Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Faculté des Sciences de Rabat
Bases de Données Dr. M.Benkhalifa Faculté des Sciences de Rabat Septembre 2008

2
Introduction Générale
Historique des Bases de donnees (Pré-relationnel Relationnel post-Relationnel) Emploi des fichiers (ensemble d’enregistrements) Passage au Système de fichiers pour gérer un ensemble plus complexe de fichiers. Système de fichiers conventionnels = problèmes. 1ere génération des SGBD (hiérarchique /réseau): séparation des programmes d’applications des données. 2eme génération des SGBD (relationnel): model relationnel. BD orientées objet Entrepôts de données. ( data warehouses) Parallélisme entre SGBD et compilateurs : Langages : machine --- langage naturel SGBD: interface entre utilisateur et données.
 Emploi des fichiers (ensemble d’enregistrements) Passage au Système de fichiers pour gérer un ensemble plus complexe de fichiers. Système de fichiers conventionnels = problèmes. 1ere génération des SGBD (hiérarchique /réseau): séparation des programmes d’applications des données. 2eme génération des SGBD (relationnel): model relationnel. BD orientées objet. Entrepôts de données. ( data warehouses) Parallélisme entre SGBD et compilateurs : Langages : machine --- langage naturel. SGBD: interface entre utilisateur et données.")
3
1965 – 1970 SGBD navigationel: hiérarchique, réseau
1950 – 1965 SGF 1965 – 1970 SGBD navigationel: hiérarchique, réseau … SGBD relationnel Exemples : DB2, Oracle, Teradata, Informix, mySQL, SQL-Server SGBD orienté objets. En pratique : une impasse Exemples: O2, Objectstore, Objectivity … SGBD relationnel – objet (RO).
.")
4
Exemples de Bases de données: Système de cartes de crédits Stock
Banques,universités….. Agences de voyages Réservations d'hôtels Compagnies de ventes… Système de Gestion de Fichiers: Chaque département possède ses propres applications et fichiers. Exemple d’un SGF – voir le transparent suivant. Limites des SGF Gestion des données. Exige trop de programmation en langage (3GL) Consomme du temps Les requêtes ad-hoc sont impossible a satisfaire Mène au “ islands of information” Dépendances des données Dépendance structurelle. Redondance anomalies, non intégrité, inconsistance Système de Gestion de Base de Données: Tous les départements partagent la même BD, qui est une large collection de données gérée par un logiciel appelé SGBD.
 Consomme du temps. Les requêtes ad-hoc sont impossible a satisfaire. Mène au islands of information Dépendances des données. Dépendance structurelle. Redondance anomalies, non intégrité, inconsistance. Système de Gestion de Base de Données: Tous les départements partagent la même BD, qui est une large collection de données gérée par un logiciel appelé SGBD.")
5
SGF

6
Environnement BD

7
Pourquoi une BD? Exemple: 3 départements: vie, autos, locaux
3 programmes d’applications pour chaque dept: gestion des assurances: F1: assures;P1,P2, P3 gestion des sinistres: F2:sinistres; P4,P5 Règlement des sinistres: F1, F2; P6 Figure Problèmes de cette conception? Redondance de l’information Inconsistance de l’information Les pgs sont dépendants des données Les données sont accessibles uniquement à travers des pgs Trop grand délais de réponse.

8
SGF BD redondance de l’information dépendances des pgs des données
données sont accessibles seulement a travers des pgs Données dispersées Chacun a ses propres fichiers unicité de l’information indépendance des pgs des données des pgs généraux : langages de requêtes accessibles par les non informaticiens intégration des données partage des données par plusieurs utilisateurs

9
Tâches/rôles dans l'environnement des BDs:
Utilisateur: (naïf, spécialiste) accède aux données a travers des programmes/ à travers des langages de requêtes. Programmeur: développe des programmes pour d’autres utilisateurs. Administrateur de la BD: responsable de la conception, création et la maintenance de la BD. = super-utilisateur Administrateur de données: responsable d’établir la politique des données.
 accède aux données a travers des programmes/ à travers des langages de requêtes. Programmeur: développe des programmes pour d’autres utilisateurs. Administrateur de la BD: responsable de la conception, création et la maintenance de la BD. = super-utilisateur. Administrateur de données: responsable d’établir la politique des données.")
10
Chapitre 1 Concepts de base d’une BD
Qu’est ce qu’une BD? Information # données. 2 concepts fondamentaux: La base de données: Ensemble structure de données interdépendants, stockées sans redondance inutile sur des supports accessibles par ordinateur, organisées de manière indépendante des pgs pour satisfaire simultanément plusieurs utilisateurs de façon sélective et en un temps opportun. Il est sous le contrôle d’une seule autorité qui est l’administrateur de la BD. Un SGBD: Un logiciel qui permet à un utilisateur d'interagir avec une BD. (stocker, chercher, mettre a jour, …..)
")
11
Les fonctions d’un SGBD:
Stocker les données sur les supports périphériques. Rechercher des informations. Sélectionner des données. Description des données: langage de description des données. Logique /physique Utilisation: interaction avec la BD Intégrité: définir des règles (contraintes) pour maintenir l'intégrité de la BD. La confidentialité: Synchronisation des accès: Sécurité
 pour maintenir l intégrité de la BD. La confidentialité: Synchronisation des accès: Sécurité.")
12
Importance d’un SGBD Gestion de données plus efficace
Le langage de requêtes permet des réponses rapides aux requêtes Ad-hoc Favorise une intégration de toutes les opérations de l’entreprise.

