Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Module calcul parallèle
بـسـم الله الرحــمــن الرحـــيــم Module calcul parallèle Cours DESA ANITS 2005/2006 Abdelhak LAKHOUAJA عبد الحق لخـواجـــة Bureau m10

2
Introduction Nous allons donner une introduction au calcul parallèle et aux machines parallèles. Pour commencer, nous allons traiter un exemple réel pour faire une analogie avec le calcul parallèle.

3
Organisation d'une bibliothèque.
Supposons que les livres sont organisés en plusieurs rayons. Un employé fait le travail dans un certain temps. Pour gagner du temps, on peut utiliser plusieurs employés. Meilleur stratégie de travail? La manière la plus simple est de diviser tous les livres de façon équitable aux employés. Chaque employé doit parcourir la bibliothèque pour stocker les livres. A chaque employé est affecté le même nombre de rayons et le même nombre de livres de façon arbitraire. Chaque employé, soit stocke les livres, soit les passe a un autre employé.

4
L'exemple précédent montre comment une tâche peut être accomplie rapidement en la divisant en plusieurs sous-tâches affectées à plusieurs employés. Il n'y a pas une seule façon d'affecter les tâches aux employés. L'affectation des livres aux employés est un partage de tâches. Passer les livres est un exemple de communication entre les tâches.

5
Pour certains problèmes, affecter le travail à plusieurs employés peut demandé plus de temps que s'il est fait par un seul employé. Certains problèmes s'exécutent complètement en série (creuser un trou).
.")
6
Exemple : Prédiction du temps
1000 x 1000 km², sur 10 km de hauteur Méthode : EDP, éléments finis Élément de 0,1 km de côté => ~ 1010 éléments Prédiction à 4 jours / 10 min => ~600 étapes Un calcul d’élément nécessite 150 flop.

7
Exemple : Prédiction du temps (suite)
Vitesse d’un processeur : 1 Gflop/s (109 flops/s) Nombre total de Flop : 1010 x 150 x 600 = ~ 1015 1 processeur mettrait au minimum 106 s, soit 280 h. Avec 100 processeurs, on peut faire le même calcul en 3h. Certains ordinateurs atteignent aujourd’hui le Tflop/s
 Nombre total de Flop : 1010 x 150 x 600 = ~ processeur mettrait au minimum 106 s, soit 280 h. Avec 100 processeurs, on peut faire le même calcul en 3h. Certains ordinateurs atteignent aujourd’hui le Tflop/s.")
8
Définition Une machine parallèle (appelée aussi système multiprocesseur) est un système composé de plusieurs processeurs. Les processeurs travaillent d'une manière indépendante et peuvent communiquer entre eux pour échanger les données ou partager une mémoire commune. Les processeurs fonctionnent, soit en mode asynchrone (chaque processeur a sa propre unité de contrôle), soit en mode synchrone (tous les processeurs sont dirigés par la même unité de contrôle).
, soit en mode synchrone (tous les processeurs sont dirigés par la même unité de contrôle).")
9
Cette nouvelle conception a entraînée de nouvelles contraintes qui se rajoutent par rapport aux architectures séquentielles : combien de processeurs? à quelle puissance? comment relier les processeurs? comment distribuer les charges aux processeurs? comment diminuer les communications? comment concevoir des algorithmes efficaces?

10
L'introduction du parallélisme a nécessitée d'adapter l'informatique à tout les niveaux:
concepts environnements modèles algorithmique langages …

11
Pour quelles applications ?
Calcul scientifique intensif (High Performance Computing ou HPC) Prédiction météo, climat simulation de crash chimie/physique moléculaire Modèles de pollution, thermique ...
 Prédiction météo, climat. simulation de crash. chimie/physique moléculaire. Modèles de pollution, thermique. ...")
12
Pour quelles applications ? (suite)
Serveurs à grand nombre de transactions/s banques, finance internet, web ... Applications critiques temps-réel contrôle aérien aéronautique, spatial, ferroviaire

