Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Traitement d’images : concepts fondamentaux
Amélioration d’images Amélioration du contraste Filtrage passe-bas du bruit Morphologie mathématique cas d’images binaires : Erosion, dilatation, ouverture et fermeture binaires, reconstruction géodésique, étiquetage en composantes connexes, squelette Classification Cas pixelique, décision bayésienne, algorithme des k-moyennes Détection de contours Filtrage passe-haut, filtrage optimal, transformée de Hough

2
Classification : objectifs
Mettre en évidence les similarités/ dissimilarités entre les ‘objets’ (e.g. pixels) Obtenir une représentation simplifiée (mais pertinente) des données originales Mettre sous un même label les objets ou pixels similaires Définitions préalables Passer de l’espace des caractéristiques à celui des classes → règle : supervisée / non supervisée, paramétrique / non paramétrique, probabiliste / syntaxique / autre, avec rejet / sans rejet Espace des caractéristiques d (sS, ysd) Espace de décision = ensemble des classes W (sS, xsW), W = {wi, i[1,c] } Règle de décision ( = d(ys) ) Critère de performance numériques ou syntaxiques
 Obtenir une représentation simplifiée (mais pertinente) des données originales. Mettre sous un même label les objets ou pixels similaires. Définitions préalables. Passer de l’espace des caractéristiques à celui des classes → règle : supervisée / non supervisée, paramétrique / non paramétrique, probabiliste / syntaxique / autre, avec rejet / sans rejet. Espace des caractéristiques d (sS, ysd) Espace de décision = ensemble des classes W (sS, xsW), W = {wi, i[1,c] } Règle de décision ( = d(ys) ) Critère de performance. numériques ou syntaxiques.")
3
Ex. de classification non paramétrique
Classification k-ppv (plus proches voisins) On dispose d’un ensemble (de ‘référence’) d’objets déjà labelisés Pour chaque objet y à classifier, on estime ses k ppv selon la métrique de l’espace des caractéristiques, et on lui affecte le label majoritaire parmi ses k ppv Possibilité d’introduire un rejet (soit en distance, soit en ambiguïté) Très sensible à l’ensemble de référence Exemples : Euclidienne, Mahanolobis… Possibilité de modélisation de loi complexes, de forme non nécessairement paramétrique (ex. en 2D disque et couronne) 1-ppv 3-ppv 5-ppv k-ppv (/24)
 On dispose d’un ensemble (de ‘référence’) d’objets déjà labelisés. Pour chaque objet y à classifier, on estime ses k ppv selon la métrique de l’espace des caractéristiques, et on lui affecte le label majoritaire parmi ses k ppv. Possibilité d’introduire un rejet (soit en distance, soit en ambiguïté) Très sensible à l’ensemble de référence. Exemples : Euclidienne, Mahanolobis… Possibilité de modélisation de loi complexes, de forme non nécessairement paramétrique (ex. en 2D disque et couronne) 1-ppv. 3-ppv. 5-ppv. k-ppv (/24)")
4
Connaissance des caractéristiques des classes
Cas supervisé Connaissance a priori des caractéristiques des classes Apprentissage à partir d’objets déjà étiquetés (cas de données ‘complètes’) Cas non supervisé Définition d’un critère, ex. : - minimisation de la probabilité d’erreur - minimisation de l’inertie intra-classe maximisation de l’inertie inter-classes Définition d’un algorithme d’optimisation
 Cas non supervisé. Définition d’un critère, ex. : - minimisation de la probabilité d’erreur. - minimisation de l’inertie intra-classe maximisation de l’inertie inter-classes. Définition d’un algorithme d’optimisation.")
5
Equivalence minimisation de la dispersion intra-classe / maximisation de la dispersion inter-classes

