Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Champs de Markov cachés pour la classification de gènes..
…en combinant des données individuelles et de paires Matthieu VIGNES & Florence FORBES (INRIA Rhône-Alpes – Equipe Mistis) {matthieu.vignes,florence.forbes}[AT]inrialpes.fr RIA’s mars 2006
 {matthieu.vignes,florence.forbes}[AT]inrialpes.fr RIA’s mars")
2
Introduction Contexte Travaux antétieurs
Intégrer différents types de données issues de bases de données pour la classification d’entités biologiques Travaux antétieurs Classification hiérarchique (Eisen et al 1998), k-means (Tavazoie et al, 1999), SVM (Brown et al, 2000), SOM (Tamayo et al, 1999), bi-clustering (Tanay et al, 2004), méthodes à noyaux (Vert et al, 2003), etc. Aussi modèles de mélange : Yeung et al, 2001 Limitation majeure de toutes ces approches : données individuelles et de paires ne sont pas incorporées dans un modèle statistique unique
, k-means (Tavazoie et al, 1999), SVM (Brown et al, 2000), SOM (Tamayo et al, 1999), bi-clustering (Tanay et al, 2004), méthodes à noyaux (Vert et al, 2003), etc. Aussi modèles de mélange : Yeung et al, Limitation majeure de toutes ces approches : données individuelles et de paires ne sont pas incorporées dans un modèle statistique unique.")
3
Modèle de champ de Markov caché
xi donnée individuelle associée à l’objet i zi étiquette de l’objet i L’objet i interagit avec ses voisins via un Champ de Markov :

4
Modèle de champ de Markov caché
Prise en compte des voisinages au travers de la fonction d’énergie H

5
Modèle de champ de Markov caché
Prise en compte des voisinages au travers de la fonction d’énergie H Difficultés: calcul de W(D) et de probabilités conditionnelles nécessaires mais impossibles explicitement approximations de type champ moyen nécessaires (Celeux et al 2003)
 et de probabilités conditionnelles nécessaires mais impossibles explicitement approximations de type champ moyen nécessaires (Celeux et al 2003)")
6
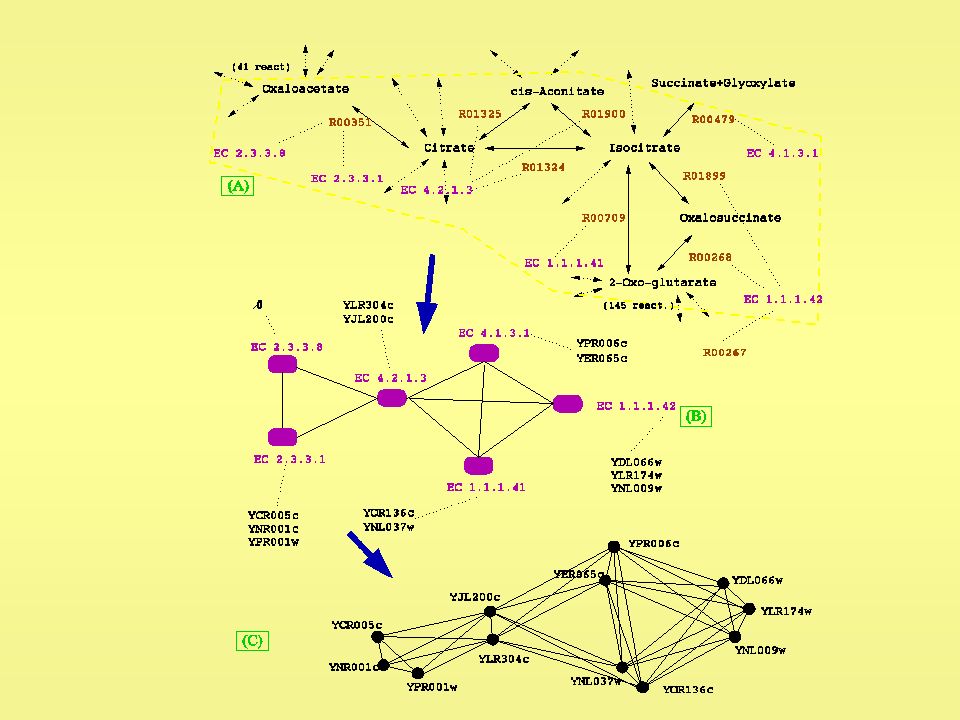
Construction du système de voisinage
2 enzymes sont voisines si elles catalysent 2 réactions ayant au moins 1 composé en commun comme réactif ou produit 2 gènes sont voisins s’ils sont associés à ces 2 enzymes On traduit un enchaînement métabolique potentiel élargi. Limitation de la base de données...

8
Expériences sur données simulées
5 jeux de 1536 objets en dimension 20 répartis dans 6 classes.

9
Expériences sur données simulées
EM (haut) comparé à l’algorithme en champ simulé (bas)
 comparé à l’algorithme en champ simulé (bas)")
10
Expériences sur données simulées
En Champ simulé, une classe «poubelle» peut apparaître…

11
Expériences sur données issues de la levure
Données d’expression publiques (Chu et al, 1998) Base de données LIGAND de KEGG pour la définition des voisinages 635 gènes en dimension 10 : 6 classes (BIC)
 Base de données LIGAND de KEGG pour la définition des voisinages. 635 gènes en dimension 10 : 6 classes (BIC)")
12
Expériences sur données issues de la levure
Problème majeur de la validation (Handl et al, 2005) (1) On regarde si on retrouve des voies métaboliques
 (1) On regarde si on retrouve des voies métaboliques.")
13
Expériences sur données issues de la levure
(2) On s’intéresse à la distribution de propriétés qui joueront le rôle de critère biologique Exemple des termes GO (p-valeurs : Benjamini et al, 2003)
 On s’intéresse à la distribution de propriétés qui joueront le rôle de critère biologique. Exemple des termes GO (p-valeurs : Benjamini et al, 2003)")
14
Conclusion Prise en compte simultanée de plusieurs types de données individuelles et de paires Bon comportement du modèle et bons résultats sur données simulées et réelles Perspectives : écrire le programme pour des données manquantes, modélisation de classes empiétantes (Battle et al, 2004).
.")
15
Merci de votre attention!!
Conclusion Prise en compte simultanée de plusieurs types de données individuelles et de paires Bon comportement du modèle et bons résultats sur données simulées et réelles Perspectives : écrire le programme pour des données manquantes, modélisation de classes empiétantes (Battle et al, 2004). Merci de votre attention!!
. Merci de votre attention!!")
Présentations similaires