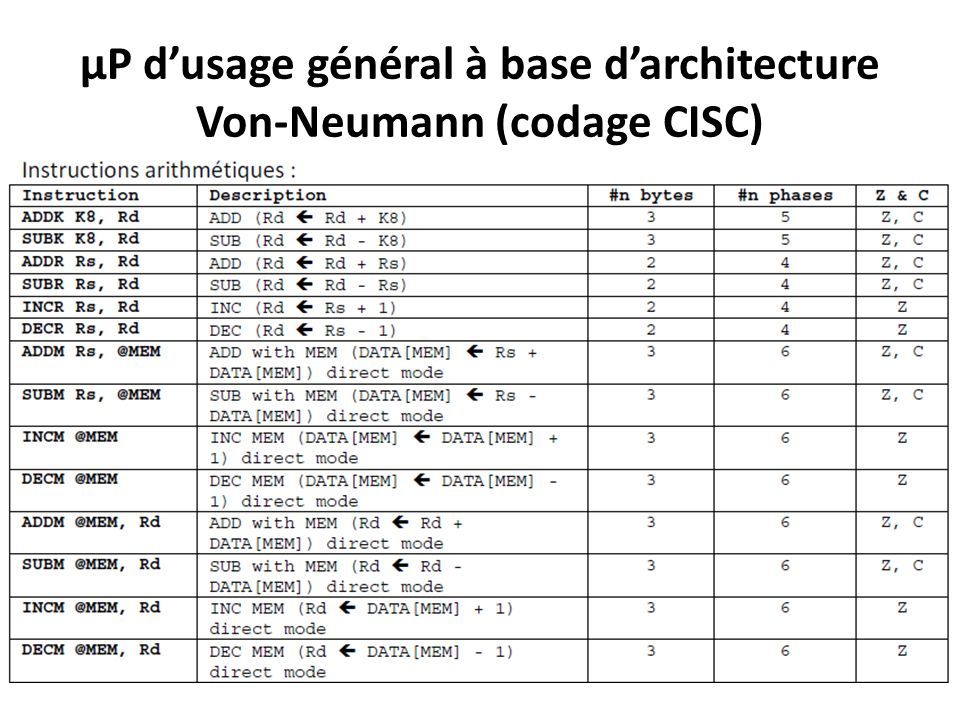
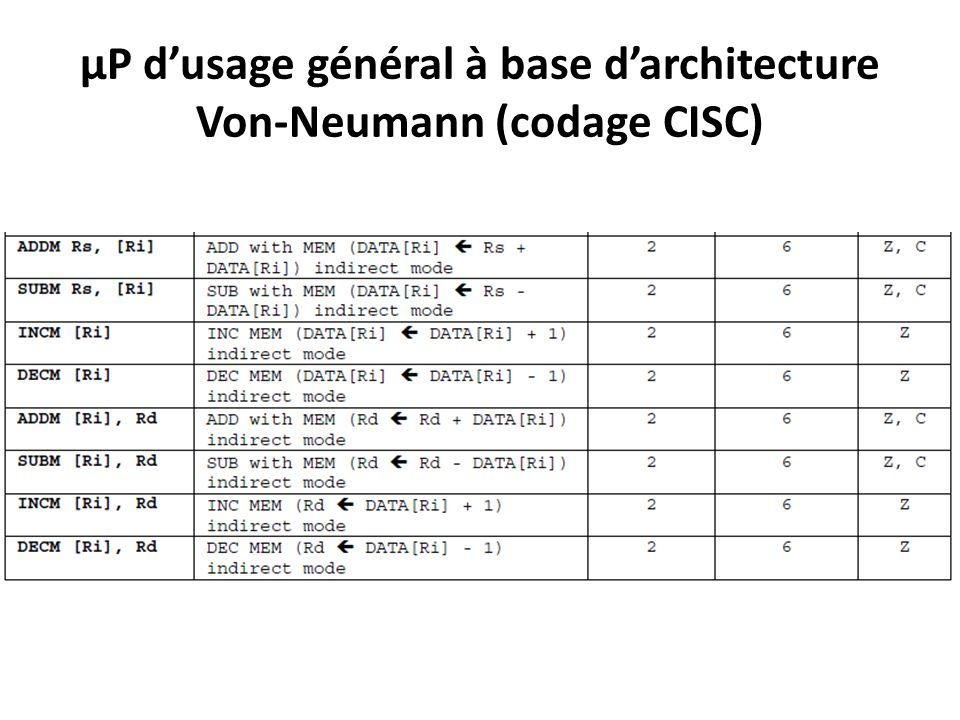
µP d’usage général à base d’architecture Von-Neumann (codage CISC) Groupes & Formats des instructions: Groupe 3: contient les instructions arithmétiques ( ADD, SUB, INC, DEC );
 Groupes & Formats des instructions: Groupe 3: contient les instructions arithmétiques ( ADD, SUB, INC, DEC );")
19
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 3.
 Groupe 3.")
20
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 3.
 Groupe 3.")
21
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Groupe 3.
 Groupe 3.")
22
µP d’usage général à base d’architecture Von- Neumann (codage CISC) Les différentes phases par cycle machine: le cycle machine est le temps nécessaire pour exécuter une instruction, dont ce cycle se compose par un ensemble de phases sont: La phase FETCH (F): lire l’op-code par le PC dans l’espace CODE et charger dans I-REG puis incrémenter le PC. La phase READ-POST-CODE (RPOC): lire le post-code par le PC dans l’espace CODE et charger dans le registre POST-CODE puis incrémenter le PC. La phase READ-K8 (RK8): lire la constante K8 par le PC dans l’espace CODE et charger dans le registre DATA- REG/un registre d’usage général puis incrémenter le PC.
: lire le post-code par le PC dans l’espace CODE et charger dans le registre POST-CODE puis incrémenter le PC. La phase READ-K8 (RK8): lire la constante K8 par le PC dans l’espace CODE et charger dans le registre DATA- REG/un registre d’usage général puis incrémenter le PC..")
23
µP d’usage général à base d’architecture Von-Neumann (codage CISC) La phase READ-@MEM (ADRM): lire la constante qui présente une adresse mémoire par le PC dans l’espace CODE et charger dans le registre ADR-REG puis incrémenter le PC. La phase READ-@LABEL (ADRL): lire la constante qui présente une adresse mémoire par le PC dans l’espace CODE et charger dans le registre ADR-REG puis incrémenter le PC. La phase SET-PC (SPC): charger le PC par le contenu de registre ADR-REG pour faire un saut. La phase SET-ADR-REG (SAR): charger le ADR-REG par le contenu d’un registre d’usage général pour faire un adressage indirect.