13
Les différents niveaux de représentation d’une BD
3 niveaux suivant que l’on regarde du coté utilisateur ou du coté stockage physique: Le niveau conceptuel: correspond au schéma conceptuel de la BD (la partie fondamentale de la BD) Le niveau externe: schémas externes qui correspondent aux différents groupes d’utilisateurs. Le niveau interne: schéma physique. Figure des 3 niveaux. Niveau interne: comment les données sont stockées en terme de fichiers physiques, types d'adressage, indexes….. Niveau conceptuel: le passage du monde réel (ce qu’on veut stocker dans la BD) au schéma conceptuel correspond à un processus de modélisation. = modèle de données : entité relation.
 Le niveau externe: schémas externes qui correspondent aux différents groupes d’utilisateurs. Le niveau interne: schéma physique. Figure des 3 niveaux. Niveau interne: comment les données sont stockées en terme de fichiers physiques, types d adressage, indexes….. Niveau conceptuel: le passage du monde réel (ce qu’on veut stocker dans la BD) au schéma conceptuel correspond à un processus de modélisation. = modèle de données : entité relation.")
14
Exemple: Modèle de données permet de décrire les associations (relations) entre les objets. Dans une BD universitaire: (étudiants, enseignants, cours,…) Inscription: elle associe un étudiant à un enseignement. On distingue 3 grandes catégories de modèles qui se distinguent par la nature des associations qu’ils permettent de modéliser: modèle hiérarchique modèle réseau modèle relationnel. Le niveau externe: correspond à la vision de tous ou une partie du schéma conceptuel par un groupe d’utilisateurs concernés par une application. Utilisateurs concernés par l’inscription des étudiants n’ont pas besoin d’avoir une vue globale sur la BD.== sous schéma. (vue)
 Inscription: elle associe un étudiant à un enseignement. On distingue 3 grandes catégories de modèles qui se distinguent par la nature des associations qu’ils permettent de modéliser: modèle hiérarchique. modèle réseau. modèle relationnel. Le niveau externe: correspond à la vision de tous ou une partie du schéma conceptuel par un groupe d’utilisateurs concernés par une application. Utilisateurs concernés par l’inscription des étudiants n’ont pas besoin d’avoir une vue globale sur la BD.== sous schéma. (vue)")
15
Mise en œuvre d’un SGBD:
Comment est t-il possible qu’un utilisateur interagit avec la BD à travers un SGBD? = langages pour décrire et pour manipuler les données. Langage de description de données: primitives construction du schéma conceptuel ainsi que les sous schémas, les contraintes d'intégrité. Langage de manipulation de données: langage de requêtes. 2 objectifs: 1) être autonome 2) peut être utilise avec un langage évolué. Exécution d’une requête par un SGBD: Un programmeur écrit son programme à partir des connaissances sur le schéma externe. Le SGBD convertit la requête en terme de schéma conceptuel puis en commandes sur la BD physique.== figure. Architecture d’un SGBD:== figure
 être autonome 2) peut être utilise avec un langage évolué. Exécution d’une requête par un SGBD: Un programmeur écrit son programme à partir des connaissances sur le schéma externe. Le SGBD convertit la requête en terme de schéma conceptuel puis en commandes sur la BD physique.== figure. Architecture d’un SGBD:== figure.")
16
Administration d’une BD:
Création de la BD. Gestion des autorités d'accès: Amélioration des performances. Sécurité et cohérence des données. Manipulation du dictionnaire des données. Structures de stockage et méthodes d'accès Rédaction avec l’utilisateur du schéma externe.

17
Chapitre 2 Organisation Physique d’une BD
Problème de Performance: (Temps de lecture DD est + élevé) Organisation des données Structures d’indexation Algorithmes de recherche Stockage de données: Technologie RAID (Redundant Array of indeependant Disks) Limiter les conséquences de pannes en répartissant les données sur un grand nombre de disques de manière à s’assurer que la défaillance de l’un des disques n’entraîne ni perte de données ni l’indisponibilité du système. RAID 0, RAID1, RAID4, RAID5 Fichiers Le SGBD ne s’appuit pas sur le SGF du SE. Pourquoi? Le SGBD a son propre SGF: SE un Fichier est une suite d’octets répartis sur les blocs Disque. organisation : Arborescence. SGBD un Fichier est une ensemble d’enregistrements (ensemble d’attributs) dont chacun a un type (nombre d’octets) Organisation: liste de blocs regroupés (contigus) chaînés entre eux. - structure utilisé pour stockage BONNE Organisation: optimiser le Temps et l’Espace doit réaliser compromis entre les 4 principales opérations: INSERTION, RECHERCHE, MODIFICATION et DESTRUCTION
 Organisation des données. Structures d’indexation. Algorithmes de recherche. Stockage de données: Technologie RAID (Redundant Array of indeependant Disks) Limiter les conséquences de pannes en répartissant les données sur un grand nombre de disques de manière à s’assurer que la défaillance de l’un des disques n’entraîne ni perte de données ni l’indisponibilité du système. RAID 0, RAID1, RAID4, RAID5. Fichiers. Le SGBD ne s’appuit pas sur le SGF du SE. Pourquoi Le SGBD a son propre SGF: SE un Fichier est une suite d’octets répartis sur les blocs Disque. organisation : Arborescence. SGBD un Fichier est une ensemble d’enregistrements (ensemble d’attributs) dont chacun a un type (nombre d’octets) Organisation: liste de blocs regroupés (contigus) chaînés entre eux. - structure utilisé pour stockage. BONNE Organisation: optimiser le Temps et l’Espace. doit réaliser compromis entre les 4 principales opérations: INSERTION, RECHERCHE, MODIFICATION et DESTRUCTION.")
18
Organisation Séquentielle:
Accès Séquentiel Simple: l’ordre logique des enregistrements (par rapport à la valeur de la clé primaire) correspond à l’ordre physique de stockage. Grande taille du fichier == accès trop lent Accès Séquentiel Indexé: Créer un (ou plusieurs) index 1) Index non dense: - fichier trié sur clé primaire - l’index est un fichier contenant: (clé, Adr) - toutes les valeurs de clé existant dans le fichier de données ne sont pas représentées dans l’index. 2) Index Dense: - baser l’index sur toutes les valeurs de clé existant dans le fichier de données. 3) Index multi-niveaux: - créer un index pour l’index.
 correspond à l’ordre physique de stockage. Grande taille du fichier == accès trop lent. Accès Séquentiel Indexé: Créer un (ou plusieurs) index. 1) Index non dense: - fichier trié sur clé primaire. - l’index est un fichier contenant: (clé, Adr) - toutes les valeurs de clé existant dans le fichier de données ne sont pas représentées dans l’index. 2) Index Dense: - baser l’index sur toutes les valeurs de clé existant dans le fichier de données. 3) Index multi-niveaux: - créer un index pour l’index.")
19
Organisation arborescente:
Plusieurs niveaux d’index sont utilisés Le dernier niveau est celui des feuilles (données) Tous les autres niveaux supérieurs sont des index non denses. 1) Arbre Binaire: Exp: Inconvénient: Déséquilibre provoqué par les insertions et suppressions = Arbre équilibré 2) B- Arbre : B-arbre d’ordre d est un arbre équilibré avec pour chaque nœud (sauf la racine ) - nombre de clés compris entre d et 2d - nombre de pointeurs entre d+1 et 2d+1 (la racine peut comprendre seulement 2 pointeurs et une clé.) pour localiser un enregistrement , le nombre maximum d’accès disque est LOG par rapport à la taille globale du fichier : LOG d (N)
 Tous les autres niveaux supérieurs sont des index non denses. 1) Arbre Binaire: Exp: Inconvénient: Déséquilibre provoqué par les insertions et suppressions. = Arbre équilibré. 2) B- Arbre : B-arbre d’ordre d est un arbre équilibré avec pour chaque nœud (sauf la racine ) - nombre de clés compris entre d et 2d. - nombre de pointeurs entre d+1 et 2d+1. (la racine peut comprendre seulement 2 pointeurs et une clé.) pour localiser un enregistrement , le nombre maximum d’accès disque est LOG par rapport à la taille globale du fichier : LOG d (N)")
20
B+ arbre: est un arbre dont toutes les clés (avec éventuellement les enregistrements) résident dans les feuilles de l’arborescence. Les niveaux supérieurs jusqu’à la racine jouent le rôle d’index. Les feuilles sont liées séquentiellment. Recherche: Accès direct par clé: Accès séquentiel.

