Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
LE PARALLELISME DANS LE MODELE CLIMATIQUE DE L’IPSL
01/04/2017

2
Le parallélisme dans le modèle couplé…
Contexte Codes déjà existant initialement développés en séquentiel, ciblés pour machine vectorielle. Parallélisme « sur mesure » fournissant la meilleure efficacité en fonction des contraintes existantes. Rester peu intrusif au niveau des codes de façon à ne pas freiner le développement des modèles. Travail délicat : on gère 4 niveaux de parallélismes imbriqués Couplage asynchrone des modèles (OASIS). Parallélisme MPI par découpage de domaines (mémoire distribuée : inter-nœuds). Parallélisme OpenMP (mémoire partagée : intra-nœuds). Vectorisation. Couplage jusqu’à 5 codes parallèles Océan + glace de mer (OPA/LIMNEMO) : MPI Biogéochimie marine (PISCES) : MPI Atmosphère (LMDZ) : mixte MPI/OpenMP Surfaces continentales (ORCHIDEE) : mixte MPI/OpenMP Chimie atmosphérique (INCA – REPROBUS) : mixte MPI/OpenMP 01/04/2017
. Parallélisme MPI par découpage de domaines (mémoire distribuée : inter-nœuds). Parallélisme OpenMP (mémoire partagée : intra-nœuds). Vectorisation. Couplage jusqu’à 5 codes parallèles. Océan + glace de mer (OPA/LIMNEMO) : MPI. Biogéochimie marine (PISCES) : MPI. Atmosphère (LMDZ) : mixte MPI/OpenMP. Surfaces continentales (ORCHIDEE) : mixte MPI/OpenMP. Chimie atmosphérique (INCA – REPROBUS) : mixte MPI/OpenMP. 01/04/2017.")
3
Un exemple : le parallélisme dans LMDZ
LMDZ : Modèle de circulation général atmosphérique (gcm) Développé et maintenu au LMD (Jussieu). Volume du code : ~ lignes ~ 90 % du temps du couplé (pas de temps plus petit que pour l’océan). Contient 2 parties conceptuellement très différentes : La partie dynamique Résolution des équations de Navier-Stoke sur la sphère en milieu tournant Transport des traceurs (eau liquide/vapeur, espèces chimiques, traceurs isotopiques…) Beaucoup de dépendance entre mailles voisines La partie physique Résolution des processus à l’intérieur d’une même colonne d’atmosphère -- Convection, rayonnement, nuages, couches limites… -- Les colonnes d’atmosphères sont indépendantes entre elles 01/04/2017
 Développé et maintenu au LMD (Jussieu). Volume du code : ~ lignes. ~ 90 % du temps du couplé (pas de temps plus petit que pour l’océan). Contient 2 parties conceptuellement très différentes : La partie dynamique. Résolution des équations de Navier-Stoke sur la sphère en milieu tournant. Transport des traceurs (eau liquide/vapeur, espèces chimiques, traceurs isotopiques…) Beaucoup de dépendance entre mailles voisines. La partie physique. Résolution des processus à l’intérieur d’une même colonne d’atmosphère. -- Convection, rayonnement, nuages, couches limites… -- Les colonnes d’atmosphères sont indépendantes entre elles. 01/04/2017.")
4
La parallélisation de la dynamique
La partie dynamique Résolution sur une grille orthogonale longitude-latitude Schéma spatial en différence finie sur une grille de type C (Arakawa) Schéma temporel de type « leapfrog / matsuno » Resserrement des mailles au pôle => non respect des conditions CFL Application d’un filtre en longitude près des pôles 1/6 à chaque pôle, soit 1/3 de la surface globale Opération de type matrice-vecteur (N2), remplacée par une FFT (N log N) pour une grille régulière (non zoomée) Appelé à chaque utilisation d‘un opérateur différentiel (divergence, laplacien, rotationnel…) Coût en calcul très important ( grille 1°, 50% temps de calcul) Difficile, voir contre performant, à découper en domaine Traceurs advectés sur plusieurs mailles 01/04/2017
 Schéma temporel de type « leapfrog / matsuno » Resserrement des mailles au pôle => non respect des conditions CFL. Application d’un filtre en longitude près des pôles. 1/6 à chaque pôle, soit 1/3 de la surface globale. Opération de type matrice-vecteur (N2), remplacée par une FFT (N log N) pour une grille régulière (non zoomée) Appelé à chaque utilisation d‘un opérateur différentiel. (divergence, laplacien, rotationnel…) Coût en calcul très important ( grille 1°, 50% temps de calcul) Difficile, voir contre performant, à découper en domaine. Traceurs advectés sur plusieurs mailles. 01/04/2017.")