6
Algorithme des c-moyennes (cas non sup.)
Initialisation (itération t=0) : choix des centres initiaux (e.g. aléatoirement, répartis, échantillonnés) Répéter jusqu’à vérification du critère d’arrêt : t++ Labelisation des objets par la plus proche classe Mise à jour des centres par minimisation de l’erreur quadratique : Estimation du critère d’arrêt (e.g. test sur #ch(t) ) c=2 c=3 c=4 Remarques : # de classes a priori Dépendance à l’initialisation c=5
 : choix des centres initiaux (e.g. aléatoirement, répartis, échantillonnés) Répéter jusqu’à vérification du critère d’arrêt : t++ Labelisation des objets par la plus proche classe. Mise à jour des centres par minimisation de l’erreur quadratique : Estimation du critère d’arrêt (e.g. test sur #ch(t) ) c=2. c=3. c=4. Remarques : # de classes a priori. Dépendance à l’initialisation. c=5.")
7
Variantes K-moyennes ISODATA Nuées dynamiques
Regroupement ou division de classes nouveaux paramètres : qN=#min objets par classe, qS seuil de division (division de la classe i si : maxj[1,d]sij > qS et #objets de la classe > 2qN+1 et Iintra(i) > Iintra), qC seuil de regroupement (regroupement des classes i et j si : dist(mi, mj)qC), #max itérations Nuées dynamiques Remplacement de la mesure de ‘distance’ par une mesure de ‘dissemblance’ dis(ys,wi) minimiser classe i représentée par son ‘noyau’, e.g. centre ( K-moyennes), plusieurs ‘échantillons’ de référence zl l[1,p] (dis(.,.) = moyenne des distances de l’objet aux zl)
 > Iintra), qC seuil de regroupement (regroupement des classes i et j si : dist(mi, mj)qC), #max itérations. Nuées dynamiques. Remplacement de la mesure de ‘distance’ par une mesure de ‘dissemblance’ dis(ys,wi) minimiser. classe i représentée par son ‘noyau’, e.g. centre ( K-moyennes), plusieurs ‘échantillons’ de référence zl l[1,p] (dis(.,.) = moyenne des distances de l’objet aux zl)")
8
Probabilités et mesure de l’information
Probabilités fréquencistes / subjectivistes Physique stat. : répétition de phénomènes dans des ‘longues’ séquences probabilité = passage à la limite d’une fréquence ≠ Modèle de connaissance a priori : degré de confiance relatif à un état de connaissance probabilité = traduction numérique d’un état de connaissance Remarque : Quantité d’information et probabilités I = -log2(pi) I ≥ 0, information d’autant plus importante que évènement inattendu (de faible probabilité)
 I ≥ 0, information d’autant plus importante que évènement inattendu (de faible probabilité)")
9
Théorie bayésienne de la décision
La théorie de la décision bayésienne repose sur la minimisation du ‘risque’ Soit Ct(x,x’) le coût associé à la décision de x’ alors que la réalisation de X était x La performance de l’estimateur x’ est mesurée par le risque de Bayes E[Ct(x,x’)] = Coût marginal (conditionnel à y) à minimiser Or x’P(x’/y)=1 et x’, P(x’/y)≥0, La règle qui minimise le coût moyen est donc celle telle que P(x’/y)=1 si et seulement si xP(x/y)Ct(x,x’)=1 P(x’/x,y)=P(x’/y) car décision selon y seul
 le coût associé à la décision de x’ alors que la réalisation de X était x. La performance de l’estimateur x’ est mesurée par le risque de Bayes E[Ct(x,x’)] = Coût marginal (conditionnel à y) à minimiser. Or x’P(x’/y)=1 et x’, P(x’/y)≥0, La règle qui minimise le coût moyen est donc celle telle que P(x’/y)=1 si et seulement si xP(x/y)Ct(x,x’)=1. P(x’/x,y)=P(x’/y) car décision selon y seul.")
10
Exemple Détection d’un véhicule dangereux (V)
Décider V si et seulement si Cas où a>b, on va décider plus facilement V que V en raison du coût plus fort d’une décision erronée en faveur de V que de V

11
Critère du Maximum A Posteriori
Ct(x,x’) = 0, si x = x’ = 1, si x x’
 = 0, si x = x’ = 1, si x x’")
12
Cas d’un mélange de lois normales
Exemples