13
Classification des architectures parallèles
La classification la plus connue est celle de Flynn (1966), qui classifie les architectures parallèles suivant les flux d'instructions et ceux de données : Single Instruction (SI) Multiple Instruction (MI) Single Data (SD) Multiple Data (MD)
, qui classifie les architectures parallèles suivant les flux d instructions et ceux de données : Single Instruction (SI) Multiple Instruction (MI) Single Data (SD) Multiple Data (MD)")
14
Classification des architectures parallèles
DONNEE SD MD SI SISD SIMD MI MISD MIMD INSTRUCTION

15
Architecture SISD Elle définit la plupart des ordinateurs séquentiels existants d'aujourd'hui. Les instructions sont exécutées de façon séquentielle. Modèle de Von Neumann (1946)
")
16
Architecture SIMD Ce système est composé de plusieurs processeurs identiques, qui ne sont en fait que des unités arithmétiques et logiques programmables et non de véritables processeurs.

17
Les instructions sont émises par la même unité de contrôle (unité de contrôle centralisée).
C'est une architecture multiprocesseurs synchrone

18
La difficulté essentielle de telles machines, est la diffusion synchrone de la même unité de contrôle d'une instruction à plusieurs milliers de processeurs qui est un problème technique complexe. Ces machines sont utilisées pour résoudre des problèmes qui ont une structure régulière

19
Architecture MISD Plusieurs instructions successives traitent la même donnée! Architecture non réalisable!

20
Architecture MIMD Les processeurs exécutent des instructions différentes (Multiple Instruction) sur des données différentes (Multiple Data). Chaque processeur possède sa propre unité de contrôle et sa mémoire locale (de taille petite ou grande).
.")
21
Les communications entre les processeurs sont effectuées, soit :
via une mémoire globale (architecture à mémoire partagée). via l'intermédiaire d'un réseau d'interconnexion (architecture à mémoire distribuée) qui relie physiquement les processeurs entre eux.
. via l intermédiaire d un réseau d interconnexion (architecture à mémoire distribuée) qui relie physiquement les processeurs entre eux.")
22
Architecture des machines parallèles à mémoire partagée
L'architecture de base est composée d'une mémoire globale et de plusieurs processeurs.

23
Les processeurs communiquent entre eux via la mémoire globale et par conséquent le temps de communication entre deux processeurs différents ne dépend pas de la position du processeur dans le réseau. Chaque processeur peut avoir une mémoire locale suffisamment grande pour le traitement local et le stockage temporaire. Le point sensible des architectures à mémoire partagée et la difficulté d'accès à la mémoire (conflits d'accès à la mémoire) qui limite le nombre processeurs. Au delà de quelque dizaine de processeurs les performances commencent à ce dégrader.
 qui limite le nombre processeurs. Au delà de quelque dizaine de processeurs les performances commencent à ce dégrader.")
24
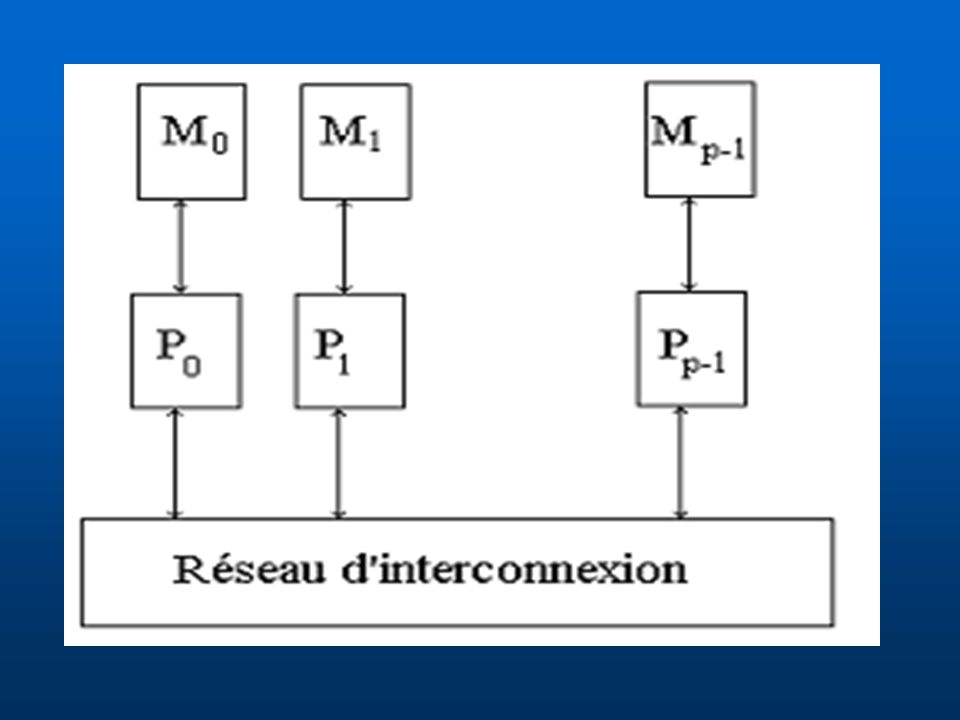
Architecture des machines parallèles à mémoire distribuée
Pour pouvoir connecter un nombre important de processeurs, entre eux et éviter le problème du conflit d'accès à la mémoire dans le cas des mémoires partagées, on a recours à des architectures à mémoire distribuée. Chaque processeur à sa propre mémoire, et communique avec les autres processeurs via un réseau d'interconnexion qui relie physiquement les processeurs entre eux.