5
La parallélisation de la dynamique
Découpage MPI en bandes de latitude Avantages Règle implicitement le découpage du filtre, puisqu’il ne s’applique que sur des mailles de même latitude. Pas problème lorsque les traceurs sont advectés sur plusieurs mailles en longitude Au plus 2 domaines voisins Conserve la vectorisation et la structure du code Inconvénient Granularité importante 3 bandes minimums par domaine pour permettre le recouvrement des halos Longitudes Latitudes Couches verticales 01/04/2017

6
La parallélisation de la dynamique
Problème d’équilibrage de charge les processus près des pôles consomment plus de CPU à cause du filtre Répartition en domaines de taille non-uniforme Les processus physiques traités n’utilisent pas le filtre de façon équivalente Pas de distribution optimum unique 4 distributions de domaine chacune équilibrées Distribution caldyn : calcul des équations Naviers-Stocke : forte utilisation du filtre Distribution advect : advection des traceurs : pas de filtre Distribution dissip : dissipation (laplacien itératif) : très forte utilisation du filtre Distribution physique : calcul de la physique (colonne d’atmosphère indépendantes) Passage d’une distribution à l’autre au cours d’un même pas de temps Inclus les transferts MPI pour les données manquantes sur un processus. Procédure d’ajustement automatique Détermine les distributions optimum par essais successifs 01/04/2017
 : très forte utilisation du filtre. Distribution physique : calcul de la physique (colonne d’atmosphère indépendantes) Passage d’une distribution à l’autre au cours d’un même pas de temps. Inclus les transferts MPI pour les données manquantes sur un processus. Procédure d’ajustement automatique. Détermine les distributions optimum par essais successifs. 01/04/2017.")
7
La parallélisation de la dynamique
Les fonctions de transferts MPI (halos de recouvrement) Ne transfèrent que les données nécessaires Transfèrent tous les halos des différents champs en un seul appel Minimisation des latences MPI Communications asynchrones non bloquantes MPI_Issend, MPI_Irecv, MPI_Wait Permettent le recouvrement calcul /communication. Ajout d’un niveau de parallélisme sur les niveaux verticaux avec OpenMP Ajout de directives sur les boucles verticales Suppression des synchronisations implicites à la fin des boucles (NOWAIT) Un seule section parallèle ouverte dès l’initialisation Augmentation de la scalabilité plus de CPU sur une même grille Pas de surconsommation mémoire 01/04/2017
 Ne transfèrent que les données nécessaires. Transfèrent tous les halos des différents champs en un seul appel. Minimisation des latences MPI. Communications asynchrones non bloquantes. MPI_Issend, MPI_Irecv, MPI_Wait. Permettent le recouvrement calcul /communication. Ajout d’un niveau de parallélisme sur les niveaux verticaux avec OpenMP. Ajout de directives sur les boucles verticales. Suppression des synchronisations implicites à la fin des boucles (NOWAIT) Un seule section parallèle ouverte dès l’initialisation. Augmentation de la scalabilité. plus de CPU sur une même grille. Pas de surconsommation mémoire. 01/04/2017.")
8
La parallélisation de la physique
La partie physique : peu communicante, colonnes d’atmosphère indépendantes. Distribution des colonnes d’atmosphère aux processus MPI, puis aux tâches OpenMP Équilibrage de charge => distribution non-homogène du nombre de colonnes par processus Communication collectives nécessaires uniquement lors : Des entrées /sorties. De l’appel au coupleur. Encapsulation dans des routines d’appel génériques Transparentes pour le développeur quelque soit la technologie employée (MPI, OpenMP, mixte) 01/04/2017
 01/04/2017.")