13
Estimation de seuils (cas supervisé)
Image = ensemble d’échantillons suivant une loi de distribution de paramètres déterminés par la classe ex. : distribution gaussienne Cas 1D (monocanal), si seuil de séparation des classes wi et wi+1, probabilité d’erreur associée : Maximum de vraisemblance :
, si seuil de séparation des classes wi et wi+1, probabilité d’erreur associée : Maximum de vraisemblance :")
14
Maximum de vraisemblance (suite) :
Maximum A Posteriori :

15
Lien c-moyennes / théorie bayésienne
Maximum de vraisemblance sur des lois de paramètres qi (e.g. qi=(mi,Si)) inconnus : Cas d’échantillons indépendants : max. de la logvraisemblance d’où : (*) or : d’où (*) Cas gaussien, Si connus, mi inconnus résolution itérative K-moyennes : Si=Id i[1,c] et P(wi | ys,q) = 1 si wi = xs, = 0 sinon en effet : en effet : d’où :
) inconnus : Cas d’échantillons indépendants : max. de la logvraisemblance. d’où : (*) or : d’où (*) Cas gaussien, Si connus, mi inconnus résolution itérative. K-moyennes : Si=Id i[1,c] et P(wi | ys,q) = 1 si wi = xs, = 0 sinon. en effet : en effet : d’où :")
16
Classification : exercices (I)
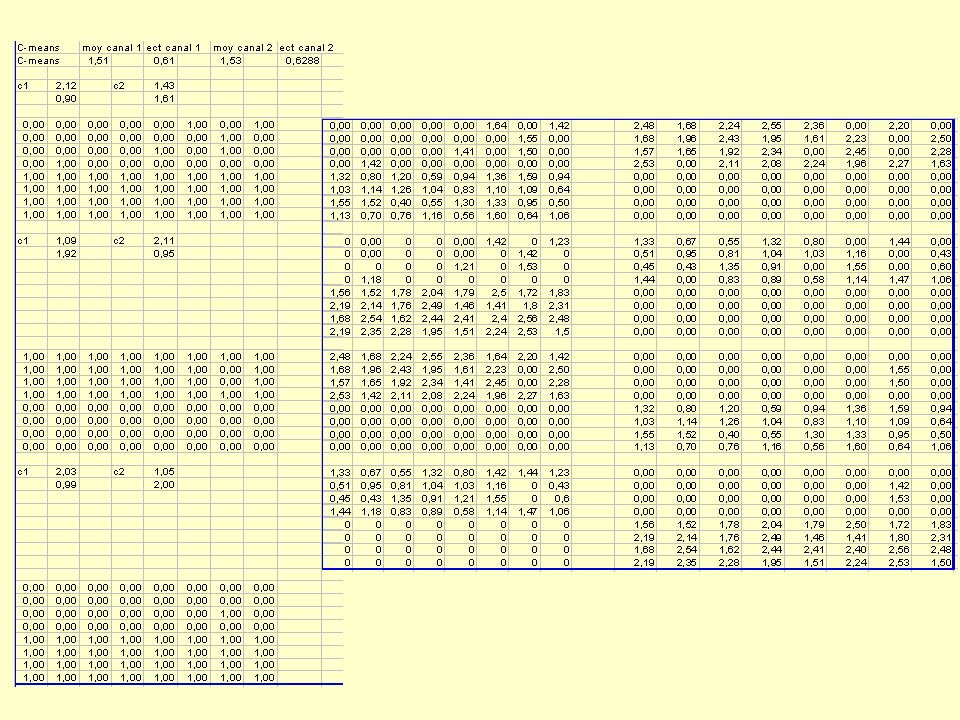
Soit l’image à deux canaux suivante : Soit les pixels de référence suivants : label 1 : valeurs (1,03;2,19) (0,94;1,83) (0,59;2,04) label 2 : valeurs (2,08;0,89) (2,23;1,16) (1,96;1,14) Effectuer la classification au k-ppv. Commentez l’introduction d’un nouveau pixel de référence de label 1 et de valeurs (1,32;1,56) 2,48 1,68 2,24 2,55 2,36 1,64 2,20 1,42 1,96 2,43 1,95 1,61 2,23 1,55 2,50 1,57 1,65 1,92 2,34 1,41 2,45 1,50 2,28 2,53 2,11 2,08 2,27 1,63 1,32 0,80 1,20 0,59 0,94 1,36 1,59 1,03 1,14 1,26 1,04 0,83 1,10 1,09 0,64 1,52 0,40 0,55 1,30 1,33 0,95 0,50 1,13 0,70 0,76 1,16 0,56 1,60 1,06 1,33 0,67 0,55 1,32 0,80 1,42 1,44 1,23 0,51 0,95 0,81 1,04 1,03 1,16 0,43 0,45 1,35 0,91 1,21 1,55 1,53 0,60 1,18 0,83 0,89 0,58 1,14 1,47 1,06 1,56 1,52 1,78 2,04 1,79 2,50 1,72 1,83 2,19 2,14 1,76 2,49 1,46 1,41 1,80 2,31 1,68 2,54 1,62 2,44 2,41 2,40 2,56 2,48 2,35 2,28 1,95 1,51 2,24 2,53 1,50
