Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Aperçu des architectures des systèmes d’information web
Camille MAUSSANG – IC05 – 11 mai 2004

2
Plan Le web : sytème de données semi-structurées Crawler ? Architecture d’un moteur de recherche Cas de Google 98 Architecture de TARENTe v2 Perspectives Références

3
Le web : système de données semi-structurées
Ensemble de pages HTML reliées entre elle par des liens hypertextes et transmises à travers le protocole HTTP. Trois inconvénients majeurs Formats hétérogènes (Flash, PDF, etc.) Dynamisme temporel - programmes côté serveur (CGI) cookies - code exécuté côté serveur (PHP) formulaires - code exécuté côté client (Java, ActiveX) Souplesse vis à vis du code Pour y remédier - Traitements spécifiques - Formaliser le dynamisme - Faculté de « corriger » les erreurs de syntaxe
 Dynamisme. temporel - programmes côté serveur (CGI) cookies - code exécuté côté serveur (PHP) formulaires - code exécuté côté client (Java, ActiveX) Souplesse vis à vis du code. Pour y remédier. - Traitements spécifiques. - Formaliser le dynamisme. - Faculté de « corriger » les erreurs de syntaxe.")
4
Crawler ? Auparavant Collections fermées, possibilité d’établir un catalogue exhaustif Aujourd’hui L’unique moyen d’obtenir un index est de collecter des pages liées à d’autres pages déjà collectées Fonctionnement soumission d’URL download (extraction des liens) traitement Crawler à grande échelle Être capable de télécharger beaucoup de pages en peu de temps tout en respectant les règles de politesse et sans surcharger le réseau Gestion du DNS Sockets asynchrone Eviter les pièges à robot
 traitement. Crawler à grande échelle. Être capable de télécharger beaucoup de pages en peu de temps tout en respectant les règles de politesse et sans surcharger le réseau. Gestion du DNS. Sockets asynchrone. Eviter les pièges à robot.")
5
Schéma de l’architecture de 98
Download des pages Stockage et compression URLs à crawler Crawler Stockage des pages (docID) URL Server Crawler Store Server Crawler Repository Stockage des liens (from, to, texte) Anchors Reconstruction des URLs, docIDs Parsing et indexation Indexer URL resolver Lexique (régénéré à partir de l’index inverse) Stockage des mots (occ., typo, position) Stockage des liens (docID_f, docID_t) Lexicon Barrels Links Doc Index Génération de l’index inverse Sorter Index des docIDs Pagerank Searcher Calcul du Pagerank Moteur de recherche