9
Entrées/Sorties - Couplage
Gestion des Entrées/Sorties de fichier Fichier de démarrage / redémarage Seul le processus maître lit/écrit Scatter / Gather vers les autres processus/tâches Les fichiers histoires (mensuels, journaliers, hautes fréquences…) Chaque processus MPI écrit son domaine reconstruction en post-traitement (rebuild) Gestion du couplage parallèle avec les autres codes INCA/REPROBUS : même grille que la physique de LMDZ Utilise les mêmes techniques de parallélisme ORCHIDEE : même grille que la physique de LMDZ, Ne travaille que sur les points de terre Communications lors du routage de l’eau Couplage vers NEMO à l’aide du coupleur OASIS 01/04/2017
 Chaque processus MPI écrit son domaine. reconstruction en post-traitement (rebuild) Gestion du couplage parallèle avec les autres codes. INCA/REPROBUS : même grille que la physique de LMDZ. Utilise les mêmes techniques de parallélisme. ORCHIDEE : même grille que la physique de LMDZ, Ne travaille que sur les points de terre. Communications lors du routage de l’eau. Couplage vers NEMO à l’aide du coupleur OASIS. 01/04/2017.")
10
Etat de l’art du couplé parallèle
Codes : LMDZ : mixte MPI/OpenMP ORCHIDEE : mixte MPI/OpenMP INCA/REPROBUS : mixte MPI/OpenMP OASIS 3 : MPI NEMO : MPI Version couplés : Version de développement fonctionnelle mixte MPI/OpenMP En production : couplé MPI : IPSLCM5 Évolution vers le couplé mixte MPI/OpenMP en production Accès à des résolutions plus élevées (1°, ½°, 1/3° …) en couplé Simulation en paléoclimat (résolutions dégradées) sur les machines scalaires. 01/04/2017
 en couplé. Simulation en paléoclimat (résolutions dégradées) sur les machines scalaires. 01/04/2017.")
11
Quelques chiffres… Résolution standard : 96x95x39
Titane : 256 procs : ~ 4h / 10 ans simulations (accélération ~ 120 sur 256 proc, ~75 sur 128) SX 9 : 1 proc : 35 h / 10 ans, 4 procs : 11.4 h/10 ans Résolution au degré (360x180x55) ES : 10 ans LMDZ forcés (128 proc. vectoriels SX7) Platine : 480 procs (accélération ~ 300) Résolution ~ ½ ° 720x360x19 512x512x64 => 1024 proc et + … (Idris / IBM Vargas) ~ 15 jours / 10 ans 01/04/2017
 SX 9 : 1 proc : 35 h / 10 ans, 4 procs : 11.4 h/10 ans. Résolution au degré (360x180x55) ES : 10 ans LMDZ forcés (128 proc. vectoriels SX7) Platine : 480 procs (accélération ~ 300) Résolution ~ ½ ° 720x360x x512x64 => 1024 proc et + … (Idris / IBM Vargas) ~ 15 jours / 10 ans. 01/04/2017.")
12
Une simulation frontière :
- GRAND DEFI CINES - 01/04/2017

13
Le modèle Premier couplé IPSL à très haute-résolution 1/3° atmosphère, 1/4° océan Résolution ~ 25 km océan et ~30km atmosphère Modèle type GIEC simplifié LMDZ+ORCHIDEE (atmosphère & surface continentale) NEMO (océan & glace de mer) Coupleur OASIS 3 Configuration : 20 ans de simulation LMDZ+ORCHIDEE Grand Défi GD/GIEC Taille du domaine 768x767x39 (23M) x60 Pas de temps/jours 4800 (20 ans : 35M) x10 NEMO Grand Défi GD/GIEC Taille du domaine 1442x1021x46 (67M) x80 Pas de temps/jours 72 (20 ans: 0.5M) x10 01/04/2017
 NEMO (océan & glace de mer) Coupleur OASIS 3. Configuration : 20 ans de simulation. LMDZ+ORCHIDEE. Grand Défi. GD/GIEC. Taille du domaine. 768x767x39 (23M) x60. Pas de temps/jours (20 ans : 35M) x10. NEMO. Grand Défi. GD/GIEC. Taille du domaine. 1442x1021x46 (67M) x80. Pas de temps/jours. 72 (20 ans: 0.5M) x10. 01/04/2017.")