21
Conception Logique d’une BD
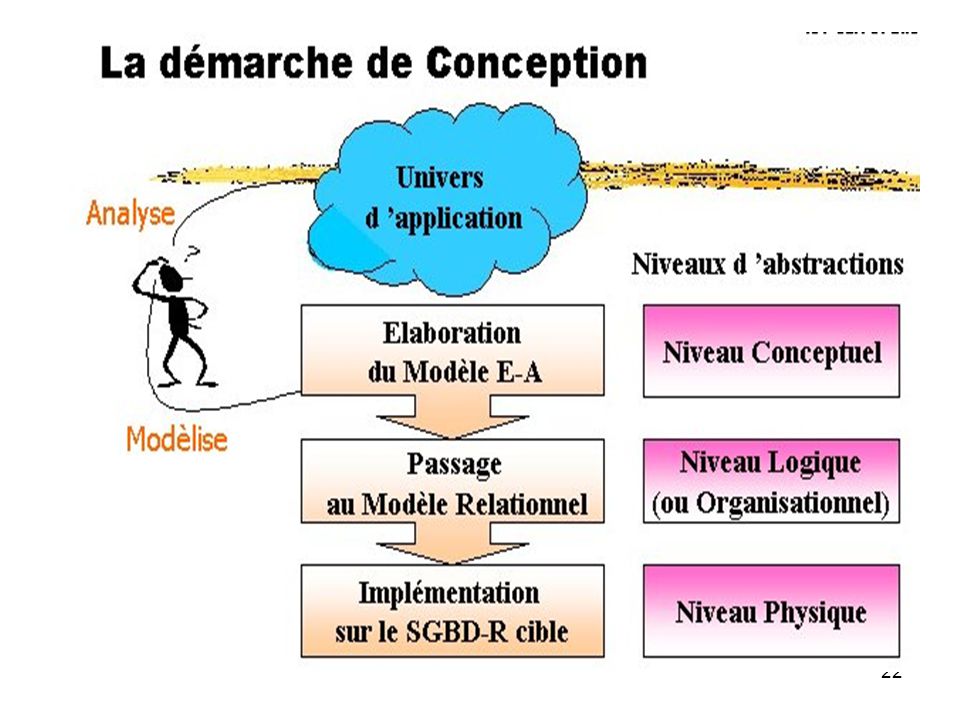
Les BD constituent le cœur du système d’information. La conception de ces bases est la tâche la plus ardue du processus de développement du système d’information. Les méthodes de conception préconisent une démarche en étapes et font appel à des modèles pour représenter les objets qui composent les systèmes d’information, les relations existantes entre ces objets ainsi que les règles sous-jacentes. La modélisation se réalise en trois étapes principales qui correspondent à trois niveaux d’abstraction différents :

23
voir fichier conception des BDs

24
Chapitre 4 Model Hierarchique
Définition: un modèle hiérarchique est un ensemble de définitions d’arborescences. Une définition d’arborescence est un diagramme de données dans lequel chaque entité sauf la racine a un seul arc incident de type 1:N, et 0, 1 ou plusieurs arcs émergents de type 1:N. Chaque arc entre 2 entités est unique par conséquent il n’est pas nécessaire de l’identifier par une étiquette. Exemples: Une base de données hiérarchique est un ensemble d’occurrences de définitions d’arborescence. Exemples: du modèle hiérarchique a la BD hiérarchique. La relation Parent-Enfant: Une occurrence d’entité d’un niveau i est dite parent si elle est associée au moins avec une occurrence d’entité de niveau i+1. Exemple.

25
Modèle Hiérarchique: Accès
3 primitives d’accès sont disponibles: (A) recherche de la racine à partir de la clé primaire (B) accès séquentiel au suivant d’un segment (C) accès séquentiel des fils d’un segment Traduction du schéma conceptuel: liens 1:N et N:M
 recherche de la racine à partir de la clé primaire. (B) accès séquentiel au suivant d’un segment. (C) accès séquentiel des fils d’un segment. Traduction du schéma conceptuel: liens 1:N et N:M.")
26
Défauts du modèle hiérarchique:
Défauts de mise a jour: Exemple: Problème de suppression: élimination d’une occurrence entraîne l’élimination de tous ses descendants. Exp: Problème d’insertion: on ne peut insérer une occurrence d’un segment fils tant qu’on n’a pas insérer au préalable tous les parents hiérarchiques et ceci jusqu’a la racine. Exemple. Problème de modification: entraîne un risque d’incohérence et un coût très élevé. Problème de consultation: requêtes non satisfaites. En plus Difficulté d’exprimer les liens mailles. Une modification de la conception par l’utilisateur peut entraîner une perte d’efficacité du système. Exp. Espace de stockage très important. Impossible d’exprimer des parents multiples. Limitation quant au nombre de sous schémas.

27
Avantages du modèle hiérarchique:
Conceptuellement simple a comprendre et a utiliser Plusieurs applications nécessitent uniquement des relations 1:N.