 URL. Server. Crawler. Store. Server. Crawler. Repository. Stockage des liens (from, to, texte) Anchors. Reconstruction. des URLs, docIDs. Parsing et indexation. Indexer. URL. resolver. Lexique (régénéré à partir. de l’index inverse) Stockage des mots. (occ., typo, position) Stockage des liens. (docID_f, docID_t) Lexicon. Barrels. Links. Doc. Index. Génération de l’index inverse. Sorter. Index des docIDs. Pagerank. Searcher. Calcul du Pagerank. Moteur de recherche.")
6
Détails sur Google Le crawler de Google : GoogleBot Fresh Bot (MAJ)
Deep Bot (Indexation massive) La GoogleDance toutes les 4 semaines Pagerank - Si A pointe B alors le pagerank de B augmente. - Le pagerank de B augmente en fonction du pagerank de A. - Moins A possède de liens plus le pagerank de B augmente. Favorise la connectivité au dépend d’autres facteurs : Traffic des sites pointant vers B Nb. de clics sur le lien de A vers B Nb. de clics sur le lien des résultats de Google vers B Yahoo! Search Technology Le crawler de Yahoo! : Slurp
 La GoogleDance toutes les 4 semaines. Pagerank. - Si A pointe B alors le pagerank de B augmente. - Le pagerank de B augmente en fonction du pagerank de A. - Moins A possède de liens plus le pagerank de B augmente. Favorise la connectivité au dépend d’autres facteurs : Traffic des sites pointant vers B. Nb. de clics sur le lien de A vers B. Nb. de clics sur le lien des résultats de Google vers B. Yahoo! Search Technology. Le crawler de Yahoo! : Slurp.")
7
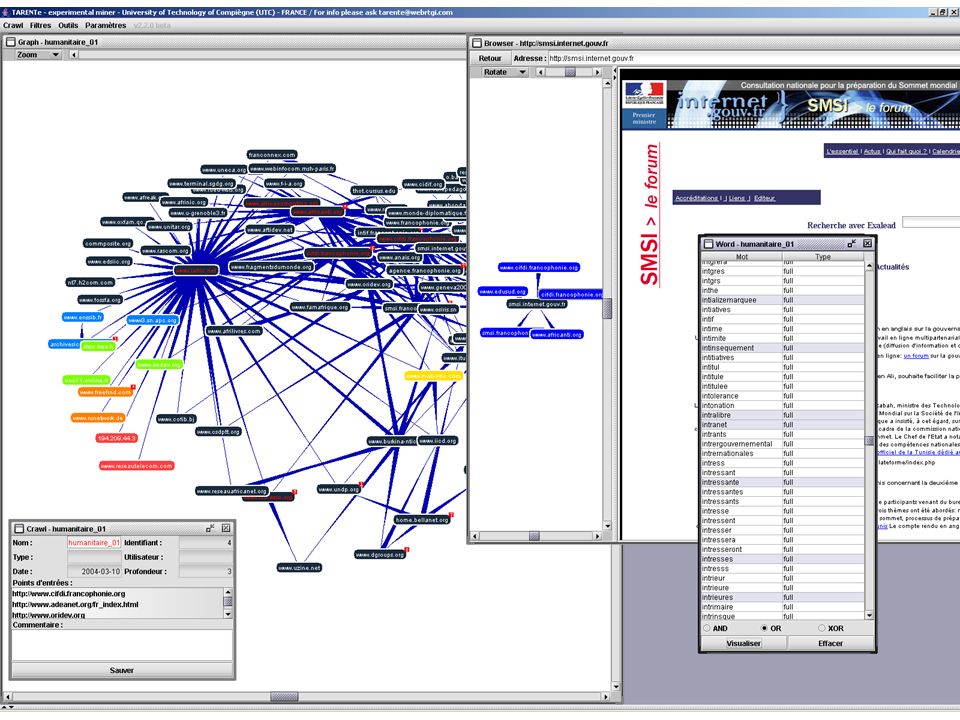
Schéma de l’architecture de TARENTe v2
Download des pages Dictionnaire des mots Indexation Word Pile d’URLs à crawler Crawler Crawler Page Analyser Worm URLs toVisit Stockage des nœuds Node URL Submiter Extraction des liens Traitements statistiques Stockage des liens URL Expander Link CHP Soumet à la politique de crawl URLs Already Visited HITS like Crawler Pile d’URLs déjà visitées Exportation Export - Problèmes à grande échelle - Centré sur l’utilisateur TouchGraph WordTable Map

9
Perspectives Focused Crawler
Parcours « guidé » du web à partir d’indices de contenus Crawler périodique - Crawler de « rafraîchissement », tourne en continu - Optimise la fraîcheur de la base Crawler de deep-web - Crawler couplé à une table d’association (Label/Value) - Capable de remplir un formulaire Crawler de forum - Corrélation topologique/sémantique naturelle - Extraction de profils d’acteurs
 - Capable de remplir un formulaire. Crawler de forum. - Corrélation topologique/sémantique naturelle. - Extraction de profils d’acteurs.")
10
Références http://wwwetu.utc.fr/~cmaussan/dea.html (fr) Bibliographie
Développements de Google (fr) Comment optimiser son référencement chez Google et Yahoo! (en) Portail dédié aux moteurs de recherche
 Comment optimiser son référencement. chez Google et Yahoo! (en) Portail dédié aux moteurs de recherche.")
Présentations similaires