14
Machine : extension Jade au CINES :
Parallélisme Machine : extension Jade au CINES : SGI : Intel Xéon Néhalem 2.93Ghz, bi-socket/quadricoeurs (8 cœurs/nœuds) ~ coeurs Parallélisme Total : 2191 Coeurs LMDZ+ORCHIDEE : 2048 Cœurs 256 processus MPI 8 thread openMP / processus NEMO : 120 processus MPI OASIS : 23 processus (1 processus par champ échangé) 20 ans simulés ~ 35 jours de calcul sur 2200 CPU 01/04/2017
 ~ coeurs. Parallélisme Total : 2191 Coeurs. LMDZ+ORCHIDEE : 2048 Cœurs. 256 processus MPI. 8 thread openMP / processus. NEMO : 120 processus MPI. OASIS : 23 processus (1 processus par champ échangé) 20 ans simulés ~ 35 jours de calcul sur 2200 CPU. 01/04/2017.")
15
Performance 1024 procs : ~ speed-up 820 2048 procs : ~ speed-up 1200
01/04/2017 15

16
De nombreuses difficultés
Génération des états initiaux Fait en séquentiel, algorithmes d’interpolation non adaptés à la haute résolution ( algorithmes quadratiques). Plusieurs heures pour LMDZ, échec pour ORCHIDEE. ORCHIDEE : génération à partir d’un fichier de plus basse résolution (144x142) Pb de tenue en mémoire LMDZ : génération des états initiaux sur SX9 (1 To de mémoire). Problème de tenue en mémoire (LMDZ) Restructuration de la dynamique, suppression des tableaux globaux. Gestion du couplé mixte/OpenMP au niveau du gestionnaire de batch LMDZ/ORCHIDEE : MPI/OpenMP : 8 thread/proc, NEMO/OASIS : MPI, 1 proc/coeur Répartition non homogène des processus par nœud de calcul en fonction des codes. Non géré en natif par les gestionnaire de batch Gestion de fichier de configuration PBS « à la main » (aide du support applicatif du CINES) Pas de queue batch dédiée au développement et à la mise au point (queue test) Mise à disposition de ressources dédiées pour le grand défi IPSL 01/04/2017 16
. Plusieurs heures pour LMDZ, échec pour ORCHIDEE. ORCHIDEE : génération à partir d’un fichier de plus basse résolution (144x142) Pb de tenue en mémoire. LMDZ : génération des états initiaux sur SX9 (1 To de mémoire). Problème de tenue en mémoire (LMDZ) Restructuration de la dynamique, suppression des tableaux globaux. Gestion du couplé mixte/OpenMP au niveau du gestionnaire de batch. LMDZ/ORCHIDEE : MPI/OpenMP : 8 thread/proc, NEMO/OASIS : MPI, 1 proc/coeur. Répartition non homogène des processus par nœud de calcul en fonction des codes. Non géré en natif par les gestionnaire de batch. Gestion de fichier de configuration PBS « à la main » (aide du support applicatif du CINES) Pas de queue batch dédiée au développement et à la mise au point (queue test) Mise à disposition de ressources dédiées pour le grand défi IPSL. 01/04/")
17
De nombreuses difficultés
Problèmes hardware Détection de composants défectueux remplacement de toutes les cartes-mère. report du grand défi en octobre. Problèmes physico-numériques instabilité sur les champs convectifs « rayure horizontale » passage à la « nouvelle physique » Gestion des IO 100 Go/mois ~ 50 To/20ans Stockage au CINES Accès au serveur d’archivage instable (NFS) Débit insuffisant Pas de machine de post-traitetement Rapatriement à l’IDRIS (Gaya) Post-traitement… Illustration des instabilités sur le champ de précipitations 01/04/2017 17
 Débit insuffisant. Pas de machine de post-traitetement. Rapatriement à l’IDRIS (Gaya) Post-traitement… Illustration des instabilités sur le champ de précipitations. 01/04/")