26
Le coût de communication entre deux processeurs différents dépend de la position de ces deux processeurs dans le réseau. Plusieurs façons de connecter les processeurs entre eux ont été étudiées. Plusieurs machines parallèles à mémoire distribuée existent et diffèrent suivant la topologie du réseau d'interconnexion.

27
Réseaux d'interconnexion
Un réseau d'interconnexion permet de connecter physiquement les processeurs entre eux. On distingue deux types de réseaux : les réseaux statiques : la topologie est définie une fois pour toute lors de la construction de la machine parallèle. les réseaux dynamiques : la topologie peut varier en cours d’exécution d'un programme. Ce type de réseau est programmable.

28
Le réseau Complet La façon la plus idéale de connecter les processeurs entre eux est celle qui connecte chaque processeur à tous les autres: réseau complet.

29
Le nombre de connexions entre processeurs rend impossible la réalisation d'une telle architecture pour un grand nombre de processeurs. Pour un réseau composé de p processeurs, le nombre de liens pour chacun est p‑1, et ceci n'est pas réalisable pour p grand.

30
Le réseau linéaire C'est l'une des architectures les plus simples.
Les processeurs internes ont deux voisins, et ceux des extrémités ont un seul voisin. P0 P1 P2 P3 P4 La structure n'est pas symétrique et pose des problèmes de communication, surtout si le nombre de processeurs est grand.

31
L'anneau C'est aussi une des architectures les plus simples.
Chaque processeur est connecté à ses deux voisins. P0 P1 P2 P3 P4

32
L'anneau Ce système est efficace, surtout, si les communications sont faites entre processeurs voisins, mais ne convient pas dans le cas contraire.

33
La grille 2D C'est aussi une architecture simple pour laquelle, chaque processeur est relié à quatre autres processeurs au maximum.

34
La grille 2D Un des inconvénients de la grille est le manque de symétrie; les processeurs de bord nécessitent des programmes particuliers. Pour avoir la symétrie, une solution simple consiste à relier les processeurs de bord entre eux. On obtient ainsi un tore 2D.