28
Chapitre 5 Le Modèle Réseau
L’approche hiérarchique est un cas particulier d’une structure réseau. Le modèle réseau est plus général du fait qu’une occurrence d’une entité donnée peut avoir n’importe quel nombre de parents immédiats. l’approche réseau nous permet de modéliser une relation de type N:M d’une façon plus directe que l’approche hiérarchique. L’une des façons pour représenter une structure réseau est celle qui est basée sur les relations binaires et qui correspond au modèle DBTG (Data Base Task Group) Le modèle DBTG est base sur la notion du SET qui représente une relation binaire entre 2 types d’enregistrements: Le 1er type est appelé possesseur (owner) Le 2eme type est appelé membre (member) Construction de SET dans différentes structures: Structure hiérarchique à un niveau: exemple Structure hiérarchique à plusieurs niveaux: exemple. Les lien mailles: exemple.
 Le modèle DBTG est base sur la notion du SET qui représente une relation binaire entre 2 types d’enregistrements: Le 1er type est appelé possesseur (owner) Le 2eme type est appelé membre (member) Construction de SET dans différentes structures: Structure hiérarchique à un niveau: exemple. Structure hiérarchique à plusieurs niveaux: exemple. Les lien mailles: exemple.")
29
Avantages: Inconvenients: Le modèle réseau: accès
3 Primitives d’accès sont disponibles: – (A) recherche du propriétaire d’un set à partir de la clé primaire – (B) accès séquentiel aux membres d’un set à partir de son propriétaire – (C) accès au propriétaire d’un set à partir d’un membre quelconque Exp: Voir exemple: (fichier model Hier+Reseau) Avantages: Il n’y a pas d’anomalies de MAJ : Suppression: Modification: Insertion: La representation naturelle des liens mailles (M:N) Inconvenients: Proceduralité des LMD == l’utilisateur doit naviguer les chaines de pointeurs. ==== le chemin optimal pour retrouver l’information.
 recherche du propriétaire d’un set à partir de la clé primaire. – (B) accès séquentiel aux membres d’un set à partir de son propriétaire. – (C) accès au propriétaire d’un set à partir d’un membre quelconque. Exp: Voir exemple: (fichier model Hier+Reseau) Avantages: Il n’y a pas d’anomalies de MAJ : Suppression: Modification: Insertion: La representation naturelle des liens mailles (M:N) Inconvenients: Proceduralité des LMD == l’utilisateur doit naviguer les chaines de pointeurs. ==== le chemin optimal pour retrouver l’information.")
30
Chapitre 6 Modele Relationnel
Introduction: Le modele relationnel repose sur le concept de relation. La difference entre le modele relationnel et les autres modeles: Les autres modeles considerent des le depart certaines associations priviligies entre entites comme etant des contraintes du systeme. Exp: Le modele relationnel consider les entites comme etant autonomes et permet l’etablissement de toute association nouvelle dont le besoin survient par la suite = le modele relationel n’est pas fige. Dans le modele relationnel, une entite sera consideree comme une relation. Au modele relationnel est associe une theorie tres importante connue sous le nom de la theorie de NORMALISATION de relations. Les objectifs de cette theorie: Eliminer les anomalies semantiques qui peuvent provenir de la MAJ Eliminer la redondance des informations.

31
Les concepts de base du modele relationnel:
Domaine: l’ensemble des valeurs d’une categorie dinformation donnee. Une relation: une relation R sur les domaines D1, D2,…..,Dn est un sous ensemble du produit cartesien D1xD2x….xDn forme des tuples (d1,d2,….,dn)/ chaque di d’un tuple donne appartient au domaine Di correspondant. Dans le cadre des BD, une relation est caracterisee par un nom et peut etre vue comme une table a 2 dimensions dans le quel les colonnes correspondent aux domaines et les lignes aux tuples. Les elements d’une relation sont les tuples et ils correspondent a un sous ensemble dun produit cartesien d’une liste de domaines. Exp: Il ne peut pas y avoir 2 tuples identiques dans une relation (2 tuples identiques ssi pour chaque domaine ils ont la meme valeur) Un attribut (ou plusieurs) permettant d’identifier chaque tuple sans ambiguite est une cle possible.
/ chaque di d’un tuple donne appartient au domaine Di correspondant. Dans le cadre des BD, une relation est caracterisee par un nom et peut etre vue comme une table a 2 dimensions dans le quel les colonnes correspondent aux domaines et les lignes aux tuples. Les elements d’une relation sont les tuples et ils correspondent a un sous ensemble dun produit cartesien d’une liste de domaines. Exp: Il ne peut pas y avoir 2 tuples identiques dans une relation (2 tuples identiques ssi pour chaque domaine ils ont la meme valeur) Un attribut (ou plusieurs) permettant d’identifier chaque tuple sans ambiguite est une cle possible.")
32
L’analogie entre le relationnel et les autres modeles:
Relation ------ fichier Tuple (ligne) ------ occurrence Attribut (colonne) -- un element de donnees Representation d’une relation: Exemple. Une BD relationnelle: l’ensemble des schemas de relations et dont les occurences sont les tuples de ces relations. Voir fichier conception relationnelle. Règles à suivre pour concevoir un schéma relationnel
 ------ occurrence. Attribut (colonne) -- un element de donnees. Representation d’une relation: Exemple. Une BD relationnelle: l’ensemble des schemas de relations et dont les occurences sont les tuples de ces relations. Voir fichier conception relationnelle. Règles à suivre pour concevoir un schéma relationnel.")
33
Langages d’interrogation
Algèbre relationnelle Pour comprendre comment le SGBD exécute les requêtes Calcul relationnel à variable nuplet La base logique du langage SQL Calcul relationnel à variable domaine La base logique pour les langages de requêtes graphiques SQL (Structured Query Langage) Ces langages sont équivalents : ils permettent de désigner les mêmes ensembles de données
 Ces langages sont équivalents : ils permettent de. désigner les mêmes ensembles de données.")
34
Algèbre relationnelle
Opérations unaires : sélection des nuplets satisfaisant un certain prédicat Etudiant(Etudiant_ID, Nom, Prénom, Rue, Ville, Code-Postal, Téléphone, Fax, , NumAnnées) σ(Ville=‘ Paris ’) (Etudiant) σ(Ville=‘ Paris ’) and (NumAnnées ≥ 2) (Etudiant) projection : élimination de certains attributs d’une relation ΠNom,Prénom(Etudiant) ΠNom,Prénom( σ(Ville=‘ Paris ’) (Etudiant) ) Exemple:
 σ(Ville=‘ Paris ’) (Etudiant) σ(Ville=‘ Paris ’) and (NumAnnées ≥ 2) (Etudiant) projection : élimination de certains attributs d’une relation. ΠNom,Prénom(Etudiant) ΠNom,Prénom( σ(Ville=‘ Paris ’) (Etudiant) ) Exemple:")
35
Opérations binaires Union : rassemblement des nuplets de 2 relations compatibles Enseignant( Enseignant_ID, Département_ID, Nom, Prénom, Grade, Téléphone, Fax, ) ΠNom,Prénom(Etudiant) ∪ ΠNom,Prénom(Enseignant) Différence : des nuplets de 2 relations compatibles ΠNom,Prénom(Enseignant) - ΠNom,Prénom(Etudiant) Produit cartésien : combinaison des nuplets de 2 relations Département(Département_ID, Nom_Département) Produit cartésien de Enseignant × Departement a pour schéma : (Enseignant_ID, Enseignant.Département_ID, Nom, Prénom, Grade, Téléphone, Fax, , Département.Département_ID, Nom_Département) Exemple:
 ΠNom,Prénom(Etudiant) ∪ ΠNom,Prénom(Enseignant) Différence : des nuplets de 2 relations compatibles. ΠNom,Prénom(Enseignant) - ΠNom,Prénom(Etudiant) Produit cartésien : combinaison des nuplets de 2 relations. Département(Département_ID, Nom_Département) Produit cartésien de Enseignant × Departement a pour schéma : (Enseignant_ID, Enseignant.Département_ID, Nom, Prénom, Grade, Téléphone, Fax, , Département.Département_ID, Nom_Département) Exemple:")
36
Jointure Jointure naturelle :
une composition de deux opérations (prooduit cartésien, sélection) Exemple: expression de requêtes avec l ’algèbre : Exps:
 Exemple: expression de requêtes avec l ’algèbre : Exps:")
37
Normalisation d’un schéma relationnel
Mises à jour et cohérence But d'un schéma logique : décrire une BD qui va effectivement être utilisée chargée , accédée , mise à jour (maj) Les maj (insertions, suppressions, modifications) doivent conserver la cohérence de la base de données intégrité référentielle toute contrainte d'intégrité en particulier les dépendances entre attributs Plus la bd contient de redondances, plus les maj avec maintien de la cohérence est difficile
 Les maj (insertions, suppressions, modifications) doivent. conserver la cohérence de la base de données. intégrité référentielle. toute contrainte d intégrité. en particulier les dépendances entre attributs. Plus la bd contient de redondances, plus les maj avec. maintien de la cohérence est difficile.")
38
Exemple d'anomalies de maj
LivraisonTot ( N°f , adrF , N°p , typeP , qté ) 3 ausanne meuble 12 22 Bienne ordinateur 6 22 Bienne papier Lausanne papier Vevey ordinateur 15 Définition : Le fournisseur N°f, qui est actuellement à telle adresse adrF, a livré au total telle quantité du produit N°p, produit qui est de tel type. Si un fournisseur change d’adresse et qu’un seul tuple est mis à jour ⇒ incohérence Si un nouveau tuple est inséré pour un fournisseur connu, avec une adresse différente ⇒ incohérence Impossibilité d'enregistrer un nouveau fournisseur sans livraison
 3 ausanne 52 meuble Bienne 10 ordinateur Bienne 25 papier Lausanne 25 papier Vevey 10 ordinateur 15. Définition : Le fournisseur N°f, qui est actuellement à telle. adresse adrF, a livré au total telle quantité du produit N°p, produit qui est de tel type. Si un fournisseur change d’adresse et qu’un seul tuple est. mis à jour ⇒ incohérence. Si un nouveau tuple est inséré pour un fournisseur connu, avec une adresse différente ⇒ incohérence. Impossibilité d enregistrer un nouveau fournisseur sans. livraison.")
39
Qu’est-ce qu’une BD relationnelle ‘incorrecte’ ?
Une relation n’est pas correcte si : elle implique des répétitions au niveau de sa population elle pose des problèmes lors des maj (insertions, modifications et suppressions) Les conditions pour qu'une relation soit correcte peuvent être définies formellement : => règles de normalisation
 Les conditions pour qu une relation soit correcte peuvent être définies formellement : => règles de normalisation.")
40
Exemple (suite) LivraisonTot ( N°f , adrF , N°p , typeP , qté )
3 ausanne meuble 12 22 Bienne ordinateur 6 22 Bienne papier Lausanne papier Vevey ordinateur 15 L’adresse du fournisseur ne dépend que du fournisseur et pas du produit. Le type du produit ne dépend que du produit et pas du fournisseur ⇒ REDONDANCES ⇒ Anomalies de mise à jour Cette relation n'est pas correcte. Il faut la normaliser.