18
Mais quelques beaux résultats…
Quelques cyclones… 01/04/2017

19
Conclusions Perspectives
Démonstration de notre capacité à accéder à la haute résolution globale en mode production avec le modèle couplé de l’IPSL. Ouverture de nouveaux champs de recherche scientifique Nécessité d’améliorer la physique des modèles Démonstration de notre aptitude à sortir du vectoriel. Démonstration de notre capacité à accéder aux machines scalaire massivement parallèle de classe pétaflopique (Tiers 0). Mise en évidence de problème hardware sur Jade Un des objectifs de l’accès préliminaire des nouvelles machines avant l’entrée en production Perspectives Prolongement du grand défi par un « preliminary access » au Tiers 0 Curie Réglage de la physique de LMDZ aux hautes résolutions. Préparation pour l’arrivée de la phase II de Curie Projet autour de nouveaux cœurs dynamiques (grilles icosahédriques) Suppression des points singuliers au pôles et du filtre, maillage plus uniforme ANR SVEMO, projet G8 ICOMEX Projet autour des IOs : XMLIO/SERVER (H. Ozdoba – IS-ENES) Souplesse dans la définitions des IO, externalisation sous forme de fichiers hiérarchiques (XML) Processus MPI dédiés aux IOs (aspect SERVER) Ecritures parallèles (netcdf4-HDF5/netcdfpar) Codage en cours de la version 2 (réécriture en C++)
. Mise en évidence de problème hardware sur Jade. Un des objectifs de l’accès préliminaire des nouvelles machines avant l’entrée en production. Perspectives. Prolongement du grand défi par un « preliminary access » au Tiers 0 Curie. Réglage de la physique de LMDZ aux hautes résolutions. Préparation pour l’arrivée de la phase II de Curie. Projet autour de nouveaux cœurs dynamiques (grilles icosahédriques) Suppression des points singuliers au pôles et du filtre, maillage plus uniforme. ANR SVEMO, projet G8 ICOMEX. Projet autour des IOs : XMLIO/SERVER (H. Ozdoba – IS-ENES) Souplesse dans la définitions des IO, externalisation sous forme de fichiers hiérarchiques (XML) Processus MPI dédiés aux IOs (aspect SERVER) Ecritures parallèles (netcdf4-HDF5/netcdfpar) Codage en cours de la version 2 (réécriture en C++)")
20
Prochaine génération de GCM à l’IPSL
- Le projet DYNAMICO -

21
S’appuie sur plusieurs projets
DYNAMICO : groupe de travail autour du développement de nouveaux cœurs dynamique pour LMDZ Leader : Thomas Dubos (LMD polytechnique) Développement : S. Dubesh, F. Hourdin (transport), Marine Tort (atmosphère profonde), Yann Meurdesoif (architecture, implémentation équations GCM et parallélisme). De nombreux autres membres LMD (réunions) S’appuie sur plusieurs projets Collaboration Franco-Indienne ANR SVEMO Projet G8 ICOMEX. Objectif : Préparer les très hautes résolutions du modèle atmosphérique du LMD. < 10 km Cœur non hydrostatique Parallélisme massif.
 Développement : S. Dubesh, F. Hourdin (transport), Marine Tort (atmosphère profonde), Yann Meurdesoif (architecture, implémentation équations GCM et parallélisme). De nombreux autres membres LMD (réunions) S’appuie sur plusieurs projets. Collaboration Franco-Indienne. ANR SVEMO. Projet G8 ICOMEX. Objectif : Préparer les très hautes résolutions du modèle atmosphérique du LMD. < 10 km. Cœur non hydrostatique. Parallélisme massif.")