: lire la constante qui présente une adresse mémoire par le PC dans l’espace CODE et charger dans le registre ADR-REG puis incrémenter le PC. La phase SET-PC (SPC): charger le PC par le contenu de registre ADR-REG pour faire un saut. La phase SET-ADR-REG (SAR): charger le ADR-REG par le contenu d’un registre d’usage général pour faire un adressage indirect..")
24
µP d’usage général à base d’architecture Von-Neumann (codage CISC) La phase WRITE-RD (WRD): charger le registre destination Rd par le contenu de registre R-REG. La phase READ-MEM (RDM): Lire la case mémoire dans l’espace DATA pointé par ADR-REG et charger la dans le registre DATA-REG ou dans un registre d’usage général. La phase WRITE-MEM (WRM): charger la case mémoire dans l’espace DATA pointé par ADR-REG par le contenu de registre R-REG ou un des registres généraux.
: Lire la case mémoire dans l’espace DATA pointé par ADR-REG et charger la dans le registre DATA-REG ou dans un registre d’usage général. La phase WRITE-MEM (WRM): charger la case mémoire dans l’espace DATA pointé par ADR-REG par le contenu de registre R-REG ou un des registres généraux..")
25
µP d’usage général à base d’architecture Von-Neumann (codage CISC) La phase PROCESS (P): charger le registre R- REG par le résultat de l’ALU. La phase PROCESS-Z (PZ): charger le registre R-REG par le résultat de l’ALU et charger le flag Z par l’état de l’ALU. La phase PROCESS-ZC (PZC): charger le registre R-REG par le résultat de l’ALU et charger les flags Z & C par l’état de l’ALU.
: charger le registre R-REG par le résultat de l’ALU et charger le flag Z par l’état de l’ALU. La phase PROCESS-ZC (PZC): charger le registre R-REG par le résultat de l’ALU et charger les flags Z & C par l’état de l’ALU..")
26
µP d’usage général à base d’architecture Von-Neumann (codage CISC) Exemple : les différentes phases pour exécuter l’instruction ANDK K8, Rd. Exemple: LD @MEM, Rd. FRPOCRK8PZWRD FADRMRDM