41
Normalisation d'un schéma logique
Processus de transformation d'un schéma S1 pour obtenir un schéma S2 : qui est équivalent (même contenu) dont les maj assurant la cohérence de la bd sont simples maj simple : un changement élémentaire dans le monde réel se traduit par une mise à jour d'un tuple Exemples de changements élémentaires LivraisonTot (N°f, adrF, N°p, typeP, qté) La quantité totale pour un produit et un fournisseur est mise à jour => 1 tuple à m.a.j. Un fournisseur change d'adresse => N tuples à m.a.j.
 dont les maj assurant la cohérence de la bd sont simples. maj simple : un changement élémentaire dans le monde réel se traduit. par une mise à jour d un tuple. Exemples de changements élémentaires. LivraisonTot (N°f, adrF, N°p, typeP, qté) La quantité totale pour un produit et un fournisseur est mise à jour => 1 tuple à m.a.j. Un fournisseur change d adresse => N tuples à m.a.j.")
42
Normalisation d'une relation
Processus de décomposition d'une relation à maj complexes en plusieurs relations à maj simples Processus sur le schéma relationnel formel Exemple : La relation LivraisonTot (N°f, adrF, N°p, typeP, qté) sera décomposée en : LivraisonTot’ (N°f, N°p, qté) Fournisseur (N°f, adrF) Produit (N°p, typeP)
 sera décomposée en : LivraisonTot’ (N°f, N°p, qté) Fournisseur (N°f, adrF) Produit (N°p, typeP)")
43
Normalisation On mesure la qualité d'une relation par son degré de normalisation : 1FN (première forme normale), 2FN, 3FN, FNBC (forme normale de Boyce Codd), 4FN, etc.
, 2FN, 3FN, FNBC (forme normale de Boyce Codd), 4FN, etc.")
44
Dependances fonctionnelles:
Une DF represente une contrainte d’integrite du systeme dans le modele relationnel. Soit une relation R ayant au moins deux attributs A et B. on dit que l’attribut B est fonctionnellement dependant de A si a chaque instant la valeur de l’attribut A determine celle de B, en d’autres termes quqand on connait A on connait B. la Df est notee par A determine---- B. Exemples: La DF est transitive: Exemple Si un attribut est FD d’un groupe d’attributs sans qu’il le soit avec une partie de ce groupe alors dans ce cas cet attribut est totalement dependant de la concatenation de ces attributs: c’est la DF totale. Exemple.