22
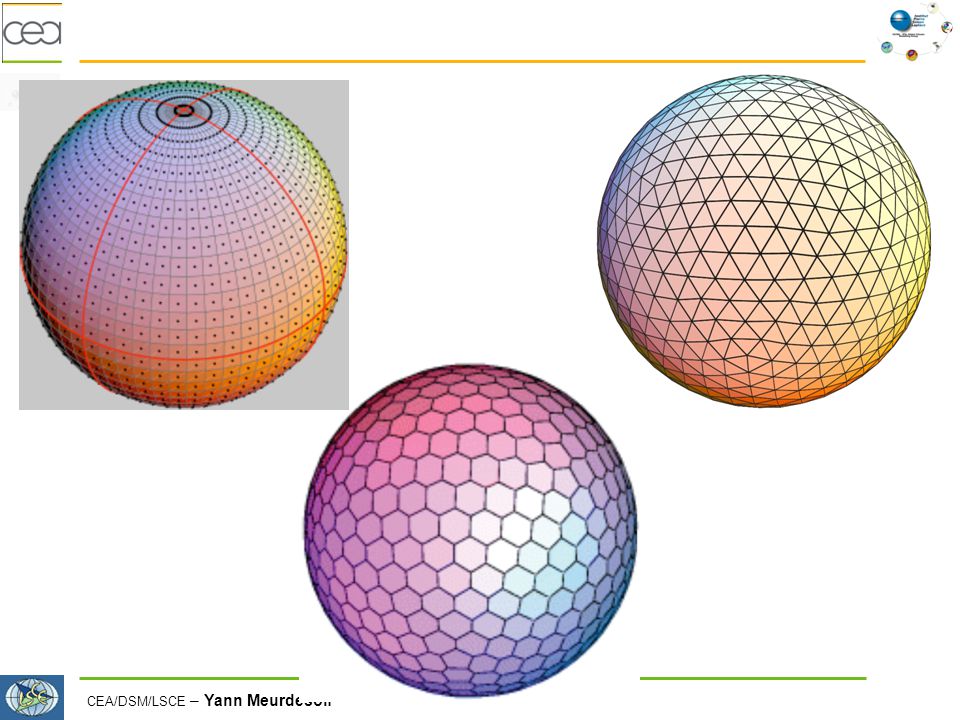
Changement de grille : motivation
La grille lon-lat Resserrement des mailles au pôles Application d’un filtre sur les latitudes polaires Coûteux en CPU Advection sur plusieurs mailles Non idéal pour le parallélisme (découpage en bande) Traitement particuliers aux pôles Coût en performance Complexification du code Grille icosahérique 20 triangles principaux subdivisés en sous-triangles par raffinement. Le sommet d’un triangle correspond au centre d’une maille sur la grille C Chaque maille a 6 mailles voisines Maille hexagonale Sauf aux 12 sommets de l’icosaèdre, 5 mailles voisines 12 mailles pentagonales Grille relativement uniforme, pas de point singulier.
 Traitement particuliers aux pôles. Coût en performance. Complexification du code. Grille icosahérique. 20 triangles principaux subdivisés en sous-triangles par raffinement. Le sommet d’un triangle correspond au centre d’une maille sur la grille C. Chaque maille a 6 mailles voisines. Maille hexagonale. Sauf aux 12 sommets de l’icosaèdre, 5 mailles voisines. 12 mailles pentagonales. Grille relativement uniforme, pas de point singulier.")
24
L’héritage de LMDZ… Grille C de type Arakawa
Quantités scalaires (pression, température…) évaluées au centre des mailles. Vent évalués sur les bords des mailles (composante normale). Vorticité évalué aux sommets des mailles. Quantités conservées (au moins en shalow water) Masse Vorticité potentielle et enstrophie (Vs énergie). Implémentation native du parallélisme massif (blue-gene, 0( ) coeurs) Struture des données en mémoire adaptées aux futures architectures de calcul. GPU Many core (MIC) FPGA ?
 évaluées au centre des mailles. Vent évalués sur les bords des mailles (composante normale). Vorticité évalué aux sommets des mailles. Quantités conservées (au moins en shalow water) Masse. Vorticité potentielle et enstrophie (Vs énergie). Implémentation native du parallélisme massif. (blue-gene, 0( ) coeurs) Struture des données en mémoire adaptées aux futures architectures de calcul. GPU. Many core (MIC) FPGA")
25
Maillage semi-structuré : l’héritage de LMDZ
Principe joindre 2 triangles pour obtenir un losange 10 tuiles en forme de losange Chaque tuile losange peut être facilement subdivisée Domaines parallélépipédiques de dimension iim x jjm Les données de chaque domaine peuvent être aisément stocké en mémoire sous forme de tableau 2D (ou 1D linéarisé)
")
26
Gestion du voisinage Domaines de taille iim*jjm
Donnée stockée dans des tableaux 1D linéarisés real :: cell(iim*jjm) Maille de coordonnée (i,j) : indice n=(j-1)*iim+i 6 mailles proches voisines right : cell(n+t_right) = cell (n+1 ) right-up : cell(n+t_rup) = cell(n+iim ) left-up : cell(n+t_lup) = cell(n+iim-1 ) left : cell(n+t_left) = cell(n-1 ) left-down : cell(n+t_ldown) = cell(n-iim) right-down : cell(n+t_rdown) = cell(n-iim+1 )