27
HOME WORK 1 D’après le groupage, formats et les différentes phases d’un cycle machine, Essayiez de trouver les phases du cycle machine de chaque instruction.

28
µP d’usage général à base d’architecture Von-Neumann (codage CISC)
")
34
Exemple Programmez en assembleur la somme d’un tableau de 8 octets. Puis calculez le nombre de top d’horloge consommé pour exécuter.

35
Amélioration vers l’architecture HARVARD (codage RISC) Vous remarquez que: Le nombre d’instructions est important. Le codage d’instructions est dynamique variai entre 1 jusqu’à 3 octets. L’espace DATA et CODE partage les mêmes bus de données & adresse. L’exécution d’une instruction prend de 2 jusqu’à 6 phases selon la complexité. Il y a des instructions présentent un aller/retour vers l’espace DATA comme ADDM Rs, @MEM.

36
Amélioration vers l’architecture HARVARD (codage RISC) Toutes ces contraintes influence directement sur la vitesse de µP, donc la possibilité de travailler en temps réel !!! La question qui se pose est: comment augmenter la vitesse de µP sans d’augmenter la fréquence de l’horloge??????????? Comme premier pas on bascule vers une architecture de type HARVARD et de codage RISC. Une autre question: il se base sur quoi l’architecture de HARVAD et le codage RISC??????

37
Amélioration vers l’architecture HARVARD (codage RISC) L’architecture de HARVARD se base sur la séparation des deux espaces DATA & CODE par le doublement des bus de données & adresse; donc, on va voir un bus données/adresse pour le DATA et un autre pour le CODE comme indique la figure suivante: CPU CODEDATA
 L’architecture de HARVARD se base sur la séparation des deux espaces DATA & CODE par le doublement des bus de données & adresse; donc, on va voir un bus données/adresse pour le DATA et un autre pour le CODE comme indique la figure suivante: CPU CODEDATA")
38
Amélioration vers l’architecture HARVARD (codage RISC) Le codage RISC se base sur: Diminuez le nombre d’instructions par l’élimination des instructions qu’on peut réaliser par une suite d’instructions plus simple. De rendre le codage statique au lieu du codage dynamique; donc, toutes les instructions prennent le même nombre de bits (exemple toutes les instruction sont codées sur 14 bits). Essayiez de rendre toutes les instructions prennent le même nombre de phases (un cycle machine de durée statique).
. Essayiez de rendre toutes les instructions prennent le même nombre de phases (un cycle machine de durée statique)..")
39
Amélioration vers l’architecture HARVARD (codage RISC) Toutes les instructions qui manipule l’espace DATA avec un registre d’usage général on élimine comme ANDM R1, @MEM; par ce que on peut remplacer par: ANDM R1, @MEM LD @MEM, R0 ANDR R1, R0 ST R0, @MEM
 Toutes les instructions qui manipule l’espace DATA avec un registre d’usage général on élimine comme ANDM par ce que on peut remplacer par: ANDM R0 ANDR R1, R0 ST")
40
Amélioration vers l’architecture HARVARD (codage RISC) Donc, il reste dans le groupe 2 les instructions suivantes: ANDK, ORK, XORK, ANDR, ORR, XORR, NOTR. Dans le goupe3 reste seulement : ADDK, SUBK, ADDR, SUBR. Par ce que on peut éliminer les deux instructions INC & DEC (l’incrémentation est d’ajouter un 1 et la décrémentation est de soustraire un 1). Les groupes 0 & 1 restent tel quels.
. Les groupes 0 & 1 restent tel quels..")
41
Amélioration vers l’architecture HARVARD (codage RISC) D’après le nombre de groupes, on a besoin de 2 bits pour les coder. Groupe 0 : on peut diviser ce groupe en 4 sous groupes [ NOP, JMP, MOVR, MOVK ]. Donc, on a besoin de 2 bits pour le sous groupe comme indique la figure suivante :