45
Exemple de Conception d’un schema relationnel:
on veut modeliser par des relations la possession des voitures par des personnes. Une seule relations appelee PROPRIETAIRE. (nom-personne, CIN, N voiture, Marque, adresse, type, puissance, couleur, date achat, prix) Exercise: Trouver toutes les DF simples et transitives Les anomalies de cette relation: LA REDONDANCE === marque, type, nom-personne Risque d’inconsistence Problemes de MAJ (suppression, insertion) ==== solution : DECOMPOSITION DES RELATIONS Approche par decomposition: elle tend a partir d’une relation composee de tous les attributs a decomposer cette relation en un ensemble de relations qui ne souffrent pas des anomalies:
 Exercise: Trouver toutes les DF simples et transitives. Les anomalies de cette relation: LA REDONDANCE === marque, type, nom-personne. Risque d’inconsistence. Problemes de MAJ (suppression, insertion) ==== solution : DECOMPOSITION DES RELATIONS. Approche par decomposition: elle tend a partir d’une relation composee de tous les attributs a decomposer cette relation en un ensemble de relations qui ne souffrent pas des anomalies:")
46
Les Operations sur les BD relationelles:
== la relation precedente peut etre remplacee par 3 relations: Personne (CIN, nom, adresse) Voiture (N voiture, Marque, type, puissance, couleur) Propriete ( CIN, N Voiture, date achat, prix) Les Operations sur les BD relationelles: La comprehension de la theorie de decomposition des relations necessite la connaissance de 2 operations de manipulation de relations: PROJECTION JOINTURE La projection: La projection d’une relation de schema R(A1,A2,….,An) sur les attributs (Ai1, Ai2,….,Aip) avec p <= n et ij#ik est une relation R’ de schema (Ai1,Ai2,…..,Aip) dont les tuples sont ceux obtenus par elimination des valeurs des attributs de R qui n’appartienent pas a R’ et par suppression des tuples en double. La projection est notee par Π. Exp.
 Voiture (N voiture, Marque, type, puissance, couleur) Propriete ( CIN, N Voiture, date achat, prix) Les Operations sur les BD relationelles: La comprehension de la theorie de decomposition des relations necessite la connaissance de 2 operations de manipulation de relations: PROJECTION. JOINTURE. La projection: La projection d’une relation de schema R(A1,A2,….,An) sur les attributs (Ai1, Ai2,….,Aip) avec p <= n et ij#ik est une relation R’ de schema (Ai1,Ai2,…..,Aip) dont les tuples sont ceux obtenus par elimination des valeurs des attributs de R qui n’appartienent pas a R’ et par suppression des tuples en double. La projection est notee par Π. Exp.")
47
La theorie de normalisation:
La jointure: l’operation inverse de la projection. La jointure de 2 relations R et S de schems respectifs R(A1,A2,….,An) et S (B1,B2,….,Bp) est une relation T ayant pour attributs l’union des attributs de R et de S. la jointure se fait par au moins un attribut commun. Exp. La theorie de normalisation: La normalisation des relations est un concept base sur un processus de decomposition de relations de base de telle sorte d’aboutir a un ensemble de relations qui ne souffrent des pbs de redondances et de MAJ et ceci sans perte d’informations (cad la jointure naturelle des relations permet de retrouver les relations de base). La theorie de normalisation est basee sur une serie de formes normales (1FN, 2FN, ….6FN). 1ere forme normale:une relation est en 1FN si tous ses attributs sont: Simples Atomiques Non decomposables Ne forment pas de groupes repetitifs
 et S (B1,B2,….,Bp) est une relation T ayant pour attributs l’union des attributs de R et de S. la jointure se fait par au moins un attribut commun. Exp. La theorie de normalisation: La normalisation des relations est un concept base sur un processus de decomposition de relations de base de telle sorte d’aboutir a un ensemble de relations qui ne souffrent des pbs de redondances et de MAJ et ceci sans perte d’informations (cad la jointure naturelle des relations permet de retrouver les relations de base). La theorie de normalisation est basee sur une serie de formes normales (1FN, 2FN, ….6FN). 1ere forme normale:une relation est en 1FN si tous ses attributs sont: Simples. Atomiques. Non decomposables. Ne forment pas de groupes repetitifs.")
48
2eme forme normale: Une relation est en 2eme FN si:
Elle est en 1ere FN. Tout attribut n’appartenant pas a la cle primaire ne depend pas d’une partie de cette cle (depend de toute la cle) Exp: Autrement dit: une relationm est en 2eme FN si: Elle set en 1ere FN Si l’une des 3 conditions suivantes est verifiee: La cle primaire est formee d’un seul attribut La cle primaire contient tous les attributs de la relation Tout attribut qui ne fait pas partie de la cle depend de toute celle ci et pas seulement d’une partie.
 Exp: Autrement dit: une relationm est en 2eme FN si: Elle set en 1ere FN. Si l’une des 3 conditions suivantes est verifiee: La cle primaire est formee d’un seul attribut. La cle primaire contient tous les attributs de la relation. Tout attribut qui ne fait pas partie de la cle depend de toute celle ci et pas seulement d’une partie.")
49
3eme Forme normale: 4eme forme normale:?
Une relation est en 3eme FN si: Elle est en 2eme FN Tout attribut n’appartenant pas a la cle ne depend pas d’un attribut non cle (aucun attribut non cle ne peut dependre d’un autre qui ne fait pas partie de la cle primaire) Exp: 4eme forme normale:? Transformation d’un modele quleconque en un model relationnel normalise: Hierarchique --- relationnel : exp. Reseau -- relationnel : exp
 Exp: 4eme forme normale: Transformation d’un modele quleconque en un model relationnel normalise: Hierarchique --- relationnel : exp. Reseau -- relationnel : exp.")
50
INTRODUCTION A ORACLE ORACLE is un SGBD relationnel compose d’un noyau, SQL (Structured Query Language), UFI (User Friendly Interface) et des utilitaires. SQL est l’interface principale pour ORACLE. Elle est consideree comme “on line query language”. SQL dispose de plusieurs commandes pour des taches differentes: Requettes insertion, mise a jour, et suppression des donness dans les tables creation, remplacement, modification et elimination des tables. controler les acces aux database et tables guarantir l’ integrite des donnees creation des TABLES et ajout des donnees : CREATE, INSERT === EXEMPLES DESCRIBE, START, SPOOL, ….., SPOOL OFF/SPOOL OUT.==== EXEMPLES ALTER, DROP SET ECHO ON, SET LINESIZE algebre relationnelle: c’est un language reservee principalement a la recherceh des donnees . Elle est basee sur un ensemble d’operateurs unaires et binaires qui operent sur des tables. SELECT COMMAND: (sur une table) Syntax: SELECT (liste des attributs) FROM <table> [ WHERE <Conditions>] SELECT * FROM <table> [ WHERE <conditions>] Exp: relation INVOICE (inv-no, cust-no, inv-date, amount) SELECT inv-no, cust-no FROM INVOICE; SELECT DISTINCT Cust-no FRON INVOICE;