35
Tore 2D Chaque processeur a exactement quatre voisins.

36
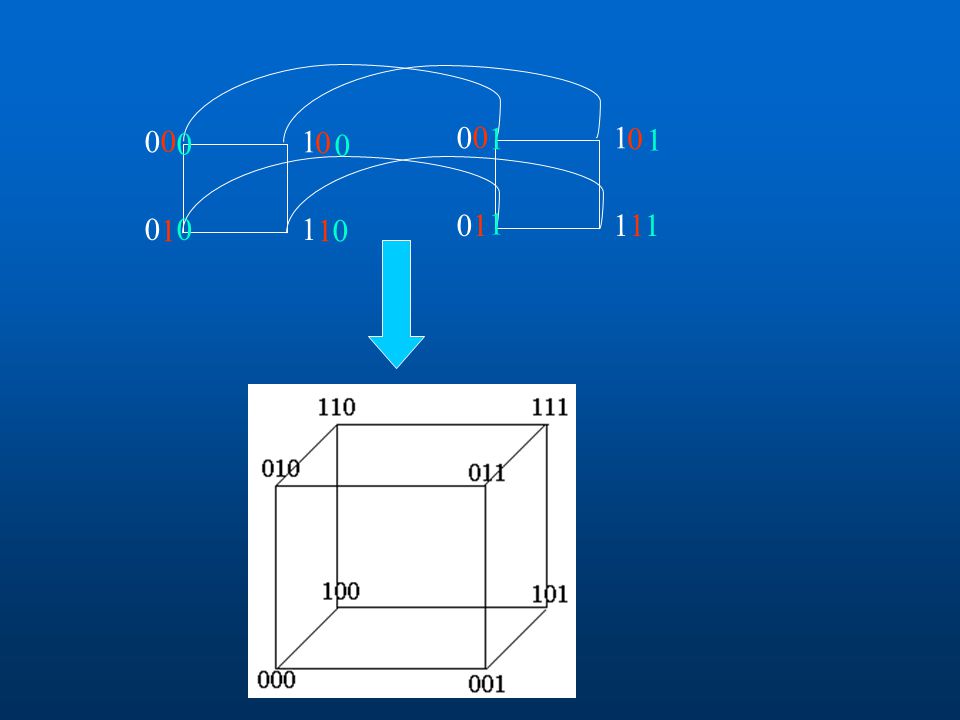
L'hypercube C'est une topologie qui possède plusieurs propriétés très intéressantes. Elle permet l'utilisation de plusieurs processeurs avec un nombre de connexions petit. Un hypercube de dimension d (appelé aussi d‑cube), est composé de 2d processeurs numérotés de 0 à 2d‑1 (en représentation binaire). La connexion de deux processeurs est réalisée, seulement si leurs numéros respectifs (toujours en représentation binaire) diffèrent d'un seul bit. Par conséquent chaque processeur a exactement d liens (d voisins).
, est composé de 2d processeurs numérotés de 0 à 2d‑1 (en représentation binaire). La connexion de deux processeurs est réalisée, seulement si leurs numéros respectifs (toujours en représentation binaire) diffèrent d un seul bit. Par conséquent chaque processeur a exactement d liens (d voisins).")
37
L'hypercube Hypercube de dimension 3

38
L'hypercube La construction de l'hypercube est faite par récurrence :
0‑cube est un seul processeur (d+1)‑cube est obtenu à partir de deux d‑cube en reliant les processeurs de même numéro.
‑cube est obtenu à partir de deux d‑cube en reliant les processeurs de même numéro.")
39
1 1 1 1 1
40
L'hypercube Hypercube de dimension 4

41
Hypercube de dimension 4

42
L'hypercube Plusieurs topologies peuvent être immergées dans l'hypercube : l'anneau, la grille, ... Construction d'un anneau à 8 processeurs à partir d'un hypercube de dimension 3 :

43
Grandeurs des réseaux d'interconnexion
Le diamètre : c'est la distance maximale (nombre de liens) entre deux processeurs quelconque dmini,j = min(d(Pi,Pj)) diamètre = maxi,j (dmini,j) La connectivité : indique de combien de manières différentes deux processeurs peuvent être connectés. Plus la connectivité est grande, plus le réseau est tolérant aux pannes et autorise la communication à un grand nombre de processeurs. Le coût : plusieurs critères peuvent être utilisé pour mesurer le coût d'un réseau. Une façon de définir le coût, est le nombre de liens total du réseau.
 entre deux processeurs quelconque. dmini,j = min(d(Pi,Pj)) diamètre = maxi,j (dmini,j) La connectivité : indique de combien de manières différentes deux processeurs peuvent être connectés. Plus la connectivité est grande, plus le réseau est tolérant aux pannes et autorise la communication à un grand nombre de processeurs. Le coût : plusieurs critères peuvent être utilisé pour mesurer le coût d un réseau. Une façon de définir le coût, est le nombre de liens total du réseau.")
44
sommaire des caractéristiques des réseaux étudiés
Réseau diamètre connectivité coût complet p-1 p(p-1)/2 linéaire p p-1 anneau p/2 p grille 2(p - 1) (p - p ) tore 2 p/2 p hypercube log2(p) log2(p) p log2(p)/2
/2. linéaire p-1 1 p-1. anneau p/2 2 p. grille 2(p - 1) 2 2(p - p ) tore 2 p/2 4 2p. hypercube log2(p) log2(p) p log2(p)/2.")
45
Mesure des performances
Accélération : Elle évalue le gain apporté par l'utilisation d'une machine parallèle. Elle est définie par le rapport : Sp = T1 / TP T1 : temps d'exécution du meilleur algorithme séquentiel (implémenté sur un seul processeur) Tp : temps d'exécution parallèle du même algorithme en utilisant p processeurs.
 Tp : temps d exécution parallèle du même algorithme en utilisant p processeurs.")
46
Exemple : Supposons que : p = 5 T1 = 8 s T5 = 2 s
alors, on a : Sp = 8/2 = 4 Ceci montre que l'algorithme parallèle est 4 fois plus rapide que l'algorithme séquentiel avec utilisation de 5 processeurs.