42
Amélioration vers l’architecture HARVARD (codage RISC) 4 bits 16 bits 14 bits 7 bits 8 bits 14 bits
 4 bits 16 bits 14 bits 7 bits 8 bits 14 bits")
43
Amélioration vers l’architecture HARVARD (codage RISC) 14 bits 8 bits 14 bits 8 bits
 14 bits 8 bits 14 bits 8 bits")
44
Amélioration vers l’architecture HARVARD (codage RISC) 15 bits 9 bits 8 bits
 15 bits 9 bits 8 bits")
45
Amélioration vers l’architecture HARVARD (codage RISC) 14 bits 8 bits
 14 bits 8 bits")
46
Amélioration vers l’architecture HARVARD (codage RISC) D’après le nouveau codage, on remarque que la plus longue instruction est JMPCC @LABEL, nécessite pour coder 16 bits; donc on va réorganiser toutes les instructions sur 16 bits comme suit:
 D’après le nouveau codage, on remarque que la plus longue instruction est nécessite pour coder 16 bits; donc on va réorganiser toutes les instructions sur 16 bits comme suit:")
47
Amélioration vers l’architecture HARVARD (codage RISC)
")
50
L’ancienne architecture a rendu les instructions prennent de 2 à 6 phases pour exécuter. On essaye de proposer une autre architecture se base sur l’architecture de HARVARD pour faire passée toutes les instruction par le même nombre de phases. L’espace DATA et CODE sont séparés, dont le DATA est un espace de 256x8bits et le CODE est un espace de 256x16bits (à cause de la taille d’une instruction) avec chaque ligne dans l’espace CODE prend une instruction. Donc, au moment de la phase FETCH le I-REG contient toute l’instruction (I-REG de 16 bits), elle n’est pas comme le premier cas le I-REG contient seulement le premier octet de l’instruction (I-REG de 8 bits).
 avec chaque ligne dans l’espace CODE prend une instruction. Donc, au moment de la phase FETCH le I-REG contient toute l’instruction (I-REG de 16 bits), elle n’est pas comme le premier cas le I-REG contient seulement le premier octet de l’instruction (I-REG de 8 bits)..")
51
Amélioration vers l’architecture HARVARD (codage RISC) CPU (?) CODEDATA 8 168 8 Qu’est ce qu’il y a dedans ?????
 CPU ( ) CODEDATA Qu’est ce qu’il y a dedans")
52
Amélioration vers l’architecture HARVARD (codage RISC) CODEDATA INTERNAL 8 BIT ADDRESS BUS INTERNAL 8 BIT DATA BUS ALU Z C REG BANK IRCCU PC 16 8
 CODEDATA INTERNAL 8 BIT ADDRESS BUS INTERNAL 8 BIT DATA BUS ALU Z C REG BANK IRCCU PC 16 8")
53
Amélioration vers l’architecture HARVARD (codage RISC) D’après cette architecture, toutes les instructions prennent deux phases pour exécuter. D’une façon générale : La phase FETCH (charger toute l’instruction dans le IR et incrémenter le PC pour pointer vers l’instruction suivante). La phase PRECESS (la réalisation de l’opération demandée par l’instruction). FETCHPROCESS
. La phase PRECESS (la réalisation de l’opération demandée par l’instruction). FETCHPROCESS.")
54
Exemple Programmez en assembleur la somme d’un tableau de 8 octets par le nouveau CPU. Puis calculez le nombre de top d’horloge consommé pour exécuter et faites une comparaison entre le CPU CISC & le CPU RISC.

55
Notion de pipeline Est-ce que on peut améliorer plus?????? Exemple de la chaîne du lavage des vêtements [Laver, sécher et plier].

56
Notion de pipeline Absolument OUI. Vous remarquez que l’exécution des instructions présente un aspect purement séquentiel bien qu’il soit possible d’obtenir un recouvrement dans l’exécution d’instructions successives. FETCH1PROCESS1FETCH2PROCESS2 Instruction 1Instruction 2 FETCH1PROCESS1 FETCH2PROCESS2 4 Tops pour exécuter 2 instructions 3 Tops pour exécuter 2 instructions Pour N instructions, on a come bien de tops pour exécuter?????

57
Notion de pipeline Malgré ce gain en terme du temps d’exécution, ce genre d’architecture en pipeline présente un ensemble de problèmes sont liés : – Aux accès à la mémoire. – Aux conflits de dépendance entre registres. – Aux branchement et au traitement des interruptions. Tous ces problèmes peuvent être résolus soit par: – Matériel(techniques basées sur un Marquage de registres). – Logiciel (insertion de NOP ou Permutation des instructions par compilateur).
. – Logiciel (insertion de NOP ou Permutation des instructions par compilateur)..")
58
Notion de pipeline Soit le programme en assembleur suivant: Donnez moi les valeur des registre R0 et R1 après exécution de ce code. MOVK 10, R1 MOVK 8, R2 MOVK 0, R0 AGAIN: ADDK 1, R0 SUBK 1, R2 JMPNZ AGAIN ADDK 1, R1

59
Notion de pipeline Proposez une solution pour empêcher l’exécution ADDK 1, R1 au moment de branchement.

60
Notion de pipeline MOVK 10, R1 MOVK 8, R2 MOVK 0, R0 AGAIN: ADDK 1, R0 SUBK 1, R2 JMPNZ AGAIN NOP ADDK 1, R1

61
Conclusion Les processeurs les plus rapide sont des processeur d’architecture HARVARD, un codage d’instruction RISC et travaille en pipeline. Mais, la programmation en assembleur nécessite beaucoup de soin, les résultats pouvant être imprévisible si l’on ne tient pas compte des spécificités de ces processeur.

Présentations similaires




>")

 Le CPU doit être rapide (mesuré en temps de CPU) UNITE DE CONTROLE Générer les signaux de control/temps Contrôler le décodage/exécution.>")














?>")