, UFI (User Friendly Interface) et des utilitaires. SQL est l’interface principale pour ORACLE. Elle est consideree comme on line query language . SQL dispose de plusieurs commandes pour des taches differentes: Requettes. insertion, mise a jour, et suppression des donness dans les tables. creation, remplacement, modification et elimination des tables. controler les acces aux database et tables. guarantir l’ integrite des donnees. creation des TABLES et ajout des donnees : CREATE, INSERT === EXEMPLES. DESCRIBE, START, SPOOL, ….., SPOOL OFF/SPOOL OUT.==== EXEMPLES. ALTER, DROP. SET ECHO ON, SET LINESIZE. algebre relationnelle: c’est un language reservee principalement a la recherceh des donnees . Elle est basee sur un ensemble d’operateurs unaires et binaires qui operent sur des tables. SELECT COMMAND: (sur une table) Syntax: SELECT (liste des attributs) FROM <table> [ WHERE <Conditions>] SELECT * FROM <table> [ WHERE <conditions>] Exp: relation INVOICE (inv-no, cust-no, inv-date, amount) SELECT inv-no, cust-no FROM INVOICE; SELECT DISTINCT Cust-no FRON INVOICE;")
51
Copier des tuples a partir d’autres tables:
Requettes simples: Copier des tuples a partir d’autres tables: Populate une table durant la creation avec des donnees d’une autre table: SELECT * FROM INVOICE; SELECT * FROM INVOICE WHERE Cust-no = 101; SELECT * FROM INVOICE WHERE Cust-no = 101 AND amount > 500; SELECT invno FROM INVOICE WHERE inv-date != ’02-JAN-92’; Cette requette n’inclut pas l’enregistrement numero 6 . SELECT COUNT(*) FROM INVOICE WHERE inv-date = NULL; ERREUR SELECT COUNT(*) FROM INVOICE WHERE inv-date IS NULL; SELECT * FROM INVOICE WHERE amount BETWEEN 60 AND 90; SELECT * FROM INVOICE WHERE cust-no IN (100, 101); SELECT * FROM INVOICE ORDER BY amount; SELECT * FROM INVOICE ORDER BY amount DESC; Recherche par group: SELECT AVG(amount) FROM INVOICE ; SELECT AVG(amount) “average amount” FROM INVOICE; SELECT AVG(amount) FROM INVOICE; SELECT COUNT(inv-date) FROM INVOICE; SELECT COUNT(inv-date), AVG (amount) FROM INVOICE GROUP BY cust-no; SELECT cust-no, COUNT(*), AVG (amount) FROM INVOICE GROUP BY cust-no; SELECT cust-no, COUNT(*) FROM INVOICE GROUP BY cust-no HAVING COUNT(*) >=3; Exp2 : on considere une autre table CUSTOMER (cust-no, name, address, credit-lim) SELECT * FROM CUSTOMER WHERE name LIKE ‘A_C%’;
 FROM INVOICE WHERE inv-date = NULL; ERREUR. SELECT COUNT(*) FROM INVOICE WHERE inv-date IS NULL; SELECT * FROM INVOICE WHERE amount BETWEEN 60 AND 90; SELECT * FROM INVOICE WHERE cust-no IN (100, 101); SELECT * FROM INVOICE ORDER BY amount; SELECT * FROM INVOICE ORDER BY amount DESC; Recherche par group: SELECT AVG(amount) FROM INVOICE ; SELECT AVG(amount) average amount FROM INVOICE; SELECT AVG(amount) FROM INVOICE; SELECT COUNT(inv-date) FROM INVOICE; SELECT COUNT(inv-date), AVG (amount) FROM INVOICE GROUP BY cust-no; SELECT cust-no, COUNT(*), AVG (amount) FROM INVOICE GROUP BY cust-no; SELECT cust-no, COUNT(*) FROM INVOICE GROUP BY cust-no HAVING COUNT(*) >=3; Exp2 : on considere une autre table CUSTOMER (cust-no, name, address, credit-lim) SELECT * FROM CUSTOMER WHERE name LIKE ‘A_C%’;")
52
L’editeur SQL : Recherche a travers des jointures:
Modification et elimination des donnees: Update command: utilisation de WHERE pour specifier la ligne a modifier. Delete command : utilisation de WHERE pour specifier la ligne a eliminer. Recherche a travers des jointures: Jointure simple de 2 tables: On a besoin du client (nom et adresse) qui a commande la facture numero 2.? Jointure avec alias: La meme requette: Self joins: Pour chaque client, on a besoin de la liste de tous les autres clients qui une limite de credit superieure.? Autres jointures: La liste des clients avec leurs factures (les numeros uniquement). les attributs NULL? La meme liste ou apparait les attributs NULLs? L’editeur SQL : Commande change : La commande LIST ldonne le contenu du buffer SQL. L’etoile (*) indique la ligne courante. Taper une serie de commandes SQL> C/cusno/name ? Typer la numero de la ligne pour changer la ligne couranet (SQL> 2) . La commande INPUT insert une ou plusieurs lignes apres la ligne courante. La commande DEL supprime la ligne courante. La commande APPEND texte = insert du texte a la fin de la ligne courante. La commande RUN pour executer ou bien / Les commandes Save and GET . Les commandes EDIT and START.
 qui a commande la facture numero 2. Jointure avec alias: La meme requette: Self joins: Pour chaque client, on a besoin de la liste de tous les autres clients qui une limite de credit superieure. Autres jointures: La liste des clients avec leurs factures (les numeros uniquement). les attributs NULL La meme liste ou apparait les attributs NULLs L’editeur SQL : Commande change : La commande LIST ldonne le contenu du buffer SQL. L’etoile (*) indique la ligne courante. Taper une serie de commandes. SQL> C/cusno/name Typer la numero de la ligne pour changer la ligne couranet (SQL> 2) . La commande INPUT insert une ou plusieurs lignes apres la ligne courante. La commande DEL supprime la ligne courante. La commande APPEND texte = insert du texte a la fin de la ligne courante. La commande RUN pour executer ou bien / Les commandes Save and GET . Les commandes EDIT and START.")
53
Les commandes de formattage des rapports:
on besoin de la liste des clients (leurs noms), avec leurs factures (inv-numbers, inv-dates, inv-amounts) triees pae les noms des clients. On peut ameliorer l’apparence des resultats de la meme requette: TTITLE CENTER/LEFT/RIGHT ‘…………text…..’ = genere le titre du haut de la page. SKIP 2 = saute 2 lignes BTITLE RIGHT ‘page’ SQL.PNO == insert le titre du bas de la page avec une variable systeme SQL.PNO. BREAK ON NAME SKIP 1 == eliminates les clients doubles et insert une ligne vide chaque fois que le client change. COMPUTE SUM OF invamt ON NAME = calcule le total des Qtes pour chaque nom client . COMPUTE SUM OF invamt ON REPORT == calcule les grand totaux. COLUMN name HEADING ‘………’ == insert un titre pour la colonne du rapport.
, avec leurs factures (inv-numbers, inv-dates, inv-amounts) triees pae les noms des clients. On peut ameliorer l’apparence des resultats de la meme requette: TTITLE CENTER/LEFT/RIGHT ‘…………text…..’ = genere le titre du haut de la page. SKIP 2 = saute 2 lignes. BTITLE RIGHT ‘page’ SQL.PNO == insert le titre du bas de la page avec une variable systeme SQL.PNO. BREAK ON NAME SKIP 1 == eliminates les clients doubles et insert une ligne vide chaque fois que le client change. COMPUTE SUM OF invamt ON NAME = calcule le total des Qtes pour chaque nom client . COMPUTE SUM OF invamt ON REPORT == calcule les grand totaux. COLUMN name HEADING ‘………’ == insert un titre pour la colonne du rapport.")
54
Des requettes plus complexes:
Sous requette: Sous requettes correles. Operateur EXISTS/NOT EXISTS.