47
L'accélération est généralement sous-linéaire (Spp)
# processeurs

48
Accélération sur-linéaire
Parfois on a des accélérations sur-linéaires (Sp>p). # processeurs ceci peut s'expliquer par le fait que l'algorithme parallèle : tire profit des caractéristiques matériels (temps d'accès à la mémoire). peut économiser des instructions.
. # processeurs. ceci peut s expliquer par le fait que l algorithme parallèle : tire profit des caractéristiques matériels (temps d accès à la mémoire). peut économiser des instructions.")
49
Exemple Considérons l'algorithme suivant : pour i = 1 à 100 a[i] = 0;
ceci nécessite ~ 300 instructions (incrémentation, test et affectation). Supposons que nous disposons d'une machine composée de 100 processeurs, alors chaque processeur exécutera l'algorithme suivant: i = indice_processeur(); Comme chaque processeur exécute 2 instructions: S100 = 300/2 = 150 > 100
![Exemple Considérons l algorithme suivant : pour i = 1 à 100 a[i] = 0;](http://slideplayer.fr/slide/4932166/16/images/49/Exemple+Consid%C3%A9rons+l+algorithme+suivant+%3A+pour+i+%3D+1+%C3%A0+100+a%5Bi%5D+%3D+0%3B.jpg "ceci nécessite ~ 300 instructions (incrémentation, test et affectation). Supposons que nous disposons d une machine composée de 100 processeurs, alors chaque processeur exécutera l algorithme suivant: i = indice_processeur(); Comme chaque processeur exécute 2 instructions: S100 = 300/2 = 150 > 100.")
50
Efficacité Elle mesure l'accélération moyenne par processeur. Elle est définie par : Ep = Sp / p Ep est comprise entre 0 et 1. Ep = 1, veut dire que les processeurs consacrent 100% de leurs temps à faire du calcul.

51
Exemple : Supposons que : p = 5 T1 = 8 s T5 = 2 s
alors, on a : Sp = 4 et Ep = 4/5 = 0,8 Les processeurs sont utilisés à 80%

52
Loi d’Amdahl Elle établit que l'accélération maximale d'un algorithme est limité par le nombre d'opérations, qui ne peuvent être effectuées que séquentiellement. Supposons que : Tseq = ts + tpar = aTseq + (1-a)Tseq 0a 1 ts est la partie séquentielle de l'algorithme tpar la partie qui se parallélise parfaitement.
Tseq 0a 1. ts est la partie séquentielle de l algorithme. tpar la partie qui se parallélise parfaitement.")
53
On a donc: Tp ts + tpar/p Sp (ts + tpar)/(ts + tpar/p) Sp 1/(a + (1-a)/p) limp 1/(a + (1-a)/p) = 1/a Ceci veut dire que l'accélération borné supérieurement par 1/

54
Loi d’Amdahl La loi d'Amdahl interdit toute accélération sur-linéaire.
Pour l'algorithme : pour i = 1 à 100 a[i] = 0; on peut faire la simulation suivante: i = 1 a[i] =0 … i = 100 Comme il faut 200 instructions, on a : S100 = 200/2 = 100