 Maille de coordonnée (i,j) : indice n=(j-1)*iim+i. 6 mailles proches voisines. right : cell(n+t_right) = cell (n+1 ) right-up : cell(n+t_rup) = cell(n+iim ) left-up : cell(n+t_lup) = cell(n+iim-1 ) left : cell(n+t_left) = cell(n-1 ) left-down : cell(n+t_ldown) = cell(n-iim) right-down : cell(n+t_rdown) = cell(n-iim+1 )")
27
Données évalué sur un lien (i.e. vents u)
6 liens par maille, un lien est partagé par 2 mailles 3*iim*jjm liens par domaine real :: u(3*iim*jjm) 3 liens sont liés à une maillle Les autres liens sont liés aux cellules voisines Pour une maille n : lien right à l’indice n en mémoire lien left-up à l’indice : n+iim*jjm lien left-down à l’indice : n+2*iim*jjm Accès aux valeurs sur les liens pour une maille n u(n + u_right) = u(n) u(n + u_rup) = u(n + t_rup + u_ldown) = u(n + iim + 2*iim*jjm) u(n +u_lup) = u(n + iim*jjm) u(n +u_left) = u(n + t_left + u_right) = u(n-1) u(n +u_ldown) = u(n + 2*iim*jjm) u(n +u_lright) = u(n + t_ldown + u_lup) = u(n- iim + iim*jjm)
 3 liens sont liés à une maillle. Les autres liens sont liés aux cellules voisines. Pour une maille n : lien right à l’indice n en mémoire. lien left-up à l’indice : n+iim*jjm. lien left-down à l’indice : n+2*iim*jjm. Accès aux valeurs sur les liens pour une maille n. u(n + u_right) = u(n) u(n + u_rup) = u(n + t_rup + u_ldown) = u(n + iim + 2*iim*jjm) u(n +u_lup) = u(n + iim*jjm) u(n +u_left) = u(n + t_left + u_right) = u(n-1) u(n +u_ldown) = u(n + 2*iim*jjm) u(n +u_lright) = u(n + t_ldown + u_lup) = u(n- iim + iim*jjm)")
28
Pour les points de vorticité
Même méthode que pour les liens Un vertex est partagé par 3 mailles, donc 2*iim*jjm vertex par domaine Gestion des pentagones Les 12 pentagones sont considérés comme des hexagones normaux La contribution du lien supplémentaire est annulé en ajustant la métrique i.e. longueur du lien supplémentaire : le = 0 Supression des conditionnels sur les pentagones Exemple : calcul de l’opérateur divergence DO j=jj_begin,jj_end DO i=ii_begin,ii_end n=(j-1)*iim+i dhi(n)=-1./Ai(n)*(ne(n,right)*ue(n+u_right)*le(n+u_right) + & ne(n,rup)*ue(n+u_rup)*le(n+u_rup) & ne(n,lup)*ue(n+u_lup)*le(n+u_lup) & ne(n,left)*ue(n+u_left)*le(n+u_left) + & ne(n,ldown)*ue(n+u_ldown)*le(n+u_ldown) + & ne(n,rdown)*ue(n+u_rdown)*le(n+u_rdown)) ENDDO
*iim+i. dhi(n)=-1./Ai(n)*(ne(n,right)*ue(n+u_right)*le(n+u_right) + & ne(n,rup)*ue(n+u_rup)*le(n+u_rup) + & ne(n,lup)*ue(n+u_lup)*le(n+u_lup) + & ne(n,left)*ue(n+u_left)*le(n+u_left) + & ne(n,ldown)*ue(n+u_ldown)*le(n+u_ldown) + & ne(n,rdown)*ue(n+u_rdown)*le(n+u_rdown)) ENDDO.")