 (0,94;1,83) (0,59;2,04) label 2 : valeurs (2,08;0,89) (2,23;1,16) (1,96;1,14) Effectuer la classification au k-ppv. Commentez l’introduction d’un nouveau pixel de référence de label 1 et de valeurs (1,32;1,56) 2,48. 1,68. 2,24. 2,55. 2,36. 1,64. 2,20. 1,42. 1,96. 2,43. 1,95. 1,61. 2,23. 1,55. 2,50. 1,57. 1,65. 1,92. 2,34. 1,41. 2,45. 1,50. 2,28. 2,53. 2,11. 2,08. 2,27. 1,63. 1,32. 0,80. 1,20. 0,59. 0,94. 1,36. 1,59. 1,03. 1,14. 1,26. 1,04. 0,83. 1,10. 1,09. 0,64. 1,52. 0,40. 0,55. 1,30. 1,33. 0,95. 0,50. 1,13. 0,70. 0,76. 1,16. 0,56. 1,60. 1,06. 1,33. 0,67. 0,55. 1,32. 0,80. 1,42. 1,44. 1,23. 0,51. 0,95. 0,81. 1,04. 1,03. 1,16. 0,43. 0,45. 1,35. 0,91. 1,21. 1,55. 1,53. 0,60. 1,18. 0,83. 0,89. 0,58. 1,14. 1,47. 1,06. 1,56. 1,52. 1,78. 2,04. 1,79. 2,50. 1,72. 1,83. 2,19. 2,14. 1,76. 2,49. 1,46. 1,41. 1,80. 2,31. 1,68. 2,54. 1,62. 2,44. 2,41. 2,40. 2,56. 2,48. 2,35. 2,28. 1,95. 1,51. 2,24. 2,53. 1,50.")
17
Exercices (I) : correction
 : correction")
18
Classification : exercices (II)
Sur l’image à deux canaux précédente : Déterminer les seuils de décision pour chacun des canaux si l’on suppose 2 classes gaussiennes de caractéristiques respectives : canal 1 : (m1,s1)=(2.0,0.38), (m2,s2)=(1.0,0.34) canal 2 : (m1,s1)=(1.0,0.36), (m2,s2)=(2.0,0.39) Effectuer la classification par seuillage. Effectuer la classification c-means pour c=2. Comparer avec les résultats précédents. Comparer avec la classification c-means pour c=3.
=(2.0,0.38), (m2,s2)=(1.0,0.34) canal 2 : (m1,s1)=(1.0,0.36), (m2,s2)=(2.0,0.39) Effectuer la classification par seuillage. Effectuer la classification c-means pour c=2. Comparer avec les résultats précédents. Comparer avec la classification c-means pour c=3.")
19
Exercices (II) : correction
 : correction")
Présentations similaires

>")











>")