55
Hit-parade des 500 ordinateurs les plus puissants dans le monde
Liste mise à jour tous les 6 mois par les Universités de Mannheim et de Tennessee Liste actuelle : 26ème liste, novembre 2005

56
Les communications dans les réseaux statiques
Dans la parallélisation d'algorithmes, les communications des données entre processeurs sont des contraintes supplémentaires qui se rajoutent par rapport à l'algorithme séquentiel. Par conséquent, risquent de diminuer les performances des algorithmes parallèles. Pour cela, il nécessaire: soit de les couvrir par les calculs soit d'affecter les tâches aux processeurs efficacement pour diminuer les échanges entre processeurs.

57
Les communications La communication de m données entre deux processeurs voisins est modélisée par : +m : temps d'initialisation : temps de transfert (envoie/réception) d'une donnée 1/ : le débit (aussi appelé bande passante), qui est le nombre de données à envoyer par secondes, exprimé en Mo/s.
 d une donnée. 1/ : le débit (aussi appelé bande passante), qui est le nombre de données à envoyer par secondes, exprimé en Mo/s.")
58
Modèles de communication
Modèle unidirectionnel : on ne peut pas effectuer simultanément l'envoi de Pi vers Pj et de Pj vers Pi sur le même canal. Modèle half-duplex Pi Pj canal de communication (lien physique)
")
59
Modèles de communication
Modèle bidirectionnel : envoi et réception (simultanément) sur le même canal Modèle full-duplex Pi Pj
 sur le même canal. Modèle full-duplex. Pi. Pj.")
60
Communication entre deux processeurs quelconques
But : envoyer un message M de taille m d'un processeur Pi vers Pj, distants de h (h est le nombre de liens entre Pi et Pj). Exemple: h=4 Pi Pj
. Exemple: h=4. Pi. Pj.")
61
Première solution: Envoyer le message M (complet) de proche en proche en passant par les processeurs intermédiaires (store-and-forward) : Pi Pj M Etape 1: Pi Pj M Etape 2: Pi Pj M Etape 3: Pi Pj M Etape 4:

62
au bout de h étapes, le message M arrive à sa destination.
le coût pour envoyer M est : h(b + mt) = hb + hmt
 = hb + hmt.")
63
Deuxième solution : Utilisation du technique du pipeline : le message est découpé en q paquets, M1, …, Mq de même taille m/q. Exemple : M = q=3. M3 M2 M1

64
Etape 1: Etape 2: Etape 3: Etape 4: Etape 5: Etape 6: Pi Pj Pi Pj Pi
M1 Etape 1: Pi Pj M1 Etape 2: M2 Pi Pj M1 Etape 3: M2 M3 Pi Pj M1 Etape 4: M2 M3 Pi Pj Etape 5: M2 M3 Pi Pj Etape 6: M3

65
tq = t = (h+q-1)(b + m/qt) = f(q)
Le premier paquet M1 arrive à Pj au temps : t1 = h(b + m/qt) Le deuxième paquet M2 arrive à Pj au temps : t2 = t1 + (b + m/qt) Le message M arrive à Pj lorsque le dernier paquet Mq arrive à Pj tq = t(q-1) + (b + m/qt) Par récurrence : tq = t = (h+q-1)(b + m/qt) = f(q)
 Le deuxième paquet M2 arrive à Pj au temps : t2 = t1 + (b + m/qt) Le message M arrive à Pj lorsque le dernier paquet Mq arrive à Pj. tq = t(q-1) + (b + m/qt) Par récurrence : tq = t = (h+q-1)(b + m/qt) = f(q)")
66
Question : Quel est le nombre de paquets qui minimise t?
f(q) = (h+q-1)(b + m/qt) = (h-1)b + mt + (h-1)mt/q + qb f'(q) = b - (h-1)mt/q2 f'(q) = 0 f''(q) 0 q0 est un minimum global
 = (h+q-1)(b + m/qt) = (h-1)b + mt + (h-1)mt/q + qb. f (q) = b - (h-1)mt/q2. f (q) = 0 f (q) 0 q0 est un minimum global.")
Présentations similaires
>")







>")





>")

>")