29
Statut actuel Implémentation d‘un cadre de développement suivant la structure décrite précédemment. calcul de la métrique gestion des différents type de champs : scalaire (h,t), vents, vorticité Découpage logique en domaines. Implémentation des échanges de halos entre domaines (pour le moment en mémoire partagée). Implémentation d’un cœur « shalow water » suivant le schéma « TRISK » Conservation de la masse. Conservation de la vorticité potentielle et de l’enstrophie. Implémentation de schémas temporels simples Euler Leapfrog, leapfrog/matsuno Adam-bashforth Implémentation du transport (conservatif, 2nd ordre, FV avec limiteur de pente) Implémentation de la dissipation (laplacien itéré) Sortie des champs au format netcdf Uniquement champ scalaire (maillage primaire) et les champs de vorticité (maillage dual) Visualisation des fichiers de sorties Outil développé par Patrick Brockmann
, vents, vorticité. Découpage logique en domaines. Implémentation des échanges de halos entre domaines (pour le moment en mémoire partagée). Implémentation d’un cœur « shalow water » suivant le schéma « TRISK » Conservation de la masse. Conservation de la vorticité potentielle et de l’enstrophie. Implémentation de schémas temporels simples. Euler. Leapfrog, leapfrog/matsuno. Adam-bashforth. Implémentation du transport (conservatif, 2nd ordre, FV avec limiteur de pente) Implémentation de la dissipation (laplacien itéré) Sortie des champs au format netcdf. Uniquement champ scalaire (maillage primaire) et les champs de vorticité (maillage dual) Visualisation des fichiers de sorties. Outil développé par Patrick Brockmann.")
30
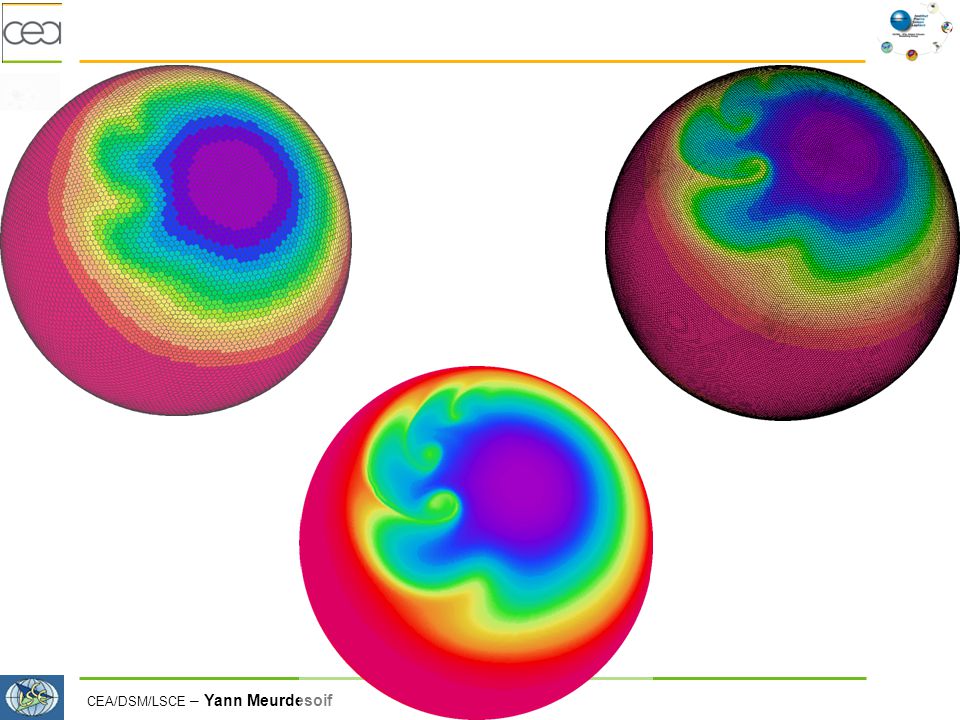
Validation du Shalow Water (2D)
Implémentation de cas test idéalisé Williamson & al.

31
Validation via des cas tests idéalisés (Jablonowki & al, 2006)
Passage au 3D Cœur hydrostatique (~OK) Niveau sigma (LMDZ) Transport 3D (presque OK) Validation via des cas tests idéalisés (Jablonowki & al, 2006) Exercice d’intercomparaison des cœurs dynamiques des GCMs DCMIP2012, NCAR, Boulder(CO), 30/07/ /08/2012.
 Niveau sigma (LMDZ) Transport 3D (presque OK) Validation via des cas tests idéalisés (Jablonowki & al, 2006) Exercice d’intercomparaison des cœurs dynamiques des GCMs. DCMIP2012, NCAR, Boulder(CO), 30/07/ /08/2012.")
Présentations similaires