55
Les Indexes : Buts : 1)reduction du temps d’acces et 2) renforcer l’unicite de la cle primaire. Creation des indexes: Syntaxe: CREATE INDEX <index-name> ON TABLE <table-name> (col-name1, col-name2,……) Exp: create index inv-index on invoice (custno) Unique index: = CREATE UNIQUE INDEX <index-name> ON TABLE <table-name> (col-name1, col-name2, ……) Exp: create unique index customer-index on customer (custno); Exp: create unique index invoice-index on invoice (invno, custno); == jusqu’a 16 colonnes pour un indexe == les indexes sont logiquement et physiquement independent des donnees . = les indexes peuvent etre crees et detruits a n’importe quel moment. Dropping un index: DROP INDEX index-name;
 Exp: create index inv-index on invoice (custno) Unique index: = CREATE UNIQUE INDEX <index-name> ON TABLE <table-name> (col-name1, col-name2, ……) Exp: create unique index customer-index on customer (custno); Exp: create unique index invoice-index on invoice (invno, custno); == jusqu’a 16 colonnes pour un indexe. == les indexes sont logiquement et physiquement independent des donnees . = les indexes peuvent etre crees et detruits a n’importe quel moment. Dropping un index: DROP INDEX index-name;")
56
Contraintes d’integrite:
Unique key: 2 lignes d’une table ne peuvent pas avoir les memes valeurs pour une ou plusieurs colonnes . Cette constrainte genere automatiquement un index unique pour les colonne(s), mais elle ne met pas ces dernieres a NOT NULL. Primary key: 2 lignes d’une table ne peuvent pas avoir les memes valeurs pour une ou plusieurs colonnes, et valeurs NULL ne sont pas permises pour ces colonnes. Cette constrainte genere automatiquement un index unique pour les colonne(s), elle met ces dernieres a NOT NULL. Exp: create table deparment ( deptno number(4) PRIMARY KEY, deptname varchar2(20) UNIQUE, ……. ) Foreign key: renforce l’ integrite referentielle.. Exp: 2 tables: Employee(empno, empname, salary, deptno) department (deptno, dept-name, deptchief) deptno (in employee table) est une cle etrangere qui refernce la cle primaire deptno dans la table department == Oracle s’assure que chaque valeur de deptno dans la table employee doit correspondre a une valuer de deptno dans la table department ou bien avoir une valeur NULL .
, mais elle ne met pas ces dernieres a NOT NULL. Primary key: 2 lignes d’une table ne peuvent pas avoir les memes valeurs pour une ou plusieurs colonnes, et valeurs NULL ne sont pas permises pour ces colonnes. Cette constrainte genere automatiquement un index unique pour les colonne(s), elle met ces dernieres a NOT NULL. Exp: create table deparment ( deptno number(4) PRIMARY KEY, deptname varchar2(20) UNIQUE, ……. ) Foreign key: renforce l’ integrite referentielle.. Exp: 2 tables: Employee(empno, empname, salary, deptno) department (deptno, dept-name, deptchief) deptno (in employee table) est une cle etrangere qui refernce la cle primaire deptno dans la table department == Oracle s’assure que chaque valeur de deptno dans la table employee doit correspondre a une valuer de deptno dans la table department ou bien avoir une valeur NULL .")
57
Desactiver les contraintes:
Create table employee ( Empno numbre(4) primary key, Empname varchar2(20), Salary number(6), Deptno number(4) foreign key references department (deptno)); Contrainte CHECK : Utilises pour une ou plueieurs colonnes qui doivent satisfaire des conditions: Exp: a table parts(partid, color, maxdiscount) ou color pourra etre RED ou BLACK et la valeur maximum de discount est 50%. == create table parts ( partid number primary key, color varchar2(5) CONSTRAINT VALID_COLOR CHECK(COLOR IN(‘RED’, ‘BLACK’)), maxdiscount number (2) NOT NULL CONSTRAINT VALID_DISCOUNT CHECK (maxdiscount , 50)); Desactiver les contraintes: Alter table employee DISABLE Primary key; Alter table parts DIABLE CONSTRAINT VALID_COLOR;
 primary key, Empname varchar2(20), Salary number(6), Deptno number(4) foreign key references department (deptno)); Contrainte CHECK : Utilises pour une ou plueieurs colonnes qui doivent satisfaire des conditions: Exp: a table parts(partid, color, maxdiscount) ou color pourra etre RED ou BLACK et la valeur maximum de discount est 50%. == create table parts ( partid number primary key, color varchar2(5) CONSTRAINT VALID_COLOR CHECK(COLOR IN(‘RED’, ‘BLACK’)), maxdiscount number (2) NOT NULL CONSTRAINT VALID_DISCOUNT CHECK (maxdiscount , 50)); Desactiver les contraintes: Alter table employee DISABLE Primary key; Alter table parts DIABLE CONSTRAINT VALID_COLOR;")
58
Creation et utilisation des vues: == tables virtuelles
Creation: create view viewname [col-name,…..] AS query [WITH CHECK OPTION] EXP: creer une vue a partir de la table invoice table qui contient les details invoice details du client numero 101 seulement: Create view inv101 AS select invno, cusno, invdate, invamt from invoice where cusno=101; Insert into inv101 values (9, 999, ’02-jan-93’, 99); insert ces donnes dans la table invoice. from invoice where cusno=101 WITH CHECK OPTION; Insert into inv101 values (9, 999, ’02-jan-93’, 99) ; genere une erreur.
; insert ces donnes dans la table invoice. from invoice where cusno=101 WITH CHECK OPTION; Insert into inv101 values (9, 999, ’02-jan-93’, 99) ; genere une erreur.")
59
Exemples: Elimination des vues:
Creer une vue contenant le sous ensemble des colonnes (custno, custname) a partir de la table customer Creer une vue qui, pour chaque client, donne le montant total des factures. Creer une vue contenant les details invoice (de la table invoice ) avec le nom client (de la table customer ) Elimination des vues: DROP VIEW viewname; Exp: Drop view inv101;
 a partir de la table customer. Creer une vue qui, pour chaque client, donne le montant total des factures. Creer une vue contenant les details invoice (de la table invoice ) avec le nom client (de la table customer ) Elimination des vues: DROP VIEW viewname; Exp: Drop view inv101;")
Présentations similaires

 L'algèbre relationnelle.>")









 langage dinterrogation dune base de données.>")







